目录
集成学习分为Bagging,Boosting和Stacking,今天重点总结下Boosting。对于Bagging这里简单总结一下原理:
1.Bootstrap抽样:首先从原始训练数据集中,采用有放回抽样的方式抽取一定数量的样本,形成一个新的子数据集。由于是有放回抽样,每次抽取的子数据集可能包含原始数据集中的重复样本,也可能不包含某些样本。
2.训练基学习器:针对每个通过Bootstrap抽样得到的子数据集,独立地训练一个基学习器。基学习器可以是各种机器学习模型,常见的如决策树,也可以是支持向量机、逻辑回归等。这些基学习器之间相互独立,并行训练,例如,我们得到了5个子数据集,就可以并行训练5个决策树作为基学习器。
3.预测结果 :通过投票法对测试样本进行分类预测。例如,对于分类任务 ,有5个基学习器,其中 3个预测样本属于A类,2个预测属于B类,那么最终预测该样本属于A类;对于回归任务,则采用平均法,将每个基学习器对测试样本的预测值进行算术平均,得到的平均值作为最终的预测结果。
下面讲Boosting:
一.AdaBoost基本框架
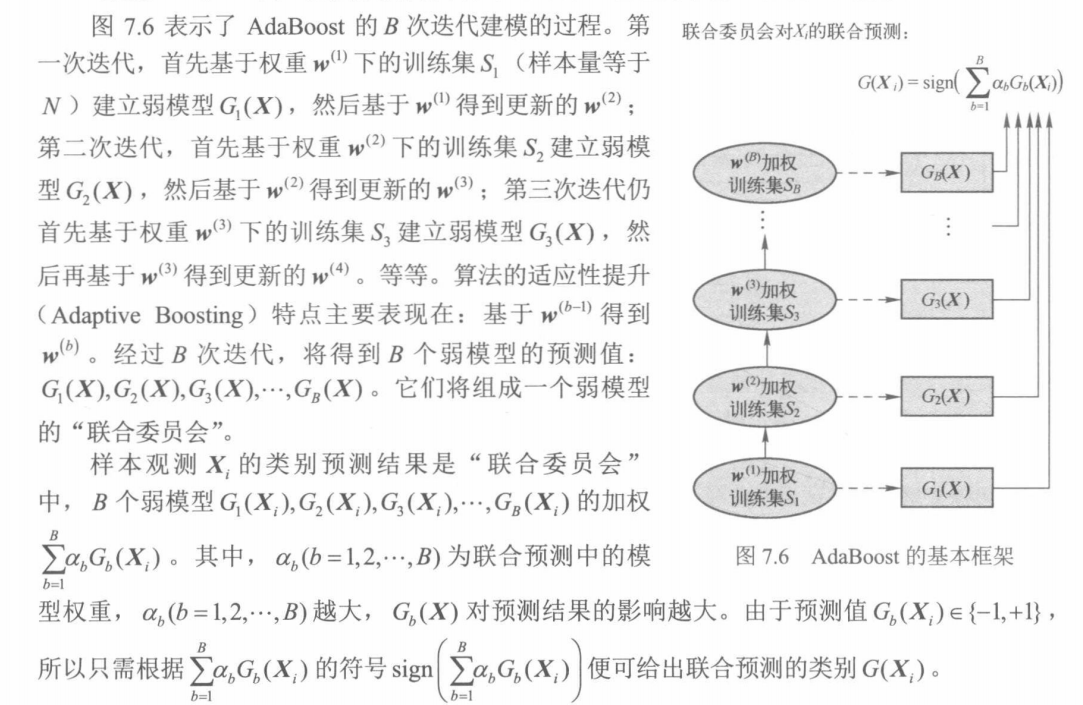
AdaBoost框架构成的集成学习器的训练误差为: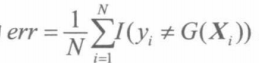 ,其中,I(.)为示性函数,y≠G(
,其中,I(.)为示性函数,y≠G()成立时,函数值等于1,否则等于 0。测试误差仍为基于 OOB 计算的误差。
如下图,数据集包含10个输入变量、12000个样本观测。利用旁置法将其划分成训练集(70%)和测试集(30%)。分别建立单棵树深度等于9的复杂模型、树深度等于1的简单模型(弱模型)以及将多个弱模型按照AdaBoost框架构成的集成学习器,并分别计算三个模型的测试误差。
python
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings(action = 'ignore')
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn import tree
import sklearn.linear_model as LM
from sklearn import ensemble
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.metrics import zero_one_loss,r2_score,mean_squared_error,accuracy_score
import xgboost as xgb
#利用make_classification生成样本量等于12000,10个输入变量,输出变量为二分类的数据集。
X,Y=make_classification(n_samples=12000,n_features=10,n_redundant=0,n_informative=2,random_state=123,n_clusters_per_class=1)
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,train_size=0.70, random_state=123)
#建立树深度等于1的弱模型,计算其测试误差。
dt_stump = tree.DecisionTreeClassifier(max_depth=1, min_samples_leaf=1)
dt_stump.fit(X_train, Y_train)
dt_stump_err = 1.0 - dt_stump.score(X_test, Y_test)
#建立树深度等于9的复杂决策树,计算其测试误差。
dt = tree.DecisionTreeClassifier(max_depth=9, min_samples_leaf=1)
dt.fit(X_train, Y_train)
dt_err = 1.0 - dt.score(X_test, Y_test)
#两种AdaBoost提升策略(SAMME和SAMME.R)
#SAMME算法的AdaBoost(离散型)
B=400
ada_discrete = ensemble.AdaBoostClassifier(base_estimator=dt_stump,n_estimators=B,algorithm="SAMME")
ada_discrete.fit(X_train, Y_train) # 在训练集上训练
#SAMME.R算法的AdaBoost(实数型)
ada_real = ensemble.AdaBoostClassifier(base_estimator=dt_stump,n_estimators=B,algorithm="SAMME.R")
ada_real.fit(X_train, Y_train)
#存储SAMME在测试集上的误差
ada_discrete_err = np.zeros((B,))
for i,Y_pred in enumerate(ada_discrete.staged_predict(X_test)):
ada_discrete_err[i] = zero_one_loss(Y_pred, Y_test)
#存储SAMME.R在测试集上的误差
ada_real_err = np.zeros((B,))
for i, Y_pred in enumerate(ada_real.staged_predict(X_test)):
ada_real_err[i] = zero_one_loss(Y_pred, Y_test)
fig = plt.figure()
axes = fig.add_subplot(111)
axes.axhline(y=dt_stump_err,c='red',linewidth=0.8,label='单个弱模型')
axes.axhline(y=dt_err,c='blue',linewidth=0.8,label='单棵树深度=9的分类树')
axes.plot(np.arange(B), ada_discrete_err,linestyle='--',label='离散AdaBoost')
axes.plot(np.arange(B), ada_real_err,linestyle='-.',label='连续AdaBoost')
axes.set_xlabel('迭代次数B')
axes.set_ylabel('测试误差')
axes.set_title('单棵树、弱模型和adaBoost集成树')
axes.legend()
#leg = axes.legend(loc='upper right', fancybox=True)
#leg.get_frame().set_alpha(0.7)
plt.show()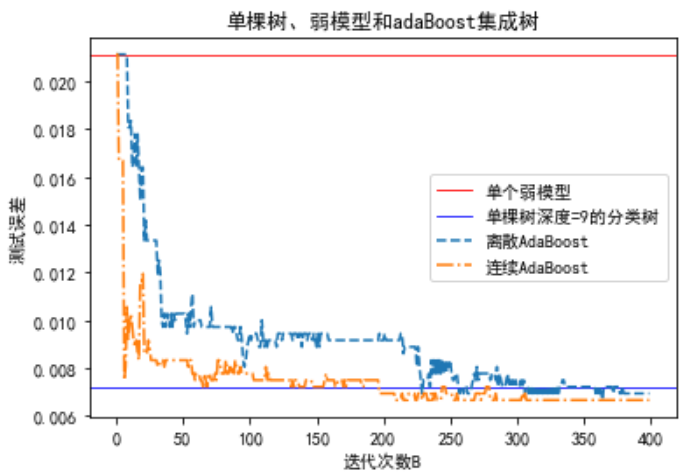
结论:
弱模型的测试误差最高,复杂决策树的测试误差最低,但随迭代次数的增加,AdaBoost提升策略的测试误差会低于复杂模型的测试误差。
二.AdaBoost.M1
AdaBoost.M1是AdaBoost框架下用于解决二分类问题的算法。AdaBoost.M1与SAMME一样都属于离散型提升算法,通过"样本权重"和"模型权重"迭代训练多个弱分类器,并加权组合成强分类器。
1.样本权重
初始时,所有样本权重相等,即 ,N 是样本总数。每次迭代后,预测错误的样本权重会增大, 比如样本
,被弱模型G1错分,它的
就会变大,目的是让后续迭代"重点关注这些难分类的样本"。
第二次迭代,这些难分类的样本会被"重点学习",因为其权重更高,更容易被抽中。这样,新的弱模型G2会优先关注G1没有分队的样本,弥补前一个模型的不足。
弱模型也就是简单分类器,如简单决策树,目的是让样本正确分类,但预测能力一般。
2.模型权重
模型权重用于计算弱模型的"投票权",用训练误差计算弱模型的"可信度":
越小,
越大,那么这个弱模型在"最终组合"里话语权越高。把多个弱模型的预测结果,按
加权求和。这样使得准的模型影响更大。这里要求
<0.5,否则
≤0,
就没有意义了。
按上面的方法迭代,循环B次,把所有按
加权组合,就能得到强分类器。

样本权重的更新方法:

注意:
每次更新样本权重后,都有一个归一化步骤,保证=1,让权重始终是 "相对重要性"。
3.数据模拟
下面基于800个样本在X1、X2两个输入变量上的联合分布,预测样本类别:
python
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings(action = 'ignore')
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn import tree
import sklearn.linear_model as LM
from sklearn import ensemble
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.metrics import zero_one_loss,r2_score,mean_squared_error,accuracy_score
import xgboost as xgb
N=800
X,Y=make_circles(n_samples=N,noise=0.2,factor=0.5,random_state=123) #利用make_circles生成样本量等于800
unique_lables=set(Y)
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(15,6))
colors=plt.cm.Spectral(np.linspace(0,1,len(unique_lables)))
#标记样式
markers=['o','*']
#循环绘制每个类别的样本点
for k,col,m in zip(unique_lables,colors,markers):
x_k=X[Y==k]
#plt.plot(x_k[:,0],x_k[:,1],'o',markerfacecolor=col,markeredgecolor="k",markersize=8)
axes[0].scatter(x_k[:,0],x_k[:,1],color=col,s=30,marker=m)
axes[0].set_title('%d个样本观测点的分布情况'%N)
axes[0].set_xlabel('X1')
axes[0].set_ylabel('X2')
dt_stump = tree.DecisionTreeClassifier(max_depth=1, min_samples_leaf=1)
#生成500个弱分类器
B=500
#初始化AdaBoost分类器:基分类器为决策树桩(树深度等于1的分类树),迭代500次,算法采用提升策略
adaBoost = ensemble.AdaBoostClassifier(base_estimator=dt_stump,n_estimators=B,algorithm="SAMME",random_state=123)
adaBoost.fit(X,Y)
adaBoostErr = np.zeros((B,))
#staged_predict会返回AdaBoost在每一次迭代(添加一个弱分类器)后的预测结果,通过计算每次的错误率,展示随着迭代次数增加,训练误差如何下降
for b,Y_pred in enumerate(adaBoost.staged_predict(X)):
adaBoostErr[b] = zero_one_loss(Y,Y_pred)
axes[1].plot(np.arange(B),adaBoostErr,linestyle='-')
axes[1].set_title('迭代次数与训练误差')
axes[1].set_xlabel('迭代次数')
axes[1].set_ylabel('训练误差') 以上代码以树深度等于1的分类树为基础学习器,采用提升策略进行集成学习。随迭代次数的增加,前期训练误差快速下降,大约30次后下降不明显并保持在一个基本稳定的水平。
输出:
python
# 遍历每一次迭代,更新样本权重并在特定迭代次数绘图
for b,Y_pred in enumerate(adaBoost.staged_predict(X)):
data['Y_pred']=Y_pred # 存储当前迭代的预测结果
# 更新样本权重:预测错误的样本权重增大
# (1.0-adaBoost.estimator_errors_[b])/adaBoost.estimator_errors_[b] 等价于exp(α_b),其中α_b是第b个弱分类器的权重
data.loc[data['Y']!=data['Y_pred'],'Weight'] *= (1.0-adaBoost.estimator_errors_[b])/adaBoost.estimator_errors_[b]
# 当迭代次数为5、10、20、450时,绘制高权重样本的分布
if b in [5,10,20,450]:
axes = fig.add_subplot(2,2,[5,10,20,450].index(b)+1) # 在2行2列的子图中添加当前迭代的图
# 按类别绘制样本点,点的大小由权重决定(权重越大,点越大)
for k,col,m in zip(unique_lables,colors,markers):
tmp=data.loc[data['Y']==k,:] # 筛选标签为k的样本
# 权重映射到点的大小(归一化后放大,便于可视化)
tmp['Weight']=10+tmp['Weight']/(tmp['Weight'].max()-tmp['Weight'].min())*100
axes.scatter(tmp['X1'],tmp['X2'],color=col,s=tmp['Weight'],marker=m) # 绘制散点图(大小由权重决定)
axes.set_xlabel('X1')
axes.set_ylabel('X2')
axes.set_title("高权重的样本观测点(迭代次数=%d)"%b) # 注明当前迭代次数以上代码以点的大小展示迭代5次,10次,20次和450次时样本观测的权重大小。高权重(预测误差)的样本观测主要集中在两类的圆形边界上(两类的 "边界" 就是内圆和外圆之间的过渡区域,这些边界上的点,既像内圆的点,又像外圆的点,最容易被模型错分,因此会被反复增大权重,最终在图中表现为最大的点。)
输出:
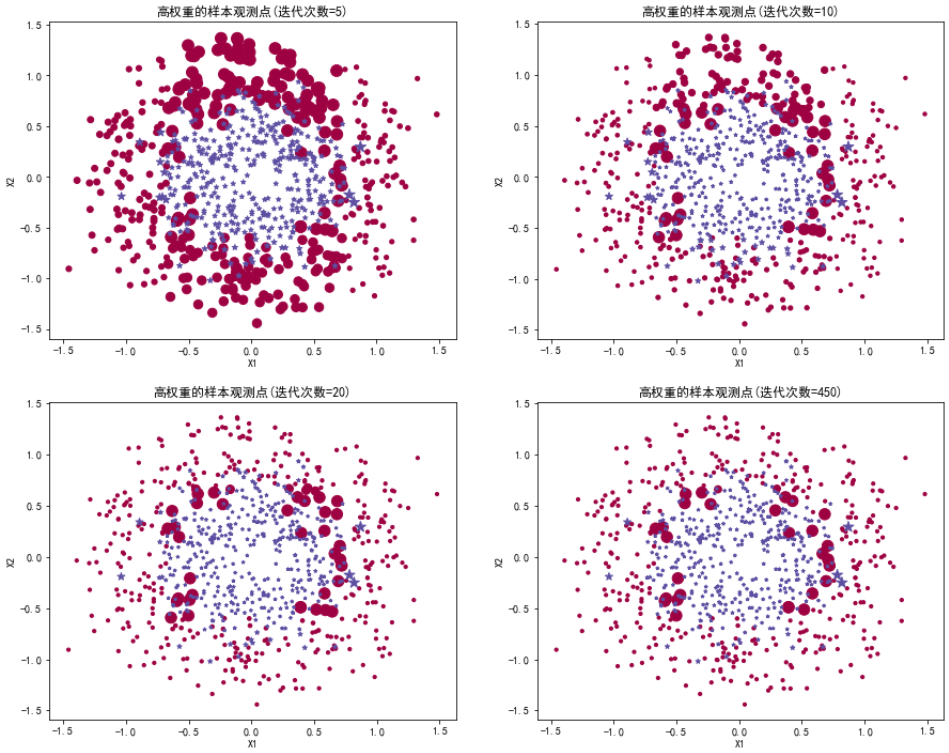
可以看到,随着迭代推进,大部分样本已被正确分类,只剩最顽固的边界点还保持高权重。
三.回归预测中的提升法
回归预测中的提升法所用框架与AdaBoost类似。


通过数据模拟,随机生成样本量为1000的数据集,包括10个输入变量,输出变量服从高斯分布。然后,利用旁置法将数据集划分为训练集(70%)和测试集(30%)。之后,选择树深度为1的回归树作为弱模型进行集成学习。
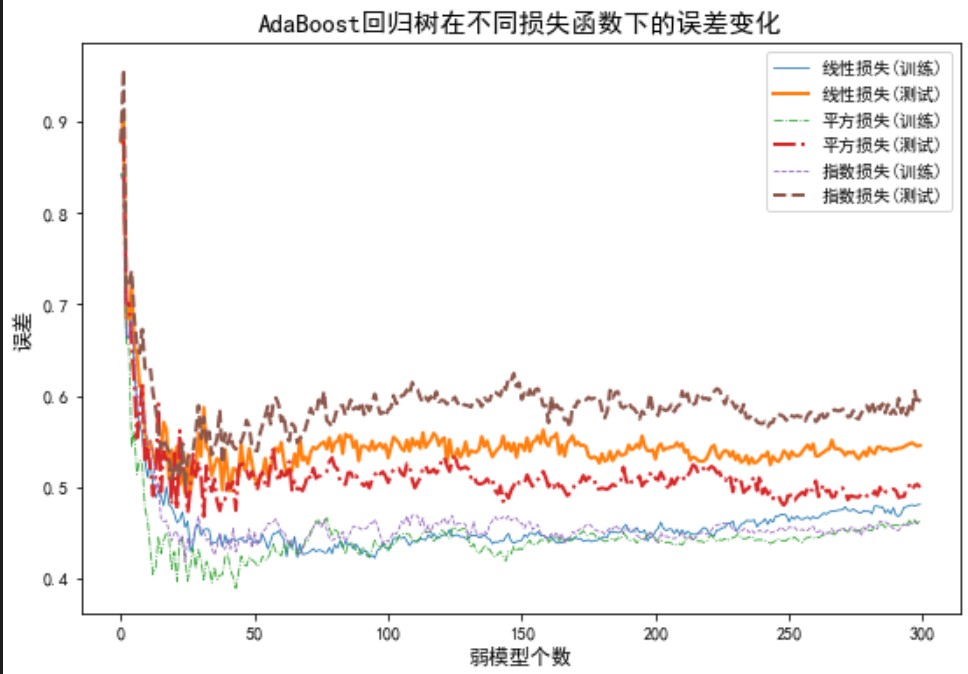
可以看到,平方损失函数下模型的测试误差,低于其他两种损失定义下模型的测试误差,所以应选择平方损失函数下的集成学习预测模型。
代码如下:
python
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings(action = 'ignore')
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn import tree
import sklearn.linear_model as LM
from sklearn import ensemble
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.metrics import zero_one_loss,r2_score,mean_squared_error,accuracy_score
import xgboost as xgb
N=1000
X,Y=make_regression(n_samples=N,n_features=10,random_state=123)
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,train_size=0.70, random_state=123)
B=300
dt_stump = tree.DecisionTreeRegressor(max_depth=1, min_samples_leaf=1)
Loss=['linear', 'square', 'exponential']
LossName=['线性损失','平方损失','指数损失']
Lines=['-','-.','--']
plt.figure(figsize=(9,6))
for lossname,loss,lines in zip(LossName,Loss,Lines):
TrainErrAdaB=np.zeros((B,))
TestErrAdaB=np.zeros((B,))
adaBoost = ensemble.AdaBoostRegressor(base_estimator=dt_stump,n_estimators=B,loss=loss,random_state=123)
adaBoost.fit(X_train,Y_train)
for b,Y_pred in enumerate(adaBoost.staged_predict(X_train)):
TrainErrAdaB[b]=1-r2_score(Y_train,Y_pred)
for b,Y_pred in enumerate(adaBoost.staged_predict(X_test)):
TestErrAdaB[b]=1-r2_score(Y_test,Y_pred)
plt.plot(np.arange(B),TrainErrAdaB,linestyle=lines,label="%s(训练)"%lossname,linewidth=0.8)
plt.plot(np.arange(B),TestErrAdaB,linestyle=lines,label="%s(测试)"%lossname,linewidth=2)
plt.title("AdaBoost回归树在不同损失函数下的误差变化",fontsize=15)
plt.xlabel("弱模型个数",fontsize=12)
plt.ylabel("误差",fontsize=12)
plt.legend()四.梯度提升树
梯度提升树采用向前式分步可加建模方式,基于损失函数采用梯度下降法,通过不断迭代最终获得理想的预测模型。可以理解为"集成学习"与"梯度下降"相结合的方法,"集成学习"即上面讲到的有多个弱学习器得到一个强学习器。"梯度下降"即沿着损失函数负梯度方向,逐步减少误差,用这种思路指导弱学习器训练。
AdaBoost回归树与梯度提升树的对比:
如下图所示,大约 25 次迭代后,AadBoost 集成学习策略的训练误差下降不明显(基本保持不变),但梯度提升树的训练误差呈现持续降低的趋势,这是梯度提升树的算法机理决定的,且没有出现模型过拟合。梯度提升树优于 AadBoost 集成学习策略。
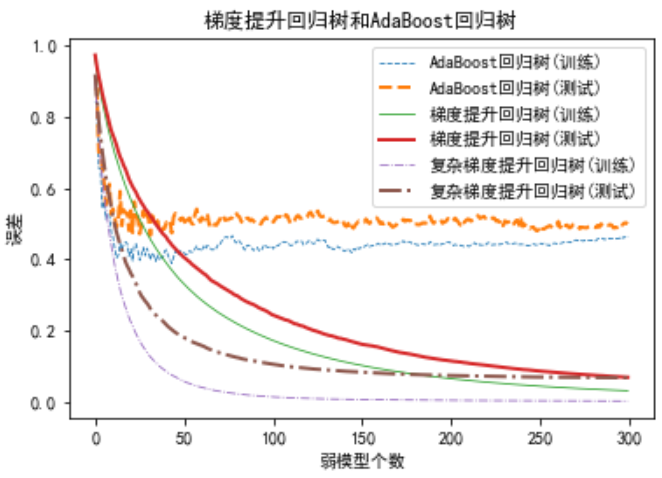
代码如下:
python
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings(action = 'ignore')
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn import tree
import sklearn.linear_model as LM
from sklearn import ensemble
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.metrics import zero_one_loss,r2_score,mean_squared_error,accuracy_score
import xgboost as xgb
#利用make_regression生成样本量等于1000,包括10个数据变量,输出变量为数值型的数据集。
N=1000
X,Y=make_regression(n_samples=N,n_features=10,random_state=123)
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,train_size=0.70, random_state=123)
B=300
dt_stump = tree.DecisionTreeRegressor(max_depth=1, min_samples_leaf=1)
TrainErrAdaB=np.zeros((B,))
TestErrAdaB=np.zeros((B,))
#计算提升策略回归树的训练误差和测试误差,基础学习器为简单树桩(max_depth=1)
adaBoost = ensemble.AdaBoostRegressor(base_estimator=dt_stump,n_estimators=B,loss= 'square',random_state=123)
adaBoost.fit(X_train,Y_train)
for b,Y_pred in enumerate(adaBoost.staged_predict(X_train)):
TrainErrAdaB[b]=1-r2_score(Y_train,Y_pred)
for b,Y_pred in enumerate(adaBoost.staged_predict(X_test)):
TestErrAdaB[b]=1-r2_score(Y_test,Y_pred)
#计算梯度提升回归树的训练误差和测试误差,基础学习器为简单树桩(max_depth=1),与AdaBoost基础学习器复杂度一致
GBRT=ensemble.GradientBoostingRegressor(loss='ls',n_estimators=B,max_depth=1,min_samples_leaf=1,random_state=123)
GBRT.fit(X_train,Y_train)
TrainErrGBRT=np.zeros((B,))
TestErrGBRT=np.zeros((B,))
for b,Y_pred in enumerate(GBRT.staged_predict(X_train)):
TrainErrGBRT[b]=1-r2_score(Y_train,Y_pred)
for b,Y_pred in enumerate(GBRT.staged_predict(X_test)):
TestErrGBRT[b]=1-r2_score(Y_test,Y_pred)
#计算基础学习器为较复杂模型下,提升策略回归树的训练误差和测试误差。
GBRT0=ensemble.GradientBoostingRegressor(loss='ls',n_estimators=B,max_depth=3,min_samples_leaf=1,random_state=123)
GBRT0.fit(X_train,Y_train)
TrainErrGBRT0=np.zeros((B,))
TestErrGBRT0=np.zeros((B,))
for b,Y_pred in enumerate(GBRT0.staged_predict(X_train)):
TrainErrGBRT0[b]=1-r2_score(Y_train,Y_pred)
for b,Y_pred in enumerate(GBRT0.staged_predict(X_test)):
TestErrGBRT0[b]=1-r2_score(Y_test,Y_pred)
plt.plot(np.arange(B),TrainErrAdaB,linestyle='--',label="AdaBoost回归树(训练)",linewidth=0.8)
plt.plot(np.arange(B),TestErrAdaB,linestyle='--',label="AdaBoost回归树(测试)",linewidth=2)
plt.plot(np.arange(B),TrainErrGBRT,linestyle='-',label="梯度提升回归树(训练)",linewidth=0.8)
plt.plot(np.arange(B),TestErrGBRT,linestyle='-',label="梯度提升回归树(测试)",linewidth=2)
plt.plot(np.arange(B),TrainErrGBRT0,linestyle='-.',label="复杂梯度提升回归树(训练)",linewidth=0.8)
plt.plot(np.arange(B),TestErrGBRT0,linestyle='-.',label="复杂梯度提升回归树(测试)",linewidth=2)
plt.title("梯度提升回归树和AdaBoost回归树")
plt.xlabel("弱模型个数")
plt.ylabel("误差")
plt.legend()不同模型分类预测效果:
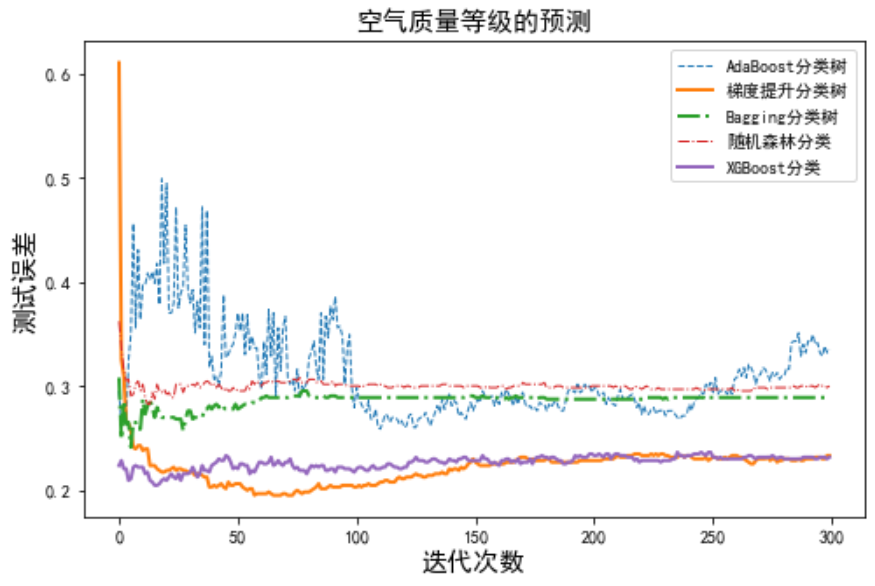
如下图所示,在空气质量等级的预测中,100次迭代后随机森林和袋装法(Bagging分类树)的测试误差基本保持在各自的水平上。梯度提升树的测试误差最低,但大约选代70次后出现了过拟合线性,70次的迭代模型是较为理想的。迭代300次时AdaBoost分类树的测试误差仍有较大波动,表明还需更多次的迭代。梯度提升树的测试误差最低,预测效果最为理想。
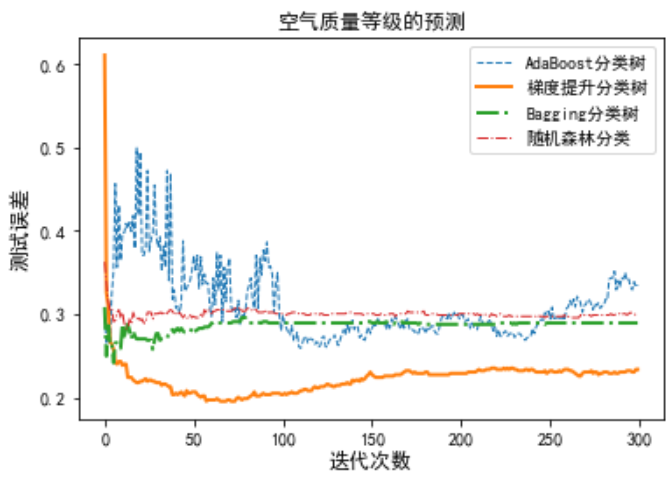
代码如下:
python
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings(action = 'ignore')
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn import tree
import sklearn.linear_model as LM
from sklearn import ensemble
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.metrics import zero_one_loss,r2_score,mean_squared_error,accuracy_score
import xgboost as xgb
data=pd.read_excel('北京市空气质量数据.xlsx')
data=data.replace(0,np.NaN)
data=data.dropna()
X=data.iloc[:,3:-1]
Y=data['质量等级']
Y=Y.map({'优':'1','良':'2','轻度污染':'3','中度污染':'4','重度污染':'5','严重污染':'6'})
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,train_size=0.70, random_state=123)
B=300
#深度为 3 的决策树,作为所有集成算法的 "弱学习器"。
dt_stump = tree.DecisionTreeClassifier(max_depth=3, min_samples_leaf=1)
TestErrAdaB=np.zeros((B,))
#初始化AdaBoost分类器:基模型为dt_stump,迭代300次
adaBoost = ensemble.AdaBoostClassifier(base_estimator=dt_stump,n_estimators=B,random_state=123)
adaBoost.fit(X_train,Y_train)
for b,Y_pred in enumerate(adaBoost.staged_predict(X_test)):
TestErrAdaB[b]=zero_one_loss(Y_test,Y_pred)
TestErrGBRT=np.zeros((B,))
## 初始化梯度提升分类器:损失函数deviance,迭代300次,基模型深度3
GBRT=ensemble.GradientBoostingClassifier(loss='deviance',n_estimators=B,max_depth=3,min_samples_leaf=1,random_state=123)
GBRT.fit(X_train,Y_train)
for b,Y_pred in enumerate(GBRT.staged_predict(X_test)):
TestErrGBRT[b]=zero_one_loss(Y_test,Y_pred)
TestErrBag=np.zeros((B,))
TestErrRF=np.zeros((B,))
for b in np.arange(B):
#Bagging分类器:基模型dt_stump,n_estimators=b+1(每次迭代增加1个基模型) Bag=ensemble.BaggingClassifier(base_estimator=dt_stump,n_estimators=b+1,oob_score=True,random_state=123,bootstrap=True)
Bag.fit(X_train,Y_train)
TestErrBag[b]=1-Bag.score(X_test,Y_test)
#随机森林分类器:基模型决策树(默认),n_estimators=b+1,特征随机选择(max_features="auto") RF=ensemble.RandomForestClassifier(max_depth=3,n_estimators=b+1,oob_score=True,random_state=123,bootstrap=True,max_features="auto")
RF.fit(X_train,Y_train)
TestErrRF[b]=1-RF.score(X_test,Y_test)
plt.figure(figsize=(6,4))
plt.plot(np.arange(B),TestErrAdaB,linestyle='--',label="AdaBoost分类树",linewidth=1)
plt.plot(np.arange(B),TestErrGBRT,linestyle='-',label="梯度提升分类树",linewidth=2)
plt.plot(np.arange(B),TestErrBag,linestyle='-.',label="Bagging分类树",linewidth=2)
plt.plot(np.arange(B),TestErrRF,linestyle='-.',label="随机森林分类",linewidth=1)
plt.title("空气质量等级的预测",fontsize=12)
plt.xlabel("迭代次数",fontsize=12)
plt.ylabel("测试误差",fontsize=12)
plt.legend() 五.XGBoost


XGBoost与其他模型的对比:
python
plt.figure(figsize=(8,5))
plt.plot(np.arange(B),TestErrAdaB,linestyle='--',label="AdaBoost分类树",linewidth=1)
plt.plot(np.arange(B),TestErrGBRT,linestyle='-',label="梯度提升分类树",linewidth=2)
plt.plot(np.arange(B),TestErrBag,linestyle='-.',label="Bagging分类树",linewidth=2)
plt.plot(np.arange(B),TestErrRF,linestyle='-.',label="随机森林分类",linewidth=1)
plt.plot(np.arange(B),result['validation_1']['merror'],linestyle='-',label="XGBoost分类",linewidth=2)
plt.title("空气质量等级的预测",fontsize=15)
plt.xlabel("迭代次数",fontsize=15)
plt.ylabel("测试误差",fontsize=15)
plt.legend() 输出如下,可以看到XGBoost的收敛速度最快,大约经20次左右的选代就可到达较低的测试误差,这是其他集成学习算法无法实现的。尽管梯度提升树的测试误差最低,但要求的迭代却较多(大约70次)。
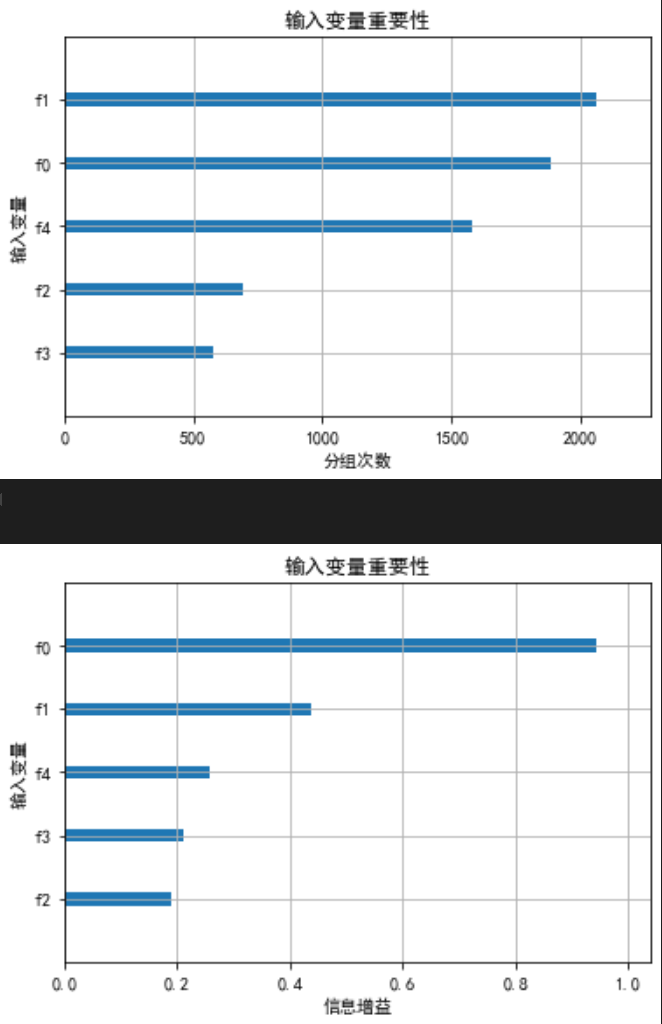
XGBoost可以根据成为最佳分组变量的次数或者根据的平均值的大小来评价变量的重要性。
下图中,纵坐标上的f0对应PM2.5,f1对应PM10,f2对应,f3对应CO,f4对应
。依据成为最佳分组变量的次数,PM10的重要性最高、CO最低。依分组有效性(信息增益),PM2.5的重要性最高、
最低。
代码:
python
xgb.plot_importance(modelXGB,title="输入变量重要性",ylabel="输入变量",xlabel="分组次数",importance_type="weight",show_values=False)
xgb.plot_importance(modelXGB,title="输入变量重要性",ylabel="输入变量",xlabel="信息增益",importance_type="gain",show_values=False)总结:


