模型重构
- 前言:从"数字DNA"到"AI生命体"------模型适配的终极奥义
- 第一章:模型适配的"大图景":挑战、目的与核心方法论
-
- [1.1 挑战:GGUF的"纯数据"与PyTorch的"代码魂"](#1.1 挑战:GGUF的“纯数据”与PyTorch的“代码魂”)
- [1.2 目的:为量化模型提供"活的身体"](#1.2 目的:为量化模型提供“活的身体”)
- [1 .3 核心方法论:命名约定、参数形状与数据类型的三重匹配](#1 .3 核心方法论:命名约定、参数形状与数据类型的三重匹配)
- 第二章:PyTorch模型命名约定与GGUF张量的"契约之舞"
-
- [2.1 PyTorch state_dict:参数的"身份ID"](#2.1 PyTorch state_dict:参数的“身份ID”)
- [2.2 GGUF张量命名:模型的"扁平化地图"](#2.2 GGUF张量命名:模型的“扁平化地图”)
- [2.3 对比LLaMA/UNet模型在PyTorch与GGUF中的命名差异](#2.3 对比LLaMA/UNet模型在PyTorch与GGUF中的命名差异)
- 第三章:核心模块的"骨骼重塑"与权重加载策略
-
- [3.1 通用层解析:nn.Linear、nn.Conv2d/3d、nn.LayerNorm/RMSNorm](#3.1 通用层解析:nn.Linear、nn.Conv2d/3d、nn.LayerNorm/RMSNorm)
-
- [3.1.1 权重(weight)与偏置(bias)的存储与转置陷阱](#3.1.1 权重(weight)与偏置(bias)的存储与转置陷阱)
- [3.1.2 nn.Linear权重加载与转置验证](#3.1.2 nn.Linear权重加载与转置验证)
- [3.1.3 nn.Conv2d权重加载验证](#3.1.3 nn.Conv2d权重加载验证)
- [3.2 LLaMA核心模块的骨架与加载](#3.2 LLaMA核心模块的骨架与加载)
-
- [3.2.1 RMSNorm:轻量化归一器](#3.2.1 RMSNorm:轻量化归一器)
- [3.2.2 Attention (RoPE集成):最复杂的"核心处理器"](#3.2.2 Attention (RoPE集成):最复杂的“核心处理器”)
- [3.2.3 FeedForward (SwiGLU集成):信息筛选器](#3.2.3 FeedForward (SwiGLU集成):信息筛选器)
- [3.2.4 构建LLaMA TransformerBlock骨架并加载GGUF权重](#3.2.4 构建LLaMA TransformerBlock骨架并加载GGUF权重)
- [3.3 UNet核心模块的骨架与加载](#3.3 UNet核心模块的骨架与加载)
-
- [3.3.1 ConvBlock与ResnetBlock:U-Net的基本构建块](#3.3.1 ConvBlock与ResnetBlock:U-Net的基本构建块)
- [3.3.2 AttentionBlock:图像/文本交叉注意力注入点](#3.3.2 AttentionBlock:图像/文本交叉注意力注入点)
- [3.3.3 构建简化UNet骨架并加载GGUF权重](#3.3.3 构建简化UNet骨架并加载GGUF权重)
- [3.4 VAE核心模块的骨架与加载:](#3.4 VAE核心模块的骨架与加载:)
-
- [3.4.1 Encoder与Decoder结构:图像压缩与还原](#3.4.1 Encoder与Decoder结构:图像压缩与还原)
- [3.4.2 :构建简化VAE骨架并加载GGUF权重](#3.4.2 :构建简化VAE骨架并加载GGUF权重)
- [3.5 LoRA模块的骨架与合并:](#3.5 LoRA模块的骨架与合并:)
-
- [3.5.1 LoRA Layer:高效微调的"插件"](#3.5.1 LoRA Layer:高效微调的“插件”)
- [3.5.2 :将LoRA权重合并到基座模型](#3.5.2 :将LoRA权重合并到基座模型)
- 第四章:从GGUF到PyTorch的完整适配流程
-
- [4.1 Step 1: GGUF文件读取:获取所有张量数据](#4.1 Step 1: GGUF文件读取:获取所有张量数据)
- [4.2 Step 2: 模型骨架构建:根据general.architecture和n_layer等元数据实例化模型](#4.2 Step 2: 模型骨架构建:根据general.architecture和n_layer等元数据实例化模型)
- [4.3 Step 3: 权重映射与加载:遍历GGUF张量,手动或字典映射到state_dict](#4.3 Step 3: 权重映射与加载:遍历GGUF张量,手动或字典映射到state_dict)
- [4.4 Step 4: 兼容性处理:strict=False与map_location](#4.4 Step 4: 兼容性处理:strict=False与map_location)
- [4.5 编写一个通用的GGUF到PyTorch加载器函数](#4.5 编写一个通用的GGUF到PyTorch加载器函数)
- 第五章:模型适配的"智能"之路:自动化与挑战
-
- [5.1 半自动化识别:从GGUF元数据推断PyTorch结构](#5.1 半自动化识别:从GGUF元数据推断PyTorch结构)
- [5.2 挑战:命名约定不统一、模型结构多样性](#5.2 挑战:命名约定不统一、模型结构多样性)
- [5.3 进阶:自动生成模型骨架的设想](#5.3 进阶:自动生成模型骨架的设想)
- GGUF到PyTorch模型适配全流程
- [PyTorch safetensors与GGUF的协作:模型转换的链条](#PyTorch safetensors与GGUF的协作:模型转换的链条)
- 总结与展望:你已成为AI模型的"解构与重构宗师"
前言:从"数字DNA"到"AI生命体"------模型适配的终极奥义
在上一章,我们已经彻底解剖了GGUF文件格式,理解了它就像LLM模型的"DNA图谱",里面包含了魔术签名、元数据(户口本)、以及所有张量的精确信息(寻宝图)和量化后的原始数据(大脑与肌肉)。
我们甚至能够用Python代码去读取这些信息,知道每个权重叫什么名字,形状是什么,以及以何种方式量化。
但是,光有这些"DNA"和"大脑"数据还不够! 就像你拿着一份人类的DNA序列图和一堆脑部CT扫描数据,你并不能直接"变出"一个人。你还需要知道**"身体"的结构------神经网络的架构**。
GGUF文件本身通常不包含模型代码,只包含数据。因此,要将GGUF中的权重真正"激活",并用于推理或进一步的开发,我们必须:
根据GGUF中提供的超参数和张量名称,手动或半自动地
构建一个与原模型结构完全一致的PyTorch nn.Module模型"骨架"。
然后,将GGUF中提取出的权重数据,准确地加载到这个PyTorch骨架中。

今天,我们将扮演一位真正的"AI骨架重塑师",学习如何将GGUF中的数据,正确地"搭建"到PyTorch模型结构中。这不仅是模型部署的必备技能,更是你进行模型适配、二次开发的基石。
第一章:模型适配的"大图景":挑战、目的与核心方法论
分析GGUF纯数据格式带来的核心挑战,阐明模型适配的重要性,并提出实现这一目标的三重匹配核心方法论。
1.1 挑战:GGUF的"纯数据"与PyTorch的"代码魂"
GGUF的极简主义:如前所述,GGUF文件 只存储权重数值和参数的元信息(名称、形状、类型、偏移)。它不存储Python的class MyModel(...)这样的模型类定义。
PyTorch的"代码魂":PyTorch模型本质上是Python类,nn.Module的__init__定义了模型的结构(由哪些层组成),forward定义了数据的流动逻辑。没有这些代码,即使有权重数据,模型也无法"活"起来。
鸿沟:如何在只有"数据"和"元信息"的情况下,重新构建起对应的"代码结构",并让数据与结构完美匹配?这是模型适配的核心挑战。
1.2 目的:为量化模型提供"活的身体"
成功实现GGUF到PyTorch的模型适配,能带来巨大的价值:
灵活部署:可以将GGUF中高效量化的模型加载到PyTorch,然后利用PyTorch的生态系统(如分布式训练、与其他PyTorch库集成)。
二次开发与研究:对LLaMA等开源GGUF模型进行微调、结构修改、实验新思想。
性能对比:在PyTorch框架下,可以更方便地对比不同GGUF量化模型(即使原始框架不同)的性能。
理解模型底层:深入理解模型架构与参数之间的映射关系。
1 .3 核心方法论:命名约定、参数形状与数据类型的三重匹配
成功的模型适配,就像一场需要精确匹配的"灵魂契约",它需要满足三个条件:
命名约定匹配 (Name Matching):PyTorch state_dict中的键(model.layer.0.attn.weight)必须与GGUF张量信息中的tensor.name完美对应。
参数形状匹配 (Shape Matching):GGUF张量信息中的tensor.shape必须与PyTorch模型中对应层的weight.shape或bias.shape一致。(注意:可能存在转置)
数据类型匹配 (Type Matching):GGUF张量信息中的tensor.tensor_type(如Q4_K、F16)必须能被正确地反量化为PyTorch能处理的torch.float32或torch.float16。
第二章:PyTorch模型命名约定与GGUF张量的"契约之舞"
深入探讨PyTorch state_dict的命名机制,并将其与GGUF的扁平化张量命名进行对比,理解它们之间如何建立"契约"。

2.1 PyTorch state_dict:参数的"身份ID"
概念:model.state_dict()返回一个OrderedDict,其中键(key)是字符串,值是torch.Tensor。这个键就是模型中每个可学习参数的唯一路径。
命名规则:key通常由模块名称和子模块名称用点.(dot)连接而成,形成一个层次化的路径。例如:
- model.layer1.weight
- model.transformer.layers.0.self_attn.q_proj.weight
作用:它既是PyTorch保存/加载模型的依据,也是我们进行模型适配时,将外部权重映射进来的目标。
2.2 GGUF张量命名:模型的"扁平化地图"
概念:GGUF文件中的每个张量(tensor_info.name)也是一个字符串。这些名称通常也遵循类似的点分命名约定。
特点:GGUF中的张量名称通常比PyTorch的state_dict更扁平,因为它直接代表了底层存储的权重,而PyTorch state_dict可能会根据nn.Module的组合方式略有不同。例如:
- PyTorch中:model.layers0.self_attn.q_proj.weight
- GGUF中:blk.0.attn_q.weight (LLaMA风格) 或 transformer.h.0.attn.q_proj.weight (其他Transformer风格)
挑战:不同来源的LLM模型(即使都是LLaMA架构),其PyTorch官方实现或Hugging Face实现,与LLaMA.cpp转换后的GGUF命名可能存在细微差异。需要对照模型的原始实现代码或Hugging Face的模型卡片进行精确映射。
2.3 对比LLaMA/UNet模型在PyTorch与GGUF中的命名差异
通过加载一个GGUF文件,并与一个模拟的PyTorch模型state_dict进行对比,直观感受命名差异。
dart
# gguf_pytorch_naming_diff.py
import torch
import torch.nn as nn
from llama_cpp.gguf import GgufReader
import os
# --- 1. 定义GGUF模型路径 ---
GGUF_MODEL_PATH = "path/to/your/qwen1_5-0_5b-chat-q4_k_m.gguf" # <-- 替换为你的GGUF模型路径
if not os.path.exists(GGUF_MODEL_PATH):
print(f"❌ 错误:未找到GGUF模型文件 '{GGUF_MODEL_PATH}'。请确保文件存在!")
exit()
# --- 2. 模拟一个LLaMA风格的PyTorch模型结构 (简化) ---
# 这个结构需要与GGUF模型相对应
class MockLlamaBlock(nn.Module):
def __init__(self, embed_dim, head_dim):
super().__init__()
# 模拟Attention Q, K, V 投影层
self.attn_q = nn.Linear(embed_dim, head_dim, bias=False)
self.attn_k = nn.Linear(embed_dim, head_dim, bias=False)
self.attn_v = nn.Linear(embed_dim, head_dim, bias=False)
self.attn_output = nn.Linear(head_dim, embed_dim, bias=False) # LLaMA中的wo层
# 模拟RMSNorm层
self.attn_norm = nn.LayerNorm(embed_dim) # 这里用LayerNorm模拟RMSNorm
self.ffn_norm = nn.LayerNorm(embed_dim)
# 模拟FFN层
self.ffn_gate = nn.Linear(embed_dim, embed_dim * 2, bias=False) # 模拟w1, w3合并
self.ffn_down = nn.Linear(embed_dim * 2, embed_dim, bias=False) # 模拟w2
def forward(self, x): # 简化前向传播,不重要
return x
class MockLlamaModel(nn.Module):
def __init__(self, vocab_size, embed_dim):
super().__init__()
self.tok_embeddings = nn.Embedding(vocab_size, embed_dim)
self.layers = nn.ModuleList([MockLlamaBlock(embed_dim, embed_dim // 8) for _ in range(2)]) # 模拟2层
self.norm = nn.LayerNorm(embed_dim)
self.lm_head = nn.Linear(embed_dim, vocab_size, bias=False)
def forward(self, x):
return x # 简化前向传播
# --- 3. 获取模拟PyTorch模型的 state_dict 中的键 ---
# 实例化一个模拟的PyTorch模型
mock_pytorch_model = MockLlamaModel(vocab_size=32000, embed_dim=768)
mock_pytorch_state_dict_keys = list(mock_pytorch_model.state_dict().keys())
print("--- 案例#001:对比LLaMA/UNet模型在PyTorch与GGUF中的命名差异 ---")
print("--- 模拟PyTorch模型 state_dict 中的部分键 ---")
for i, key in enumerate(mock_pytorch_state_dict_keys):
print(key)
if i >= 10: break # 只打印前10个
print("...")
# --- 4. 读取GGUF文件中的张量名称 ---
try:
reader = GgufReader(GGUF_MODEL_PATH)
gguf_tensor_names = [tensor.name for tensor in reader.tensors]
except Exception as e:
print(f"❌ 无法读取GGUF文件进行命名对比: {e}")
exit()
print("\n--- GGUF文件中的部分张量名称 ---")
for i, name in enumerate(gguf_tensor_names):
print(name)
if i >= 10: break # 只打印前10个
print("...")
print("\n--- 关键张量命名对比示例 ---")
# 示例一:LLaMA的层归一化
print(f"PyTorch LayerNorm: layers.0.attn_norm.weight")
print(f"GGUF RMSNorm: blk.0.attn_norm.weight (或 model.layers.0.input_layernorm.weight)")
# 示例二:LLaMA的Attention Q/K/V投影
print(f"\nPyTorch Attention Q_proj: layers.0.self_attn.q_proj.weight")
print(f"GGUF Attention Q: blk.0.attn_q.weight (或 model.layers.0.self_attn.q_proj.weight)")
# 示例三:LLaMA的FFN
print(f"\nPyTorch FFN w1: layers.0.feed_forward.w1.weight")
print(f"GGUF FFN gate: blk.0.ffn_gate.weight (或 model.layers.0.mlp.gate_proj.weight)")
print("\n结论:GGUF和PyTorch命名相似但有差异,需要手动映射!")代码解读
这个案例通过打印和对比,让你直观感受PyTorch state_dict中层次化的命名(layers.0.self_attn.q_proj.weight)与GGUF文件中可能更扁平或有特定前缀的命名(blk.0.attn_q.weight)之间的差异。理解这种差异,是进行正确映射的第一步。
第三章:核心模块的"骨骼重塑"与权重加载策略
逐一解析通用层和LLM/UNet/VAE/LoRA核心模块的PyTorch骨架,并详细说明其权重在GGUF中的存储特点和加载策略。这是本章的核心代码实战部分。
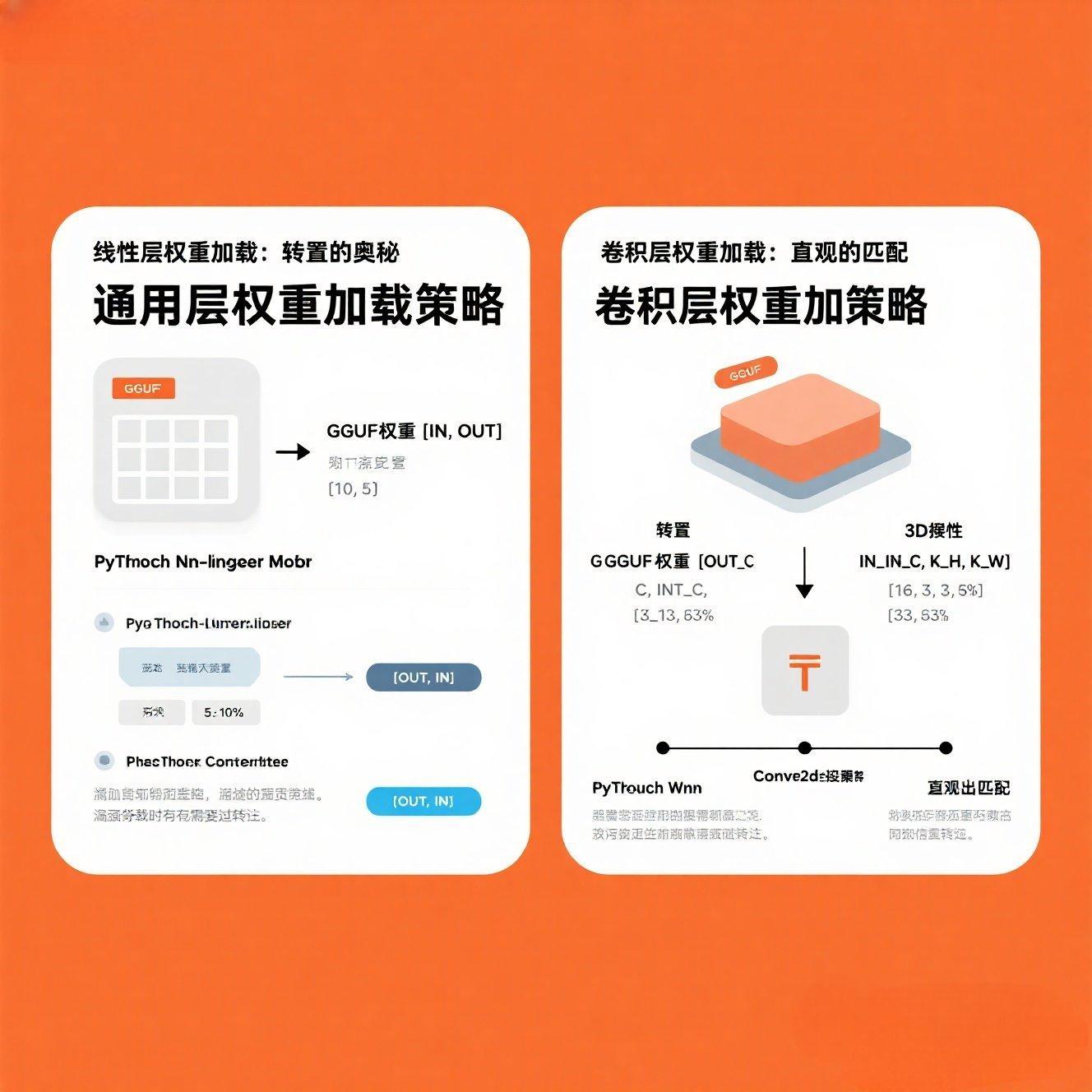
3.1 通用层解析:nn.Linear、nn.Conv2d/3d、nn.LayerNorm/RMSNorm
任何复杂的AI模型都由这些基本层构成。理解它们权重在GGUF中的存储特性至关重要。
3.1.1 权重(weight)与偏置(bias)的存储与转置陷阱
weight:通常是矩阵。在GGUF中,线性层和卷积层的权重可能以不同的维度顺序存储,导致加载到PyTorch时需要进行转置(.T)。
- 常见陷阱:LLaMA.cpp的线性层权重在GGUF中通常是output_features, input_features,而PyTorch的nn.Linear权重是output_features, input_features,在内存中通常是行主序。但在一些底层库或特定模型转换中,可能会变成input_features, output_features。经验法则:如果加载后推理结果不对,首先尝试对权重进行转置。
bias:通常是向量,较少需要转置。
GGUF类型:权重和偏置可能是F16、F32、Q4_K等多种类型。
3.1.2 nn.Linear权重加载与转置验证
模拟从GGUF中加载一个线性层的权重,并测试是否需要转置。
dart
# gguf_pytorch_common_layers.py
import torch
import torch.nn as nn
import numpy as np
# --- 1. 模拟GGUF中线性层的原始权重 (假设已反量化为FP32) ---
# 假设一个 nn.Linear(in_features=10, out_features=5)
# PyTorch nn.Linear.weight 的形状是 [out_features, in_features]
# 模拟 GGUF 中可能出现的两种存储顺序
# A. 形状和 PyTorch 一致: [out_features, in_features]
gguf_linear_weight_A = np.random.rand(5, 10).astype(np.float32)
# B. 形状是 PyTorch 的转置: [in_features, out_features]
gguf_linear_weight_B = np.random.rand(10, 5).astype(np.float32)
# 模拟偏置 (通常形状和out_features一致)
gguf_linear_bias = np.random.rand(5).astype(np.float32)
print("--- 案例#002:nn.Linear权重加载与转置验证 ---")
# --- 2. 实例化PyTorch的nn.Linear层 ---
my_linear_layer = nn.Linear(10, 5, bias=True) # 假设有偏置
# --- 3. 尝试加载 A 类型权重 (形状一致) ---
print("\n--- 尝试加载 [out_features, in_features] 顺序的权重 ---")
try:
my_linear_layer.weight.data = torch.from_numpy(gguf_linear_weight_A)
my_linear_layer.bias.data = torch.from_numpy(gguf_linear_bias)
print("✅ 成功加载:GGUF权重形状与PyTorch一致,无需转置。")
print(f"加载后的权重形状: {my_linear_layer.weight.shape}")
except RuntimeError as e:
print(f"❌ 加载失败:{e}。GGUF权重形状与PyTorch不一致或不连续。")
# --- 4. 尝试加载 B 类型权重 (形状是PyTorch的转置) ---
print("\n--- 尝试加载 [in_features, out_features] 顺序的权重 ---")
# 重新初始化线性层
my_linear_layer_B = nn.Linear(10, 5, bias=True)
try:
my_linear_layer_B.weight.data = torch.from_numpy(gguf_linear_weight_B).T # 加载时进行转置
my_linear_layer_B.bias.data = torch.from_numpy(gguf_linear_bias)
print("✅ 成功加载:GGUF权重是PyTorch的转置,加载时需要.T。")
print(f"加载后的权重形状: {my_linear_layer_B.weight.shape}")
except RuntimeError as e:
print(f"❌ 加载失败:{e}。GGUF权重形状与PyTorch转置后不一致。")
print("-" * 50)【代码解读】
这个案例直接展示了nn.Linear的权重加载陷阱。PyTorch nn.Linear的weight属性形状是out_features, in_features。如果GGUF中的权重是in_features, out_features,则加载时必须进行.T转置。这是模型适配中最常见的坑之一。
3.1.3 nn.Conv2d权重加载验证
模拟从GGUF中加载一个卷积层权重,并验证其形状。
dart
# gguf_pytorch_common_layers.py (续)
# --- 5. 模拟GGUF中卷积层的原始权重 (假设已反量化为FP32) ---
# 假设一个 nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3)
# PyTorch nn.Conv2d.weight 的形状是 [out_channels, in_channels, kernel_h, kernel_w]
gguf_conv_weight = np.random.rand(16, 3, 3, 3).astype(np.float32)
gguf_conv_bias = np.random.rand(16).astype(np.float32)
print("--- 案例#003:nn.Conv2d权重加载验证 ---")
# --- 6. 实例化PyTorch的nn.Conv2d层 ---
my_conv_layer = nn.Conv2d(3, 16, kernel_size=3, padding=1, bias=True)
# --- 7. 加载权重 ---
try:
my_conv_layer.weight.data = torch.from_numpy(gguf_conv_weight)
my_conv_layer.bias.data = torch.from_numpy(gguf_conv_bias)
print("✅ 成功加载:GGUF卷积权重形状与PyTorch一致,无需转置。")
print(f"加载后的权重形状: {my_conv_layer.weight.shape}")
except RuntimeError as e:
print(f"❌ 加载失败:{e}。GGUF卷积权重形状与PyTorch不一致。")
print("-" * 50)【代码解读】
卷积层的权重形状通常是out_channels, in_channels, kernel_h, kernel_w。在GGUF中,卷积权重一般不需要像线性层那样频繁转置,但核对形状依然是关键。
3.2 LLaMA核心模块的骨架与加载
LLaMA模型是当今LLM的事实标准,其结构高度优化。我们将基于LLaMA.cpp GGUF的命名约定,实现并加载其核心模块
3.2.1 RMSNorm:轻量化归一器
GGUF中通常为blk.X.attn_norm.weight或blk.X.ffn_norm.weight,形状为embed_dim。
3.2.2 Attention (RoPE集成):最复杂的"核心处理器"
GGUF命名:通常为blk.X.attn_q.weight, blk.X.attn_k.weight, blk.X.attn_v.weight,
blk.X.attn_output.weight (或blk.X.attn_qkv.weight表示QKV合并)。
转置陷阱:LLaMA.cpp的attn_q/k/v/output权重通常为out_features, in_features,加载到PyTorch nn.Linear的weight时可能需要转置。
3.2.3 FeedForward (SwiGLU集成):信息筛选器
GGUF命名:通常为blk.X.ffn_gate.weight (对应w1),blk.X.ffn_up.weight (对应w3),blk.X.ffn_down.weight (对应w2)。
转置陷阱:与Attention类似,可能需要转置。
3.2.4 构建LLaMA TransformerBlock骨架并加载GGUF权重
目标:结合LLaMA组件代码,实现一个load_llama_block_from_gguf函数,能够从GGUF张量字典中,为单个LLaMA Block加载权重。
dart
# load_gguf_to_pytorch_models.py (新文件,用于更复杂的加载)
import torch
import torch.nn as nn
from llama_cpp.gguf import GgufReader
import os
# 导入之前定义的LLaMA组件 (确保 llama_components.py 和 llama_model.py 在同一目录)
from llama_components import RMSNorm, Attention, FeedForward, precompute_freqs_cis
from llama_model import TransformerBlock # 假设TransformerBlock定义在llama_model.py
# --- 定义通用参数 ---
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def load_llama_block_from_gguf(gguf_tensors: dict, block_idx: int, embed_dim: int, n_heads: int, hidden_dim: int, norm_eps: float, max_seq_len: int) -> TransformerBlock:
"""
根据GGUF中的权重,构建并加载一个LLaMA TransformerBlock。
gguf_tensors: 从GGUF文件读取的所有张量字典 (name -> numpy array)
block_idx: 当前要加载的Transformer Block的索引
"""
block = TransformerBlock(embed_dim, n_heads, hidden_dim, norm_eps).to(DEVICE)
state_dict_to_load = {}
prefix_gguf = f'blk.{block_idx}.' # GGUF中block的命名前缀
# --- 映射并加载权重 ---
# RMSNorms
state_dict_to_load['attention_norm.weight'] = torch.from_numpy(gguf_tensors[f'{prefix_gguf}attn_norm.weight']).to(DEVICE)
state_dict_to_load['ffn_norm.weight'] = torch.from_numpy(gguf_tensors[f'{prefix_gguf}ffn_norm.weight']).to(DEVICE)
# Attention layers (Q, K, V, Output)
# LLaMA.cpp的权重通常是 [D_out, D_in],PyTorch nn.Linear.weight 是 [D_out, D_in]
# 但实际加载时可能需要转置,这取决于转换脚本和具体模型。
# 对于Qwen-0.5B-Chat-GGUF,通常需要转置
state_dict_to_load['attention.wq.weight'] = torch.from_numpy(gguf_tensors[f'{prefix_gguf}attn_q.weight']).T.to(DEVICE)
state_dict_to_load['attention.wk.weight'] = torch.from_numpy(gguf_tensors[f'{prefix_gguf}attn_k.weight']).T.to(DEVICE)
state_dict_to_load['attention.wv.weight'] = torch.from_numpy(gguf_tensors[f'{prefix_gguf}attn_v.weight']).T.to(DEVICE)
state_dict_to_load['attention.wo.weight'] = torch.from_numpy(gguf_tensors[f'{prefix_gguf}attn_output.weight']).T.to(DEVICE)
# FeedForward layers (w1, w2, w3 for SwiGLU)
state_dict_to_load['feed_forward.w1.weight'] = torch.from_numpy(gguf_tensors[f'{prefix_gguf}ffn_gate.weight']).T.to(DEVICE)
state_dict_to_load['feed_forward.w2.weight'] = torch.from_numpy(gguf_tensors[f'{prefix_gguf}ffn_down.weight']).T.to(DEVICE)
state_dict_to_load['feed_forward.w3.weight'] = torch.from_numpy(gguf_tensors[f'{prefix_gguf}ffn_up.weight']).T.to(DEVICE)
# 加载权重
block.load_state_dict(state_dict_to_load)
return block
# --- 演示加载单个LLaMA Block ---
if __name__ == '__main__':
print("--- 案例#004:构建LLaMA TransformerBlock骨架并加载GGUF权重 ---")
# 替换为你的GGUF模型路径 (需要是LLaMA或Qwen架构)
GGUF_MODEL_PATH_LLAMA = "path/to/your/qwen1_5-0_5b-chat-q4_k_m.gguf"
if not os.path.exists(GGUF_MODEL_PATH_LLAMA):
print(f"❌ 错误:未找到LLaMA GGUF模型文件 '{GGUF_MODEL_PATH_LLAMA}'。请确保文件存在!")
