一,概述
什么是 SPI
SPI 即 Service Provider Interface ,也就是"服务提供者的接口"。
SPI 将服务接口和具体的服务实现分离开来,将服务调用方和服务实现者解耦,能够提升程序的扩展性、可维护性。同时,修改或者替换服务的实现不需要修改调用方。
Java 中有许多地方都使用到了 SPI 机制,比如数据库加载驱动 JDBC、Spring、以及
Dubbo 的扩展实现等。
对比 API 有什么区别
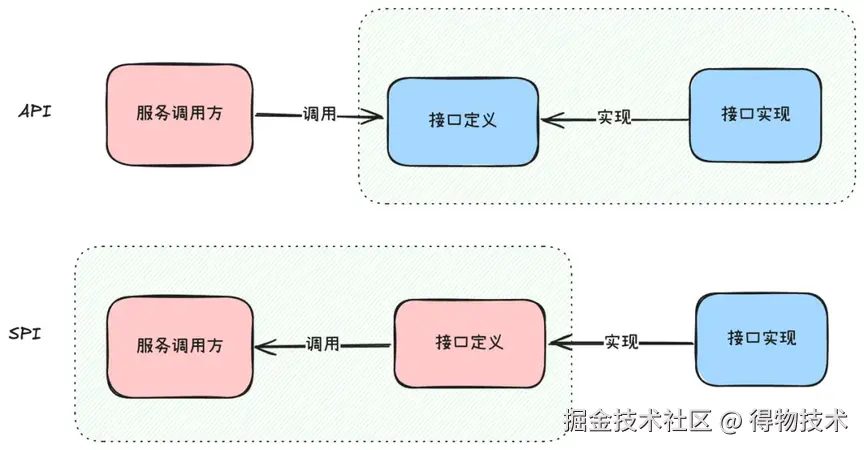
API:接口实现方同时负责接口定义和接口实现,接口控制权在服务提供方。
SPI:服务调用方负责接口定义,不同的接口实现方根据接口定义可以有不同的实现,能够在运行时动态的加载不用实现类,接口控制权在服务调用方。
SPI 有什么用
解耦
在框架开发中,通常需要依赖一些可插拔的功能,但不希望实现具体的适配(能够保持灵活性)。SPI 机制通过定义接口和动态加载实现 ,可以让框架与服务实现解耦。
※ 场景
- 一个数据库连接池库需要支持多个数据库实现(如 MySQL、PostgreSQL),可以通过 SPI 机制动态加载这些数据库驱动。
日志框架(比如 SLF4J)的具体实现,可以通过 SPI 机制加载不同的日志库(如 Log4j、Logback)。
可扩展
SPI 机制提供了动态发现和加载服务的能力,可以让应用程序非常方便地实现扩展,而不需要修改现有代码。
※ 场景
一个文件处理系统需要支持不同的文件格式(如 JSON 或 XML)。通过 SPI 机制可以动态发现不同的文件解析器插件,无需提前硬编码支持的格式。
动态加载
SPI 可以用来实现插件化架构,通过动态加载具体的服务实现增减模块,而无需重新发布整个系统。
※ 场景
-
Web 服务器(如 Tomcat)可以通过 SPI 机制动态加载不同的 HTTP 处理器或过滤器。
-
数据分析系统可以通过 SPI 机制动态加载新的分析算法。
SPI 工作机制
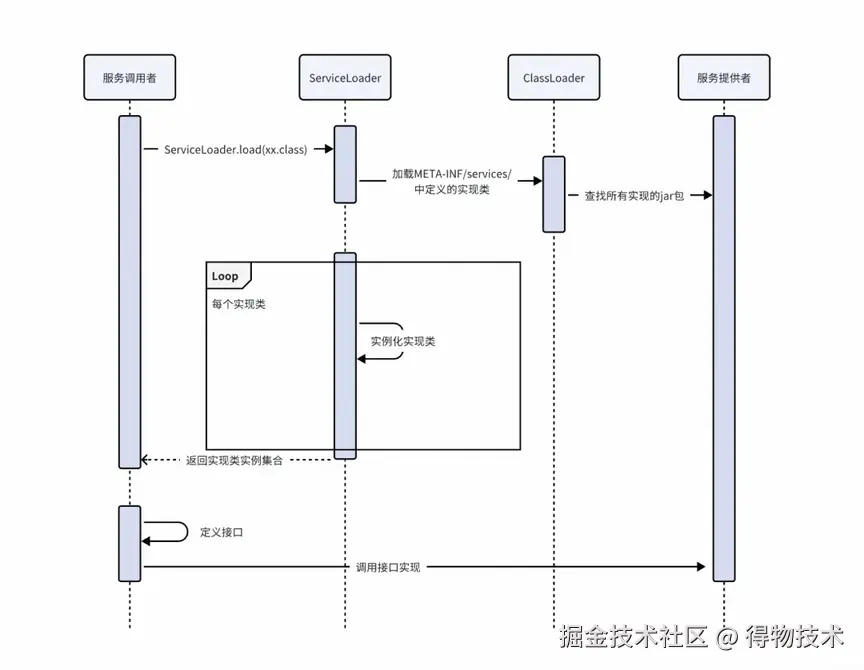
二,ServiceLoader
ServiceLoader 是 JDK 中提供的服务加载类,位于 java.util 包下,final 修饰不可被继承,是实现 SPI 机制的核心。
源码解析
arduino
public final class ServiceLoader<S>
implements Iterable<S>
{
// 默认加载路径前缀
private static final String PREFIX = "META-INF/services/";
// The class or interface representing the service being loaded
// 被加载的实例或接口
private final Class<S> service;
// The class loader used to locate, load, and instantiate providers
// 类加载器
private final ClassLoader loader;
// The access control context taken when the ServiceLoader is created
private final AccessControlContext acc;
// Cached providers, in instantiation order
// 本地缓存,key: 类名 value;类
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
// The current lazy-lookup iterator
// 迭代器
private LazyIterator lookupIterator;
}※ load 方法
scss
// 暴露给外部使用的加载方法
public static <S> ServiceLoader<S> load(Class<S> service,
ClassLoader loader)
{
return new ServiceLoader<>(service, loader);
}
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
// 构造方法私有化
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
// 如果指定了claseLoader,则使用该classLoader,如果没有指定,则使用默认classLoader
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}※ reload 方法
csharp
public void reload() {
// 清空缓存,将linkedHashMap的头和尾置为null
providers.clear();
lookupIterator = new LazyIterator(service, loader);
