目录
在自然语言处理(NLP)中,语义分析是理解语言深层含义的核心任务,其目标是让计算机能够像人类一样解析文本的意义,包括词语、句子乃至篇章的含义,以及它们之间的逻辑关系。
一、语义学概述
语义学(Semantics)是研究语言意义的学科,主要关注语言符号(如词语、句子)与它们所指代的事物、概念或情境之间的关系。
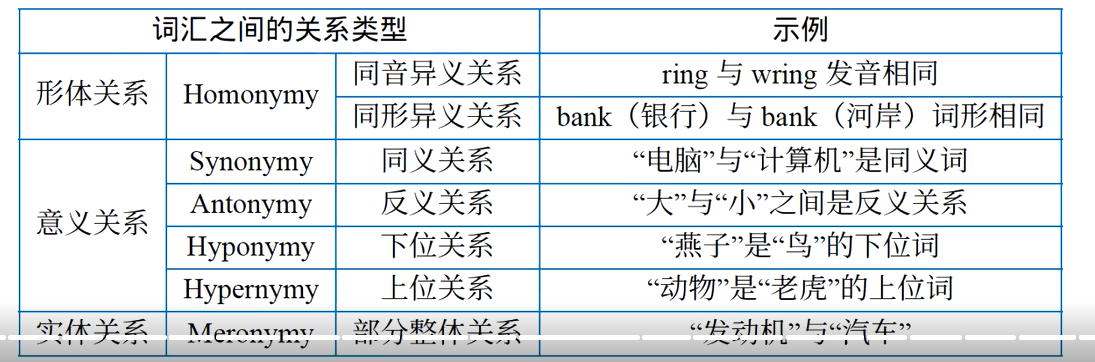
- 词汇语义:研究单个词语的意义以及词汇之间的相互关系【形体、意义、实体】,包括词义的内涵、外延、多义性(如 "银行" 可指 "金融机构" 或 "河岸")、同义 / 反义关系(如 "高兴" 与 "开心" 是同义,"高" 与 "矮" 是反义)等。
WordNet是目前最常用的英语词汇知识资源库。在其中词汇按照义项组合成同义集(Synset)每个义项表达不同的概念。名词、动词、形容词和副词各自独立的组合成网络。
- 句子语义:研究句子的整体意义以及句子之间的相互关系【同义、反义、蕴含、预设】,包括句子的真值条件(句子为真的情境)、歧义性(如 "咬死了猎人的狗" 可理解为 "狗咬死了猎人" 或 "猎人的狗被咬死了")、以及句子之间的逻辑关系(如蕴含、矛盾、同义)。
- 篇章语义:研究多个句子组成的篇章的意义,关注句子之间的连贯性(如指代关系 "小明买了一本书,他很喜欢它" 中 "他" 指代 "小明","它" 指代 "书")、因果关系等。
二、语义表示
语义表示(Semantic Representation)是将自然语言的意义用结构化、形式化的符号系统表示出来的过程,是计算机处理语义的基础。其核心目标是让不同的语言表达(如 "小明打了小红" 和 "小红被小明打了")具有一致的语义表示,从而实现意义的等价性计算。
1、谓词逻辑表示法【早期】
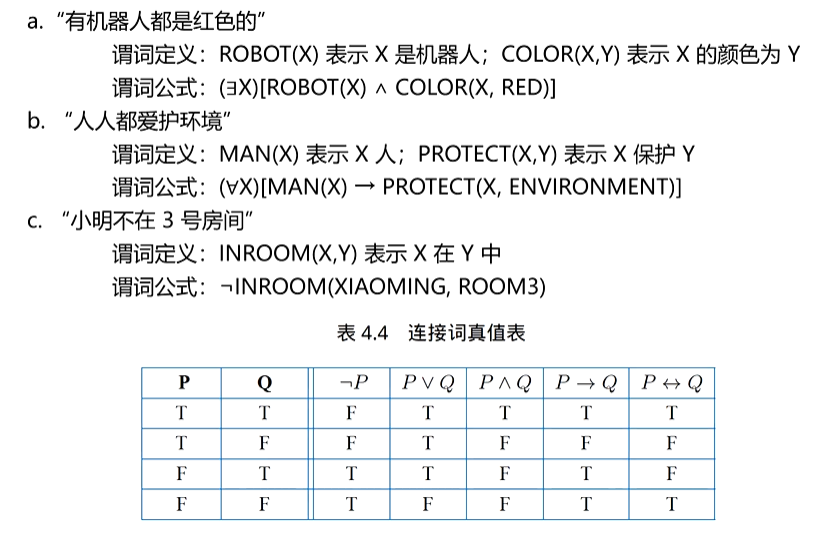
自然语言的语义表示中也经常采用数理逻辑的方法。其中常用的是谓词逻辑(Predicate Logic)和命题逻辑(PropositionalLogic), 谓词逻辑 可以更细致的刻画语义,可以表示事物的状态、属性、概念等事物性语义,也可以表示因果关系等规则性语义。
除了直接使用单个谓词和指代对象的常量、变量或者函数组成原子公式之外,还可以使用 5种逻辑连接词和量词构造复杂的表示,就是谓词逻辑中的公式。原子公式是谓词演算的基本组块,运用连接词可以组合多个原子公式,以构成更加复杂的公式。

