应用背景
大型语言模型(LLM)在理解和生成上下文连贯的对话方面取得了巨大成功。然而,它们固有的"记忆缺陷"------即有限的上下文窗口------严重制约了其在跨会话、跨应用的长时间交互中保持一致性的能力。一旦对话超出上下文长度,LLM 就会像一个"失忆"的伙伴,忘记用户的偏好、重复提问,甚至与之前确立的事实相矛盾。
想象一下这个场景:你告诉一个AI助手你是素食主义者且不吃乳制品。几天后,当你向它寻求晚餐建议时,它却推荐了烤鸡。这种体验无疑会削弱用户对AI的信任和依赖。

LLM的长期记忆遗忘问题
缺乏记忆的AI(左侧)会忘记用户的关键信息,而具备有效记忆的AI(右侧)则能跨会话保持上下文,提供精准、个性化的服务。
本文给出基于PolarDB-PG的一站式长记忆方案。PolarDB-PG依托长记忆框架Mem0,为其提供了向量数据库引擎、图数据库引擎以及大语言模型、Embedding模型的一站式能力。其中,Mem0(发音为 "mem-zero") 是专为现代 AI Agent设计的Memory,它充当统一的持久记忆层,使智能体能够跨会话、跨应用持续保留用户偏好、事实背景与历史交互信息,从而实现真正的个性化和持续学习体验。
场景分类
Mem0支持两类长记忆方案,基于纯向量数据库方案,和向量数据库+图数据库的组合方案,分别适用于以下场景:
1、纯向量数据库方案
- 适用场景:
- 需要快速语义检索的对话场景,例如在线客服、实时聊天机器人等
- 成本敏感型应用,假设需要分别采购向量库和图数据库两种产品或服务,采用纯向量方案能减少至少一半的产品费用支出。
- 技术特点:
- 通过LLM提取对话关键事实并向量化存储
- 采用动态阈值控制检索范围,平衡召回率与精准度
2、向量数据库+图数据库方案
- 适用场景:
- 复杂关系推理场景:如医疗诊断(跟踪患者病史和药物相互作用)、旅行规划(整合航班、酒店、景点等关系)等。
- 长期知识管理:通过三元组(实体1-关系-实体2)结构化存储知识,适合构建企业级知识库或跨会话连贯性要求高的智能助手,如需跟踪用户偏好演变关系的智能座仓AI助手、AI伴侣等,做到长期个性化服务。
- 动态演进型系统:知识图谱支持增量更新和子图检索,适合业务规则频繁变化的场景(如金融风控中的动态规则库)。
- 技术特点:
- 向量库处理语义搜索,图数据库存储实体间关联关系
- 支持时间感知的动态知识图谱更新
- 基于Mem0g方案,通过两阶段流水线实现结构化记忆
两种方案的互补性体现在:向量+图虽能处理复杂关系,但检索效率上带来更大挑战;而纯向量方案在简单场景中更高效,但缺乏对深层关系的建模能力。实际部署时,可结合业务复杂度与实时性需求进行混合架构设计。
一站式方案
基于PolarDB-PG的一站式长记忆方案包含以下五个主要部分:
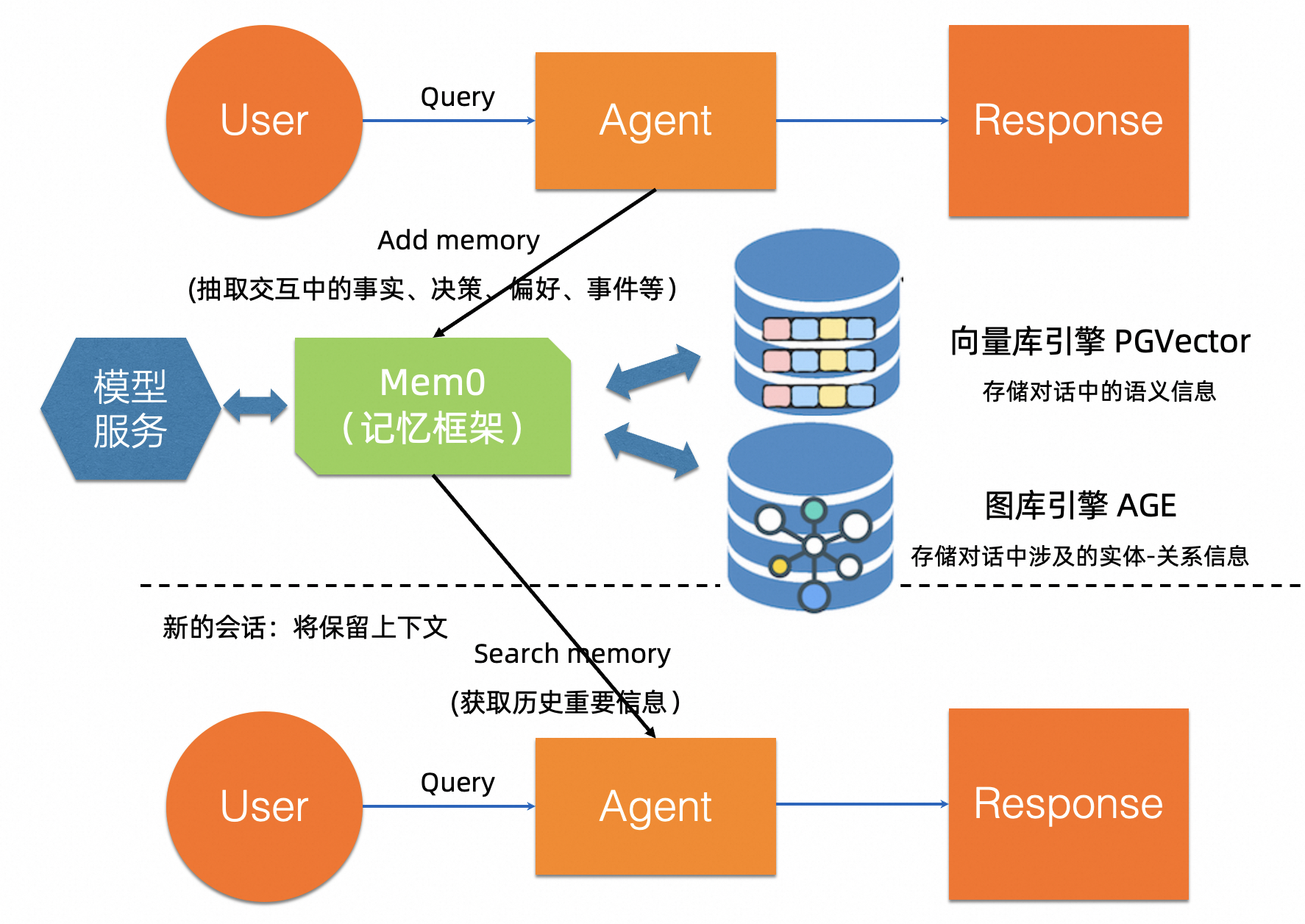
PolarDB-PG+mem0的记忆存储和记忆搜索整体框架
1、记忆体引擎
建议采用mem0框架,该框架核心能力包括:
- 长短期记忆融合(LTM/STM)+自适应上下文压缩能力
- 四类记忆能力(分层记忆):
-工作记忆:短期会话意识
-事实记忆:长期结构化知识(例如偏好、设置)
-情景记忆:记录过去的具体对话
-语义记忆:随着时间的推移提取知识
- 四类记忆操作:memory add、search、update、delete
- 支持多模态记忆:关系 + 文本 + 图片
- 支持Graph Memory:已集成PolarDB-PG图引擎AGE,实时建立会话信息中的实体关联(如人与人、人与地点),查询时从图中获取关联性洞察
- 支持Vector Memory:已集成PolarDB-PG向量引擎PGVector,支持基于向量召回历史会话
2、基础数据引擎
- PolarDB-PG向量数据库引擎 + 图数据库引擎一站式组合。其中,向量数据库引擎采用经优化的PGVector插件;PGVector在PG社区已经被广泛应用,具备十分良好的AI生态支持。图数据库引擎兼容开源AGE(A Graph Extension,为Apache软件基金会的顶级项目),且经过PolarDB-PG与云原生能力的增强融合以及在大量图客户上的多年应用改进和性能优化,不仅表现成熟稳定,且具备在百亿级规模图场景下仍然保持万级以上QPS和百毫秒以下的查询延迟的极佳表现。
- 支持集中式版本或分布式版本,加持存储侧PolarFS云原生分布式文件系统能力,无需担心扩展性风险。
3、模型服务
- 大模型在mem0中扮演了核心的角色,主要包含以下作用:
-负责从用户与智能体的对话中自动提取关键信息,自动识别并提取出具有长期价值的关键信息
-将这些信息转化为高维向量,实现高效的语义检索
-如果需要图数据库进行存储,需要借助于大模型将用户语义提取为三元组信息
- 模型调用的效率占据了客户体验的关键一环,本方案支持在PolarDB-PG中增加AI节点(带GPU),基于优化的本地LLM模型服务和Embedding模型服务进行记忆内容提取、更新、向量嵌入等操作;通过高度优化的链路,大幅提升记忆相关推理效率。
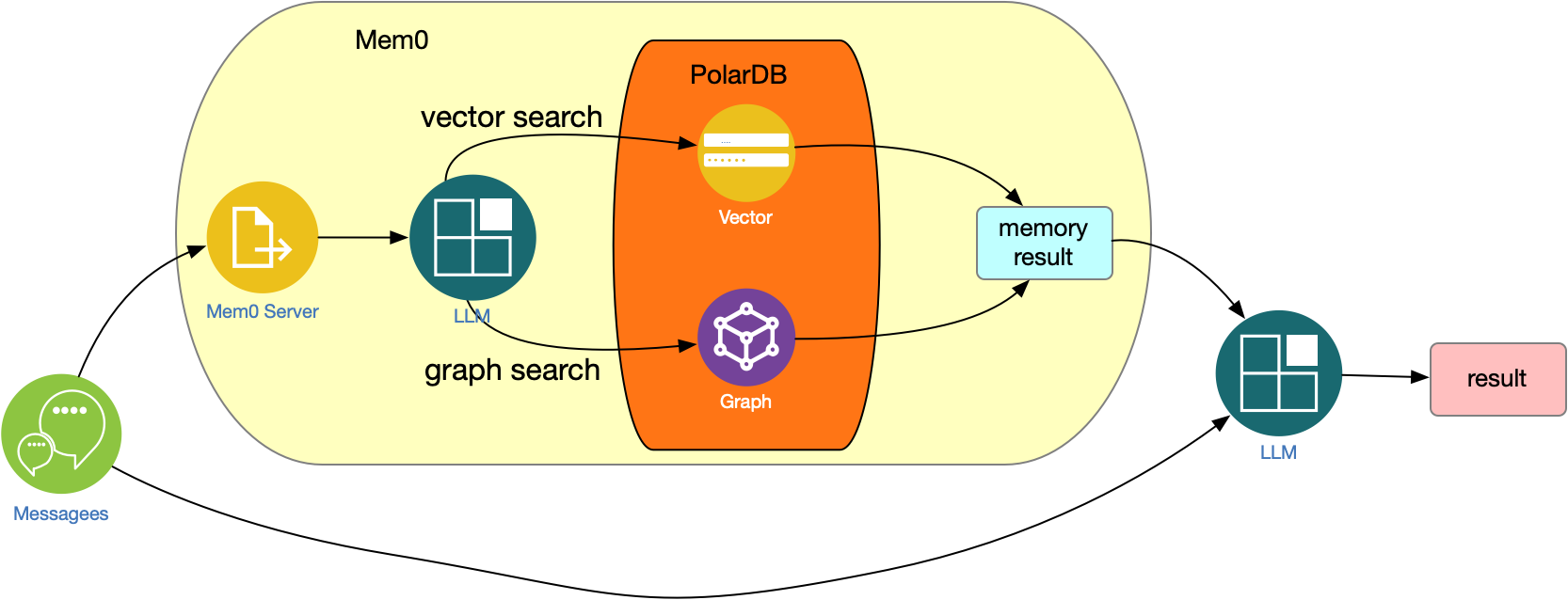
综合mem0、向量引擎、图引擎和模型服务的交互过程
4、AI应用构建平台
PolarDB-PG AI应用(商店)支持一键开启dify框架,而mem0支持作为插件加入到dify框架,形成更加便利的整体解决方案。mem0同时支持:Langchain、LangGraph、AgentOps、LlamaIndex、AutoGen等框架/平台。
5、KV缓存增强
在实时性要求极高的长短记忆混合场景下,PolarDB-PG支持开启分布式KVCache的上下文缓存加速层能力;通过加入KVCache层,减少历史token转向量的重复计算,加速上下文关联,并稳定推理延迟。
方案核心优势
总结基于PolarDB-PG的长记忆方案的核心优势如下:
- **一站式:**PolarDB-PG作为阿里云战略级核心产品,同时具备向量数据库引擎和图数据库引擎,多引擎一站式方案取代需要多个数据库产品的组合方案(客户需要分别采购向量数据库和图数据库),不仅采购成本降低至少50%,且大幅减少跨系统维护成本和项目风险;同时,模型服务、KVCache以及Dify等内置AI应用的一键拉起和组合使用,能够大幅降低自建复杂度,提升上线进度;当然,也可以根据项目实际情况选择性使用必要的组件。
- **可扩展:**PolarDB-PG的分布式版本支持百亿级向量存储,无论向量索引的创建和搜索,均无OOM风险,检索性能(QPS、准确率等)优于业内竞品;图数据库引擎具备百亿级(点+边)大图管理能力,支持万级以上高QPS图搜索的可扩展性,且支持TTL记录生命周期自动回收、支持控制台开启图管理节点进行可视化。
- **高性能:**支持向量、图实时写入(索引自动更新)、写入即可查,查询RT最优低于 50 毫秒;结合AI节点和本地模型部署,推理效率较远程服务可提升1-2倍,进一步结合KVCache,推理速度提升5倍以上,相比重复计算可降低约30%-50%的显存占用。借助综合优化方案,为顾及长短记忆融合下的图+向量混合架构设计带来写入吞吐、数据可见性、交互延迟上的大幅优化空间(具体需结合业务逻辑设计)。
使用流程
以PolarDB-PG图+向量引擎组合方案为例,结合阿里云QWen大模型,给出基于mem0使用流程示例。
基础环境
购买同一region的ECS与PolarDB-PG实例,ECS通过内网连接地址访问PolarDB-PG数据库。
部署mem0
ECS下载mem0源码:https://github.com/mem0ai/mem0
(注:开源mem0代码仅支持使用PolarDB纯向量长记忆功能,如果要体验图+向量长记忆组合功能,请工单联系我们或扫描文末二维码加入钉钉群)
cpp
-- 安装依赖包
pip3 install mem0ai
pip3 install rank_bm25以使用PolarDB-PG 16为例,系统提供polar_age + pgvector插件:
cpp
-- 创建database
CREATE DATABASE mem0;
ALTER DATABASE mem0 SET session_preload_libraries TO 'polar_age';
-- 创建插件
create extension polar_age;
create extension vector;mem0配置信息
使用百炼提供的通义千问大语言模型以及text-embedding-v4文本向量模型,具体配置信息如下:
cpp
from mem0 import Memory
# This example must connect to a age-graph instance with 1536 vector dimensions specified.
config = {
"llm" : {
"provider": "bailian",
"config": {"model": "qwen-plus"},
},
"embedder": {
"provider": "bailian",
"config": {"model": "text-embedding-v4", "embedding_dims": 1536},
},
"vector_store": {
"provider": "pgvector",
"config": {
"host": "pc-********.pg.polardb.rds.aliyuncs.com",
"port": int(5432),
"dbname": "mem0",
"user": "ganos",
"password": "ganos",
"collection_name": "memories",
},
},
"graph_store": {
"provider": "polardb",
"config": {
"url": "pc-********.pg.polardb.rds.aliyuncs.com",
"port": 5432,
"database": "mem0",
"username": "ganos",
"password": "ganos",
"graphname": "mem0",
},
},
}
m = Memory.from_config(config_dict=config)创建Graph
cpp
\c mem0
select ag_catalog.create_graph('mem0');
alter table mem0._ag_label_vertex add column embedding vector(1536);注意:PolarDB-PG在Graph的点表中增加了向量字段,底层实现了图+向量混合检索。
问答记忆流程解析
以下给出用户在调用mem0接口后,返回的结果示例。
- add("I like pizza", user_id="alice")
cpp
{
'results': [{
'id': '43558f37-b22c-4157-94db-c935728c74f6',
'memory': 'I like pizza',
'event': 'ADD'
}],
'relations': {
'deleted_entities': [],
'added_entities': [
[{
'source': 'i',
'relationship': 'likes',
'target': 'pizza',
'source_id': '3_14',
'destination_id': '3_15',
'relationship_id': '4_13'
}]
]
}
}2.add("I hate pizza", user_id="alice")
cpp
{
'results': [{
'id': '43558f37-b22c-4157-94db-c935728c74f6',
'memory': 'I like pizza',
'event': 'DELETE'
}],
'relations': {
'deleted_entities': [
[]
],
'added_entities': [
[{
'source': 'user_id:_alice',
'relationship': 'hates',
'target': 'pizza',
'source_id': '3_16',
'destination_id': '3_15',
'relationship_id': '5_5'
}]
]
}
}3.add("I like football", user_id="alice", metadata={"category": "hobbies"})
cpp
{
'results': [{
'id': 'a3e8ae1e-3d11-4574-849c-63c058ba32cf',
'memory': 'I like football',
'event': 'ADD'
}],
'relations': {
'deleted_entities': [],
'added_entities': [
[{
'source': 'i',
'relationship': 'likes',
'target': 'football',
'source_id': '3_14',
'destination_id': '3_17',
'relationship_id': '4_14'
}]
]
}
}4.add("I like pizza", user_id="alice", agent_id="food-assistant")
cpp
{
'results': [{
'id': 'c2246008-8935-43ab-a6ed-f08dab766686',
'memory': 'I like pizza',
'event': 'ADD'
}],
'relations': {
'deleted_entities': [],
'added_entities': [
[{
'source': 'alice',
'relationship': 'likes',
'target': 'pizza',
'source_id': '3_18',
'destination_id': '3_19',
'relationship_id': '4_15'
}]
]
}
}5.get_all(user_id="alice")
cpp
{
'results': [{
'id': 'a3e8ae1e-3d11-4574-849c-63c058ba32cf',
'memory': 'I like football',
'hash': 'db38eb7ce206333d12734e4251d964c1',
'metadata': {
'category': 'hobbies'
},
'created_at': '2025-08-01T02:27:43.750094-07:00',
'updated_at': None,
'user_id': 'alice'
}, {
'id': 'c2246008-8935-43ab-a6ed-f08dab766686',
'memory': 'I like pizza',
'hash': '3acb2fb7961d7f09e42b99b96b605f3f',
'metadata': None,
'created_at': '2025-08-01T02:27:48.270658-07:00',
'updated_at': None,
'user_id': 'alice',
'agent_id': 'food-assistant'
}],
'relations': [{
'source': 'user_id:_alice',
'relationship': 'hates',
'target': 'pizza'
}, {
'source': 'i',
'relationship': 'likes',
'target': 'pizza'
}, {
'source': 'i',
'relationship': 'likes',
'target': 'football'
}, {
'source': 'alice',
'relationship': 'likes',
'target': 'pizza'
}]
}6.get_all(user_id="alice", agent_id="food-assistant")
cpp
{
'results': [{
'id': 'c2246008-8935-43ab-a6ed-f08dab766686',
'memory': 'I like pizza',
'hash': '3acb2fb7961d7f09e42b99b96b605f3f',
'metadata': None,
'created_at': '2025-08-01T02:27:48.270658-07:00',
'updated_at': None,
'user_id': 'alice',
'agent_id': 'food-assistant'
}],
'relations': []
}7.search("tell me my name.", user_id="alice")
cpp
{
'results': [{
'id': 'a3e8ae1e-3d11-4574-849c-63c058ba32cf',
'memory': 'I like football',
'hash': 'db38eb7ce206333d12734e4251d964c1',
'metadata': {
'category': 'hobbies'
},
'score': 0.696223974227903,
'created_at': '2025-08-01T02:27:43.750094-07:00',
'updated_at': None,
'user_id': 'alice'
}, {
'id': 'c2246008-8935-43ab-a6ed-f08dab766686',
'memory': 'I like pizza',
'hash': '3acb2fb7961d7f09e42b99b96b605f3f',
'metadata': None,
'score': 0.7073328582247228,
'created_at': '2025-08-01T02:27:48.270658-07:00',
'updated_at': None,
'user_id': 'alice',
'agent_id': 'food-assistant'
}],
'relations': [{
'source': '"alice"',
'relationship': 'likes',
'destination': '"pizza"'
}]
}8.search("tell me my name.", user_id="alice", agent_id="food-assistant")
cpp
{
'results': [{
'id': 'c2246008-8935-43ab-a6ed-f08dab766686',
'memory': 'I like pizza',
'hash': '3acb2fb7961d7f09e42b99b96b605f3f',
'metadata': None,
'score': 0.7073328582247228,
'created_at': '2025-08-01T02:27:48.270658-07:00',
'updated_at': None,
'user_id': 'alice',
'agent_id': 'food-assistant'
}],
'relations': [{
'source': '"alice"',
'relationship': 'likes',
'destination': '"pizza"'
}]
}9.search("what food do you like.", user_id="alice")
cpp
{
'results': [{
'id': 'c2246008-8935-43ab-a6ed-f08dab766686',
'memory': 'I like pizza',
'hash': '3acb2fb7961d7f09e42b99b96b605f3f',
'metadata': None,
'score': 0.41329889774629736,
'created_at': '2025-08-01T02:27:48.270658-07:00',
'updated_at': None,
'user_id': 'alice',
'agent_id': 'food-assistant'
}, {
'id': 'a3e8ae1e-3d11-4574-849c-63c058ba32cf',
'memory': 'I like football',
'hash': 'db38eb7ce206333d12734e4251d964c1',
'metadata': {
'category': 'hobbies'
},
'score': 0.4586412037228734,
'created_at': '2025-08-01T02:27:43.750094-07:00',
'updated_at': None,
'user_id': 'alice'
}],
'relations': []
}10.search("what sport do you like.", user_id="alice")
cpp
{
'results': [{
'id': 'a3e8ae1e-3d11-4574-849c-63c058ba32cf',
'memory': 'I like football',
'hash': 'db38eb7ce206333d12734e4251d964c1',
'metadata': {
'category': 'hobbies'
},
'score': 0.2785342501720326,
'created_at': '2025-08-01T02:27:43.750094-07:00',
'updated_at': None,
'user_id': 'alice'
}, {
'id': 'c2246008-8935-43ab-a6ed-f08dab766686',
'memory': 'I like pizza',
'hash': '3acb2fb7961d7f09e42b99b96b605f3f',
'metadata': None,
'score': 0.4836080516459955,
'created_at': '2025-08-01T02:27:48.270658-07:00',
'updated_at': None,
'user_id': 'alice',
'agent_id': 'food-assistant'
}],
'relations': [{
'source': '"i"',
'relationship': 'likes',
'destination': '"football"'
}]
}11.delete_all(user_id="alice")
cpp
{
'message': 'Memories deleted successfully!'
}12.delete_all(user_id="alice", agent_id="food-assistant")
cpp
{
'message': 'Memories deleted successfully!'
}记忆分类与标签
输入:
cpp
# 添加对话记忆
messages = [
{"role": "user", "content": "我喜欢科幻电影,尤其是星际穿越。"},
{"role": "assistant", "content": "星际穿越确实是一部经典的科幻电影!我会记住你喜欢这类电影。"},
{"role": "user", "content": "我也喜欢克里斯托弗·诺兰的其他电影。"},
{"role": "assistant", "content": "诺兰的作品确实很出色!除了《星际穿越》,他还导演了《盗梦空间》、《信条》、《记忆碎片》等经典作品。您对这些电影有什么特别的看法吗?"}
]
# 添加记忆,并附加元数据
m.add(messages, user_id="alice", metadata={"category": "movies", "tags": ["sci-fi", "preferences"], "importance": "high"})
# 检索记忆
memories = m.search(query="我喜欢什么类型的电影?", user_id="alice", filters={"category": "movies"})
print(json.dumps(memories, indent=2, ensure_ascii=False))输出:
cpp
{
"results": [
{
"id": "cf931a04-628d-438a-9cf9-fd90c6d53eab",
"memory": "我喜欢科幻电影,尤其是星际穿越",
"hash": "d3747e8081810fc535f641ee28207d90",
"metadata": {
"tags": [
"sci-fi",
"preferences"
],
"category": "movies",
"importance": "high"
},
"created_at": "2025-08-04T05:16:03.481050-07:00",
"updated_at": null,
"user_id": "alice"
},
{
"id": "8a6ad8ac-ce78-4a0a-9042-8475bd76f90e",
"memory": "我也喜欢克里斯托弗·诺兰的其他电影",
"hash": "77408cade088bfad20138a6b405f9e65",
"metadata": {
"tags": [
"sci-fi",
"preferences"
],
"category": "movies",
"importance": "high"
},
"created_at": "2025-08-04T05:16:03.493277-07:00",
"updated_at": null,
"user_id": "alice"
}
],
"relations": [
{
"source": "user_id:_alice",
"relationship": "喜欢",
"target": "科幻电影"
},
{
"source": "user_id:_alice",
"relationship": "喜欢",
"target": "星际穿越"
},
{
"source": "星际穿越",
"relationship": "属于",
"target": "科幻电影"
},
{
"source": "克里斯托弗·诺兰",
"relationship": "导演",
"target": "星际穿越"
},
{
"source": "克里斯托弗·诺兰",
"relationship": "导演",
"target": "盗梦空间"
},
{
"source": "克里斯托弗·诺兰",
"relationship": "导演",
"target": "信条"
},
{
"source": "克里斯托弗·诺兰",
"relationship": "导演",
"target": "记忆碎片"
}
]
}观察上述案例,相对于纯向量的记忆,结合图搜索,增加了实体间关联关系(relations)的输出,即我与哪些电影具备了"喜欢"的关系,以及电影是否"属于"科幻电影的分类归属等,使得语义信息叠加关联关系,为进一步实现业务上的规则过滤或大模型语料输入提供了结构化和层次化的扩展内容。
结语
本文基于PolarDB的PostgreSQL兼容版本,给出了基于mem0的长短记忆融合方案,对应用背景、核心组件、方案优势、使用过程进行了介绍。与同类产品相比,基于PolarDB-PG的长记忆方案具备向量数据库和图数据库一站式、系统规模可扩展、云原生+模型推理加速+分布式KVCache组合高性能等综合优势,在产品成熟度,以及成本、性能、安全、扩展性等各方面为 AI Agent长记忆应用构建提供了重要基础组件。
试用体验
欢迎访问PolarDB免费试用页面,选择试用"云原生数据库PolarDB PostgreSQL版",体验PolarDB的AI能力。