}ServiceLoader 实现了 Iterable 接口的方法后,拥有了迭代的能力,在这个 iterator 方法被调用时,首先会在 ServiceLoader 的 Provider 缓存中进行查找,如果缓存中没有命中,则在 LazyIterator 中进行查找。
typescript
public Iterator<S> iterator() {
return new Iterator<S>() {
// 本地缓存providers
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
// 优先查本地缓存
if (knownProviders.hasNext())
return true;
// 没有则在LazyInterator中进行查找
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}LazyIterator 使 ServiceLoader 拥有了懒加载的能力,只有调用 iterator 方法或遍历的时候才会去加载对应的实现类,核心代码如下:
typescript
// Private inner class implementing fully-lazy provider lookup
//
private class LazyIterator
implements Iterator<S>
{
Class<S> service;
ClassLoader loader;
Enumeration<URL> configs = null;
Iterator<String> pending = null;
String nextName = null;
private LazyIterator(Class<S> service, ClassLoader loader) {
this.service = service;
this.loader = loader;
}
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
// 配置文件路径,默认 /META-INF/services/ 开头
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else // 读取实现类 类名
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
// 解析配置文件中每行类名
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
// 加载对应的实现类
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
// 创建实现类
S p = service.cast(c.newInstance());
// 放到缓存中
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}
public boolean hasNext() {
if (acc == null) {
return hasNextService();
} else {
PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() {
public Boolean run() { return hasNextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
public S next() {
if (acc == null) {
return nextService();
} else {
PrivilegedAction<S> action = new PrivilegedAction<S>() {
public S run() { return nextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
public void remove() {
throw new UnsupportedOperationException();
}
}小结
ServiceLoader 本质上就是读取约定目录(/META-INF/services/ )下对应接口全限定命名的文件,然后通过反射全量加载文件中定义的所有接口实现类,从而将接口与实现进行解耦。
※ 优点
解耦 :接口与实现分离,无需在代码中硬编码实现类。
扩展性 :新增实现只需添加配置,无需修改已有代码。
※ 缺点
线程不安全 : ServiceLoader 非线程安全,不能保证单例。
性能开销 :每次迭代都重新加载文件(可通过缓存解决),并且会全量配置文件中指定的所有实现类。
无健壮性 :配置错误(如类未找到)会抛出异常而非优雅降级。
三,SPI 实际应用场景
JDBC
JDK 中定义了 Driver 接口,用于连接数据库。
java
package java.sql;
import java.util.logging.Logger;
public interface Driver {
Connection connect(String url, java.util.Properties info)
throws SQLException;
boolean acceptsURL(String url) throws SQLException;
DriverPropertyInfo[] getPropertyInfo(String url, java.util.Properties info)
throws SQLException;
int getMajorVersion();
int getMinorVersion();
boolean jdbcCompliant();
public Logger getParentLogger() throws SQLFeatureNotSupportedException;
}不同的数据库厂商实现这个接口,从而实现与数据库的连接,以我们最熟悉的 MySQL 为例,获取数据库连接的示例代码如下:
ini
// 获取数据库连接
DriverManager connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "123");
// 创建statement
Statement statement = connection.createStatement();
// 执行sql
ResultSet resultSet = statement.executeQuery("select * from student");其中 DriverManager 加载时会执行静态代码块去加载 driver,部分核心代码如下:
typescript
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
}
private static void loadInitialDrivers() {
String drivers;
try {
drivers = AccessController.doPrivileged(new PrivilegedAction<String>() {
public String run() {
return System.getProperty("jdbc.drivers");
}
});
} catch (Exception ex) {
drivers = null;
}
// 如果驱动程序被打包为服务提供者(Service Provider),则加载它。
// 通过类加载器获取所有驱动程序
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
// 这里就使用ServiceLoader去加载接口实现类
// 以mysql-connector-java为例,加载的是 com.mysql.jdbc.Driver 和 com.mysql.fabric.jdbc.FabricMySQLDriver
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
println("DriverManager.initialize: jdbc.drivers = " + drivers);
if (drivers == null || drivers.equals("")) {
return;
}
String[] driversList = drivers.split(":");
println("number of Drivers:" + driversList.length);
for (String aDriver : driversList) {
try {
println("DriverManager.Initialize: loading " + aDriver);
// 加载数据库驱动Driver, 以mysql-connector-java为例,这里加载的是 com.mysql.jdbc.Driver 和 com.mysql.fabric.jdbc.FabricMySQLDrive
// 并注册到registeredDrivers中
Class.forName(aDriver, true,
ClassLoader.getSystemClassLoader());
} catch (Exception ex) {
println("DriverManager.Initialize: load failed: " + ex);
}
}
}随后在 getConnection 方法中遍历已经加载的 driver,执行 connect 方法进行连接。
scss
private final static CopyOnWriteArrayList<DriverInfo> registeredDrivers = new CopyOnWriteArrayList<>();
// 遍历已经注册的driver,调用connect方法进行连接
for(DriverInfo aDriver : registeredDrivers) {
if(isDriverAllowed(aDriver.driver, callerCL)) {
try {
println(" trying " + aDriver.driver.getClass().getName());
Connection con = aDriver.driver.connect(url, info);
if (con != null) {
// Success!
