文章目录
- [1. 背景简介](#1. 背景简介)
- [2. 环境搭建](#2. 环境搭建)
-
- [2.1 下载 Tesseract](#2.1 下载 Tesseract)
-
- [2.1.1 安装 Tesseract](#2.1.1 安装 Tesseract)
- [2.1.2 配置Tesseract环境变量](#2.1.2 配置Tesseract环境变量)
- [2.1.3 验证Tesseract 环境变量配置成功](#2.1.3 验证Tesseract 环境变量配置成功)
- [2.2 下载 JDK](#2.2 下载 JDK)
-
- [2.2.1 安装 JDK](#2.2.1 安装 JDK)
- [2.2.2 配置JDK环境变量](#2.2.2 配置JDK环境变量)
- [2.2.3 验证 JDK 环境变量](#2.2.3 验证 JDK 环境变量)
- [2.3 下载 jTessBoxEditor](#2.3 下载 jTessBoxEditor)
-
- [2.3.1 安装 jTessBoxEditor](#2.3.1 安装 jTessBoxEditor)
- [2.3.2 运行 jTessBoxEditor](#2.3.2 运行 jTessBoxEditor)
- [3. 训练数据](#3. 训练数据)
-
- [3.1 准备图片素材](#3.1 准备图片素材)
- [3.2 训练数据](#3.2 训练数据)
-
- [3.2.1 生成 tif 文件](#3.2.1 生成 tif 文件)
- [3.2.2 使用 tesseract 生成.box文件](#3.2.2 使用 tesseract 生成.box文件)
- [3.2.3 使用 jTessBoxEditor 标注文件](#3.2.3 使用 jTessBoxEditor 标注文件)
- [3.2.4 生成 font_properties 文件(该文件没有后缀名)](#3.2.4 生成 font_properties 文件(该文件没有后缀名))
- [3.2.5 使用 tesseract 生成 .tr 训练文件](#3.2.5 使用 tesseract 生成 .tr 训练文件)
- [3.2.6 生成字符集文件](#3.2.6 生成字符集文件)
- [3.2.7 生成shape文件](#3.2.7 生成shape文件)
- [3.2.8 生成聚字符特征文件](#3.2.8 生成聚字符特征文件)
- [3.2.9 生成字符正常化特征文件](#3.2.9 生成字符正常化特征文件)
- [3.2.10 文件重命名](#3.2.10 文件重命名)
- [3.2.11 合并训练文件](#3.2.11 合并训练文件)
- [4. 验证识别效果](#4. 验证识别效果)
-
- [4.1 使用命令行验证](#4.1 使用命令行验证)
- [4.2 使用Java代码验证](#4.2 使用Java代码验证)
- [5. 总结](#5. 总结)
-
- [5.1 坑点](#5.1 坑点)
1. 背景简介
Tesseract 是一个开源的 OCR(光学字符识别)引擎,由 HP 实验室开发并在 2005 年开源,后来由 Google 维护和优化。它能够从图像中识别和提取文本,支持 100 多种语言,包括中文、英文、日文等,广泛应用于文档扫描、车牌识别、自动化数据录入等领域。
文字识别的前提是根据已有文本图像数据训练数据字库 ,从而识别同类图像上的文本。官方已有的训练数据,包含了中文、英文等:Tesseract字库数据集。
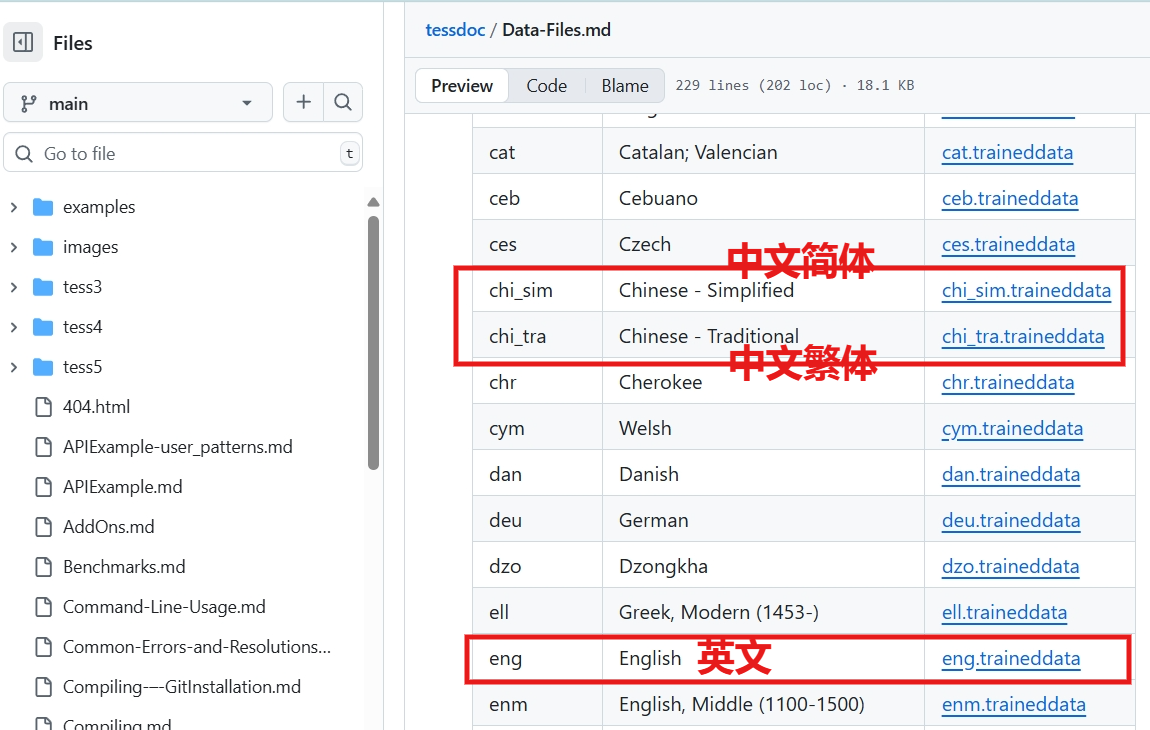
这些训练数据已经能满足大多识别场景了,但总有一些特别的字体会出现识别不准的情况,那么就需要训练自己的字库,从而进行特定字体的识别了。
本文将介绍如何训练自己的字体库 ,从而进行特定的字体识别。包括从环境搭建 到训练数据准备 、训练数据字库生成 、最后到结果验证 。中间还会介绍一些踩坑注意事项,确保按照本文的操作流程,一步步操作,能够实现最终的效果!
备注:本文演示所有电脑为 Windows 11 64 位操作系统。
2. 环境搭建
首先安装所需的软件及相关环境。
2.1 下载 Tesseract
Tesseract 是进行 OCR 识别的验证工具,可以理解为一个软件,后面将通过它进行 OCR 识别验证。
Tesseract 下载:Tesseract下载地址
本文使用 64位 windows 系统,下载 tesseract-ocr-w64-setup-v5.0.0.20190623.exe安装包。
2.1.1 安装 Tesseract
双击下载好的 exe 文件,启动安装弹窗:
点 Next :
点 I Agree :
继续 Next, 按照图示操作即可:
这里的语言可选择多下载几个:
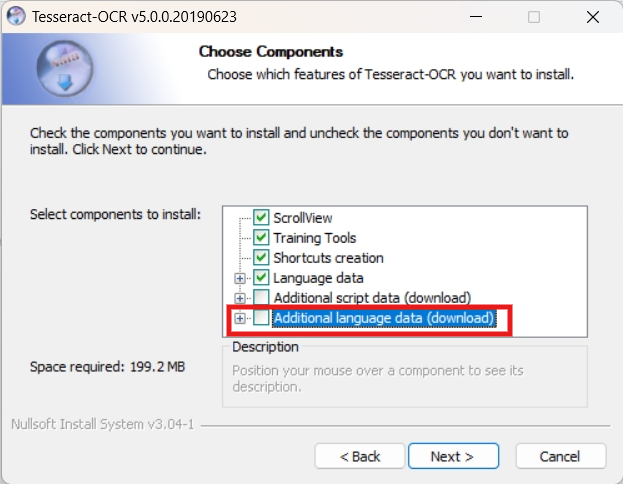
展开节点,选择几个语言,比如中文的几个选项,可能会下载失败,但是没关系,忽略即可。
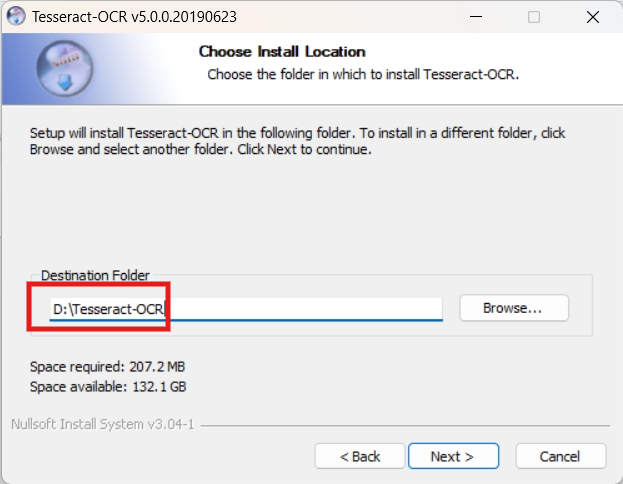
选择安装位置,比如 D 盘的某个目录,确保不要有中文!
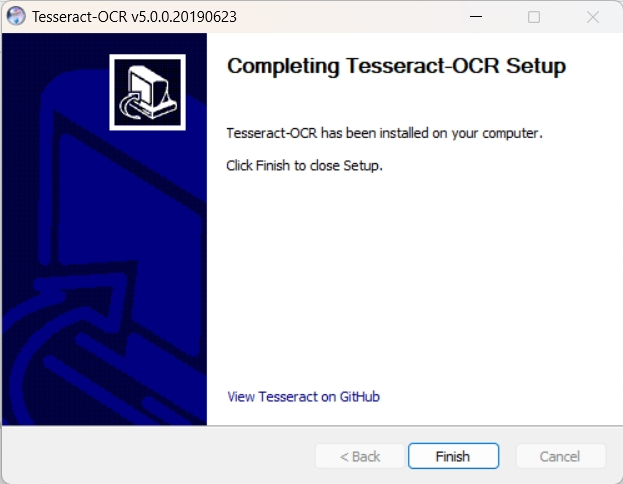
2.1.2 配置Tesseract环境变量
为了能够在命令行中执行 Tesseract 命令进行识别,我们需要在电脑环境变量中配置 Tesseract 。
对于 windows 11 系统来说,打开设置,找到系统,高级系统设置,安装下面图示操作即可。
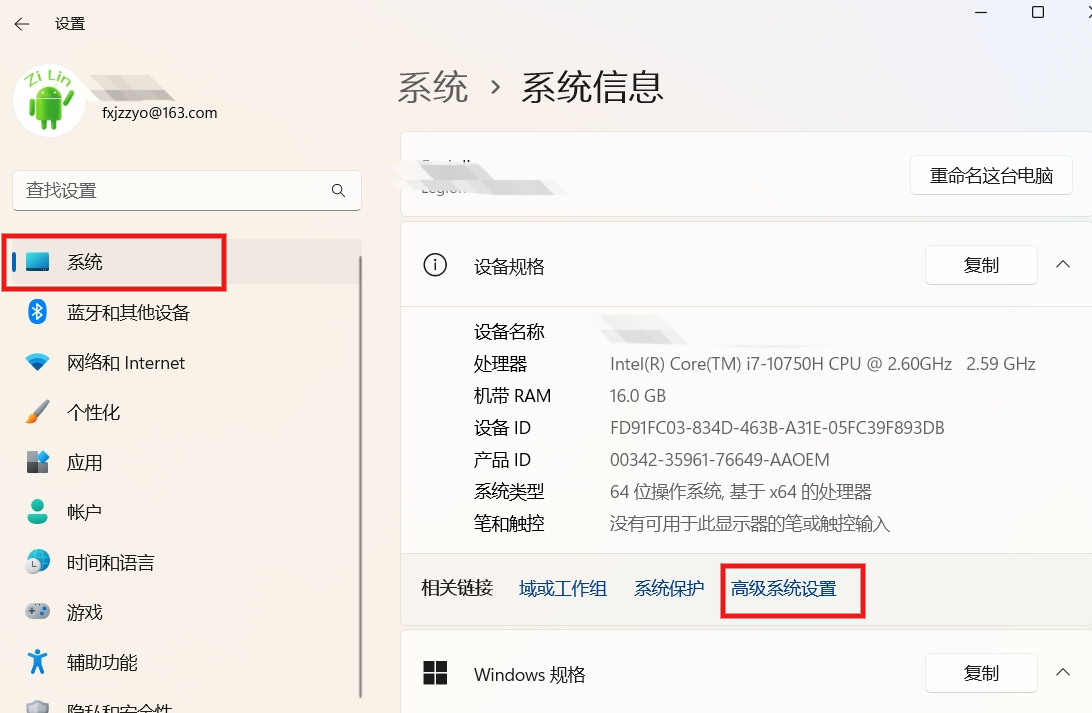
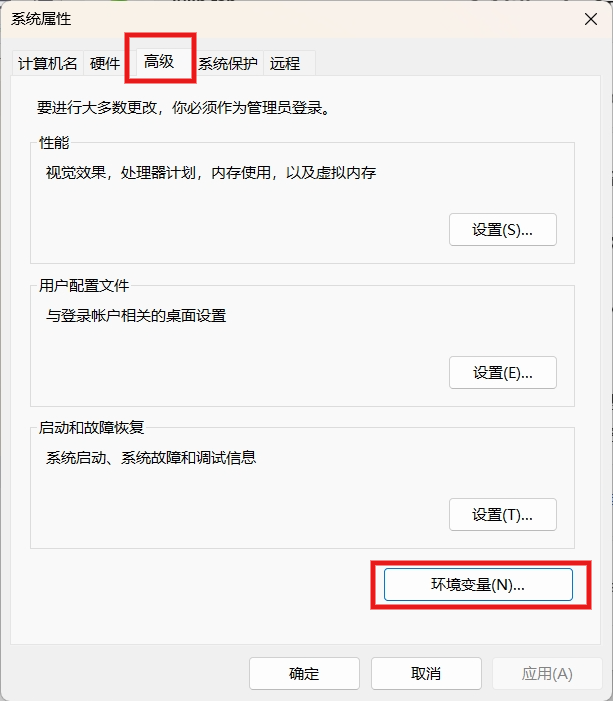
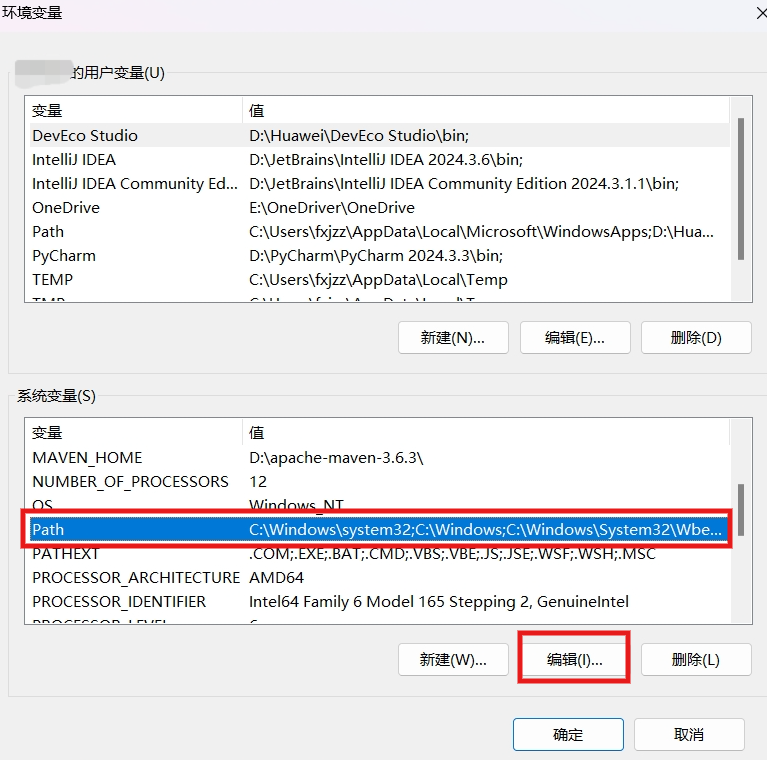
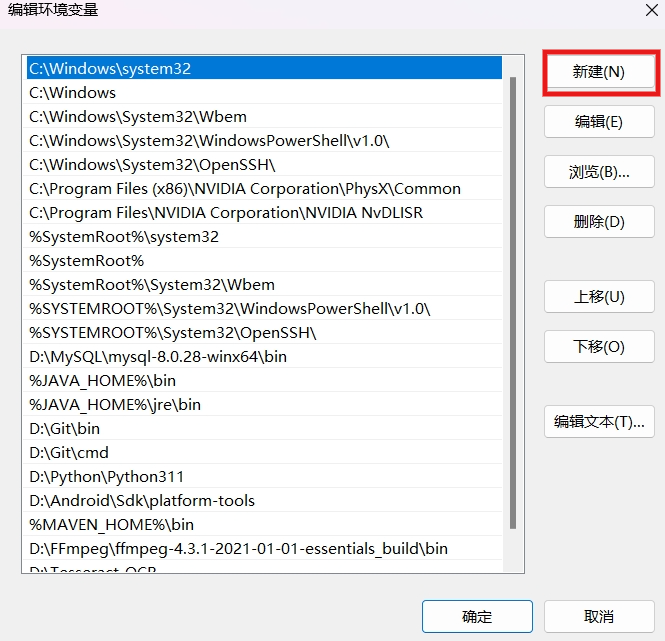
新建 Path ,输入上文中的安装目录。
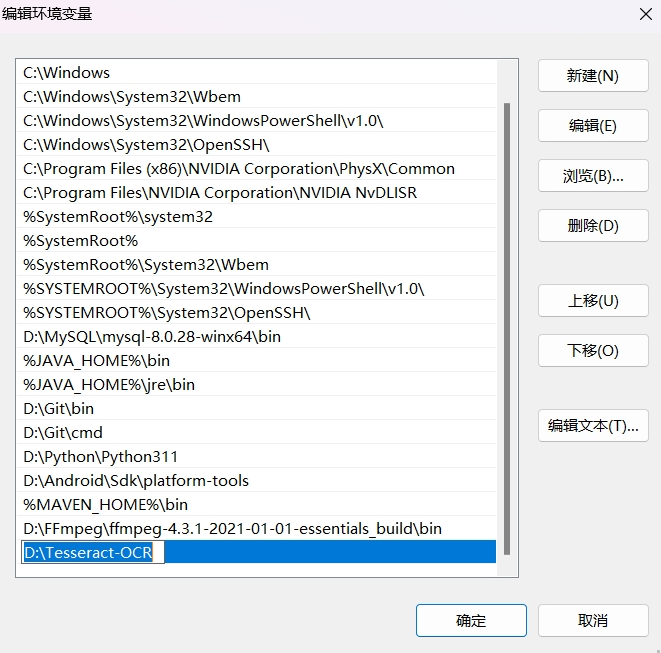
新建系统环境变量
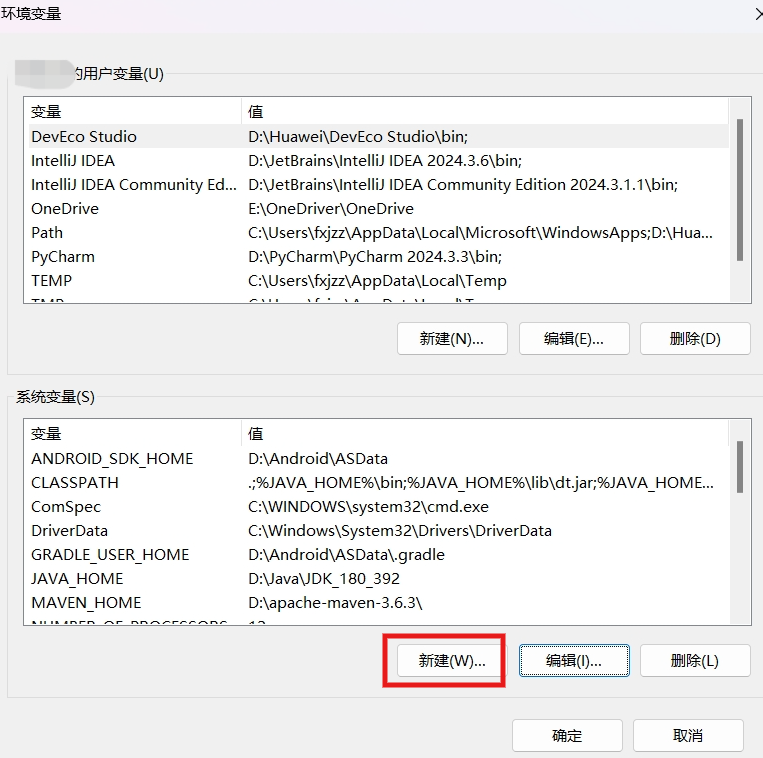
新建环境变量,名:TESSDATA_PREFIX
值为Tesseract 安装目录下的 tessdata文件夹路径:D:\Tesseract-OCR\tessdata
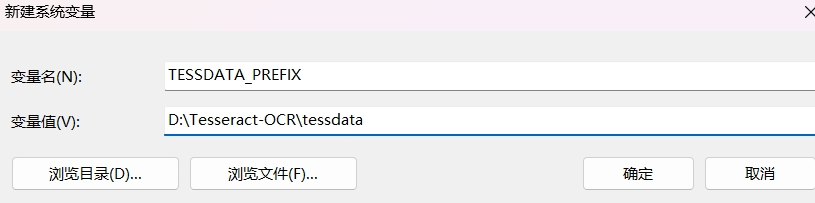
点击确定后,Tesseract 的环境变量配置完成。
2.1.3 验证Tesseract 环境变量配置成功
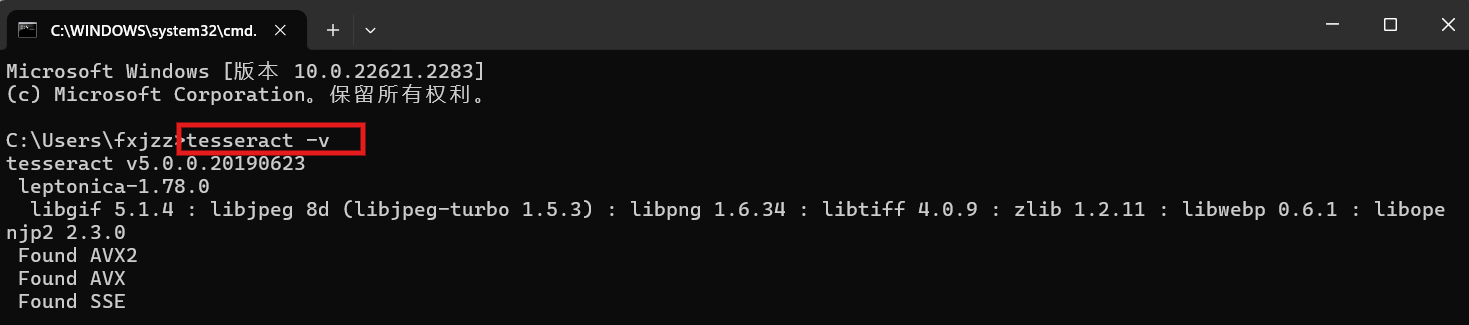
电脑底部任务栏搜索"终端",打开终端,输入命令:tesseract -v
如果成功输出 tesseract 版本号,代表环境变量配置成功。
2.2 下载 JDK
经过本人验证,截止当前2025年8月10日,必须下载 Amazon Corretto提供的 OpenJDK 1.8.0_392 ,其他版本的JDK已经无法运行下面数据标注所用的软件 jTessBoxEditor。如果使用其他版本的JDK很可能会遇到 jTessBoxEditor 运行闪退的问题。
Amazon Corretto Open JDK 下载地址:https://aws.amazon.com/cn/corretto/
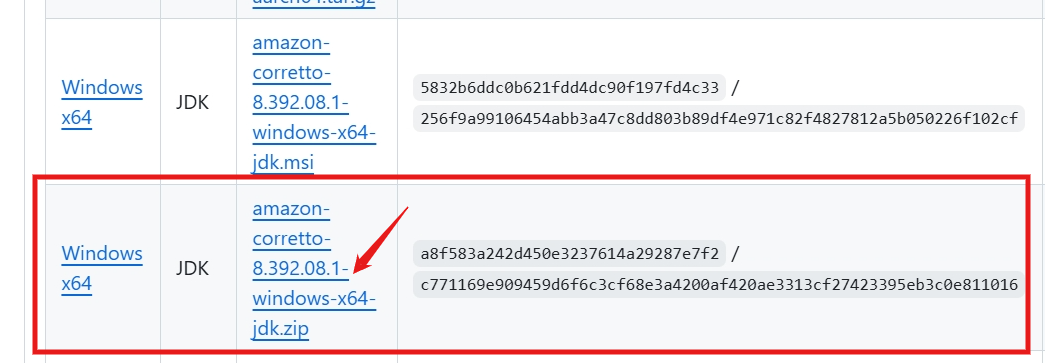
里面可以选择不同版本的JDK,本文所需的是Amazon Corretto OpenJDK 1.8.0_392(Corretto-8.392.08.1),直接给出下载页面:https://github.com/corretto/corretto-8/releases?page=2
点击下图所示的链接下载 zip 包,解压到本地文件夹即可。
2.2.1 安装 JDK
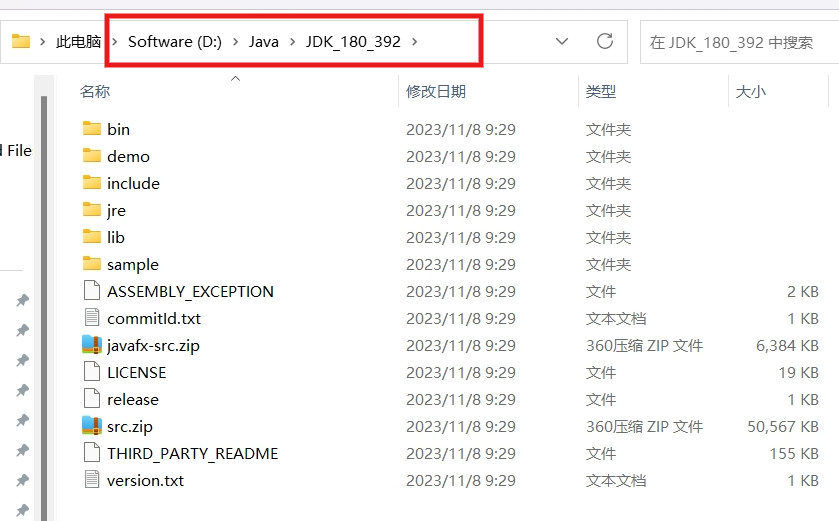
由于我们下载的是 zip 包,直接解压后即可使用,无须安装过程。
解压后的文件应该如下图所示:比如我的放到了 D:\Java\JDK_180_392
2.2.2 配置JDK环境变量
接下来配置JDK环境变量,可以参考JDK8下载安装与Win10下Java环境变量配置。
唯一需要注意的是,在设置环境变量 JAVA_HOME 的值时,路径要写成上面我们JDK下载解压后的位置: D:\Java\JDK_180_392
2.2.3 验证 JDK 环境变量
同样的打开终端,输入命令:java -version,如果能输出如下图的版本号等说明信息,则代表JDK环境变量配置成功。

2.3 下载 jTessBoxEditor
jTessBoxEditor 是用来标注文字的工具,使用它我们可以准备自己的训练数据。
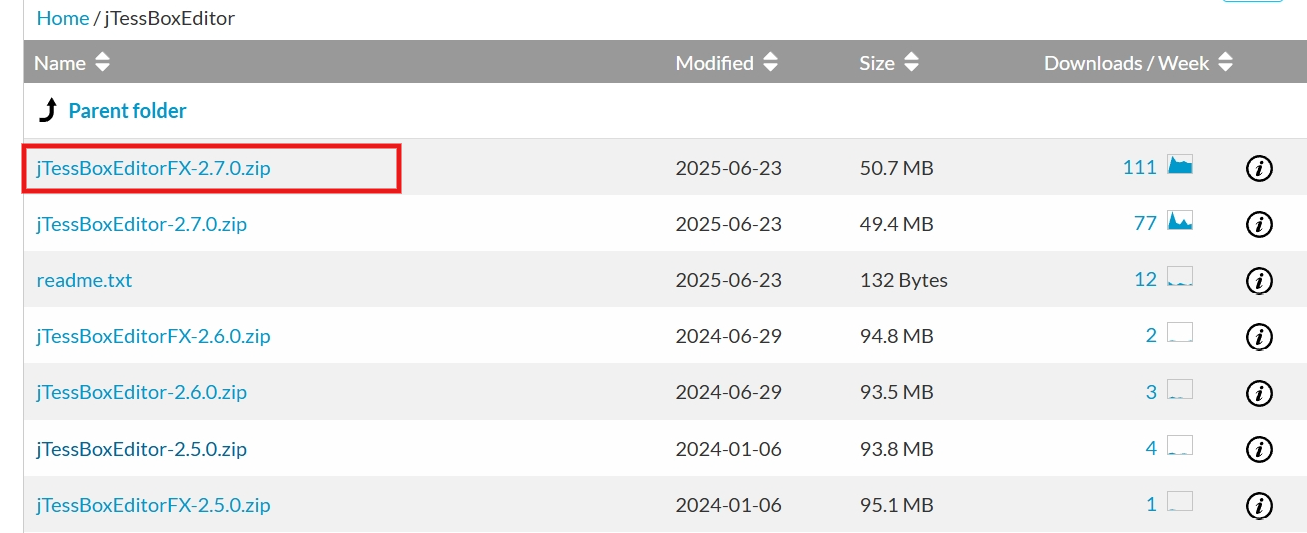
下载地址:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
比如,点击下方 jTessBoxEditorFX-2.7.0.zip 下载 2.7.0 的版本。
下载后,解压到本地某个文件夹。
2.3.1 安装 jTessBoxEditor
直接解压后即可使用,无须安装。
2.3.2 运行 jTessBoxEditor
网上大多教程描述的运行方式是 双击 train.bat 启动运行,但目前 JDK已经不支持 jTessBoxEditor 的运行了,这种方式运行会发现闪退。这是本操作流程中的第一个坑!
