引言
在上一章中,我们探讨了机器学习的基础知识,包括监督学习、非监督学习和强化学习。本章将深入探讨深度学习(Deep Learning),这是机器学习的子领域,专注于使用多层神经网络来学习复杂的数据模式。深度学习是人工智能(AI)领域的核心驱动力,2025年已推动了生成式AI、多模态模型和自主代理等领域的重大突破。
本章将涵盖以下内容:
- 深度学习的定义和历史
- 神经网络基础(人工神经元、激活函数、前向传播、反向传播)
- 高级神经网络架构(CNN、RNN、Transformer、MoE)
- 深度学习的应用(图像识别、NLP、生成模型等)
- 深度学习框架(TensorFlow、PyTorch、Keras)
- 挑战与未来方向(过拟合、计算资源、伦理问题、效率趋势)
- 实践示例:使用PyTorch构建一个简单的CNN模型
什么是深度学习?
深度学习是机器学习的一个分支,专注于使用多层神经网络(通常称为深层网络)来学习数据中的复杂模式。这些网络通过层层堆叠的非线性变换,能够捕捉数据的抽象特征,实现对图像、语音、文本等复杂数据的处理。深度学习的核心优势在于其能够自动提取特征,无需人工设计。
深度学习的历史
深度学习的起源可以追溯到20世纪40年代,Warren McCulloch和Walter Pitts提出了第一个人工神经网络模型。1986年,Rumelhart等人提出的反向传播算法使训练多层神经网络成为可能。2006年,Hinton等人引入了深层信念网络(DBN),标志着深度学习的复兴。2012年,AlexNet在ImageNet竞赛中取得突破性成果,开启了深度学习在计算机视觉领域的黄金时代。随后,深度学习迅速扩展到自然语言处理、语音识别等领域。
2025年,深度学习已成为AI的核心技术。根据Stanford AI Index,全球AI市场规模约为3910亿美元,深度学习技术推动了多模态AI和生成式AI的快速发展。例如,Meta的Llama-4-Maverick模型(17B活跃参数,128个专家)展示了深度学习在多模态理解(文本和图像)方面的领先能力。
深度学习与AI、机器学习的关系
- 人工智能(AI):广义概念,指机器执行需要人类智能的任务。
- 机器学习(ML):AI的子领域,专注于从数据中学习。
- 深度学习(DL):ML的子领域,使用多层神经网络处理复杂数据。
简单来说,AI是目标,ML是方法,DL是ML的高级实现。
神经网络基础
神经网络是深度学习的核心,是模仿人类大脑工作方式的计算模型,由多个互联的节点(神经元)组成,组织成输入层、隐藏层和输出层。
人工神经元和激活函数
- 人工神经元 :接受多个输入信号,通过加权求和并应用激活函数产生输出。公式为:
y = f(\\sum_{i} w_i x_i + b)
其中,(x_i) 是输入,(w_i) 是权重,(b) 是偏置,(f) 是激活函数。 - 激活函数 :引入非线性,使网络能够学习复杂模式。常见激活函数包括:
- Sigmoid:将输出压缩到(0,1),适合二分类。
- ReLU(Rectified Linear Unit):(f(x) = \max(0, x)),加速训练。
- Tanh:将输出压缩到(-1,1),适合标准化数据。
以下是一个简单的神经元计算示例:
import numpy as np
# 输入和权重
inputs = np.array([1.0, 2.0, 3.0])
weights = np.array([0.2, 0.8, -0.5])
bias = 2.0
# 计算输出(使用ReLU激活函数)
output = np.maximum(0, np.dot(inputs, weights) + bias)
print("输出:", output)前向传播和反向传播
- 前向传播:输入数据通过网络层层传递,计算输出。
- 反向传播:通过计算损失函数相对于权重的梯度,更新权重以最小化损失。优化器(如SGD、Adam)用于调整权重。
图表说明:下面是一个神经网络结构图,展示输入层、隐藏层和输出层的连接,以及权重和激活函数的作用:
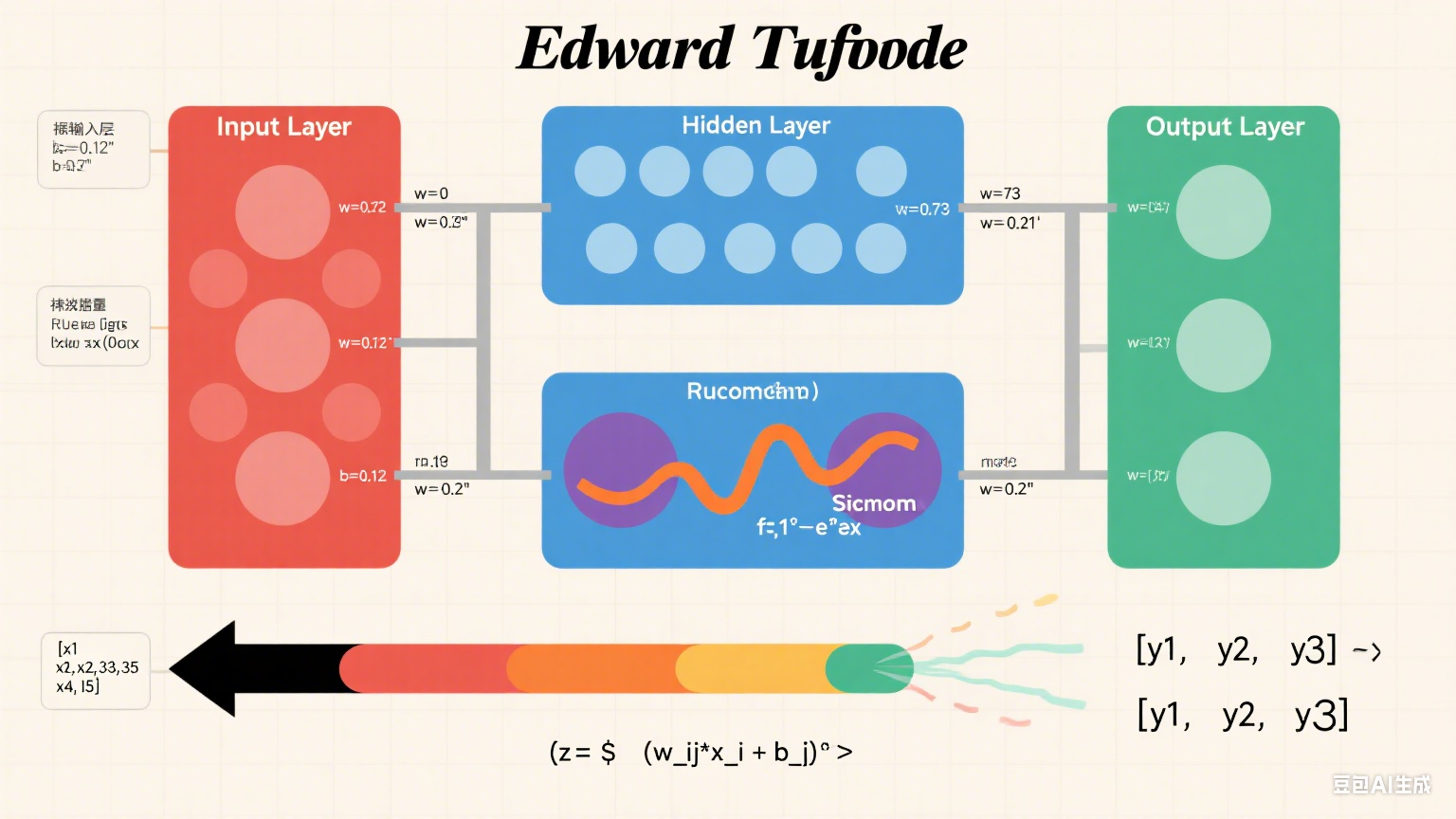
高级神经网络架构
深度学习的成功得益于各种高级神经网络架构的开发。以下是几种重要的架构:
卷积神经网络(CNN)
- 用途:处理图像数据,提取局部特征(如边缘、纹理)。
- 关键组件 :
- 卷积层:应用滤波器提取特征。
- 池化层:降低空间维度,减少计算量。
- 全连接层:进行分类或回归。
- 应用:图像分类、物体检测、语义分割。
- 示例:LeNet-5用于手写数字识别,ResNet用于复杂图像分类。
图表说明:此处可插入一个CNN架构图,展示卷积层、池化层和全连接层的结构。
循环神经网络(RNN)
- 用途:处理序列数据,如文本、语音。
- 关键特性:记忆单元,允许信息随时间传递。
- 改进版本 :
- LSTM(长短期记忆):通过门控机制解决梯度消失问题。
- GRU(门控循环单元):简化LSTM,提高效率。
- 应用:语言建模、语音识别、机器翻译。
Transformer和注意力机制
- 用途:处理长序列依赖,广泛用于自然语言处理。
- 关键特性:自注意力机制,动态分配权重给输入的不同部分。
- 应用:机器翻译、文本生成、聊天机器人。
- 示例:BERT、GPT、Llama-4。
混合专家(Mixture-of-Experts,MoE)架构
- 用途:构建大规模模型,同时保持高效。
- 关键特性:多个专家模型(小型网络),通过路由机制动态选择。
- 应用:大型语言模型、多模态AI。
- 示例:Meta的Llama-4-Maverick使用MoE架构,包含128个专家和17B活跃参数(总参数400B),支持文本和图像的多模态理解,上下文窗口高达1000万token。
深度学习的应用
深度学习已广泛应用于以下领域:
图像识别和计算机视觉
- 任务:物体检测、图像分类、语义分割。
- 模型:ResNet、EfficientNet、YOLO。
- 应用:自动驾驶(如百度Apollo)、医疗影像分析(如肺部CT扫描)。
自然语言处理(NLP)
- 任务:机器翻译、情感分析、文本生成。
- 模型:BERT、GPT、Llama-4。
- 应用:聊天机器人(如小冰)、搜索引擎优化。
语音识别
- 任务:语音转文本、语音合成。
- 模型:Deep Speech、Wav2Vec。
- 应用:语音助手(如阿里云语音识别)、实时字幕。
生成模型
- 任务:生成文本、图像、视频。
- 模型:GAN、VAE、Diffusion Models(如Stable Diffusion)。
- 应用:艺术生成、虚拟试衣、视频合成。
多模态AI
- 任务:处理文本、图像、音频等多种数据。
- 模型:Llama-4-Maverick、CLIP。
- 应用:视觉问答、多媒体生成。
- 示例:Llama-4-Maverick支持12种语言的文本和图像处理,在视觉推理和代码生成方面超越GPT-4o和Gemini 2.0。
其他应用
- 推荐系统:个性化推荐(如淘宝、Netflix)。
- 医疗:疾病诊断、药物发现。
- 金融:欺诈检测、算法交易。
深度学习框架
深度学习框架简化了模型开发和部署。以下是几种主流框架:
| 框架 | 开发者 | 特点 | 适用场景 |
|---|---|---|---|
| TensorFlow | 生产级部署,生态系统完善 | 工业应用、研究 | |
| PyTorch | 动态计算图,灵活性强 | 研究、快速原型 | |
| Keras | 社区开发 | 高层API,易于上手 | 初学者、快速开发 |
这些框架提供预构建的层、优化器和工具,支持快速实验和生产部署。
挑战与未来方向
深度学习面临以下挑战:
- 过拟合:深层网络容易过拟合,使用正则化(如Dropout、权重衰减)缓解。
- 计算资源:训练需要GPU/TPU,成本高昂。
- 伦理问题:模型偏见、隐私问题需透明性和公平性。
- 效率问题:大型模型计算复杂,需优化。
2025年的趋势包括:
- 多模态AI:如Llama-4-Maverick,支持文本和图像处理。
- 模型效率:量化(如FP8)、剪枝、知识蒸馏降低计算需求。
- 自主代理:深度学习驱动的AI代理(如Microsoft 365 Copilot)自主执行任务。
- 伦理与监管:关注公平性、透明度和隐私保护。
实践示例:CNN for MNIST
以下是一个使用PyTorch构建的简单CNN模型,用于MNIST手写数字识别(28x28灰度图像,0-9数字)。
安装PyTorch
pip install torch torchvision代码实现
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# 数据加载
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False)
# 定义CNN模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1) # 输入1通道,输出32通道,3x3卷积核
self.conv2 = nn.Conv2d(32, 64, 3, 1) # 输入32通道,输出64通道
self.fc1 = nn.Linear(9216, 128) # 全连接层
self.fc2 = nn.Linear(128, 10) # 输出10类
def forward(self, x):
x = self.conv1(x)
x = nn.functional.relu(x)
x = self.conv2(x)
x = nn.functional.relu(x)
x = nn.functional.max_pool2d(x, 2) # 2x2最大池化
x = torch.flatten(x, 1)
x = self.fc1(x)
x = nn.functional.relu(x)
x = self.fc2(x)
return x
net = Net()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 训练模型
for epoch in range(2): # 训练2个epoch
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
running_loss = 0.0
print('训练完成')
# 测试模型
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'测试集10000张图像的准确率: {100 * correct / total}%')结果分析
模型通常在测试集上达到95%以上的准确率,展示了CNN在图像分类任务中的强大能力。
图表说明:此处可插入一个训练损失曲线图,展示损失随epoch减少的趋势。
结论
本章介绍了深度学习的基础知识,从定义和历史到高级架构和应用。我们探讨了2025年的最新趋势,如多模态AI和高效模型,并通过一个简单的CNN示例展示了深度学习的实践方法。下一章将深入探讨自然语言处理(NLP),介绍深度学习在语言理解和生成中的应用。
参考资料: