TF-IDF 详解与实战教程
1. 概念与背景
TF-IDF(Term Frequency - Inverse Document Frequency)
在信息检索与文本挖掘中,我们经常需要衡量一个词语在文档中的重要性。
直觉上:
如果一个词在某篇文章中出现得多,可能比较重要(例如该文章的主题词)。
但如果一个词在所有文章中都出现(如"的""是""在"),它的重要性反而很低。
TF-IDF 就是用来平衡这两方面的统计方法:
-
TF(词频):衡量一个词在当前文档中的频率。
-
IDF(逆文档频率):衡量一个词在整个语料库中的稀有程度。
最终,TF-IDF 值越高,说明该词对某篇文章的权重越高。
TF-IDF 的意义
衡量一个词对一篇文档的重要程度,从而有效提取文本特征,广泛用于文本分析和信息检索领域。
1. 区分关键词与常用词
-
词频(TF) 突出了词在当前文档中出现的频率,反映该词在文档内部的重要性。
-
逆文档频率(IDF) 抑制了在大部分文档中普遍出现的词(如"的"、"是"、"and"),因为它们对区分文档贡献不大。
这样,TF-IDF 能突出在某篇文档中频繁出现,但在整个语料库中较少出现的词,这类词往往才是文档的主题词或关键词。
2. 降低无效词的影响
在文本处理中,常见的停用词和高频词对文本分类、聚类、搜索等任务贡献有限。TF-IDF 自动帮我们降低这些词的权重,避免它们干扰模型判断。
3. 提升文本挖掘和检索效果
-
搜索引擎用TF-IDF来衡量关键词与文档的相关性,帮助排序和匹配最相关的内容。
-
文本分类和聚类中,TF-IDF向量作为特征输入,提高算法的效果和准确度。
-
关键词提取帮助快速理解文档主题和摘要。
2. 公式推导
2.1 词频(TF)

举例:
-
文档 d:
"机器 学习 是 人工 智能 的 分支" -
词
"机器"出现 1 次,总词数 7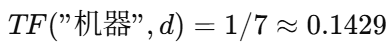
2.2 逆文档频率(IDF)
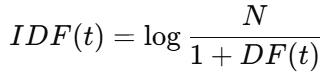
-
N:总文档数
-
DF(t):包含词 t 的文档数
-
分母加 1 是为了防止分母为 0(平滑处理)
举例:
-
总文档数 N=100
-
词
"机器"出现在 5 篇文档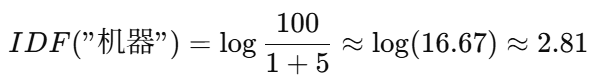
2.3 TF-IDF
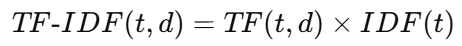
举例:
-
"机器"在某篇文章的 TF = 0.1429,IDF = 2.81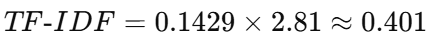
3. 优缺点分析
优点
-
简单高效,易于计算
-
能有效降低常见词的权重
-
在搜索引擎、关键词提取等场景中表现好
缺点
-
忽略词语的顺序与上下文(是词袋模型的局限)
-
不能处理同义词、语义信息
-
在短文本中效果可能不稳定
4. Python 实现案例
4.1 TfidfVectorizer使用
Kotlin
from sklearn.feature_extraction.text import TfidfVectorizer
# 示例文本
docs = [
"机器 学习 是 人工 智能 的 分支",
"深度 学习 是 机器 学习 的 一个 子集",
"人工 智能 涉及 机器 学习 和 深度 学习"
]
# 初始化 TF-IDF 向量器
vectorizer = TfidfVectorizer()
# 计算 TF-IDF 矩阵
tfidf_matrix = vectorizer.fit_transform(docs)
# 输出结果
print("特征词表:", vectorizer.get_feature_names_out())
print("TF-IDF 矩阵:\n", tfidf_matrix.toarray())运行结果示例: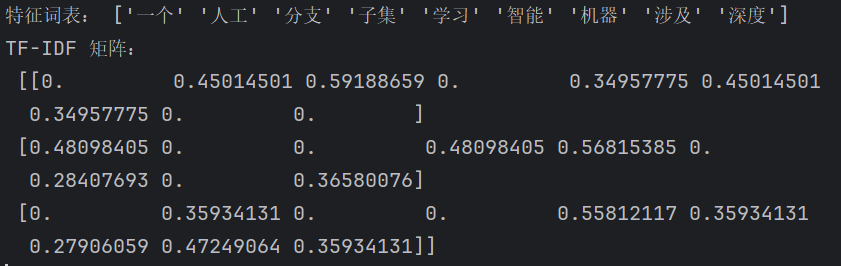
4.2 更多显示
Kotlin
# 导入sklearn库中的TfidfVectorizer类,用于将文本转换为TF-IDF特征向量
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
corpus = [
"机器 学习 是 人工 智能 的 分支",
"深度 学习 是 机器 学习 的 一个 子集",
"人工 智能 涉及 机器 学习 和 深度 学习"
]
# 创建TfidfVectorizer对象,用于后续的文本向量化处理
vectorizer = TfidfVectorizer()
# 拟合模型并将文本转换为TF-IDF矩阵
# fit_transform()方法会先分析文本语料库,构建词汇表,然后vectorizer将每个文本转换为对应的TF-IDF向量
TFIDF = vectorizer.fit_transform(corpus)
# 打印TF-IDF矩阵(稀疏矩阵形式,只显示非零元素的位置和值)
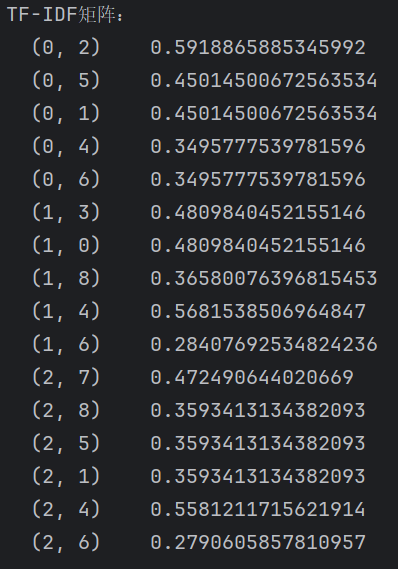
print("TF-IDF矩阵:")
print(TFIDF)
# 获取构建的词汇表,返回一个包含所有特征词的列表
wordlist = vectorizer.get_feature_names()
print("\n特征词表:")
print(wordlist)
# 将TF-IDF矩阵转换为稠密矩阵并转置,然后创建DataFrame
# 行索引为词汇表中的词语,列索引为原始文本的索引
df = pd.DataFrame(TFIDF.T.todense(), index=wordlist)
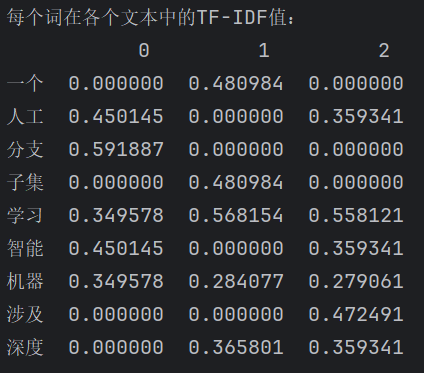
# 打印这个DataFrame,展示每个词在各个文本中的TF-IDF值
print("\n每个词在各个文本中的TF-IDF值:")
print(df)
# 提取DataFrame中第3列(索引为2)的数据,转换为列表
# 这表示第3个文本中各个词的TF-IDF值
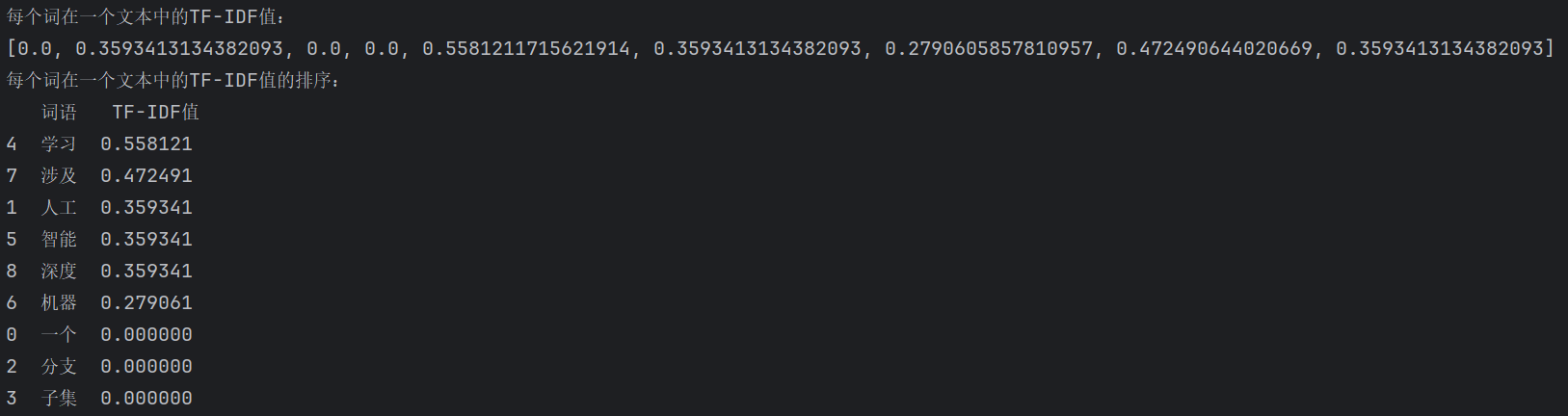
TFIDF_list = df.iloc[:,2].to_list()
print("\n每个词在一个文本中的TF-IDF值:")
print(TFIDF_list)
# 直接使用词语列表和对应的TF-IDF值创建DataFrame
# 列名分别为"词语"和"TF-IDF值"
# 使用pandas的sort_values方法按TF-IDF值降序排序,False表示降序排列
df_words = pd.DataFrame({
"词语": wordlist,
"TF-IDF值": TFIDF_list
}).sort_values(by="TF-IDF值", ascending=False)
print("每个词在一个文本中的TF-IDF值的排序:")
print(df_words)
5. 应用场景
-
搜索引擎:根据关键词匹配计算相关度
-
关键词提取:快速找出文章的核心词
-
文本分类:作为特征输入到机器学习模型
-
相似度计算:配合余弦相似度判断文本相似性
6. 总结
-
TF 关注的是"词在文档中的重要性"
-
IDF 关注的是"词在整个语料库的稀有程度"
-
TF-IDF 通过乘积平衡这两者,效果简洁高效
-
在实际 NLP 项目中,TF-IDF 常作为基础特征或搜索权重计算方法