println("getConnection returning " + aDriver.driver.getClass().getName());
return (con);
}
} catch (SQLException ex) {
if (reason == null) {
reason = ex;
}
}
} else {
println(" skipping: " + aDriver.getClass().getName());
}
}
scala
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
public Driver() throws SQLException {
}
static {
try {
DriverManager.registerDriver(new Driver());
} catch (SQLException var1) {
throw new RuntimeException("Can't register driver!");
}
}
}Spring
Spring 中没有直接使用 Java SPI 机制,不过 Spring 的 spring.factories 机制类似于 SPI 机制并拥有更强大的扩展机制,通过读取 META-INF/spring.factories 文件实现自动装配、上下文初始化等功能。
ini
// SpringFactoriesLoader 源码核心逻辑
public final class SpringFactoriesLoader {
public static final String FACTORIES_RESOURCE_LOCATION = "META-INF/spring.factories";
public static List<String> loadFactoryNames(Class<?> factoryType, @Nullable ClassLoader classLoader) {
// 从所有jar包的spring.factories文件加载配置
Enumeration<URL> urls = (classLoader != null ?
classLoader.getResources(FACTORIES_RESOURCE_LOCATION) :
ClassLoader.getSystemResources(FACTORIES_RESOURCE_LOCATION));
List<String> result = new ArrayList<>();
while (urls.hasMoreElements()) {
Properties properties = PropertiesLoaderUtils.loadProperties(
new UrlResource(urls.nextElement()));
String factoryClassNames = properties.getProperty(factoryType.getName());
// 支持逗号分隔的多个实现
result.addAll(Arrays.asList(StringUtils.commaDelimitedListToStringArray(factoryClassNames)));
}
return result;
}
public static <T> List<T> loadFactories(Class<T> factoryType, @Nullable ClassLoader classLoader) {
// 1. 加载所有实现类名
List<String> names = loadFactoryNames(factoryType, classLoader);
// 2. 实例化所有实现
List<T> instances = new ArrayList<>(names.size());
for (String name : names) {
Class<?> instanceClass = ClassUtils.forName(name, classLoader);
instances.add((T) ReflectionUtils.accessibleConstructor(instanceClass).newInstance());
}
// 3. 按@Order排序
AnnotationAwareOrderComparator.sort(instances);
return instances;
}
private static Map<String, List<String>> loadSpringFactories(@Nullable ClassLoader classLoader) {
MultiValueMap<String, String> result = (MultiValueMap)cache.get(classLoader);
if (result != null) {
return result;
} else {
try {
Enumeration<URL> urls = classLoader != null ? classLoader.getResources("META-INF/spring.factories") : ClassLoader.getSystemResources("META-INF/spring.factories");
MultiValueMap<String, String> result = new LinkedMultiValueMap();
while(urls.hasMoreElements()) {
URL url = (URL)urls.nextElement();
UrlResource resource = new UrlResource(url);
Properties properties = PropertiesLoaderUtils.loadProperties(resource);
Iterator var6 = properties.entrySet().iterator();
while(var6.hasNext()) {
