- 代码部分 : quantize_qwen3_coder_30b_a3b_instruct_gptq.py
python
import os
########## 环境变量设置 ##########
# 当前可用的 CUDA 编号
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
# GPU 显存资源片段优化
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
# GPU 物理设备
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
import torch
from datasets import load_dataset
from transformers import AutoTokenizer
from gptqmodel import GPTQModel, QuantizeConfig
# 校准数据集路径 (公开代码生成 bigcode/the-stack 数据集的 python 代码部分数据集)
local_parquet_path = "./calibration_dataset/train-00000-of-00206.parquet"
# Qwen3-Coder-30B-A3B-Instruct 模型路径
model_name_or_path = "./models/Qwen3-Coder-30B-A3B-Instruct"
# 量化后模型保存路径
quantized_model_dir = "./models/Qwen3-Coder-30B-A3B-Instruct-GPTQ"
# 量化配置
# 参考 gptqmodel 示例和文档进行调整
quantize_config = QuantizeConfig(
bits=4, # 量化为 4-bit
group_size=128, # group size 128 依据模型的 config.json "head_dim": 128
damp_percent=0.01, # Dampening
desc_act=False, # 设为 False 可提升速度和兼容性
static_groups=False, # 不设置静态组
sym=True, # 对称量化
true_sequential=True, # 真正的顺序量化
# 根据 gptqmodel 文档可能还有其他参数
)
# 内存映射配置 (启用 CPU 卸载)
# 告诉 transformers / accelerate 如何分配 CPU 和 GPU 内存
max_memory = {
1: "22GiB", # 数字键值表示 GPU 编号,量化过程分配的 GPU 1 显存
"cpu": "65GiB" # 量化过程分配的 CPU 内存
}
# 校准数据集配置
calibration_config = {
"n_samples": 300, # 校准样本数
"seq_len": 1024, # 序列长度
"seed": 42, # 随机种子
}
########## 加载 tokenizer ##########
print("1. Loading tokenizer...")
# 使用 trust_remote_code=True (Qwen 系列模型通常需要)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True, trust_remote_code=True)
# 如果词向量编码中没有 pad_token,则将 eos_token 给它
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
########## 加载并准备校准数据集 ##########
print("2. Loading and preparing calibration dataset from local parquet file...")
try:
n_samples = calibration_config["n_samples"]
seq_len = calibration_config["seq_len"]
seed = calibration_config["seed"]
print(f" Loading dataset from {local_parquet_path}...")
# 加载本地 parquet 文件
raw_datasets = load_dataset("parquet", data_files=local_parquet_path, split="train")
print(f" Total samples in file: {len(raw_datasets)}")
# 随机打乱并选择样本
print(f" Shuffling and selecting {n_samples} samples...")
raw_datasets = raw_datasets.shuffle(seed=seed).select(range(min(n_samples, len(raw_datasets))))
########## tokenize function ##########
def tokenize_function(example):
"""对单个样本进行 Tokenize, 用于 GPTQ 的输入"""
# 1. 获取文本内容,从 "content" 键获取代码文本
text = example.get("content", "")
# 2. 快速检查: 确保是字符串且非空
if not isinstance(text, str) or not text.strip():
# 如果不是字符串或为空,直接跳过
return None
try:
# 3. tokenize 文本
# 设置 return_tensors=None 确保返回 Python List (通常是 List[List[int]])
encodings = tokenizer(
text,
truncation=True, # 超过 max_length 则截断
padding=False, # 不进行填充
max_length=seq_len, # 最大序列长度
return_tensors=None, # 返回 Python List
)
# 4. 提取 input_ids 和 attention_mask
input_ids = encodings["input_ids"]
attention_mask = encodings["attention_mask"]
# 5. 检查 input_ids 必须存在且是列表 (这一步会过滤掉所有不符合预期格式的样本)
if not (isinstance(input_ids, list) and isinstance(attention_mask, list)):
return None
# 6. 检查数据长度必须足够
if len(input_ids) != len(attention_mask) or len(input_ids) < 32:
return None
# 7. 截断到指定长度,虽然 truncation=True 已经处理了,但显式截断更安全
input_ids = input_ids[:seq_len]
attention_mask = attention_mask[:seq_len]
# 8. 返回符合 gptqmodel 要求的格式: {"input_ids": List[int], "attention_mask": List[int]}
# gptqmodel 内部会将这个列表转换为 tensor
return {
"input_ids": input_ids,
"attention_mask": attention_mask
}
except Exception as e:
# 6. 捕获任何在 tokenize 或处理过程中发生的意外错误,并跳过该样本
# 这可以防止一个坏样本导致整个量化过程崩溃
# print(f"Warning: Skipping sample due to tokenization error: {e}")
return None
########## tokenize dataset ##########
print(" Tokenizing dataset...")
tokenized_datasets = raw_datasets.map(
tokenize_function,
batched=False,
remove_columns=raw_datasets.column_names, # 移除数据集原始列
desc="Tokenizing the stack (Python)",
)
########## 过滤无效样本 ##########
print(" Filtering tokenized dataset...")
initial_count = len(tokenized_datasets)
tokenized_datasets = tokenized_datasets.filter(
lambda example: example is not None and
isinstance(example["input_ids"], list) and
len(example["input_ids"]) >= 32
)
filtered_count = len(tokenized_datasets)
print(f" Samples after filtering: {filtered_count} (removed {initial_count - filtered_count})")
########## 准备最终校准数据集格式 ##########
print(" Formatting final calibration dataset...")
calibration_dataset = []
for sample in tokenized_datasets:
input_ids_list = sample["input_ids"]
attention_mask_list = sample["attention_mask"]
# 最终检查并转换为 tensor
if (isinstance(input_ids_list, list) and
isinstance(attention_mask_list, list) and
len(input_ids_list) == len(attention_mask_list) and
len(input_ids_list) >= 32):
try:
tensor_input_ids = torch.tensor(input_ids_list, dtype=torch.long)
tensor_attention_mask = torch.tensor(attention_mask_list, dtype=torch.long)
calibration_dataset.append({
"input_ids": tensor_input_ids,
"attention_mask": tensor_attention_mask
})
except Exception:
# 忽略无法转换为 tensor 的样本
pass
print(f" Final calibration dataset prepared with {len(calibration_dataset)} samples.")
if len(calibration_dataset) == 0:
raise ValueError("Final calibration dataset is empty!")
except Exception as e:
print(f"Error during data loading / preparation: {e}")
raise
########## 加载模型 ##########
print("3. Loading model with memory mapping...")
try:
# 使用 device_map="auto" 和 max_memory 自动管理内存分配
model = GPTQModel.from_pretrained(
model_name_or_path,
quantize_config=quantize_config,
device_map="auto", # 自动分配设备,可以自动将模型卸载到 CPU 内存上,量化过程中 CPU-GPU 之间的数据交互
max_memory=max_memory, # 指定最大内存分配
torch_dtype=torch.bfloat16, # 使用模型精度 bfloat16 加载
trust_remote_code=True, # Qwen 系列通常需要
# low_cpu_mem_usage=True, # 尝试减少 CPU 内存峰值
# offload_folder="offload", # 如果需要,指定一个磁盘文件夹用于卸载
)
print(" Model loaded successfully.")
except Exception as e:
print(f"Error loading model: {e}")
raise
########## 执行量化 ##########
print("4. Starting quantization process...")
try:
model.quantize(calibration_dataset=calibration_dataset)
print(" Quantization completed successfully.")
except Exception as e:
print(f"Error during quantization: {e}")
raise # 重新抛出以停止
########## 保存模型 ##########
print("5. Saving quantized model...")
try:
model.save_quantized(quantized_model_dir)
tokenizer.save_pretrained(quantized_model_dir)
print(f" Quantized model saved to {quantized_model_dir}.")
except Exception as e:
print(f"Error saving model: {e}")
raise
print("All steps completed successfully!")
