一、引言
在复杂的系统性能调优过程中,函数执行耗时的精准统计与分析是定位性能瓶颈的核心环节。无论是内核态函数,还是用户态业务函数,了解它们的真实运行时间,才能为优化决策提供科学依据。然而,现有的性能分析手段往往存在采样粒度不足、参数过滤不灵活、关联调用链追踪困难等瓶颈,导致性能问题难以精准定位,调优过程耗时且低效。 针对这一痛点,本人自主研发了 func_latency 工具,专注于函数级耗时统计分析。它支持内核函数、用户函数、以及 tracepoint 的多源联合追踪,能够灵活提取函数参数,支持复杂的条件过滤,并可结合调用栈信息进行深度剖析。通过这些能力,func_latency 实现了从函数执行时间到调用上下文的全方位透视,极大提升了性能调优的效率和精度。
本文将详细介绍 func_latency 的功能特点和使用方法,并通过实战示例展示其在真实场景中的应用价值,助力性能专家更快更准地定位系统瓶颈。
二、func_latency 是什么?
这是一款基于 BCC 技术实现的 eBPF 工具,功能总览如下表所示:
| 功能点 | 支持情况 |
|---|---|
| 支持内核函数 | ✅ 通配/正则匹配 |
| 支持用户函数(uprobe) | ✅ |
| 支持 tracepoint | ✅ |
| 参数提取 | ✅ 任意类型、结构体 |
| 参数过滤 | ✅ 按值、结构体成员 |
| 栈信息打印 | ✅ 可选 |
| 输出格式 | ✅ 普通 / 直方图 |
| 指定 PID/TID | ✅ |
| 定时输出 / 限时运行 | ✅ |
| 多函数组合分析 | ✅ 如 从func1至func2的耗时分析` |
三、基本使用示例
✅ 示例 1:测量所有以 vfs_ 开头的内核函数的执行时间
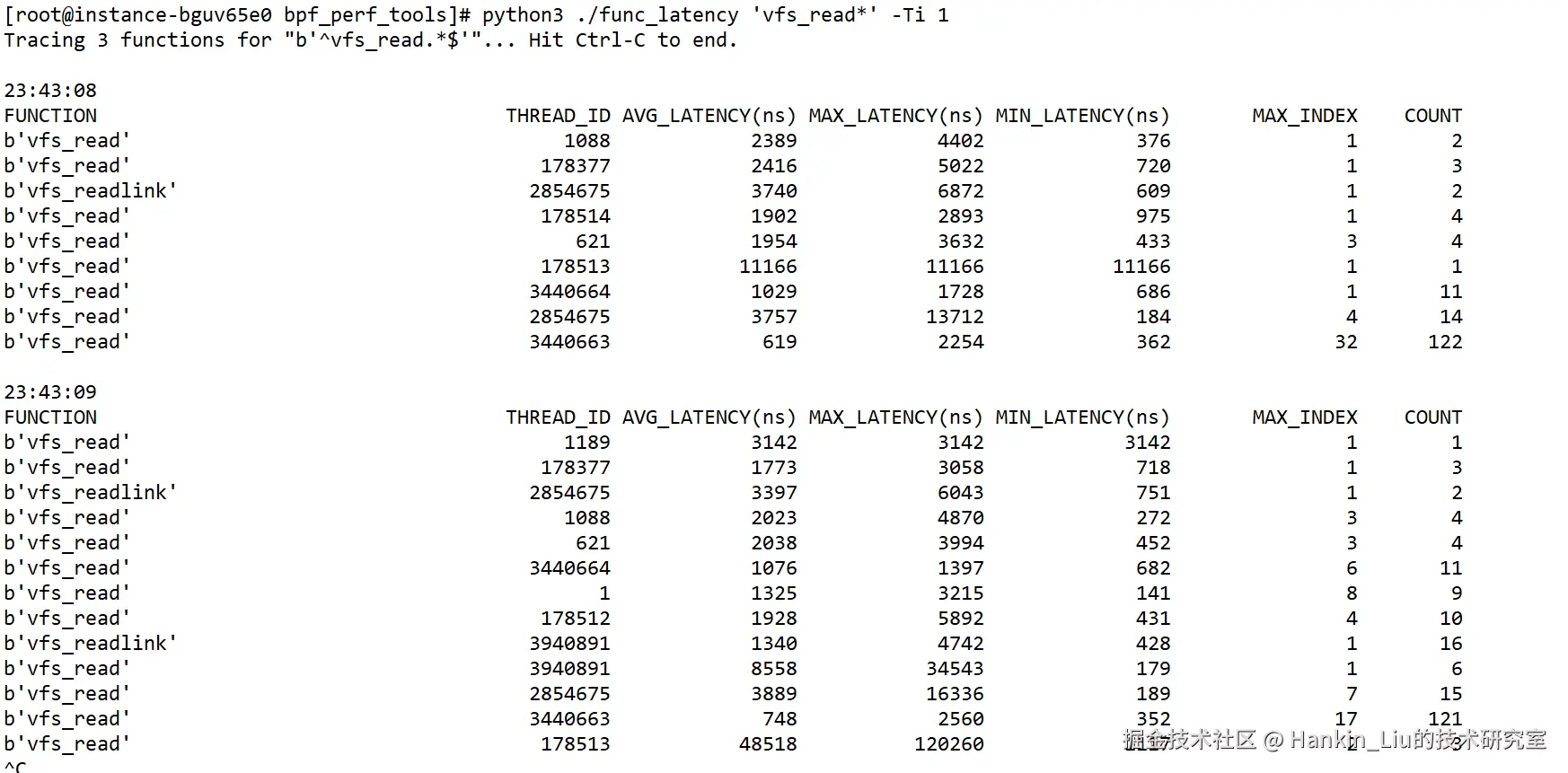
root@instance-bguv65e0 bpf_perf_tools# python3 ./func_latency 'vfs_read*' -Ti 1
 结果说明:
结果说明:
每秒会输出一次当秒内核函数vfs_read*的调用耗时情况,以线程号来区分,统计信息有:
AVG_LATENCY(ns):平均耗时,单位纳秒;
MAX_LATENCY(ns):最大耗时,单位纳秒;
MIN_LATENCY(ns):最小耗时,单位纳秒;
MAX_INDEX:最大耗时是第几次调用;
COUNT:总共调用了多少次。
参数说明:
-T,输出的结果中显示时间;
-i,输出结果的时间间隔,此例中是1秒输出一次。
✅ 示例 2:只分析 以vfs_开头的内核函数,并且只记录耗时 50us ~ 10ms 的调用
root@instance-bguv65e0 bpf_perf_tools# python3 ./func_latency 'vfs_*' -m 50000 -M 1000000 -Ti 1
 参数说明:
参数说明:
-m:过滤最小耗时,低于此值,不统计;
-M:过滤最大耗时,高于此值,不统计。
✅ 示例 3:测量从syscalls:sys_enter_write至syscalls:sys_exit_write之间的耗时
root@instance-bguv65e0 bpf_perf_tools# python3 ./func_latency 't:syscalls:sys_enter_write;t:syscalls:sys_exit_write' -Ti 1

✅ 示例4:内核函数tcp_v4_connect耗时,并获取参数sa_family和addr_len的值
root@instance-bguv65e0 bpf_perf_tools# python3 ./func_latency 'tcp_v4_connect' -Ti 1 -args 'ushort arg2->0,uint32_t arg3:'
 结果说明:
结果说明:
函数原型:int tcp_v4_connect(struct sock *sk, struct sockaddr uaddr, int addr_len)
struct sockaddr的定义为:
struct sockaddr {
unsigned short sa_family; / address family, AF_xxx /
char sa_data14; / 14 bytes of protocol address */
};
所以要想获取sa_family的值,则需要从第二个参数uaddr的偏移量为0处开始取2字节(unsigned short),且还需要取第三个参数,对应脚本参数表达式"-args 'ushort arg2->0,uint32_t arg3:'"。
✅ 示例5:C++用户态函数耗时,并获取参数中成员a的值
首先,编译并运行以下demo程序;
cpp
// test.cpp
#include <iostream>
#include <thread>
#include <chrono>
#include <cstdlib>
struct double_t
{
double data;
};
typedef struct double_wrapper
{
double_wrapper() { dp = new double_t(); }
~double_wrapper() { delete dp; }
uint32_t a;
double_t d;
double_t* dp;
} double_w_t;
double uprobe_sum_dw_ref(const double_w_t& d1, const double_w_t& d2)
{
printf("d1.a = %u,d2.a = %u, d1.d.data = %lf, d2.d.data = %lf, d1.dp->data = %lf, d2.dp->data = %lf\n",
d1.a, d2.a, d1.d.data, d2.d.data, d1.dp->data, d2.dp->data);
return d1.dp->data + d2.dp->data;
}
int main()
{
srand((int)time(0));
while(1) {
double_w_t d1, d2;
d1.a = rand();
d1.d.data = rand() + (double)rand() / RAND_MAX;
d1.dp->data = rand() + (double)rand() / RAND_MAX;
d2.a = rand();
d2.d.data = rand() + (double)rand() / RAND_MAX;
d2.dp->data = rand() + (double)rand() / RAND_MAX;
auto ret = uprobe_sum_dw_ref(d1, d2);
std::this_thread::sleep_for(std::chrono::seconds(5));
}
return 0;
}
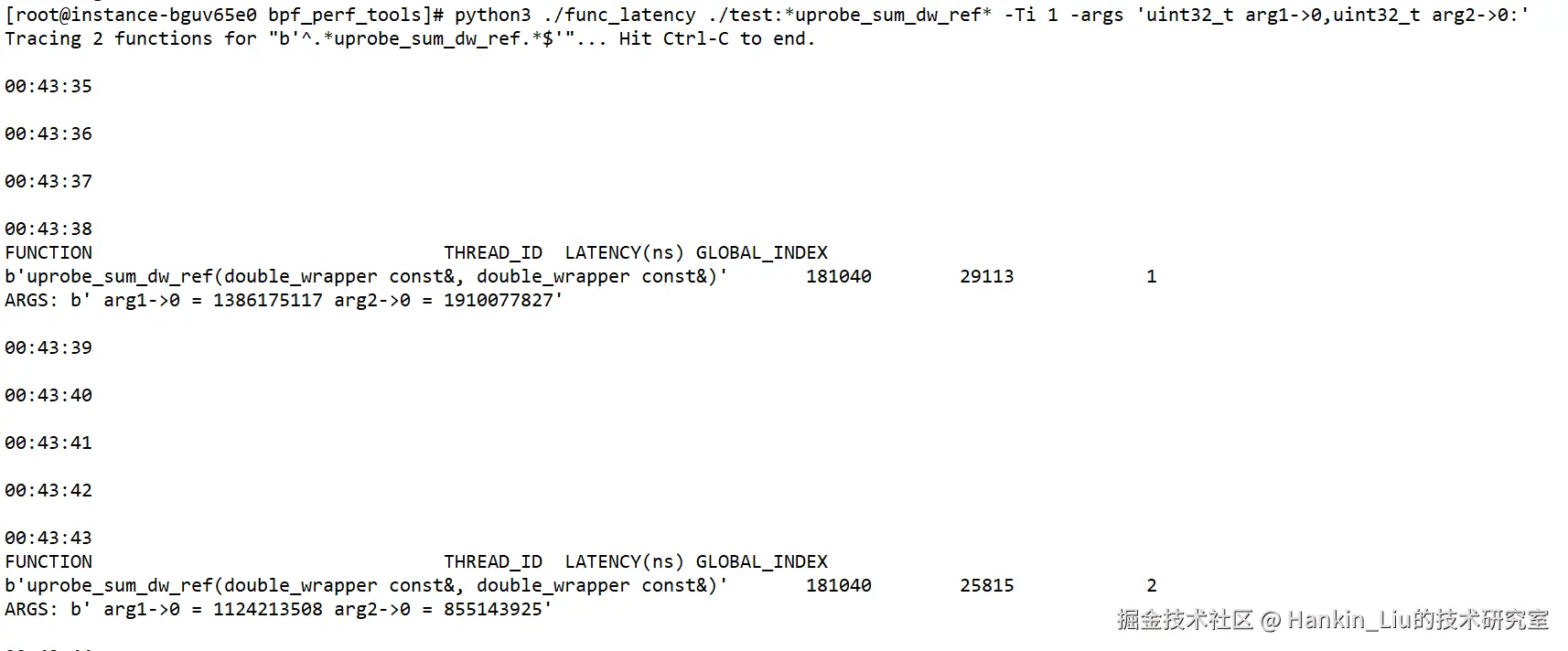
//编译命令:g++ test.cpp -g -o testroot@instance-bguv65e0 bpf_perf_tools# python3 ./func_latency ./test:uprobe_sum_dw_ref -Ti 1 -args 'uint32_t arg1->0,uint32_t arg2->0:'
结果说明:
在struct double_wrapper结构体中,成员a的偏移量为0,长度为4字节,对应指令参数"-args 'uint32_t arg1->0,uint32_t arg2->0:'",要监测的语法是bin文件路径:函数符号,这里由于是C++语言,函数符号会在函数名的基础上加以填充,所以在函数名前后加星号,使用正则来匹配。
四、如何获取脚本?
func_latency 是本人自研的性能工具,可免费使用,版权所有,请匆传播发放或用于商业用途,为了更好地维护、更新和支持使用者,目前采用 私密发放 的方式。
📌 获取方式如下:
1️⃣ 关注我的微信公众号:Hankin-Liu的技术研究室
2️⃣ 发送关键词:func_latency
3️⃣ 获取脚本
4️⃣ 加入技术交流群
五、写在最后
BCC + eBPF 是当前 Linux 性能诊断的最强组合,而 func_latency 则是我基于实战需求精心打磨的利器。 无论你是内核工程师、运维专家,还是系统性能爱好者,都值得拥有这把"时间分析的瑞士军刀"。
📬 有任何使用问题,也欢迎公众号(Hankin-Liu的技术研究室)后台留言,我会亲自答复!