概述
VAD 的核心任务是鉴别音频信号中的语音出现(speech presence)和语音消失(speech absence),也就是区分语音和非语音(或静音)部分。想象一下,在一个有背景噪音的环境中,VAD 就像一个智能"守门人",它能准确识别什么时候有人在说话,什么时候是纯粹的环境噪音或沉默。
这项技术在许多场景中都扮演着关键角色:
- 语音编码和降噪:VAD 可以帮助系统只处理含有语音的部分,从而节省带宽、提高压缩效率,并有效降低背景噪音,提升语音通话质量。
- 自动语音识别 (ASR):在将语音转换为文本之前,VAD 可以移除音频中的静音部分,减少不必要的计算,提高识别的准确性和效率。
- 智能语音助手和机器人:在这些应用中,VAD 能够更准确地识别用户的语音指令,避免被环境噪音触发。
- 数据清洗和准备:对于训练神经网络等机器学习任务,VAD 可用于从大量的音频记录中提取出纯净的语音片段,去除静音,从而提高模型训练的质量。
工作原理
一个 VAD 系统通常包含两个主要部分:特征提取 和语音/非语音判决。
-
特征提取 好的特征是 VAD 分类问题的关键,它们应该具备区分能力 (让语音和噪声的分布分离度高)和噪声鲁棒性(在背景噪声下也能保持特征的区分能力)。常用的特征类型包括:
- 基于能量的特征:假设语音能量大于背景噪声能量。然而,当噪声较大时,这种方法区分能力会下降。
- 频域特征:通过短时傅里叶变换 (STFT) 将时域信号转换为频域信号。即使在低信噪比下,某些频带的长时包络也能区分语音和噪声。WebRTC VAD 就利用了这一思想,将频谱分成六个子带进行能量分析。
- 倒谱特征:例如,能量倒谱峰值可以确定语音信号的基频,MFCC (梅尔频率倒谱系数) 也可以作为特征。
- 谐波特征:语音的一个明显特征是包含基频及其多个谐波频率,即使在强噪声环境下也存在。
- 长时特征:语音是非稳态信号,其统计特性随时间变化;而大多数日常噪声是稳态或变化缓慢的。
-
判决准则 在提取特征后,需要一个判决机制来决定当前帧是语音还是非语音。主要有三类方法:
- 基于门限的方法:根据预先设定的门限值来判断。对于变化的噪声场景,需要使用自适应门限。
- 统计模型方法:这类方法源于似然比检验 (LRT),假设语音和背景噪声服从独立的高斯分布或其他分布(如拉普拉斯、伽马分布),通过计算信号是语音或噪声的概率来做出判决。WebRTC VAD 就采用了这一思想,使用高斯模型对噪声和语音的概率进行计算,并通过似然比检验进行判决。
- 机器学习方法:通过训练数据学习语音模型。这类方法的难点在于强噪声场景下训练数据集的准确标注。然而,近年来深度学习的发展,极大地提升了 VAD 的性能和适应性。
常见的 VAD 模型和工具包
目前有许多优秀的 VAD 模型和工具包可供选择,它们各有特点和应用场景:
Silero VAD
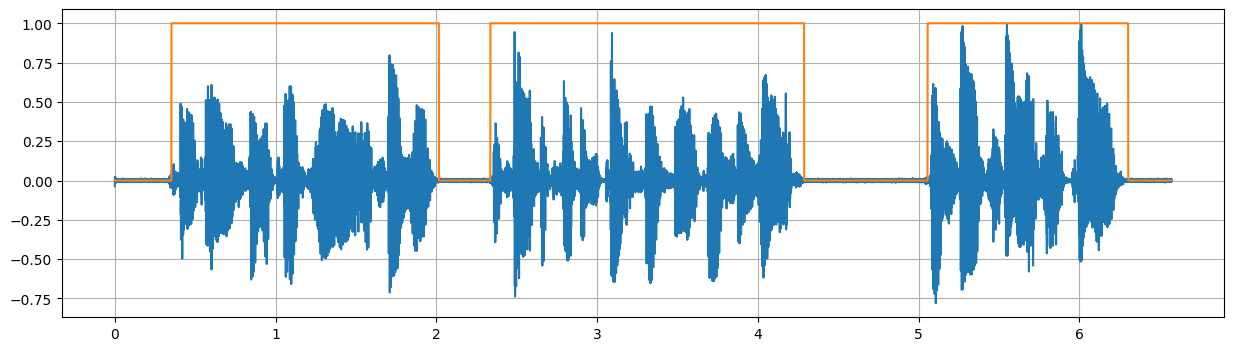
** Silero VAD** 是一种基于深度学习技术的轻量级语音活动检测模型,被描述为"企业级预训练模型"。
我的看法:还不错,但是对清辅音的识别稍微欠缺,日语轻声效果有点差
特点
- 轻量级:模型文件大小仅约 2.2MB。
- 速度快:在单 CPU 线程上处理一个音频块(30+ms)所需时间不到 1ms。
- 通用性强:在包含 6000 多种语言的庞大语料库上进行训练,对不同领域、不同背景噪声和质量的音频表现良好。
- silero支持非常丰富的参数调节,
安装: pip install silero
speech_timestamps = get_speech_timestamps(wav, model,
sampling_rate=sr,
threshold=0.5,
min_speech_duration_ms=10, # 语音块的最小持续时间 ms, 语音超过这个最小时长才会被判为是语音
min_silence_duration_ms=140, # 语音块之间的最小静音时间 ms, 静音超过这个最小时长才会被判为静音
window_size_samples=512, # 窗长 512\1024\1536
speech_pad_ms=0, # 往VAD时间戳左右padding (ms)
)
FSMN-VAD (FunASR)
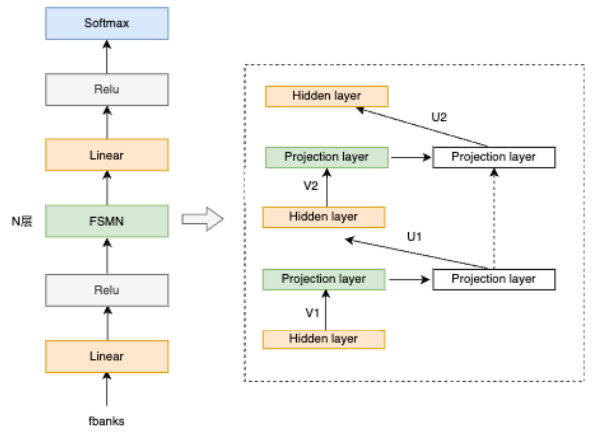
** FSMN-VAD** 是达摩院语音团队提出的高效语音端点检测模型,用于检测输入音频中有效语音的起止时间点信息,并将检测出来的有效音频片段输入识别引擎进行识别,减少无效语音带来的识别错误。
我的看法:**检测是否有语音很准,但是由于是识别类的VAD,检测语音的时间戳会相对相对宽一点,**FunASR唱歌也会检测为语音,但是silero不会
特点:
- 参数量:0.4M
- 训练数据:5000小时,普通话和英语
安装: pip3 install -U funasr
funasr也有很多配置参数,调参与不调参差别会非常大,下面标红的参数是重点调参对象,参数文件在:/home/xxx/.cache/modelscope/hub/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch
- sample_rate:采样率,输入音频的采样率(Hz),必须和模型训练时一致,常用 16000。
- frame_in_ms:帧移(ms),每一帧的间隔时间,比如 10ms 表示每 10ms 产生一帧特征。
- frame_in_ms:帧长(ms),每一帧特征的时间长度,比如 25ms 表示一帧包含 25ms 的音频数据。
- window_size_ms:分析窗口长度(ms),推理时,VAD 会基于一个滑动窗口来做判断,这个是窗口的时长。
- 起点/终点检测
- detect_mode: 检测模式 一般 0 或 1,不同模式对应不同的端点检测策略,1 通常更严格,0 更宽松。
- do_start_point_detection: 是否启用起点检测 True 表示检测语音开始位置。
- do_end_point_detection: 是否启用终点检测 True 表示检测语音结束位置。
- max_start_silence_time: 起点前允许的最大静音时间(ms) 如果静音超过这个时间,还没检测到语音,起点会被重置。0 表示不限制。我设置为0
- max_end_silence_time: 终点后允许的最大静音时间(ms) 超过该时间后会强制切断 segment,0 表示不限制。我设置为0
- lookback_time_start_point: 起点回溯时间(ms) 检测到语音后,向前回溯一段时间作为起点(防止起点切掉前几个字)。我设置为0
- lookahead_time_end_point: 终点提前时间(ms) 检测到静音后,可提前终止 segment(减少延迟)。我设置为0
- sil_to_speech_time_thres: 静音→语音判定时间(ms) 从静音状态切换为语音状态所需的连续触发时长。我设置为150
- speech_to_sil_time_thres: 语音→静音判定时间(ms) 从语音状态切换为静音状态所需的连续静音时长。我设置为150
- do_extend: 是否延长语音段 1 表示语音段会延长,避免截断尾音。
- 分段控制
- max_single_segment_time 单段最大时长(ms) 一段语音超过该时长会被强制切分。
- 噪声与能量门限
- snr_mode 信噪比模式 0 表示关闭基于 SNR 的判定,1 表示启用。
- snr_thres 信噪比阈值(dB) SNR 判定的门限,低于该值可能判为噪声。
- noise_frame_num_used_for_snr SNR 估计用的噪声帧数 用多少帧静音来计算噪声均值。
- decibel_thres 分贝阈值 低于该分贝的帧判为静音。
- speech_noise_thres 语音与噪声能量比阈值 控制噪声过滤的灵敏度。我设置为0.8
- speech_noise_thresh_low / speech_noise_thresh_high 双阈值 用于判定语音与噪声的上下限阈值,增加稳健性。
- speech_2_noise_ratio 语音/噪声比例 调节判定灵敏度,越大越严格。
- fe_prior_thres 特征能量先验阈值 小于该值的帧直接视为静音(特征域判定)。
- 模型类别映射
- silence_pdf_num 静音类别数 模型输出中静音类别的数量。
- sil_pdf_ids 静音类别 ID 列表 用于指定哪些类别属于静音,例如 0 表示类别 0 是静音。
- 输出选项
- output_frame_probs 是否输出帧级概率 True 会输出每一帧是语音的概率,用于调试或后处理。
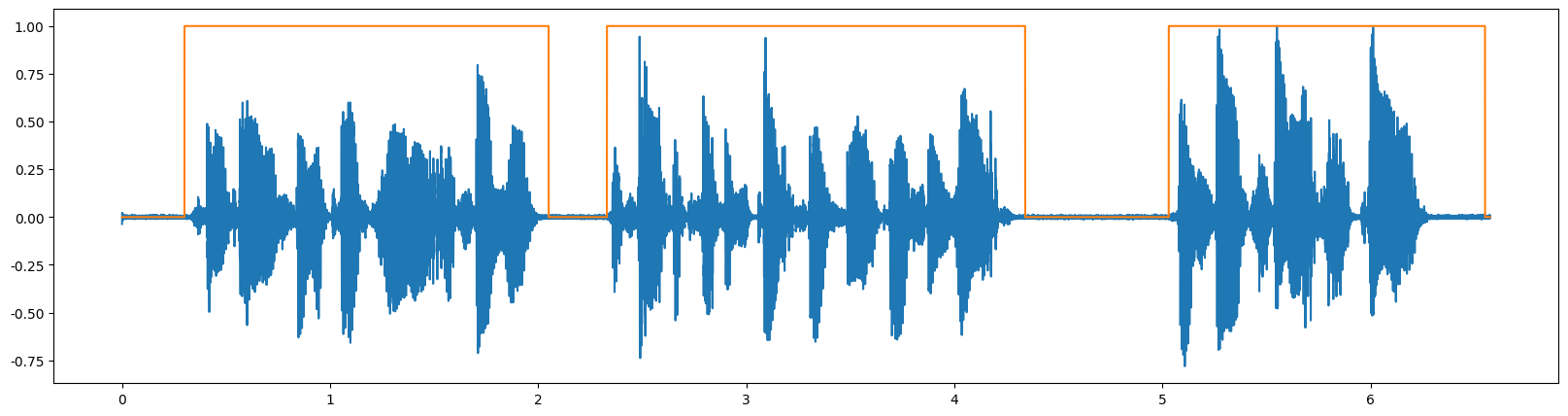
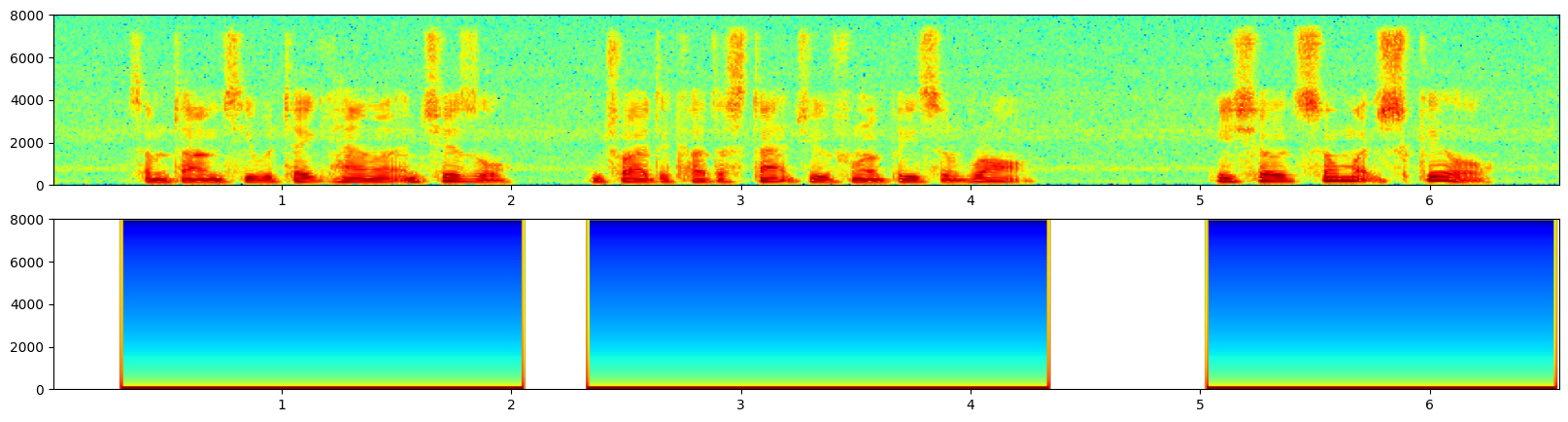
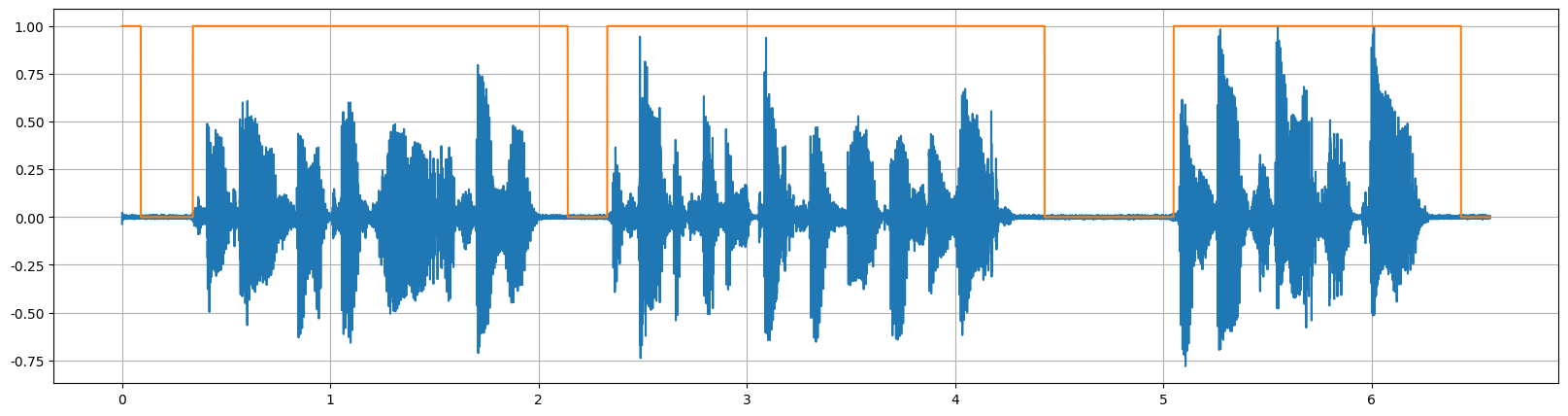
WebRTC VAD
WebRTC VAD 是谷歌为 WebRTC 项目开发的 VAD 模块,WebRTC 是 Google 开源的实时通信框架,特别适用于实时性要求较高的语音通信场景。
WebRTC 的 VAD 实现属于 特征驱动 + 统计模型 的方案:
- 将音频分帧(如 10ms / 20ms / 30ms)
- 提取多个语音特征(短时能量、过零率、谱特征),将频谱分成 6 个子带(80Hz~4KHz)来计算能量特征。
- 短时能量:语音通常能量较大,静音或噪声能量较小。
- 过零率:语音(尤其是清音辅音)ZCR 较高,元音较低;纯噪声的 ZCR 往往更高。
- 谱质心:频谱的"重心位置",反映频率分布的集中程度。清辅音(高频)谱质心较高,元音(低频)谱质心较低。
- 频带能量分布:WebRTC 会将语音分成多个频段,计算各段能量比例,用来区分人声与背景噪声的频谱特征。
- 谱斜率 / 倾斜度(Spectral Slope / Tilt):谱斜率 / 倾斜度(Spectral Slope / Tilt),元音低频强,高频弱;噪声则频谱较平坦。
- 平谱熵:平谱熵,语音的频谱分布较有结构,熵较低;噪声通常更随机,熵更高。
- 输入到已经训练好的高斯混合模型(GMM)中进行分类
- 输出是否包含语音的布尔值(True / False)
安装: pip install webrtcvad