Map.Entry<?, ?> entry = (Map.Entry)var6.next();
String factoryClassName = ((String)entry.getKey()).trim();
String[] var9 = StringUtils.commaDelimitedListToStringArray((String)entry.getValue());
int var10 = var9.length;
for(int var11 = 0; var11 < var10; ++var11) {
String factoryName = var9[var11];
result.add(factoryClassName, factoryName.trim());
}
}
}
// 读取META-INF/spring.factories文件夹下文件,解析文件内容并缓存到Map中
cache.put(classLoader, result);
return result;
} catch (IOException var13) {
IOException ex = var13;
throw new IllegalArgumentException("Unable to load factories from location [META-INF/spring.factories]", ex);
}
}
}
}spring.factories 文件的格式为 xxx=xxxx,=号前面的 key 为接口全限定名,=号后面的 value 为接口实现类全限定名 ,多个实现类之间用逗号分割,下图中指定的 key 为 EnableAutoConfiguration,这样 spring 就会为=号后面的类注册为 bean。spring 自动装配原理这里暂不展开。
ini
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
org.apache.hadoop.hbase.client.MonitorAlicloudHBaseAutoConfigurationDubbo
Dubbo 的可扩展机制也使用到了 SPI,不过不是原生的 SPI,而是经过优化的。
由上文 ServiceLoader 源码解析可知,SPI 会读取配置文件,遍历所有类并实例化,如果某些类并不会使用,此时还是会加载进来,造成了资源的浪费;Java SPI 配置文件中只是简单列出了所有扩展实现,没有给他们命名,无法在程序中准确引用;无法做到自动注入和装配等等...... Dubbo 扩展点机制优化了上述问题,提供了动态扩展的能力。
Demo
定义一个接口,并使用 @SPI 注解标注,这表明这个接口是一个扩展点,可被 Dubbo 的 ExtensionLoader 加载。
csharp
@SPI
public interface DemoSpi {
void say();
}接口实现:
typescript
public class DemoSpiImpl implements DemoSpi {
public void say() {
}
}将实现类放在特定目录下,Dubbo 在加载扩展类的时候,会从 META-INF/services/ META-INF/dubbo/ META-INF/dubbo/internal/ 这几个目录下读取。这里在 META-INF/dubbo 目录下新建一个以 DemoSpi 接口名为文件名的文件,内容如下:
ini
demoSpiImpl = com.xxx.xxx.DemoSpiImpl(为 DemoSpi 接口实现类的全类名)接口实现类的全类名)使用如下:
java
public class DubboSPITest {
@Test
public void sayHello() throws Exception {
ExtensionLoader<DemoSpi> extensionLoader =
ExtensionLoader.getExtensionLoader(DemoSpi.class);
DemoSpi dmeoSpi = extensionLoader.getExtension("demoSpiImpl");
dmeoSpi.sayHello();
}
}源码解析
由上面的例子可以看出,Dubbo 主要通过 ExtensionLoader 加载配置文件中指定的实现类,整体流程上和 ServiceLoader 加载流程类似,同时做了相关的优化扩展。
※ duboo 加载扩展主要步骤
-
读取并解析配置文件
-
缓存所有扩展实现
-
基于用户执行的扩展名,实例化对应的扩展实现
-
进行扩展实例化属性的 IOC 注入及实例化扩展的包装类,实现 AOP 特性
SPI 加载固定扩展类的入口是 ExtensionLoader 的 getExtension 方法,该方法主要调用 createExtession 方法获取扩展实例:
scss
private T createExtension(String name, boolean wrap) {
// 从配置文件中加载所有的拓展类,可得到"配置项名称"到"配置类"的映射关系表
Class<?> clazz = getExtensionClasses().get(name);
// 如果没有该接口的扩展,或者该接口的实现类不允许重复但实际上重复了,直接抛出异常
if (clazz == null || unacceptableExceptions.contains(name)) {
throw findException(name);
}
try {
T instance = (T) EXTENSION_INSTANCES.get(clazz);
// 这段代码保证了扩展类只会被构造一次,也就是单例的.
if (instance == null) {
EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.getDeclaredConstructor().newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
// 向实例中注入依赖
injectExtension(instance);
// 如果启用包装的话,则自动为进行包装.
// 比如我基于 Protocol 定义了 DubboProtocol 的扩展,但实际上在 Dubbo 中不是直接使用的 DubboProtocol, 而是其包装类 ProtocolListenerWrapper
if (wrap) {
List<Class<?>> wrapperClassesList = new ArrayList<>();
if (cachedWrapperClasses != null) {
wrapperClassesList.addAll(cachedWrapperClasses);
wrapperClassesList.sort(WrapperComparator.COMPARATOR);
Collections.reverse(wrapperClassesList);
}
// 循环创建 Wrapper 实例
if (CollectionUtils.isNotEmpty(wrapperClassesList)) {
for (Class<?> wrapperClass : wrapperClassesList) {
Wrapper wrapper = wrapperClass.getAnnotation(Wrapper.class);
if (wrapper == null || (ArrayUtils.contains(wrapper.matches(), name) && !ArrayUtils.contains(wrapper.mismatches(), name))) {
// 将当前 instance 作为参数传给 Wrapper 的构造方法,并通过反射创建 Wrapper 实例。 // 然后向 Wrapper 实例中注入依赖,最后将 Wrapper 实例再次赋值给 instance 变量
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
}
}
// 初始化
initExtension(instance);
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance (name: " + name + ", class: " + type + ") couldn't be instantiated: " + t.getMessage(), t);
}
}※ 上述代码全流程
-
通过 getExtensionClasses 获取所有的拓展类
-
通过反射创建拓展对象
-
向拓展对象中注入依赖
-
将拓展对象包裹在相应的 Wrapper 对象中
-
初始化扩展对象
获取所有拓展类 getExtensionClasses 和 JDK SPI 类似,也是先从缓存中拿,拿不到加锁再次查缓存,还拿不到则通过 loadExtensionClasses 加载拓展类。
typescript
private Map<String, Class<?>> getExtensionClasses() {
Map<String, Class<?>> classes = (Map)this.cachedClasses.get();
if (classes == null) {
synchronized(this.cachedClasses) {
classes = (Map)this.cachedClasses.get();
if (classes == null) {
classes = this.loadExtensionClasses();
this.cachedClasses.set(classes);
}
}
}
return classes;
}loadExtensionClasses 总共做了两件事情,一是解析 @SPI 注解,二是调用 loadDirectory 方法加载指定文件夹配置文件。
scss
private Map<String, Class<?>> loadExtensionClasses() {
// 缓存默认的 SPI 扩展名
cacheDefaultExtensionName();
Map<String, Class<?>> extensionClasses = new HashMap<>();
// 基于策略来加载指定文件夹下的文件
// 分别读取 META-INF/services/ META-INF/dubbo/ META-INF/dubbo/internal/ 这几个目录下的配置文件
for (LoadingStrategy strategy : strategies) {
loadDirectory(extensionClasses, strategy.directory(), type.getName(), strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());
loadDirectory(extensionClasses, strategy.directory(), type.getName().replace("org.apache", "com.alibaba"), strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());
}
return extensionClasses;
}其中 loadDirectory 方法则是拿到指定文件夹下文件的全路径名,调用 loadResource 去加载资源。
ini
private void loadResource(Map<String, Class<?>> extensionClasses, ClassLoader classLoader, java.net.URL resourceURL, boolean overridden, String... excludedPackages) {
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(resourceURL.openStream(), StandardCharsets.UTF_8));
Throwable var7 = null;
try {
String line;
try {
// 读取配置文件中每一行
while((line = reader.readLine()) != null) {
// 只读取#前面的内容,#后面的为注释
int ci = line.indexOf(35);
if (ci >= 0) {
line = line.substring(0, ci);
}
line = line.trim();
if (line.length() > 0) {
try {
String name = null;
int i = line.indexOf(61);
if (i > 0) {
// 分别读取=前的作为name,=后面的为具体的实现类全路径名
name = line.substring(0, i).trim();
line = line.substring(i + 1).trim();
}
if (line.length() > 0 && !this.isExcluded(line, excludedPackages)) {
this.loadClass(extensionClasses, resourceURL, Class.forName(line, true, classLoader), name, overridden);
}
} catch (Throwable var21) {
Throwable t = var21;
IllegalStateException e = new IllegalStateException("Failed to load extension class (interface: " + this.type + ", class line: " + line + ") in " + resourceURL + ", cause: " + t.getMessage(), t);
this.exceptions.put(line, e);
}
}
}
} catch (Throwable var22) {
var7 = var22;
throw var22;
}
} finally {
//close ...
}
} catch (Throwable var24) {
Throwable t = var24;
logger.error("Exception occurred when loading extension class (interface: " + this.type + ", class file: " + resourceURL + ") in " + resourceURL, t);
}
}loadResource 则主要读取配置文件中每一行,分为 key 和 value 两部分,key 为=前面的实现类别名,value 为=后面的实现类实例,加载实例的过程为 loadClass 方法,如下:
vbnet
private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name, boolean overridden) throws NoSuchMethodException { if (!type.isAssignableFrom(clazz)) { throw new IllegalStateException("Error occurred when loading extension class (interface: " + type + ", class line: " + clazz.getName() + "), class " + clazz.getName() + " is not subtype of interface."); } // 检测目标类上是否有 Adaptive 注解 if (clazz.isAnnotationPresent(Adaptive.class)) { cacheAdaptiveClass(clazz, overridden); } else if (isWrapperClass(clazz)) { // 缓存包装类 cacheWrapperClass(clazz); } else { // 进入到这里,表明只是该类只是一个普通的拓展类 // 检测 clazz 是否有默认的构造方法,如果没有,则抛出异常 clazz.getConstructor(); if (StringUtils.isEmpty(name)) { // 如果 name 为空,则尝试从 Extension 注解中获取 name,或使用小写的类名作为 name name = findAnnotationName(clazz); if (name.length() == 0) { throw new IllegalStateException("No such extension name for the class " + clazz.getName() + " in the config " + resourceURL); } } String[] names = NAME_SEPARATOR.split(name); if (ArrayUtils.isNotEmpty(names)) { // 如果类上有 Activate 注解,则使用 names 数组的第一个元素作为键, // 存储 name 到 Activate 注解对象的映射关系 cacheActivateClass(clazz, names[0]); for (String n : names) { // 存储 Class 到名称的映射关系 cacheName(clazz, n); // 存储 name 到 Class 的映射关系. // 如果存在同一个扩展名对应多个实现类,基于 override 参数是否允许覆盖,如果不允许,则抛出异常. saveInExtensionClass(extensionClasses, clazz, n, overridden); } } }}Dubbo SPI 应用场景
※ 协议扩展
shell
# META-INF/dubbo/org.apache.dubbo.rpc.Protocoldubbo=org.apache.dubbo.rpc.protocol.dubbo.DubboProtocolhttp=org.apache.dubbo.rpc.protocol.http.HttpProtocolgrpc=org.apache.dubbo.rpc.protocol.grpc.GrpcProtocol※ 集群容错
java
@SPI(FailoverCluster.NAME)public interface Cluster { @Adaptive <T> Invoker<T> join(Directory<T> directory) throws RpcException;}
// 使用示例<dubbo:reference cluster="failfast"/>※ 服务治理 filter 过滤器
java
@SPIpublic interface Filter { Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException; public interface Listener { void onResponse(Result appResponse, Invoker<?> invoker, Invocation invocation); void onError(Throwable t, Invoker<?> invoker, Invocation invocation); }}四,总结
值得一提的是,SPI 在实际使用过程中存在一些问题:
※ 资源浪费预性能问题
由上文源码解析可知,ServiceLoader 在加载时会扫描 META-INF/services 目录并解析文件,会通过反射实例化所有实现类,如果实现类很多,或者初始化很耗时,会造成一定程度上的性能开销和资源浪费,所以 Dubbo 的 ExtensionLoader 在此之上进行了优化,通过缓存以及在配置文件中指定 key 实现只加载部分实现类。
※ 多个实现类加载顺序问题
ServiceLoader 加载服务提供者实现的顺序由 classpath 中 jar 包的顺序决定,如果你的逻辑依赖于获取到的第一个实现,在不同环境下可能会出现加载顺序不一致导致的异常问题,所以尽可能避免依赖加载顺序。
※ 类重复加载问题
如果 classpath 中存在多个 jar 包都申明了同一个接口的相同实现类,或者同一个 jar 包被不同类加载器加载多次,会导致同一个实现类被多次加载和实例化,可能导致单例失效或资源冲突。
总的来说,SPI 机制的应用场景还是很广的,其核心在于通过读取配置文件动态加载接口实现,解耦了接口定义与实现 ,实现了框架可扩展性,在各大框架中都能看到其身影。
往期回顾
1.Java volatile 关键字到底是什么|得物技术
2.社区搜索离线回溯系统设计:架构、挑战与性能优化|得物技术
3.从 Rust 模块化探索到 DLB 2.0 实践|得物技术
4.eBPF 助力 NAS 分钟级别 Pod 实例溯源|得物技术
5.正品库拍照 PWA 应用的实现与性能优化|得物技术
文 / 琉璃
关注得物技术,每周一、三更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。