文章目录
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主
一、项目背景
随着信息技术的不断发展和互联网的广泛普及,计算机相关资源如软件教程、开源项目、技术文档、硬件参数等在网络上日益丰富。面对海量数据,如何高效、精准地收集、整理并呈现这些资源,成为提升学习效率与技术积累的关键。传统的人工收集方式费时费力,且不具备实时更新能力。因此,开发一套能够自动化爬取计算机资源并可视化展示的系统,对于提升资源利用率和信息获取效率具有重要意义。
二、项目目标
本项目旨在开发一个基于Django框架的计算机资源爬虫及可视化系统。系统将包括三个核心模块:
- 资源爬虫模块:基于Python编写的定向网络爬虫,可自动抓取指定网站上的计算机类资源,如开源项目信息、教程文章、硬件评测等。
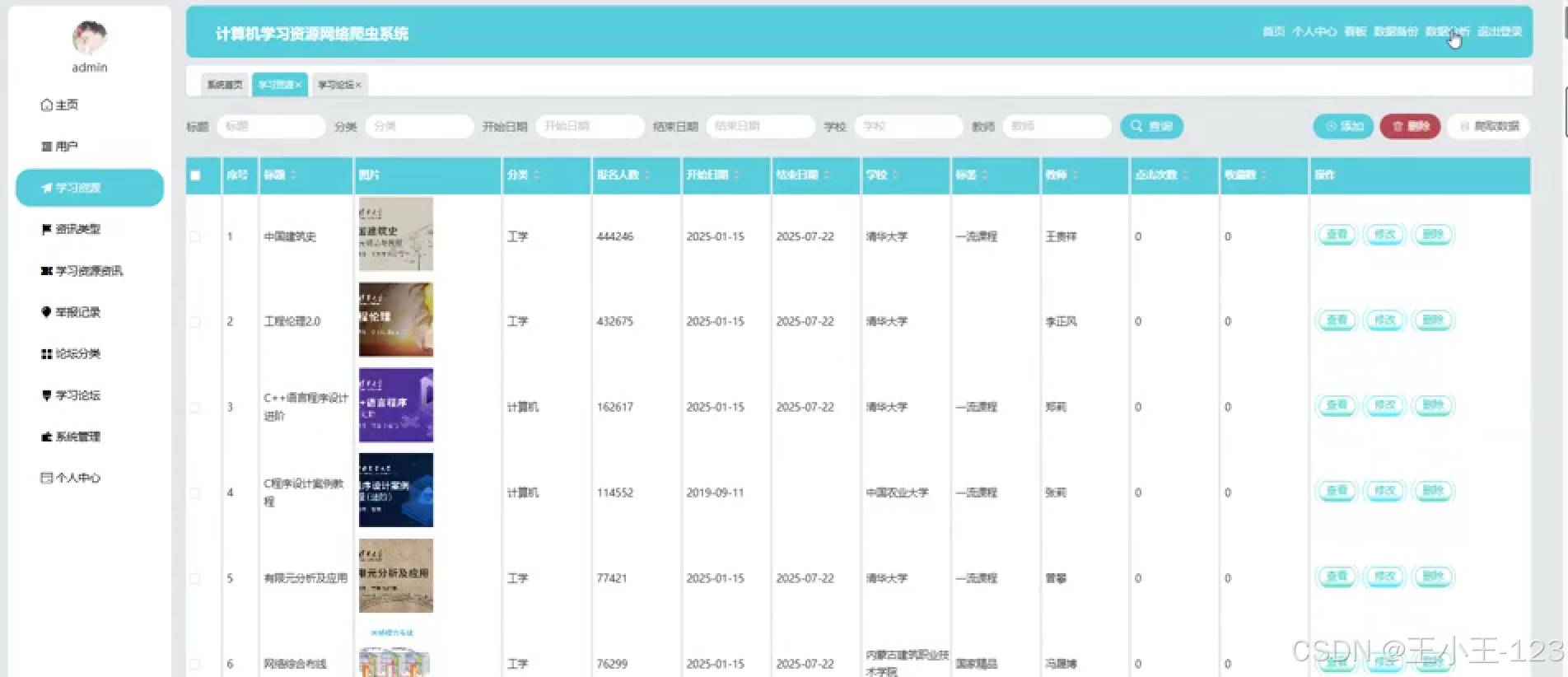
- 数据管理模块:通过Django后台管理系统,实现对爬取数据的分类、存储、检索与管理功能。
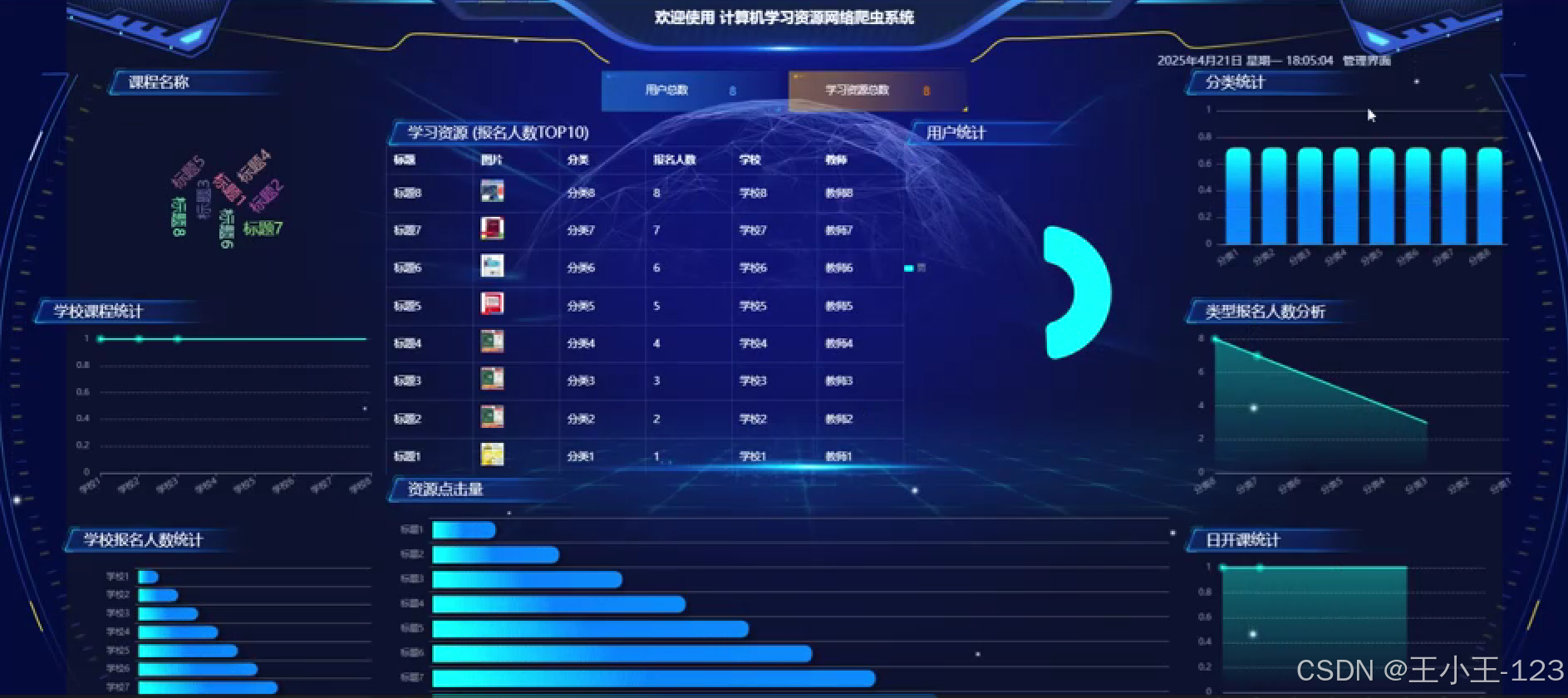
- 可视化展示模块:利用图表与交互界面,直观展示数据分布、趋势、热门话题等信息,帮助用户高效获取所需内容。
三、系统架构与技术选型
-
后端框架:Django
- Django作为一个高效、可扩展的Web框架,提供了完备的MVC结构,适合快速开发和部署;
- 利用其ORM(对象关系映射)功能,实现对数据库中爬取资源的高效管理;
- 自带的Admin管理后台便于开发者进行数据审核和内容控制。
-
**爬虫技术:Scrapy **
- 使用Scrapy框架构建高性能爬虫;
- 配合Requests和BeautifulSoup库,提高页面解析和数据提取的灵活性;
- 支持定时爬取和反爬机制处理(如User-Agent伪装、IP代理、请求限速等)。
-
数据库:MySQL 或 PostgreSQL
- 存储结构化的计算机资源数据;
- 配合Django ORM进行高效的数据操作。
-
前端技术:Vue+ Echarts/D3.js
- 前端页面通过Bootstrap或Tailwind进行响应式设计;
- 使用Echarts或D3.js实现数据图表的动态可视化,提供图形界面如词云、折线图、柱状图等;
- 支持关键词搜索、分类筛选等交互功能。
四、系统功能模块
-
资源爬取
- 用户可设定关键词或选择来源网站;
- 系统自动抓取页面内容,并提取标题、内容摘要、URL、发布时间等信息;
- 定期自动更新数据,确保资源的时效性。
-
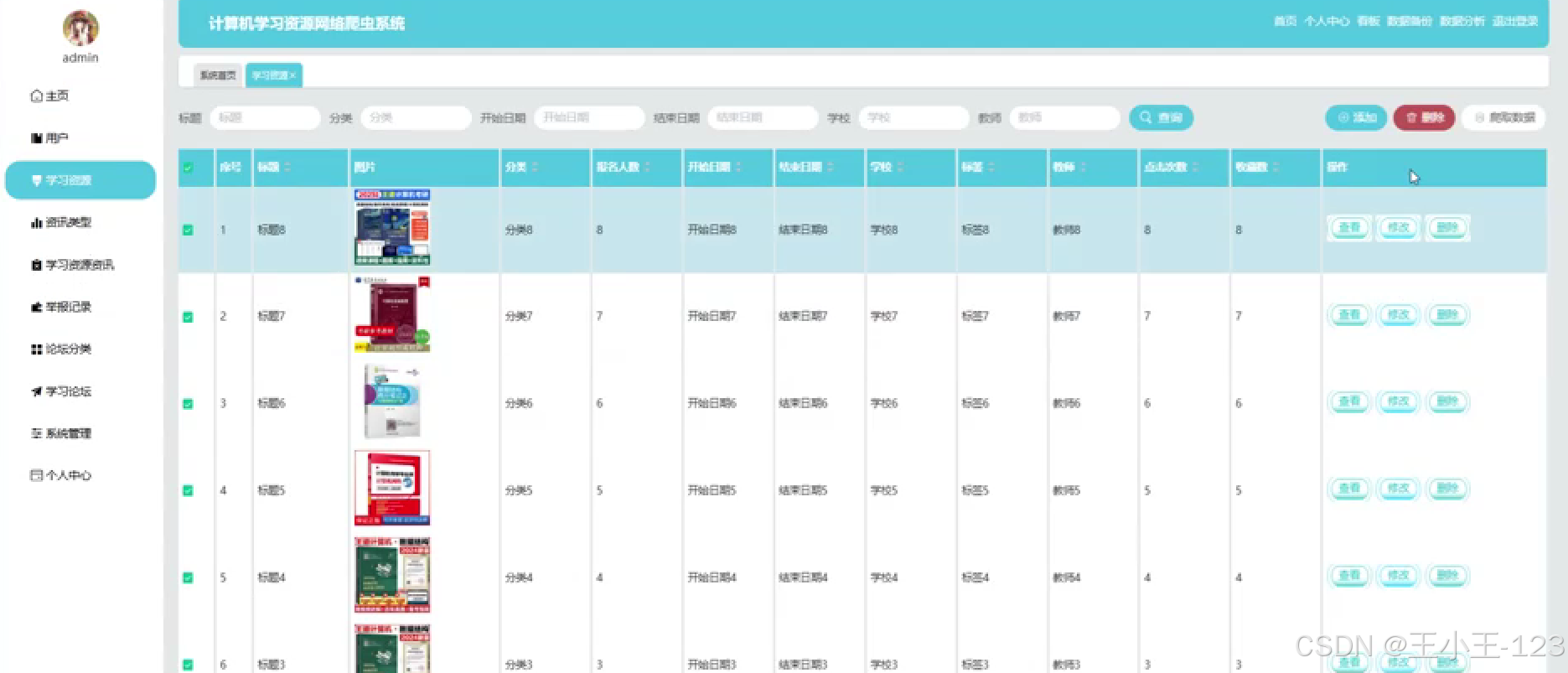
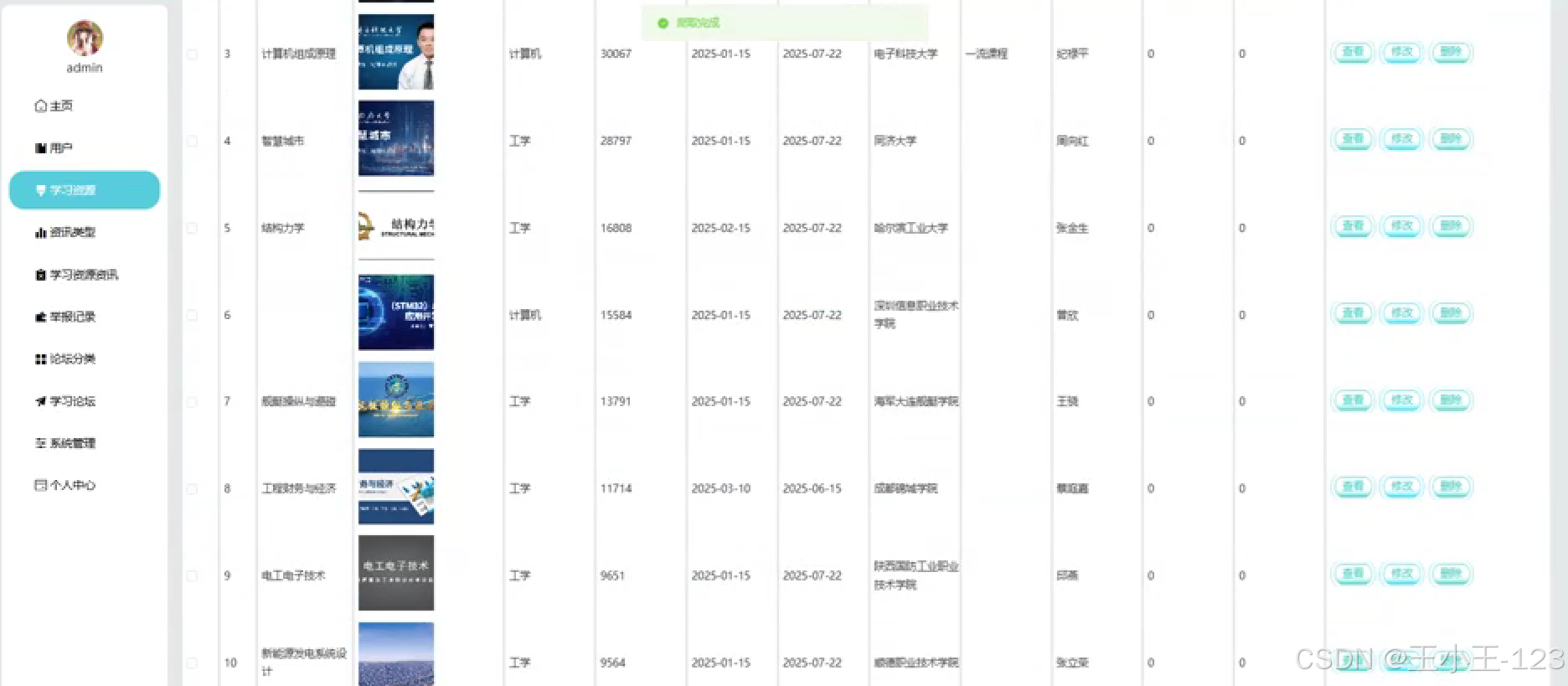
数据管理
- 后台管理系统用于审核、编辑、删除或归类资源;
- 提供分页检索、关键词过滤、标签管理等功能;
