导读:
基于深度学习的推荐算法已成为推荐系统领域的研究趋势。然而,大多数现有工作仅考虑单一的用户与物品交互数据,限制了算法的预测性能。本文提出一种画像约束的编码方式,并融合隐因子模型中的潜在特征,丰富了推荐算法的输入以提升评分预测的准确性。该算法利用矩阵分解得到潜在特征初始化用户与物品的嵌入,然后通过线性注意力机制增强模型对画像特征的敏感度,最后结合深度神经网络进行评分预测。通过本文算法与其他基线算法在MovieLens与Netflix数据集上进行对比,该算法与基线算法相比显著提高了评分预测的精度,并在推荐列表排序性能等方面表现出色。本文的研究揭示了加入用户与物品的画像约束和潜在特征,可以有效提升推荐系统的性能。
关注汉斯,获取更多论文资讯,如您需要论文原文,欢迎私信获取~
作者信息:
艾 均, 柏光耀, 苏 湛, 马菀言:上海理工大学光电信息与计算机工程学院,上海
正文
推荐算法的发展呈现出以下几个主要趋势:基于隐因子模型的推荐算法、基于用户画像的推荐算法、基于深度学习的推荐算法。
推荐系统发展至今仍面临一些问题:1) 大多数推荐算法仅依赖用户对物品的显式反馈,如用户--物品评分数据,往往忽视了用户的兴趣或隐式偏好,导致推荐效果难以达到最佳。2) 如何从复杂的用户--物品交互数据中有效提取并利用用户与物品的特征,是提升个性化推荐算法准确性的重要挑战。3) 当遇到新用户或新物品时,由于缺乏历史数据,推荐系统难以提供准确的推荐,进而面临冷启动问题。针对如何利用用户的兴趣或隐式偏好以及如何从复杂的交互数据中提取并利用用户和物品的特征,本文提出一种融合画像约束和潜在特征的深度推荐算法(Deep Portrait Feature and Latent Embedding Algorithm, DPFLE)。
大多数基于深度学习的推荐算法仅依赖于用户--物品评分数据,且普遍存在可解释性不足的问题,本文提出的DPFLE使用矩阵分解初始化用户和物品的嵌入向量,利用物品标签信息构建细粒度的画像向量,并通过线性注意力机制增强模型对画像特征的敏感度,丰富算法输入的同时还改善了算法的可解释性。
算法设计
整体算法如图1所示。首先对用户--物品评分矩阵,使用矩阵分解技术,得到用户和物品的潜在特征,利用预先计算的潜在特征来初始化用户嵌入层以及物品嵌入层。随后,利用物品的标签信息并结合评分信息计算出用户和物品的画像向量,经过portrait_encoder层编码得到用户画像约束以及物品画像约束,对这个四个特征进行融合,之后利用深度神经网络进行评分预测。
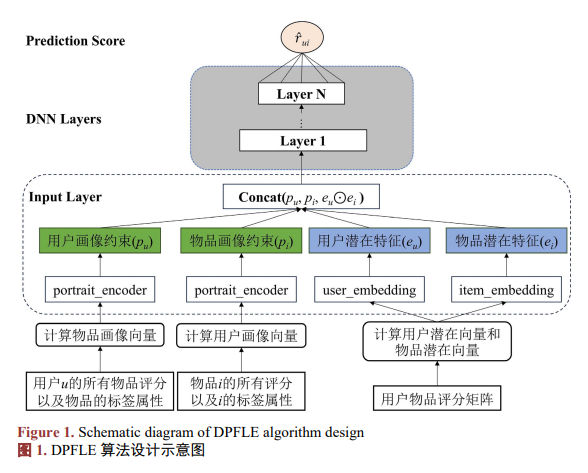
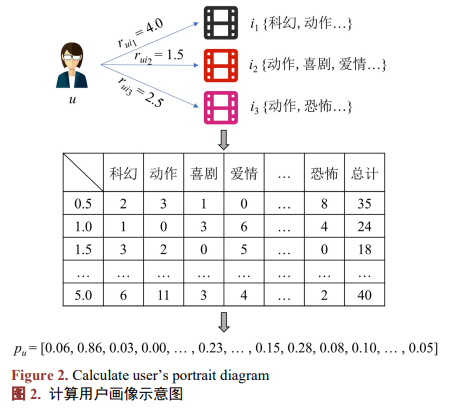
在电影推荐领域,电影标签作为电影的抽象表示,蕴含了丰富的用户隐式信息,合理利用电影标签数据,可以有效提升推荐算法的性能,具有重要的应用价值。 通过统计用户对不同标签的物品在不同评分下的评分次数,并除以相同评分下的评分总次数最后进行拼接操作得到用户的画像向量。具体过程如图2所示。
实验设计与分析
1. 数据集
本文使用经典数据集MovieLens以及Netflix来验证提出的方法。MovieLens25M记录了16万位用户对6万部电影的2500万余条评分数据,评分的范围为0.5到5,间隔为5,电影的类型有动作片、恐怖片、喜剧片等等,一共有19种类型。Netflix记录了48万位用户对1万余部电影的10000万余条评分数据,评分的范围为1到5,间隔为1。本文分别从两个数据集中随机选取1500位用户的所有数据进行实验,以节省计算资源和时间。需要注意的是,由于Netflix数据集中不包含电影类型的信息,因此本文通过电影标题在MovieLens数据集中查找其相应的类型。本文将数据集按照90%,10%的比例将数据集划分为训练集和测试集,每个算法仅基于训练集预测每个测试集中的所有评分,并进行折十验证,最终结果取所有实验的平均值。
2. 评价指标
本文使用平均绝对误差(Mean Absolute Error, MAE) 、均方根误差(Root Mean Square Error, RMSE) 来评估评分预测的误差。MAE反映了算法预测评分与用户实际评分之间的偏差,RMSE表示预测用户评分与实际评分之间偏差的均方根值。使用归一化折损累计增益(Normalized Discounted Cumulative Gain, NDCG) 来评估推荐列表的排序性能。
3. 基线算法
为了评估本文提出的DPFLE的性能,本文将其与其他基线算法进行了上述评价指标的比较。所有算法均取其论文中的最优指标。
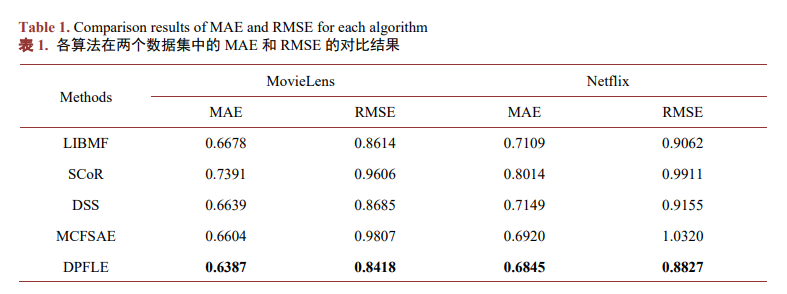
在MovieLens数据集和Netflix数据集中的MAE和RMSE结果对比如表1所示,其中表现最佳的值以黑体加粗标出,后续也用此形式表示最优值。DPFLE的MAE值和RMSE值在两个数据集上相较于其他对比算法均达到了最优。
表2显示了NDCG和Diversity在两个数据集上的结果对比。
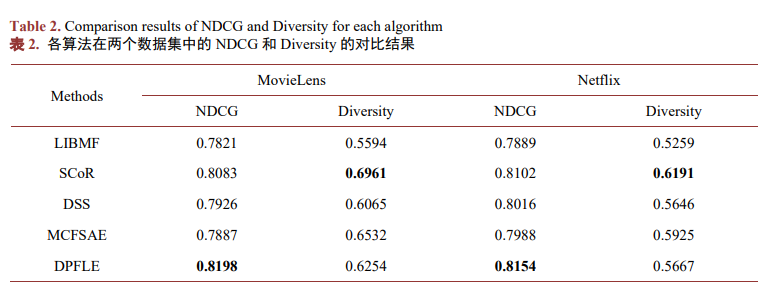
表3显示了各个算法的Accuracy,Precision以及Recall在两个数据集上的表现。
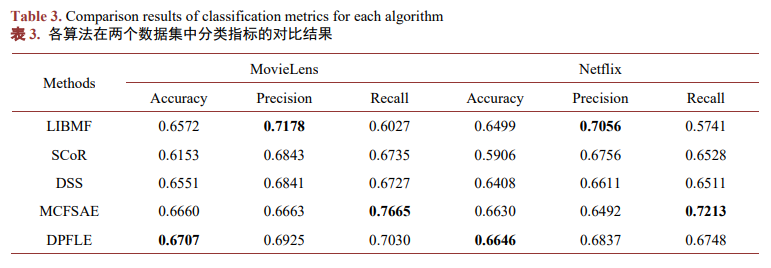
在MovieLens与Netflix数据集中,各算法的总体实验结果表现如图4,其中本文提出的DPFLE在MAE、RMSE、NDCG、Accuracy这四个指标上均取得了最好的效果。由上述实验结果可知,将画像约束与潜在特征相融合并利用深度学习进行评分预测,能够有效降低推荐系统中的误差,并且在推荐列表的排序性能方面也有显著提升。然而,在推荐列表的多样性方面,本文提出的DPFLE表现并不出色。由于将用户与物品的画像约束加入算法中,推荐结果往往集中于用户已经喜欢的物品,而忽视了其他潜在的、有趣的选项。
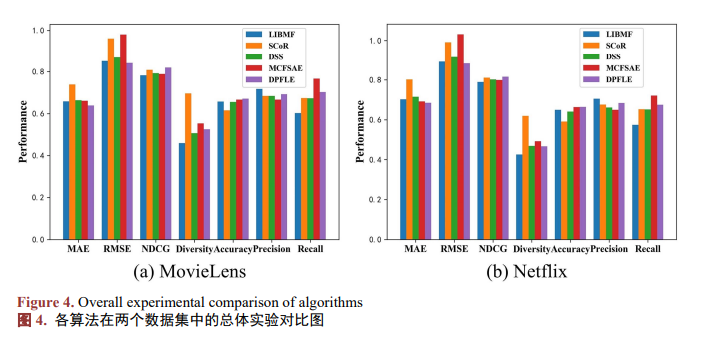
为了探究潜在特征的大小对实验的影响,本文将k 分别设置为50、100、200、300,并在两个数据集上进行实验。表4显示了在不同的潜在特征大小下,DPFLE在两个数据集中的MAE和RMSE的表现。当k 大于300时,MAE和RMSE的实验结果变化非常小,但是算法的执行时间会更长。为了节省计算资源和时间,本文没有过多探究更大的k对实验的影响。
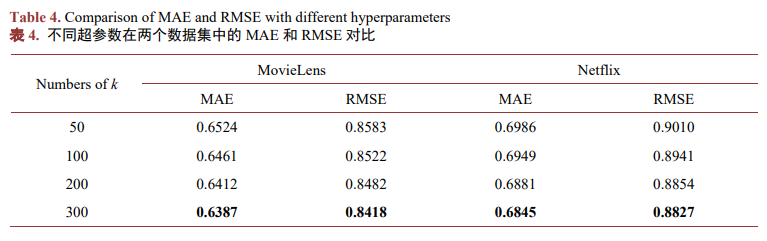
表5显示了去掉AFTSimple注意力模块后与原始算法的比较,其中DPFLE-AFT表示去除注意力模块后的模型,经比较可以得出DPFLE在两个数据集中的MAE平均降低了2.11%,RMSE平均降低了1.16%,说明通过线性注意力机制对画像特征进行加权计算能够更好地捕捉用户和物品之间复杂的关系并提升模型的预测精度。
总结与展望
本文在两个真实世界的数据集中进行了验证,实验结果显示,在预测精度与推荐列表的排序方面,本文所提出的方法相较于一些先进的算法有明显的提升。
在未来的工作中,本文将考虑图神经网络替代传统的多层感知机,利用用户与物品之间的复杂关系构建交互图,挖掘更深层次的特征关联,以提高推荐系统的性能,为用户提供更加个性化和精准的推荐服务。
基金项目:
国家自然科学基金项目(61803264)