前置工作
使用 pnpm i @faker-js/faker 安装 faker.js 来填充一些数据
编码流程
1.分页
我们用 faker.js 来给我们的 db 填充一些数据
tsx
// src/mock/faker.ts
import { fakerZH_CN as faker } from '@faker-js/faker'
// 设置种子,这样每次生成的数据和上一次是相同的
faker.seed(1)
export function createRandomUser() {
return {
id: faker.string.uuid(),
name: faker.person.fullName(),
city: faker.location.city()
};
}
export const users = faker.helpers.multiple(createRandomUser, {
count: 1000,
});
// src/mock/database.ts
import { factory, primaryKey } from '@mswjs/data';
import { users } from './faker';
export const db = factory({
user: {
id: primaryKey(String),
name: String,
age: Number,
city: String,
},
});
// 初始化我们的数据
users.map(item => {
db.user.create(item)
})
export default db我们修改一下接口mock,添加分页参数
tsx
// src/mock/handlers/user.ts
export const userHandlers = [
// 获取用户列表
http.post<never, { pageNo: number; pageSize: number }>(
getApiUrl("/user/getList"),
async ({ request }) => {
const params = await request.json();
const totalData = db.user.getAll();
const pageNo = params.pageNo || 1,
pageSize = params.pageSize || 10;
const total = totalData.length,
totalPage = Math.floor(total / pageSize);
const list = totalData.slice((pageNo - 1) * pageSize, pageNo * pageSize);
const data = {
total,
totalPage,
list,
pageNo,
pageSize,
};
return sendJson(RESPONSE_CODE_DICT.SUCCESS, data);
}
),
//...
];
export default userHandlers;修改我们的 UserList 组件,添加分页的逻辑,这里我们不用 Table 组件自带的 Pagination 功能,引入 Pagination 组件(其实是一样的,单独用把分页功能从列表的属性里摘出来)。我们使用一个副作用来处理在 paginate 变化的时候获取数据。
tsx
// src/pages/user/UserList.tsx
function UserList() {
const [paginate, setPaginate] = useState({
pageNo: 1,
pageSize: 10
})
const [pageInfo, setPageInfo] = useState({
total: 0
})
const handlePageChange = (pageNo: number, pageSize: number) => {
if (pageSize !== paginate.pageSize) {
setPaginate({
pageNo: 1,
pageSize
})
} else {
setPaginate({
...paginate,
pageNo
})
}
}
useEffect(() => {
loadData()
}, [paginate])
const fetchData = async () => {
