目录
[1. 导入所需库](#1. 导入所需库)
[2. 数据读取与预处理](#2. 数据读取与预处理)
[3. 数据准备](#3. 数据准备)
[4. DBSCAN 参数调优](#4. DBSCAN 参数调优)
[5. 确定最佳参数并应用](#5. 确定最佳参数并应用)
简介
本次我们将聚焦于一款极具特色的聚类算法 ------DBSCAN。相较于 K-means 等需要预先指定簇数量的算法,DBSCAN 以其 "无监督自适应" 的特性,在聚类领域占据着不可替代的地位。
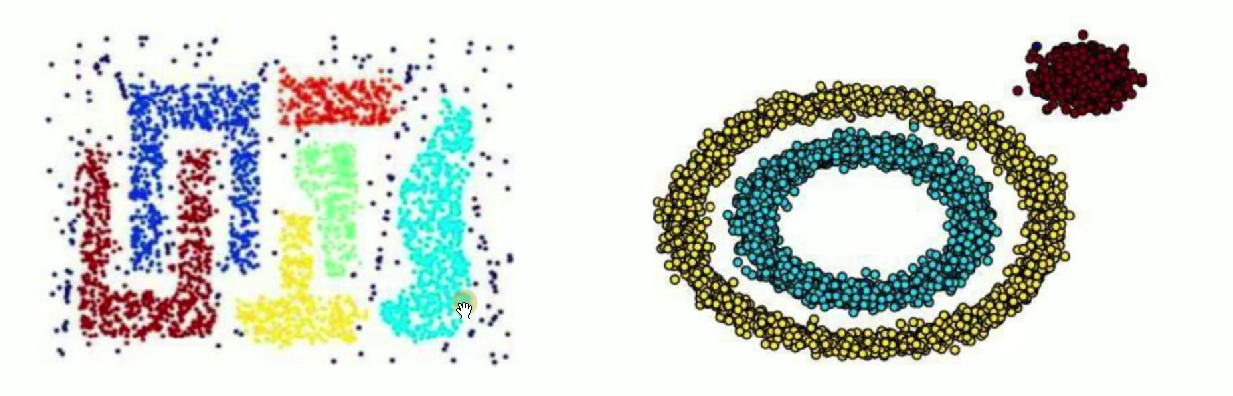
在这一课中,我们会深入剖析 DBSCAN 算法的核心原理。你将了解到它如何通过 "密度可达" 和 "核心对象" 等关键概念,自动发现数据集中任意形状的簇,还能识别出那些不属于任何簇的噪声点。这一特性让它在处理非凸形状、存在噪声的数据时,展现出远超传统聚类算法的优势。
一、dbscan相关概念
概念:
基于密度的带噪声的空间聚类应用算法,它是将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并在噪声的空间数据集中发现任意形状的聚类。
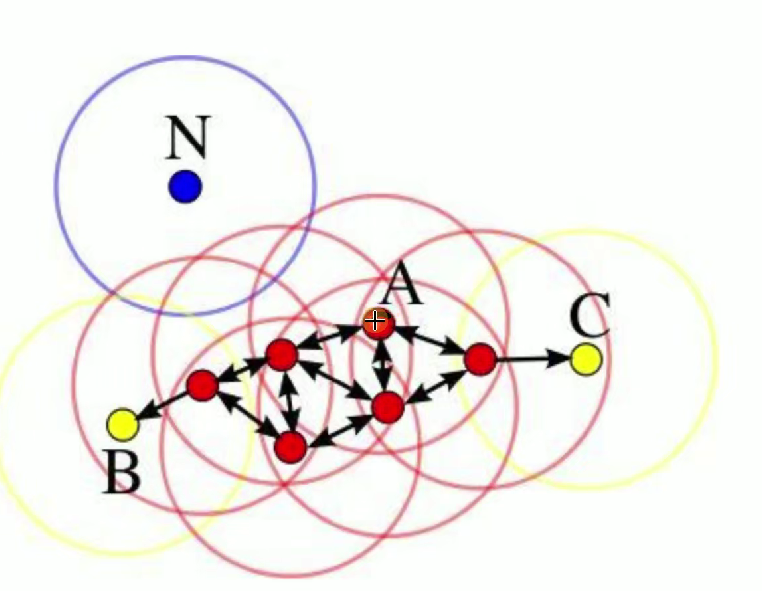
- 核心对象:A 点在 DBSCAN 算法中,如果一个点的 E 邻域内包含的点的数量大于等于某个给定的阈值(MinPts) ,则这个点被称为核心对象。图中的 A 点就是核心对象,以 A 为圆心的红色圆圈代表其 E 邻域,可以看到在这个邻域内有足够多的其他点(超过了算法设定的阈值)。
- E 邻域:给定对象半径为 E 内的区域,对于给定的一个对象(点),以该对象为中心,半径为 E 的区域就是这个对象的 E 邻域。图中围绕每个点的圆圈就代表了相应点的 E 邻域,例如红色圆圈是核心对象 A 的 E 邻域,蓝色圆圈是点 N 的 E 邻域 ,黄色圆圈是点 B 和点 C 的 E 邻域。
- 直接密度可达:如果点 p 在点 q 的 E 邻域内,并且 q 是核心对象,那么我们称点 p 从点 q 直接密度可达。在图中,一些红色的点位于核心对象 A 的 E 邻域内,这些点就从 A 点直接密度可达。
- 密度可达:如果存在一个点链 p1, p2, ..., pn,其中 p1 = q,pn = p,对于 pi ∈ {p1, p2, ..., pn-1},pi+1 从 pi 直接密度可达,那么我们称点 p 从点 q 密度可达。例如图中,点 B 和点 C 虽然不在核心对象 A 的 E 邻域内,但可以通过一系列直接密度可达的点(图中的红色点链 ),从 A 点密度可达。
- 边界点:B 点、C 点边界点是指在其 E 邻域内有点属于某个簇,但自身不是核心对象的点。图中的 B 点和 C 点就是边界点,它们的 E 邻域(黄色圆圈 )内有来自核心对象 A 所在簇的点,但它们自身的 E 邻域内点数未达到成为核心对象的阈值。
- 离群点:N 点 离群点是指既不是核心对象也不是边界点的点,也就是不在任何簇中的点。
实现过程:
- 输入数据集
- 指定半径;
- 指定密度阈值;
二、dbscan的API
class sklearn.cluster.DBSCAN(eps=0.5, min_samples=5,
metric='euclidean', metric_params=None, algorithm='auto', leaf_size=30, p=None, n_jobs=None)参数解释
eps:即图中提到的 "半径" ,DBSCAN 算法中定义的邻域半径。它决定了一个点的邻域范围,在这个范围内去判断点的密度情况,默认值0.5。min_samples:可以理解为密度阈值相关,即构成核心点所需的邻域(eps范围内)最少样本数量,用于判断核心对象,默认5。metric:用于计算距离的度量方式,这里是euclidean(欧几里得距离),也可选择其他距离度量,比如曼哈顿距离等,默认用欧氏距离衡量点与点之间的远近。metric_params:度量函数的额外参数,一般用默认值None即可,当metric有特殊参数需求时才设置。algorithm:近邻搜索算法,auto表示让算法自动选择合适的近邻搜索方法(如ball_tree、kd_tree或brute等 ),根据数据情况自适应选择。leaf_size:构建BallTree或KDTree时的叶子节点大小,会影响树构建和查询的效率,默认30。p:当metric为闵可夫斯基距离(minkowski)时,p是闵可夫斯基距离的阶数,p=2就是欧氏距离,p=1是曼哈顿距离;若metric不是闵可夫斯基距离,该参数无意义,默认None。n_jobs:用于并行计算的 CPU 核心数,None表示使用 1 个核心,-1表示使用所有可用核心,可加速近邻搜索等过程。
三、案例分析
1. 导入所需库
python
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import adjusted_rand_score, normalized_mutual_info_score
import numpy as np2. 数据读取与预处理
python
# 读取训练集和测试集数据
data_train = pd.read_csv("datingTestSet2.txt", sep='\t', encoding='utf-8', engine='python', header=None)
data_test = pd.read_csv("datingTestSet1.txt", sep='\t', encoding='utf-8', engine='python', header=None)
# 初始化标准化器
scaler = StandardScaler()
# 对特征列进行标准化(所有列除了最后一列,假设最后一列是标签)
data_train.iloc[:, :-1] = scaler.fit_transform(data_train.iloc[:, :-1])
data_test.iloc[:, :-1] = scaler.transform(data_test.iloc[:, :-1])- 标准化处理是 DBSCAN 等基于距离的算法必需的步骤,因为它对特征的尺度敏感
- 测试集使用训练集的标准化参数,避免数据泄露
3. 数据准备
python
x_train = data_train.iloc[:, :-1] # 训练集特征
x_test = data_test.iloc[:, :-1] # 测试集特征
y_train_true = data_train.iloc[:, -1] # 训练集真实标签
y_test_true = data_test.iloc[:, -1] # 测试集真实标签4. DBSCAN 参数调优
python
# 定义要测试的eps参数范围
scores = []
eps_param_range = [0.09, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6]
for eps in eps_param_range:
# 初始化并训练DBSCAN模型
dbscan = DBSCAN(eps=eps, min_samples=2)
train_labels = dbscan.fit_predict(x_train)
# 计算评估指标,忽略噪声点(-1)
mask = train_labels != -1
if np.sum(mask) > 0: # 确保有非噪声点
ari = adjusted_rand_score(y_train_true[mask], train_labels[mask])
nmi = normalized_mutual_info_score(y_train_true[mask], train_labels[mask])
score_mean = (ari + nmi) / 2 # 平均得分
scores.append(score_mean)
print(f"eps等于{eps}的平均得分(ARI+NMI)/2为{score_mean:.4f}")
else:
print(f"eps等于{eps}时,所有样本都被标记为噪声点")
scores.append(-1)eps是 DBSCAN 中最重要的参数,定义了邻域半径min_samples是构成核心点所需的最小样本数- 使用 ARI(调整兰德指数)和 NMI(标准化互信息)作为评估指标,这两个指标都需要真实标签
- 忽略噪声点(标签为 - 1)对评估的影响
5. 确定最佳参数并应用
python
# 找到最佳的eps参数
best_eps = eps_param_range[np.argmax(scores)]
print(f"最好的eps是:{best_eps}")
# 使用最佳参数重新训练模型
best_dbscan = DBSCAN(eps=best_eps, min_samples=2)
train_labels = best_dbscan.fit_predict(x_train)
print("训练集聚类标签:\n", train_labels)
# 对测试集进行预测
test_labels = best_dbscan.fit_predict(x_test)
print("测试集聚类标签:\n", test_labels)- 选择平均得分最高的
eps作为最佳参数 - 使用最佳参数重新训练模型并输出聚类结果
- 对测试集进行聚类并输出结果
总结
这个案例我做的比较简单,重点是学习其代码的逻辑、这个代码框架可以作为 DBSCAN 算法应用的模板,只需根据实际数据集调整文件路径和参数范围即可。