目录
[1 初始化链表](#1 初始化链表)
[2 插入节点](#2 插入节点)
[3 删除节点](#3 删除节点)
[4 访问节点](#4 访问节点)
[5 查找节点](#5 查找节点)
[数组 vs 链表](#数组 vs 链表)
链表
概念
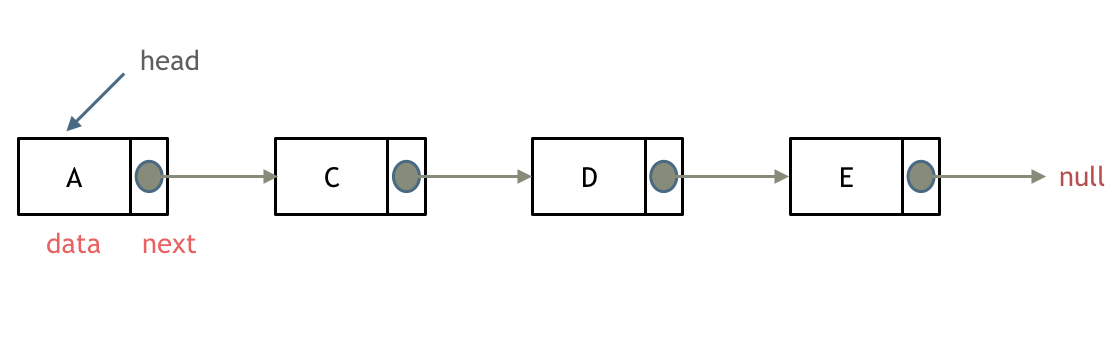
链表是一种通过指针串联在一起的线性结构,每一个节点由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向null(空指针的意思)。
链表的入口节点称为链表的头结点也就是head。
如图所示:
链表的类型
单链表
每个节点只有一个指针域,即指向下一个节点的指针,这种链表称为单链表。如上图,就是单链表。
双链表
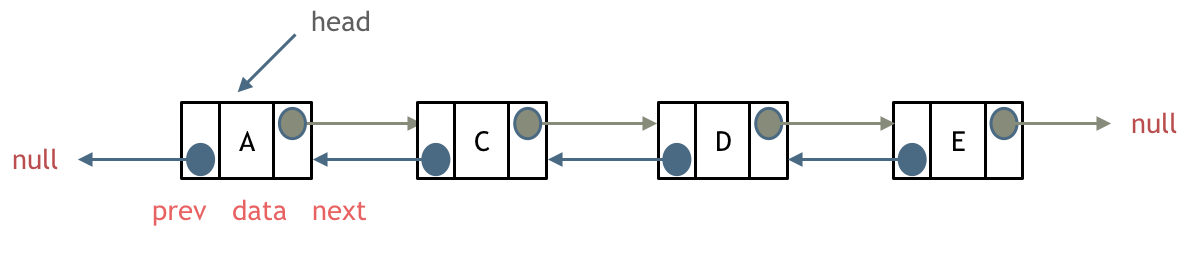
每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。
双链表 既可以向前查询也可以向后查询。
如图所示:
循环链表
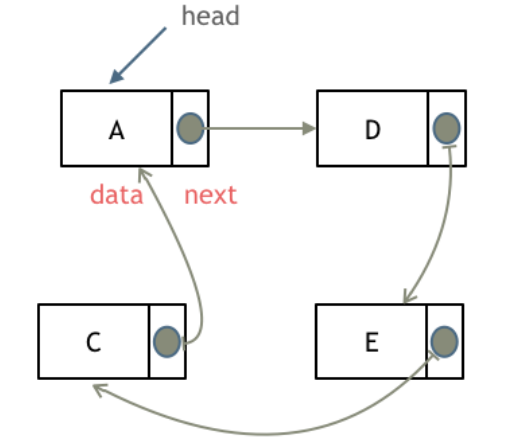
循环链表,顾名思义,就是链表首尾相连。
循环链表可以用来解决约瑟夫环问题。
如图所示:
链表的存储方式
链表(linked list)是一种线性数据结构,其中的每个元素都是一个节点对象,各个节点通过"引用"相连接。引用记录了下一个节点的内存地址,通过它可以从当前节点访问到下一个节点。
链表的设计使得各个节点可以分散存储在内存各处,它们的内存地址无须连续。
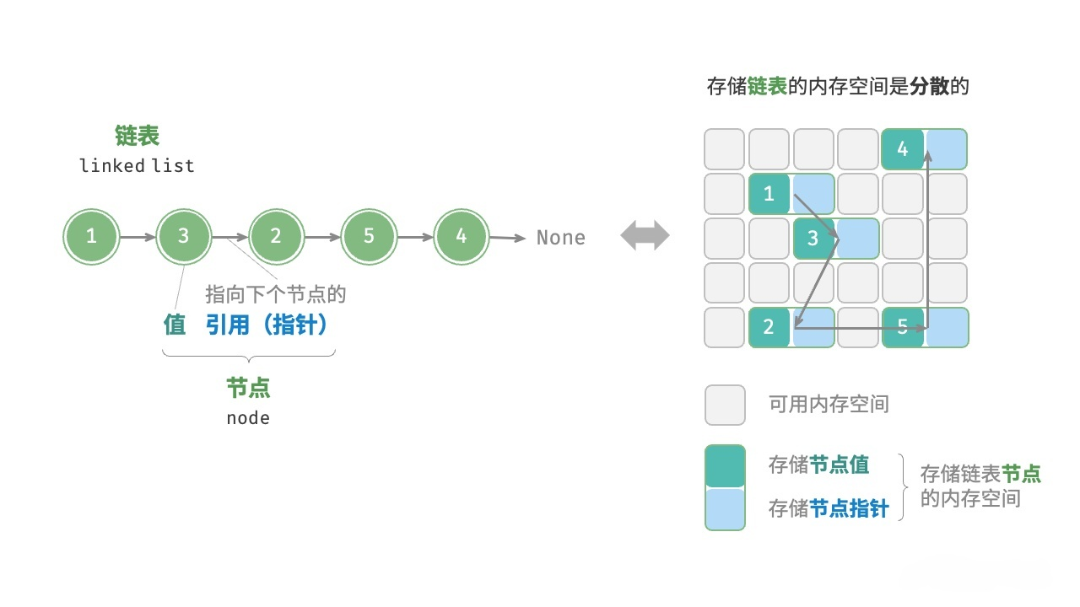
链表的组成单位是节点(node)对象。每个节点都包含两项数据:节点的"值"和指向下一节点的"引用"。
链表的首个节点被称为"头节点",最后一个节点被称为"尾节点"。
尾节点指向的是"空",它在 Java、C++ 和 Python 中分别被记为 null、nullptr 和 None 。
在 C、C++、Go 和 Rust 等支持指针的语言中,上述"引用"应被替换为"指针"。
如以下代码所示,链表节点 ListNode 除了包含值,还需额外保存一个引用(指针)。因此在相同数据量下,链表比数组占用更多的内存空间。
链表的定义
C/C++的定义链表节点方式,如下所示:
cpp
// 单链表
struct ListNode {
int val; // 节点上存储的元素
ListNode *next; // 指向下一个节点的指针
ListNode(int x) : val(x), next(NULL) {} // 节点的构造函数
};java定义链表节点方式,如下所示:
java
/* 链表节点类 */
class ListNode {
int val; // 节点值
ListNode next; // 指向下一节点的引用
ListNode(int x) { val = x; } // 构造函数
}链表的操作
1 初始化链表
建立链表分为两步,第一步是初始化各个节点对象,第二步是构建节点之间的引用关系。初始化完成后,我们就可以从链表的头节点出发,通过引用指向 next 依次访问所有节点。
c++代码如下:
cpp
/* 初始化链表 1 -> 3 -> 2 -> 5 -> 4 */
// 初始化各个节点
ListNode* n0 = new ListNode(1);
ListNode* n1 = new ListNode(3);
ListNode* n2 = new ListNode(2);
ListNode* n3 = new ListNode(5);
ListNode* n4 = new ListNode(4);
// 构建节点之间的引用
n0->next = n1;
n1->next = n2;
n2->next = n3;
n3->next = n4;java代码如下:
java
/* 初始化链表 1 -> 3 -> 2 -> 5 -> 4 */
// 初始化各个节点
ListNode n0 = new ListNode(1);
ListNode n1 = new ListNode(3);
ListNode n2 = new ListNode(2);
ListNode n3 = new ListNode(5);
ListNode n4 = new ListNode(4);
// 构建节点之间的引用
n0.next = n1;
n1.next = n2;
n2.next = n3;
n3.next = n4;数组整体是一个变量,比如数组 nums 包含元素 nums0 和 nums1 等,而链表是由多个独立的节点对象组成的。我们通常将头节点当作链表的代称,比如以上代码中的链表可记作链表 n0 。
2 插入节点
在链表中插入节点非常容易。如图所示,假设我们想在相邻的两个节点 n0 和 n1 之间插入一个新节点 P ,则只需改变两个节点引用(指针)即可,时间复杂度为O(1)。
相比之下,在数组中插入元素的时间复杂度为O(n),因为数组的每个元素都需要移动。在大数据量下的效率较低。
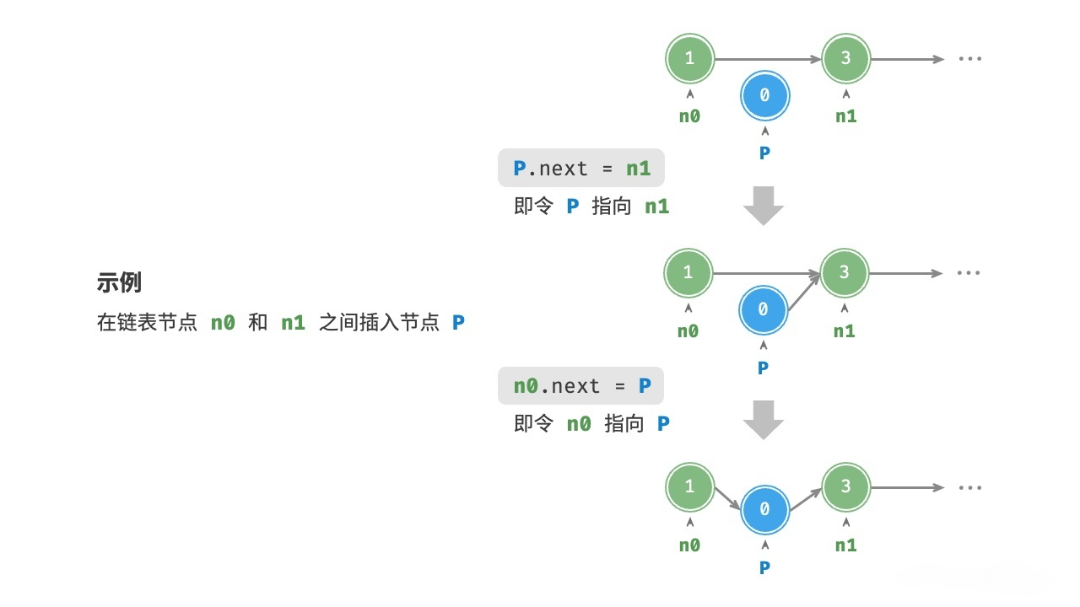
c++代码如下:
cpp
/* 在链表的节点 n0 之后插入节点 P */
void insert(ListNode *n0, ListNode *P) {
ListNode *n1 = n0->next;
P->next = n1;
n0->next = P;
}java代码如下:
java
/* 在链表的节点 n0 之后插入节点 P */
void insert(ListNode n0, ListNode P) {
ListNode n1 = n0.next;
P.next = n1;
n0.next = P;
}3 删除节点
在链表中删除节点也非常方便,只需改变一个节点的引用(指针)即可。
请注意,尽管在删除操作完成后节点 P 仍然指向 n1 ,但实际上遍历此链表已经无法访问到 P ,这意味着 P 已经不再属于该链表了。
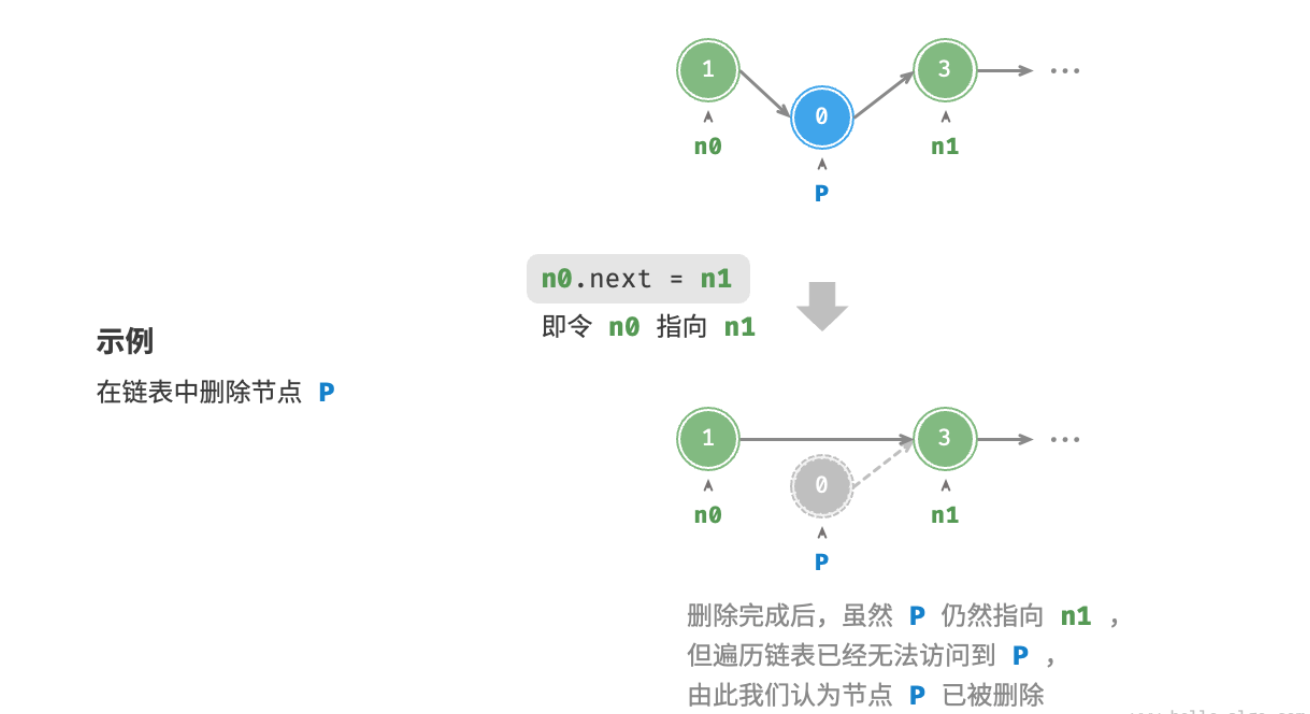
c++代码如下:
cpp
/* 删除链表的节点 n0 之后的首个节点 */
void remove(ListNode *n0) {
if (n0->next == nullptr)
return;
// n0 -> P -> n1
ListNode *P = n0->next;
ListNode *n1 = P->next;
n0->next = n1;
// 释放内存
delete P;
}java代码如下:
java
/* 删除链表的节点 n0 之后的首个节点 */
void remove(ListNode n0) {
if (n0.next == null)
return;
// n0 -> P -> n1
ListNode P = n0.next;
ListNode n1 = P.next;
n0.next = n1;
}4 访问节点
在链表中访问节点的效率较低。我们可以在O(1)时间下访问数组中的任意元素。链表则不然,程序需要从头节点出发,逐个向后遍历,直至找到目标节点。也就是说,访问链表的第i个节点需要循环i-1轮,时间复杂度为O(n)。
c++代码如下:
cpp
/* 访问链表中索引为 index 的节点 */
ListNode *access(ListNode *head, int index) {
for (int i = 0; i < index; i++) {
if (head == nullptr)
return nullptr;
head = head->next;
}
return head;
}java代码如下:
java
/* 访问链表中索引为 index 的节点 */
ListNode access(ListNode head, int index) {
for (int i = 0; i < index; i++) {
if (head == null)
return null;
head = head.next;
}
return head;
}5 查找节点
遍历链表,查找其中值为 target 的节点,输出该节点在链表中的索引。此过程也属于线性查找。
c++代码如下:
cpp
/* 在链表中查找值为 target 的首个节点 */
int find(ListNode *head, int target) {
int index = 0;
while (head != nullptr) {
if (head->val == target)
return index;
head = head->next;
index++;
}
return -1;
}java代码如下:
java
/* 在链表中查找值为 target 的首个节点 */
int find(ListNode head, int target) {
int index = 0;
while (head != null) {
if (head.val == target)
return index;
head = head.next;
index++;
}
return -1;
}数组 vs 链表
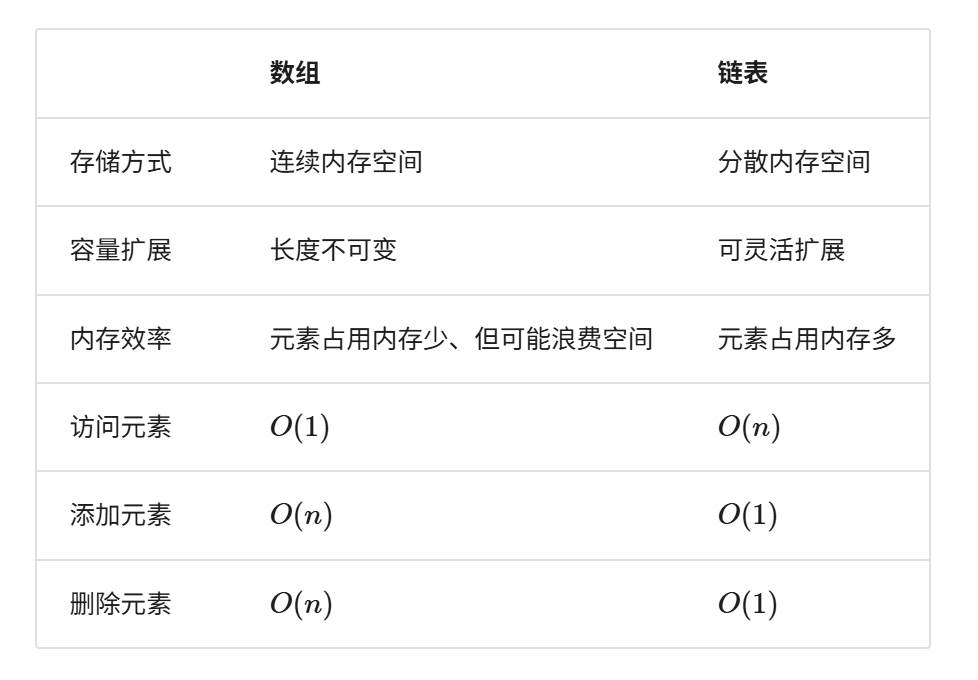
下图总结了数组和链表的各项特点并对比了操作效率。由于它们采用两种相反的存储策略,因此各种性质和操作效率也呈现对立的特点。