该库py-webrtcvad 是一个 Python 封装库,支持四种激进模式 (0-3),检测敏感度与数值大小正相关
设定的 VAD 模式(Vad(0/1/2/3))实际上是改变了阈值:
0:宽松(漏检少,但容易误判噪声为语音)
3:严格(容忍度低,更容易漏掉低能量语音)
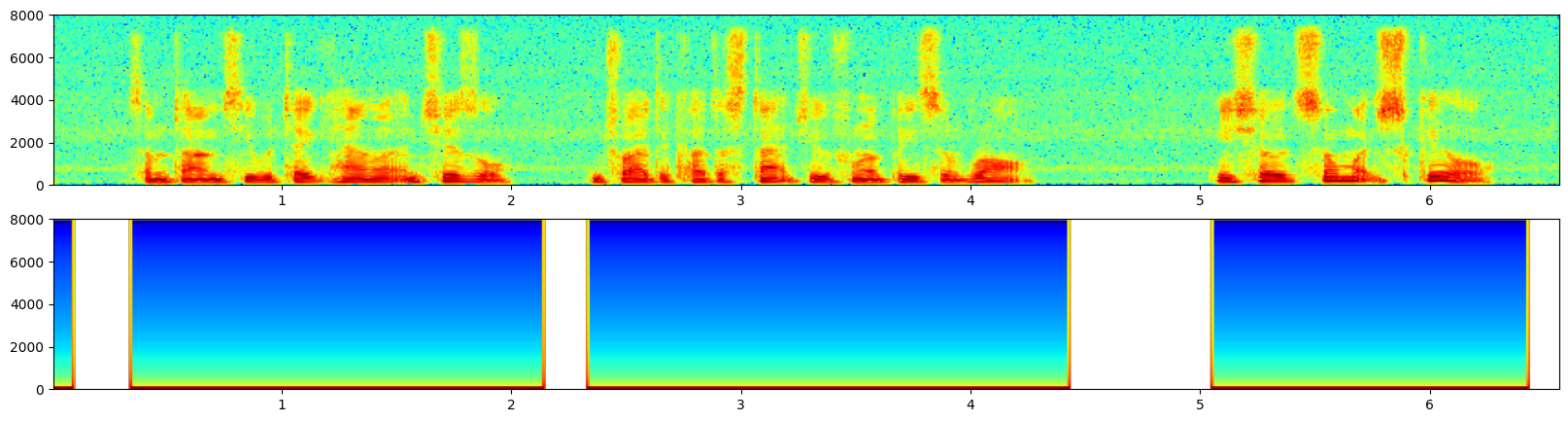
稍微宽了一点
TEN VAD
TEN VAD 是 TEN Framework 生态系统中的一个高性能、低延迟、轻量级的实时语音活动检测(VAD)系统,专为企业级对话 AI 应用设计,旨在提供精准的帧级语音活动检测。
- 低延迟 :TEN VAD 能迅速检测语音与非语音的切换,减少对话系统的响应延迟。
- 轻量级 :TEN VAD 的计算复杂度和内存占用低于 Silero VAD,适合嵌入式和边缘设备使用。
- 跨平台支持 :支持 Windows、macOS 和 Linux 平台,且提供 ONNX 格式模型,方便与 Python 等语言集成。
GitHub 仓库:https://github.com/TEN-framework/ten-vad
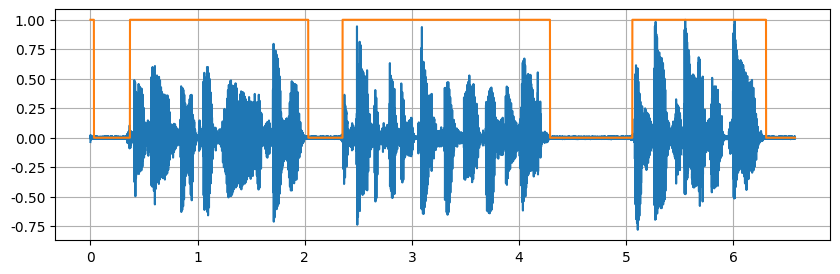
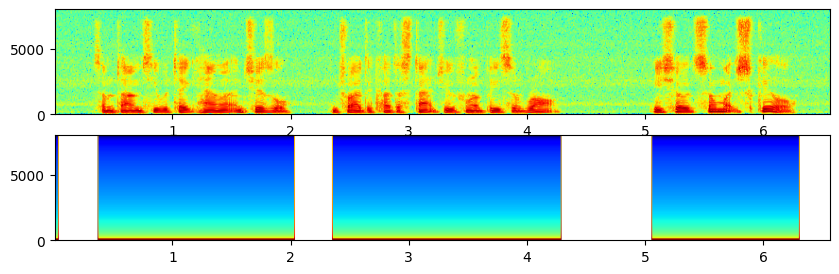
这效果没有他吹的这么牛啊
whisper
虽然 OpenAI Whisper 本身不是专门的 VAD 模型,但我们可以借助它的时间戳功能,实现一个带 VAD 效果的长音频切分。下面我来给你详细介绍原理、方法和示例代码。
- Whisper 转录时会返回
segments(每句话的开始与结束时间)。 - 我们只保留包含语音的
segment,就等于做了"语音段提取",静音部分自然被丢弃。 - 如果需要更细粒度,可使用
word_timestamps=True,结合时间差判断语音间的空隙,再分割音频。
优点
- 不需要额外安装 VAD 模型
- 直接结合语音识别,VAD 结果与识别文本对齐
- 方便长音频切分,并保留对应的字幕
缺点
- 推理成本大,只做 VAD 性价比低
- 在背景噪声大、非语音片段多的情况下不如专用 VAD 鲁棒


import whisper
import soundfile as sf
# 1. 加载模型(可根据显存选择 tiny/base/small/medium/large)
model = whisper.load_model("small")
# 2. 读取音频(保持16k采样率)
wav_path = "audio.wav"
audio, sr = sf.read(wav_path)
assert sr == 16000, "Whisper要求16k采样率"
# 3. 转录,获取每个 segment 的时间戳
result = model.transcribe(wav_path)
# 4. 提取语音段落时间,作为 VAD 结果
vad_segments = []
for seg in result['segments']:
vad_segments.append({
"start": seg['start'],
"end": seg['end'],
"text": seg['text']
})
# 输出检测到的语音片段
for s in vad_segments:
print(f"{s['start']:.2f}s - {s['end']:.2f}s : {s['text']}")View Code
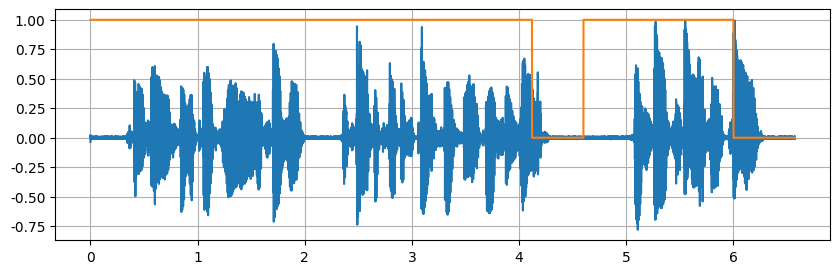
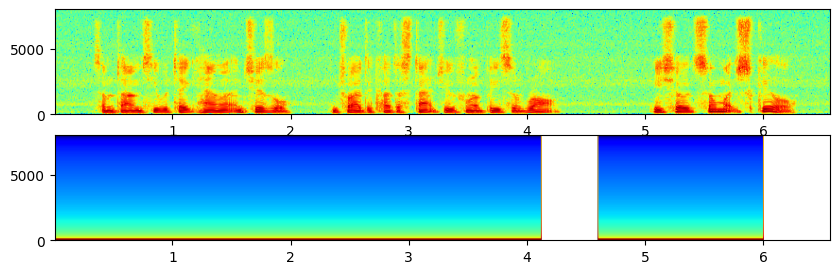
基于识别模型做的VAD都宽
energy-vad
energy-vad 是一个非常简单的 基于能量(energy-based)的语音活动检测器(VAD),由 Rhasspy 项目发布(Rhasspy 是一个离线语音助手框架)。
energy-vad 的核心思想很简单:
- 分帧:将音频分割成小片段(例如每 10ms 一帧)
- 对每帧计算 RMS(均方根能量):E=1N∑i=1Nxi2E=N1i=1∑Nxi2
- 阈值判断:如果 RMS 能量大于设定阈值 → 判定为语音帧;否则 → 判定为静音帧
- 起止判定:当连续若干帧大于阈值 → 检测到语音开始;当连续若干帧小于阈值 → 检测到语音结束
通过计算短时音频帧的能量,判断当前帧是否可能包含语音,从而确定语音开始和结束的时间点。这种方法在干净音频条件下非常高效,但对背景噪声较敏感。
安装: pip install energy-vad
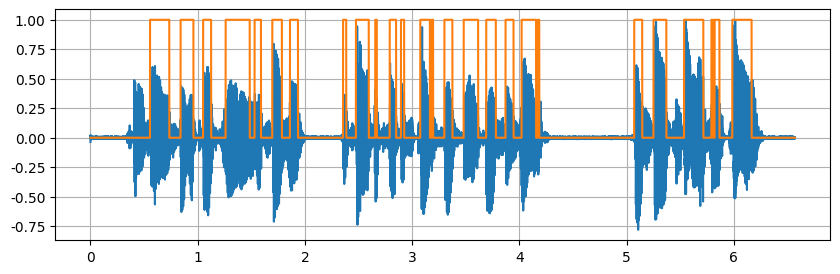
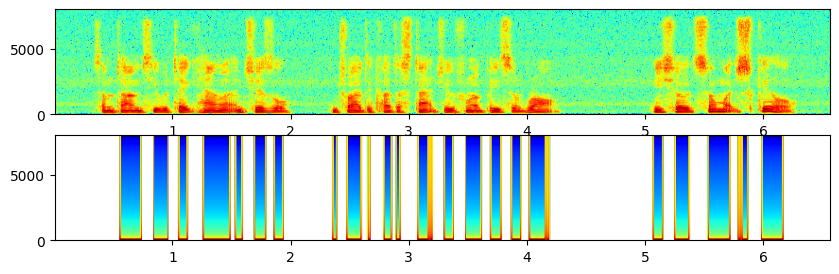
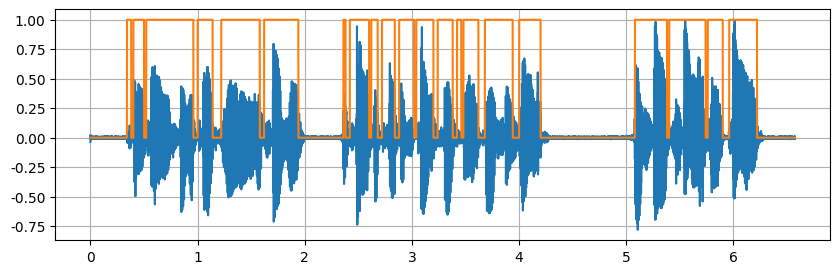
误差比较大,而且连着的语音没必要分割,但是该方法还是分割了
基于谱变化率的vad
该方法提供了一个基于谱特征变化率(Spectral Flux) 的简单语音活动检测(Voice Activity Detection)算法实现,与传统基于能量的 VAD 不同,该项目利用音频频谱的动态变化来区分语音与静音/背景噪声。
算法原理
- 短时傅里叶变换(STFT)
- 计算谱通量(Spectral Flux)
- 对相邻两帧的幅度谱求差,并取正变化部分的平方和,得到谱通量值。
- 谱通量衡量了频谱随时间变化的程度,语音帧通常变化更大,静音/稳态噪声音频谱变化较小。
- 阈值检测
- 将谱通量与设定阈值
threshold对比,大于阈值的帧标记为含语音。 - 通过连续帧合并、忽略过短片段等规则,输出语音区间。
- 将谱通量与设定阈值
安装: pip install vad
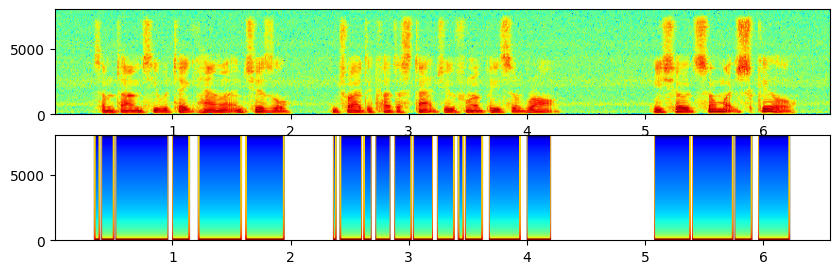
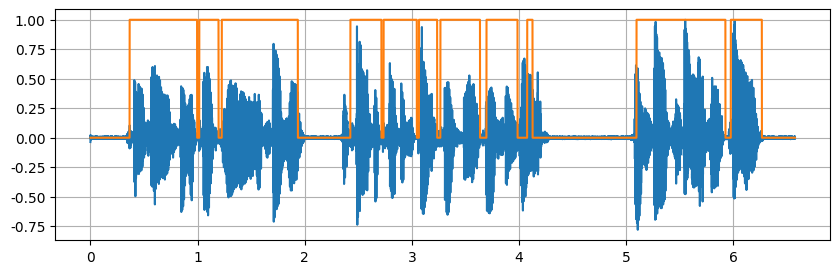
基于统计模型的VAD
这个项目实现的是一种基于统计模型的语音活动检测(VAD)算法,核心参考了 Sohn 等人在 1999 年发表的经典方法。它的主要流程是:
- 特征提取:将音频信号分帧,并在频域上计算功率谱,用于后续的统计推断。
- 似然比检验(Likelihood Ratio Test, LRT):假设每一帧可能是"语音"或"噪声",分别建立统计模型,通过似然比来判定该帧更可能属于哪一类。
- 参数估计:使用决策导向(Decision-Directed)方法平滑地更新噪声功率谱估计,这可以减少突变和检测抖动。
- Hang-over Scheme:在决策时引入"挂延机制",即当检测到语音时会延迟一段时间才切换到静音状态,从而避免语音末尾被过早截断。
参考:https://github.com/eesungkim/Voice_Activity_Detector
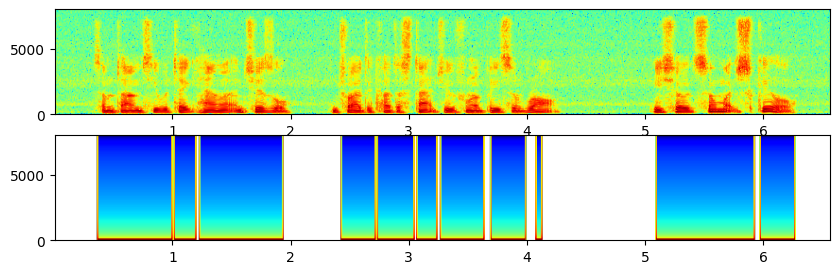
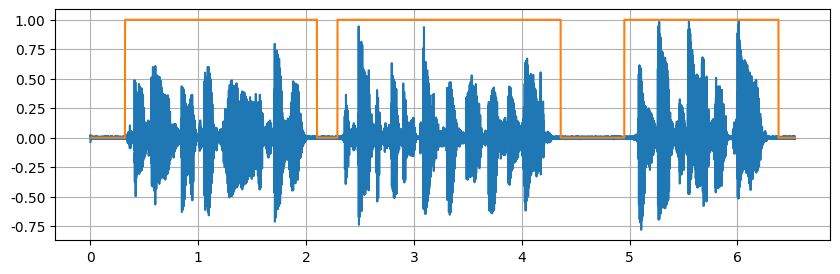
语间细节把握的很好,但是有时候会吞掉一个字
rVADfast
论文:Tan Z H, Dehak N. rVAD: An unsupervised segment-based robust voice activity detection methodJ. Computer speech & language, 2020, 59: 1-21.
链接:https://github.com/zhenghuatan/rVADfast
核心思想和方法流程:
两阶段降噪:
- 第一阶段 使用后验信噪比(a posteriori SNR)加权能量差法检测高能量段,并在无音高检测时将其视为高能噪声段,直接置零。
- 第二阶段 应用语音增强技术(例如 Wiener 滤波等)消除更稳定的噪声。