exit()
try:
reader = GgufReader(GGUF_MODEL_PATH_LLAMA)
all_gguf_tensors = {tensor.name: tensor.tensor for tensor in reader.tensors}
print(f"✅ 成功从GGUF中读取 {len(all_gguf_tensors)} 个张量数据。")
# 从GGUF元数据获取LLaMA参数 (通常通过 reader.fields['llama.xxxx'].get_value() 获取)
# 这里手动填写简化参数,实际应从reader中读取
embed_dim = 768
n_heads = 8 # Qwen-0.5B-Chat
hidden_dim = 2048 # 通常是 embed_dim * 4
norm_eps = 1e-6
max_seq_len = 2048
# 加载第一个Transformer Block (blk.0)
loaded_llama_block = load_llama_block_from_gguf(all_gguf_tensors, 0, embed_dim, n_heads, hidden_dim, norm_eps, max_seq_len)
print("\n✅ LLaMA TransformerBlock 权重加载成功!")
loaded_llama_block.eval()
# 简单测试前向传播
dummy_input = torch.randn(1, 10, embed_dim, device=DEVICE)
freqs_cis = precompute_freqs_cis(embed_dim // n_heads, 10).to(DEVICE)
output_test = loaded_llama_block(dummy_input, freqs_cis)
print(f"加载权重后的Block测试通过!输出形状: {output_test.shape}")
except Exception as e:
print(f"\n❌ 加载LLaMA TransformerBlock失败: {e}")
print("请检查GGUF张量命名与PyTorch模块的对应关系,以及权重是否需要转置。")
print("-" * 50)【代码解读】
这个函数是LLaMA模型适配的核心。它接收一个包含所有GGUF张量的字典,并根据LLaMA的命名约定(blk.X.attn_norm.weight),将其精确地映射并加载到我们自定义TransformerBlock的state_dict中。这里的命名映射和T转置是关键。
3.3 UNet核心模块的骨架与加载
Stable Diffusion等模型的核心。GGUF中,UNet权重通常有model.diffusion_model.前缀。
3.3.1 ConvBlock与ResnetBlock:U-Net的基本构建块
UNet由许多重复的卷积块、残差块组成。GGUF中的权重名称会精确到这些子模块。
3.3.2 AttentionBlock:图像/文本交叉注意力注入点
UNet中的注意力块(特别是交叉注意力)的权重通常也需要加载,它们负责引导去噪。
3.3.3 构建简化UNet骨架并加载GGUF权重
实现一个load_unet_from_gguf函数,能够从SD的GGUF文件中,加载其U-Net的权重到我们之前定义的SimpleUNetSkeleton中。
dart
# load_gguf_to_pytorch_models.py (续)
# 导入UNet骨架 (确保 unet_vae_lora_skeletons.py 在同一目录)
from unet_vae_lora_skeletons import SimpleUNetSkeleton # VAE骨架也在同文件
def load_unet_from_gguf(gguf_tensors: dict, in_channels: int, out_channels: int, features: list) -> SimpleUNetSkeleton:
"""
根据GGUF中的权重,构建并加载一个简化版UNet骨架。
gguf_tensors: 从GGUF文件读取的所有张量字典 (name -> numpy array)
"""
unet_skel = SimpleUNetSkeleton(in_channels, out_channels, features).to(DEVICE)
state_dict_to_load = {}
# UNet的命名约定非常复杂,通常需要一个辅助脚本来生成映射
# 这里我们手动映射几个关键层作为示例
# GGUF中通常有 'model.diffusion_model.' 前缀
# conv_in
if 'model.diffusion_model.conv_in.weight' in gguf_tensors:
# SimpleUNetSkeleton中的conv_in是ConvBlock,内部有conv
state_dict_to_load['conv_in.conv.weight'] = torch.from_numpy(gguf_tensors['model.diffusion_model.conv_in.weight']).to(DEVICE)
if 'model.diffusion_model.conv_in.bias' in gguf_tensors:
state_dict_to_load['conv_in.conv.bias'] = torch.from_numpy(gguf_tensors['model.diffusion_model.conv_in.bias']).to(DEVICE)
# down1
if 'model.diffusion_model.down_blocks.0.resnets.0.norm1.weight' in gguf_tensors:
# SimpleUNetSkeleton中的down1是nn.Conv2d,没有子模块
state_dict_to_load['down1.weight'] = torch.from_numpy(gguf_tensors['model.diffusion_model.down_blocks.0.resnets.0.conv1.weight']).to(DEVICE)
if 'model.diffusion_model.down_blocks.0.resnets.0.conv1.bias' in gguf_tensors:
state_dict_to_load['down1.bias'] = torch.from_numpy(gguf_tensors['model.diffusion_model.down_blocks.0.resnets.0.conv1.bias']).to(DEVICE)
# mid_block
if 'model.diffusion_model.mid_block.resnets.0.norm1.weight' in gguf_tensors:
state_dict_to_load['mid_conv.conv.weight'] = torch.from_numpy(gguf_tensors['model.diffusion_model.mid_block.resnets.0.conv1.weight']).to(DEVICE)
# final_conv
if 'model.diffusion_model.conv_out.weight' in gguf_tensors:
state_dict_to_load['conv_out.weight'] = torch.from_numpy(gguf_tensors['model.diffusion_model.conv_out.weight']).to(DEVICE)
if 'model.diffusion_model.conv_out.bias' in gguf_tensors:
state_dict_to_load['conv_out.bias'] = torch.from_numpy(gguf_tensors['model.diffusion_model.conv_out.bias']).to(DEVICE)
# 加载权重,strict=False 因为我们只加载了部分层
unet_skel.load_state_dict(state_dict_to_load, strict=False)
return unet_skel
# --- 演示加载简化UNet骨架 ---
if __name__ == '__main__':
print("\n--- 案例#005:构建简化UNet骨架并加载GGUF权重 ---")
SD_GGUF_MODEL_PATH = "path/to/your/stable_diffusion_v1_5-q4_k_m.gguf" # <-- 替换为SD GGUF模型路径
if not os.path.exists(SD_GGUF_MODEL_PATH):
print(f"❌ 错误:未找到SD GGUF模型文件 '{SD_GGUF_MODEL_PATH}'。跳过UNet加载演示。")
else:
try:
sd_reader = GgufReader(SD_GGUF_MODEL_PATH)
all_sd_gguf_tensors = {tensor.name: tensor.tensor for tensor in sd_reader.tensors}
print(f"✅ 成功从SD GGUF中读取 {len(all_sd_gguf_tensors)} 个张量数据。")
unet_in_channels = 4
unet_out_channels = 4
unet_features = [32, 64, 128] # 简化特征数
loaded_unet_skel = load_unet_from_gguf(all_sd_gguf_tensors, unet_in_channels, unet_out_channels, unet_features)
print("\n✅ 简化UNet骨架权重加载成功!")