2、框架表示法
框架(Frame)表示法是以框架语义理论为基础发展起来的一种语义表示方法。框架用来表示所讨论对象(一个事物、概念或者事件)的语义。每个框架由若干**槽(Slot)**组成,描述框架所讨论对象的某一方面的属性。

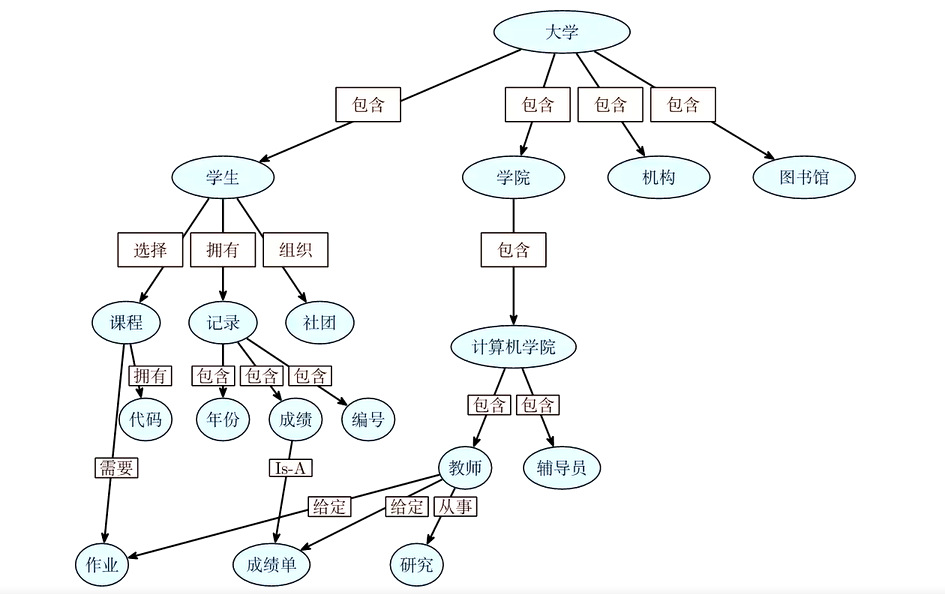
3、语义网表示法
语义网络(Semantic Network)是一种用实体及其语义关系来表达知识和语义的网络图。语义网
络由节点和弧组成:节点表示各种事件、事物、概念、属性、动作等,也可以是一个语义子网络;
弧表示节点之间的语义关系,并且是有方向和标注的,方向表示节点间的主次关系且方向不能随意
调换。
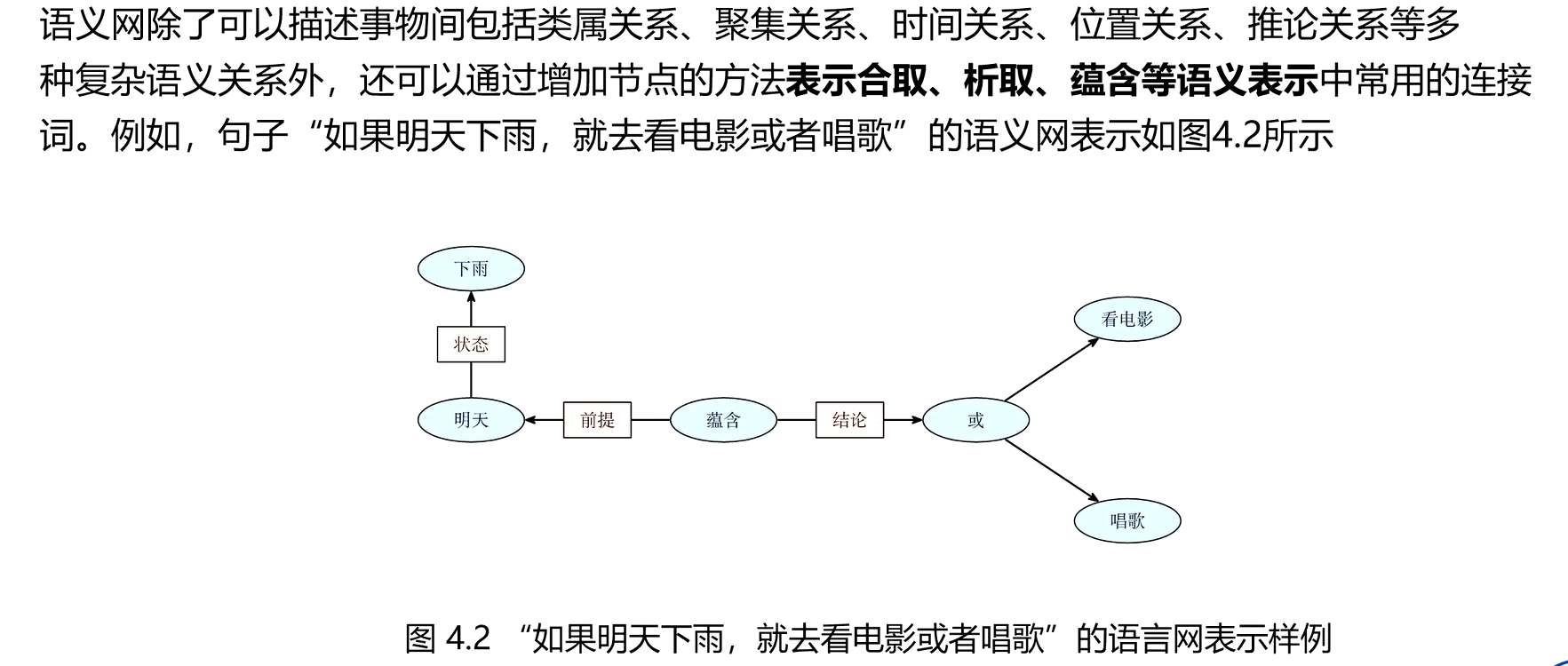
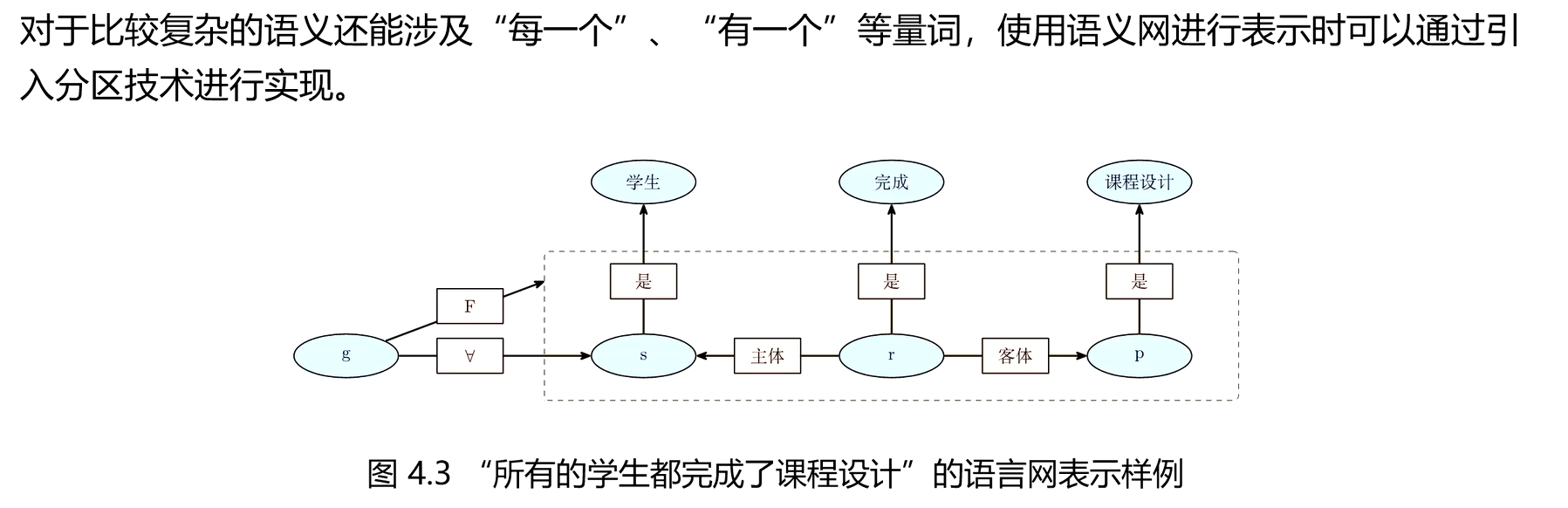
三、分布式表示
分布式表示提出之前,许多自然语言处理算法采用独热表示(One-hot Representation),其中每个维度表示某个单词是否在该文中出现。独热表示的维度和词表的大小一致,存在表示稀疏性的问题,而且无法表示单词之间的语义相似度, 分布式表示通过将文本表示为低维空间下稠密的向量,并在低维表示空间中利用表示向量之间的计算关系,体现文本间的语义关联,有效地解决了这一问题。当应用在下游任务时,文本分布式表示也体现出良好的泛化能力,而且能有效地编码任务所需要的语法和语义信息
向量空间模型(VSM)阐述了将单词和篇章表示为向量的思想。对文本的处理可以直观地映射到向量空间,体现为对文本向量的加法、减法、距离度量等操作;将向量化的文本作为输入,从而直接将统计学习与机器学习算法应用在自然语言处理应用上。
1、单词分布式表示

相比于独热表示,分布式表示可以编码不同单词之间的语义关联。如上例中,如果采用独热表示,"计算机"与"电脑"以及"计算机"与"冰激凌"之间的相似度都相同。但是采用分布式表示可以
使得"计算机"和"电脑"在大多数维度上相近,这样"计算机"和"电脑"的向量之间的距离可以远小于 "江算机"和"冰激凌"之间的距离。
单词分布式表示的目标,即在向量空间建构单词之间的语义关联,使含义相近的单词有相似的向量表示。这自然地引出了两个问题:(1)如何衡量单词语义的相近;(2)如何衡量表示的相似性。 
(1)基于共现矩阵奇异值分解的词向量模型
共现矩阵,是一种表示文本数据中词汇之间关系的矩阵。通常根据文本窗口来确定词汇的共现关系,即共现矩阵,它是一种表示文本数据中词汇之间关系的矩阵。通常根据文本窗口来确定词汇的共现关系,即在一个固定大小的窗口内,统计词语之间的共现次数。例如,在句子 "I like apples and bananas" 中,若窗口大小为 3,那么 " I" 和 "like"、"like" 和 "apples" 等就会被视为共现,共现矩阵的元素记录了这些共现次数。。例如,在句子 "I like apples and bananas" 中,若窗口大小为 3,那么 " I" 和 "like"、"like" 和 "apples" 等就会被视为共现,共现矩阵的元素记录了这些共现次数。


(2)基于上下文单词预测词向量模型
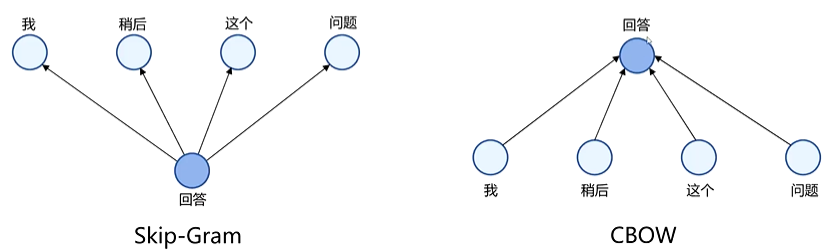
基于上下文单词预测词向量模型的典型代表是 Word2Vec,它包含连续词袋模型(CBOW)和跳字模型(Skip - Gram)两种架构。
-
连续词袋模型(CBOW) :

- 目标 :根据上下文预测中心词。
- 原理:对于句子中的每个词,以它为中心,取其前后的若干个词作为上下文。将上下文词的 one - hot 向量输入到神经网络中,通过投影层将这些稀疏的 one - hot 向量转换为密集的词向量,然后通过隐藏层进行计算,最后通过输出层的 softmax 函数,计算每个词库中的词作为中心词的概率,选择概率最高的词作为预测结果。
- 特点:CBOW 通常比 Skip - gram 训练更快,因为它用多个上下文词来预测一个中心词,对高频词效果较好,对小数据集更有效。不考虑顺序
-
跳字模型(Skip - Gram) :

- 目标 :根据中心词预测上下文词。
- 原理:将中心词的 one - hot 向量输入到神经网络中,通过投影层将其转换为词向量,然后通过隐藏层,对于每个可能的上下文位置,都有一个独立的输出层,通过 softmax 计算该位置出现每个词的概率。训练时,调整词向量以 最小化预测上下文词的误差。
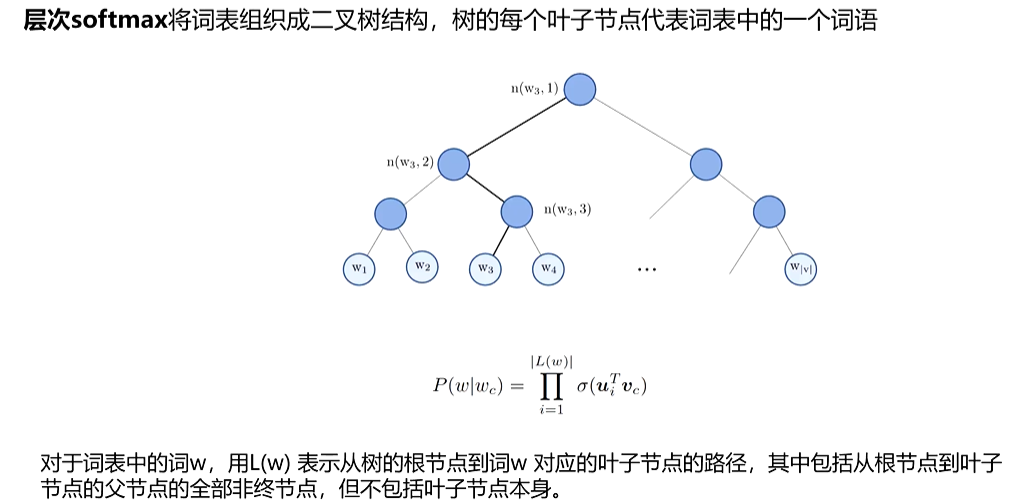
- 特点:Skip - gram 通常在大型数据集上表现更好,尤其是对生僻词的处理,因为它试图将一个词传播到更广泛的上下文中。虽然计算量看起来更大,但 Word2Vec 使用了负采样或层次 softmax 等技巧来加速训练。会考虑顺序

(3)全局向量GloVe模型
Sikp-Gram和CBOW模型根据局部信息进行学习,而LSA模型则基于词共现矩阵全局信息得到词语表示,全局统计信息和局部信息都对词表示学习提供有效信息。全局向(GlobalVectors forWord Representation,GloVe)模型则结合了上述模型的思想,从共现概率的角度分析并改进了Skip-Gram模型,即使用文本中局部的上下文信息,又对语料库的全局共现统计数据加以利用。


(4)基于字节对编码的字词表示模型
背景:

原理:

举例:

(5)单词分布式表示评价和应用
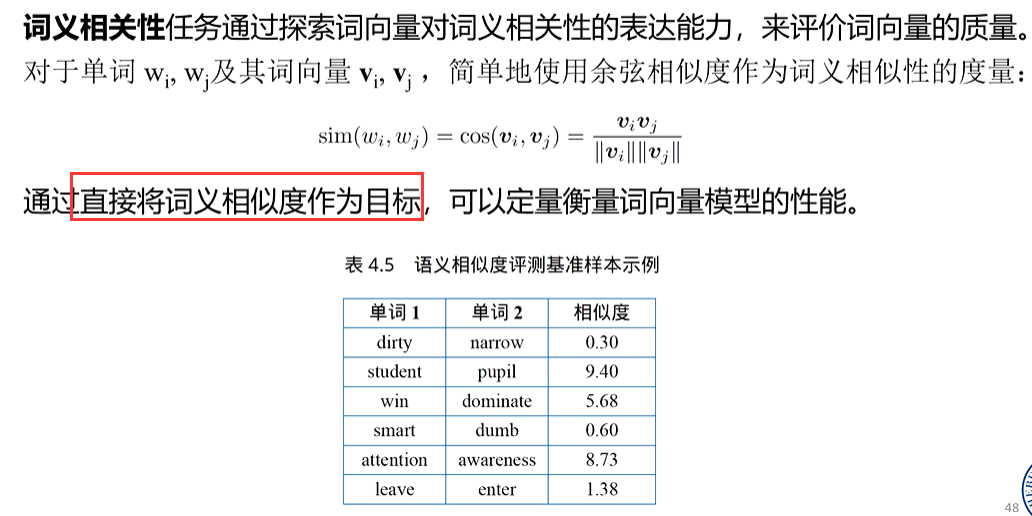
单词分布式表示模型的定量评估方法主要分为内部评价(IntrinsicEvaluation)和外部评价(Extrinsic Evaluation)两种方法
内部评价方法通常基于一个特殊设计的辅助任务 ,这个辅助任务探测词向量应该具有的某种性质如词义相关性、类比性等,并最终返回一个分数,来表示词向量的好坏,从而帮助我们理解词
向量模型的特点。
外部评方法通常基于一个实际应用任务,通过将词向量作为该任务的输入表示,比较不同词向量模型在该任务上的性能,来选择适合于该任务的词向量模型。
2、句子分布式表示
句子分布式表示主要用于句子级别的任务,如情感分析、文本推理、语义匹配等。对于句子级别表示的构建,不但要考虑句子中所包含单词的语义,也要考虑句子内部词之间的关系,即词的共现信息和句子语义之间的联系。还要考虑句子和句子之间隐含的语义相似性,以及其他的语义关系。这些性质对于句子级别的下游应用任务都很重要。
(1)skip-Thought模型
Skip-Thought模型借鉴了Skip-Gram模型的思想,认为可以基于一个句子预测出其上下文的句子,并以此作为监督信号,学习句子之间的语义关系,得到句子表示模型。