- 支持用户评价或收藏功能;
-
可视化展示
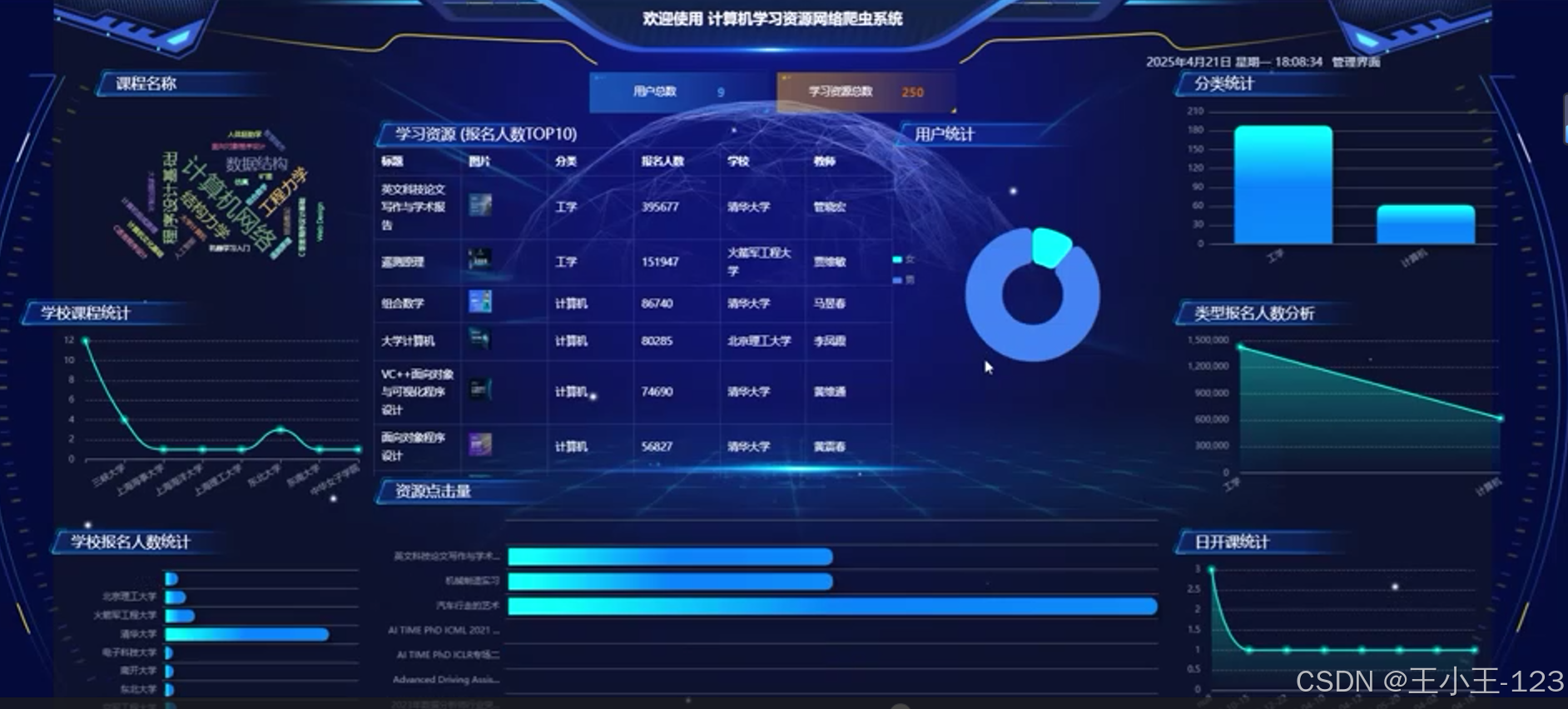
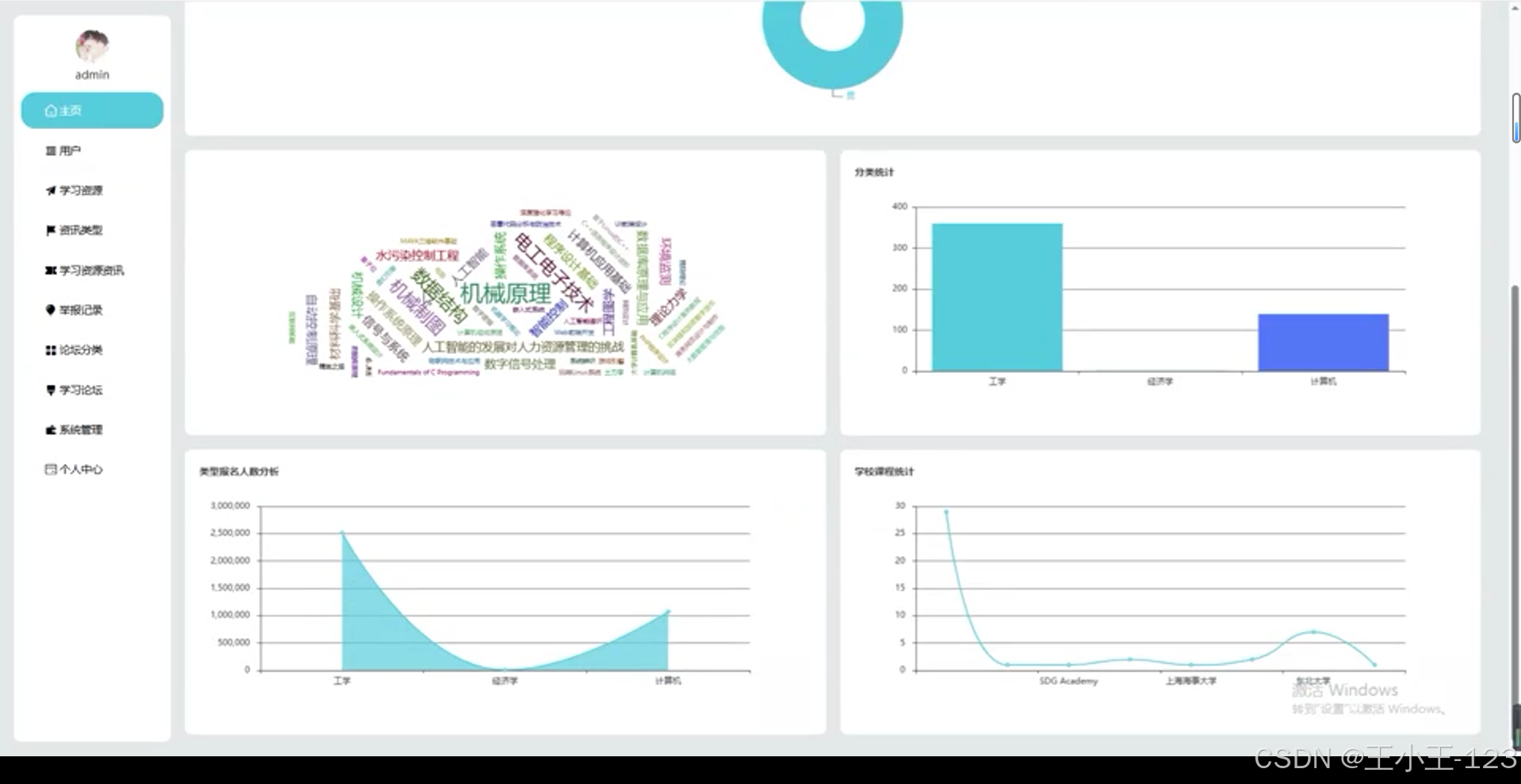
- 首页展示资源总览图,如资源数量趋势图、热门关键词词云;
- 提供各类图表展示资源的类型分布、来源占比、发布时间曲线等;
- 可根据用户偏好生成个性化推荐图谱。
五、应用场景与价值
- 技术学习平台:为学习者提供最新、最全的技术教程与工具;
- 信息聚合工具:整合多源资源,避免用户在多个网站反复查找;
- 数据分析与决策支持:通过可视化图表,快速洞察技术发展趋势与用户兴趣变化;
- 辅助教学与研究:为高校教师或科研人员提供技术资料收集与展示平台。
六、项目特色与创新点
- 基于Django实现后端一体化管理,开发效率高、可维护性强;
- 爬虫模块灵活可扩展,支持多站点、多类型资源采集;
- 可视化图表增强用户交互体验,提高数据利用效率;
- 支持自定义爬取规则,具备良好的适应性和扩展性。
七、总结
"基于Django的计算机资源爬虫及可视化系统"是一个集数据抓取、分类管理与可视化展示为一体的信息平台。该系统不仅提高了计算机资源的获取效率,也通过可视化手段降低了用户获取信息的门槛。随着数据规模扩大和算法优化的加入,未来该系统可进一步拓展到更多领域,如人工智能、网络安全、区块链等,成为信息时代中高效的数据聚合与知识服务工具。


每文一语
本文无语