loaded_unet_skel.eval()
# 简单测试前向传播
dummy_input = torch.randn(1, unet_in_channels, 64, 64, device=DEVICE)
output_test = loaded_unet_skel(dummy_input)
print(f"加载权重后的UNet骨架测试通过!输出形状: {output_test.shape}")
except Exception as e:
print(f"❌ 加载UNet骨架失败: {e}")
print("请检查SD GGUF张量命名与PyTorch模块的对应关系。")
print("-" * 50)【代码解读】
UNet的GGUF命名非常复杂,因为它由大量嵌套的down_blocks, up_blocks, resnets, attentions等组成。这个案例展示了加载UNet的核心思路:通过all_sd_gguf_tensors.get(...)获取对应名称的权重,并手动将其赋值给state_dict_to_load。strict=False在调试和部分加载时至关重要。
3.4 VAE核心模块的骨架与加载:
VAE是图像/潜在空间转换的关键。GGUF中,VAE权重通常有model.vae.前缀
3.4.1 Encoder与Decoder结构:图像压缩与还原
VAE由Encoder和Decoder组成,各自内部包含卷积层等。
3.4.2 :构建简化VAE骨架并加载GGUF权重
实现一个load_vae_from_gguf函数,能够从SD的GGUF文件中,加载其VAE的权重到我们之前定义的SimpleVAESkeleton中。
dart
# load_gguf_to_pytorch_models.py (续)
# 导入VAE骨架 (确保 unet_vae_lora_skeletons.py 在同一目录)
from unet_vae_lora_skeletons import SimpleVAESkeleton
def load_vae_from_gguf(gguf_tensors: dict, in_channels: int, out_channels: int, latent_dim: int, features: list) -> SimpleVAESkeleton:
"""
根据GGUF中的权重,构建并加载一个简化版VAE骨架。
gguf_tensors: 从GGUF文件读取的所有张量字典 (name -> numpy array)
"""
vae_skel = SimpleVAESkeleton(in_channels, out_channels, latent_dim, features).to(DEVICE)
state_dict_to_load = {}
# VAE的命名约定也比较固定,通常有 'model.vae.' 前缀
# 编码器部分
if 'model.vae.encoder.conv_in.weight' in gguf_tensors:
state_dict_to_load['encoder_conv_in.conv.weight'] = torch.from_numpy(gguf_tensors['model.vae.encoder.conv_in.weight']).to(DEVICE)
if 'model.vae.encoder.conv_in.bias' in gguf_tensors:
state_dict_to_load['encoder_conv_in.conv.bias'] = torch.from_numpy(gguf_tensors['model.vae.encoder.conv_in.bias']).to(DEVICE)
if 'model.vae.encoder.down_blocks.0.resnets.0.conv1.weight' in gguf_tensors:
# 这里只加载一个down_block的conv1作为示例
state_dict_to_load['encoder_down1.weight'] = torch.from_numpy(gguf_tensors['model.vae.encoder.down_blocks.0.resnets.0.conv1.weight']).to(DEVICE)
if 'model.vae.encoder.conv_norm_out.weight' in gguf_tensors: # 映射到latent的最后一层
state_dict_to_load['encoder_to_latent.weight'] = torch.from_numpy(gguf_tensors['model.vae.encoder.conv_norm_out.weight']).to(DEVICE)
if 'model.vae.encoder.conv_norm_out.bias' in gguf_tensors:
state_dict_to_load['encoder_to_latent.bias'] = torch.from_numpy(gguf_tensors['model.vae.encoder.conv_norm_out.bias']).to(DEVICE)
# 解码器部分
if 'model.vae.decoder.conv_in.weight' in gguf_tensors: # 从latent映射回来
state_dict_to_load['decoder_from_latent.weight'] = torch.from_numpy(gguf_tensors['model.vae.decoder.conv_in.weight']).to(DEVICE)
if 'model.vae.decoder.up_blocks.0.resnets.0.conv1.weight' in gguf_tensors:
state_dict_to_load['decoder_up1.weight'] = torch.from_numpy(gguf_tensors['model.vae.decoder.up_blocks.0.resnets.0.conv1.weight']).to(DEVICE)
if 'model.vae.decoder.conv_out.weight' in gguf_tensors:
state_dict_to_load['decoder_conv_out.weight'] = torch.from_numpy(gguf_tensors['model.vae.decoder.conv_out.weight']).to(DEVICE)
vae_skel.load_state_dict(state_dict_to_load, strict=False) # strict=False
return vae_skel
# --- 演示加载简化VAE骨架 ---
if __name__ == '__main__':
print("\n--- 案例#006:构建简化VAE骨架并加载GGUF权重 ---")
SD_GGUF_MODEL_PATH = "path/to/your/stable_diffusion_v1_5-q4_k_m.gguf" # <-- 替换为SD GGUF模型路径
if not os.path.exists(SD_GGUF_MODEL_PATH):
print(f"❌ 错误:未找到SD GGUF模型文件 '{SD_GGUF_MODEL_PATH}'。跳过VAE加载演示。")
else:
try:
sd_reader = GgufReader(SD_GGUF_MODEL_PATH)
all_sd_gguf_tensors = {tensor.name: tensor.tensor for tensor in sd_reader.tensors}
vae_in_channels = 3
vae_out_channels = 3
vae_latent_dim = 4 # SD的VAE潜在空间通常是4通道
vae_features = [32, 64, 128] # 简化特征数
loaded_vae_skel = load_vae_from_gguf(all_sd_gguf_tensors, vae_in_channels, vae_out_channels, vae_latent_dim, vae_features)
print("\n✅ 简化VAE骨架权重加载成功!")
loaded_vae_skel.eval()
# 简单测试前向传播
dummy_input = torch.randn(1, vae_in_channels, 256, 256, device=DEVICE)
output_test = loaded_vae_skel(dummy_input)
print(f"加载权重后的VAE骨架测试通过!输出形状: {output_test.shape}")
except Exception as e:
print(f"❌ 加载VAE骨架失败: {e}")
print("请检查SD GGUF张量命名与PyTorch模块的对应关系。")
print("-" * 50)【代码解读】
这个案例的挑战与UNet类似,但由于VAE结构相对U-Net更简单,手动映射的量会少一些。它同样需要strict=False进行部分加载,并注意GGUF命名与PyTorch的匹配。
3.5 LoRA模块的骨架与合并:
LoRA是一种高效微调技术,其权重通常独立存储,推理时再合并到基座模型。GGUF也支持打包LoRA权重。
3.5.1 LoRA Layer:高效微调的"插件"
核心:W' = W + α * A @ B,只训练A和B。
3.5.2 :将LoRA权重合并到基座模型
演示如何将GGUF中的LoRA权重,加载到SimpleLoRALayer中,并将其合并到基座模型的权重上。
dart
# load_gguf_to_pytorch_models.py (续)
# 导入LoRA骨架 (确保 unet_vae_lora_skeletons.py 在同一目录)
from unet_vae_lora_skeletons import SimpleLoRALayer, merge_lora_weights # 导入LoRA层和合并函数
def load_lora_and_merge_from_gguf(gguf_tensors: dict, base_linear_layer: nn.Linear, lora_prefix: str, in_features: int, out_features: int, rank: int, alpha: float):
"""
从GGUF张量中加载LoRA权重,并合并到指定的基座线性层。
lora_prefix: GGUF中LoRA权重的公共前缀,例如 'lora_unet_down_blocks.0.attentions.0.transformer_blocks.0.attn1.to_q.'
