官方文档:MongoDB中文手册|官方文档中文版 | MongoDB-CN-Manual
什么是MongoDB?
MongnDB是一个分布式文件存储数据库(或叫文档数据库),是一个介于 关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库,最接近关系型数据库的。
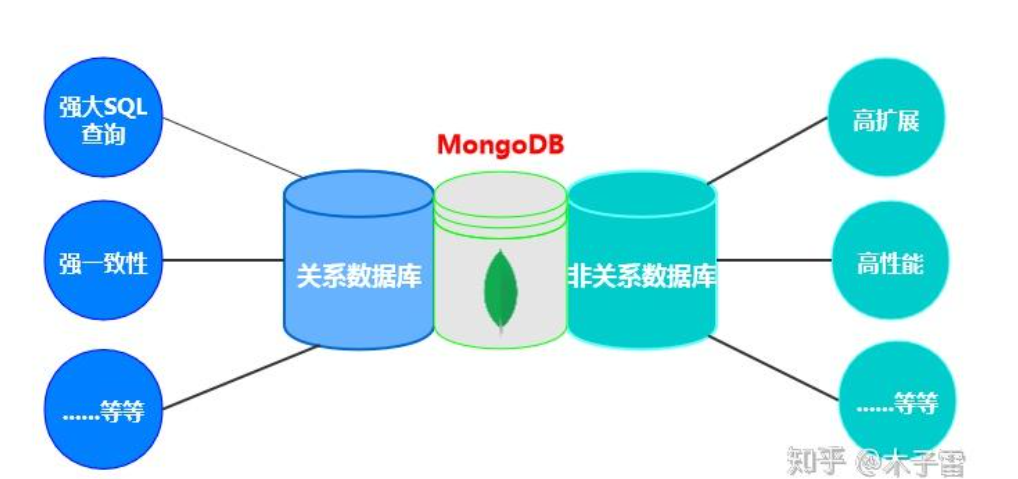
MongoDB中的记录是一个文档,它是由字段和值(key:value)对组成的数据结构。MongoDB文档类似于JSON的BSON类型,BSON就是JSON的二进制表示,文档的字段的值可以包括其他文档,数组和文档数组。
MongoDB 特点
MongoDB 的一些关键特点:
- 文档导向:MongoDB 存储 BSON(二进制 JSON)文档,这些文档可以包含复杂的数据结构,如数组和嵌套对象。
- 高性能:MongoDB 提供了高性能的数据持久化和查询能力,特别是对于写入密集型的应用。
- 水平扩展:通过分片(sharding)技术,MongoDB 可以在多个服务器之间分布数据,实现水平扩展。
- 高可用性:MongoDB 支持副本集(replica sets),提供数据的自动故障转移和数据冗余。
- 灵活的聚合框架:MongoDB 提供了一个强大的聚合框架,允许执行复杂的数据处理和聚合操作。
- 丰富的查询语言:MongoDB 的查询语言(MQL)支持丰富的查询操作,包括文本搜索、地理位置查询等。
- 存储过程:MongoDB 支持在数据库内部执行 JavaScript 代码,允许定义和执行复杂的数据处理逻辑。
- GridFS:对于存储大于 BSON 文档大小限制(16MB)的文件,MongoDB 提供了 GridFS,一种用于存储和检索大文件的规范。
- 安全性:MongoDB 提供了多层次的安全特性,包括认证、授权和加密。
- 驱动程序和工具:MongoDB 拥有广泛的驱动程序支持,适用于不同的编程语言,以及各种管理工具和可视化界面。
- 社区和生态系统:MongoDB 拥有一个活跃的开发者社区,提供了大量的教程、文档和第三方工具
MongoDB三大核心概念
1. 数据库(Database)
数据库是集合的物理容器,每个数据库在文件系统上有自己的文件集,一个MongoDB服务器通常有多个数据库,类似于关系型数据库中的数据库。
2. 集合(Collection)
集合是一组MongoDB文档的集合,相当于RDBMS的表。集合存在于一个单独的数据库中。集合不强制执行模式,集合中的文档可以具有不同的字段,通常,集合中的所有文档具有相似或相关的目的。类似于关系型数据库中的表。
3. 文档(Document)
文档是一组键值对。文档具有动态模式,动态模式意味着同一个集合中的文档不需要具有相同的字段或结构,并且集合的文档中的共同字段可能包含不同类型的数据。类似于关系型数据库中的行(row),以 BSON 格式存储。
一条文档示例:(博客)
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2011,1,20,2,15),
like: 0
},
{
user:'user2',
message: 'My second comments',
dateCreated: new Date(2011,1,25,7,45),
like: 5
}
]
}其中"_id"是自动生成的,可以自己另外设置一个"_id"的值覆盖自动生成"_id"的值。但是如果文档已经生成了就无法直接去修改"_id"的值,但是可以通过"删除-添加"的方式实现
RDBMS术语与MongoDB之间的关系
|-------------------|----------------------------------------------------------------------------------------------------|
| 关系型数据库管理系统(RDBMS) | MongoDB |
| 数据库(Database) | 数据库(Database) |
| 表(Table) | 集合(Collection) |
| 元组/行(Tuple/Row) | 文档(Document) |
| 列(Column) | 字段(Field) |
| 表连接(Table Join) | 嵌入式文档(Embedded Documents) |
| 主键(Primary Key) | 主键(默认键_id由MongoDB自身提供) |
MongoDB的安装
下载地址:Download MongoDB Community Server | MongoDB
选择合适的版本下载:
安装步骤链接:Windows(超详细保姆级教学)安装mongodb数据库_windows安装mongodb-CSDN博客
根据上面的连接成功连接上mongodb数据库
注意:安装过程中是否设置了密码,我没有设置所以验证就是none;
MongoDB的常用操作命令
数据库操作
a. 创建数据库
use 数据库名
使用 use 命令来指定一个数据库时,如果该数据库不存在,MongoDB将自动创建它。
b. 查看数据库列表
show dbs
c. 删除数据库
use 数据库名 //先切换到要删除的数据库
db.dropDatabase() //然后删除当前数据库
集合操作
操作某个数据库的集合要记住使用【use 数据库名】,切换数据库
a. 创建集合
db.createCollection(name, options)
参数说明:
- name: 要创建的集合名称。
- options: 可选参数, 指定有关内存大小及索引的选项。
options 可以是如下参数:
|--------------------|-----|------------------------------------------------------------------------------------------------------|---------------------------------|
| 参数名 | 类型 | 描述 | 示例值 |
| capped | 布尔值 | 是否创建一个固定大小的集合。 | true |
| size | 数值 | 集合的最大大小(以字节为单位)。仅在 capped 为 true 时有效。 | 10485760 (10MB) |
| max | 数值 | 集合中允许的最大文档数。仅在 capped 为 true 时有效。 | 5000 |
| validator | 对象 | 用于文档验证的表达式。 | { $jsonSchema: { ... }} |
| validationLevel | 字符串 | 指定文档验证的严格程度。 "off" :不进行验证。 "strict" :插入和更新操作都必须通过验证(默认)。 "moderate" :仅现有文档更新时必须通过验证,插入新文档时不需要。 | "strict" |
| validationAction | 字符串 | 指定文档验证失败时的操作。 "error" :阻止插入或更新(默认)。 "warn" :允许插入或更新,但会发出警告。 | "error" |
| storageEngine | 对象 | 为集合指定存储引擎配置。 | { wiredTiger: { ... }} |
| collation | 对象 | 指定集合的默认排序规则。 | { locale: "en", strength: 2 } |
b. 更新集合
db.adminCommand({
renameCollection: "原数据库.原集合",
to: "目标数据库.目标集合",
dropTarget: <boolean>
})
参数说明:
- renameCollection:要重命名的集合的完全限定名称(包括数据库名)。
- to:目标集合的完全限定名称(包括数据库名)。
- dropTarget (可选):布尔值。如果目标集合已经存在,是否删除目标集合。默认值为
false。
c. 删除集合
db.集合名.drop()
drop() 方法可以永久地从数据库中删除指定的集合及其所有文档,这是一个不可逆的操作,因此需要谨慎使用
文档操作
a. 添加文档
|----------------|-----------|------|
| 方法 | 用途 | 是否弃用 |
| insertOne() | 插入单个文档 | 否 |
| insertMany() | 插入多个文档 | 否 |
| insert() | 插入单个或多个文档 | 是 |
| save() | 插入或更新文档 | 是 |
db.集合.insertOne(document, options)
- document:要插入的单个文档。
- options(可选):一个可选参数对象,可以包含 writeConcern 和 bypassDocumentValidation 等。
实例:
db.myCollection.insertOne(
{
name: "Alice",
age: 25,
city: "New York"
}
);
db.集合.insertMany(documents, options)
- documents:要插入的文档数组。
- options(可选):一个可选参数对象,可以包含 ordered、writeConcern 和 bypassDocumentValidation 等。
db.myCollection.insertMany(
{ name: "Bob", age: 30, city: "Los Angeles" }, { name: "Charlie", age: 35, city: "Chicago" }
);
从 MongoDB 4.2 开始,db.collection.save() 和 insert()已被标记为弃用
b. 更新文档
ⅰ. 更新单个文档
db.集合.updateOne(filter, update, options)
- filter:用于查找文档的查询条件。
- update:指定更新操作的文档或更新操作符。
- options :可选参数对象,如
upsert、arrayFilters等。
示例:
db.myCollection.updateOne(
{ name: "Alice" }, // 过滤条件
{ $set: { age: 26 } }, // 更新操作
{ upsert: false } // 可选参数
);
ⅱ. 批量更新
db.集合.updateMany(filter, update, options)
ⅲ. 单个文档替换
db.集合.replaceOne(filter, replacement, options)
- filter:用于查找文档的查询条件。
- replacement:新的文档,将替换旧的文档。
- options :可选参数对象,如
upsert等。
示例:
db.myCollection.replaceOne(
{ name: "Bob" }, // 过滤条件
{ name: "Bob", age: 31 } // 新文档
);
ⅳ. 查找并更新
db.集合.findOneAndUpdate(filter, update, options)
- filter:用于查找文档的查询条件。
- update:指定更新操作的文档或更新操作符。
- options :可选参数对象,如
projection、sort、upsert、returnDocument等
options 参数通常可以包含以下选项:
- upsert:如果没有匹配的文档,是否插入一个新文档。
- arrayFilters:当更新嵌套数组时,指定应更新的数组元素的条件。
- collation:指定比较字符串时使用的排序规则。
- returnDocument:在 findOneAndUpdate 中使用,指定返回更新前 ("before") 或更新后 ("after") 的文档。
c. 删除文档
ⅰ. 删除单个文档
db.集合.deleteOne(filter, options)
- filter:用于查找要删除的文档的查询条件。
- options(可选):一个可选参数对象。
ⅱ. 批量删除
db.集合.deleteMany(filter, options)
ⅲ. 查找并删除单个文档
db.集合.findOneAndDelete(filter, options)
- filter:用于查找要删除的文档的查询条件。
- options :可选参数对象,如
projection、sort等
示例:
db.myCollection.findOneAndDelete(
{ name: "Charlie" },
{ projection: { name: 1, age: 1 } }
);
删除操作options 参数通常可以包含以下选项:
- writeConcern:指定写操作的确认级别。
- collation:指定比较字符串时使用的排序规则。
- projection (仅适用于
findOneAndDelete):指定返回的字段。 - sort (仅适用于
findOneAndDelete):指定排序顺序以确定要删除的文档。
d. 查询文档
ⅰ. 简单查询
db.集合.find(query, projection)
- query :用于查找文档的查询条件。默认为
{},即匹配所有文档。 - projection(可选):指定返回结果中包含或排除的字段。
示例
db.myCollection.find(
{ age: { $gt: 25 } },
{ name: 1, age: 1, _id: 0 }
);
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
db.集合.find().pretty()
pretty() 方法以格式化的方式来显示所有文档。
示例
db.col.find().pretty()
结果:
{
"_id" : ObjectId("56063f17ade2f21f36b03133"),
"title" : "MongoDB 教程",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "菜鸟教程",
"url" : "http://www.runoob.com",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
db.集合.findOne(query, projection)
ⅱ. 高级查询方法
1. 使用比较操作符
MongoDB 支持多种比较操作符,如 gt、lt、gte、lte、eq、ne 等。
|--------|----------|-----------------------------------|
| 操作符 | 描述 | 示例 |
| $eq | 等于 | { age: { $eq: 25 } } |
| $ne | 不等于 | { age: { $ne: 25 } } |
| $gt | 大于 | { age: { $gt: 25 } } |
| $gte | 大于等于 | { age: { $gte: 25 } } |
| $lt | 小于 | { age: { $lt: 25 } } |
| $lte | 小于等于 | { age: { $lte: 25 } } |
| $in | 在指定的数组中 | { age: { $in: [25, 30, 35] } } |
| $nin | 不在指定的数组中 | { age: { $nin: [25, 30, 35] } } |
示例:
查找年龄大于 25 的文档:
db.myCollection.find({ age: { $gt: 25 } });
2. 使用逻辑操作符
MongoDB 支持多种逻辑操作符,如 and、or、not、nor 等。
|--------|-------------|------------------------------------------------------------|
| 操作符 | 描述 | 示例 |
| $and | 逻辑与,符合所有条件 | { $and: [ { age: { $gt: 25 } }, { city: "New York" } ] } |
| $or | 逻辑或,符合任意条件 | { $or: [ { age: { $lt: 25 } }, { city: "New York" } ] } |
| $not | 取反,不符合条件 | { age: { $not: { $gt: 25 } } } |
| $nor | 逻辑或非,均不符合条件 | { $nor: [ { age: { $gt: 25 } }, { city: "New York" } ] } |
示例:
找年龄大于 25 且城市为 "New York" 的文档:
db.myCollection.find({
$and: [
{ age: { $gt: 25 } },
{ city: "New York" }
]
});
'where likes>50 AND (by = '菜鸟教程' OR title = 'MongoDB 教程')'
db.col.find({"likes": {gt:50}, or: {"by": "菜鸟教程"},{"title": "MongoDB 教程"}}).pretty()
结果:
{
"_id" : ObjectId("56063f17ade2f21f36b03133"),
"title" : "MongoDB 教程",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "菜鸟教程",
"url" : "http://www.runoob.com",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
3. 使用元素操作符
|-----------|-------------|------------------------------|
| 操作符 | 描述 | 示例 |
| $exists | 字段是否存在 | { age: { $exists: true } } |
| $type | 字段的 BSON 类型 | { age: { $type: "int" } } |
示例:
查找包含 age 字段的文档:
db.collection.find({ age: { $exists: true } })
查找 age 字段为整数类型的文档:
db.collection.find({ age: { $type: "int" } })
4. 使用数组操作符
|--------------|--------------|----------------------------------------------------------------|
| 操作符 | 描述 | 示例 |
| $all | 数组包含所有指定的元素 | { tags: { $all: ["red", "blue"] } } |
| $elemMatch | 数组中的元素匹配指定条件 | { results: { $elemMatch: { score: { $gt: 80, $lt: 85 } } } } |
| $size | 数组的长度等于指定值 | { tags: { $size: 3 } } |
5. 使用其他操作符
|----------------|-------------------------|--------------------------------------------------------------------------------------|
| 操作符 | 描述 | 示例 |
| $regex | 匹配正则表达式 | { name: { $regex: /^A/ } } |
| $text | 进行文本搜索 | { $text: { $search: "coffee" } } |
| $where | 使用 JavaScript 表达式进行条件过滤 | { $where: "this.age > 25" } |
| near** | 查找接近指定点的文档 | `db.collection.find({ location: { near: [10, 20], maxDistance: 1000 } })` |
| **geoWithin | 查找在指定地理区域内的文档 | db.collection.find({ location: { $geoWithin: { $centerSphere: [[10, 20], 1] } } }) |
6. 使用正则表达式
可以使用正则表达式进行模式匹配查询。
示例:
查找名字以 "A" 开头的文档:
db.myCollection.find({ name: /^A/ });
7. 投影(指定返回结果字段)
投影用于控制查询结果中返回的字段。可以使用包含字段和排除字段两种方式。
示例:
只返回名字和年龄字段:
db.myCollection.find(
{ age: { $gt: 25 } },
{ name: 1, age: 1, _id: 0 }
);
8. 排序
示例:
按年龄降序排序:
db.myCollection.find().sort({ age: -1 });
9. 限制与跳过(分页)
可以对查询结果进行限制和跳过指定数量的文档。
示例1:
返回前 10 个文档:
db.myCollection.find().limit(10);
示例2:
跳过前 5 个文档,返回接下来的 10 个文档:
db.myCollection.find().skip(5).limit(10);
e. 聚合统计
MongoDB 中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。
ⅰ. aggregate() 方法
db.集合.aggregate(AGGREGATE_OPERATION)
|-----------|-------------------------------------------|-----------------------------------------------------------------------------------------|
| 表达式 | 描述 | 实例 |
| sum | 计算总和。 | db.mycol.aggregate(\[{group : {_id : "by_user", num_tutorial : {sum : "likes"}}}\]) |
| avg | 计算平均值 | db.mycol.aggregate({$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}) |
| min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate(\[{group : {_id : "by_user", num_tutorial : {min : "likes"}}}\]) |
| max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate({$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}) |
| push | 将值加入一个数组中,不会判断是否有重复的值。 | db.mycol.aggregate(\[{group : {_id : "by_user", url : {push: "url"}}}\]) |
| addToSet | 将值加入一个数组中,会判断是否有重复的值,若相同的值在数组中已经存在了,则不加入。 | db.mycol.aggregate({$group : {_id : "$by_user", url : {$addToSet : "$url"}}}) |
| first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate(\[{group : {_id : "by_user", first_url : {first : "url"}}}\]) |
| last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate({$group : {_id : "$by_user", last_url : {$last : "$url"}}}) |
ⅱ. 管道操作
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- match:用于过滤数据,只输出符合条件的文档。match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
示例:
db.articles.aggregate( [
{ match : { score : { gt : 70, $lte : 90 } } }, //第一个管道
{ group: { _id: null, count: { sum: 1 } } } //第二个管道
] );
match用于获取分数大于70小于或等于90记录,然后将符合条件的记录送到下一阶段group管道操作符进行处理。
按顺序将前一个管道的处理后的数据传给后一个管道的处理,以此类推
关注我,下一篇讲Spring Boot 整合MongoDB