随着大语言模型(LLM)技术的快速发展,构建基于大模型的应用已成为企业智能化转型的核心路径。然而,从原型验证到生产部署,开发者面临着模型集成、数据处理、流程编排等多重挑战。本文将系统介绍现代大模型应用开发的三大核心工具链------LangChain框架、RAG技术及Prompt Engineering,剖析其架构原理、应用场景及最佳实践,帮助开发者高效构建智能应用。
一、LangChain:大模型应用开发的一站式框架
LangChain已成为GitHub星标超107K的大模型应用开发事实标准,日均下载量超过52万次,支持Python和JavaScript/TypeScript双语言生态。作为模块化的开发框架,它通过可组合的组件抽象,显著降低了LLM应用开发门槛。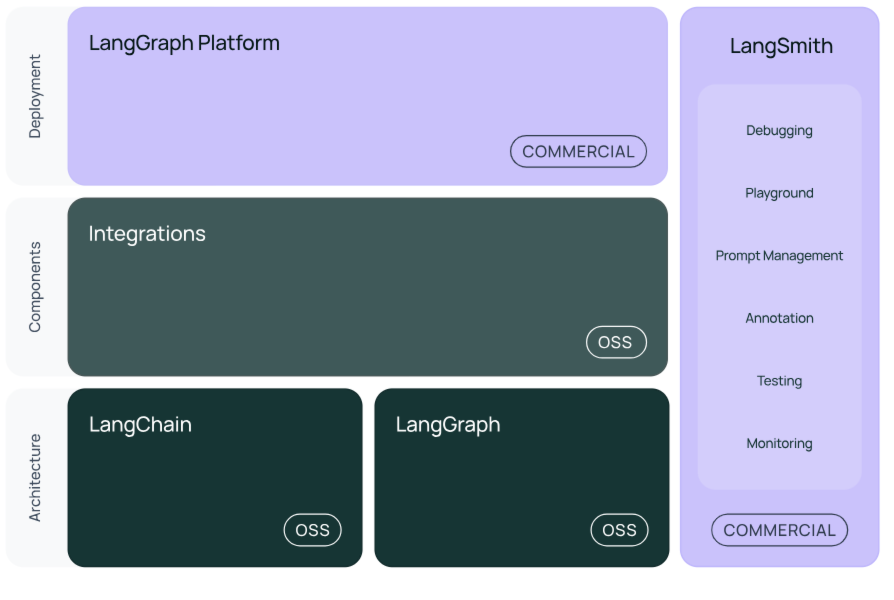
1. 核心架构与组件体系
LangChain的模块化设计涵盖了大模型应用开发的完整生命周期:
-
Model I/O模块:统一不同模型的调用接口
from langchain.chat_models import ChatOpenAI
model = ChatOpenAI(temperature=0.7) # 支持OpenAI、Anthropic、Google Vertex等
response = model.predict("推荐三部科幻电影") -
检索增强模块:支持多源数据加载与RAG实现
from langchain.retrievers import WikipediaRetriever
retriever = WikipediaRetriever() # 支持PDF/CSV/SQL/VectorDB等多种数据源 -
流程编排模块:通过Chain实现复杂任务流
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=db.as_retriever(),
chain_type="stuff" # 支持多种链式操作
) -
智能代理模块:动态工具调用能力
from langchain.agents import initialize_agent, Tool
tools = [Tool(name="Search", func=DuckDuckGoSearchRun().run)]
agent = initialize_agent(tools, llm, agent="zero-shot-react-description")
agent.run("2024年诺贝尔文学奖得主是谁?")
2. 生产级工具链支持
LangChain不仅提供开发框架,还配套了完善的运维支持:
- LangSmith:提供调试、测试与监控功能,支持全生命周期管理
- LangServe:将链封装为REST API,简化部署流程
- 性能优化:支持批量处理、异步调用及并行化操作,内置回退机制保障稳定性
3. 典型应用场景
- 文档问答系统:结合RAG技术实现基于企业知识库的智能问答
- 智能客服机器人:通过Memory模块保持多轮对话上下文
- 数据提取与转换:从非结构化文本中提取结构化信息
LangChain的模块化设计使其成为构建复杂LLM应用的首选框架,特别适合需要灵活定制开发流程的企业场景。
二、RAG技术:检索增强生成的工程实践
检索增强生成(Retrieval-Augmented Generation)已成为解决大模型幻觉问题、接入企业私有数据的标准技术路径。根据实际需求,开发者可选择不同成熟度的RAG解决方案。
1. RAG技术架构解析
标准RAG流程包含四个核心环节:
-
数据预处理:文档加载→文本分块→向量化
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
docs = text_splitter.split_text(text) # 优化chunk策略提升检索精度 -
向量存储:构建可高效查询的嵌入索引
from langchain.vectorstores import FAISS
db = FAISS.from_texts(docs, embeddings) # 支持FAISS/Pinecone/Weaviate等 -
检索排序:多阶段召回提升相关性
retriever = db.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": 0.8} # 阈值过滤低质量结果
) -
生成优化:增强Prompt构造减少幻觉
prompt_template = """基于以下上下文回答:
{context}
问题:{question}
答案需包含引用来源"""
2. 开源RAG框架对比
根据开发需求,RAG解决方案可分为两类:
开发库型(高灵活性):
- LangChain:提供RAG完整组件,适合深度定制
- LlamaIndex:专为RAG优化的轻量级方案,十几行代码即可实现
- Haystack:强调搜索系统集成,适合NLP应用
框架型(开箱即用):
| 框架 | 核心优势 | 适用场景 |
|---|---|---|
| Dify | 可视化Pipeline编排,快速原型开发 | 企业级应用脚手架 |
| RAGFlow | 深度文档理解,支持OCR/表格解析 | 复杂格式文档处理 |
| FastGPT | 商业化成熟,SaaS化支持完善 | 快速产品化落地 |
| QAnything | 全格式支持,可完全离线部署 | 数据敏感型场景 |
表:主流RAG框架功能对比
3. 进阶优化策略
生产环境中的RAG系统需考虑以下优化点:
- 混合检索:结合向量搜索+关键词检索+结构化查询
- 重排序:使用Cross-Encoder提升Top结果相关性
- 动态分块:根据文档类型调整chunk策略
- 查询扩展:通过LLM改写用户问题提升召回率
RAGFlow等先进框架已实现解析可视化 和混合检索,在金融、法律等专业领域表现优异。
三、Prompt Engineering:大模型交互的核心技艺
提示词工程(Prompt Engineering)是通过优化输入指令获得理想输出的关键技术,直接影响大模型应用的效果上限。良好的Prompt设计可使模型输出准确性提升40%以上。
1. 核心设计原则
-
清晰明确:避免模糊表述,用"生成3个电商促销文案"替代"写些文案"
-
角色设定:"你是一名资深Java架构师"可约束输出专业性
-
结构化输出:指定JSON/HTML等格式便于后续处理
prompt = """生成用户信息,格式:
{
"name": "",
"age": ,
"interests": []
}""" -
思维链(CoT):引导分步推理提升复杂任务准确率
"请逐步思考:1.识别问题类型 2.提取关键数据 3.分步计算..."
2. 进阶技巧与应用
-
少样本学习(Few-shot):提供输入输出示例
示例1:
输入:"这款手机续航怎么样?"
输出:"{"aspect":"续航","sentiment":"positive"}"请分析:"这个相机画质太差了"
-
检索增强提示:结合RAG提供事实依据
根据产品文档:
"""
{context}
"""
回答客户问题:"P10的续航时间是多久?" -
多模态提示:融合文本/图像/表格信息
分析这张销售报表[图片],
总结Q3季度表现最好的3个产品
3. 企业级Prompt管理
大规模应用需建立Prompt管理体系:
- 版本控制:跟踪不同Prompt版本的性能表现
- AB测试:对比不同Prompt的转化率
- 敏感词过滤:避免生成不当内容
- 模板库:构建领域特定的Prompt集合
阿里云百炼、百度千帆等平台已内置Prompt优化工具,可自动评估提示词效果。
四、工具链整合与选型建议
1. 全流程开发工具栈
| 开发阶段 | 推荐工具 | 优势 |
|---|---|---|
| 原型开发 | PyTorch+Transformers | 灵活、社区资源丰富 |
| 数据处理 | Pandas+AugLy | 结构化与增强支持 |
| 模型训练 | DeepSpeed/Megatron-LM | 分布式训练优化 |
| 推理加速 | TensorRT+ONNX | 高性能、跨框架兼容 |
| 应用部署 | Docker+K8s | 生产级编排能力 |
| 监控运维 | MLflow+Prometheus | 全流程可观测性 |
2. 云平台服务对比
主流MaaS(Model-as-a-Service)平台能力:
- 阿里云百炼:通义千问API、私有化部署支持
- 百度千帆:完整精调工具链(RLHF/DPO)
- AWS SageMaker:端到端机器学习流水线
- 第四范式:可视化workflow编排,开发周期缩短95%
3. 选型决策树
-
评估需求复杂度:
- 简单场景:直接使用Dify等框架
- 定制需求:基于LangChain开发
-
考虑数据敏感性:
- 公开数据:Hugging Face Hub
- 私有数据:本地化部署的QAnything
-
权衡开发资源:
- 有限资源:采用FastGPT等SaaS方案
- 专业团队:自研优化RAG流程
五、未来趋势与挑战
1. 技术演进方向
- 多模态融合:LLaVA、Fuyu等框架实现文本/图像/音频联合建模
- 小型化部署:Phi-2等轻量模型+端侧推理框架
- 自动化编排:可视化workflow工具降低使用门槛
- 评估标准化:HELM等框架提供多维度模型评估
2. 实践挑战
- 成本控制:推理API调用费用与token消耗
- 知识更新:实时数据同步与版本管理
- 安全合规:内容过滤与数据隐私保护
- 性能优化:延迟敏感场景的加速方案
中国电信等企业正通过开源协作(如OpenQiming平台)推动行业共性问题的解决。
总结
大模型应用开发工具链已形成从底层框架到上层应用的完整生态。开发者应当:
- 掌握LangChain等核心框架的模块化设计思想
- 根据场景需求选择RAG实现路径
- 持续优化Prompt Engineering技艺
- 合理利用云平台加速开发流程
随着工具链的不断成熟,大模型技术将更深度地赋能各行业应用,推动AI技术从"可用"向"好用"的持续演进。企业需建立涵盖数据处理、模型开发、应用部署的全栈能力,方能在智能化浪潮中保持竞争优势。