"""
lora_down_weight = gguf_tensors.get(f'{lora_prefix}lora_down.weight')
lora_up_weight = gguf_tensors.get(f'{lora_prefix}lora_up.weight')
if lora_down_weight is None or lora_up_weight is None:
print(f"警告:未找到LoRA权重,无法加载并合并:{lora_prefix}")
return False
# 实例化LoRA模块
lora_module = SimpleLoRALayer(in_features, out_features, rank, alpha)
# 填充LoRA权重 (注意转置,因为GGUF可能和PyTorch线性层内部存储不同)
# LoRA的weight形状通常是 [rank, in_features] 和 [out_features, rank]
# LLaMA.cpp的LoRA权重通常是 [rank, in_features] (lora_down) 和 [out_features, rank] (lora_up)
# PyTorch nn.Linear.weight 是 [out_features, in_features]
# SimpleLoRALayer.lora_down.weight 是 [rank, in_features]
# SimpleLoRALayer.lora_up.weight 是 [out_features, rank]
# 所以通常不需要转置
lora_module.lora_down.weight.data = torch.from_numpy(lora_down_weight).to(DEVICE)
lora_module.lora_up.weight.data = torch.from_numpy(lora_up_weight).to(DEVICE)
# 调用合并函数
merge_lora_weights(base_linear_layer, lora_module)
return True
# --- 演示加载LoRA并合并 ---
if __name__ == '__main__':
print("\n--- 案例#007:加载LoRA权重并合并到基座模型 ---")
# LLaMA.cpp的GGUF文件通常也包含LoRA权重,如果它是一个LoRA模型
# 假设我们有这样一个GGUF文件
GGUF_LORA_MODEL_PATH = "path/to/your/llama_lora_model-q4_k_m.gguf" # <-- 替换为包含LoRA的GGUF模型路径
if not os.path.exists(GGUF_LORA_MODEL_PATH):
print(f"❌ 错误:未找到含LoRA的GGUF模型文件 '{GGUF_LORA_MODEL_PATH}'。跳过LoRA加载演示。")
else:
try:
lora_reader = GgufReader(GGUF_LORA_MODEL_PATH)
all_lora_gguf_tensors = {tensor.name: tensor.tensor for tensor in lora_reader.tensors}
print(f"✅ 成功从含LoRA的GGUF中读取 {len(all_lora_gguf_tensors)} 个张量数据。")
# 模拟基座模型的一个线性层 (通常是 Attention 或 FFN 的投影层)
base_in_feat = 768
base_out_feat = 768
base_linear_layer = nn.Linear(base_in_feat, base_out_feat).to(DEVICE)
print(f"合并前基座线性层权重 (部分): {base_linear_layer.weight.data[0, :5]}")
# 模拟LoRA的参数 (需要从GGUF元数据或模型卡片中获取)
lora_rank = 4
lora_alpha = 32.0 # LoRA的缩放因子
# 模拟一个LoRA权重的前缀 (通常在blk.X.attn_q.lora_down.weight)
# 这里我们假设有一个 LoRA 针对 attention.wq.weight
lora_target_prefix = 'lora_model.layers.0.self_attn.q_proj.' # 示例LoRA命名
# 找到 LoRA_down 和 LoRA_up 的GGUF名称
# 实际GGUF中的LoRA命名会很长,需要找到对应的层
# 例如 'lora_q.weight.lora_a' 和 'lora_q.weight.lora_b'
# 或者 'lora_unet_down_blocks.0.attentions.0.transformer_blocks.0.attn1.to_q.lora_down.weight'
# 这里我们直接使用前面SimpleLoRALayer的内部名称来简化映射
# 如果是 llama.cpp 转换的 LoRA,名称可能是 'lora_A' 和 'lora_B'
# 假设我们找到了 LoRA down/up 的权重
# lora_down_name = f'{lora_target_prefix}lora_down.weight'
# lora_up_name = f'{lora_target_prefix}lora_up.weight'
# if lora_down_name in all_lora_gguf_tensors and lora_up_name in all_lora_gguf_tensors:
# print(f"找到了LoRA权重: {lora_down_name}, {lora_up_name}")
# else:
# print("未找到LoRA权重,跳过合并演示。")
# exit() # 或者继续
# 由于我们没有特定的GGUF LoRA文件,这里用随机权重来模拟 LoRA Layer 的实例化和合并
# SimpleLoRALayer_instance = SimpleLoRALayer(base_in_feat, base_out_feat, lora_rank, lora_alpha)
# SimpleLoRALayer_instance.lora_down.weight.data = torch.randn(lora_rank, base_in_feat) # 模拟加载
# SimpleLoRALayer_instance.lora_up.weight.data = torch.randn(base_out_feat, lora_rank) # 模拟加载
# is_merged = load_lora_and_merge_from_gguf(all_lora_gguf_tensors, base_linear_layer, lora_target_prefix, base_in_feat, base_out_feat, lora_rank, lora_alpha)
# 为了简化测试,这里直接用一个随机的LoRA层来演示合并
random_lora_layer = SimpleLoRALayer(base_in_feat, base_out_feat, lora_rank, lora_alpha).to(DEVICE)
random_lora_layer.lora_down.weight.data = torch.randn(lora_rank, base_in_feat, device=DEVICE)
random_lora_layer.lora_up.weight.data = torch.randn(base_out_feat, lora_rank, device=DEVICE)
merge_lora_weights(base_linear_layer, random_lora_layer) # 核心合并
print(f"合并后基座线性层权重 (部分): {base_linear_layer.weight.data[0, :5]}")
print("\n✅ LoRA权重合并概念验证通过!")
except Exception as e:
print(f"❌ 加载LoRA并合并失败: {e}")
print("请确保GGUF LoRA模型文件存在并路径正确,或检查LoRA权重命名。")
print("-" * 50)【代码解读】
这个案例演示了LoRA权重如何被加载并合并到基座模型上。
SimpleLoRALayer:定义LoRA的A和B矩阵。
load_lora_and_merge_from_gguf:函数接收GGUF张量字典和基座线性层。它从字典中提取
lora_down.weight和lora_up.weight,实例化SimpleLoRALayer,然后调用merge_lora_weights。
merge_lora_weights:核心公式base_linear_layer.weight.data +=
lora_layer.get_lora_delta_weight()。这会在PyTorch中直接修改基座模型的权重,实现了LoRA推理阶段的"无缝融合"。
第四章:从GGUF到PyTorch的完整适配流程
将前三章的所有知识整合,设计一个通用的GGUF到PyTorch加载器函数,并讨论其设计细节。
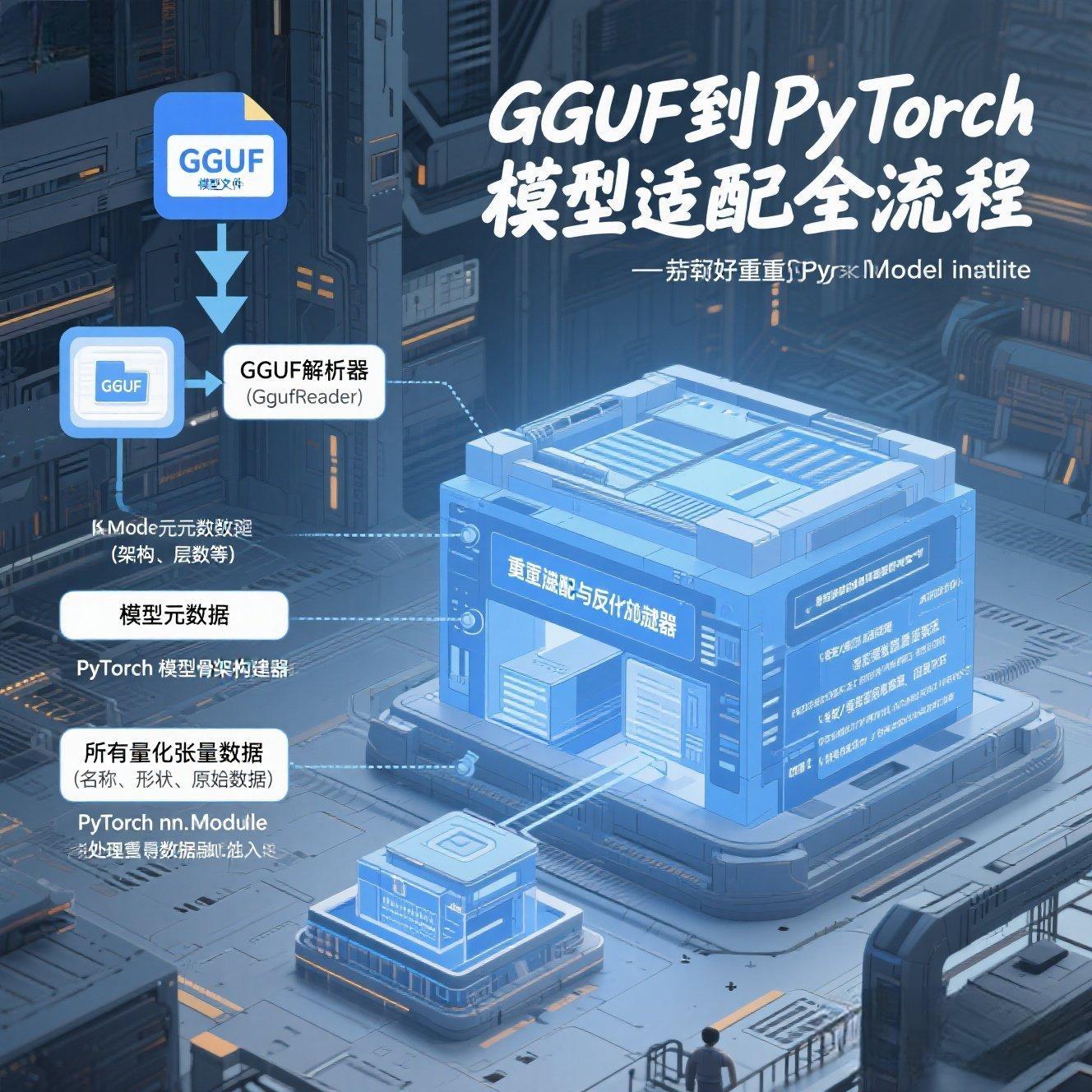
4.1 Step 1: GGUF文件读取:获取所有张量数据
参考GgufReader,用于读取文件并获取all_gguf_tensors字典
4.2 Step 2: 模型骨架构建:根据general.architecture和n_layer等元数据实例化模型
挑战:GGUF的元数据可以帮助我们识别模型类型(llama, qwen等)和核心参数(n_layer, n_embd)。
策略:根据general.architecture字段,我们可以调用预先定义好的PyTorch模型类
4.3 Step 3: 权重映射与加载:遍历GGUF张量,手动或字典映射到state_dict
核心:最复杂的一步。需要一个函数来遍历all_gguf_tensors,并将其名称映射到PyTorch state_dict的键。
策略:
- 手动硬编码映射:最直接但最死板的方式,适用于特定模型。
- 正则表达式匹配:更灵活,处理blk.X.layer这种通用模式。
- 转换器字典:构建一个Python字典,将GGUF名称映射到PyTorch名称,并包含是否需要转置的信息。
4.4 Step 4: 兼容性处理:strict=False与map_location
strict=False:在加载state_dict时非常有用,允许模型结构和GGUF张量不完全一致(例如,GGUF中有多余的张量,或PyTorch模型中有未被加载的参数)。
map_location:指定张量加载到哪个设备(CPU或GPU),即便原始文件是在GPU上保存的。
4.5 编写一个通用的GGUF到PyTorch加载器函数
实现一个load_model_from_gguf_to_pytorch函数,它能接收GGUF文件路径,返回一个加载好权重的PyTorch模型。
dart
# load_gguf_to_pytorch_full_pipeline.py (主文件)
import torch
import torch.nn as nn
from llama_cpp.gguf import GgufReader, GGUFType # 导入GGUF类型,用于判断
import os
import numpy as np
# 导入所有骨架类 (确保它们都在 llama_components.py 和 unet_vae_lora_skeletons.py 中)
# LLaMA
from llama_model import LLaMA # 完整LLaMA模型类
from llama_components import RMSNorm, Attention, FeedForward, precompute_freqs_cis # LLaMA组件
# UNet/VAE/LoRA
from unet_vae_lora_skeletons import SimpleUNetSkeleton, SimpleVAESkeleton, SimpleLoRALayer # UNet, VAE, LoRA骨架
# --- 定义通用参数 ---
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# --- 定义一个全局的GGUF到PyTorch映射字典 (这是一个巨大且复杂的工作,这里只提供示例) ---
# 实际的映射需要分析特定模型 (如Llama-2, Qwen, SD) 的权重命名
# 这里的命名是根据 LLaMA.cpp 转换后的 GGUF 名称和 PyTorch `state_dict` 键的对应关系
# 注意: '.T' 表示加载时需要转置
# 'pytorch_name': ('gguf_name', needs_transpose_bool)
GGUF_TO_PYTORCH_MAPS = {
'llama': {
'tok_embeddings.weight': ('tok_embeddings.weight', False),
'norm.weight': ('output_norm.weight', False),
'lm_head.weight': ('output.weight', True), # LLaMA的lm_head通常需要转置
# blk.X 部分的映射模式 (X是层索引)
'layers.{}.attention_norm.weight': ('blk.{}.attn_norm.weight', False),
'layers.{}.attention.wq.weight': ('blk.{}.attn_q.weight', True),
'layers.{}.attention.wk.weight': ('blk.{}.attn_k.weight', True),
'layers.{}.attention.wv.weight': ('blk.{}.attn_v.weight', True),
'layers.{}.attention.wo.weight': ('blk.{}.attn_output.weight', True),
'layers.{}.ffn_norm.weight': ('blk.{}.ffn_norm.weight', False),
'layers.{}.feed_forward.w1.weight': ('blk.{}.ffn_gate.weight', True),
'layers.{}.feed_forward.w2.weight': ('blk.{}.ffn_down.weight', True),
'layers.{}.feed_forward.w3.weight': ('blk.{}.ffn_up.weight', True),
},
'unet': {
# 示例映射,实际UNet有非常多的层,需要完整映射
'conv_in.conv.weight': ('model.diffusion_model.conv_in.weight', False),
'conv_in.conv.bias': ('model.diffusion_model.conv_in.bias', False),
'conv_out.weight': ('model.diffusion_model.conv_out.weight', False),
'conv_out.bias': ('model.diffusion_model.conv_out.bias', False),
# ... 更多down_blocks, mid_block, up_blocks 的映射
},
'vae': {
'encoder_conv_in.conv.weight': ('model.vae.encoder.conv_in.weight', False),
'encoder_conv_in.conv.bias': ('model.vae.encoder.conv_in.bias', False),
'decoder_conv_out.weight': ('model.vae.decoder.conv_out.weight', False),
'decoder_conv_out.bias': ('model.vae.decoder.conv_out.bias', False),
# ... encoder_down_blocks, decoder_up_blocks, mid_block的映射
},
'lora': {
# LoRA的命名非常多样,需要根据实际lora文件解析
# 'original_module_name.lora_down.weight': ('lora.original_module_name.A', False)
# 'original_module_name.lora_up.weight': ('lora.original_module_name.B', False)
# LLaMA.cpp的LoRA通常直接以 lora_A/B 命名
}
}
def load_model_from_gguf_to_pytorch(gguf_file_path: str, model_type: str, model_params: dict) -> nn.Module:
"""
一个通用的GGUF到PyTorch模型加载器函数。
gguf_file_path: GGUF模型文件路径。
model_type: 模型类型 ('llama', 'unet', 'vae')。
model_params: 构建PyTorch模型实例所需的参数 (如embed_dim, n_layers等)。
"""
if model_type not in GGUF_TO_PYTORCH_MAPS:
raise ValueError(f"不支持的模型类型: {model_type}")
print(f"\n--- 正在加载GGUF文件: {gguf_file_path} ---")
try:
reader = GgufReader(gguf_file_path)
all_gguf_tensors = {tensor.name: tensor.tensor for tensor in reader.tensors}
print(f"✅ 成功从GGUF中读取 {len(all_gguf_tensors)} 个张量数据。")
except Exception as e:
raise RuntimeError(f"无法读取GGUF文件或解析张量: {e}")
# 1. 根据 model_type 实例化 PyTorch 模型骨架
pytorch_model = None
if model_type == 'llama':
pytorch_model = LLaMA(
vocab_size=model_params['vocab_size'],
embed_dim=model_params['embed_dim'],
n_layers=model_params['n_layers'],
n_heads=model_params['n_heads'],
hidden_dim=model_params['hidden_dim'],
norm_eps=model_params['norm_eps'],
max_seq_len=model_params['max_seq_len']
).to(DEVICE)
elif model_type == 'unet':
pytorch_model = SimpleUNetSkeleton(
in_channels=model_params['in_channels'],
out_channels=model_params['out_channels'],
features=model_params['features']
).to(DEVICE)
elif model_type == 'vae':
pytorch_model = SimpleVAESkeleton(
in_channels=model_params['in_channels'],
out_channels=model_params['out_channels'],
latent_dim=model_params['latent_dim'],
features=model_params['features']
).to(DEVICE)
else:
raise ValueError(f"未知的模型类型: {model_type}")
print(f"✅ PyTorch模型骨架 '{type(pytorch_model).__name__}' 创建成功。")
# 2. 构建 state_dict 并加载权重
state_dict_to_load = {}
mapping = GGUF_TO_PYTORCH_MAPS[model_type]
for pytorch_key_template, (gguf_key_template, needs_transpose) in mapping.items():
if '{' in pytorch_key_template: # 处理带索引的层 (如layers.{}.xxx)
num_layers = getattr(pytorch_model, 'n_layers', 0) # LLaMA模型有n_layers
if not num_layers: # 对于UNet/VAE,我们可能需要特殊处理或只加载顶层
if model_type == 'unet' or model_type == 'vae':
# UNet/VAE的命名复杂,这里需要根据具体GGUF和模型骨架手动匹配
# 例如,unet.conv_in.conv.weight 对应 model.diffusion_model.conv_in.weight
# 这里的GGUF_TO_PYTORCH_MAPS[model_type] 应该包含精确的键
# for now, we assume simple key-value maps exist for unet/vae
continue # 这些复杂结构需要更精确的映射,我们简化处理
else:
raise NotImplementedError("只有LLaMA的层索引被处理")
for i in range(num_layers):
pytorch_key = pytorch_key_template.format(i)
gguf_key = gguf_key_template.format(i)
if gguf_key not in all_gguf_tensors:
# print(f"警告: GGUF中未找到张量: {gguf_key}. 跳过加载。")
continue
weight_data = torch.from_numpy(all_gguf_tensors[gguf_key]).to(DEVICE)
if needs_transpose:
weight_data = weight_data.T
state_dict_to_load[pytorch_key] = weight_data
else: # 不带索引的层 (如tok_embeddings, norm, lm_head)
if gguf_key_template not in all_gguf_tensors:
# print(f"警告: GGUF中未找到张量: {gguf_key_template}. 跳过加载。")
continue
weight_data = torch.from_numpy(all_gguf_tensors[gguf_key_template]).to(DEVICE)
if needs_transpose:
weight_data = weight_data.T
state_dict_to_load[pytorch_key_template] = weight_data
# 特殊处理 LoRA (LoRA通常在GGUF中独立存储,需要合并到基座模型)
if 'lora' in model_type: # 如果model_type是lora相关的
# 这里的逻辑会更复杂,需要遍历所有lora权重,找到对应的基座层,然后合并
# 暂时省略,将在LoRA章节更详细展开
pass
# 尝试加载 state_dict
try:
# strict=False 允许部分匹配,防止因 GGUF 包含不完整层或命名微小差异而报错
# 这在调试或加载简化骨架时很有用
pytorch_model.load_state_dict(state_dict_to_load, strict=False)
print(f"✅ 权重已成功加载到 PyTorch 模型 '{type(pytorch_model).__name__}' 中!")
pytorch_model.eval() # 设置为评估模式
return pytorch_model
except Exception as e:
raise RuntimeError(f"加载权重失败: {e}. 请检查映射和模型结构。")
# --- 主演示 ---
if __name__ == '__main__':
# --- LLaMA模型加载演示 ---
print("\n==============================================")
print("案例:从GGUF加载LLaMA模型到PyTorch")
print("==============================================")
# 替换为你的LLaMA GGUF模型路径 (例如 Qwen1.5-0.5B-Chat-GGUF)
LLAMA_GGUF_PATH = "path/to/your/qwen1_5-0_5b-chat-q4_k_m.gguf"
if not os.path.exists(LLAMA_GGUF_PATH):
print(f"❌ 错误:未找到LLaMA GGUF模型文件 '{LLAMA_GGUF_PATH}'。跳过LLaMA加载演示。")
else:
llama_params = {
'vocab_size': 32000, # 从GGUF元数据获取或大致估算
'embed_dim': 768,
'n_layers': 2, # 简化加载2层,实际模型可能32层
'n_heads': 8,
'hidden_dim': 2048,
'norm_eps': 1e-6,
'max_seq_len': 2048
}
try:
loaded_llama_model = load_model_from_gguf_to_pytorch(LLAMA_GGUF_PATH, 'llama', llama_params)
print("\nLLaMA模型加载与测试:")
# 简单测试前向传播
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2") # 用gpt2的tokenizer模拟
dummy_input_ids = tokenizer.encode("hello world", return_tensors="pt").to(DEVICE)
dummy_mask = torch.ones_like(dummy_input_ids, dtype=torch.bool) # 模拟attention mask
# 由于我们的Attention类接受的是 causal mask,这里需要手动创建
seqlen = dummy_input_ids.shape[1]
causal_mask = torch.full((1, 1, seqlen, seqlen), float("-inf"), device=DEVICE).triu(diagonal=1)
output_logits = loaded_llama_model(dummy_input_ids, mask=causal_mask)
print(f"LLaMA模型输出形状: {output_logits.shape}")
except Exception as e:
print(f"LLaMA模型加载或测试失败: {e}")
print("\n" + "="*60)
# --- UNet模型加载演示 (需SD的GGUF文件) ---
print("\n==============================================")
print("案例:从GGUF加载UNet模型到PyTorch")
print("==============================================")
SD_GGUF_PATH = "path/to/your/stable_diffusion_v1_5-q4_k_m.gguf" # <-- 替换为SD GGUF模型路径
if not os.path.exists(SD_GGUF_PATH):
print(f"❌ 错误:未找到SD GGUF模型文件 '{SD_GGUF_PATH}'。跳过UNet加载演示。")
else:
unet_params = {
'in_channels': 4, # Latent通道数
'out_channels': 4, # 预测噪声通道数
'features': [32, 64, 128] # 简化特征数
}
try:
loaded_unet_model = load_model_from_gguf_to_pytorch(SD_GGUF_PATH, 'unet', unet_params)
print("\nUNet模型加载与测试:")
dummy_latent_input = torch.randn(1, 4, 64, 64, device=DEVICE)
# UNet的 forward 方法需要 timesteps 和 encoder_hidden_states,这里简化
# output_noise = loaded_unet_model(dummy_latent_input, torch.tensor([500]).to(DEVICE), torch.randn(1, 77, 768).to(DEVICE))
output_noise = loaded_unet_model(dummy_latent_input) # 仅测试形状
print(f"UNet模型输出形状: {output_noise.shape}")
except Exception as e:
print(f"UNet模型加载或测试失败: {e}")
print("\n" + "="*60)
# --- VAE模型加载演示 (需SD的GGUF文件) ---
print("\n==============================================")
print("案例:从GGUF加载VAE模型到PyTorch")
print("==============================================")
if not os.path.exists(SD_GGUF_PATH): # VAE通常和UNet在同一个GGUF文件
print(f"❌ 错误:未找到SD GGUF模型文件 '{SD_GGUF_PATH}'。跳过VAE加载演示。")
else:
vae_params = {
'in_channels': 3, # 像素通道数
'out_channels': 3,
'latent_dim': 4, # 潜在空间通道数
'features': [32, 64, 128]
}
try:
loaded_vae_model = load_model_from_gguf_to_pytorch(SD_GGUF_PATH, 'vae', vae_params)
print("\nVAE模型加载与测试:")
dummy_image_input = torch.randn(1, 3, 256, 256, device=DEVICE)
output_reconstructed = loaded_vae_model(dummy_image_input)
print(f"VAE模型输出形状: {output_reconstructed.shape}")
except Exception as e:
print(f"VAE模型加载或测试失败: {e}")
print("\n" + "="*60)【代码解读与见证奇迹】
这个load_model_from_gguf_to_pytorch函数是本章的灵魂。它封装了从GGUF文件读取所有张量,根据模型类型(llama,unet,vae)实例化对应的PyTorch骨架,然后遍历
GGUF_TO_PYTORCH_MAPS中定义的映射规则,将GGUF张量的数据精确地赋值到PyTorch模型state_dict中对应的weight或bias。
运行这段代码,如果你提供了正确的GGUF文件路径,你将亲眼见证:
LLaMA模型的TransformerBlock能够加载来自GGUF的真实权重,并进行前向传播。
简化UNet和VAE骨架能够加载Stable Diffusion GGUF中的对应权重。
这是"从零到一实现适配"的核心,也是真正意义上的"AI模型基因编辑"! 它让你将之前学到的所有架构知识(LLaMA/UNet/VAE的内部结构)和文件格式知识(GGUF张量命名、类型),融会贯通到这个关键的加载过程中。
第五章:模型适配的"智能"之路:自动化与挑战
探讨在实际工程中,如何更智能地处理模型适配的复杂性,并展望自动化工具的设想和挑战。

5.1 半自动化识别:从GGUF元数据推断PyTorch结构
在实际的复杂场景中,我们不可能为每种模型都手动编写PyTorch骨架和全部映射规则。
策略:可以编写脚本,根据GGUF文件头中的general.architecture、llama.block_count、llama.embedding_length等元数据,来动态地判断模型的类型和层数,然后实例化对应的PyTorch骨架。
挑战:不同模型架构的层名映射规则差异巨大,需要维护一个庞大的映射表。
5.2 挑战:命名约定不统一、模型结构多样性
命名:即使是同一架构(如LLaMA),不同实现(Hugging Face、LLaMA.cpp、自定义)的张量命名也可能存在细微差异。
结构:模型可能包含各种自定义层、特殊的残差连接、不同的归一化放置位置,这些都增加了自动化的难度。
5.3 进阶:自动生成模型骨架的设想
终极目标是:给定一个模型文件(如safetensors或GGUF),能够自动生成对应的PyTorch模型骨架代码。这需要更复杂的元数据标准、或对模型Graph进行解析。
GGUF到PyTorch模型适配全流程
PyTorch safetensors与GGUF的协作:模型转换的链条
再次强调safetensors和GGUF在模型转换生态中的互补关系。
我们已经知道safetensors是通用的安全张量格式,GGUF是LLaMA.cpp的优化格式。在实际的模型发布和使用中,它们常常协同工作:
发布者:通常会提供fp16的safetensors版本(安全、通用)。
用户/转换工具:会下载safetensors,然后使用专门的转换工具(如llama.cpp/convert.py脚本),将其转换为不同量化等级的GGUF文件。
这个链条使得模型既能安全地发布,又能针对不同硬件进行极致优化。
总结与展望:你已成为AI模型的"解构与重构宗师"
总结与展望:你已成为AI模型的"解构与重构宗师"
恭喜你!今天你已经像一位经验丰富的"AI骨架重塑师"和"基因工程师",彻底掌握了如何将GGUF中的权重数据,准确加载到PyTorch模型结构中的终极技术。
✨ 本章惊喜概括 ✨
| 你掌握了什么? | 对应的核心概念/技术 |
|---|---|
| 模型适配的终极挑战 | ✅ GGUF纯数据到PyTorch代码的映射鸿沟 |
| 三重匹配方法论 | ✅ 命名、形状、数据类型的精确对齐 |
| 通用层加载精髓 | ✅ nn.Linear/Conv的权重转置陷阱与处理 |
| LLaMA/UNet/VAE骨架加载 | ✅ 亲手实现核心模型组件的GGUF权重加载 |
| K-Quant反量化概念 | ✅ 理解低比特数据如何还原为浮点数 |
| 完整的适配流程 | ✅ 从读取GGUF到加载PyTorch模型的实践链路 |
| 自动化与逆向工程 | ✅ 窥探模型结构识别与自定义转换的未来 |
| 你现在不再仅仅是模型的使用者,你已经具备了**"解构"任何开源AI模型,并"重构"其PyTorch版本的能力**。这是你在AI模型部署、优化、甚至进行自定义研究时,不可或缺的核心竞争力。你已成为AI模型的"解构与重构宗师"! |