在当今数字化商业浪潮中,数据无疑是企业的核心资产,而流量数据更是电商巨头京东业务运转的关键驱动力。它广泛应用于搜索推荐、广告投放等多个核心业务场景,直接影响着用户体验和商业效益。但随着业务规模的不断膨胀,传统架构在处理流量数据时逐渐力不从心,升级架构迫在眉睫。本文将深入剖析京东流量资产架构从 Lambda 架构迈向湖仓一体架构的变革之旅,包括面临的挑战、创新的解决方案、显著的收益以及未来的发展方向。
今天的介绍会围绕下面四点展开:
-
背景与痛点
-
挑战与优化
-
收益与表现
-
总结与展望
01背景与痛点
京东早期采用 Lambda 架构,在处理流量数据时,构建了离线和实时两条独立的处理链路。在实时链路中,数据经埋点采集服务裁剪解析后,进入消息队列,再由 Flink 实时加工处理,供下游业务实时使用;离线链路则将全量数据存储到对象存储,后续通过 Hive 加工,为下游业务提供离线数据分析支持。
这种架构虽然能提供不同时效的数据服务,但弊端明显。计算资源方面,两条链路独立运转,导致计算资源双倍消耗,开发和维护成本也随之翻倍。存储和计算架构异构,使得实时流数据和离线表数据常常无法对齐,存在数据差距,下游用户在使用数据时,需要花费大量时间和精力排查解决数据不一致问题,使用体验较差。
此外,为优化离线链路时效,采用小时级加工替代 T+1 批处理,却引入了数据冗余存储和多次拷贝的问题,进一步增加了存储和计算成本。而且,流量数仓 GDM 层 T+1 数据时效在日常通常为凌晨两点,面对复杂的内部业务场景,下游计算处理时间紧张,数据的 SLA(数据可用性保证)难以保障,在大促或流量高峰期,问题更加突出,严重影响业务决策的及时性和准确性。
为解决 Lambda 架构的痛点,京东引入湖仓一体架构。湖仓架构具有诸多特性,如支持数据更新、存储分离,能处理结构化和非结构化等多种数据类型。在流量资产场景中,其端到端的分钟级能力、支持事务保障数据读写一致性、MVCC(多版本并发控制)提供轻量级时间旅行能力以及数据重新布局降低存储和查询成本等特性,发挥了关键作用。
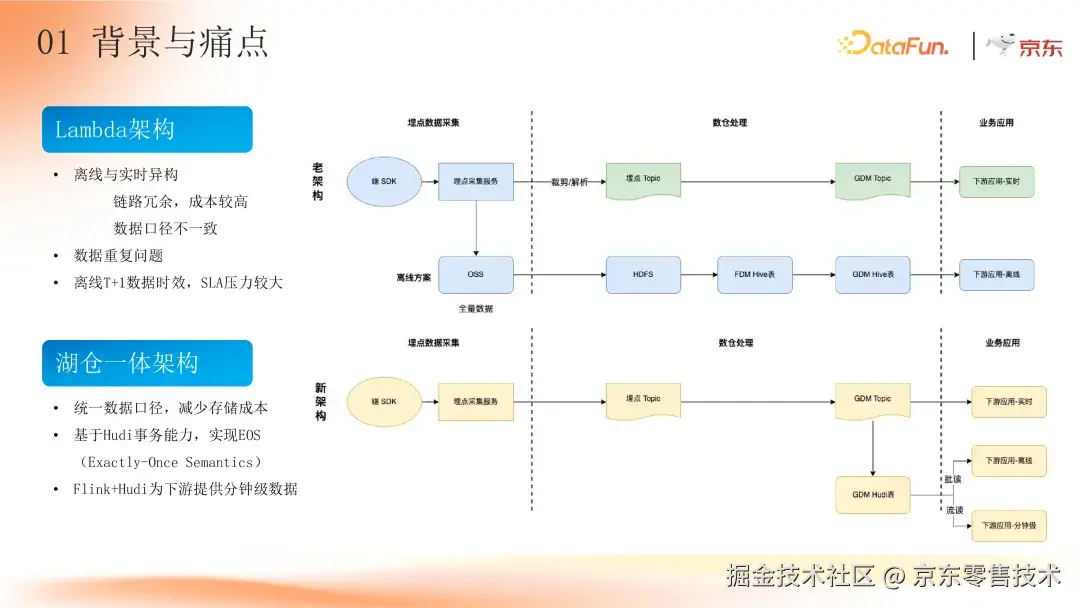
在新架构下,数据经埋点采集服务进入消息队列,由 Flink 实时加工后实时写入湖表。湖表数据既能满足下游业务分钟级时延的实时需求,也可供下游业务通过批读方式进行离线处理。新架构将两条链路收敛为一条,统一了数据口径,减少了存储成本。基于 Hudi 的事务能力,实现了数据处理的 EOS(Exactly-Once Semantics,精确一次语义),确保数据处理的准确性和完整性。Flink 与 Hudi 的技术组合,为下游业务提供了近实时的精准数据,有力地支持了业务的高效运营。
02挑战与优化
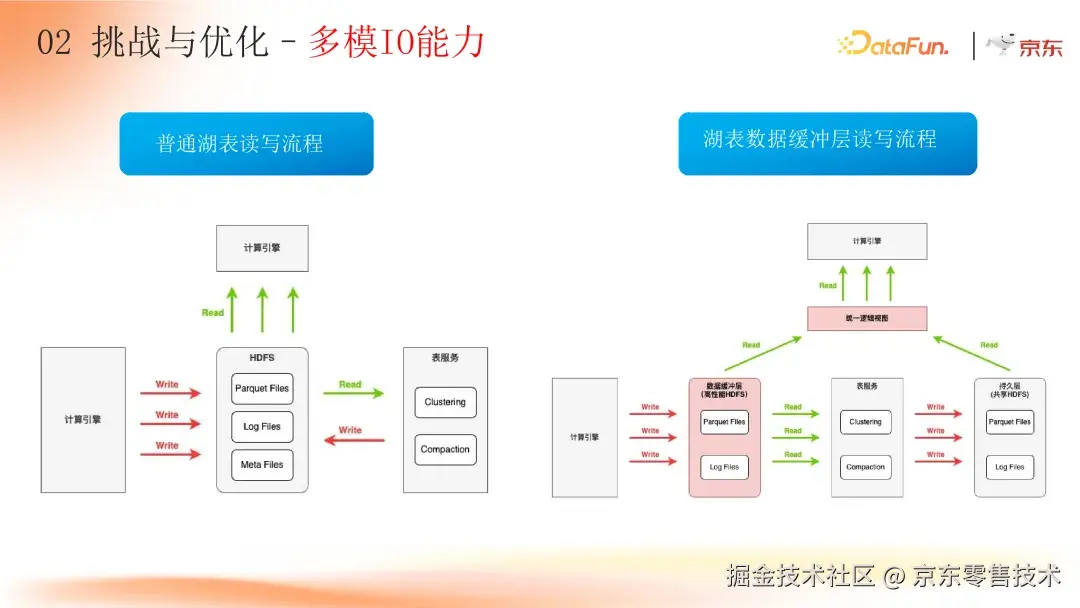
1. 多模 IO 能力优化:突破写入性能瓶颈
在 Flink 实时写入 Hudi 的过程中,某些 HDFS 集群在热点时段繁忙度高,导致 Flink 写入任务频繁出现 timeout 重试,甚至作业失败重启,严重限制了写入性能。单纯扩充 Flink 资源,对性能提升效果不佳。
京东自研多模 IO 能力,将湖表物理存储划分为缓冲层和持久层。创新性地设计统一的 IO 抽象层和 Hudi 逻辑表视图,底层存储可插拔集成多种介质,如 HDFS、OSS、Kafka、HBase、Redis 等。热数据先写入以高性能 HDFS 为基础的缓冲层,后续通过 Hudi 的 Clustering、Compaction 表服务将数据搬运到共享 HDFS 持久层。
开启数据缓冲层后,Flink 实时入湖任务的写入均值速率和稳定性显著提升。对比测试显示,写入吞吐提升 104%,checkpoint 平均完成时间减少 95%,作业异常失败次数大幅降低,稳定性提升 97%,有效解决了写入性能和任务稳定性问题。
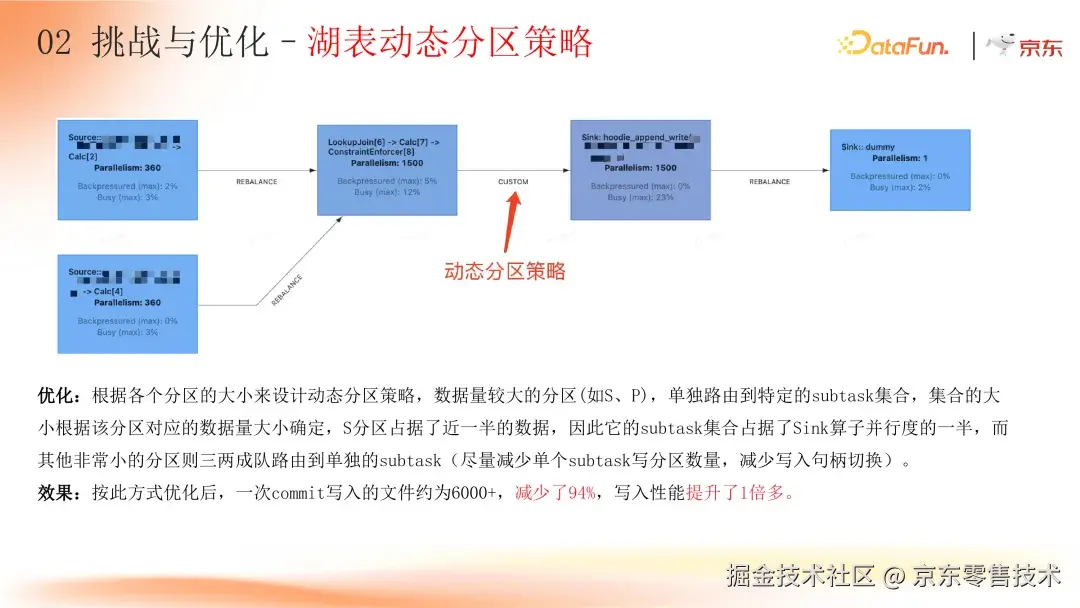
2. 湖表动态分区策略:应对数据倾斜难题
业务分区数据倾斜严重,最大分区与最小分区数据量相差达 730 万倍。若直接写入湖表,会产生大量小文件,给 HDFS 存储和后续处理带来巨大压力,同时单个 subtask 写多个分区文件,频繁切换文件柄也会消耗大量性能。
京东在 Flink 流写 Hudi 的核心拓扑链路上,新增自定义 Partitioner 策略。根据分区大小设计动态分区方案,数据量大的分区(如 S 分区)单独路由到特定的 subtask 集合,集合大小依据分区数据量确定;小分区则三两成组路由到其他单独的 subtask。优化后,一次 commit 写入文件数从约 10.8 万个减少到 6000 多个,减少了 94%,写入性能提升一倍多,有效缓解了数据倾斜和小文件问题。
3. 多写并发 Append:突破流量增长瓶颈
随着流量数据量持续增长,尤其是大促期间数据量骤增,Flink 机房资源有限,单个 Flink 集群即使扩容也会出现性能瓶颈。
京东将入湖任务拆分,利用湖的多写能力并发 Append 同一张流量湖表。例如,将数据量大的 S、P 分区拆分成一个任务,非 S、P 分区拆分成另一个任务。在拆分过程中,解决了检查点元数据冲突和 Hive 元数据同步冲突等问题。通过在每个任务的检查点元数据目录维护各自元数据信息,确保任务失败时可回滚恢复;每个作业维护自己的 last_commit_time 标识,避免分区缺失问题,实现了轻量级并发 Append,提升了实时入湖任务的写入性能。

4. 反序列化优化:降低行级反序列化成本
新架构采用 JSON 数据格式,且比旧架构多了 120 多个字段,行级反序列化成本高,成为任务性能瓶颈。
京东采取两项优化措施。一是将反序列化操作从 source 算子中抽离,source 算子仅负责从 Kafka 拉取字节级消息数据,通过注册专门的反序列化 lookup table 执行反序列化操作,并扩展该算子并行度提升读取性能。二是在拆分任务时,将消息业务域字段写入 Kafka 消息 header 中,拆分后的任务只需解析 header 过滤数据,避免反序列化整条消息,有效降低了反序列化开销。

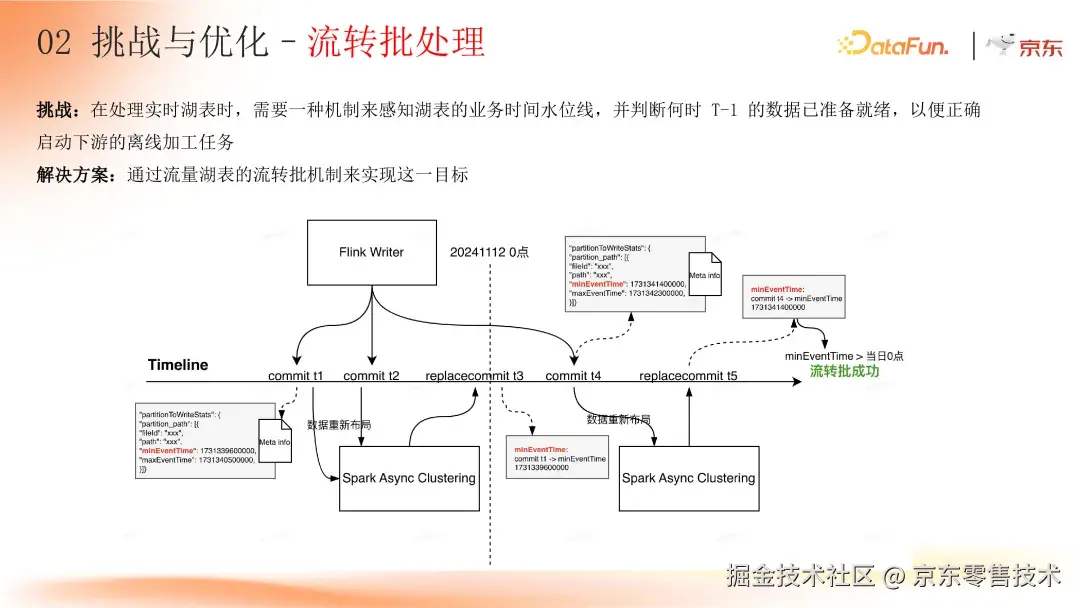
5. 流转批处理:精准调度离线任务
在处理实时湖表时,需要一种机制感知湖表业务时间水位线,判断 T-1 数据是否准备就绪,以启动下游离线加工任务。
京东通过流量湖表的流转批机制实现这一目标。改造 Flink Hudi writer,使其将业务时间写入元数据,流转批服务定期扫描湖表元数据中的业务水位线。当所有分区水位线最小值超过 T 日零点,且对应的 Clustering 表服务合并完成时,表明 T-1 数据准备就绪,下游离线任务即可调度运行,确保了离线任务调度的准确性和及时性。
03显著成效:湖仓架构升级的收益
1. 数据时效性飞跃
湖仓一体架构升级后,数据时效性从 T+1 提升到 15 分钟,SLA 从凌晨两点半提前到零点半。数据量越大,SLA 提升越明显,为下游业务提供了更充裕的处理时间,极大地提高了业务响应速度和决策效率。
2. 存储成本降低
基于社区 Clustering 能力,实现分区级 30 分钟数据全局排序与合并,提升了数据压缩率,存储数据量从每天 120TB 优化到 50TB,存储成本降低 58.3%。在流量数据增长 60% 的情况下,每年节省两千多万元,有效节约了企业运营成本。
3. 大促表现卓越
在去年双 11 大促期间,面对流量洪峰,最大流量曝光模型总量同比增长 80%,均值达每分钟 4.5 亿。新架构首次实现流量数据全时间段平稳运行且无延迟,SLA 更加稳定,T+1 GDM 层流量数据全部就绪时间从 6 点 03 分提前到 0 点 54 分,提前了 5 个小时,有力保障了大促期间业务的稳定高效运行。
04 未来展望:持续创新的方向
1. 探索生产环境大规模流读
目前,流量数据资产下游业务主要以批读方式为主,流读在生产环境中尚未大规模验证。未来,京东将重点关注流读数据的稳定性、处理性能和数据完整性。当前已在流读方面进行了部分完善,如支持更细粒度的限速、灵活的数据分发策略、多写场景下的流读功能,并丰富了 metric 指标用于监控,后续将进一步探索和优化,推动流读在生产环境中的大规模应用。
2. 追求 Hudi 秒级实时处理
数据入湖时,写入速度较慢,通常为分钟级提交。京东计划扩展湖表多模 IO 能力,将数据写入 Kafka、HBase、Redis 等高速存储中,并在湖表元数据记录高速存储的位点和 key 等元信息。读取时,将持久存储与高速存储内容联合,实现 Hudi 的秒级时延,进一步提升数据处理的实时性。
京东流量资产湖仓一体架构的升级实践,成功解决了传统架构的诸多问题,取得了显著的成效。未来,京东将继续在流读和实时处理等方面深入探索创新,不断挖掘流量数据的价值,为业务发展注入强大动力,也为行业数据架构的发展提供了宝贵的借鉴经验。