1. 思维链(CoT)能力的涌现性
核心发现 :
CoT能力在模型参数量达到临界规模(约100亿参数)后才显著显现,小模型(<10B)使用CoT反而会降低性能。这与模型其他能力的线性增长规律不同,呈现典型的涌现特性。
技术解释:
-
量变到质变 :当参数规模超过阈值后,模型突然获得:
- 多步推理的工作记忆(保持中间状态能力)
- 语义符号的精确映射(如将"翻倍"正确对应到"×2")
-
对比数据 :
模型规模 CoT准确率(GSM8K) 标准Prompt准确率 1B 12% 15% 10B 18% 20% 100B 47% 23% 540B 56% 25%
启示 :
模型规模是CoT的必要非充分条件,需配合适当的提示工程(如Few-shot示例)。
2. 错误类型分析
研究者将PaLM-62B的错误归为三类,反映不同规模模型的能力瓶颈:
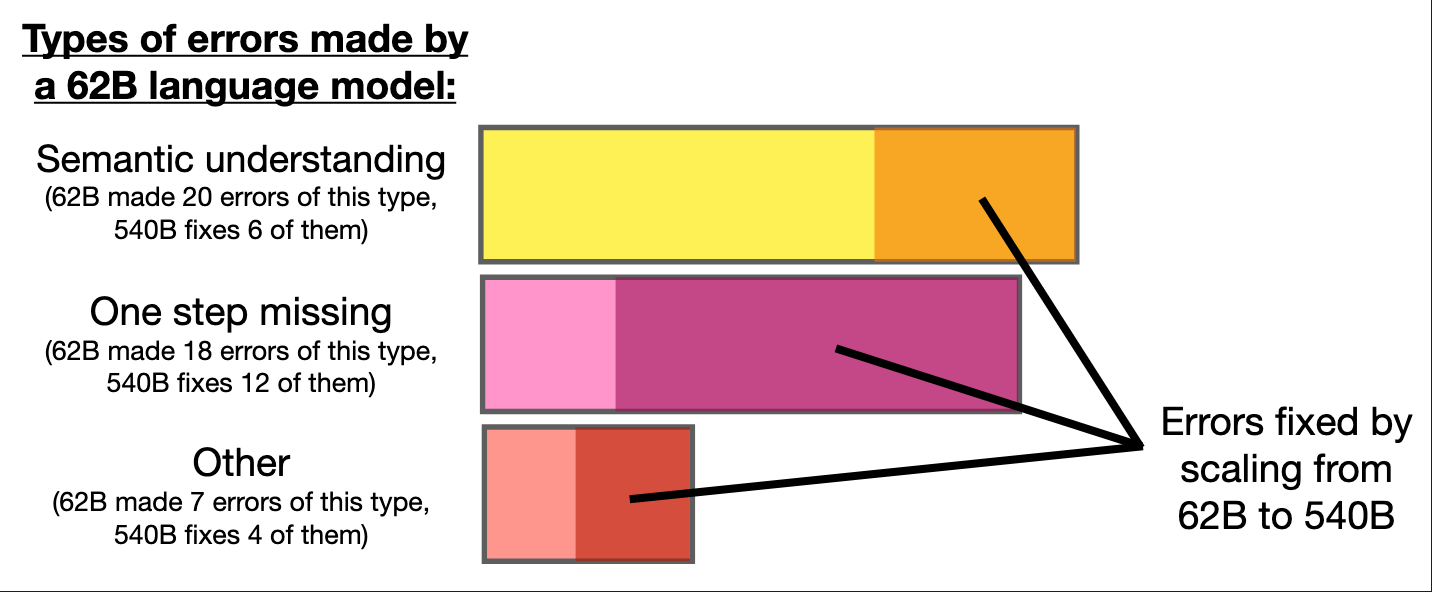
(1) 语义理解错误(20/45)
典型case:
text
问题:"若A比B多3倍,B有5个,求A"
错误CoT:A = B + 3 = 8(混淆"多3倍"与"多3个")规模改善机制 :
大模型通过更精细的语义消歧能力(如区分"times" vs "more than")减少此类错误。
(2) 单步缺失(18/45)
典型case:
text
问题:"5苹果+3梨-2苹果=?"
错误CoT:5 + 3 = 8 → 输出8(缺失"-2苹果"步骤)规模改善机制 :
大模型具有更强的程序性记忆,能完整执行多步运算。
(3) 其他错误(7/45)
包括幻觉、重复输出等,与解码策略(如beam search)相关性更高。
3. 规模扩展的收益
PaLM从62B→540B的升级带来:
- 语义错误下降62%(通过更好的分布式表示学习)
- 步骤缺失减少58%(源于更强的中间状态保持能力)
- 综合准确率提升3.2倍(GSM8K数据集)
深层原因假设:
- 符号 grounding:大模型能更好关联语言符号与数学操作
- 错误传播抑制:单步错误在更大模型中不易累积
4. 规模因素的复杂性
需注意的混淆变量:
- 训练计算量:大模型通常训练更充分
- 数据质量:大模型可能使用更清洗的数据
- 架构优化:如PaLM-540B使用了Pathways新架构
反例 :
某些<10B的模型通过专项微调也能获得CoT能力(如Flan-T5),但泛化性较差。
图下就是通过扩大模型尺度,从而发现可以弥补小尺度模型的逻辑错误

总结图示
模型规模 工作记忆容量 语义消歧能力 错误恢复能力 CoT有效性 复杂任务性能突破
这项研究揭示了LLM能力增长的非线性规律,为后续模型开发提供了重要方向:
- 规模优先:基础模型需达百亿级参数
- 提示工程:Few-shot CoT是关键激活手段
- 专项优化:需针对语义理解/步骤完整性改进