文章目录
- 一、预定义符号
- 二、#define定义常量:便捷的符号替换
- 三、#define定义宏:带参数的文本替换
- 四、带有副作用的宏参数
- 五、宏替换的规则:预处理的执行步骤
- 六、宏与函数的对比:各有优劣
- 七、#和##运算符:字符串化与记号粘合
- 八、命名约定:区分宏与函数
- 九、#undef:移除宏定义
- 十、命令行定义:编译时动态配置
- 十一、条件编译:选择性编译代码
- 十二、头文件的包含:正确引入外部代码
-
- [12.1 包含方式及查找策略](#12.1 包含方式及查找策略)
- [12.2 避免头文件重复包含](#12.2 避免头文件重复包含)
- 十三、其他预处理指令
C语言的预处理阶段是代码编译前的重要环节,它负责处理以 #开头的各种指令,为后续的编译过程做好准备。预处理看似简单,实则包含了丰富的功能和细节,掌握这些知识能让我们写出更高效、更灵活的代码。
一、预定义符号
C语言为我们内置了一些预定义符号,它们在预处理期间就会被处理,我们可以直接在代码中使用,无需额外定义。这些符号能为我们提供很多有用的信息:
__FILE__:进行编译的源文件的文件名__LINE__:当前代码在文件中的行号__DATE__:文件被编译的日期(格式为"Mmm dd yyyy")__TIME__:文件被编译的时间(格式为"hh:mm:ss")__STDC__:如果编译器遵循ANSI C标准,其值为1;否则未定义
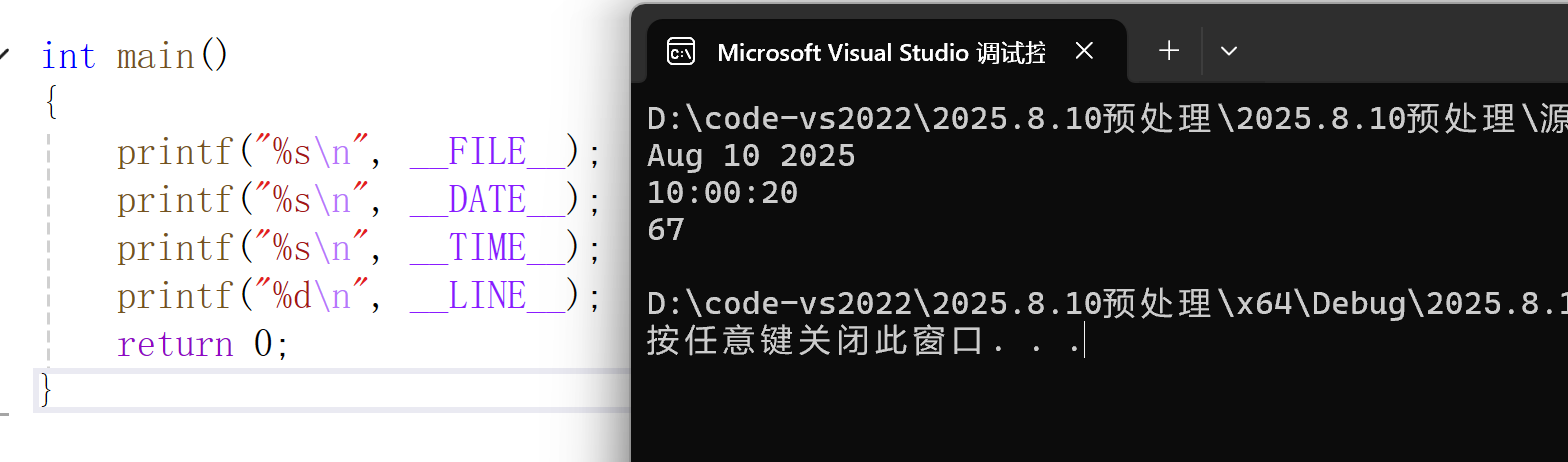
这些符号在调试代码时非常有用,例如:
c
printf("Error in file: %s at line: %d\n", __FILE__, __LINE__);当程序运行到这里时,会自动打印出错误所在的文件名和行号,帮助我们快速定位问题。
二、#define定义常量:便捷的符号替换
#define最基本的用法是定义常量,其基本语法为:
c
#define name stuff常见用法示例:
- 定义数值常量:
#define MAX 1000 - 为关键字创建简短别名:
#define reg register - 替换复杂实现为更形象的符号:
#define do_forever for(;;) - 简化代码编写:
#define CASE break;case(在switch语句中自动添加break)
注意事项:
- 不要随意添加分号 :
例如#define MAX 1000;这样的定义是不推荐的。当在
c
if(condition)
max = MAX;
else max = 0;中使用时,替换后会变成
c
if(condition)
max = 1000;;
else max = 0;导致if和else之间出现两条语句,引发语法错误。
- 长内容的分行处理 :
如果定义的内容过长,可以分成多行书写,除最后一行外,每行末尾都加上反斜杠(续行符)。反斜杠后面不能有任何内容
c
#define DEBUG_PRINT printf("file:%s\tline:%d\t \
date:%s\ttime:%s\n", \
__FILE__, __LINE__, \
__DATE__, __TIME__)三、#define定义宏:带参数的文本替换
#define还允许我们定义带参数的宏(macro),实现更灵活的文本替换。宏的声明方式为:
c
#define name(parameter-list) stuff其中parameter-list是由逗号分隔的参数列表,它们会出现在stuff中。
关键注意点:
-
参数列表与名称紧连 :参数列表的左括号必须与
name紧邻,中间不能有空白,否则参数列表会被解释为stuff的一部分。 -
运算符优先级问题 :
例如
#define SQUARE(x) x * x这个宏,当传入SQUARE(a + 1)时,会被替换为a + 1 * a + 1,结果为a + a + 1而非预期的(a+1)^2。解决方法是给参数和整体加上括号:#define SQUARE(x) (x) * (x)。更复杂的情况:
#define DOUBLE(x) (x) + (x),当调用10 * DOUBLE(5)时,会被替换为10 * (5) + (5),结果为55而非100。正确的定义应为#define DOUBLE(x) ((x) + (x))。结论:用于数值表达式求值的宏,应给参数和整体都加上括号,避免运算符优先级导致的意外结果。
四、带有副作用的宏参数
当宏参数在宏定义中出现多次,且参数带有副作用时,可能会产生不可预测的结果。副作用 指表达式求值时产生的永久性效果(如x++会改变x的值,而x+1则不会)。
例如:
c
#define MAX(a, b) ((a) > (b) ? (a) : (b))
int x = 5, y = 8, z;
z = MAX(x++, y++);预处理后会变成:
c
z = ((x++) > (y++) ? (x++) : (y++));执行后,x的值变为6,y变为10,z变为9,与直观预期可能不符。这就是副作用参数带来的问题。
五、宏替换的规则:预处理的执行步骤
在扩展#define定义的符号和宏时,预处理器遵循以下步骤:
- 调用宏时,首先检查参数是否包含
#define定义的符号,若有则先替换。 - 将替换文本插入到原位置,宏的参数名被其值替换。
- 再次扫描结果文件,若包含
#define定义的符号,重复上述过程。
重要注意:
- 宏参数中可以包含其他
#define定义的符号,但宏不能递归。 - 预处理器不会搜索字符串常量的内容(即字符串中的符号不会被替换)。
六、宏与函数的对比:各有优劣
宏和函数都能实现代码复用,但它们在多个方面存在差异:
| 属性 | #define定义宏 | 函数 |
|---|---|---|
| 代码长度 | 每次使用都会插入代码,可能大幅增加程序长度(除非宏很短) | 代码只出现一次,每次调用都使用同一份代码 |
| 执行速度 | 更快(无函数调用和返回开销) | 较慢(存在函数调用和返回的额外开销) |
| 操作符优先级 | 可能受周围表达式优先级影响,需谨慎使用括号 | 参数只在传参时求值,结果传递给函数,表达式求值可预测 |
| 副作用参数 | 参数若多次出现,副作用可能导致不可预料的结果 | 参数只在传参时求值一次,副作用易控制 |
| 参数类型 | 与类型无关,只要操作合法即可用于任何类型 | 与类型相关,不同类型可能需要不同函数(即使功能相同) |
| 调试 | 不方便调试(预处理阶段已替换) | 可逐语句调试 |
| 递归 | 不能递归 | 可以递归 |
宏的独特优势:
宏可以接受类型作为参数,而函数无法做到。例如:
c
#define MALLOC(num, type) (type *)malloc(num * sizeof(type))
// 使用
int *p = MALLOC(10, int);
// 替换后:(int *)malloc(10 * sizeof(int));七、#和##运算符:字符串化与记号粘合
7.1 #运算符:字符串化
#运算符能将宏的参数转换为字符串字面量,仅用于带参数的宏的替换列表中。
例如:
c
#define PRINT(n) printf("the value of "#n " is %d", n);
// 调用
int a = 10;
PRINT(a); // 替换后:printf("the value of ""a"" is %d", a);输出结果为:the value of a is 10
7.2 ##运算符:记号粘合
##可以将两边的符号合并为一个符号,允许从分离的文本片段创建标识符(称为"记号粘合")。
为不同类型定义求最大值的函数:
c
#define GENERIC_MAX(type)\
type type##_max(type a,type b)\
{\
return a > b ? a : b;\
}
GENERIC_MAX(int);//int_max()
GENERIC_MAX(float);//float_max()
int main()
{
int r1 = int_max(3, 9);
float r2 = float_max(4.6, 8.9);
printf("%d %f", r1, r2);
return 0;
}八、命名约定:区分宏与函数
宏和函数的使用语法相似,为了区分二者,通常遵循以下约定:
- 宏名全部大写(如
MAX、SQUARE) - 函数名不要全部大写(如
int_max、add)
九、#undef:移除宏定义
#undef指令用于移除已有的宏定义,语法为:
c
#undef NAME如果需要重新定义一个已存在的宏,应先使用#undef移除其旧定义。
十、命令行定义:编译时动态配置
许多C编译器允许在命令行中定义符号,用于启动编译过程。这在根据同一源文件编译程序的不同版本时非常有用。
根据内存大小动态调整数组长度:
c
// 源文件program.c
#include <stdio.h>
int main() {
int array[ARRAY_SIZE];
for (int i = 0; i < ARRAY_SIZE; i++) {
array[i] = i;
printf("%d ", array[i]);
}
return 0;
}编译时在命令行定义ARRAY_SIZE:
bash
# Linux环境
gcc -D ARRAY_SIZE=10 program.c # 定义数组长度为10十一、条件编译:选择性编译代码
条件编译指令允许我们选择性地编译或放弃某些语句,常用于调试代码的开关控制。
常见条件编译指令:
- 基本形式:
c
#if 常量表达式
// 代码段
#endif预处理器会求值常量表达式,为真则编译代码段。
- 多分支形式:
c
#if 常量表达式
// 代码段1
#elif 常量表达式
// 代码段2
#else
// 代码段3
#endif- 判断符号是否定义:只判断是否被定义,不判断真假
c
#if defined(symbol) // 等价于 #ifdef symbol
// 代码段
#endif
#if !defined(symbol) // 等价于 #ifndef symbol
// 代码段
#endif- 嵌套指令:
c
#if defined(OS_UNIX)
#ifdef OPTION1
unix_version_option1();
#endif
#elif defined(OS_MSDOS)
#ifdef OPTION2
msdos_version_option2();
#endif
#endif应用示例:调试代码控制
c
#define __DEBUG__ 1 // 定义调试符号
int main() {
int arr[10] = {0};
for (int i = 0; i < 10; i++) {
arr[i] = i;
#ifdef __DEBUG__
printf("arr[%d] = %d\n", i, arr[i]); // 仅调试时编译
#endif
}
return 0;
}十二、头文件的包含:正确引入外部代码
头文件包含是预处理阶段的重要操作,用于将其他文件的内容插入到当前文件中。
12.1 包含方式及查找策略
-
本地文件包含 :
#include "filename"查找策略:先在源文件所在目录查找,若未找到,再到标准库目录查找。
-
库文件包含 :
#include <filename.h>查找策略:直接到标准库目录查找,效率更高。
注意:库文件也可以用""包含,但会降低查找效率,且不易区分是本地文件还是库文件。
12.2 避免头文件重复包含
头文件被多次包含会导致代码冗余、编译时间增加,甚至出现重复定义错误。解决方法是使用条件编译:
- 方式一:
ifndef/define/endif
c
// test.h
#ifndef __TEST_H__ // 如果未定义__TEST_H__
#define __TEST_H__ // 定义__TEST_H__
// 头文件内容(函数声明、结构体定义等)
void test();
struct Stu { int id; char name[20]; };
#endif // __TEST_H__- 方式二:
#pragma once
更简洁的方式,直接在头文件开头添加:
c
#pragma once // 确保头文件只被包含一次
// 头文件内容十三、其他预处理指令
除了上述内容,C语言还有一些其他预处理指令,如:
#error:在编译时输出错误信息,终止编译#pragma:用于向编译器提供额外信息(如#pragma pack()控制结构体对齐)#line:修改当前行号和文件名
预处理是C语言编译过程中的第一个环节,它通过#define、#include、条件编译等指令,为代码的编译做好准备。掌握预处理的各种特性,不仅能帮助我们写出更高效、更灵活的代码,还能让我们在调试和维护程序时更得心应手。