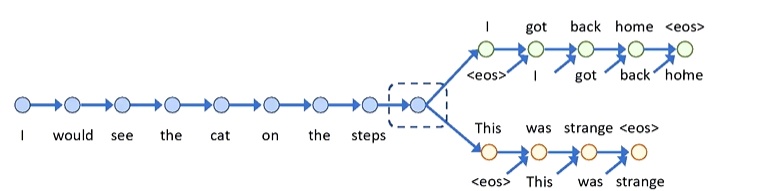
- 输入句子(如示例中 "I would see the cat on the steps" ),经编码器(常为循环神经网络及其变体,像 LSTM、GRU )处理,将句子序列转化为固定维度向量,捕捉句子语义信息,形成初始句子表示。
- 预测阶段:基于编码得到的句子表示,构建预测模块,去生成或判别上下文句子(如 "I got back home""This was strange" )
(2)Sent2Vec句子表示模型

3、篇章分布式表示
在自然语言处理和信息检索领域,部分任务会要求模型学习并表示文档级别的特征,如文档检索、文档去重、文档级情感分析、主题识别等任务。相对一般nlp任务,这类任务不需模型精确地捕获细粒度的词句信息,但需模型建模文档的主题、包含的关键词等信息。
(1)词频-逆文档频率(TF-IDF)篇章表示方法

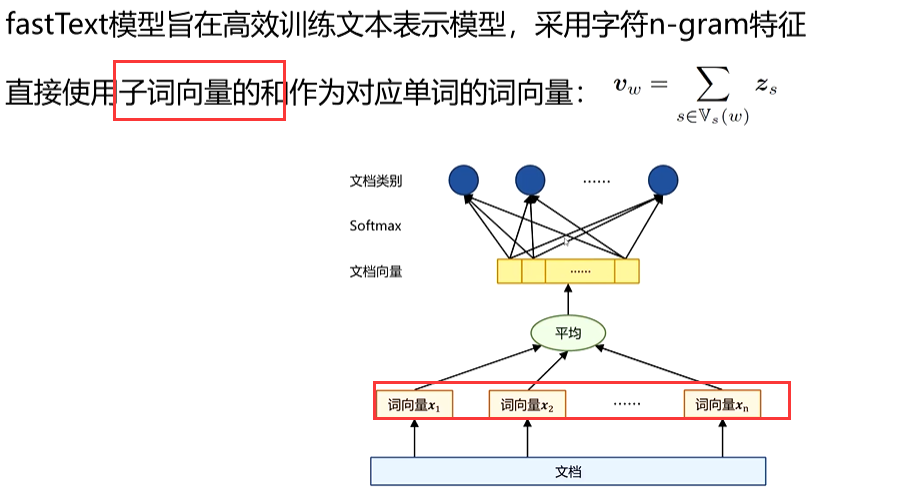
(2)fastText篇章表示模型
对于一个句子或篇章,fastText 会将其中所有词以及 n-gram 词的向量进行简单的叠加平均(或者其他聚合方式),从而得到整个句子或篇章的向量表示
四、词义消歧
词义消歧是在给定上下文中,确定多义词所表达的正确含义 的过程。
例如,"苹果"在"我买了一个苹果"中指水果,而在"苹果公司发布新手机"中指公司。
1、基于目标词上下文的词义消歧方法
利用目标词周围的上下文信息(词语、句法结构等)来推断其含义。
不依赖外部知识库,只需要足够的标注数据,对新词义适应较快;但对稀有词义和长距离依赖不敏感,数据标注成本高。
常用方法包括:
-
基于特征的机器学习方法
-
提取上下文窗口内的词(bag-of-words)、词性(POS)、依存句法等特征
-
使用分类模型(如决策树、SVM、朴素贝叶斯)进行训练
-
-
深度学习方法
-
将上下文编码为向量(word2vec、BERT 等)
-
使用上下文嵌入直接预测词义
-
句子:银行附近有很多树
上下文词:附近、有、很多、树
模型推断"银行"为"河岸"而不是"金融机构"
2、基于词义释义匹配的词义消歧方法
将上下文与词典(如WordNet)中的词义解释进行匹配,选择最相似的释义。
典型方法
-
Lesk 算法
-
计算上下文词与词义定义(gloss)的重叠程度
-
重叠最多的词义被选为结果
-
-
改进 Lesk
-
扩展词义定义(包含同义词、例句)
-
使用词向量计算相似度而不是纯词面匹配
-
句子:我去银行取钱
词典定义:
银行① 金融机构
银行② 河岸
上下文和定义①有"取钱"高度相关 → 选①
3、基于词义知识增强预训练的消歧方法
利用知识库(如WordNet、HowNet、BabelNet)将词义信息融入预训练模型,使模型在表示时区分不同词义。
代表方法
-
GlossBERT
- 将词义定义和上下文一起输入BERT,预测匹配概率
-
SenseBERT
- 在BERT预训练阶段加入"词义预测任务"
-
K-BERT / ERNIE
- 将知识图谱中的实体、概念信息注入到Transformer结构中
4、词义消歧评价方法
常见评估指标
-
准确率(Accuracy):预测正确的比例
-
宏平均F1值(Macro-F1):对每个词义计算F1,再取平均
-
微平均F1值(Micro-F1):整体计算F1
常用评测任务
-
SemEval(国际语义评测任务)
-
Senseval(早期评测任务)
评价方式
-
有监督WSD:在标注语料上进行交叉验证
-
无监督WSD:用外部任务(如翻译准确率)间接评估
5、词义消歧语料库