Segment-based 和 Pitch 引导:
- rVAD 原方法通过检测 pitch(音高)来形成语音片段,并对其进行扩展,包含更多语音/非语音内容,最后基于后验 SNR 能量差进行 VAD。
- 而 rVAD-fast 用 谱平坦性(spectral flatness) 来替代耗时的 pitch 提取,显著提升速度(大约快 10 倍),性能轻微下降但仍具实用性。
效果与优势:
-
方法适应不同噪声环境(如 babble、market、车内等),在干净或污染条件下均表现出较好的性能;在 Fearless Steps Speech Activity Detection Challenge 中,rVAD 方法在所有参赛系统中排名第 4(无监督与有监督),凸显其鲁棒性。
-
该模型在多任务(如语音识别、说话人识别、性别/年龄识别、自监督学习等)中作为预处理器得到广泛应用,在多篇文献中引用和使用
安装: pip install rVADfast
import audiofile
from rVADfast import rVADfast
vad = rVADfast()
waveform, sampling_rate = audiofile.read("your_audio.wav")
vad_labels, vad_timestamps = vad(waveform, sampling_rate)vad_la bels:是一个逐帧(frame-level)的 语音活动标签数组,通常是 0 或 1:
vad_timestamps:是一个语音段的时间戳列表,表示所有检测到的语音区间的起止时间(单位:秒)
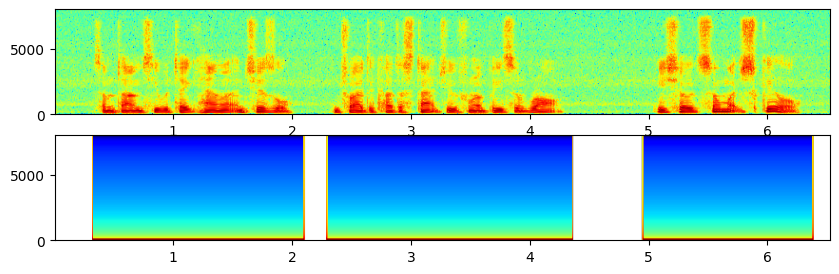
总结
语音活动检测 (VAD) 是语音处理领域的基础技术,它通过特征提取 和智能判决,将复杂的音频信号划分为有意义的语音和无声的非语音部分。从经典的 WebRTC VAD 到基于深度学习的 Silero VAD 和 FSMN-VAD,VAD 技术正在不断发展和创新,以适应更复杂的环境和更广泛的应用场景。未来,VAD 模型的准确性和鲁棒性将持续提升,为语音通信和人机交互提供更强大的支持。
注:以上测试均做了归一化和去工频(100Hz)高通滤波预处理
参考
【github】https://github.com/snakers4/silero-vad
https://github.com/mengsaisi/VAD_campare
vad数据:https://github.com/jtkim-kaist/VAD