MedBLINK: Probing Basic Perception in Multimodal Language Models for Medicine
Authors: Mahtab Bigverdi, Wisdom Ikezogwo, Kevin Zhang, Hyewon Jeong, Mingyu Lu, Sungjae Cho, Linda Shapiro, Ranjay Krishna
Deep-Dive Summary:
MedBLINK:探索医学多模态语言模型的基本感知能力
摘要
多模态语言模型(MLMs)在临床决策支持和诊断推理方面显示出潜力,提出了端到端自动化医学图像解释的前景。然而,临床医生在采纳AI工具时非常挑剔;一个在看似简单的感知任务(如确定图像方向或识别CT扫描是否增强对比)上出错的模型不太可能被用于临床任务。我们引入了MEDBLINK,一个旨在测试这些模型感知能力的基准数据集。MEDBLINK涵盖了多个成像模态和解剖区域的八个临床相关任务,共有1,429个多选题,涉及1,605张图像。我们评估了19个最先进的多模态语言模型,包括通用模型(GPT-4o, Claude 3.5 Sonnet)和领域特定模型(Med-Flamingo, LLaVA-Med, RadFM)。人类标注者的准确率为96.4%,而表现最好的模型仅达到65%。这些结果表明,当前的多模态语言模型在常规感知检查中经常失败,表明需要加强其视觉基础以支持临床应用。数据可在我们的项目页面上获取。
1. 引言
如果ChatGPT无法识别图像是否上下颠倒,你会信任它吗?对于人工智能(AI)系统来说,要被广泛采纳,不仅需要在复杂的基准测试中表现出色,还必须在简单、直观的任务上展现能力。对于医疗领域的人工智能,这一期望可能更为关键,因为在基本感知线索上的失败可能会削弱临床医生的信心。随着多模态语言模型(MLMs)越来越多地进入临床环境40, 41, 55,它们在基础任务上的可靠性与在高级诊断推理上的表现同样重要。
近年来,视觉-语言建模的进步引发了关于全自动化系统能够解释医学图像并支持临床决策的热情33, 38, 64。然而,临床医生在采纳AI工具时仍然保持谨慎7, 22, 53。医生依赖于深植内心的心智模型来解释医学图像,并期望AI能够达到同样的流畅性。模型在基本任务上的失误,例如检测图像方向或识别对比增强,可能会立即导致其被忽视,无论其后续能力如何5。例如,了解CT扫描是否经过对比增强直接影响后续的诊断解释和临床决策28。
这些基本评估,通常被称为"眨眼任务"18,在专家工作流程中几乎是反射性的。它们依赖于低努力的感知和上下文线索,而非复杂的推理或跨模态融合。如果模型在这些任务上表现不佳,就表明其未能内化对现实世界应用至关重要的视觉先验42,同时也引发了关于模型是否仅利用表面相关性的疑问49。
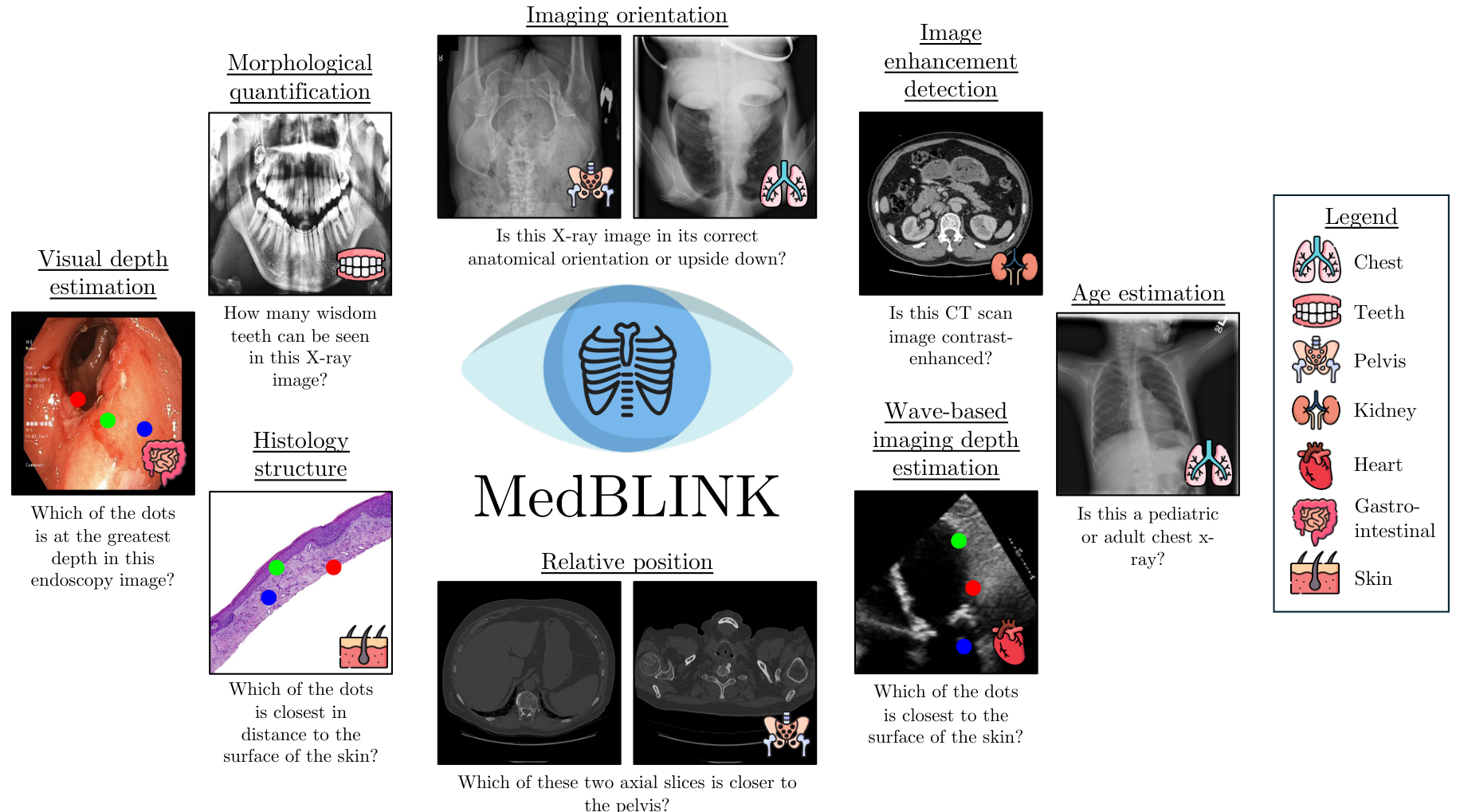
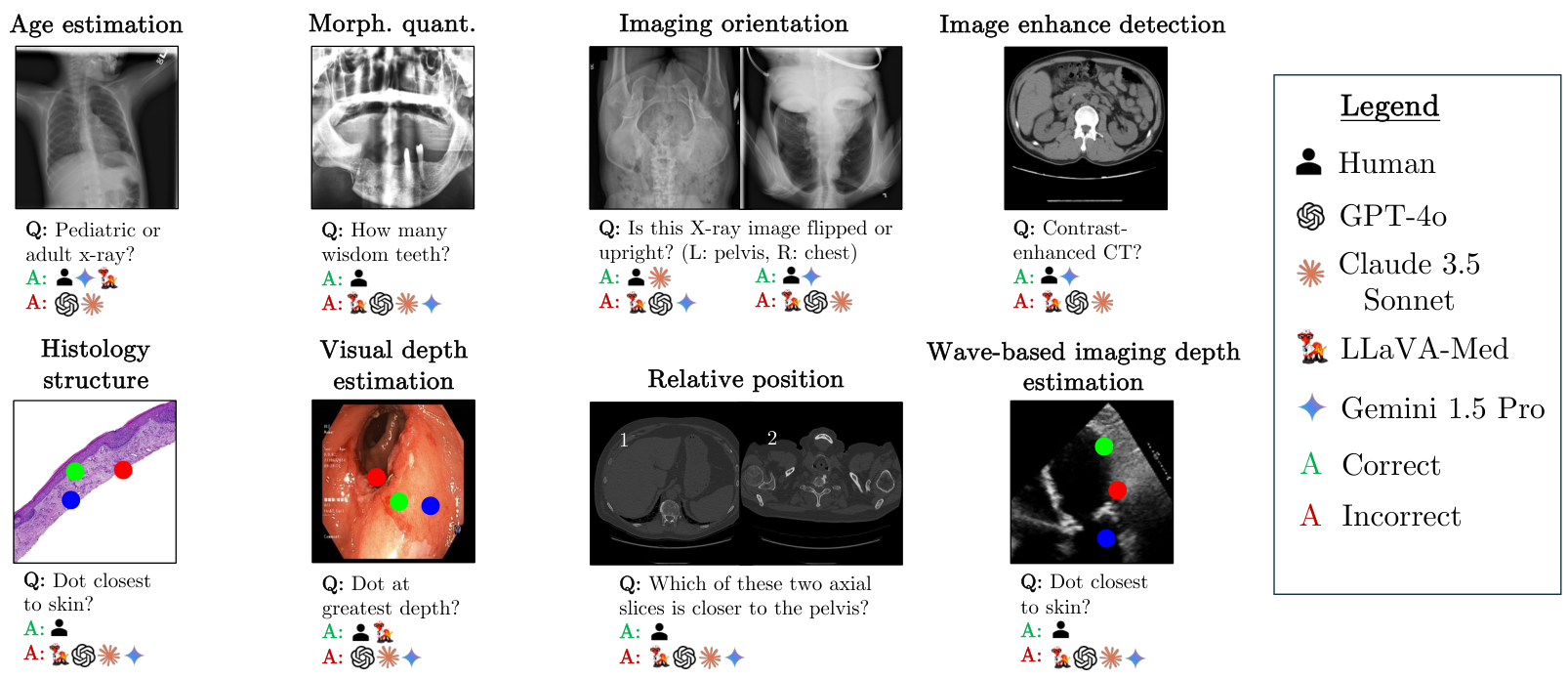
我们引入了MedBLINK,一个旨在测试这些能力的基准测试。MedBLINK包含八个感知上简单但临床上重要的任务,这些任务是与资深放射科医生协商后选定的。问题故意设计得简单,要求模型执行基本的视觉感知而非复杂推理。图1展示了每个任务的一个示例,包括视觉深度估计和图像方向检测等案例。在这些任务上的失败将揭示模型在捕捉空间关系和保持对解剖结构连贯理解方面的困难。
我们评估了19个最先进的多模态语言模型,包括通用模型如GPT-4o27和Claude 3.5 Sonnet1,以及医学领域模型如Med-Flamingo41、LLaVA-Med33和RadFM60。虽然人类标注者的准确率为96.4%,但表现最好的模型仅达到65%。通过探索模型在感知上的失败,而不仅仅是预测上的失败,MedBLINK突显了当前评估协议中的一个基本差距。解决这一差距至关重要:模型必须首先掌握这些低努力、常识性的感知任务,才能被信任支持现实世界的诊断推理和临床采纳。
2. 相关工作
多模态语言模型在医疗领域的应用
医疗图像分析从早期的计算机辅助检测技术20, 37, 58发展到近年来的多模态语言模型(MLMs)3, 31, 46, 54。这些模型结合了文本和图像理解能力,通常通过视觉问答(VQA)任务进行评估。在医疗领域的应用推动了诊断和报告生成任务在多个领域的进展15, 27, 33, 41, 55, 56, 64。然而,由于缺乏大规模的医疗图像格式支持(如2D X射线、3D CT/MRI、视频、千兆像素组织病理图像),仍然存在局限性。这促使了领域特定模型的开发,例如用于体积成像的VoxelPrompt25和Dia-LLaMA12,以及用于组织病理学的Quilt-LLaVA50、PathChat38和PathFinder19。
医疗领域的多模态基准
随着医疗MLM的发展,出现了许多评估跨模态和任务性能的基准,主要评估医学知识24, 26, 30, 34, 36, 47, 49, 50, 59-61, 65, 66。SLAKE34和VQA-RAD30从现有数据集中抽取放射学图像,创建临床诊断问答对。Path-VQA24从教科书中整理病理图像,并从标题中生成问答对。Quilt-VQA50从教学视频中提取组织病理学问答内容,基于转录生成问答。OmniMedVQA26开发了覆盖12种医疗模态的大规模VQA。GMAI-MMBench65利用38种模态进行超越诊断的感知任务。CARES61在16种模态上评估信任度,涵盖五个维度:可信度、公平性、安全性、隐私性和鲁棒性。MediConfusion49探讨视觉上不相似图像对的失败模式。RadVUQA43突出了空间、解剖和定量推理中的关键差距。与复杂的演绎基准不同,BLINK18显示感知上要求较高的任务对MLMs仍然具有挑战性。MED-BLINK延续这一研究方向,针对临床医生易于完成但当前模型持续缺失的基础感知技能进行评估。它不强调复杂推理,而是探索在临床部署中赢得信任所需的基本视觉能力,填补了当前模型信任度评估中的关键空白。
3. MEDBLINK基准
临床图像解释依赖于感知和概念推理。感知使临床医生能够在进行更复杂的诊断推断之前提取关键视觉特征42。然而,大多数医疗AI基准仅关注概念任务,假设强大的诊断性能意味着足够的视觉理解。这造成了一个关键盲点:模型可能在没有真正感知图像的情况下生成看似合理的答案。
MEDBLINK通过测试MLMs在感知上简单但临床上重要的任务(如计数、深度估计、解剖定位和增强检测)上的表现,评估这一基础信任层。这些任务反映了临床医生日常进行的早期视觉判断;表现不佳表明存在感知基础差距,从而损害下游信任。
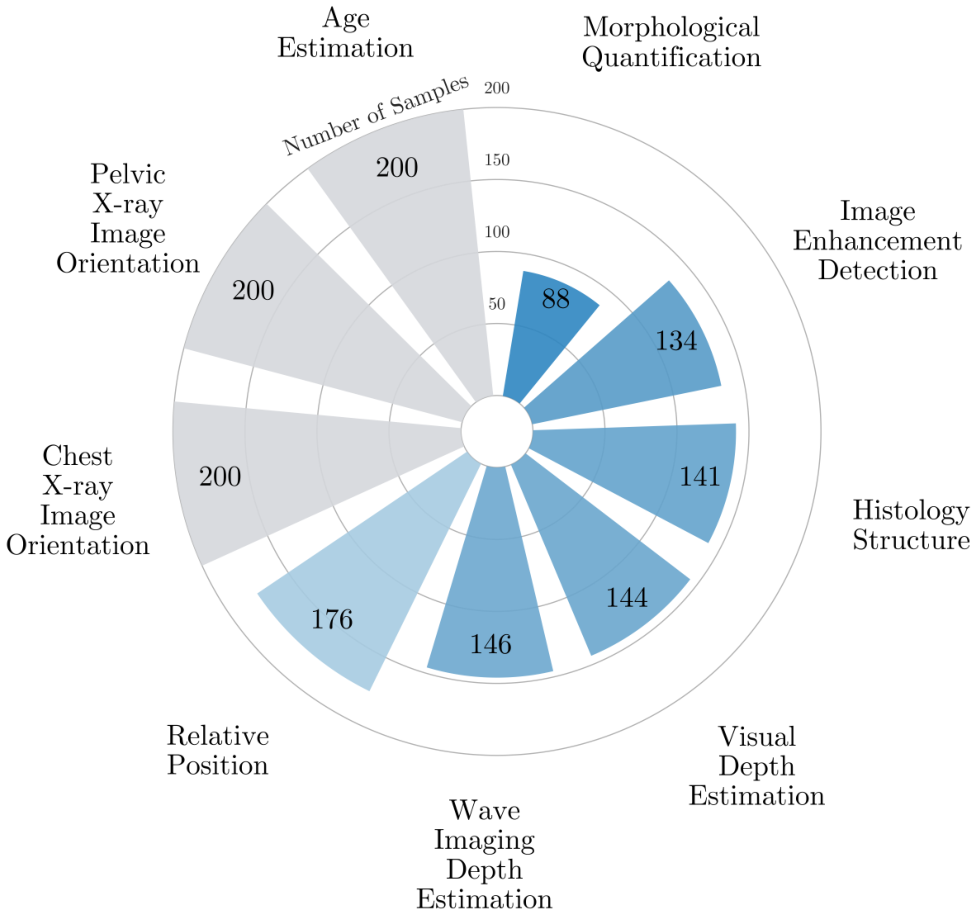
该基准包括1,429个选择题,涵盖1,605张经过专家验证的图像,涉及多种模态和解剖区域(见图2),重用并增强现有数据集,包含单张或成对图像任务(表7,第3.2节)。所有样本均经过手动审查,确保清晰度、质量和无歧义,并根据领域专家的反馈进行改进。MEDBLINK既是感知基准,也是临床环境中模型信任度的重点探测工具。
3.1. MEDBLINK 特性与特征
MEDBLINK 涵盖了5种常见的医疗成像模态,包括:X射线、CT、内窥镜、组织病理学和超声,覆盖了多个解剖器官/区域的性能评估,包括牙齿、胸部、皮肤、盆腔、腹部、心脏、肾脏和胃肠道。
这些模态的选择旨在覆盖广泛的图像获取方法(例如X射线、CT、超声、内窥镜和组织病理学)、输出类型/维度(例如3D CT扫描或组织病理学的千兆像素图像)以及解剖区域。因此,在MEDBLINK上的性能提升表明在更广泛的医疗成像模态中也有改进(例如,CT在三维维度上与MRI和PET相似,荧光透视与X射线使用相似的辐射获取方法,超声与OCT具有相似的刚性结构)。
与其他的医疗基准相比,MEDBLINK具有以下关键创新点:
- 感知任务:与其他医疗多模态基准不同,我们探索看似简单但在临床上意义重大的医疗视觉任务,这些任务对于确保准确诊断和决策至关重要。
- 多样化和可泛化任务:我们的数据来源于多种成像模态和解剖区域,任务可泛化到本基准未覆盖的其他模态。
- 视觉提示:临床医生在审查或交流发现时通常会关注特定的图像区域。我们通过利用视觉线索(如点/圆点)来模拟这种提示形式,从而在回答指定问题时对模型进行空间提示 43, 50。
- 领域内成像特性:我们明确测试模型在医疗成像的临床特性上的表现,包括对结构不对称性的了解、解剖几何推理、临床相对深度估计以及利用形态学进行特征量化。
3.2. MEDBLINK 数据整理
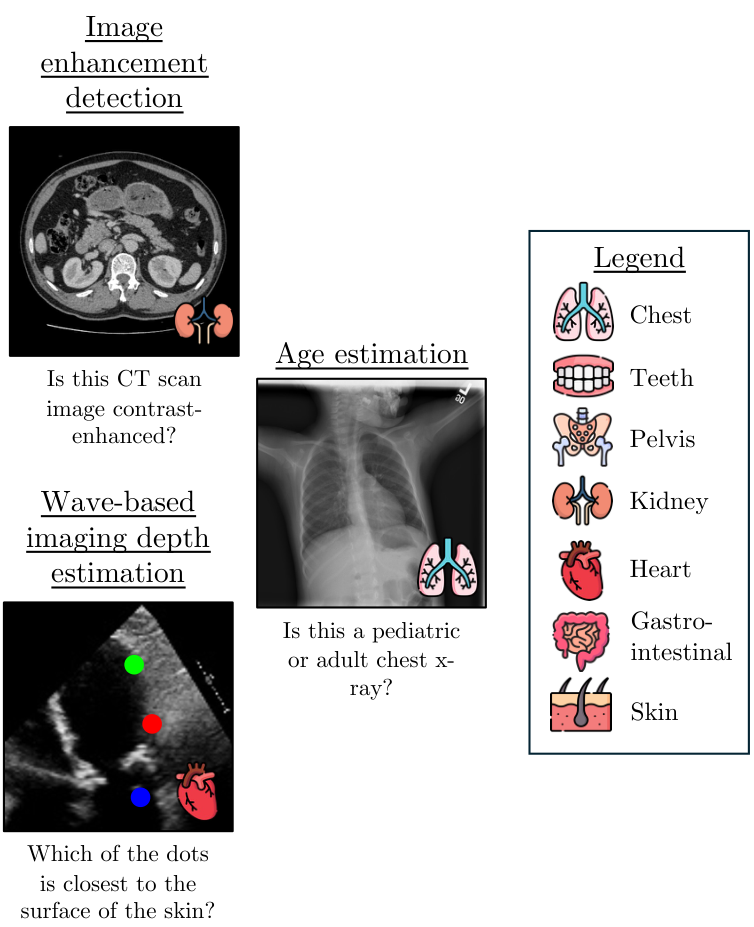
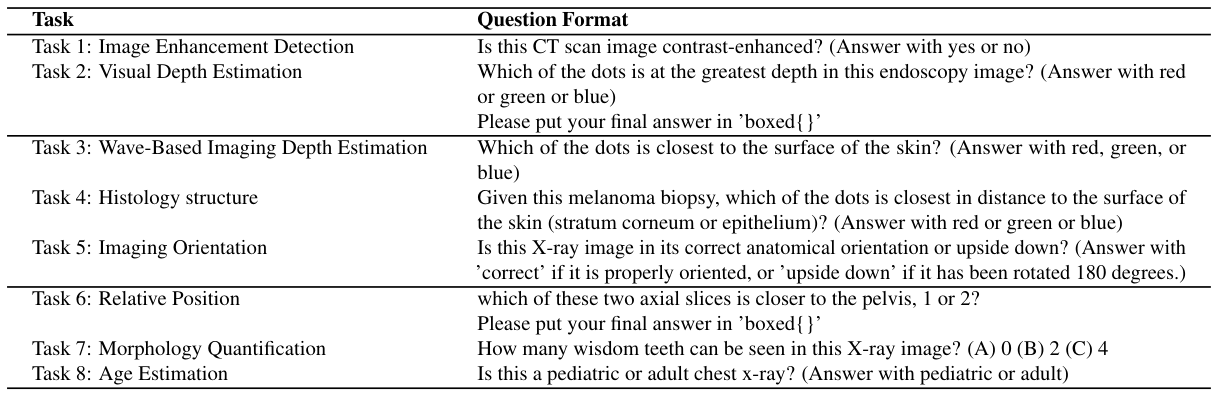
任务1:图像增强检测
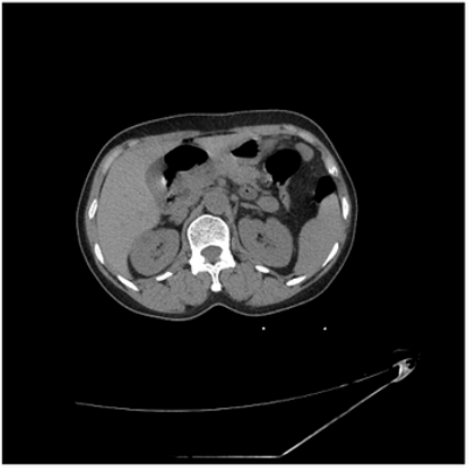
在医疗成像中,图像增强(如对比剂注射)可以提高图像质量并突出重要结构,尤其是在未增强扫描不足以满足需求时。此任务测试模型是否能够区分增强和未增强的CT图像。我们使用了VidDr多相数据集 16,该数据集包含非对比、动脉相和静脉相CT扫描。我们手动提取包含肾脏的腹部切片,其中对比效果清晰可见。每张图像都与一个询问是否经过增强的问题配对;样本提示请参见表9。
任务总结(中文)
任务2:视觉深度估计
本任务评估模型在通过RGB成像技术(如内窥镜)捕获的医学图像中推断相对深度的能力。这些成像技术生成3D解剖结构的2D表示,专家可以通过将像素位置映射到空间深度来直观地解释这些图像,就像人们可以观察图像并推断相对深度一样 11。
为了测试这一能力,我们使用了来自Kvasir数据集 45 的内窥镜图像。在每个问题中,我们展示一张随机选择的图像,并在图像中心放置一个边界框(覆盖图像面积的25%)。在边界框内,放置了三个不同深度的彩色点,这些深度是通过DepthAnything模型 63 生成的深度图确定的,并随后进行了验证。
任务3:基于波的成像深度估计
类似地,本任务测试模型在基于波的采集技术(如超声波使用声波,或OCT使用光波)的医学成像模态中估计空间区域相对深度的性能。声波传播的基本物理原理决定了超声波呈现出特有的锥形结构 51,锥体中可见特征的最高点最靠近与皮肤接触的点。
本任务的目标是评估多模态学习模型(MLMs)对基于波的医学成像模态中深度的理解。我们通过在锥体内放置视觉点,并询问哪个点最靠近接触点来实现这一目标。我们使用了EchoNet-Dynamic心脏超声视频数据集 44,选择了150个视频,并从每个视频中随机选择一帧。然后,我们使用灰度阈值处理创建超声波锥体的掩码,将掩码分为三个部分,每部分之间有10像素的间隙,并在每个部分随机放置一个点,为每个点分配随机颜色(红色、蓝色、绿色),其中最上部分的点最靠近皮肤/接触点。为了评估MLMs,我们对图像进行均匀随机的四个方向翻转:0度(正立)、90度、180度(倒立)和270度顺时针旋转。
任务4:组织学结构
通过此任务,我们评估模型对医学图像中非刚性结构的理解程度。与X射线图像等具有由人体骨骼勾勒出的刚性结构的医学领域不同,许多组织病理学子领域没有严格的解剖结构,因为成像的组织样本是从疑似癌变组织中提取的。然而,某些子领域如皮肤组织学保持了可见的细胞层结构:表皮和真皮 4,其中真皮在结构上位于表皮之下。
我们通过在表皮和真皮中放置可见点(使用对比色),并询问哪个点最靠近皮肤表面来评估模型对这些层的基本知识。我们利用了Abdul等人 48 提供的 Hematoxylin 和 Eosin 染色(H&E)的皮肤全切片图像(WSI)数据集及其掩码,分割出包括表皮和真皮在内的12个组织类别。我们裁剪代表性图像,并在表皮和真皮区域随机放置点/圆点以整理任务图像,同时记录正确点的颜色。
任务总结 (中文)
以下是对论文中提到的任务5至任务8的中文总结,原文中的Markdown格式和图片位置保持不变。
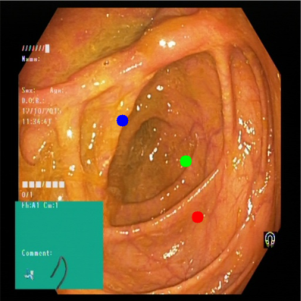
任务5:影像方向
在这一任务中,我们对模型进行基准测试,以评估其识别医疗影像是否正确定向的能力,特别是对于具有强烈结构先验的影像模态,例如X射线影像是否上下颠倒。医疗影像的正确空间方向对于准确解释解剖结构至关重要;人体生理中的固有结构不对称性在影像中作为方向标志,例如心脏轮廓向左投影,以及X射线影像中肝脏右侧占主导地位。人类专家能够直观地识别这些标志,并基于解剖先验重新调整方向错误的影像。
为了构建这一任务,我们使用了ChestX-ray8 57数据集的测试集(成人,年龄>20岁)胸部X射线数据集和一个骨盆X射线数据集。我们从每个数据集中随机抽取200张患者影像,并随机将其中100张影像翻转180度,然后询问影像是否正确定向。
任务6:相对位置
这一任务测试模型是否理解3D人体解剖结构,通过询问模型判断哪个2D切片更靠近特定器官。3D医疗模态(如CT和MRI)本质上是对固定内部解剖结构的一次快照;因此,给定CT扫描的任何切片,推断其相对于其他切片的位置相对简单,例如给定胸部和腹部的两个轴向切片,可以判断哪个切片更靠近特定器官。
我们测试多模态语言模型(MLMs)的3D解剖心理模型,以判断它们是否仅仅记忆了看到的样本,还是真正理解了人体扫描的3D结构。为此,我们利用OSIC Pulmonary Fibrosis Progression 2数据集中的176个CT扫描,挑选视觉上可区分的切片,并询问哪个切片更靠近固定器官。我们沿深度维度将切片分为3个区间,随后随机抽取两张图像:一张来自第一个区间,另一张来自最后一个区间,以确保切片内容在视觉上有合理分离(通常第一个切片来自肩部/胸部区域,后者来自胸部/腹部区域)。图像并排拼接并标注为(1或2),用于任务中要求MLMs预测哪张图像更靠近骨盆。为了打破预期,我们随机打乱图像在拼贴中的顺序。
任务7:形态量化
在这一任务中,我们测试模型是否能基于特征形态在医疗影像中计数重要的医学特征(例如细胞)。在医疗影像中,许多决定诊断及后续患者护理的临床评分依赖于某些特征的计数。例如,在放射学中,许多分层评分系统也依赖于可见特征的计数,例如在CT图像中计数结节数量为估计Lung-RADS评分提供额外上下文 39。
为了确保视觉编码器的_patch_约束不会影响MLM在计数准确性上的表现,我们利用Panoramic dental radiography 10数据集及其掩码,在放射影像中计数智齿(第三磨牙)的数量,并提供3个选项,因为智齿在视觉上比例如WSI中的细胞更突出,且通常没有遮挡。
任务8:年龄估计
这一任务评估多模态语言模型(MLMs)仅基于胸部X射线影像中的临床表现估计患者年龄组的能力。该任务需要识别影像中存在的解剖差异。例如,儿科患者的相对心脏比例较大,儿童的胸廓呈更圆形且肋骨水平方向,而成人的胸廓呈椭圆形且肋骨倾斜 9。为此任务,我们从ChestX-ray8 57数据集的训练集中收集了100张儿科患者(年龄<7岁)和100张成人(年龄>20岁)的独特患者胸部X射线影像。
4. 实验
我们在 MEDBLINK 上评估了 19 个最先进的多模态语言模型(MLMs)。首先,我们发现虽然人类在医疗视觉感知任务上的表现持续较高,但当前模型在这些任务上表现挣扎,特别是在增强检测和计数任务上。其次,我们发现增加模型参数规模可以提升大多数任务的性能,但收益递减。第三,我们发现尽管医疗 MLMs 接受了领域内训练,但相较于其他基线模型表现最差,我们讨论了其中的原因。最后,虽然基于 API 的模型在通用领域任务(如方向检测)上表现良好,但在医疗方向检测上的表现较差,这表明其医疗感知理解能力与通用感知理解能力存在明显区别。
4.1. 评估的模型
我们在 MEDBLINK 上评估了 19 个当前的多模态语言模型,分为三组:
- 医疗多模态语言模型:我们测量了 4 个专门针对医疗领域、基于医疗数据训练的模型的性能:LLaVA-Med 33、Med-Flamingo 41、LLAVA-MED++ 62 和 RadFM 60。
- 开源多模态语言模型:我们在所有任务上评估了 9 个通用开源模型:Qwen 2.5 VL(3B 和 7B)6、INTERNVL 2.5(4B、8B、26B、38B)13、LLaVA-OneVision(0.5B 和 7B)32、LLAMA 3.2 11B 21,以及 3 个专门针对空间深度推理任务的模型:AURORA 8、Spatial-RGPT 14 和 LLaVA 1.5(7B)35。
- 基于 API 的多模态语言模型 :我们测试了 3 个专有模型:GPT-4o 27、Claude 3.5 Sonnet 1 和 Gemini 1.5 Pro 52。
最后,我们还对基于 ResNet-50 23 训练的小型专门化 CNN 模型进行了基准测试,这些模型使用构建 MEDBLINK 所用的底层数据集的训练集进行训练,详细信息见附录 B.1 部分。
4.2. 实验流程
我们遵循 BLINK 的评估设置 17, 18,将温度设为 0,重试次数调整为 5,并且不对图像进行调整大小。为了统一性,我们在多图像任务(如 CT 上的 3D 相对定位)中将图像拼接在一起。我们利用临床专家进行人类评估,根据图像尺寸使用统一的视觉提示大小,并报告模型准确性。详细信息见附录 A 部分。
4.3. 结果
多模态模型的性能仍远未达到可信赖的水平。尽管人类专家在基准测试中的平均准确率为96.36%,但表现最好的模型(CLAUDE 3.5 SONNET)仅达到64.99%的准确率,仅仅略高于随机猜测的42.58%。如表1所示,基于API的模型表现最佳(55.1-64.99%),其次是开源模型(42.86-51.02%),而医学领域特定模型尽管接受了专业训练,表现却出人意料地最差(43.69-47.47%)。模型在需要对比检测和计数的感知推理任务上表现最差。在对比识别任务中,大多数模型的性能接近或低于随机概率(50%),只有GEMINI 1.5 PRO略高,为57.1%。同样,在形态量化任务中,所有模型表现都很差,GPT-40的准确率仅为12.9%,而随机概率为33.3%,人类专家则达到81.8%。这些结果表明,多模态语言模型(MLMs)在感知医学图像中的细粒度视觉差异方面存在根本性局限。
医学专用MLMs尽管具有领域专长,但表现不如通用模型。出人意料的是,领域特定的医学模型平均性能(43.69-47.47%)低于基于API的模型(55.1-64.99%)和开源模型(42.86-51.02%)。LLAVA-MED在八个任务中的五个任务上表现为随机概率或更低,尤其在形态量化任务上表现挣扎(14.7%)。RADFM和MED-FLAMINGO在组织学结构任务(分别为20.6%和29.1%)和视觉深度估计任务(分别为26.4%和29.1%)上表现尤为薄弱,这表明这些专用模型可能在诊断任务中形成了虚假相关性,而非有意义的医学感知理解,无法应对复杂的诊断问题。尽管LLAVA-MED++在EsT. AGE任务上以92.5%的成绩优于其他医学模型,但在REL. Pos.任务和平均性能上表现不佳,仅为46.62%。
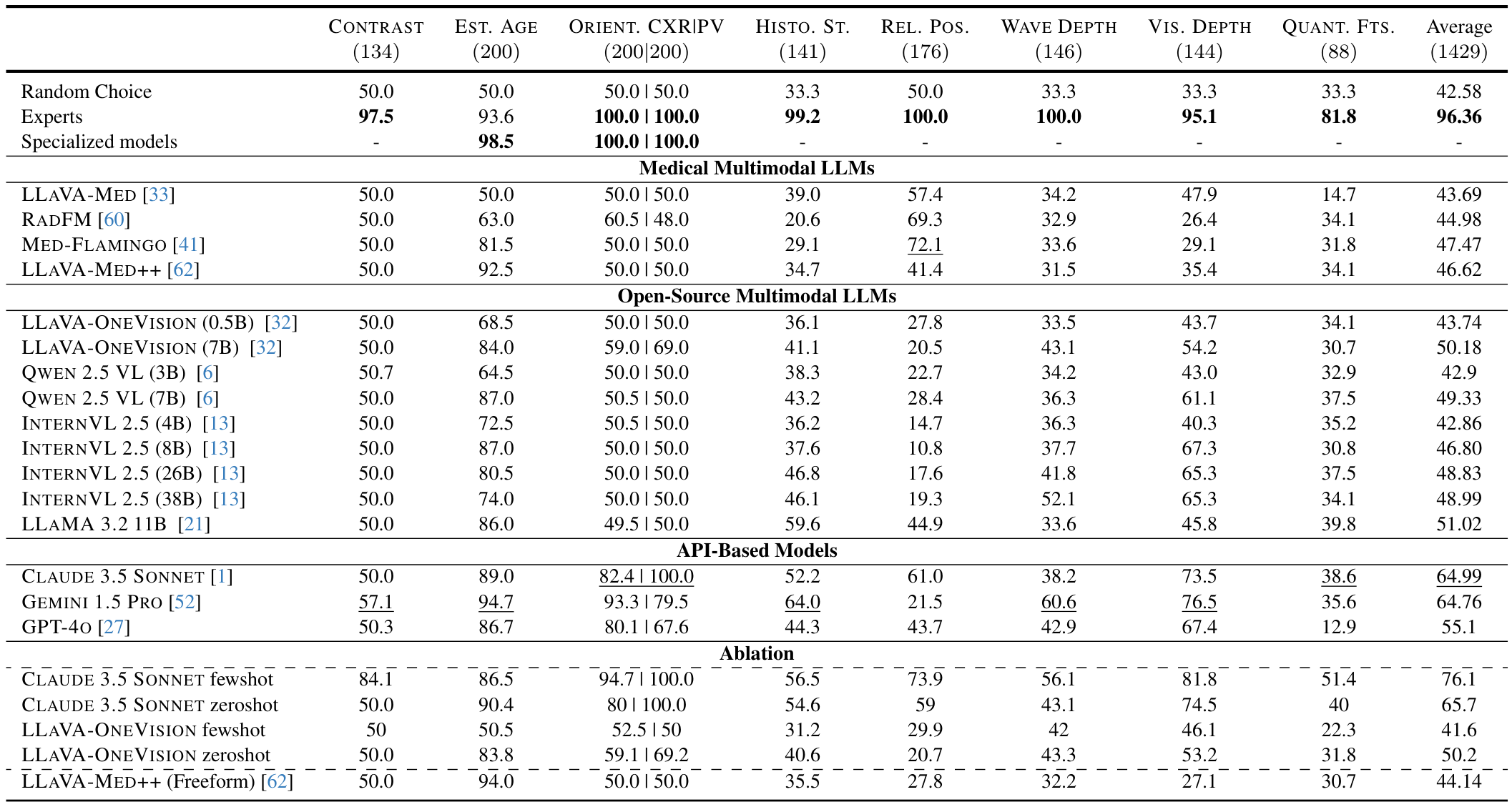
较大的模型在大多数任务上持续优于较小的变体。如表1所示,LLaVA-OneVision 7B的平均性能优于其0.5B版本(50.18% vs. 43.74%),Qwen 7B优于Qwen 3B(49.33% vs. 42.9%)。INTERNVL 2.5的参数扩展也显示出类似的趋势:从4B到8B提高了3.94%,从8B到26B提高了2.03%,从26B到38B仅提高了0.16%。这种规模效应在某些任务上尤为明显,例如从胸部X光估计年龄(LLaVA-OneVision为84.0% vs. 68.5%)和视觉深度估计(Qwen为61.1% vs. 43.0%),表明增加参数数量有助于复杂的感知推理任务。然而,在特定任务(如相对定位)上,这种趋势偶尔会逆转,LLaVA-OneVision 0.5B优于7B版本(27.8% vs. 20.5%)。
专业CNN轻松解决MEDBLINK任务。为了评估MEDBLINK中某些任务的固有难度,我们在三个任务的训练集上训练了ResNet-50模型:EsT. AGE、胸部X光方向和骨盆X光方向。在MEDBLINK相应的测试集上评估时,模型在EsT. AGE任务上达到了98.5%的准确率,在两个方向任务上均达到了100%。这些结果表明,这些任务在感知上足够简单,可以被小型卷积神经网络可靠地解决,凸显了当前MLMs的失败源于视觉 grounding 的局限,而非任务复杂性。
模型经常依赖启发式方法而非准确感知。在成像方向任务中,RADFM错误地将大多数翻转的胸部X光识别为正确方向,显示出对基本解剖方向的理解不足。同样,在组织学结构任务中,MED-FLAMINGO和RADFM经常默认预测蓝色点最接近皮肤表面,而不考虑点在不同组织层中的实际位置。在基于波的深度估计任务中,医学模型如MED-FLAMINGO、LLAVA-MED和RADFM,以及通用模型如GEMINI 1.5 PRO和CLAUDE 3.5 SONNET,经常默认预测红色点为答案。这表明模型依赖基于颜色的启发式方法或虚假相关性,而非准确感知医学图像中的深度信息。我们的分析揭示了模型在MEDBLINK任务中的反复失败模式。
尽管模型在深度和对比感知上失败,但推理显得自信。一些模型,包括GEMINI 1.5 PRO、GPT-4O和CLAUDE 3.5 SONNET,为其预测提供了解释/文本推理。在内窥镜图像的视觉深度估计任务中,这些解释并未反映图像中的实际深度关系。在利用CT切片的增强检测任务中,模型未能正确分类对比增强的CT图像,并给出了错误的解释,这表明它们可能未能检测到人类专家在执行这些任务时使用的关键解剖特征,例如主动脉。
4.4. 消融研究
以下是对论文中"4.4. Ablation Studies"部分的中文总结,保留了原文中的图片部分及其格式和位置。
模型在医学领域的空间推理能力如何?
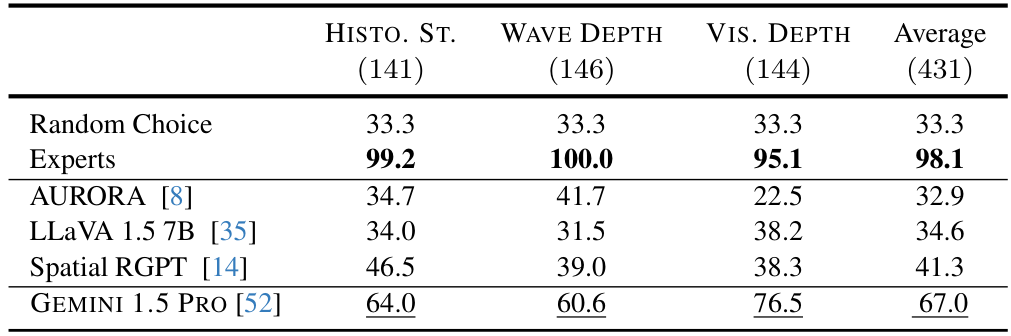
尽管近期模型在自然领域图像上的空间推理能力有所提升,但我们的结果(见表2)表明,这些进步并未转移到医学影像领域。专门为提升空间推理能力而开发的模型,如 SpatialRGPT,在需要视觉提示的任务中平均准确率仅为41.3%,仅略高于随机猜测(33.3%)。同样,AURORA 和 LLaVA1.5-7B 尽管在自然图像上表现不错,但在医学影像任务中接近随机水平。值得注意的是,Gemini 的表现较好(平均67.0%),但仍远低于专家水平的准确率(98.1%)。这些发现表明,医学影像中的空间推理提出了超越自然领域的独特挑战。
提示策略是否真的有帮助?
为探究提示策略的影响,我们在 LLAVA-MED++ 上测试了四种方法:自由形式(FF)、OmnimedVQA 的问答(OQA)、基于前缀(OPB)和多项选择(MC),涵盖 ORIENT. CXRIPV(CXR 子集)和 WAVE DEPTH 任务。表3显示性能变化很小。在 ORIENT. CXRIPV 上,所有方法均达到50%的准确率,表明提示影响微乎其微。在 WAVE DEPTH 任务中,FF 表现最佳(35.6%),比 MC 基准(34.2%)略高1.4%,而 OQA 和 OPB 表现较差,仅为33.6%。
此外,我们在 CLAUDE 3.5 SONNET 和 LLAVA-ONEVISION 两个模型上评估了少样本提示(见表1)。结果显示模型对少样本提示的敏感性差异很大:CLAUDE 3.5 SONNET 的准确率提升了10.4个百分点,而 LLAVA-ONEVISION 则下降了8.6个百分点。这种分歧表明少样本提示的效果因模型架构而异。

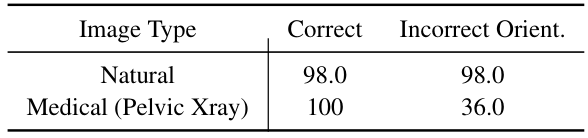
医学图像中的方向感知是否比自然图像更难?
表4的结果表明,多模态语言模型(MLMs)在医学图像的感知上存在困难。在实验中,我们从 ImageNet 中随机抽取200张图像(类别包括西伯利亚哈士奇、阿巴亚、实验室外套、餐桌、搬家车、皂液器),并随机翻转50%的图像,类似于图像方向任务。GPT-4o 在自然图像上的表现几乎完美,仅有两处错误。而在医学图像上,尽管模型在正确方向的扫描中达到人类水平,其在翻转骨盆X光片上的准确率大幅下降至36%。这种差距表明,尽管模型在一般感知能力上表现强劲,但在医学领域的方向理解上难以泛化,揭示了其在医学视觉感知上的脆弱性。
扩展或多样化 MEDBLINK 是否带来新见解?
MEDBLINK 通过关注前提感知任务来补充诊断推理。小规模精选样本(134个对比案例)持续揭示模型的失败,因此扩展规模并非必要。然而,我们通过扩展任务并使用 CLAUDE 3.5 SONNET 重新测试以验证这一点:EsT. AGE 从200个样本(89%)扩展到1000个(88.1%),WAVE DEPTH 从146个(38.2%)扩展到963个(41.3%)。结果证实扩展规模对性能无影响。在数据源多样性方面,我们评估了更改底层图像数据源对性能的影响,在 ORIENT. CXRIPV(CXR)任务中使用 ChexPert 数据集测试,结果为 CLAUDE 3.5 SONNET 86%,相比原始数据的82.4%,变化微小。这些发现表明,增加数据集规模或多样化图像来源均无法为当前模型的感知局限性提供额外见解。
模型能否在医学图像中检测并推理视觉提示?
MEDBLINK 中的任务2、3和4需要视觉提示。基于 BLINK 关于自然图像中颜色和大小影响的发现,我们研究模型是否能在医学图像中准确检测视觉提示的数量和空间位置(见表5)。模型在基本视觉提示检测中表现接近完美(任务3为100%,任务2为99%)。在垂直定位上,准确率在94.5%至95.1%之间,当彩色点间距至少10像素时进一步提升至96.3%-97.1%,因分离更清晰而易于检测。然而,水平位置检测显示出模态特定的差距:任务3(超声)保持高准确率(总体93.1%,间距>10px时为95.1%),而任务2(内窥镜)的表现显著下降(总体81.9%,间距>10px时为87.1%)。这表明内窥镜的视觉复杂环境对空间推理的挑战大于超声的简单灰度结构。总体而言,尽管模型能可靠地检测视觉提示的存在和位置,但难以在医学图像中解释其临床意义。
最后,我们在 WAVE DEPTH 任务上测试了 CLAUDE 3.5 SONNET 的视觉提示颜色-位置偏差,涵盖所有颜色-位置(红、蓝、绿)排列组合。6种排列的结果分别为:P1: 43.1%, P2: 43.8%, P3: 49.3%, P4: 41.8%, P5: 32.8%, P6: 41.4%,平均为42.0%,显示无位置偏差。

图像分辨率是否影响 MEDBLINK 任务的性能?
我们在两个应最受益于分辨率提升的任务上进行了额外分辨率实验:A) HISTO. ST. 和 B) VIS. DEPTH,使用 GPT-4O,因为可以通过 API 调用选择高低分辨率。结果为:A) 低分辨率:40.0%,高分辨率:37.9%;B) 低分辨率:68%,高分辨率:73.6%,显示分辨率对这些任务的性能影响微乎其微。
5. 研究意义
我们的研究结果对医学领域中多模态语言模型(MLMs)的设计和评估具有直接的影响。通过 MEDBLINK 的测试,我们发现当前模型,包括领先的通用模型和领域专用系统,在感知任务上的表现远低于人类水平(最佳模型准确率为 65%,而人类为 96.4%)。这一差距表明,许多模型缺乏基本的视觉 grounding,因此尚不能被信任用于临床应用。在将这些系统部署到高风险环境中之前,提升感知鲁棒性(如深度估计、计数和解剖结构识别)至关重要。MEDBLINK 提供了一个集中的基准测试,揭示了这些不足之处,并指导开发既满足临床性能需求又符合可信度期望的模型。
致谢
我们感谢 Arash Mahdavi 和 Kimia Adlparvar 在任务制定和评估方面提供的宝贵反馈。
MedBLINK:探索医学多模态语言模型的基本感知能力
补充材料 1
A. MEDBLINK 数据整理
A.1. 提示细节:文本和视觉提示
我们主要使用了两种类型的提示:文本问题和视觉提示。每个任务中使用的问题在表 9 中列出。我们在 3 个任务中使用了圆圈/点作为视觉提示。具体来说,对于两个深度估计任务,我们在 512x512 的调整后图像(原始尺寸为 112x112)上使用了 3 个(红色、绿色、蓝色)半径为 10 像素的彩色圆圈。对于组织学结构任务,我们使用了点的形式,其大小取决于全扫描图像(WSI)裁剪前的大小,具体来说,我们将圆圈的大小设置为 WSI 最大尺寸(宽度或高度)的 1/70。
A.2. 人类评估方法
我们从 4 名人类专家(3 名共同作者,1 名独立专家)中获取人类评估分数。每个任务至少由一名专家评估,平均分数被用作人类基准。
A.3. 基准统计数据
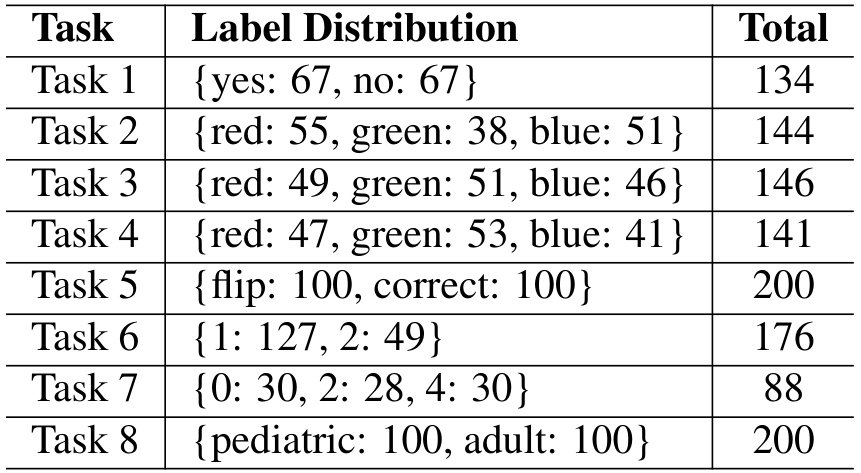
MEDBLINK 的统计数据可以在表 6 中找到,我们还在表 7 中列出了各个任务的标签分布和数量。

B. 基准模型细节
我们在 MEDBLINK 上测试了 19 个多模态语言模型,将所有模型的温度设置为 0,包括:
- GPT-40 27 版本
- CLAUDE 3.5 SONNET 1
- GEMINI 1.5 PRO 52
- QwEN 2.5 VL 6,具体来说,我们使用了 3B 和 7B 参数化的模型
- LLAVA-ONEV1SION 32,这里我们也使用了两个版本,分别是 0.5B 和 7B 参数化的模型
- LLAVA-MED 33
- MED-FLAMINGO 41,与其他模型不同,为了让 MED-FLAMINGO 产生有效响应,我们需要使用少样本提示 49。具体来说,我们使用 PMC-VQA 基准 66 中的三个问题和答案进行提示,如表 8 所示,遵循 MediConfusion 49 设置进行自由形式评估
- RADFM 60
- AURORA 8
- SpatialRGPT 14
- LLaVA 1.5 (7B) 35
- INTERNVL 2.5 13,我们使用了 4B、8B、26B 和 38B 参数化的模型
- LLAMA 3.2 11B 21
B.1. 小型专用模型
我们为一些任务训练了小型专用模型,这些任务拥有来自构建任务的原始数据集的大量训练集。我们在年龄估计和图像方向任务上对 ResNet-50 23 模型进行了微调。在训练过程中,我们使用了批大小为 32,按 80/20 比例划分数据集,每个模型训练 10 个周期,学习率为 1 × 1 0 − 3 1 \times 10^{-3} 1×10−3,衰减率为 1 × 1 0 − 4 1 \times 10^{-4} 1×10−4。
C. 失败案例的定性评估
在以下部分中,我们对失败案例进行了基于案例的定性分析,以更好地理解预测失败的模式,涉及的图表包括图4、图6、图5、图7、图8、图9、图10、图11、图12、图13。

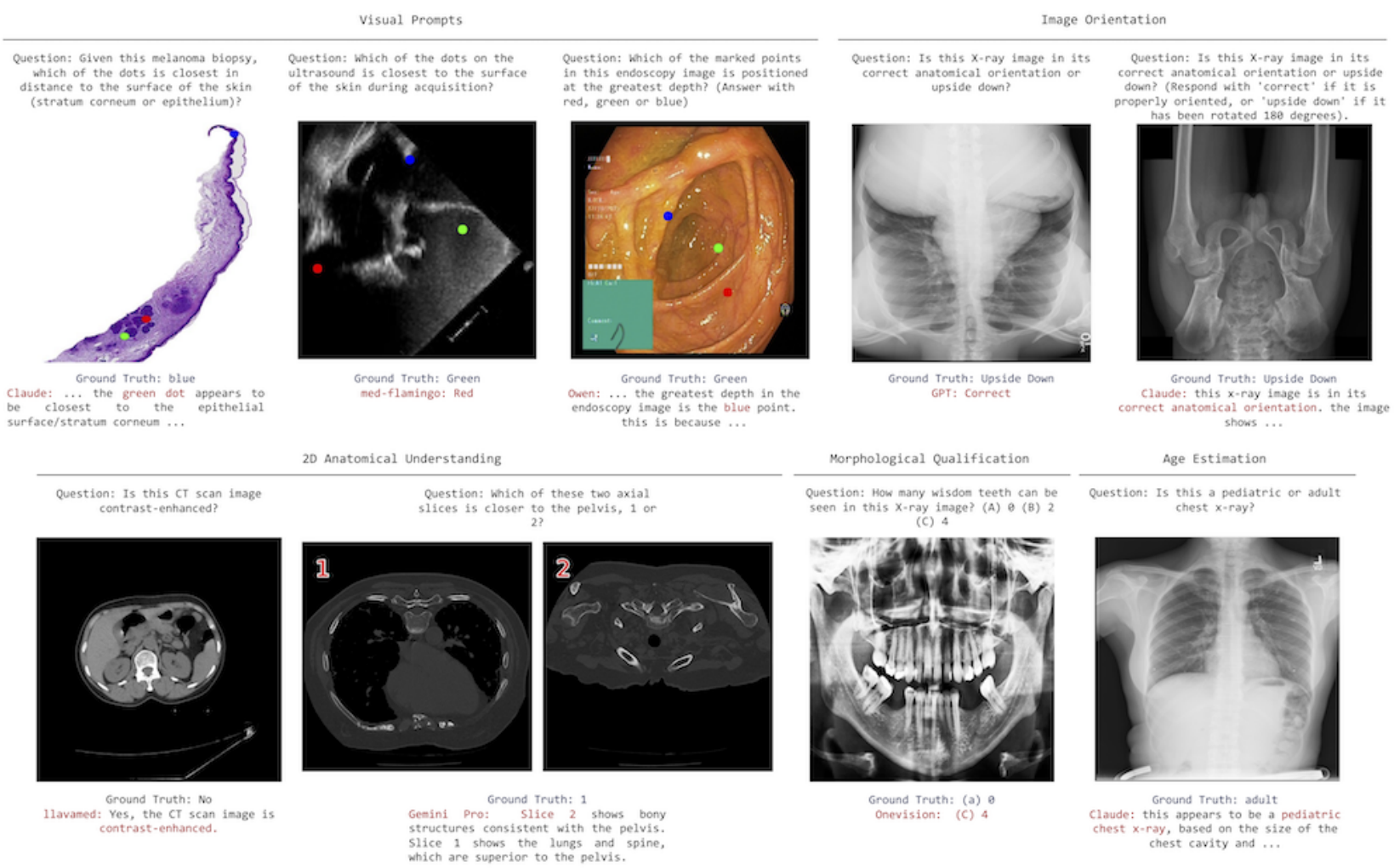
在观察内窥镜图像(似乎是大肠)时,红点似乎位于最深处。这可以通过观察肠壁的同心褶皱以及它们如何形成隧道状视角来判断,红点位于隧道最远处的可见褶皱中。
Qwen-VL
这张X光图像是否处于正确的解剖学方向,还是上下颠倒?(如果方向正确,请回答"correct";如果旋转了180度,请回答"upside down")。
correct # Figure 6. Example Failure Case in Anatomical Orientation Reasoning of MLM on pelvic X-Ray Images. Some models incorrectly classify upside-down pelvic X-Ray images as correct.
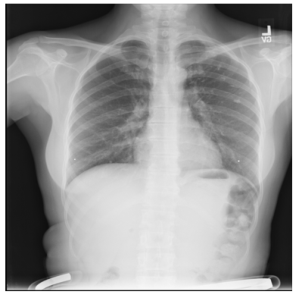
Figure 7. Example Failure Case in Age Estimation of MLM on Chest X-Ray Images. Some models incorrectly classify adult chest X-Ray images as pediatric and vice versa.
Question: Is this X-ray image in its correct anatomical orientation or upside down? (Answer with 'correct' if it is properly oriented, or 'upside down' if it has been rotated 180 degrees.)
这张胸部X光图像处于正确的解剖学方向。我们可以根据以下几点判断:1. 心脏尖指向左侧(符合正常情况);2. 膈肌在底部向上弯曲;3. 乳房组织阴影位于图像顶部;4. 脊柱排列正确(从上到下)。
Figure 8. Example Failure Case in Anatomical Orientation Reasoning of MLM on Chest X-Ray Images. Some models incorrectly classify upside-down chest X-ray images as upright, and vice versa.
Question: 'Which of the dots is closest to the surface of the skin? (Answer with red, green, or blue)'

Figure 9. Example Failure Case in Distance Reasoning of MLM on Pathology Images. Some models incorrectly identify one color to be the closest to the surface of skin, regardless of their location.
Question: Which of the dots on the ultrasound is closest to the surface of the skin during acquisition? (Answer with red or green)
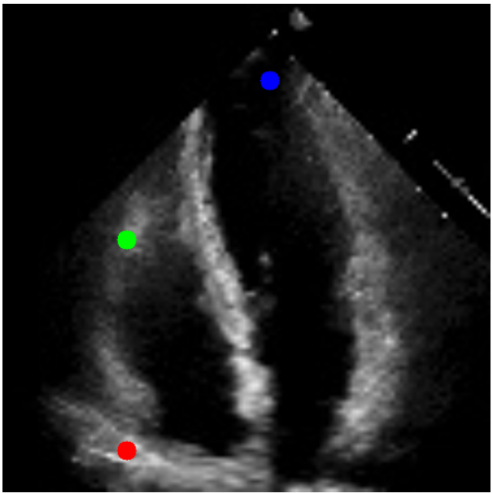 # Gemini Pro
# Gemini Pro
Red
Qwen-VL
最靠近皮肤表面的点是绿色点。
Question: Which of these two axial slices is closer to the pelvis, 1 or 2?
() (a) 0() aw u-x st u uaas aq us yaa wopsm Kuw mo
LLaVA-Med
Figure 12. Example Failure Case in Morphology Quantification. Some models fail to count the number of wisdom teeth, which are distinguishable morphological features.
Question: Is this CT scan image contrast-enhanced? (Answer with yes or no)
Original Abstract: Multimodal language models (MLMs) show promise for clinical decision support
and diagnostic reasoning, raising the prospect of end-to-end automated medical
image interpretation. However, clinicians are highly selective in adopting AI
tools; a model that makes errors on seemingly simple perception tasks such as
determining image orientation or identifying whether a CT scan is
contrast-enhance are unlikely to be adopted for clinical tasks. We introduce
Medblink, a benchmark designed to probe these models for such perceptual
abilities. Medblink spans eight clinically meaningful tasks across multiple
imaging modalities and anatomical regions, totaling 1,429 multiple-choice
questions over 1,605 images. We evaluate 19 state-of-the-art MLMs, including
general purpose (GPT4o, Claude 3.5 Sonnet) and domain specific (Med Flamingo,
LLaVA Med, RadFM) models. While human annotators achieve 96.4% accuracy, the
best-performing model reaches only 65%. These results show that current MLMs
frequently fail at routine perceptual checks, suggesting the need to strengthen
their visual grounding to support clinical adoption. Data is available on our
project page.
PDF Link: 2508.02951v1
部分平台可能图片显示异常,请以我的博客内容为准
