深度单应估计的经典论文《Content-Aware Unsupervised Deep Homography Estimation》ECCV2020
研究背景与问题
单应性估计(Homography Estimation)是许多计算机视觉应用中的基础图像对齐方法,适用于场景近似为平面或相机仅发生旋转运动的情况,在多帧 HDR 成像、图像超分辨率、视频 stabilization 等领域有广泛应用。
传统方法通常通过提取和匹配稀疏特征点(如 SIFT + RANSAC)来实现,但在低光照、低纹理图像中容易出错;现有深度单应性方法存在局限:
-
有监督方法依赖合成图像的真实单应性作为监督信号,缺乏真实场景的深度差异信息,泛化能力差;
-
无监督方法(如 Nguyen 等人的研究)虽使用真实图像对,但直接基于图像像素强度计算损失,且未考虑类似 RANSAC 的离群点剔除过程,难以处理深度差异和运动物体。
算法细节
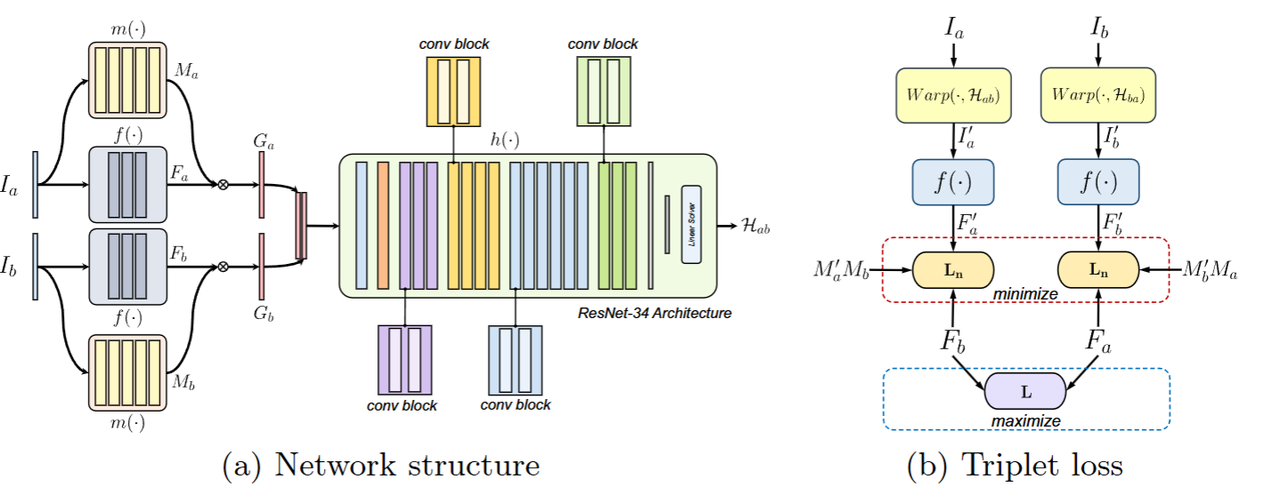
网络结构
该方法基于卷积神经网络构建,输入为两个灰度图像块Ia和Ib,输出为从Ia到Ib的单应性矩阵Hab。整体结构分为三个核心模块:特征提取器、掩码预测器和单应性估计器,均采用全卷积网络设计,可处理任意尺寸的输入。
- 在训练过程中,为避免扭曲图像出现黑边,会从原始图像中随机裁剪尺寸为 315×560 的图像块来构造输入Ia和Ib
- 特征提取器(Feature Extractor)
-
主要作用++:从输入图像中自动学习用于对齐的深度特征,而非直接使用图像的++ ++像素++ ++强度值++。(以往基于深度神经网络DNN的方法直接用像素值作为特征描述)这种设计的原因在于,像素强度容易受到光照、曝光等因素的影响,而学习到的深度特征能更好地捕捉图像的本质结构信息,从而在复杂条件下保持对齐的稳定性、
-
做法:构建了一个全卷积网络FCN,对于输入的两个图像块Ia和Ib,特征提取器通过++共享所有网络参数++的方式分别生成特征图Fa和Fb。这一机制保证了对两幅图像的特征提取遵循相同的映射规则,避免因特征空间不一致导致的对齐误差,是实现准确特征对比的基础
-
优势:在光照变化场景中,学习到的特征比像素强度更稳定,可提升损失计算的有效性
- 掩码预测器(Mask Predictor)
-
作用:学习识别图像中适合单应性变换的可靠区域(内点区域),同时抑制可能导致估计误差的离群区域(如运动物体、非平面区域、低纹理区域等)
-
并非单纯寻找两张图的重叠部分:具体来说,即使两张图存在重叠区域,其中部分重叠区域(如动态前景)也无法通过单应性矩阵对齐。++掩码预测器通过生成内点概率掩码,重点关注那些满足单应性变换约束的区域(如静态平面区域),并弱化不满足约束的区域的影响++,这一过程更接近传统 RANSAC 算法的离群点剔除逻辑,而非简单的重叠区域检测
-
例如,在包含运动车辆的街道场景中,两张图的重叠区域可能包括车辆和路面,但车辆属于动态物体(离群区域),路面属于静态平面(内点区域)。掩码预测器会突出路面区域的权重,降低车辆区域的权重,从而提升单应性估计的准确性
-
-
数学表达:

 编辑
编辑 -
双重作用:
-
作为注意力图(Attention Map),突出重要特征区域;
-
作为离群点剔除器(Outlier Rejecter),过滤运动物体或非平面区域
-
- 单应性估计器(Homography Estimator)
-
输入:经过上一步掩码加权后的特征图Ga和Gb
-
输出与计算:采用 ResNet-34 作为骨干网络,输出 8 个值(4 个角点的 2D 偏移向量),通过线性系统求解得到 8 自由度的单应性矩阵Hab
三元组损失函数(Triplet Loss for Robust Homography Estimation)
哪三元?
|----------|--------------------------------|--------------|
| 三元组中的"元" | 含义 | 符号 |
| 1. 原始对 | 未对齐前的特征差异 | ∥Fa−Fb∥1 |
| 2. 正向对齐 | 用估计的 Hab 将 Ia 对齐到 Ib 后的特征差异 | ∥Fa′−Fb∥1 |
| 3. 反向对齐 | 用估计的 Hba 将 Ib 对齐到 Ia 后的特征差异 | ∥Fb′−Fa∥1 |
-
定义:损失函数=min(对齐误差+反向对齐误差-防止退化约束+Homography 一致性约束)
-
对齐误差:希望对齐后的特征图 Fa ′ 与目标特征图 Fb 尽可能接近,且只考虑 mask 覆盖的区域
-
反向对其误差:对齐后的特征图 Fb ′ 与目标特征图 Fa 尽可能接近
-
防退化:如果只用对齐误差,网络可能会学到一个退化解:输出全零特征图(即 Fa =Fb =0),这样对齐误差也为 0,但显然没学到任何有用信息。鼓励原始特征图 Fa ,Fb 保持一定差异,防止全零特征。最小化对齐误差的同时,最大化这个差异(即公式中的负号)。
-
一致性:确保 Hab 和 Hba 互为逆矩阵
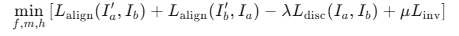
-
无监督内容感知学习(Unsupervised Content-Awareness Learning)
对网络结构中的掩码预测器(Mask Predictor)进行详细设计与解释,其目的是让网络通过无监督学习自动识别图像中适合单应性估计的可靠区域,同时剔除异常区域
具体的训练策略:
-
第一阶段:禁用掩码的注意力作用,仅通过损失加权作用初步学习掩码的离群点剔除能力,训练约 60k 次迭代。
-
第二阶段:启用注意力作用,联合优化掩码的双重角色。
实验步骤
-
训练阶段:从一张大图(如1920×1080)中随机裁剪两个 patch(如315×560),用于训练网络估计 Hab。
-
推理阶段:整张图不再裁剪,而是整张图输入网络,直接估计整张图的 homography。