量化是一种关键策略,用于优化大型机器学习模型(特别是深度神经网络),使其在资源受限的硬件(如移动设备、边缘设备,或为了云端的快速推理)上部署得更加高效。
什么是量化?
量化是指降低 用于表示模型参数(权重)和激活值的数值精度 的过程。
它不再使用 32 位浮点数(FP32),而通常采用更低精度的格式,例如 16 位浮点(FP16)、8 位整数(INT8)甚至更低。
把 FP32 → INT8/INT4/FP4 等低 bit 类型。
什么要对大型模型进行量化?
大型模型(LLMs)在推理过程中会消耗大量的内存和计算资源。而量化之后的模型可以实现以下功能:
- 缩小模型体积: 低精度数值占用更少内存。
- 加速推理: 许多硬件加速器(CPU、GPU、NPU)对低精度数据的处理速度更快,因为定点运算相比浮点运算通常更简单、更快。
- 降低功耗: 由于量化后的数据占用的存储空间更小,计算量和内存访问减少,能耗随之降低。
- 实现边缘部署: 许多硬件设备(如专用的 AI 芯片、GPU 等)对低精度计算提供了专门的硬件优化,可以高效地处理量化后的神经网络运算,因此可以在资源受限的设备上运行大型模型。
量化原理
量化的基本原理,即把模型的参数(weights)等从浮点数(如float32)转换为定点数(如int8)。在计算时,再将定点数据反量化回浮点数据。
量化的两个重要过程,一个是量化(Quantize),另一个是反量化(Dequantize):
- 量化就是将浮点型实数量化为整型数(FP32->INT8)
- 反量化就是将整型数转换为浮点型实数(INT8->FP32)
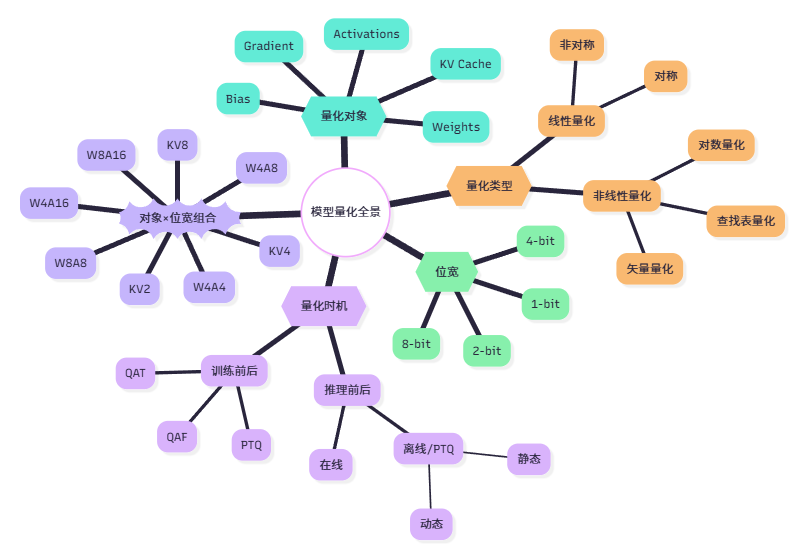
量化类型(Quantization Type)
那么具体是如何转换数值的呢?通常有以下两种转换方式:
| 类型 | 子类 | 特点与适用场景 |
|---|---|---|
| 线性量化 | 对称量化 | 零点为0,适合权重,计算高效,硬件友好。 |
| 非对称量化 | 引入零点(zero-point),适合激活值,精度高但计算复杂。 | |
| 非线性量化 | --- | 如对数量化、矢量量化、查找表量化等,适用于极端压缩或非均匀分布数据。 |
不同的方法使用不同的量化公式,得到不同的量化参数:
- ⚖️scale
- 0️⃣zero-point
具体的会在数学篇进行介绍(先挖一个坑,后面填吧)
量化策略(Quantization Strategies)
训练前后
从训练视角来看,我们可以在模型的训练前或训练后进行量化,据此可以分为以下几种:
| 策略 | 阶段 | 是否需要重训练 | 精度 | 适用 |
|---|---|---|---|---|
| PTQ (Post-Training Quant.) | 训练后 | ❌ | 稍低 | 快速部署 |
| QAT (Quant.-Aware Training) | 训练中 | ✅ | 高 | 极致精度 |
| QAF (Quant.-Aware Fine-tuning) | 微调阶段 | ✅ | 中高 | 资源有限 |
1.训练后量化(PTQ) :在不重新训练的情况下,对已训练好的模型进行量化。
2.量化感知训练(QAT):在训练过程中模拟量化,并更新量化参数。
- 通常比 PTQ 精度更高,特别适用于大型或复杂模型。
- 计算开销更大,因为需要重新训练。
3.量化感知微调(QAF):从一个已训练好的 FP32 模型出发,在模拟量化的同时进行少量微调,使权重适应低比特表示。
- 在 PTQ 与完整 QAT 之间取得折中:比从头训练快得多,但通常比 PTQ 恢复更多精度------尤其当原始 PTQ 出现明显下降时。
推理前后
从推理视角来看,根据量化过程在推理前后,可以分为:
| 分类 | 说明 | 子类 | 子类说明 |
|---|---|---|---|
| 离线 | 推理前量化 | 静态 | 用校准集一次性算好量化参数 |
| 动态 | 每次前向实时算激活值 | ||
| 在线 | 推理时量化 | --- |
1.离线量化 :上线前完成全部量化,即提前确定好激活值的量化参数 S 和 Z ,在推理时直接使用。
- 比如之前我们提到PTQ,是离线量化里最常见的实现方式。在大多数情况下,离线量化指的就是PTQ。
离线量化 ≈ PTQ(Post-Training Quantization)
-
离线量化又可以细分为:
- 静态量化 (Static Quantization):同时量化权重和激活值,推理前用校准数据集一次性算好量化参数。
因为属于离线量化之PTQ,所以也叫静态离线量化(PTQ-Static)
- 动态量化 (Dynamic Quantization):仅量化权重,激活值在推理时实时量化。
因为属于离线量化之PTQ,所以也叫动态离线量化(PTQ-Dynamic)
2.在线量化 :推理时才量化,即在推理过程中动态计算量化参数 S(scale) 和 Z(zero-point) 。
量化对象和量化层级
根据量化的对象的不同,可以分为不同的层级:
- 权重量化(Weight Quantization): 仅量化模型权重。
因为只量化权重,也称为weight-only quantization
- 激活量化(Activation Quantization): 也对各层输出(激活值)进行量化。
- 梯度量化(Gradient Quantization): 训练时对梯度进行量化以减少通信开销。
- KV缓存量化(KV Cache Quantization): 对注意力中的KV缓存进行量化以降低显存占用。
- 偏置量化(Bias Quantization): 有时也对偏置进行量化,但通常保持较高精度。
也就是说,在模型量化过程中,量化可以应用于模型的多个部分,包括:
- 模型参数(weights):如权重矩阵,这些是模型训练过程中学习到的参数。
- 激活值(activations):如神经元的输出值,这些值在前向传播过程中动态生成。
- 梯度(gradient):如反向传播过程中计算的梯度值,用于更新模型参数。
- KV Cache:在 Transformer 的自回归解码阶段,KV Cache 用于缓存每一层的键(Key)和值(Value)张量,以避免重复计算,从而显著提升长序列生成的效率。
- 偏置(Bias) :指模型中各层加性偏置项(如线性层、卷积层后的 bias)。由于偏置参数量远小于权重(百万级 vs 十亿级),其对整体模型大小的影响有限,因此通常不量化或仅使用较高精度(如 INT16或 FP16),仅在极端压缩需求下(如边缘设备部署),才考虑与权重一并量化至 INT8。
| 量化对象 | 是否常被量化 | 量化方式举例 | 备注 |
|---|---|---|---|
| 模型参数(weights) | ✅ 是 | INT8/INT4,对称或非对称量化,GPTQ/AWQ 等 | 直接决定模型大小与推理速度 |
| 激活值(activations) | ✅ 是 | 动态或静态量化,per-token/per-tensor | 显著降低显存,需校准分布误差 |
| 梯度(gradient) | ✅/❓ 可选 | 2--8 bit 均匀量化,Top-K 稀疏化 | 主要用于训练加速与分布式通信压缩 |
| KV Cache | ✅ 是 | INT8/INT4,混合精度保留关键 token | 显著降低显存,提升吞吐 |
| Bias | ❌ 通常否 | 保留为 FP16/INT16,极端场景下低比特量化 | 参数量小,量化收益低 |
量化粒度(Granularity)
| 粒度 | 解释 | 适用对象 |
|---|---|---|
| per-tensor / per-layer | 整层共享一个 scale & zero-point | 通用 |
| per-channel | 每个输出通道各自 scale | 权重 |
| per-token | 每个 token(行)各自 scale | 激活 |
| per-group / sub-channel | 每连续 N 个元素为一组 scale | 权重/激活 |
- 逐层量化(per-tensor):整个层的所有权重使用相同的缩放因子 S 和偏移量 Z 。
- 逐通道量化(per-channel):每个通道单独使用一组 S 和 Z 。
- 逐组量化(per-group):将权重按组划分,每个组使用一组 S 和 Z 。
- 逐 token 量化(per-token) :对输入序列中的 每一个 token(即矩阵的每一行) 单独计算并使用一组缩放因子 S 和偏移量 Z。
量化位宽
根据存储一个权重元素所需的位数,可以分为8bit量化、4bit量化、2bit量化和1bit量化。
| 位宽 | 特点与适用场景 |
|---|---|
| 8-bit | 最常用,精度损失小,广泛支持(INT8/FP8)。 |
| 4-bit | 极限压缩,适合大模型部署(如 AWQ、GPTQ)。 |
| 2-bit | 极端压缩,精度损失大,需配合误差补偿机制。 |
| 1-bit | 极限压缩,仅限特定任务或研究使用(如 BNN)。 |
对象×位宽组合
根据量化对象和量化位宽的不同组合,可以分为:
| 方案 | 组合名 | 含义 | 示例 |
|---|---|---|---|
| 仅权重 | W8A16 | 权重8bit,激活16bit(未量化,保持原精度) | |
| W4A16 | 权重4bit,激活16bit(未量化,保持原精度) | ||
| 权重+激活 | W8A8 | 权重8bit,激活8bit | SmoothQuant、ZeroQuant |
| W4A8 | 权重4bit,激活8bit | QoQ | |
| W4A4 | 权重4bit,激活4bit | Atom、QuaRot、OmniQuant | |
| KV Cache | KV8 | KV缓存8bit | LMDeploy、TensorRT-LLM |
| KV4 | KV缓存4bit | Atom、QuaRot、QoQ | |
| KV2 | KV缓存2bit | KIVI、KVQuant |
Summary
根据以上介绍的所有内容,为了方便理解记忆总结了一张图: