1.前言
AI搜索是一种基于人工智能技术的搜索方式,它通过机器学习、自然语言处理、深度学习等技术,提供更智能、个性化和精准的搜索体验。与传统搜索引擎相比,AI搜索在理解用户意图、提供结构化答案、个性化推荐和上下文理解等方面具有显著优势。
AI搜索的核心特点包括:
- 智能理解用户意图:通过自然语言处理(NLP)和深度学习技术,AI搜索能够理解用户的查询意图,提供更精准的答案。
- 个性化推荐:AI搜索能够根据用户的历史行为、兴趣和上下文信息,提供个性化的搜索结果和推荐。
- 多模态信息处理:AI搜索不仅支持文本搜索,还支持图像、语音等多种形式的信息检索。
- 语义搜索:AI搜索超越了传统的关键词匹配,通过语义理解和上下文分析,提供更相关的结果。
AI搜索的应用场景广泛,包括信息检索、内容推荐、企业信息管理、医疗文献检索等。目前,市场上已有多个代表性AI搜索引擎,如Perplexity AI、Microsoft Bing AI、SCOUT SEARCH等。
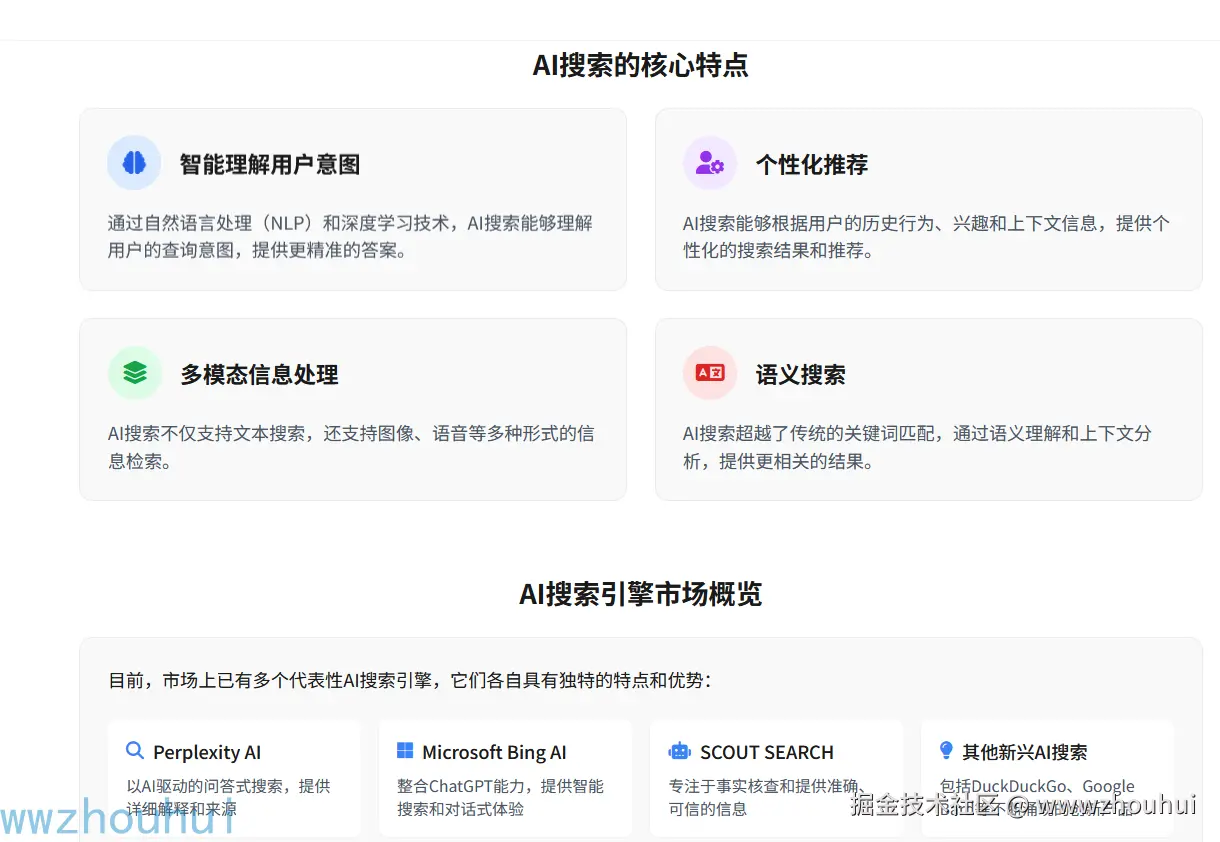
秘塔搜索是我平时用的比较多的一块AI搜索工具,之前有小伙伴给我留言说你文章中的首页的页面是怎么制作的呢?哈哈今天给大家揭晓一下答案,我其实就是用的秘塔AI 搜索生成出来的。
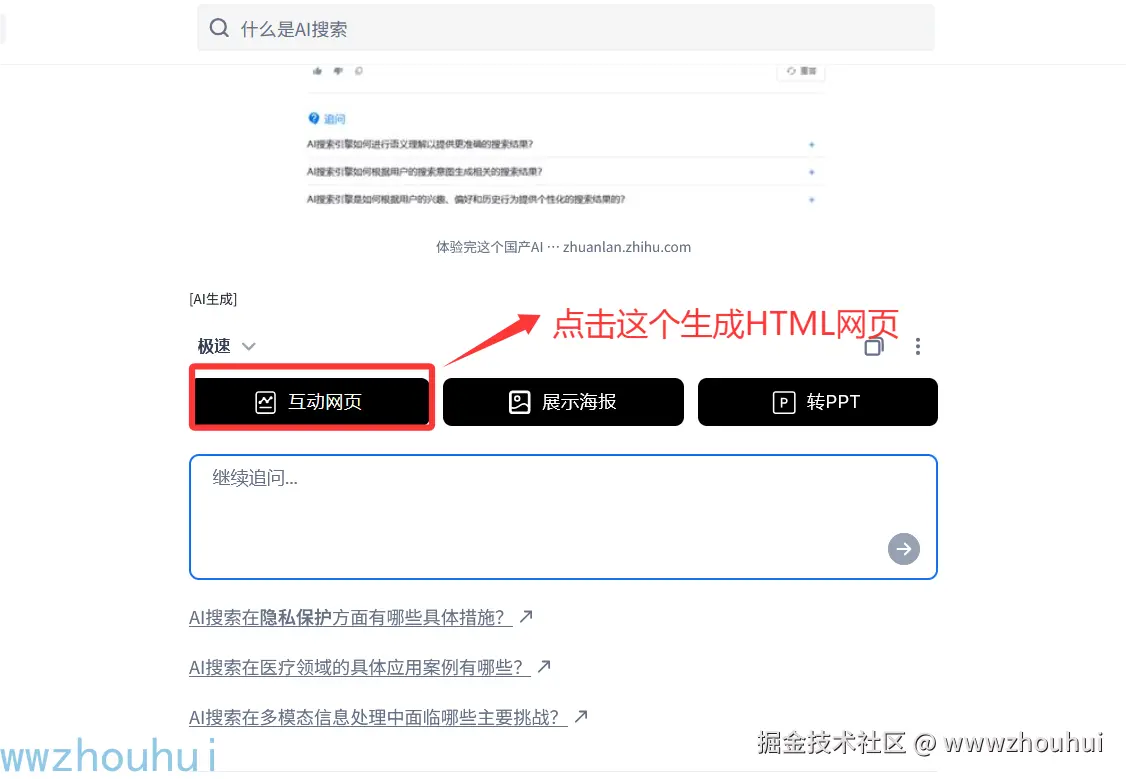
目前秘塔搜索也支持API 调用了,今天就带大家一个看一下基于dify实现的一个秘塔搜索功能的工作流。那么工作流长啥样子呢?
效果如下:
呵呵 效果还不错吧。话不多下面带大家拆解这个工作流是如何制作的。
2.工作流的制作
秘塔API秘钥获取
既然用到秘塔AI搜索,肯定用到他们家的API。我们首选需要登录注册metaso.cn。访问 metaso.cn/search-api/...
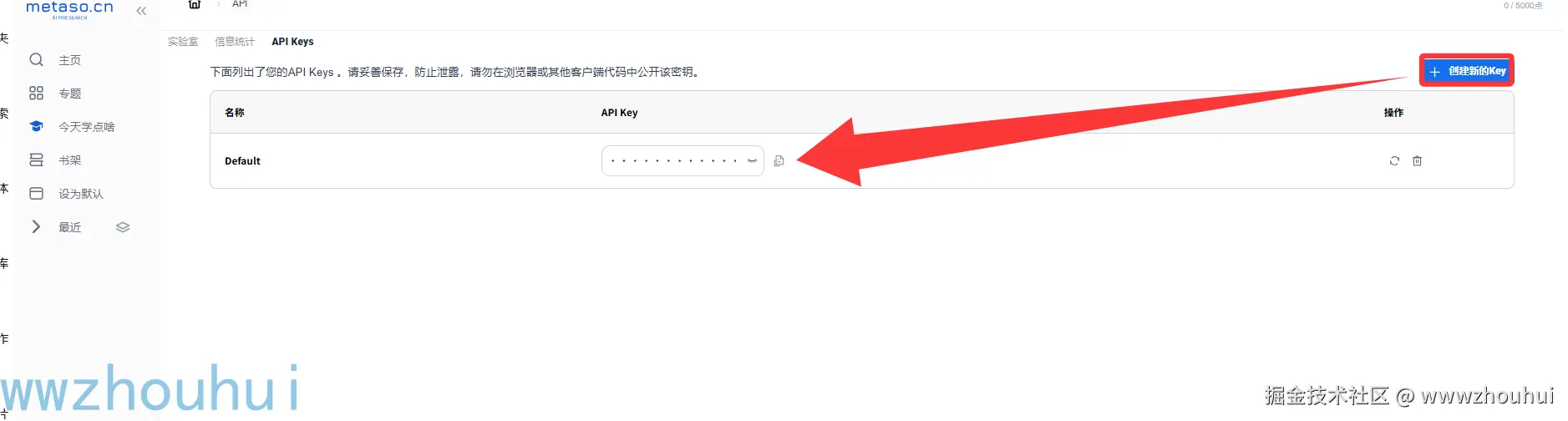
默认会送5000次调用请求量
不熟悉API 调用的小伙伴也可以在网页端查看这个API 调用。
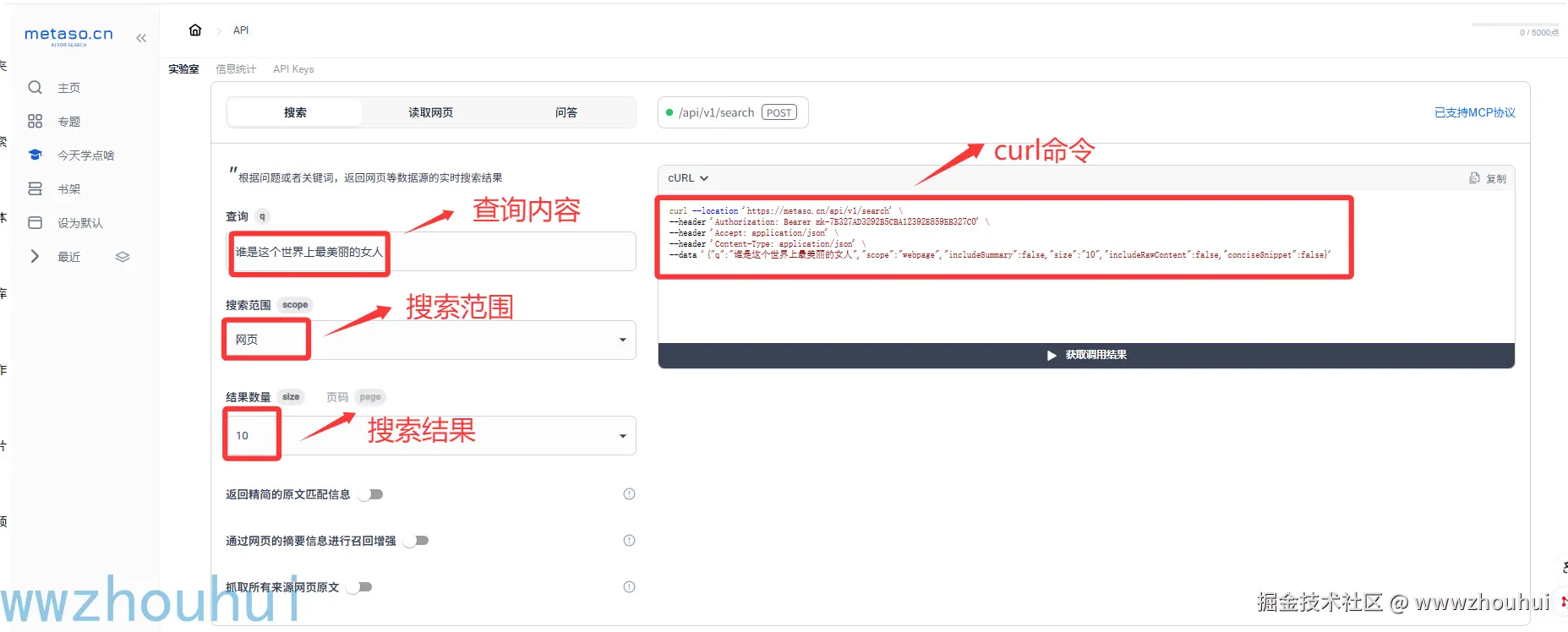
上面的接口查询条件大家稍微熟悉一下,后面的dify工作流输入参考就是根据上面的输入参数获取的。出来提供CURL 命令之外,它也提供多种开发语言客户端调用代码,方便大家集成。
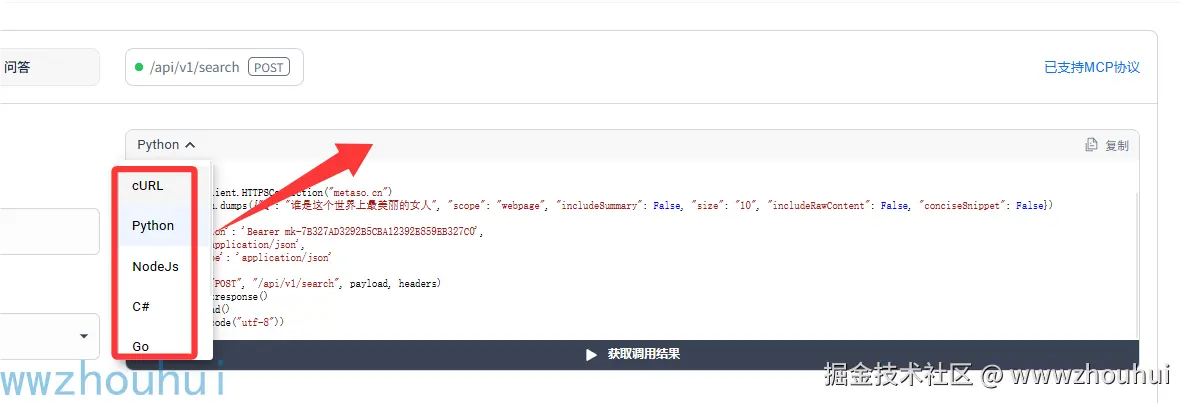
同样它也支持MCP了。MCP 应用上架了魔搭社区。www.modelscope.cn/mcp/servers...
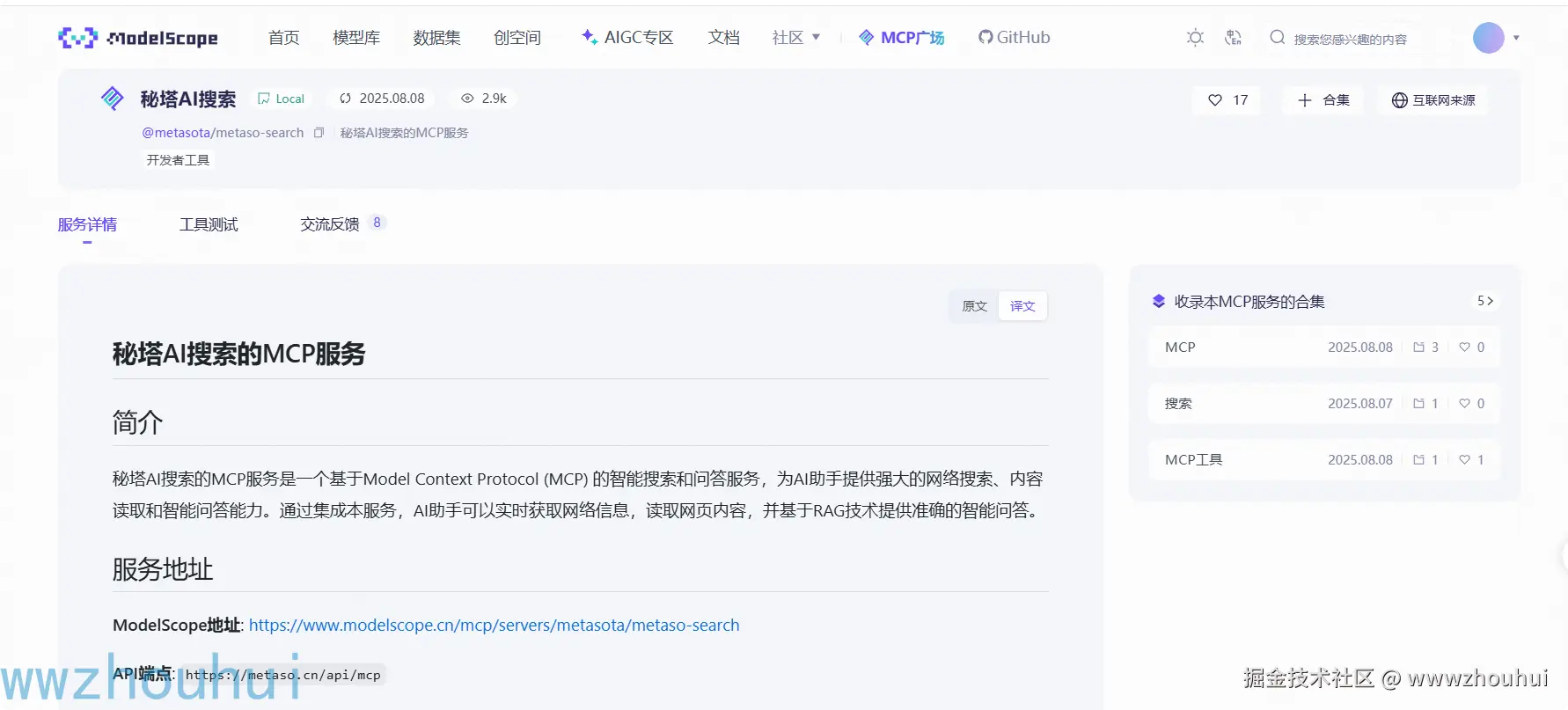
感兴趣的小伙伴可以去魔搭社区上体验。
创建工作流
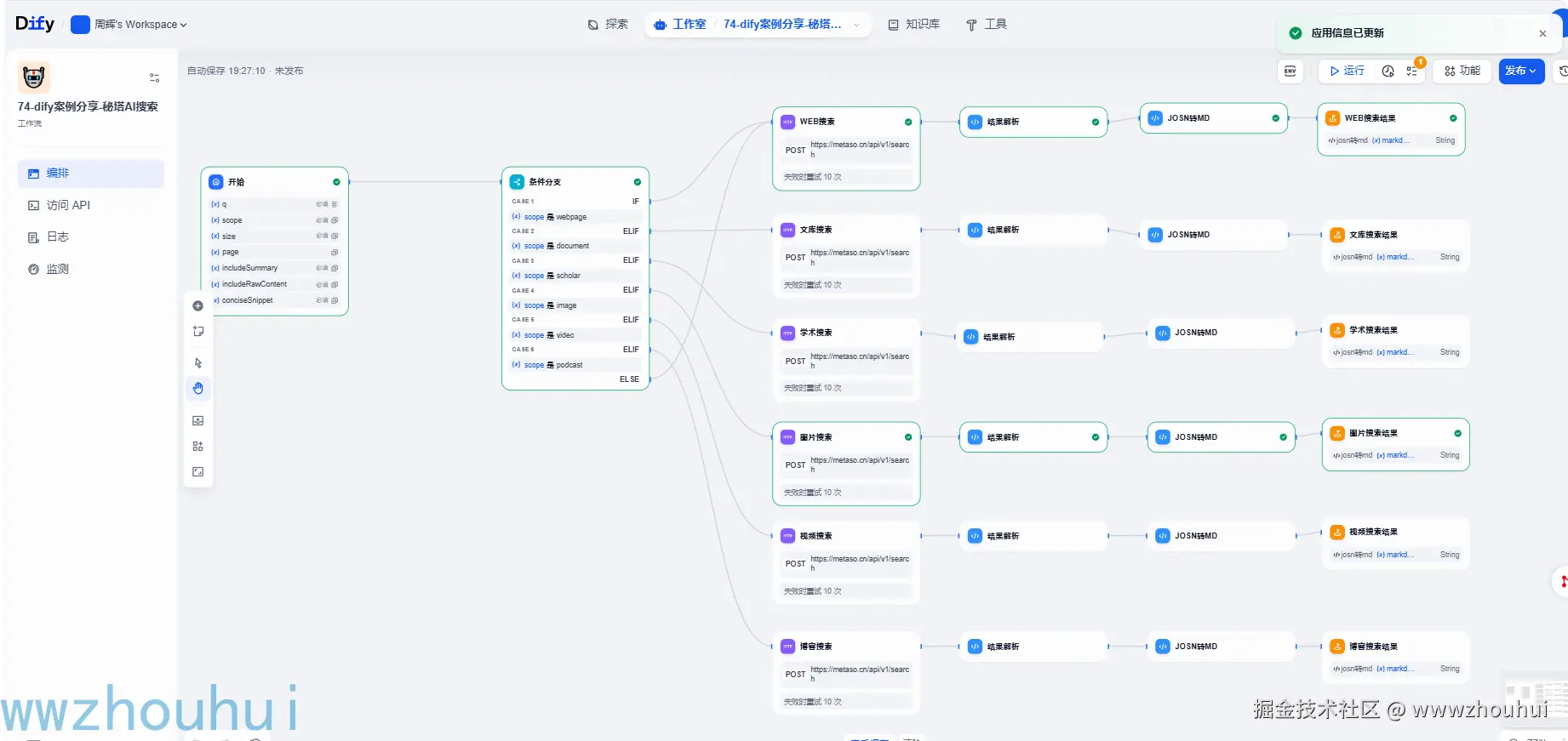
我们在dify工作台上,新建空白应用
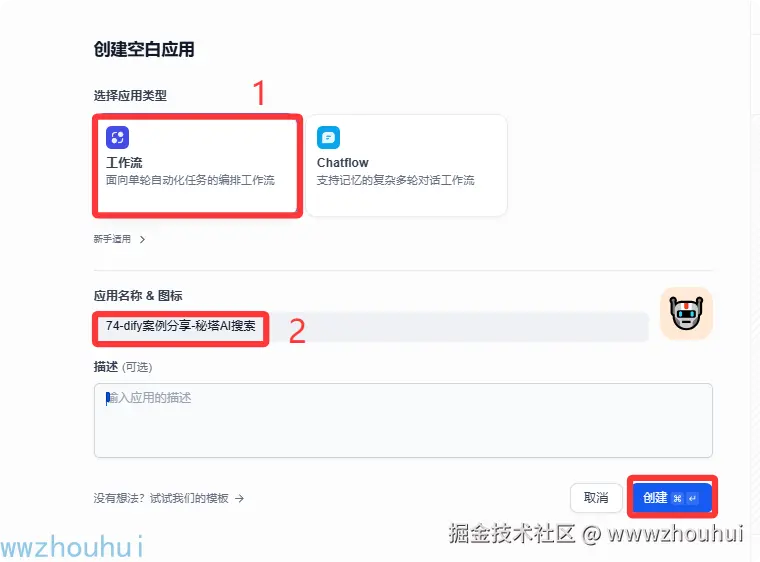
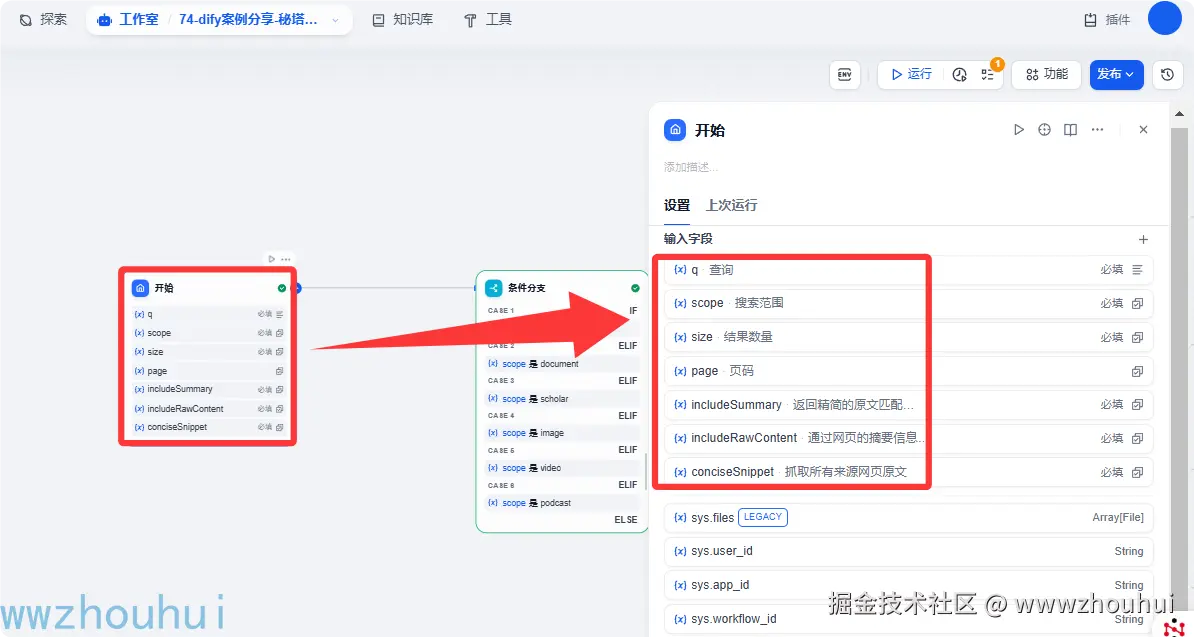
开始
这个开始节点主要是接受用户输入的参数,这些参数就是秘搭API 提供的输入参数,可以参考上面截图的请求参数。
目前有查询、搜索范围、结果数量、页码、返回精简的原文匹配信息、通过网页的摘要信息进行召回增强、抓取所有来源网页原文
这里参考较多我们就不一一举例。只介绍 1-2个
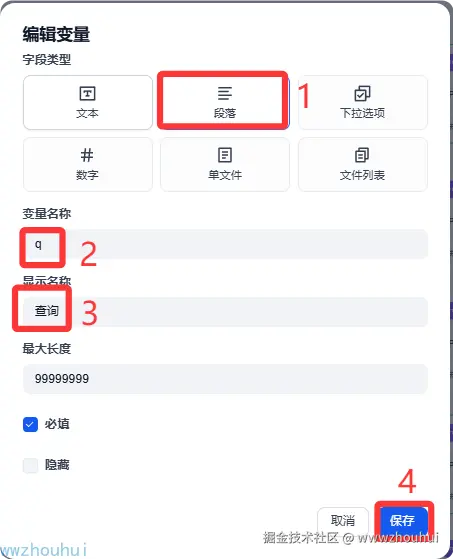
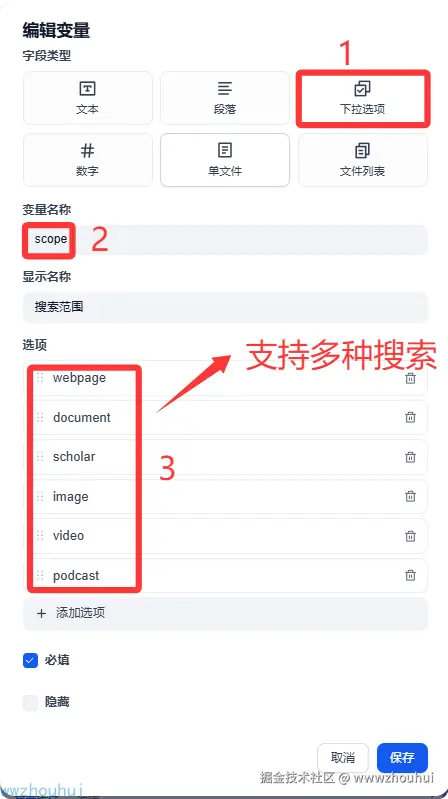
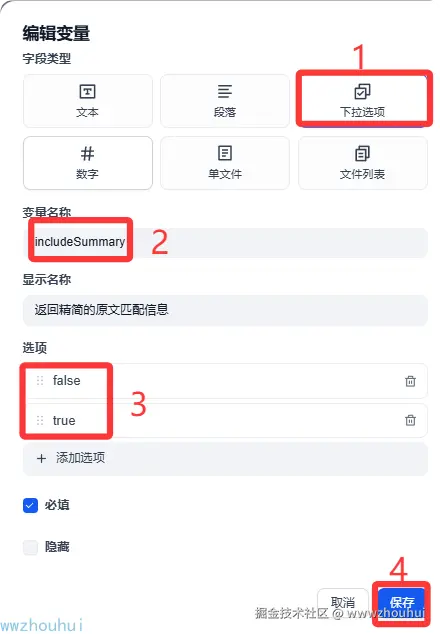
配置完成后我们可以看到开始节点配置后的请求参数
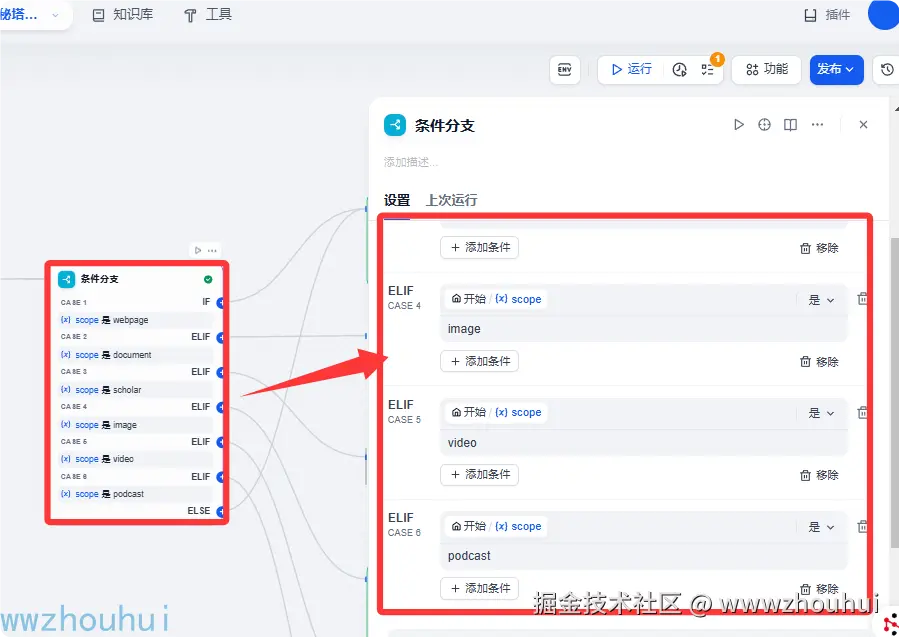
条件分支
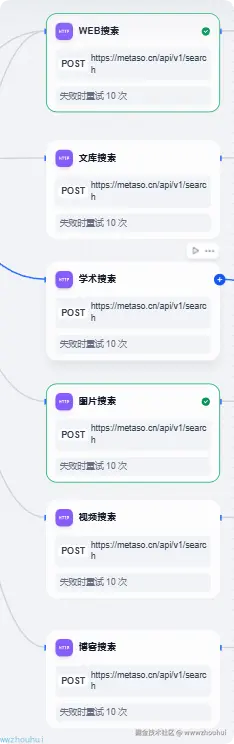
这个条件分支是dify自带的组件,这个其实很好理解秘搭提供多种类型搜索(网页、文档、学术、图片、视频、播客)我们根据开始节点scope下拉选项来进行条件分支判断。
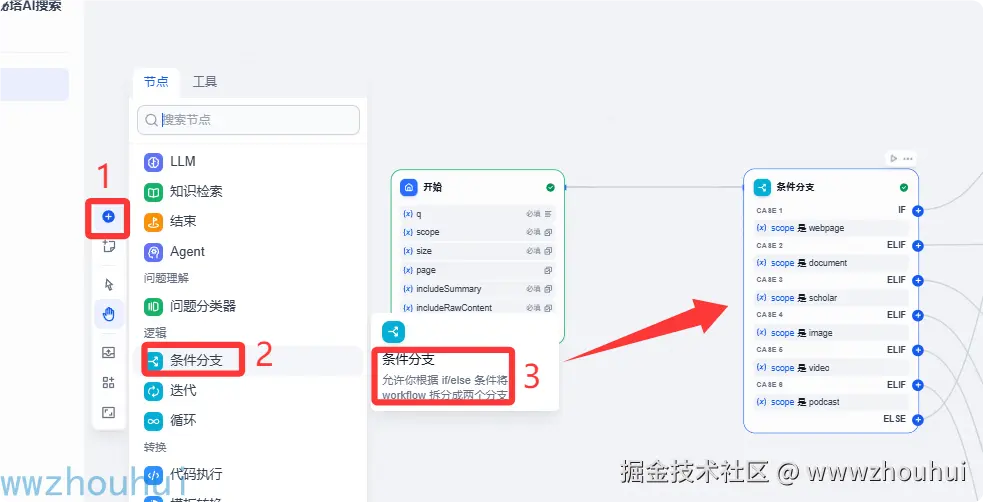
这个条件分支如下:
HTTP请求
接下来我们使用哦dify自带的http请求调用秘搭AI搜索的API 请求接口。这里我们需要设置一下api KEY 的环境变量,方便后面接口请求使用
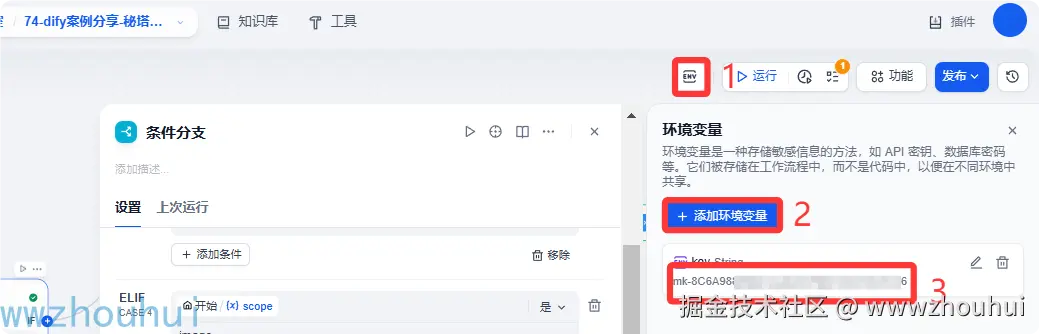
配置好环境变量后我们就可以设置http请求了
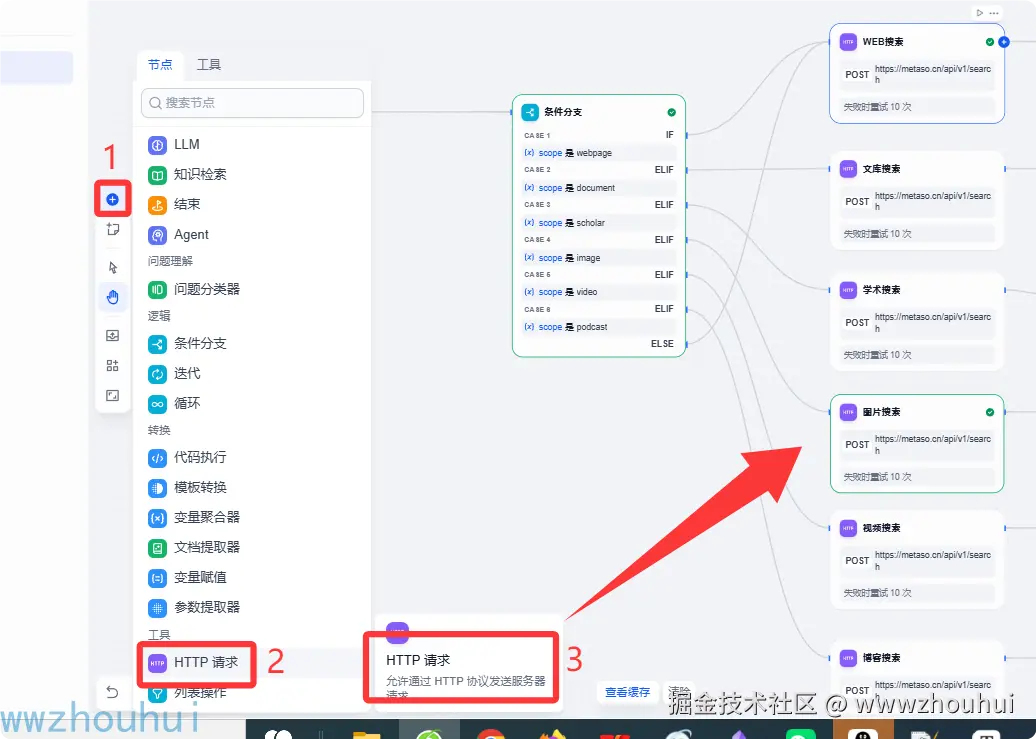
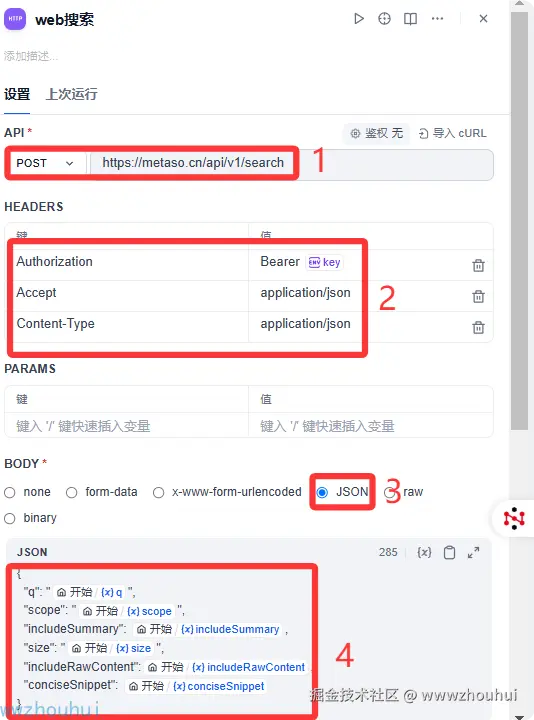
http节点请求设置如下,请求方式post.请求地址metaso.cn/api/v1/sear...
headers 设置中最关键是的设置Authorization ,数据格式类型是application/json
body部分主要是json格式数据
bash
{
"q": "{{#1753787119287.q#}}",
"scope": "{{#1753787119287.scope#}}",
"includeSummary": {{#1753787119287.includeSummary#}},
"size": "{{#1753787119287.size#}}",
"includeRawContent":{{#1753787119287.includeRawContent#}},
"conciseSnippet": {{#1753787119287.conciseSnippet#}}
}
这里的HTTP 配置都一样。
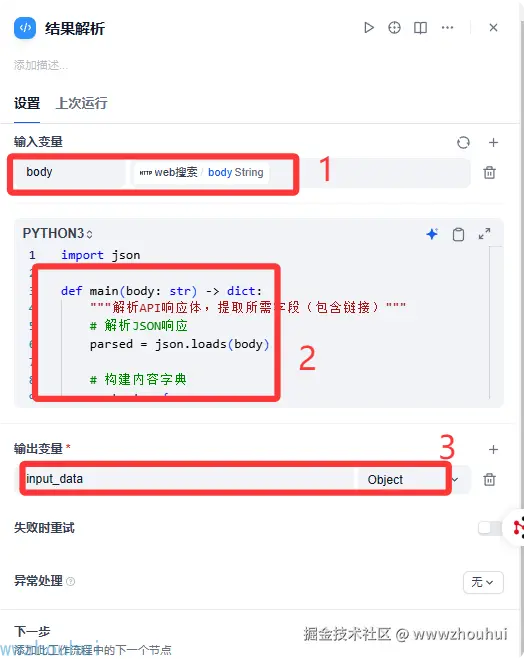
代码处理
http请求后我们需要通过代码来对结果进行简单的处理。
输入参数 body 输入值就是http请求的返回。
输出变量input_data 返回值是一个object
处理的代码如下:
python
import json
def main(body: str) -> dict:
"""解析API响应体,提取所需字段(包含链接)"""
# 解析JSON响应
parsed = json.loads(body)
# 构建内容字典
content = {
"q": parsed["searchParameters"]["q"],
"total": parsed["total"],
"webpages": []
}
# 处理每个网页
for item in parsed["webpages"]:
page = {
"title": item["title"],
"link": item["link"], # 添加链接字段
"snippet": item["snippet"],
"position": item["position"],
"date": item["date"],
"authors": item.get("authors", []) # 安全处理缺失的字段
}
content["webpages"].append(page)
# 将输出变量名改为 input_data
return {"input_data": content}这里由于返回接口返回的信息有点差异,所以返回的代码也有一点差异,总体来说结构是一样的。详细代码大家可以看后面开源的DSL文件,这里就不做详细展开了。
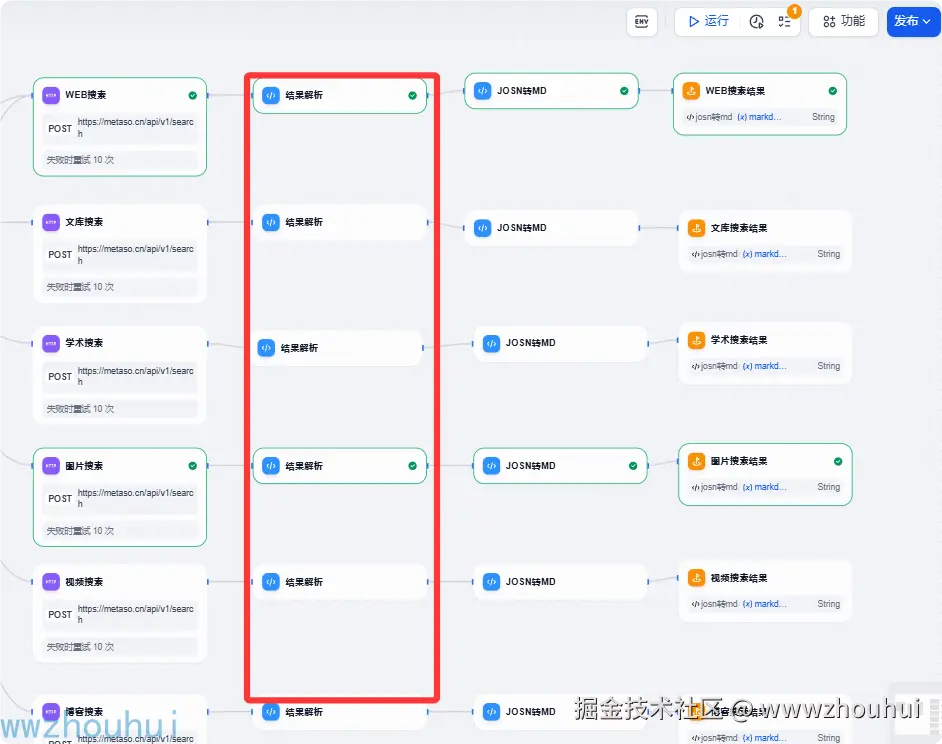
json转MD
这里我们同样使用代码处理来把返回JSON数据转成MD格式的数据
输入参数input_data 输入值object
返回参数markdown 返回值string
json转MD代码如下:
python
import logging
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def main(input_data):
# 1. 验证输入数据是否存在
if not input_data:
logger.error("输入数据为空!")
input_data = {"q": "默认搜索词", "documents": []} # 提供默认数据
# 2. 提取必要字段(带默认值)
query = input_data.get("q", "")
documents = input_data.get("documents", [])
# 3. 处理逻辑(示例:生成 Markdown 结果)
markdown_output = f"## 搜索结果\n- **关键词**: {query}\n\n"
for doc in documents:
title = doc.get("title", "无标题")
link = doc.get("link", "#")
markdown_output += f"- [{title}]({link})\n"
return {"markdown": markdown_output}
# 调用入口(Dify 自动传入 input_data)
if 'input_data' in locals():
result = main(input_data)
else:
result = {"error": "输入数据未定义"}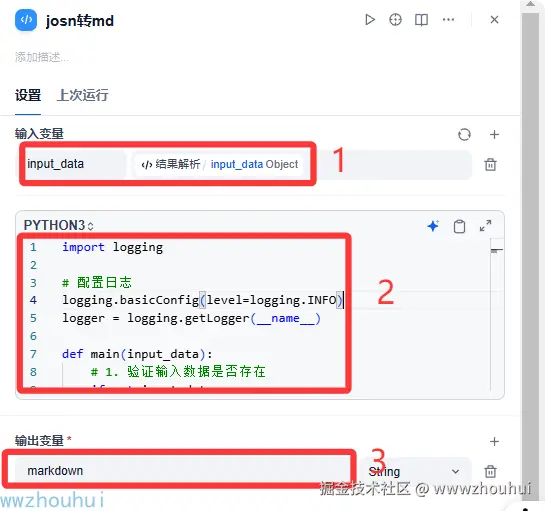
直接返回
最后工作流将转换后的MD文档输出,这个就比较简单的。输入参数result 返回是MD格式的string字符串
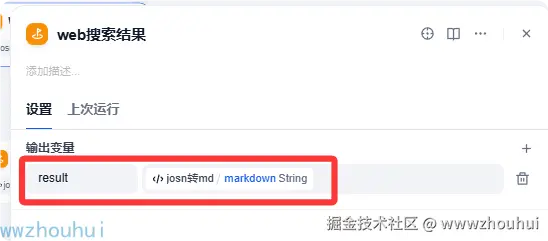
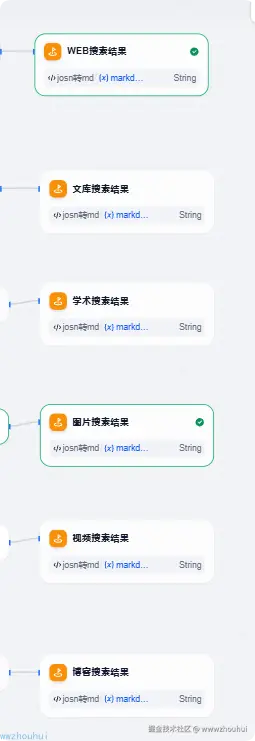
通过以上方式我们就完成了工作流的制作。
3.验证及测试
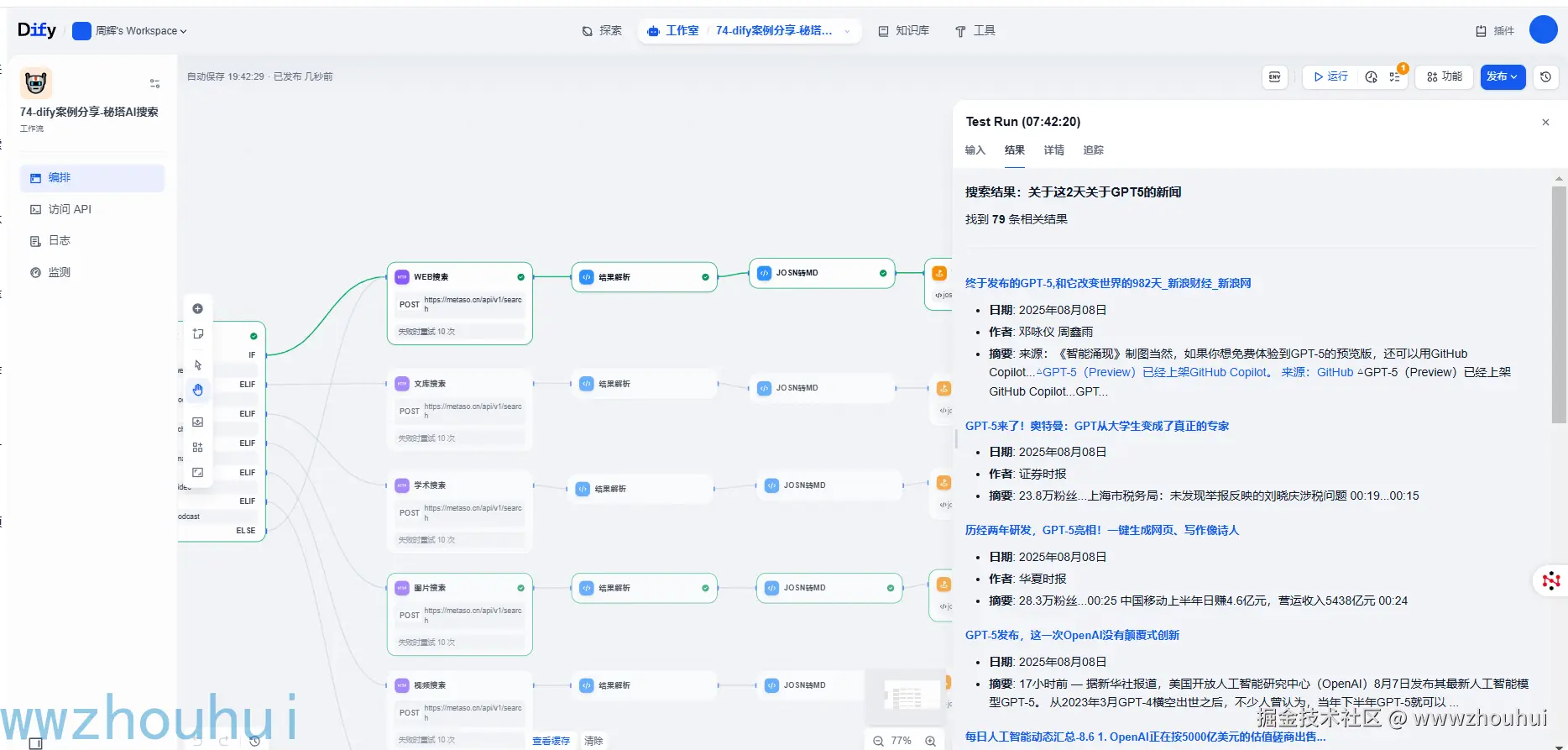
我们打开工作流运行,填写查询的条件(2025年8月9日最新科技新闻、 webpage、10、1、false 、false、true)
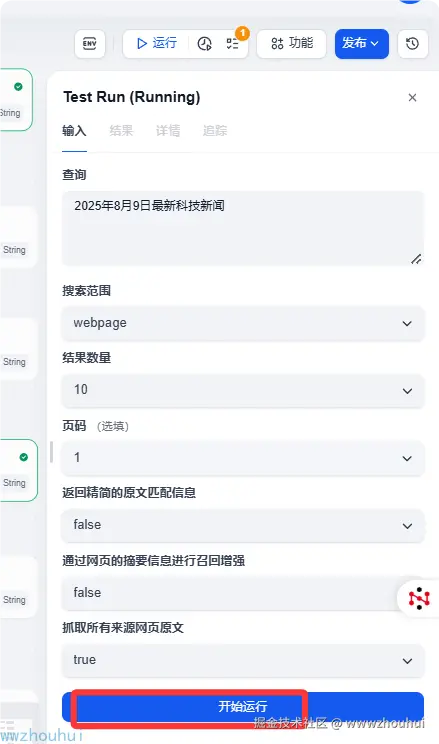
运行后的效果如下
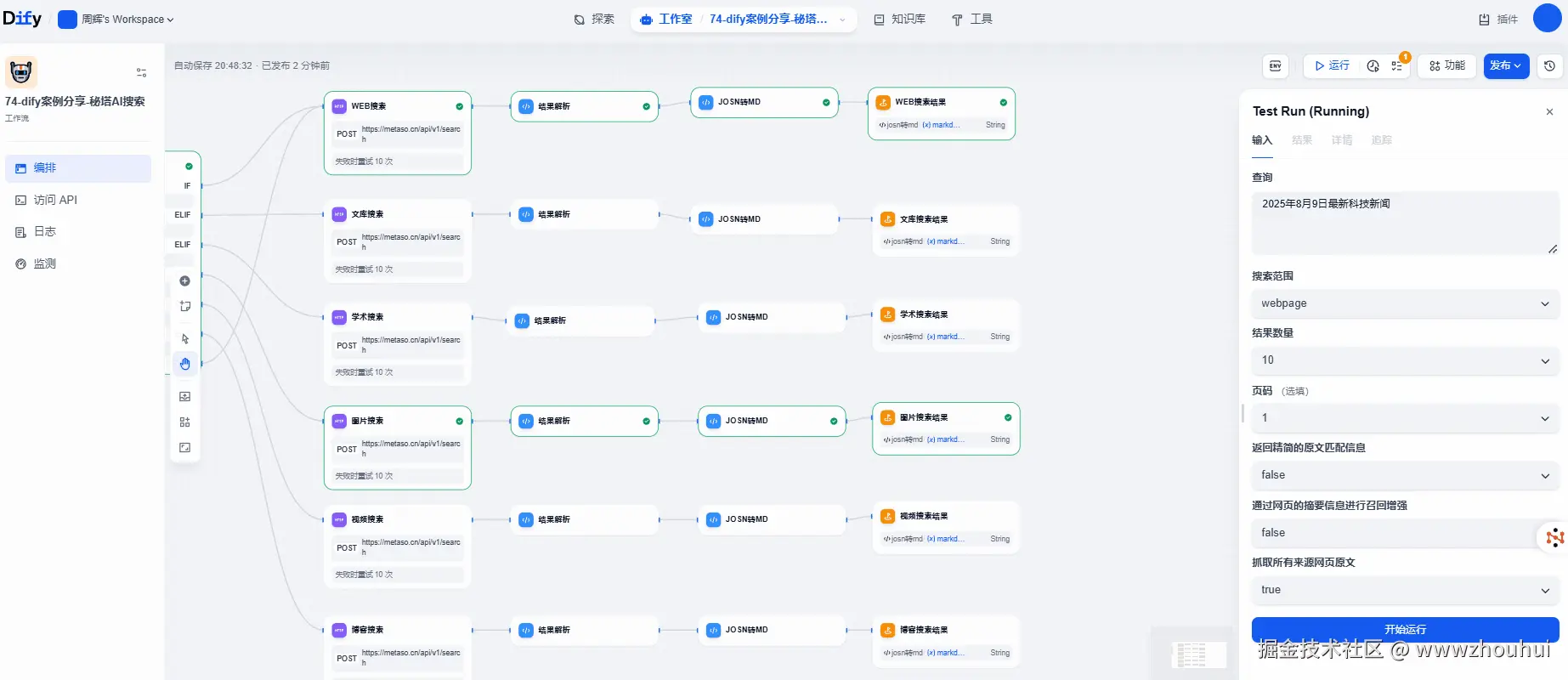
这个搜索速度还是非常快的。
体验地址
工作流地址:dify.duckcloud.fun/workflow/kb...
4.感谢
这个dify工作流是小灰灰-技术交流群6 群友阿文提供制作的。这里再次感谢它的分享,工作流基本上是使用了它原始的DSL文件制作的。
5.总结
今天主要带大家制作了一个基于 Dify 的秘塔 AI 搜索功能工作流。此次实践不仅实现了从用户输入搜索参数、通过条件分支适配不同搜索类型,到调用秘塔 API 获取结果、解析处理并转换为 Markdown 格式输出的全流程自动化,还重点展示了 Dify 在集成第三方 API、处理条件分支逻辑以及通过代码节点进行数据解析与格式转换方面的灵活能力。
总的来说,通过此次实践,我们充分体验到了 Dify 在 AI 搜索类应用开发中的便捷性和高效性。它通过直观的节点配置简化了 API 调用流程,借助条件分支轻松适配多种搜索场景,利用代码处理节点实现了搜索结果的精准提取与格式转换,为快速搭建个性化的 AI 搜索工具提供了高效、灵活的解决方案。
感兴趣的小伙伴可以按照本文步骤去尝试制作自己的 AI 搜索工作流,并探索结合更多搜索参数与结果展示形式的可能性。今天的分享就到这里结束了,我们下一篇文章见。
关注「 wwzhouhui」公众号,点赞分享这篇文章,后台私信:"dsl" 领取 dsl 工作流文件。