五、词义角色标注
定义 :
词义角色标注是一种语义分析任务,用来确定句子中谓词(通常是动词)及其相关的语义论元(谁做了什么,在什么情况下等)。它相当于给句子建立一个**"语义框架"**,标明动作的发出者、接受者、方式、时间等信息。
例如:
"小王在图书馆读书。"
谓词:读(read)
论元:
A0(施事者):小王
A1(受事物):书
AM-LOC(地点状语):图书馆

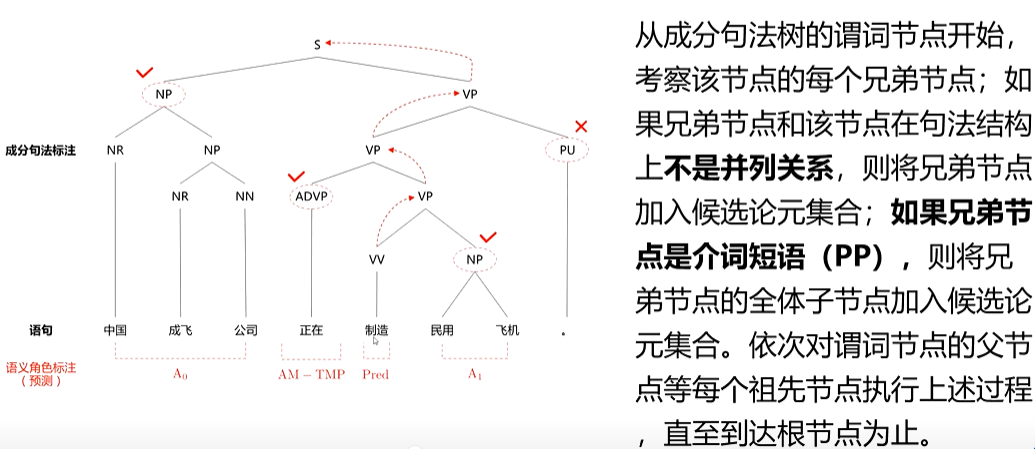
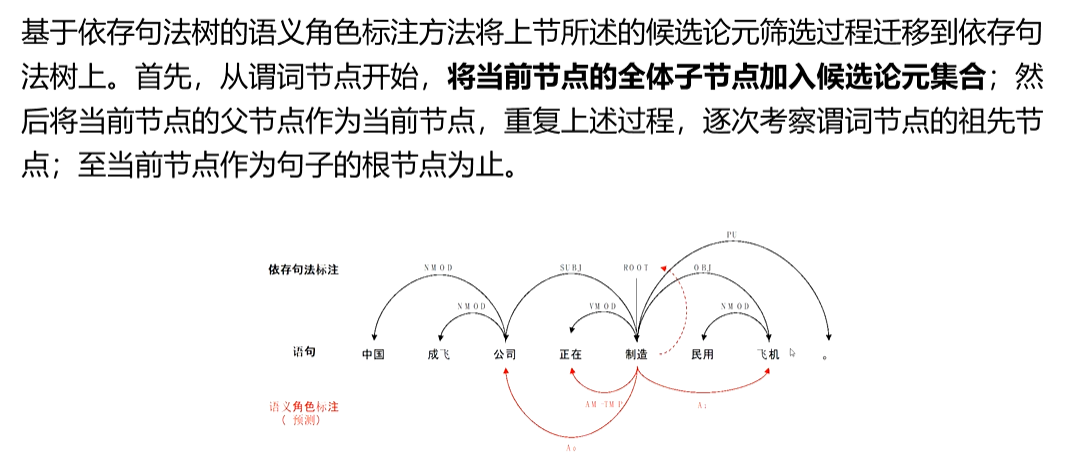
1、基于句法树的语义角色标注方法
句法结构主要有成分结构和依存结构两大类。因此,依赖句法结构的语义角色标注算法可以进细分为:基于成分结构的语义角色标注(Span-BasedSRL)和基于依存形式的语义角色标注
(Dependency-Based SRL)
(1)基于成分

(2)基于依存
2、基于深度神经网络的语义角色标注方法。
直接基于句子词序列,使用深度学习模型自动学习特征,减少人工规则依赖。
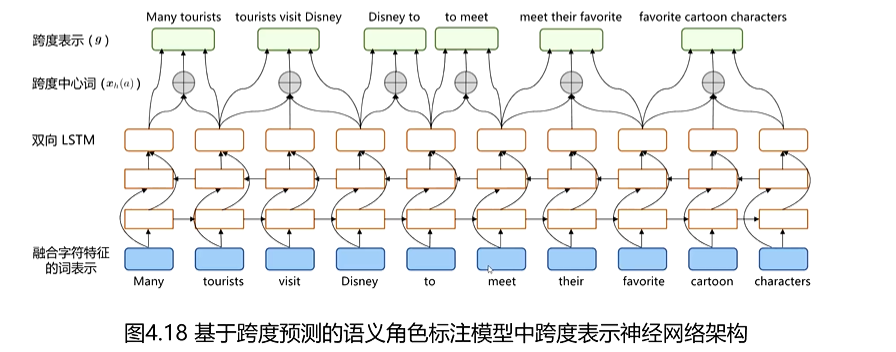
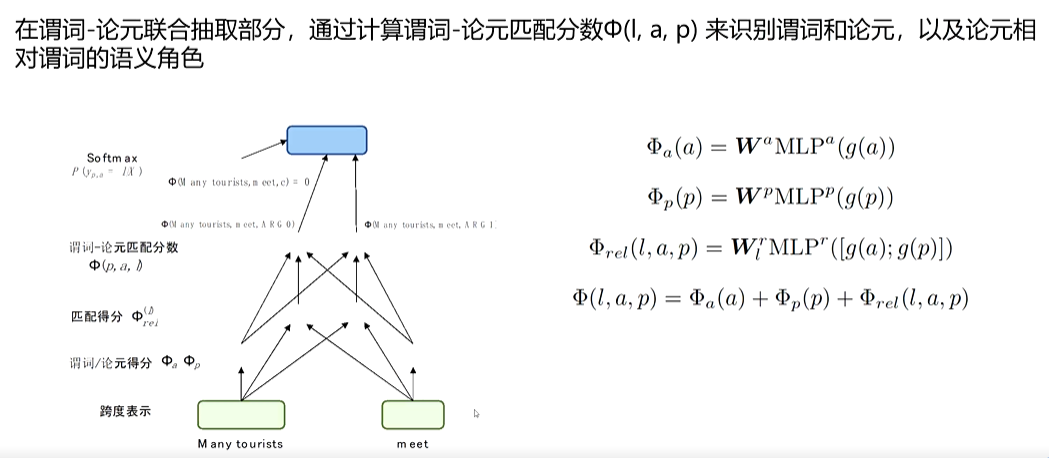
(1)基于跨度
为语句中的每个词和跨度构造表示,实现同时识别句子中的谓词和论元并判断它们之间关系的效果。该模型分为两个部分,词和跨度表示的构建以及谓词-论元的联合抽取
3、语义角色标注评价方法
在预测结果中,仅当论元范围和类型均预测正确时,才视为该论元预测正确计为真正例(True-Positives,TP)。
-
精确率(Precision):预测正确的论元数量 / 预测的论元总数。
-
召回率(Recall):预测正确的论元数量 / 真实论元总数。
-
F1值(F1-score):精确率与召回率的调和平均。
-
有时会分为:
-
识别正确率(只看是否找到了论元)
-
分类正确率(还要看角色标签是否正确)
-
4、语义角色标注语料库
常见中文语料库:
-
中文PropBank(CPB):参照英文PropBank建立,包含谓词-论元标注。
-
中文FrameNet:基于框架语义理论,包含丰富的语义场景和角色信息。
-
哈工大LTP语料:包含分词、词性、依存句法、语义角色标注等。
常见英文语料库:
-
PropBank(Penn TreeBank扩展版)
-
FrameNet(加州大学伯克利分校)
-
CoNLL共享任务数据集(常用于SRL模型评测)