经过本人验证,目前能启动的方式是:
使用上文所安装的 OpenJDK 1.8.0_392,在 jTessBoxEditor 所在的文件夹下使用终端打开,执行命令:java -jar .\jTessBoxEditorFX.jar
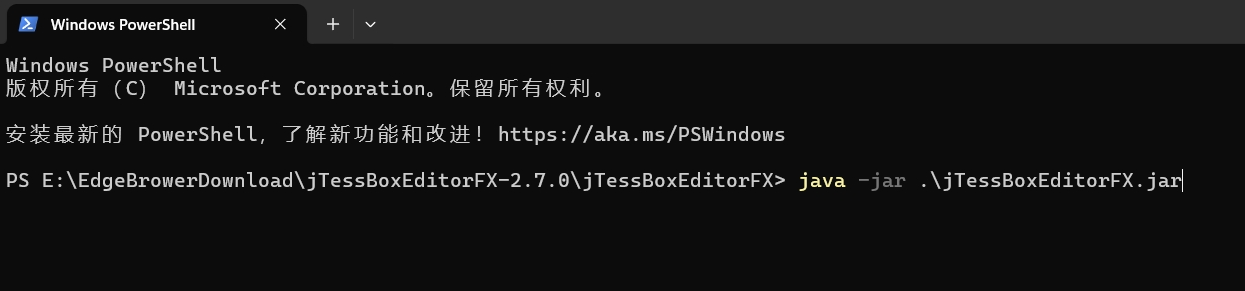
启动后,界面如下,说明成功运行了。
至此,我们终于完成了准备工作!✿✿ヽ(°▽°)ノ✿
3. 训练数据
接下来开始准备我们自己的字体训练数据。
3.1 准备图片素材
首先准备一个训练数据的文件夹,后面我们所有的操作都会在这个文件夹下。
注意,文件夹所在的路径一定不能含中文!这是第二个坑点!
比如,我准备的文件夹路径是:E:\OCRTrain
然后,准备一些带字的图片,注意要保证是白底黑字的!这是第三个坑点 !否则的话,在 jTessBoxEditor 中会识别不出来。如何做成白底黑字有很多种方法,可以用PS工具,或者网上搜索图像二值化在线处理工具,总之处理后的图像如下即可:

当然,图片素材越多越好,这里仅用1张图片来作为演示。
3.2 训练数据
3.2.1 生成 tif 文件
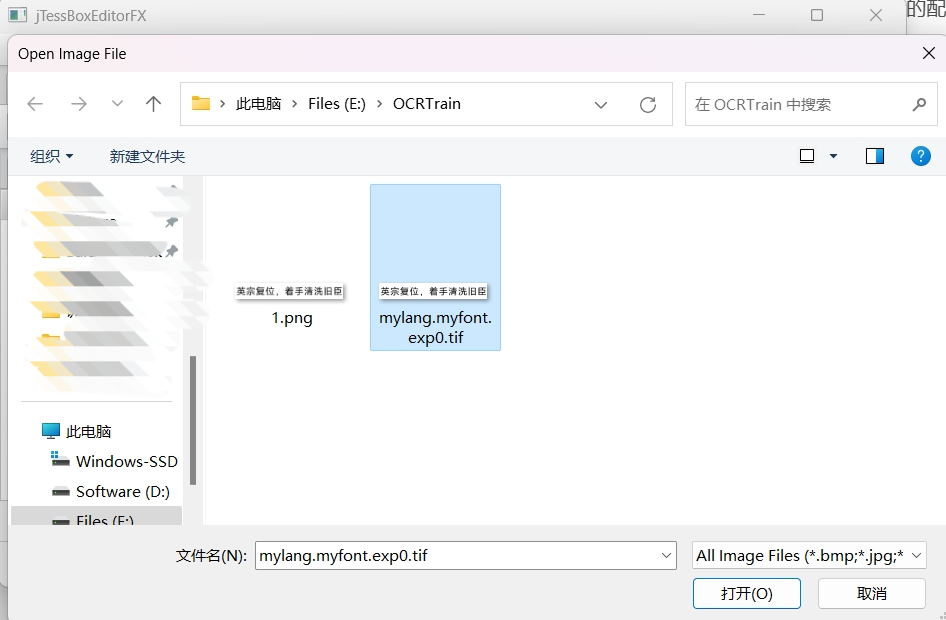
使用 jTessBoxEditor 进行训练数据,用上文所述方式启动 jTessBoxEditor,选择Tools->Merge TIFF,选择图片素材所在文件夹,选中要参与训练的图片。
注意筛选的文件类型要改成PNG,否则你可能发现没有可选择的文件。
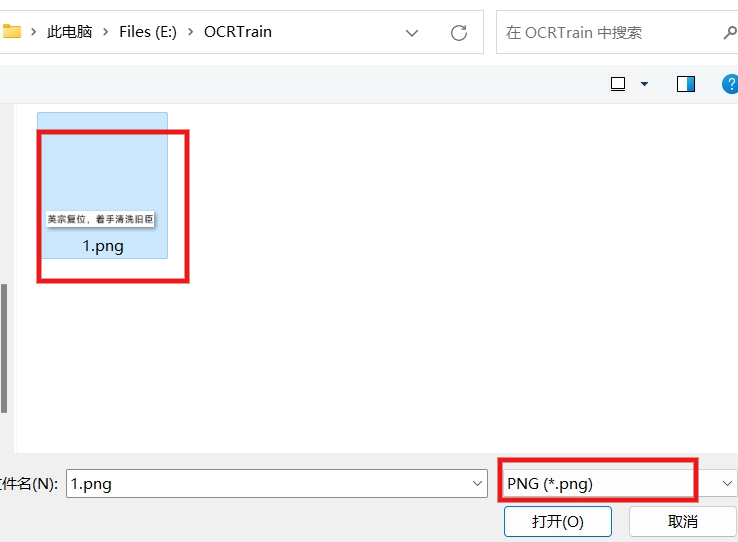
点击 "打开" 后会弹出对话框,让你保存成一种.tif格式的文件,文件命名为 mylang.myfont.exp0.tif
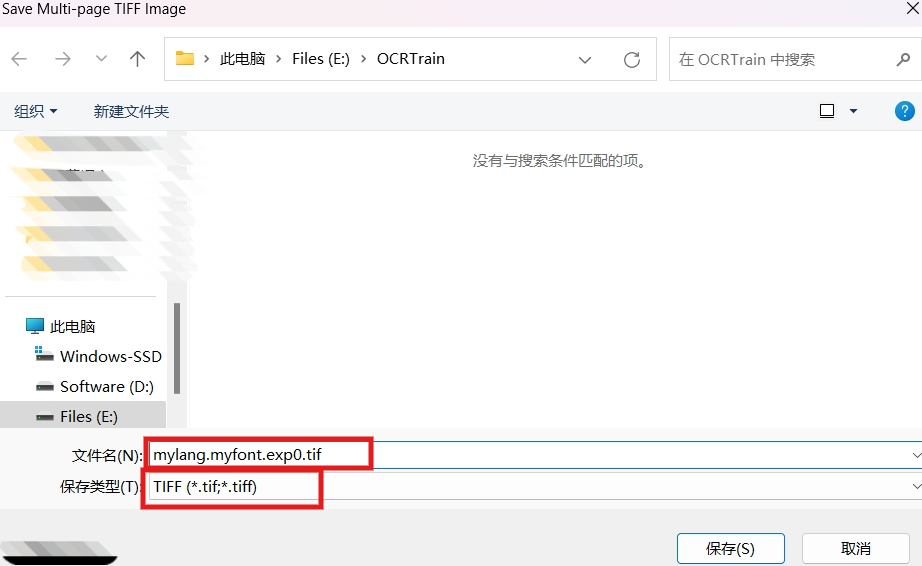
这里的文件命名有格式规范 :[lang].[fontname].exp[num].tif
- lang是语言名,这里我们起一个自己的名字即可,比如mylang
- fontname是字体名,也是起一个自己的名字,比如 myfont
- num为自定义数字,这里是 exp0
- 最后是固定后缀.tif
点击保存后,会弹出成功弹窗。
3.2.2 使用 tesseract 生成.box文件
在上一步骤生成的 mylang.myfont.exp0.tif 文件所在目录下打开终端,执行下面命令,执行完之后会生成 mylang.myfont.exp0.box 文件。
执行如下命令 : tesseract mylang.myfont.exp0.tif mylang.myfont.exp0 batch.nochop makebox
执行后,输出如下:
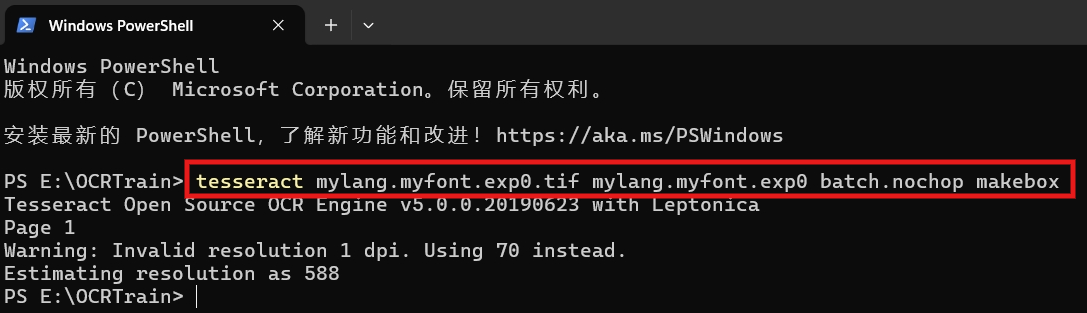
这里有可能输出错误,检查上文 TESSDATA_PREFIX 环境变量的配置是否正确!
3.2.3 使用 jTessBoxEditor 标注文件
.box文件记录了每个字符在图片上的位置和识别出的内容,训练前需要使用jTessBoxEditor调整字符的位置和内容。
打开 jTessBoxEditor 点击 Box Editor -> Open,打开步骤2中生成的 mylang.myfont.exp0.tif,会自动关联到 mylang.myfont.exp0.box 文件,这两文件要求在同一目录下。调整完点击"save"保存修改。
打开后,如下:
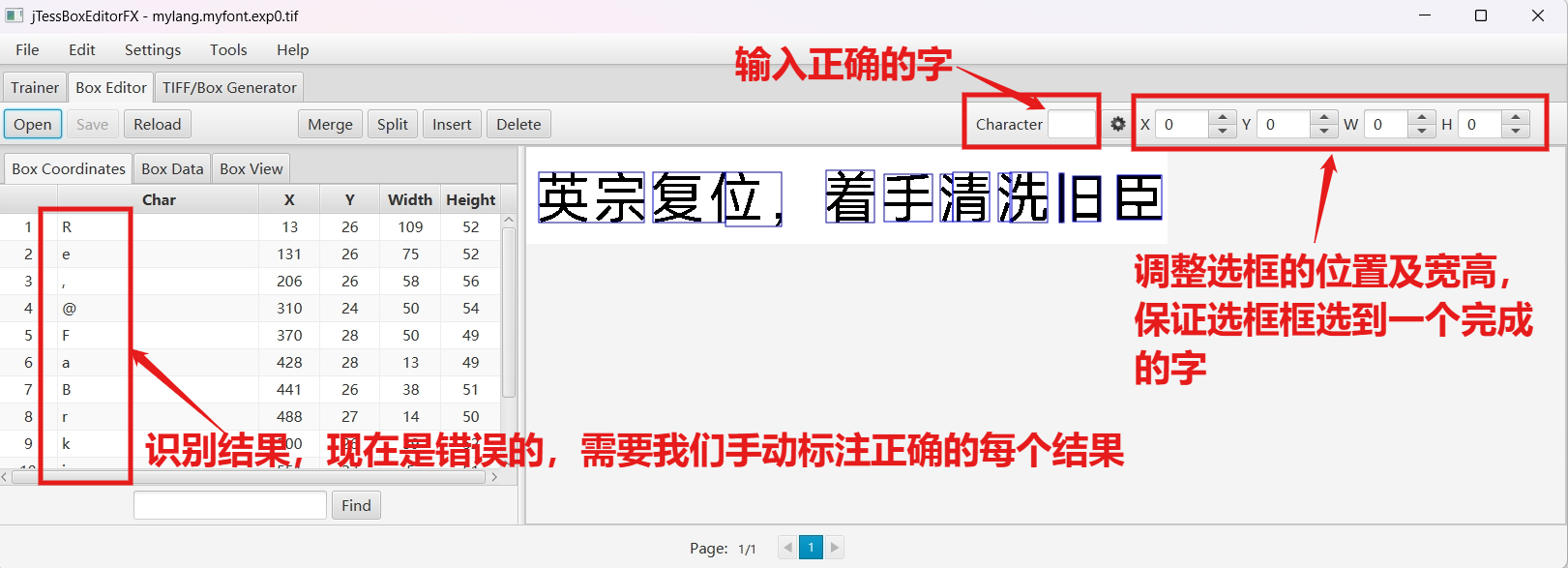
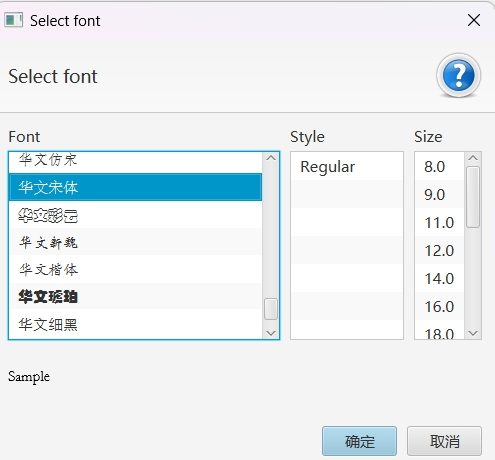
开始标注数据,这里有第四个坑点 ,标注正确的文字时无法输入中文!解决方式是:修改 jtessboxeditor 设置中的字体为宋体:
setting --> Font 里改字体为宋体,Regular
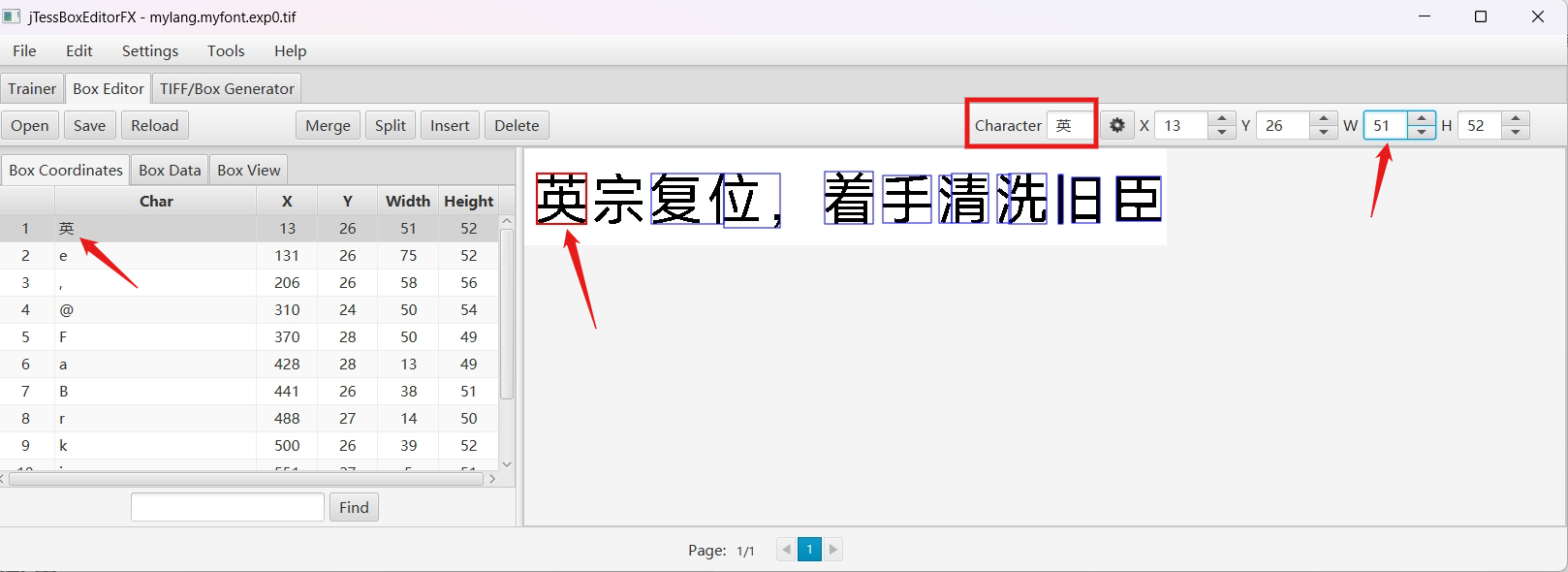
如下对第一个字"英"进行标注:
先选中第一个字英,鼠标在"英"上点一下,蓝框会变红,表示当前正在对该字进行标注。
然后在 Character 里输入 "英" 后回车,会发现左侧结果项里第1行 Char 里已经成功显示 "英"字;
最后调整 X、Y、W、H保证红框刚好框住"英"字,即可。
其他字的标注同理,全部标注完成后如下:
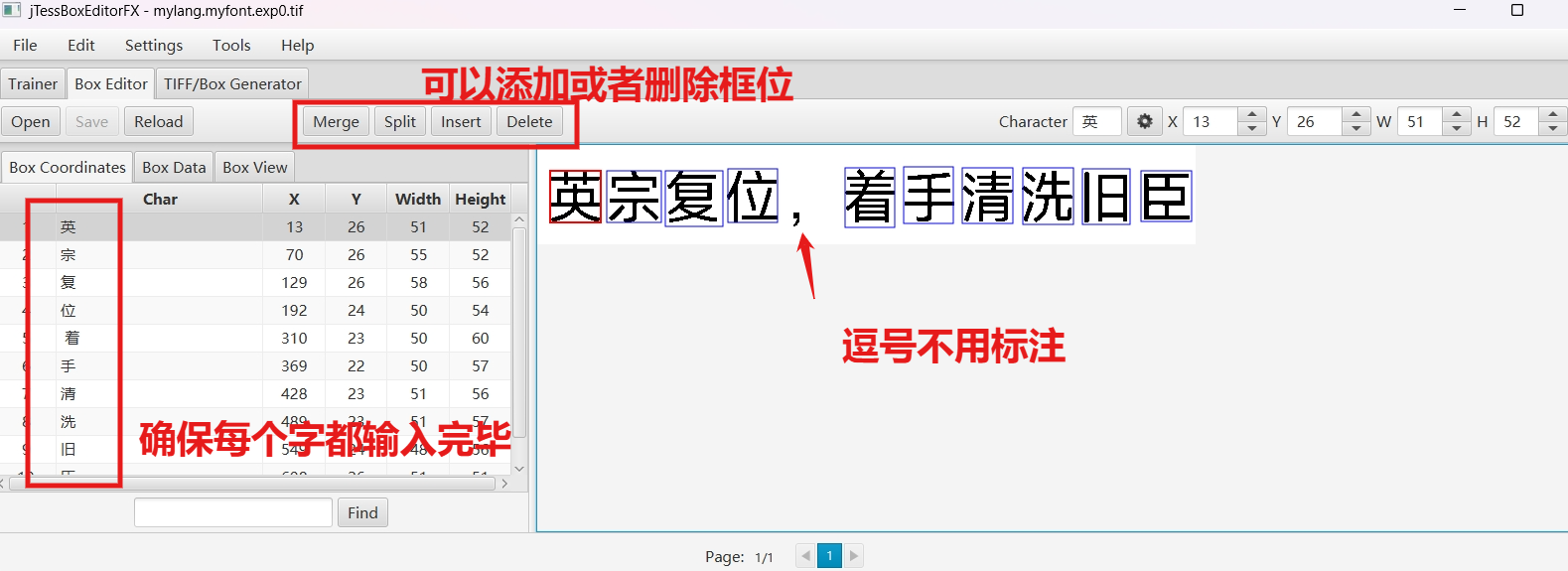
标注完成后,选择 File --> save 保存即可。
3.2.4 生成 font_properties 文件(该文件没有后缀名)
还是在当训练目录E:\OCRTrain下生成一个名为 font_properties 的文件,没有后缀。
这个文件是用来描述字体属性的,一般的教程会让执行命令 echo myfont 0 0 0 0 0 >font_properties 来新建文件,但这种方式会埋下一个大坑!那就是后面的步骤会直接卡住!
原因是直接生成的编码格式是utf16,而非UTF-8,这是第五个坑!!!
这里可以直接新建一个文本文件,命名为 font_properties:
输入内容 myfont 0 0 0 0 0 表示字体 myfont 的粗体、倾斜等共计5个属性。这里的"myfont"必须与 "mylang.myfont.exp0.box" 中的 "myfont" 名称一致。
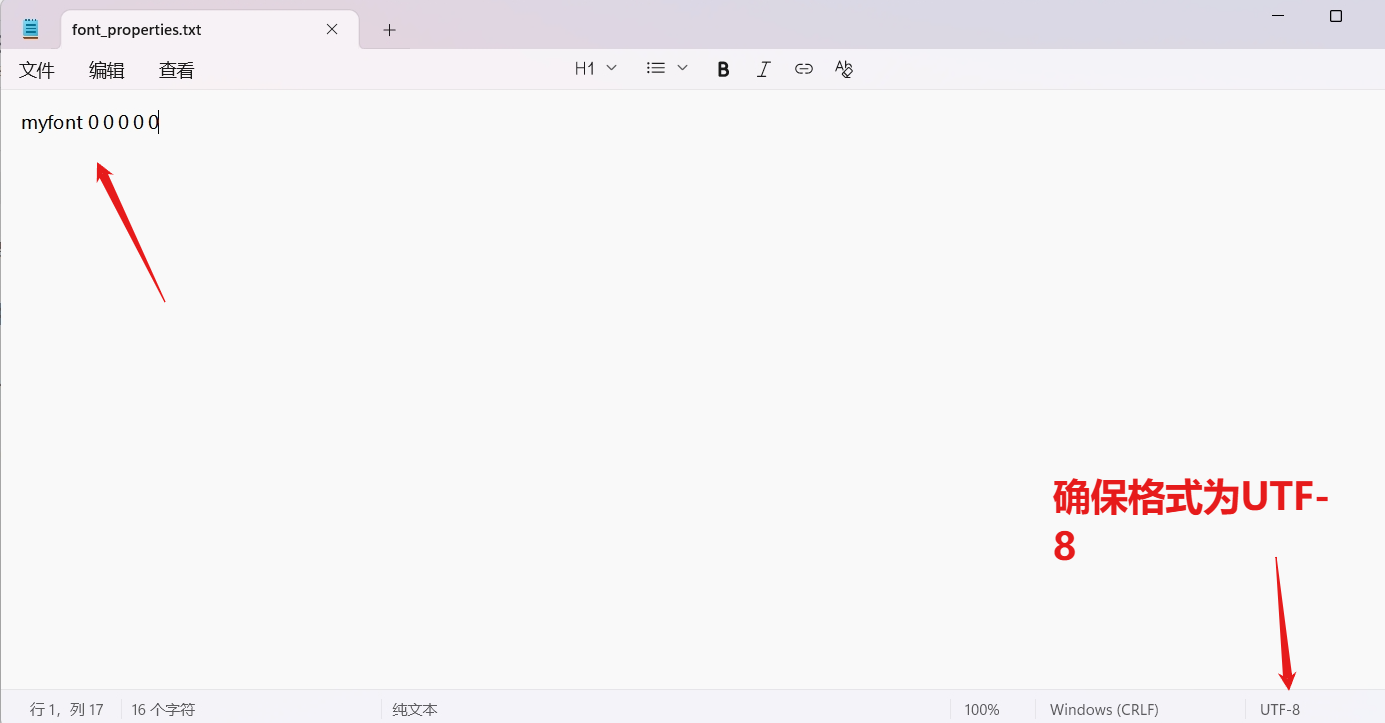
保存后,重命名,删除.txt后缀,确定。
3.2.5 使用 tesseract 生成 .tr 训练文件
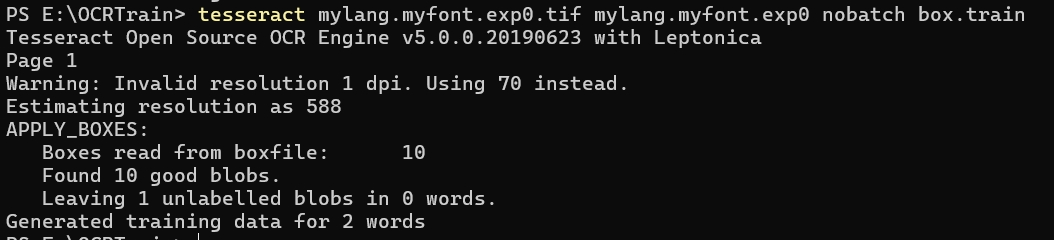
在当前目录下,打开终端,执行下面命令,执行完之后,会在当前目录生成 mylang.myfont.exp0.tr文件。
执行如下命令: tesseract mylang.myfont.exp0.tif mylang.myfont.exp0 nobatch box.train
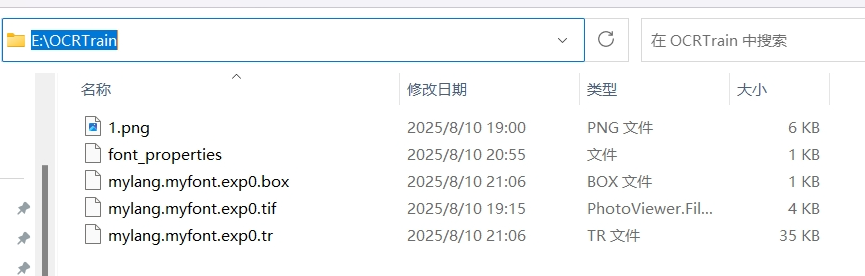
目前当前目录下有如下文件:
3.2.6 生成字符集文件
执行下面命令:执行完之后会在当前目录生成一个名为 "unicharset" 的文件。
执行命令: unicharset_extractor mylang.myfont.exp0.box

3.2.7 生成shape文件
执行下面命令,执行完之后,会生成 shapetable 和 mylang.unicharset 两个文件。
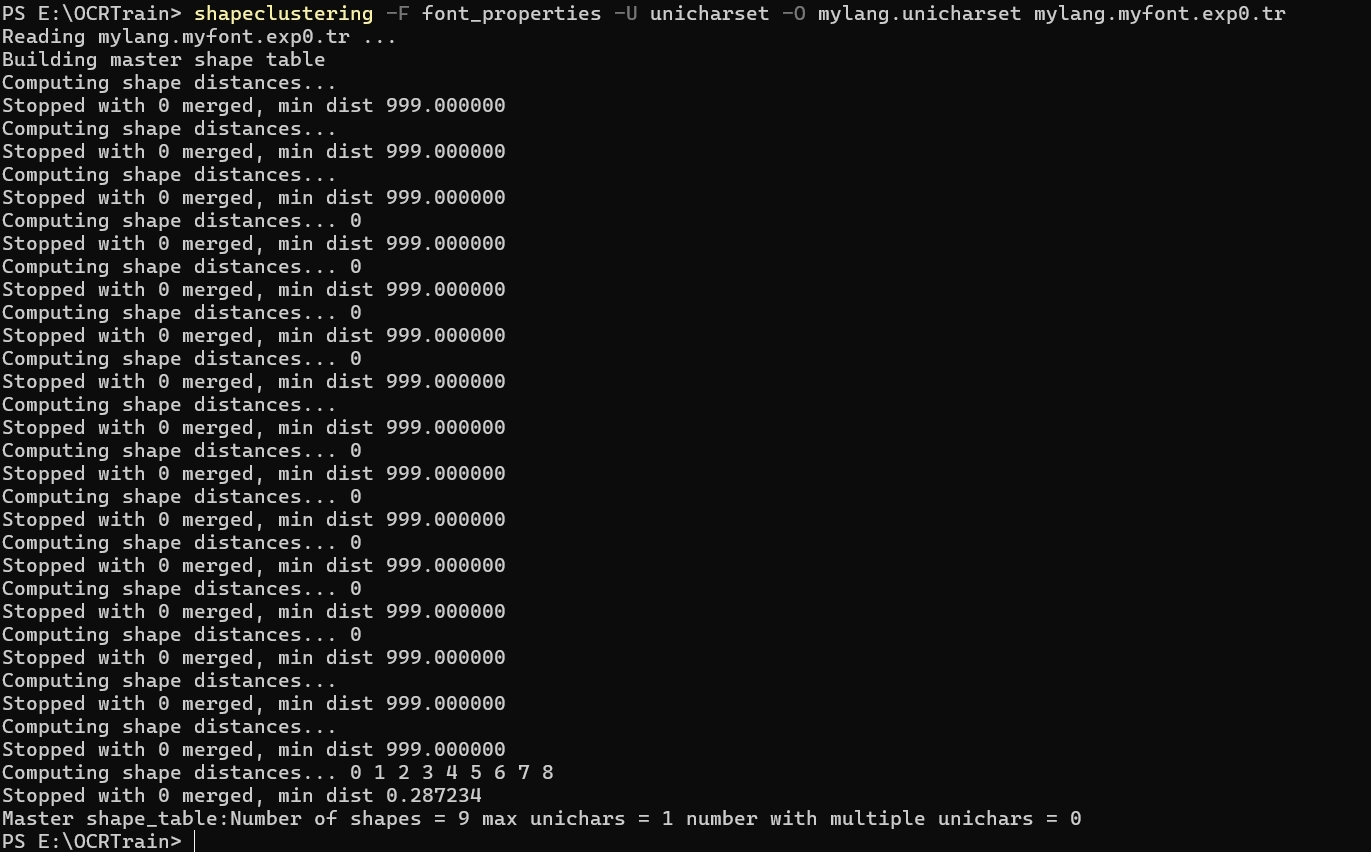
执行命令: shapeclustering -F font_properties -U unicharset -O mylang.unicharset mylang.myfont.exp0.tr
如果 font_properties 的编码格式不是 utf-8 的话,上述命令执行完会卡住。这就是上文说的第五个坑点。
3.2.8 生成聚字符特征文件
执行下面命令,会生成 inttemp、pffmtable、shapetable 和 mylang.unicharset 四个文件。
执行命令: mftraining -F font_properties -U unicharset -O mylang.unicharset mylang.myfont.exp0.tr

3.2.9 生成字符正常化特征文件
执行下面命令,会生成 normproto 文件。
执行命令: cntraining mylang.myfont.exp0.tr

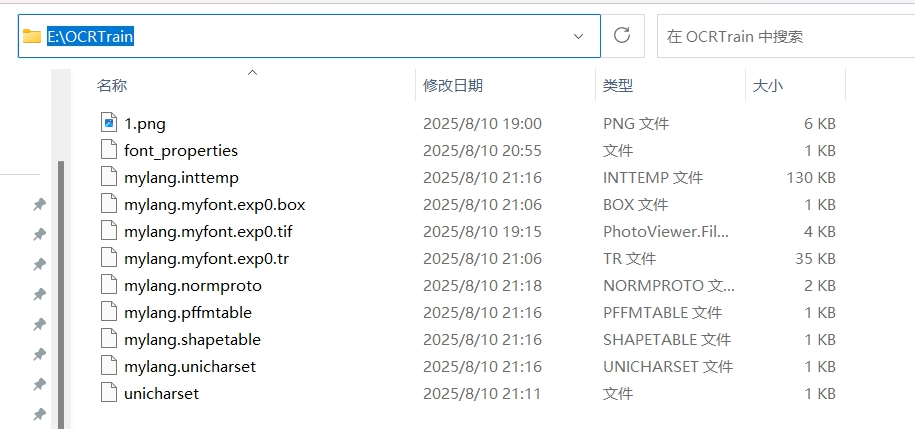
3.2.10 文件重命名
重新命名 inttemp、pffmtable、shapetable和 normproto 这四个文件的名字为 lang.xxx。
这里修改为 mylang.inttemp、mylang.pffmtable、mylang.shapetable 和 mylang.normproto
可直接在文件夹中重命名修改。
3.2.11 合并训练文件
执行下面命令,会生成 mylang.traineddata文件。
执行命令: combine_tessdata mylang.
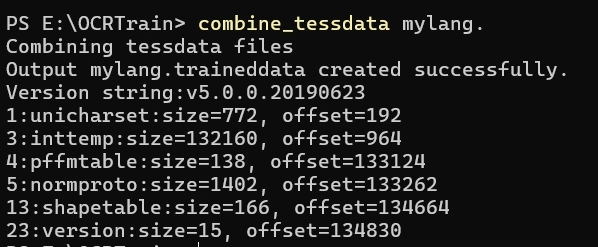
输出中的 1、3、4、5、13这些项不是 -1,表示新的语言包生成成功,即 mylang.traineddata 文件。
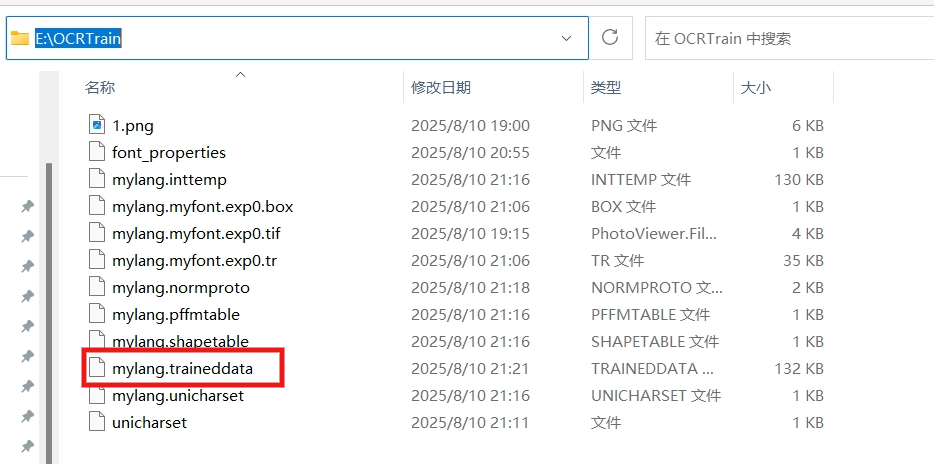
将生成的 mylang.traineddata 语言包文件复制到 Tesseract-OCR 安装目录下的tessdata文件夹中,就可以使用训练生成的语言包进行图像文字识别了。
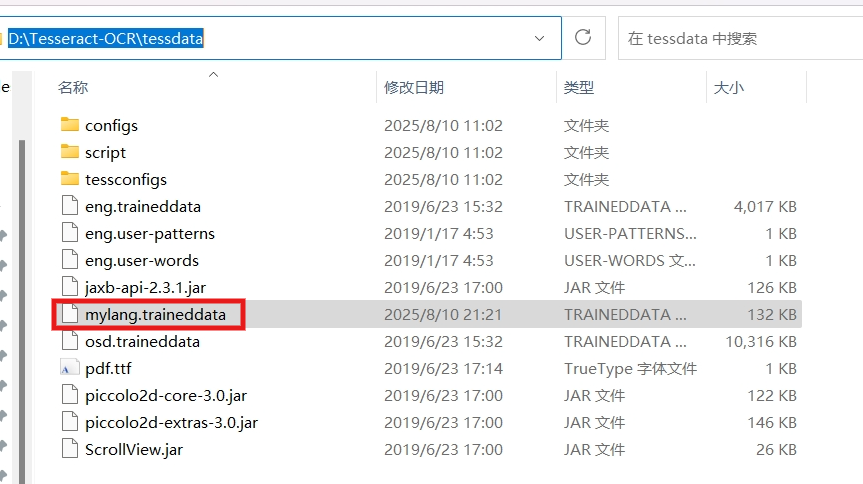
4. 验证识别效果
4.1 使用命令行验证
这里使用上文的训练图片进行OCR识别验证,还是在训练目录下打开终端。
输入命令:tesseract 1.png testT1 --l mylang
- testT1 是识别后存放结果的文本文件
- 注意,
-l是小写字母 L,代表 Language 语言的意思,而不是数字1 - 最后的 mylang 就是我们上面新生成的语言名。

查看结果:
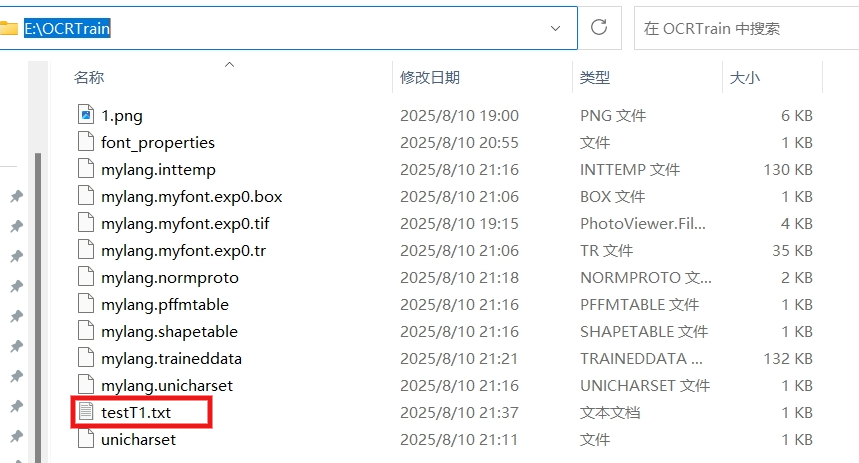
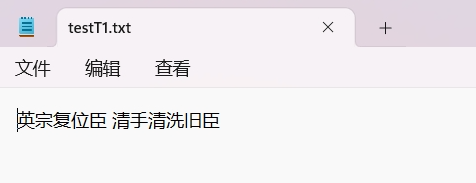
打开后可见内容如下:
4.2 使用Java代码验证
使用 Intellij Idea 新建 Java Maven工程,在 Test 代码中进行测试。
添加 Maven 依赖:
xml
<dependencies>
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>4.1.0</version>
</dependency>
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.4.0</version>
<exclusions>
<exclusion>
<groupId>com.sun.jna</groupId>
<artifactId>jna</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--单元测试的依赖-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>测试代码
java
import java.io.File;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
public class Test {
@org.junit.Test
public void testOCR()throws Exception {
// 测试图片路径
File imageFile = new File("E:\\OCRTrain\\1.png");
ITesseract instance = new Tesseract();
instance.setDatapath("D:\\Tesseract-OCR\\tessdata"); // 设置语言库路径
instance.setLanguage("mylang"); // 设置语言为自己训练的语言
try {
String result = instance.doOCR(imageFile);
System.out.println(result);
} catch (TesseractException e) {
System.err.println(e.getMessage());
}
}
}输出结果:
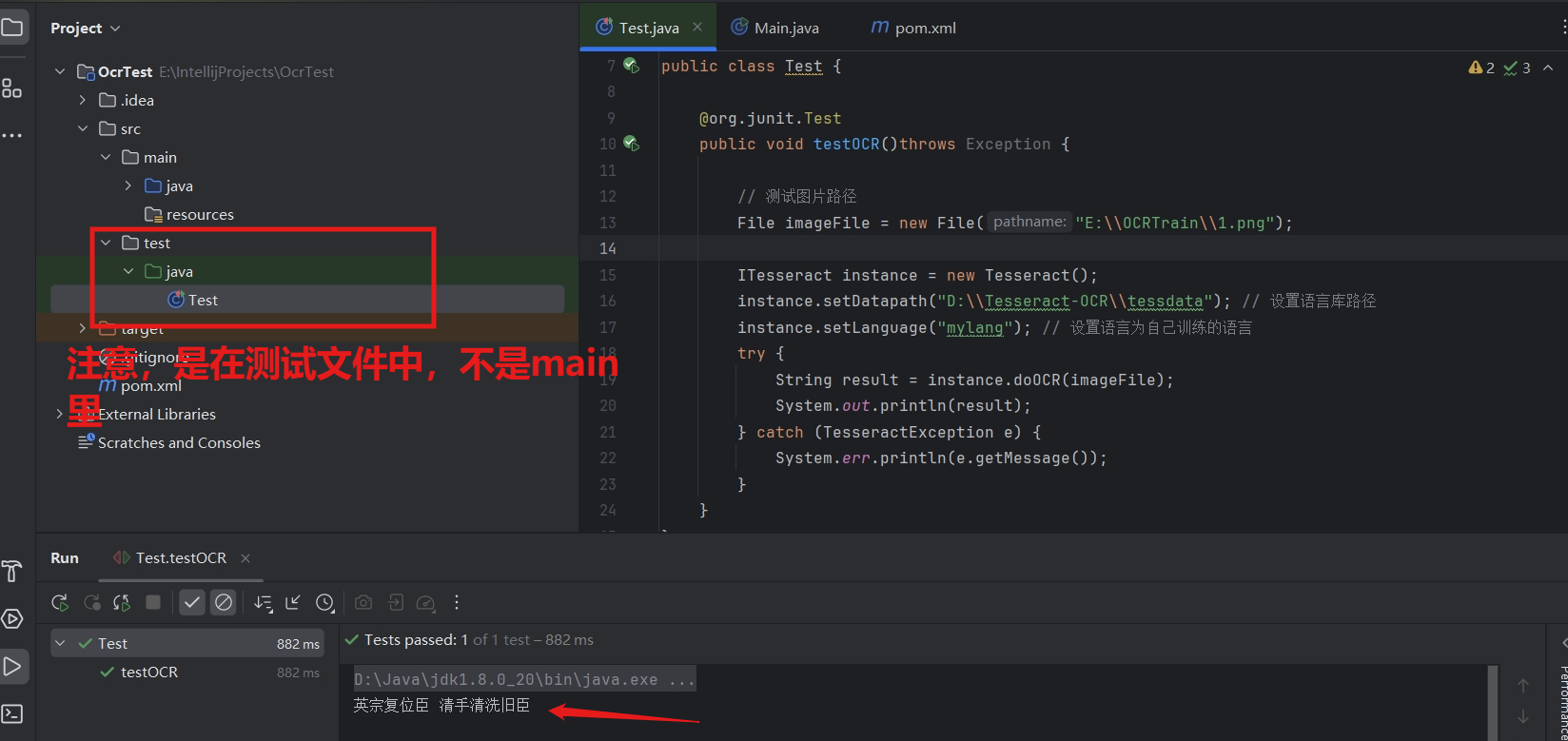
5. 总结
到此,我们终于完成了整个 Tesseract 从环境搭建 到训练数据准备 、训练数据字库生成 、最后到结果验证的全部过程!希望你也能顺利完成!
5.1 坑点
中间踩得的坑点如下:
-
坑1:jTessBoxEditor 无法启动
原因是 JDK 版本问题。解决方法:使用本文提到的
Amazon Corretto OpenJDK 1.8.0_392(Corretto-8.392.08.1),在 jTessBoxEditor 所在的文件夹下使用终端打开,执行命令:java -jar .\jTessBoxEditorFX.jar进行启动软件。 -
坑 2 :训练数据所用的文件夹所在的路径一定不能含中文
-
坑 3 :训练图片上的文字要保证是白底黑字的
-
坑 4 :标注文字时无法输入中文!
解决方式是:修改 jtessboxeditor 设置中的字体为宋体。
-
坑 5 :font_properties 文件编码格式要为 utf-8,否则 shapeclustering 命令会卡住。
如果本文对你有所帮助,欢迎支持哦~ Thanks♪(・ω・)ノ
相关链接: