深度学习软件
(这一部分去看tensorflow和pytorch的笔记)
(见专栏)
-
tensorflow和pytorch区别
tensorflow,我们先构建显示的图,然后重复运行它
pytorch,我们每次做前向传播时,都构建一个新的图
卷积神经网络CNN 结构
-
LeNet-5
比较经典的用于数字识别的cnn
pythonfrom torch import nn import torch from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Tanh class LeNet(nn.Module): def __init__(self): super(LeNet,self).__init__() self.model1 = nn.Sequential( #input:32x32x1 #conv1:28x28x6 Conv2d(1, 6, 5, 1, 0), Tanh(), #poo1:14x14x6 MaxPool2d(2, 2), #conv2:10x10x16 Conv2d(6,16,5,1,0), Tanh(), #poo2:5x5x16 MaxPool2d(2,2), Flatten(), Linear(400,120), Tanh(), Linear(120,84), Tanh(), Linear(84,10) ) def forward(self,x): x = self.model1(x) return x lenet = LeNet() -
AlexNet
很小的计算量,但是耗费存储也很多,比较低的acc
但是,实际上AlexNet 的输入图片尺寸为 224×224(这里是227×227)
pythonimport torch from torch import nn from torch.nn import Flatten, Linear class AlexNet(nn.Module): def __init__(self): super(AlexNet,self).__init__() self.model1 = nn.Sequential( #input:227x227x3 #conv1:55x55x96 nn.Conv2d(3,96,11,4,0), #pool1:27x27x96 nn.MaxPool2d(3,2), nn.ReLU(), #conv2:27x27x256 nn.Conv2d(96,256,5,1,2), #pool2:13x13x256 nn.MaxPool2d(3,2), nn.ReLU(), #conv3:13x13x384 nn.Conv2d(256,384,3,1,1), #conv4:13x13x384 nn.Conv2d(384,384,3,1,1), #conv5:13x13x256 nn.Conv2d(384,256,3,1,1), #pool3:6x6x256 nn.MaxPool2d(3,2), nn.Flatten(), #9216=6x6x256 nn.Linear(9216,4096), nn.Linear(4096,1000), nn.Linear(1000,10) ) def forward(self,x): x = self.model1(x) return x alexnet = AlexNet() -
ZFNet
注意:计算输出图尺寸是下取整(输入尺寸-卷积核尺寸+2*padding)/stride + 1
pythonimport torch from torch import nn class ZFNet(nn.Module): def __init__(self): super(ZFNet,self).__init__() self.model1 = nn.Sequential( #input:224x224x3 #conv1:110x110x96 nn.Conv2d(3,96,7,2,1), #pool1:55x55x96 nn.MaxPool2d(3,2), #conv2:26x26x256 nn.Conv2d(96,256,5,2,0), #pool2:13x13x256 nn.MaxPool2d(3,2), #conv3:13x13x384 nn.Conv2d(256,384,3,1,1), #conv4:13x13x384 nn.Conv2d(384,384,3,1,1), #conv5:13x13x256 nn.Conv2d(384,256,3,1,1), #pool5:6x6x256 nn.MaxPool2d(3,2), nn.Flatten(), #6*6*256 nn.Linear(6*6*256,4096), nn.Linear(4096,4096), nn.Linear(4096,1000) ) def forward(self,x): x = self.model1(x) return x zfnet = ZFNet() -
VGGNet
耗费最高的存储,最多的操作
pythonimport torch from torch import nn class VGG16Net(nn.Module): def __init__(self): super(VGG16Net,self).__init__() self.model1 = nn.Sequential( #input:224x224x3 nn.Conv2d(3,64,3,1,1), nn.Conv2d(64,64,3,1,1), nn.MaxPool2d(2,2), nn.Conv2d(64,128,3,1,1), nn.Conv2d(128,128,3,1,1), nn.MaxPool2d(2,2), nn.Conv2d(128,256,3,1,1), nn.Conv2d(256,256,3,1,1), nn.Conv2d(256,256,3,1,1), nn.MaxPool2d(2,2), nn.Conv2d(256,512,3,1,1), nn.Conv2d(512, 512, 3, 1, 1), nn.Conv2d(512, 512, 3, 1, 1), nn.MaxPool2d(2,2), nn.Conv2d(512,512,3,1,1), nn.Conv2d(512, 512, 3, 1, 1), nn.Conv2d(512, 512, 3, 1, 1), nn.MaxPool2d(2,2), nn.Flatten(), nn.Linear(7*7*512,4096), nn.Linear(4096,4096), nn.Linear(4096,1000) ) def forward(self,x): x = self.model1(x) return x vgg16 = VGG16Net() -
GoogLeNet
最高效
efficient Inception module:设计一个良好的本地网络拓扑结构(网络中的网络)然后将这些模块堆叠在彼此之上
没有全连接层
对来自前一层的输入应用并行filter操作
但是这样就会计算的很复杂,解决办法:采用1x1卷积来降低特征深度的"瓶颈"层
四个并行分支:1x1 卷积、1x1→3x3 卷积、1x1→5x5 卷积、3x3 池化→1x1 卷积实现:
pythonclass Inception(nn.Module): """Inception模块:并行处理不同尺度的特征""" def __init__(self, in_channels, c1, c2, c3, c4): super(Inception, self).__init__() # 分支1:1x1卷积(降维或保持维度) self.branch1 = nn.Sequential( Conv2d(in_channels, c1, kernel_size=1), BatchNorm2d(c1), ReLU(inplace=True) ) # 分支2:1x1卷积(降维)-> 3x3卷积 self.branch2 = nn.Sequential( Conv2d(in_channels, c2[0], kernel_size=1), BatchNorm2d(c2[0]), ReLU(inplace=True), Conv2d(c2[0], c2[1], kernel_size=3, padding=1), BatchNorm2d(c2[1]), ReLU(inplace=True) ) # 分支3:1x1卷积(降维)-> 5x5卷积 self.branch3 = nn.Sequential( Conv2d(in_channels, c3[0], kernel_size=1), BatchNorm2d(c3[0]), ReLU(inplace=True), Conv2d(c3[0], c3[1], kernel_size=5, padding=2), BatchNorm2d(c3[1]), ReLU(inplace=True) ) # 分支4:3x3池化 -> 1x1卷积(降维) self.branch4 = nn.Sequential( MaxPool2d(kernel_size=3, stride=1, padding=1), # 保持尺寸的池化 Conv2d(in_channels, c4, kernel_size=1), BatchNorm2d(c4), ReLU(inplace=True) ) def forward(self, x): # 四个分支的输出在通道维度拼接 b1 = self.branch1(x) b2 = self.branch2(x) b3 = self.branch3(x) b4 = self.branch4(x) return torch.cat([b1, b2, b3, b4], dim=1) # dim=1表示通道维度拼接 -
ResNet
模型效率中等,准确度最高
使用残差连接的非常深的网络(152层)
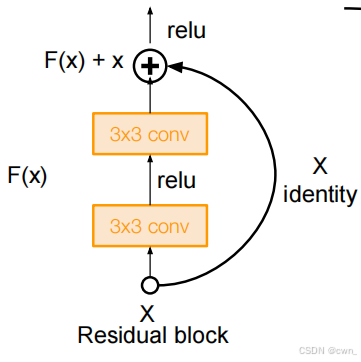
这是ResNet(残差网络)中最基础的 残差块(Residual Block) 结构示意图,用来解决深度神经网络训练时的梯度消失、模型难以收敛问题,核心是 "残差连接(跳跃连接)"设计。
下面拆解每个部分:
-
基础流程(从下往上看)
- 输入
X: 代表网络某一层的输入特征(比如是图像经过前面卷积后的特征图,包含空间维度和通道维度)。 - 主路径(计算
F(X)): - 先过一个3x3 conv(3×3 卷积层),接着relu(ReLU 激活函数),再过第二个3x3 conv。这一系列操作对输入X做特征变换,输出F(X)(F表示"残差函数",学习输入与输出的残差关系 )。 - 残差连接(
X直接跳连): 输入X不经过主路径的卷积,直接"抄近道"加到主路径输出上(图里的⊕是逐元素相加,要求X和F(X)维度匹配 )。 - 前向传播:因为这个分支仅进行简单的恒等映射或少量维度调整操作,计算量小,传播速度更快,虽然X跳连和主路径并行启动计算,但是完成时间有差异,最终会在加法操作处等待最慢的分支完成后再继续传播。
- 反向传播:在残差块反向传播过程中,来自后续层的梯度到达 (F(x) + x) 的加法操作位置时,会按照加法求导规则,同时分配到 "identity" 分支和 (F(x)) 分支。虽然 identity 分支的梯度计算简单,可能先传播到前面的层,但前面的层等待的是两个分支的梯度都传播过来后进行融合。只有当 (F(x)) 分支的梯度也传播过来后,将两个分支的梯度相加,得到总的梯度,才会用于对前面层的参数更新 。
- 输出(
F(X)+X过relu): 相加后的结果F(X)+X再经过一个relu,作为整个残差块的最终输出,传递给下一层。
- 输入
-
核心设计意义
残差连接 - 解决梯度消失:传统深层网络训练时,梯度回传易衰减。残差连接让梯度能"走捷径"直接反向传播,让深层网络更易训练。
学习残差更高效:网络不直接学"从
X到最终输出"的复杂映射,而是学"残差F(X) = 最终输出 - X"。残差通常更简单,模型收敛更快、更稳定。
-
-
其他的一些CNN结构
-
Network in Network (NiN)
带有"微网络"的Mlpconv层,在每个卷积层内部计算局部图像块,更高层次的特征抽象
微网络采用多层感知机(全连接层,即1x1卷积层)
作为GoogLeNet和ResNet "瓶颈层"的前身
-
Identity Mappings in Deep Residual Networks
-
Wide Residual Networks
-
Aggregated Residual Transformations for Deep Neural Networks (ResNeXt)
-
Deep Networks with Stochastic Depth
-
FractalNet: Ultra-Deep Neural Networks without Residuals
采用分形结构设计
-
Densely Connected Convolutional Networks
DenseNet:通过特征拼接增强层间连接
-
SqueezeNet: AlexNet-level Accuracy With 50x Fewer Parameters and <0.5Mb Model Size
-