这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或者来我的网站进行留言!!!
一、逻辑回归梯度下降的定义
逻辑回归梯度下降 是一种优化算法,通过迭代调整模型参数(权重 ww 和偏置 bb),最小化交叉熵损失函数,使预测概率逼近真实标签。其核心是计算损失函数的梯度,并沿梯度反方向更新参数,逐步降低预测误差。
通俗理解
想象蒙眼下山:
梯度就像你用脚试探出的"最陡方向",告诉你往哪走能最快降低预测错误。
学习率是"步长",步子太大会跨过最低点,太小则下山太慢。
每次更新相当于根据当前"踩点"(误差)调整下一步方向,直到踩到谷底(最优解)。
二、逻辑回归梯度下降实现


-
代价函数
图片顶部展示了逻辑回归的代价函数(交叉熵损失):
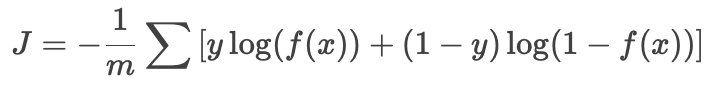
-
梯度下降更新规则
-
对参数 wj 和 b 的同步更新:
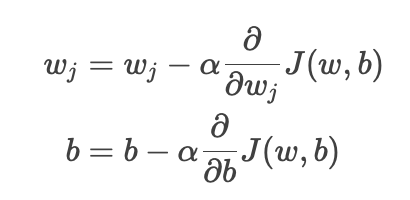
-
其中 α 是学习率,控制更新步长。
-
-
偏导数计算
-
权重 wj 的梯度:
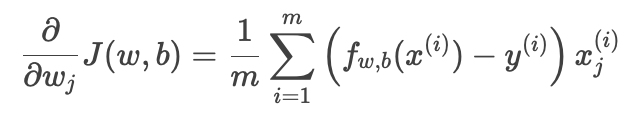
-
偏置 b 的梯度:
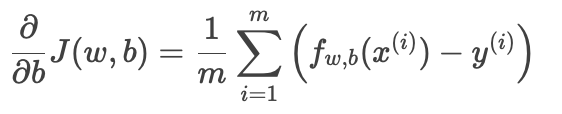
-
-
核心点
-
梯度方向指向代价函数增长最快的方向,因此通过减去梯度来最小化代价。
-
更新公式与线性回归形式相似,但 fw,b(x) 是逻辑回归的Sigmoid输出。
-
- 逻辑回归与线性回归的对比
-
线性回归:fw⃗,b(x⃗)=w⃗⋅x⃗+b(直接输出连续值)。
-
逻辑回归:fw⃗,b(x⃗)=1 /(1+e−(w⃗⋅x⃗+b))(Sigmoid 输出概率)。
-
相同点:梯度下降公式形式一致(均基于预测误差 f(x)−y),但逻辑回归的 f(x) 为概率值。
- 优化注意事项
-
监控学习曲线(learning curve)。
-
使用向量化实现(vectorized implementation)提升效率。
-
特征缩放(feature scaling)可加速收敛。
这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或者来我的网站进行留言!!!