-
执行过程会报错:
INFO -----------------------------------------------------------------------------------------------------------------------------------------
INFO | gptq | 0 | mlp.experts.121.down_proj | 0.00020292 | 267 | 0.01000 | 0.206 | 16.782 | /48] 2.1%
INFO -----------------------------------------------------------------------------------------------------------------------------------------
INFO | gptq | 0 | mlp.experts.122.down_proj | 0.00045387 | 295 | 0.01000 | 0.203 | 16.782 | /48] 2.1%
INFO -----------------------------------------------------------------------------------------------------------------------------------------
INFO | gptq | 0 | mlp.experts.123.down_proj | 0.00005101 | 291 | 0.01000 | 0.208 | 16.782 | /48] 2.1%
INFO -----------------------------------------------------------------------------------------------------------------------------------------
INFO | gptq | 0 | mlp.experts.124.down_proj | 0.00336569 | 296 | 0.01000 | 0.269 | 16.782 | /48] 2.1%
INFO -----------------------------------------------------------------------------------------------------------------------------------------
INFO | gptq | 0 | mlp.experts.125.down_proj | 0.00214480 | 295 | 0.01000 | 0.203 | 16.782 | /48] 2.1%
INFO -----------------------------------------------------------------------------------------------------------------------------------------
INFO | gptq | 0 | mlp.experts.126.down_proj | 0.00106318 | 297 | 0.01000 | 0.205 | 16.782 | /48] 2.1%
INFO -----------------------------------------------------------------------------------------------------------------------------------------
INFO | gptq | 0 | mlp.experts.127.down_proj | 0.00021535 | 271 | 0.01000 | 0.207 | 16.782 | /48] 2.1%
INFO -----------------------------------------------------------------------------------------------------------------------------------------
Quantizing layer 1 of 47 1 of 47 ██-----------------------------------------------------| 0:04:07 / 1:38:48 2/48 4.2%Error during quantization: The size of tensor a (32) must match the size of tensor b (128) at non-singleton dimension 3
Traceback (most recent call last):
File "~/Quantization/quantize_qwen3_coder_30b_a3b_instruct_gptq.py", line 194, in
model.quantize(calibration_dataset=calibration_dataset)^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "~/quantization/lib/python3.13/site-packages/gptqmodel/models/base.py", line 450, in quantize
return module_looper.loop(
~~~~~~~~~~~~~~~~~~^
calibration_enable_gpu_cache=calibration_enable_gpu_cache,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
...<2 lines>...
backend=backend,
^^^^^^^^^^^^^^^^
)
^
File "~/quantization/lib/python3.13/site-packages/torch/utils/_contextlib.py", line 120, in decorate_context
return func(*args, **kwargs)
File "~/quantization/lib/python3.13/site-packages/gptqmodel/looper/module_looper.py", line 315, in loop
module(*layer_input) if is_lm_head_module else module(*layer_input,
~~~~~~^^^^^^^^^^^^^^
**additional_layer_inputs)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "~/quantization/lib/python3.13/site-packages/transformers/modeling_layers.py", line 94, in call
return super().call (*args, **kwargs)
~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^
File "~/quantization/lib/python3.13/site-packages/torch/nn/modules/module.py", line 1773, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^
File "~/quantization/lib/python3.13/site-packages/torch/nn/modules/module.py", line 1784, in _call_impl
return forward_call(*args, **kwargs)
File "~/quantization/lib/python3.13/site-packages/transformers/models/qwen3_moe/modeling_qwen3_moe.py", line 342, in forward
hidden_states, _ = self.self_attn(
~~~~~~~~~~~~~~^
hidden_states=hidden_states,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
...<5 lines>...
**kwargs,
^^^^^^^^^
)
^
File "~/quantization/lib/python3.13/site-packages/torch/nn/modules/module.py", line 1773, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^
File "~/quantization/lib/python3.13/site-packages/torch/nn/modules/module.py", line 1784, in _call_impl
return forward_call(*args, **kwargs)
File "~/quantization/lib/python3.13/site-packages/transformers/models/qwen3_moe/modeling_qwen3_moe.py", line 167, in forward
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
File "~/quantization/lib/python3.13/site-packages/transformers/models/qwen3_moe/modeling_qwen3_moe.py", line 78, in apply_rotary_pos_emb
q_embed = (q * cos) + (rotate_half(q) * sin)
^~~
RuntimeError: The size of tensor a (32) must match the size of tensor b (128) at non-singleton dimension 3
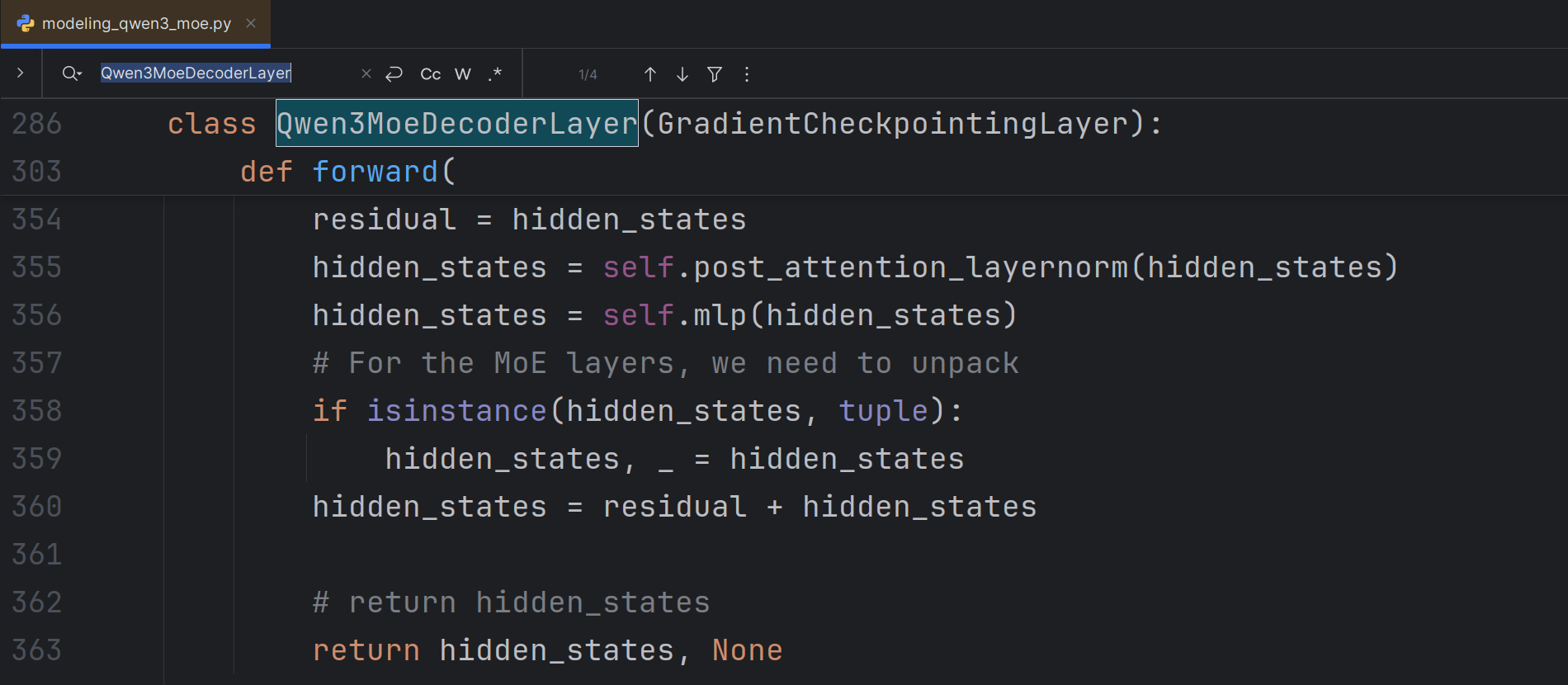
参考 https://github.com/ModelCloud/GPTQModel/issues/1665 解决错误
将 modeling_qwen3_moe.py 中 Qwen3MoeDecoderLayer 类的 forward 改写如图