https://dl.acm.org/doi/pdf/10.1145/3708985
https://www.doubao.com/chat/15495707526837250
Advances and Challenges in Foundation Agents--Memory调研
论文翻译
基于大型语言模型代理的用户行为模拟
摘要
在推荐系统、社交网络等以人为中心的应用中,高质量的用户行为数据模拟一直是一个基础性且具有挑战性的问题。用户行为模拟的主要难点源于人类认知和决策过程的复杂机制。近年来,大量证据表明,通过学习海量的网络知识,大型语言模型(LLMs)能够具备类人智能和泛化能力。受此启发,本文初步探索了在推荐领域使用大型语言模型进行用户行为模拟的潜力。为了让大型语言模型表现得像人类,我们设计了档案、记忆和行动模块来装备它们,构建基于大型语言模型的代理以模拟真实用户。为了实现不同代理之间的交互并观察它们的行为模式,我们设计了一个沙盒环境,在该环境中,每个代理都可以与推荐系统进行交互,不同代理之间可以通过一对一聊天或一对多社交广播与朋友交流。在实验中,我们首先通过主观和客观评估来证明代理生成行为的可信度。然后,为了展示我们方法的潜在应用,我们模拟并研究了两种社会现象:(1)信息茧房;(2)用户从众行为。我们发现,控制推荐算法的个性化程度和提高用户社会关系的异质性可以作为缓解信息茧房问题的两种有效策略,而用户的从众行为会受到其社会关系数量的显著影响。为了推动这一方向的发展,我们已在https://github.com/RUC-GSAI/YuLan-Rec发布了我们的项目。
1 引言
以人为中心的人工智能(AI)致力于推动为人类服务的技术发展,在过去几十年中引起了工业界和学术界的广泛关注。用户行为分析是以人为中心的人工智能的一个基本方面,尤其在推荐系统、社交网络和搜索引擎等应用中。它旨在理解和推断人类的偏好和行为模式,这对于优化用户体验和系统性能至关重要1。用户行为分析的准确性在很大程度上依赖于高质量用户数据的可用性。然而,严格的隐私法规(例如通用数据保护条例)和伦理担忧极大地限制了数据共享的范围。此外,多样化和全面的数据集的有限可用性使得有效开发和评估推荐系统变得困难。这些挑战需要替代方案来获取用户行为数据,特别是那些能够在不违反隐私规范的情况下模拟现实场景的方案2。传统的模拟策略,如数据驱动和模型驱动方法,存在明显的局限性。数据驱动方法虽然具有适应性和准确性,但严重依赖于高质量的真实世界数据,引发了隐私和伦理方面的担忧。另一方面,模型驱动方法需要复杂的规则定义,并且往往无法捕捉现实世界用户行为的动态性和细微差别3。这些局限性凸显了对创新模拟方法的需求,这些方法需要在适应性、可扩展性和真实性之间取得平衡。
近年来,大型语言模型(LLMs)凭借从多样化的网络数据中编码的广泛知识,已成为能够理解和生成类人行为的强大工具4。这种独特的能力使大型语言模型非常适合模拟用户行为,特别是在需要主观决策、动态交互模式和个性化偏好的场景中。与传统方法不同,基于大型语言模型的模拟可以在不依赖敏感用户数据的情况下运行,这使其成为推进隐私保护和可扩展用户行为分析研究的一个有前景的方向。然而,将大型语言模型的能力转移到模拟现实场景中的用户行为并非易事。首先,用户具有多样化的偏好、个性和背景,这使得大型语言模型难以有效模拟不同的用户角色。此外,现实世界中的用户行为是动态互联的,先前的行为会影响后续的行为。由于普通的大型语言模型擅长一次性的静态任务,我们需要设计额外的模块来增强它们处理动态行为的能力。
此外,现实世界场景中的用户行为数量庞大,其中许多是琐碎的,例如"吃早餐"或"刷牙"等日常活动,这些与推荐系统无关。模拟每一个用户行为既不必要也不切实际,因此需要仔细考虑哪些行为应该优先模拟。除了这些单用户挑战之外,设计一个环境和执行协议来有效组织多个用户之间的交互也需要大量的努力。
为了解决上述问题,我们提出了一种新颖的推荐模拟器,称为RecAgent。从用户角度来看,我们用一个基于大型语言模型的自主代理来模拟每个用户,该代理由档案模块、记忆模块和行动模块组成。档案模块可以灵活高效地生成不同的代理档案。记忆模块旨在使用户行为在动态环境中更加一致,用户先前的行为可以存储在记忆中,以影响他们后续的决策。在行动模块中,我们不仅纳入了用户在推荐系统内的行为,如点击和浏览项目,还考虑了朋友聊天和社交广告等外部因素,以更全面地模拟用户决策过程。通过整合所有这些模块,我们旨在实现更一致、合理和可靠的用户行为模拟。从系统角度来看,我们的模拟器最多包含1000个代理。这种配置在现实的大规模模拟需求与实际考虑(如与大型语言模型推理相关的计算时间和资源需求)之间取得了平衡。它以轮次方式执行。在每一轮中,代理根据其预定义的活动水平自主执行操作。为了促进人机协作,我们允许真实人类作为代理在模拟器中参与,并与推荐系统和其他代理进行交互。此外,还可以通过暂停模拟过程、修改代理档案,然后重新运行模拟器来主动干预系统。这种干预对于研究紧急事件的影响、用户反事实行为等方面可能是有益的。
与传统的推荐模拟策略相比,我们的模拟器使用大型语言模型来捕捉用户的决策过程。由于大型语言模型已经学习了全面的网络知识,它们在模拟推荐系统(这是一种典型的网络应用)方面可能更有效。此外,我们的模拟器不需要额外的数据来初始化模拟过程,这使得联合模拟多个场景成为可能。然而,在传统的模拟策略中3,数据驱动方法更具适应性和准确性,但需要真实世界的数据来初始化模拟器,而模型驱动方法需要手动定义复杂的规则,这些规则不具有可扩展性和有效性。
为了评估我们模拟器的有效性,我们从代理和系统两个角度进行了广泛的实验。从代理角度来看,我们首先关注记忆模块的评估,因为它是驱动代理行为的关键。然后,我们对代理进行整体评估,研究它是否能够产生可信的用户行为。从系统角度来看,我们关注模拟效率的评估以及主动干预模拟器是否能产生预期的用户行为。最后,我们通过使用模拟器研究两种现象(1)信息茧房和(2)用户从众行为,展示了模拟器的应用。
总之,本文的主要贡献可以总结如下:
我们开创了在推荐领域使用基于大型语言模型的代理进行用户行为模拟的方向。
作为该方向的初步尝试,我们设计了一个统一的代理框架和多代理环境来模拟真实用户行为。
我们进行了广泛的实验,以证明我们的模拟器所模拟的用户行为的可信度。
我们通过研究信息茧房和用户从众行为现象,展示了我们模拟器的潜力。
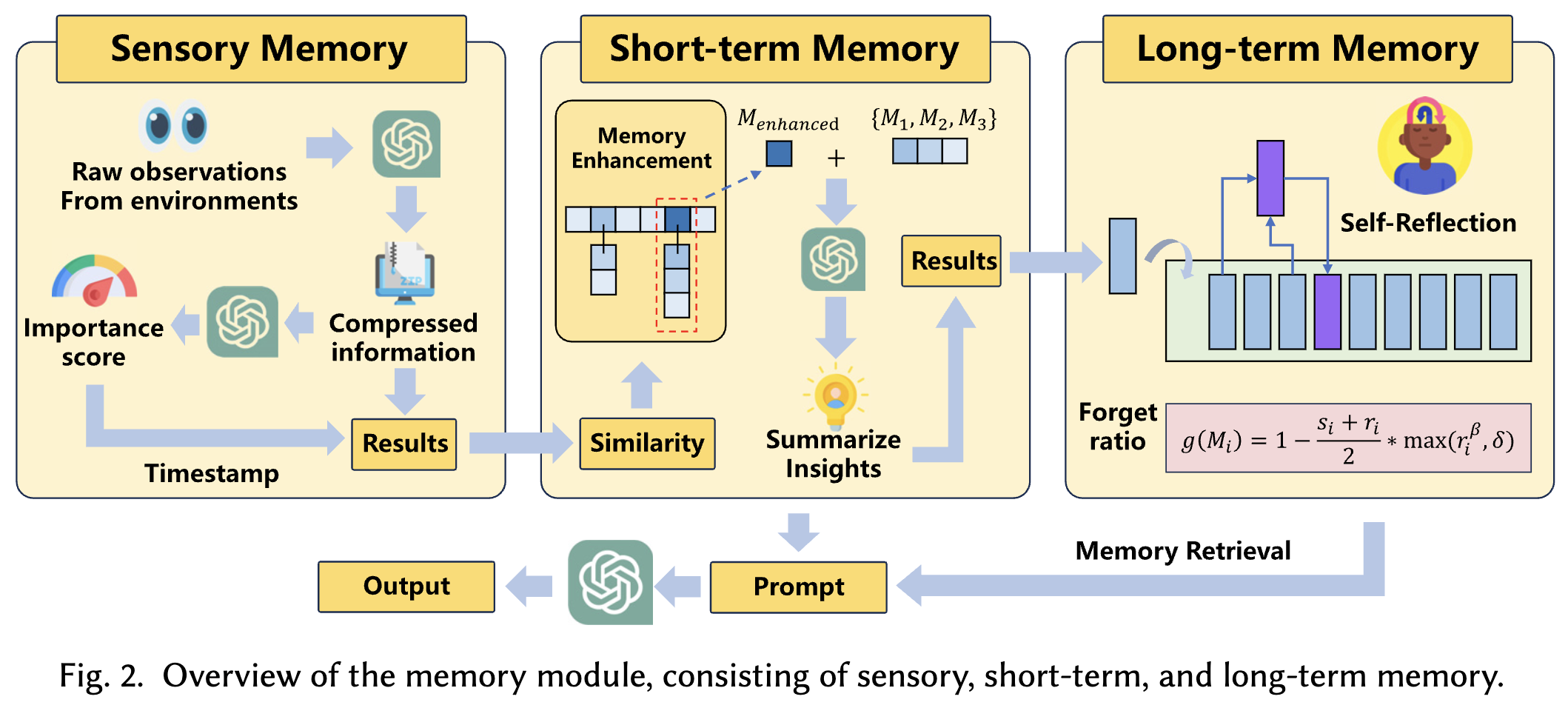
3.1.2 记忆模块
认知神经科学的最新进展63强调了人类记忆的三个关键组成部分:感觉记忆、短时记忆和长时记忆。感觉记忆直接从环境中获取信息,并仅能保留几百毫秒。在此期间,重要信息会被转移到短时记忆,而不太重要的信息则会被丢弃。短时记忆起到桥梁作用,其中的信息可以通过反复接触得到强化,并最终转移到长时记忆中。长时记忆能长时间存储信息,使人类能够根据经验做出决策并产生高级见解。为了准确模拟用户行为,我们基于上述人类记忆机制设计了模拟器的记忆模块,其详细工作原理如图2所示。下面,我们首先详细介绍模拟器中的代理感觉记忆、短时记忆和长时记忆,然后说明它们如何协同工作以完成不同的记忆操作。