const res = await request.post("user/getList", { ...condition, ...paginate });
return {
data: res.data.data.list || [],
total: res.data.data.total || 0
}
}
const loadData = async () => {
const {data, total} = await fetchData();
setData(data);
setPageInfo({
...pageInfo,
total
})
};
return (
<div>
{/*...*/}
<Pagination total={pageInfo.total} current={paginate.pageNo} pageSize={paginate.pageSize} onChange={(pageNo, pageSize) => {
handlePageChange(pageNo, pageSize)
}} />
</div>
);
}
export default UserList;
2.筛选项
我们之前定义了一个keyword,现在我们用它来筛选列表项的名字
tsx
// src/pages/user/UserList.tsx
const defaultCondition = {
keyword: "",
};
function UserList() {
const [condition, setCondition] = useState({ ...defaultCondition });
const updateCondition = (
key: keyof typeof condition,
value: (typeof condition)[keyof typeof condition]
) => {
setCondition({
...condition,
[key]: value,
});
};
return (
<div>
<div
style={{
display: "flex",
alignItems: "center",
gap: "12px",
marginBottom: "12px"
}}
>
<Input
style={{
width: "200px",
}}
placeholder="请输入用户姓名"
value={condition.keyword}
onChange={(e) => {
updateCondition("keyword", e.target.value);
}}
/>
<Button type="primary" onClick={loadData}>
搜索
</Button>
<Button onClick={() => navigate("../form")}>创建</Button>
</div>
</div>
);
}
export default UserList;接着我们修改一下 mock 接口的逻辑来筛选目标数据
tsx
// src/mock/handlers/user.ts
import { http } from 'msw'
import { v4 as uuidv4 } from 'uuid'
import { db } from '../database'
import { getApiUrl, sendJson } from '../utils'
import type { User } from '@/types/user'
import { RESPONSE_CODE_DICT } from '@/types/http'
export const userHandlers = [
// 获取用户列表
http.post<never, { pageNo: number; pageSize: number; keyword: string }>(
getApiUrl("/user/getList"),
async ({ request }) => {
const params = await request.json();
const keyword = params.keyword || "";
// 过滤符合条件的项
const totalData = db.user.getAll().filter((i) => {
return i.name.includes(keyword);
});
const pageNo = params.pageNo || 1,
pageSize = params.pageSize || 10;
const total = totalData.length,
totalPage = Math.floor(total / pageSize);
const list = totalData.slice((pageNo - 1) * pageSize, pageNo * pageSize);
const data = {
total,
totalPage,
list,
pageNo,
pageSize,
};
return sendJson(RESPONSE_CODE_DICT.SUCCESS, data);
}
),
]
export default userHandlers在页面上看看效果,发现能够正常筛选
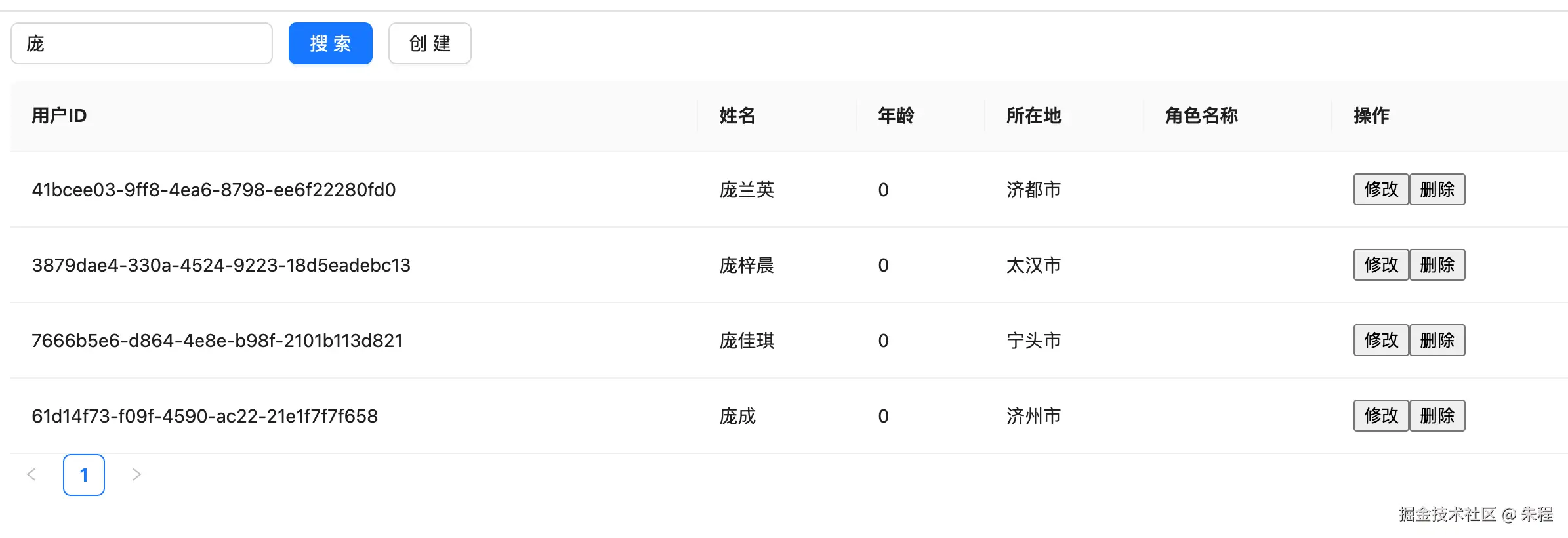
看起来好像一切都很顺利,但是真的是这样吗?来到我们的思考环节
3.阶段性思考
想象一个很常见的场景,在翻页查看数据之后,我们可能会修改筛选参数然后再次点击搜索来获取数据,这意味着我们要将分页置为第一页,按照前面的代码,我们会很自然的想到调用 setPaginate 来修改分页,于是问题就来了。在这个场景下,我们会预期会经历点击搜索 => 判断修改了条件 => setPaginate => 获取数据 这样一个流程。那么试验一下是否会按照我们的预期进行
tsx
// src/pages/user/UserList.tsx
const updateCondition = (
key: keyof typeof condition,
value: (typeof condition)[keyof typeof condition]
) => {
setCondition({
...condition,
[key]: value,
});
};
const fetchData = async () => {
const nextPaginate = {
...paginate,
pageNo: 1,
}
const res = await request.post("user/getList", {
...condition,
...nextPaginate,
});
// 数据回来之后修改分页状态
setPaginate(nextPaginate);
return {
data: res.data.data.list || [],
total: res.data.data.total || 0,
};
};打开控制台,在 keyword 中输入文字之后,点击搜索发现有两次请求出现
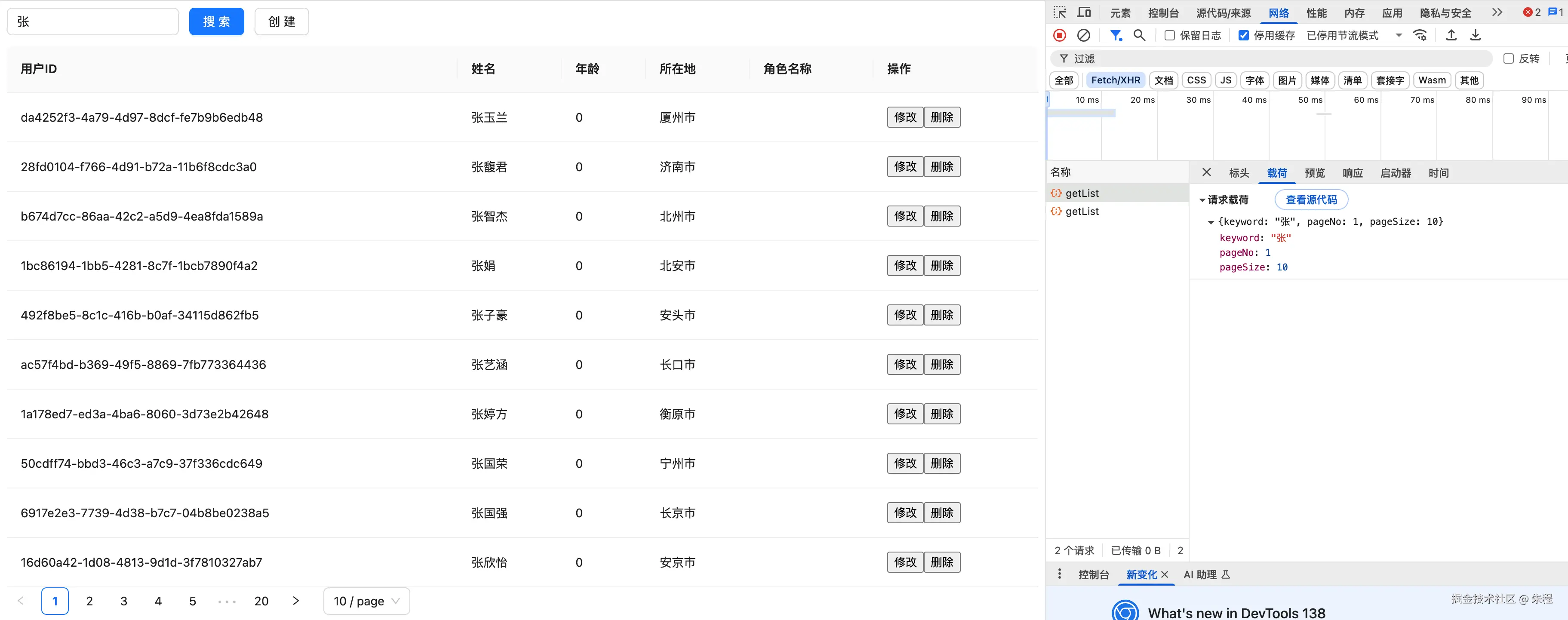
回想一下我们之前的代码,我们注册了一个副作用依赖于 paginate,paginate 改变时会执行副作用去请求数据。那我们在输入keyword之后点击搜索,实际上经历的是 [点击搜索 => 判断修改了条件 => 获取数据 => setPaginate => setData => 第一次渲染] => [effect => 获取数据 => setData => 第二次渲染] , 我们分析一下为什么会出现这个问题,我们想在分页参数修改后获取数据,所以选择了用 effect 去执行,但是分页参数的修改除了点击分页器,还有可能在其他地方改动,而我们想要实现的其实是分页器改动的时候执行这段逻辑,这是一个具体的行为,抽象来说就是一个"事件",而不是一种副作用。对此我们想到去修改handlePageChange 函数来执行获取数据的逻辑。
tsx
// src/pages/user/UserList.tsx
const handlePageChange = (pageNo: number, pageSize: number) => {
if (pageSize !== paginate.pageSize) {
setPaginate({
pageNo: 1,
pageSize,
});
} else {
setPaginate({
...paginate,
pageNo,
});
}
loadData();
};修改之后测试一下,我们发现了另一个问题,翻页的时候传的参数都是上一次修改的参数,于是我们碰到了 react 经典的闭包陷阱,由于 setState 是一个异步操作,所以在 loadData 我们每次读取到参数都是上一次的参数。分析一下如何解决这个问题,我们想到可以修改函数签名,让获取数据的函数直接接收参数。重构一下我们的 fetchData 函数,使其接收条件参数,而它的职责只负责获取数据 & 更新数据。接着我们调整获取数据的地方,由于搜索是一个具体行为,而且它需要在数据回来之后修改分页状态(为什么是在数据回来之后而不是之前?因为如果搜索失败,分页的状态已经被重置了,但是数据还是旧的)
tsx
// src/pages/user/UserList.tsx
const [loading, setLoading] = useState(false);
const fetchData = async (
customCondition = condition,
customPaginate = paginate
) => {
try {
setLoading(true);
const {
data: {
data: {
list,
total
}
}
} = await request.post("user/getList", {
...customCondition,
...customPaginate,
});
setData(list);
setPageInfo({
...pageInfo,
total,
});
} finally {
setLoading(false);
}
};
const handlePageChange = (pageNo: number, pageSize: number) => {
const nextPaginate = {
pageNo,
pageSize,
};
if (pageSize !== paginate.pageSize) {
nextPaginate.pageNo = 1;
}
setPaginate(nextPaginate);
fetchData(undefined, nextPaginate);
};
const handleSearch = async () => {
await fetchData();
setPaginate((pre) => ({
...pre,
pageNo: 1,
}));
};至此,我们完善了了我们的数据获取的细节,同时解决了之前的 bug
4.优化
上述的 fetchData 并未解决竞态问题,而我们可能翻页很快速。查询 caniuse 和 axios 文档后发现,AbortController api 被大多数浏览器支持,而我们的后台管理系统一般都会指定浏览器使用(不需要考虑万恶的 ie 兼容),所以这里我们使用 AbortController 来处理竞态问题
tsx
// src/pages/user/UserList.tsx
const abortRef = useRef<AbortController | null>(null)
const fetchData = async (
customCondition = condition,
customPaginate = paginate
) => {
if (abortRef.current) {
abortRef.current.abort()
}
const abortController = new AbortController()
abortRef.current = abortController
try {
setLoading(true);
const {
data: {
data: {
list,
total
}
}
} = await request.post("user/getList", {
...customCondition,
...customPaginate,
}, {
signal: abortController.signal
});
if (!abortController.signal.aborted) {
setData(list);
setPageInfo({
...pageInfo,
total,
});
}
} finally {
setLoading(false);
}
};小结
至此我们完整的走完了增删改查的业务逻辑,中间出现了一些 bug,比如副作用意外执行,闭包陷阱。我们不能依赖副作用来驱动我们的业务逻辑,例如之前的 paginate 问题,这也和 React 官方文档中的将事件从 Effect 中分开这一章节对应。
接下来我们研究一下 React 比较流行的状态管理库 Zustand 的使用。