大致步骤如下:
- 配置 CloudWatch 采集应用日志
- 通过 SNS 配置通知渠道,参考文章 AWS 亚马逊云预警通知接入钉钉告警(微信同样适用)
- 配置 Lambda 函数,从 CloudWatch Log 查询异常日志并推送至 SNS
- 配置 EventBridge,周期性触发上一步中的 Lambda 函数执行
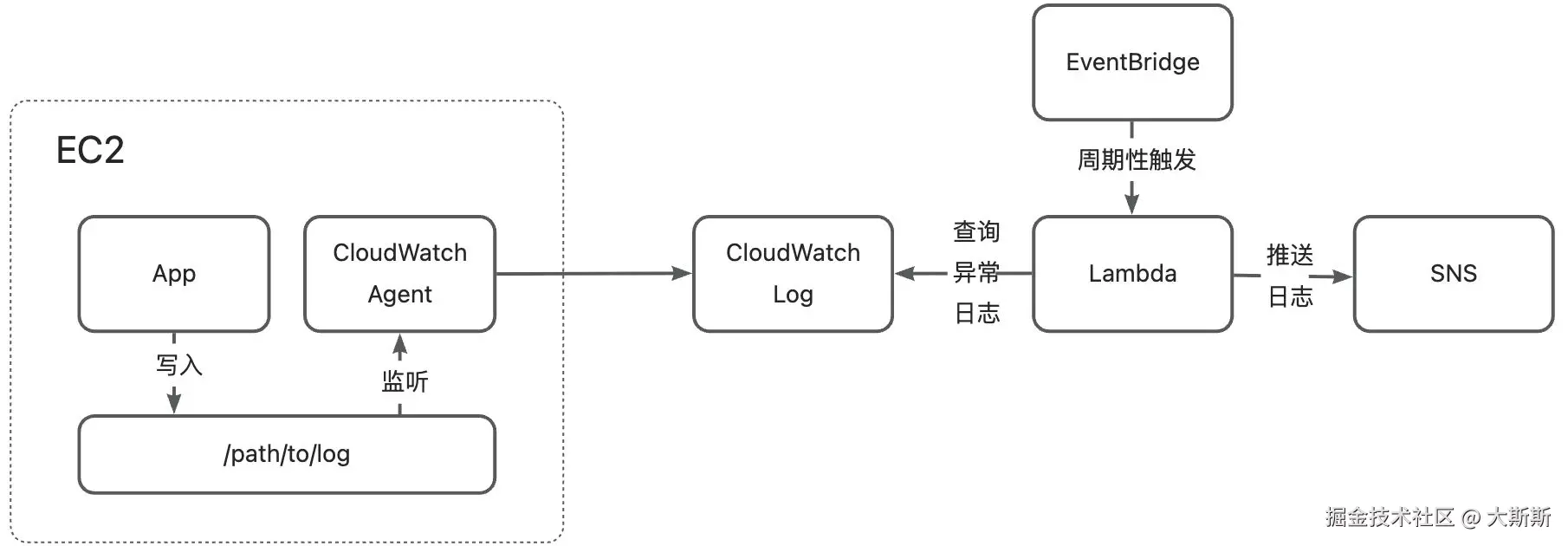
一、方案架构
解决方案如图,共包含以下产品:
- CloudWatch
- Agent:用于采集日志,并推送至日志组
- Log:用于保存推送至日志组中的日志数据,可用于查询及分析
- Lambda:编写函数,从 CloudWatch 中查询异常日志,解析后推送至 SNS
- SNS:用于异常日志的推送
- EventBridge:用于周期性触发 Lambda 的执行(例如 1 分钟执行一次)
二、操作步骤
⚠️ 操作前,确保以下可用: SNS 通知渠道已配置
2.1 配置 CloudWatch Agent 采集日志
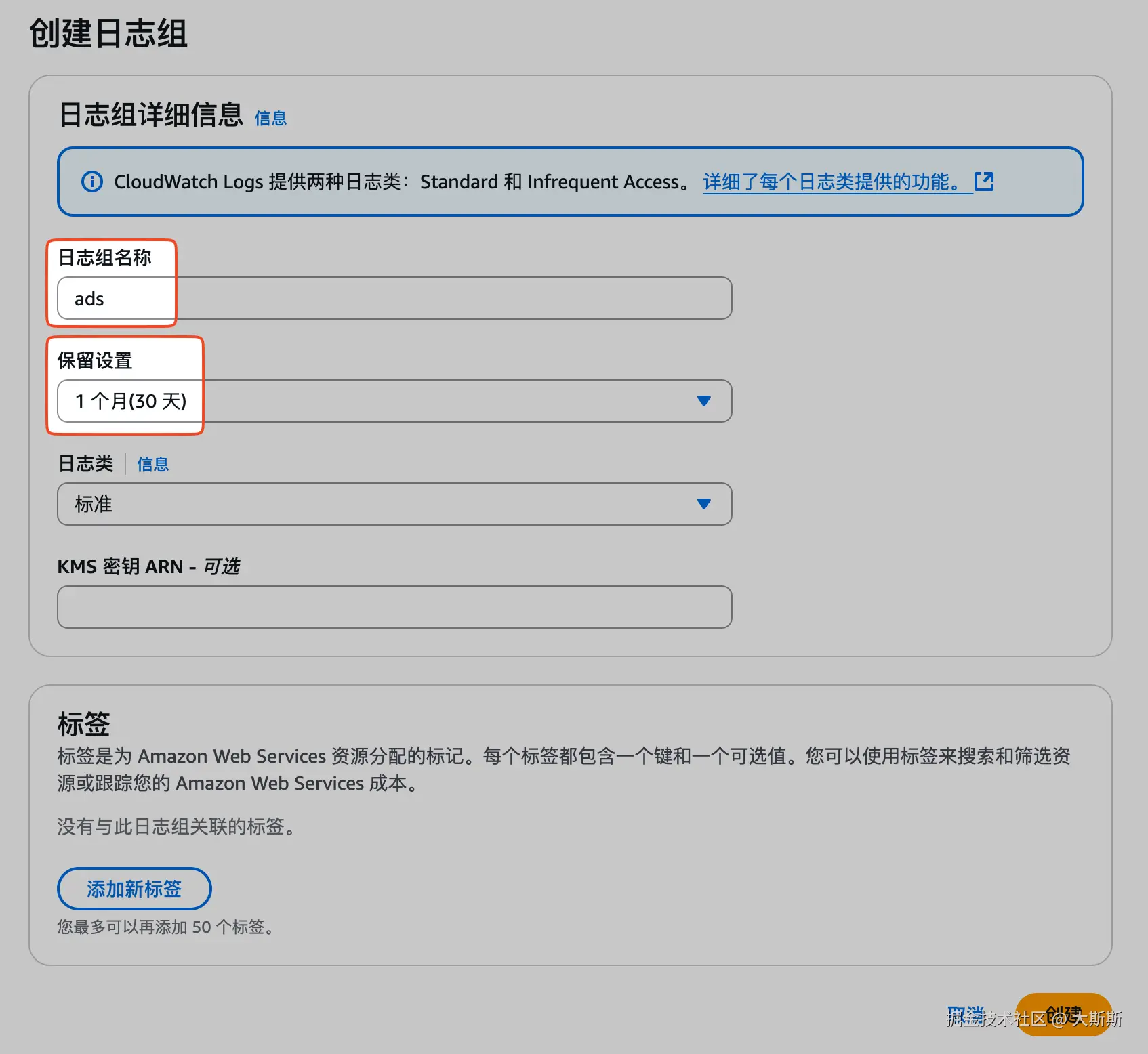
Step 1:创建日志组
步骤如下:
- 登录 CloudWatch 控制台
- 导航栏 "日志" -> "日志组"
- 点击 "创建日志组"
- 配置日志组,包括名称、日志保留周期等(这里名称为
ads,日志保留周期为30天)
Step 2:修改 CWA 配置
步骤如下:
🎙️ 下面的配置文件中,不仅配置了需要采集的指标,同时配置了需要采集的日志文件。 采集的日志文件有:
- /tmp/log/ads_dispatch/info.log
- /tmp/log/ads_docker/info.log
- /home/ubuntu/log/ads_extend/info.log 均推送至 Step 1 中创建的日志组
ads
- 在 EC2 创建
/opt/aws/amazon-cloudwatch-agent/bin/config.json配置文件,文件内容如下
json
{
"agent": {
"metrics_collection_interval": 60
},
# 配置日志采集
"logs": {
"logs_collected": {
"files": {
"collect_list": [
{
# 采集的日志文件路径
"file_path": "/tmp/log/ads_dispatch/info.log",
# 日志存放的日志组(需提前在 CloudWatch 中创建)
"log_group_name": "ads",
# 日志组中的日志流(无需提前创建)
"log_stream_name": "ads_dispatch-{instance_id}",
"retention_in_days": 30
},
{
"file_path": "/tmp/log/ads_docker/info.log",
"log_group_name": "ads",
"log_stream_name": "ads_docker-{instance_id}",
"retention_in_days": 30
},
{
"file_path": "/home/ubuntu/log/ads_extend/info.log",
"log_group_name": "ads",
"log_stream_name": "ads_extend-{instance_id}",
"retention_in_days": 30
}
]
}
}
}
}- 使用如下命令使配置生效
bash
# 新增 CWA 配置
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a append-config -m ec2 -s -c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json
Step 3:验证是否生效
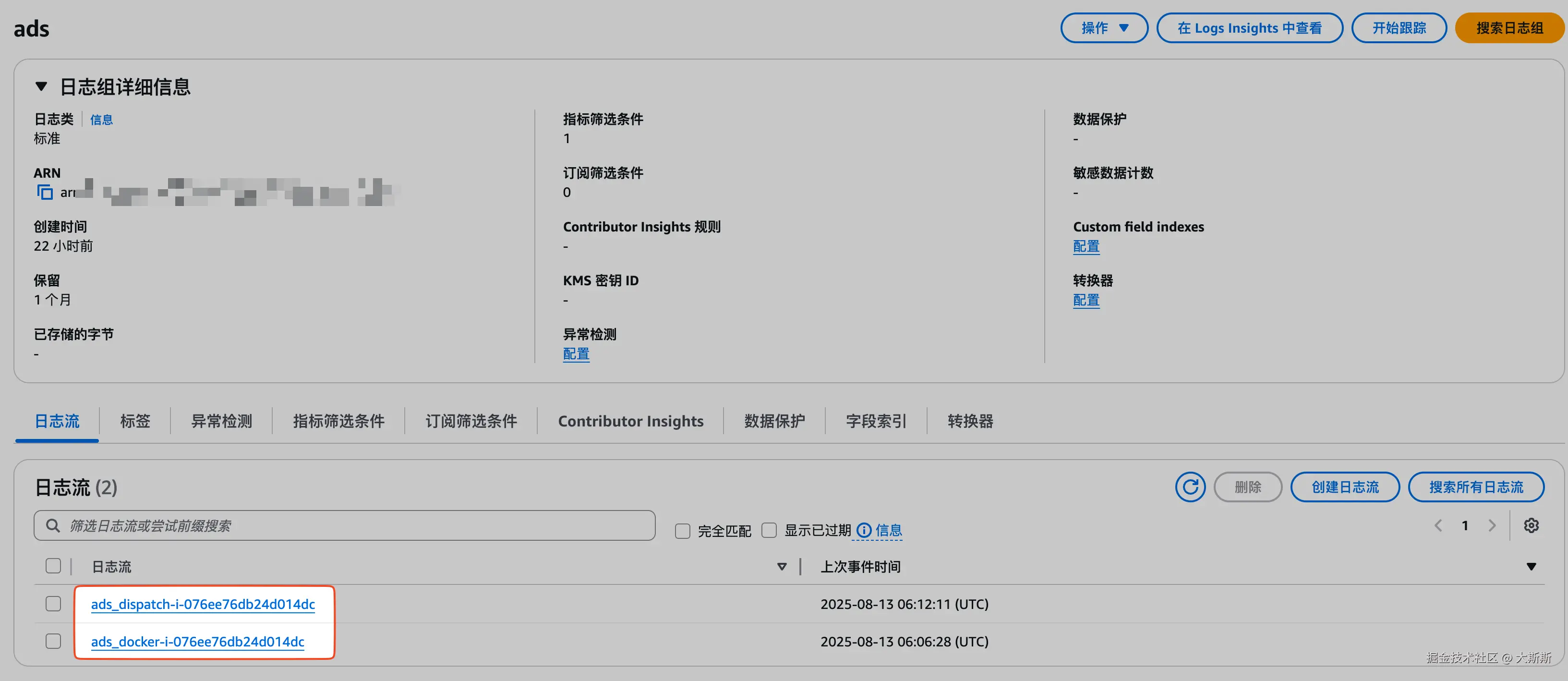
方式一:通过日志流验证
步骤如下:
- 登录 CloudWatch 控制台
- 导航栏 "日志" -> "日志组"
- 选择日志组
ads - 选择标签页 "日志流",确认是否有日志流产生【这里有 2 个是符合预期的,因为配置中的
ads_extend-在我的环境中日志文件不存在,所以没有产生相应的日志流】
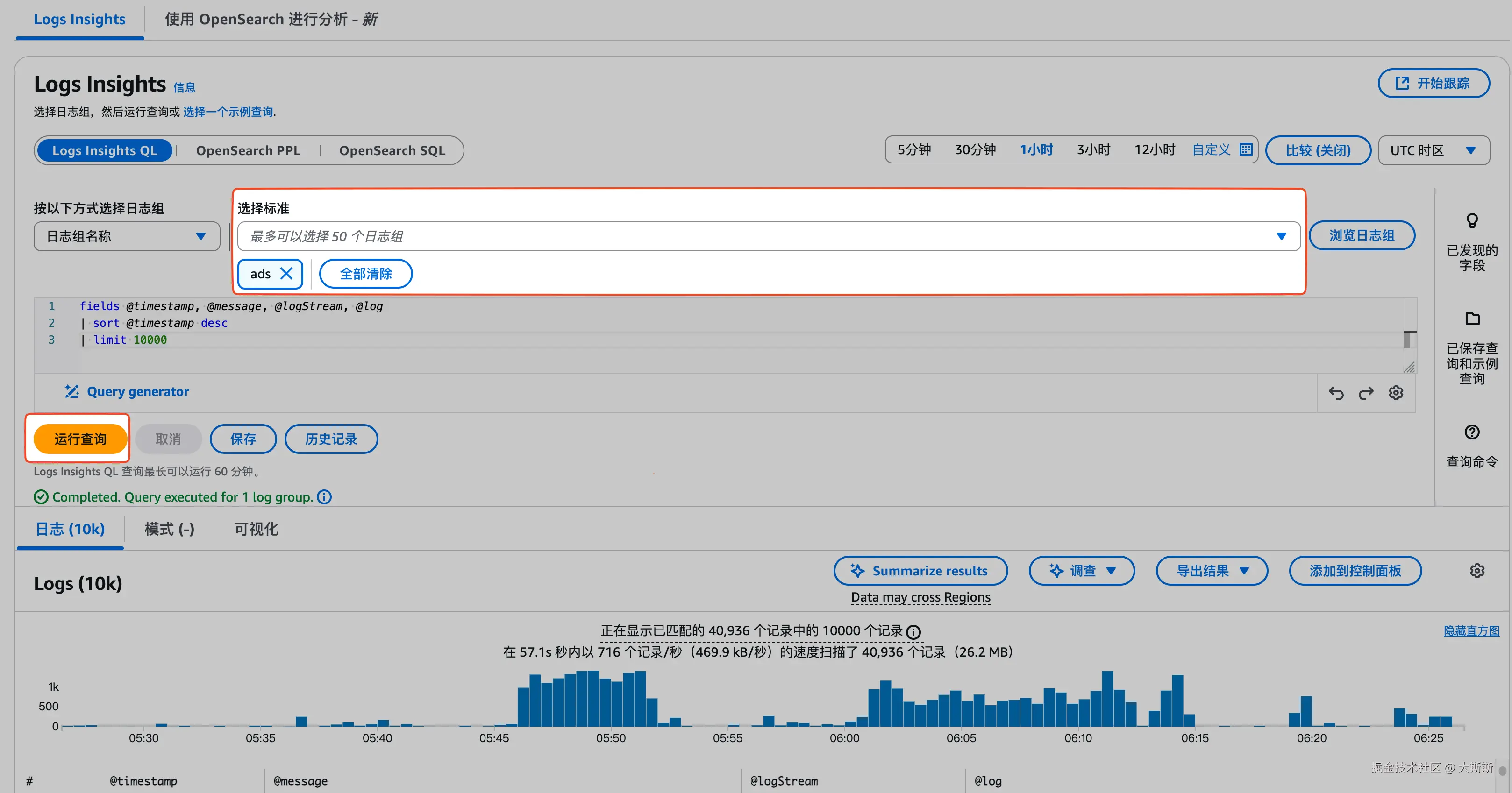
方式二:通过 Log Insights 验证日志是否可查
步骤如下:
- 登录 CloudWatch 控制台
- 导航栏 "日志" -> "Log Insights"
- 选择日志组
ads - 点击 "运行查询",确认是否有日志产生
2.2 配置 Lambda 函数查询并推送异常日志
Step 1:创建 Lambda 函数
步骤如下:
- 本地打包代码与环境依赖(这里使用 Python 开发,代码文件内容为空也没事,后续在 Lambda 控制台可以直接调整):
bash
# 1) 创建打包目录
mkdir -p lambda_pkg && cd lambda_pkg
# 2) 安装依赖到当前目录(这里依赖 boto3)
pip install --upgrade pip
pip install boto3 -t .
# 3) 放入你的代码文件
cp /path/to/lambda_function.py .
# 4) 打包(注意:zip 内应是文件本身,而非外层文件夹)
zip -r ../lambda.zip .
# 5) 返回上一层(得到的 lambda.zip 就能上传了)
cd ..- Lambda 控制台创建函数:导航栏 "函数" -> "创建函数"
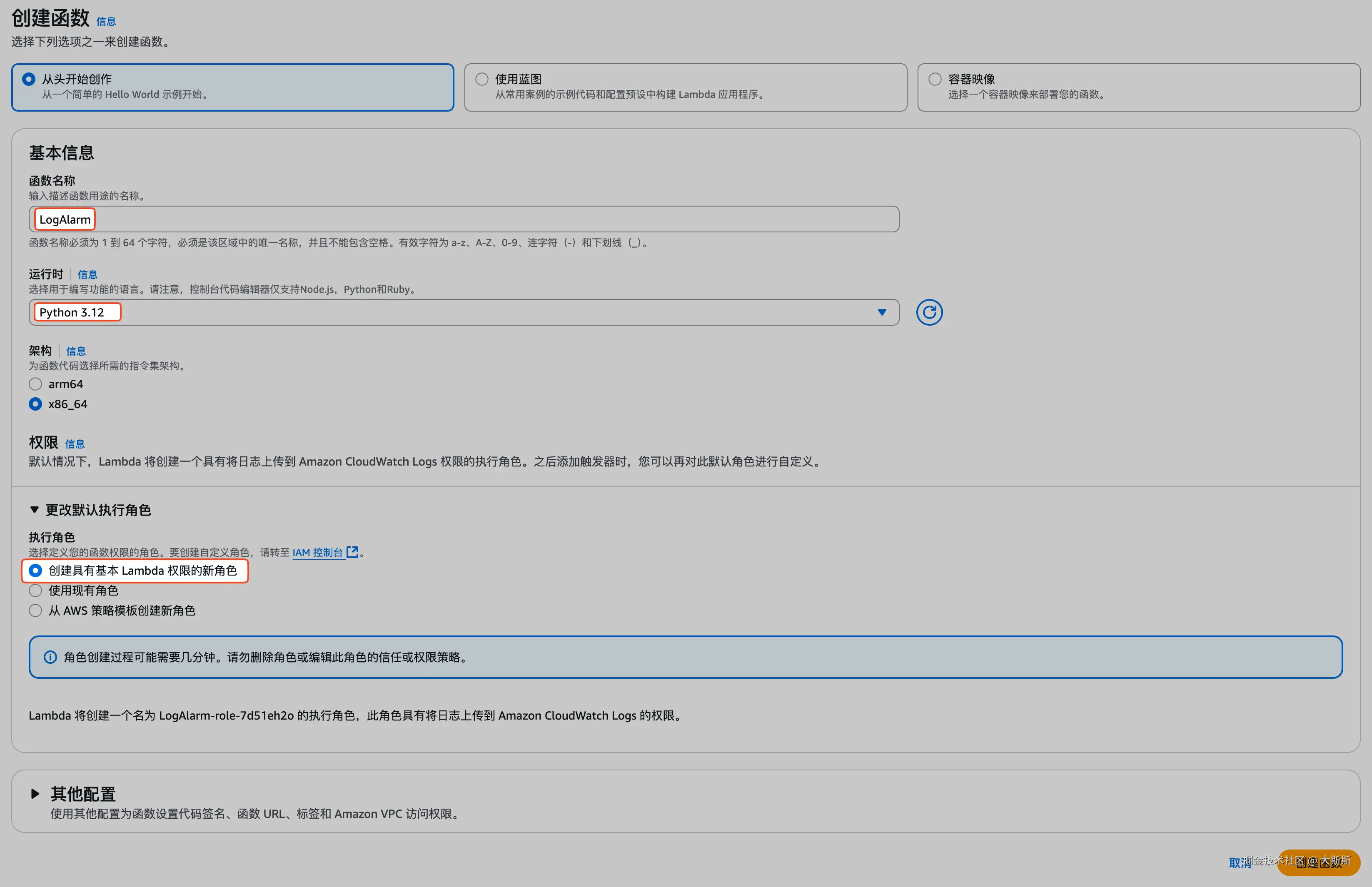
- 将第 1 步中打包的
lambda.zip上传:

- 配置环境变量 token,将之前创建钉钉机器人时获取的 access_token 传入
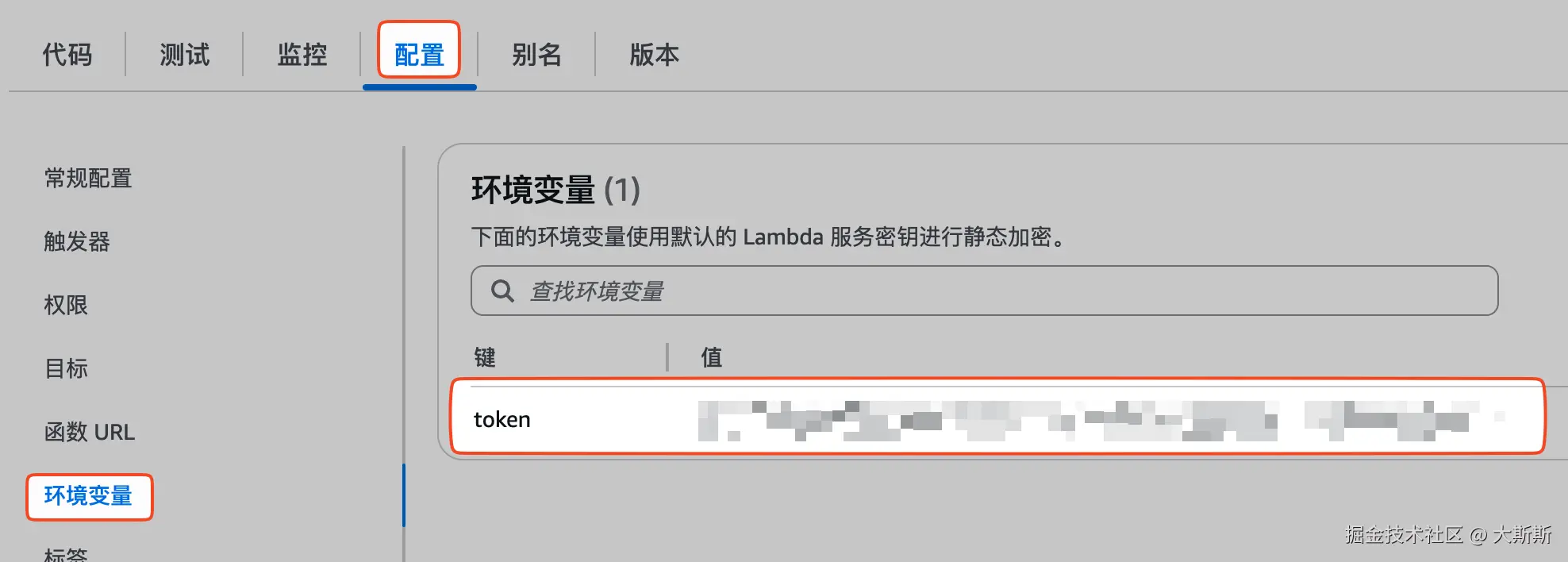
- (按需)修改代码【代码见附录】
Step 2:修改 Lambda 函数配置 - 权限
由于这个 Lambda 函数需要访问 CloudWatch 获取日志,并且需要向 SNS 推送消息,因此需要具备相应的权限。
配置步骤如下:
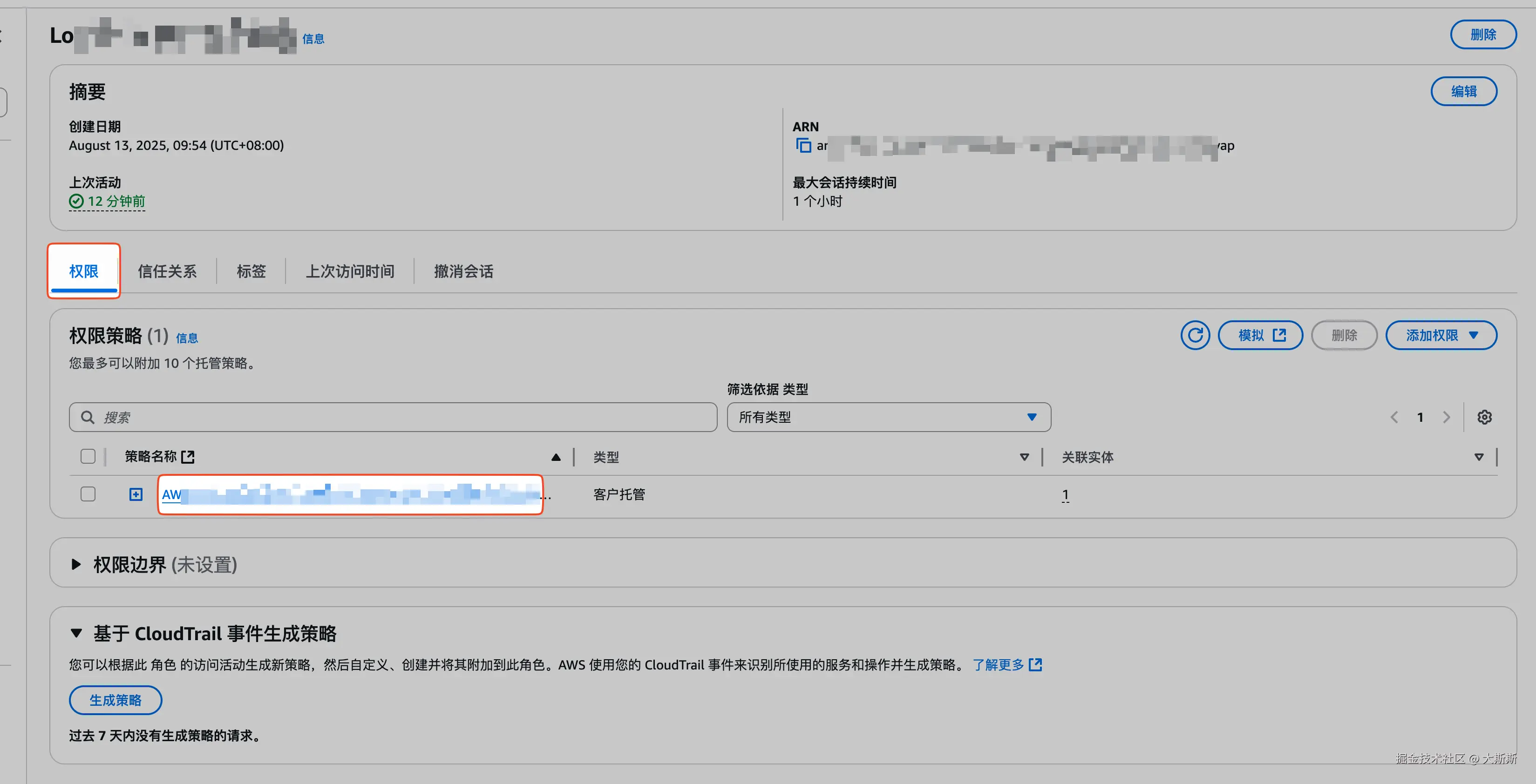
- 登录 Lambda 函数控制台
- 导航栏选择 "函数",点击
LogAlarm函数【Step 1 中创建的】 - 点击标签页 "配置",选择 "权限",点击 "角色名称",跳转至 IAM 控制台

- 选择标签页 "权限",点击默认的权限策略,跳转至权限策略配置页,点击 "编辑"
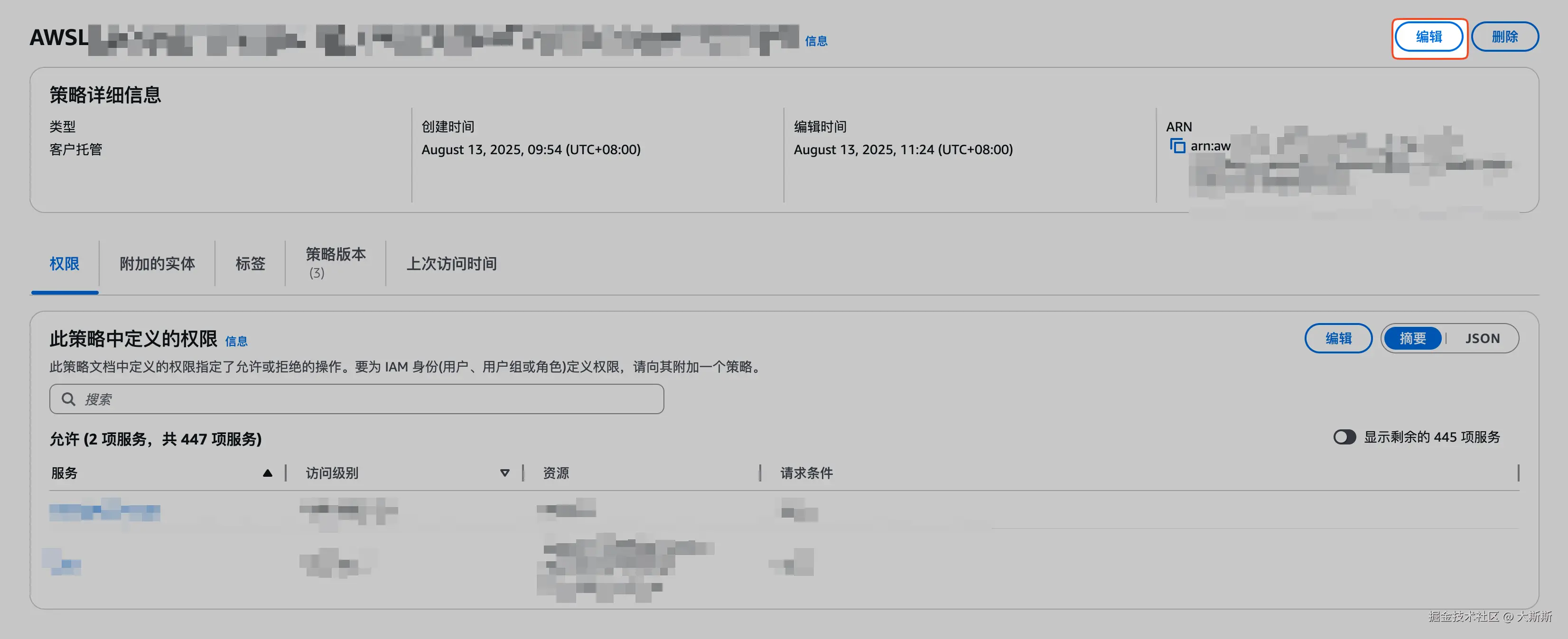
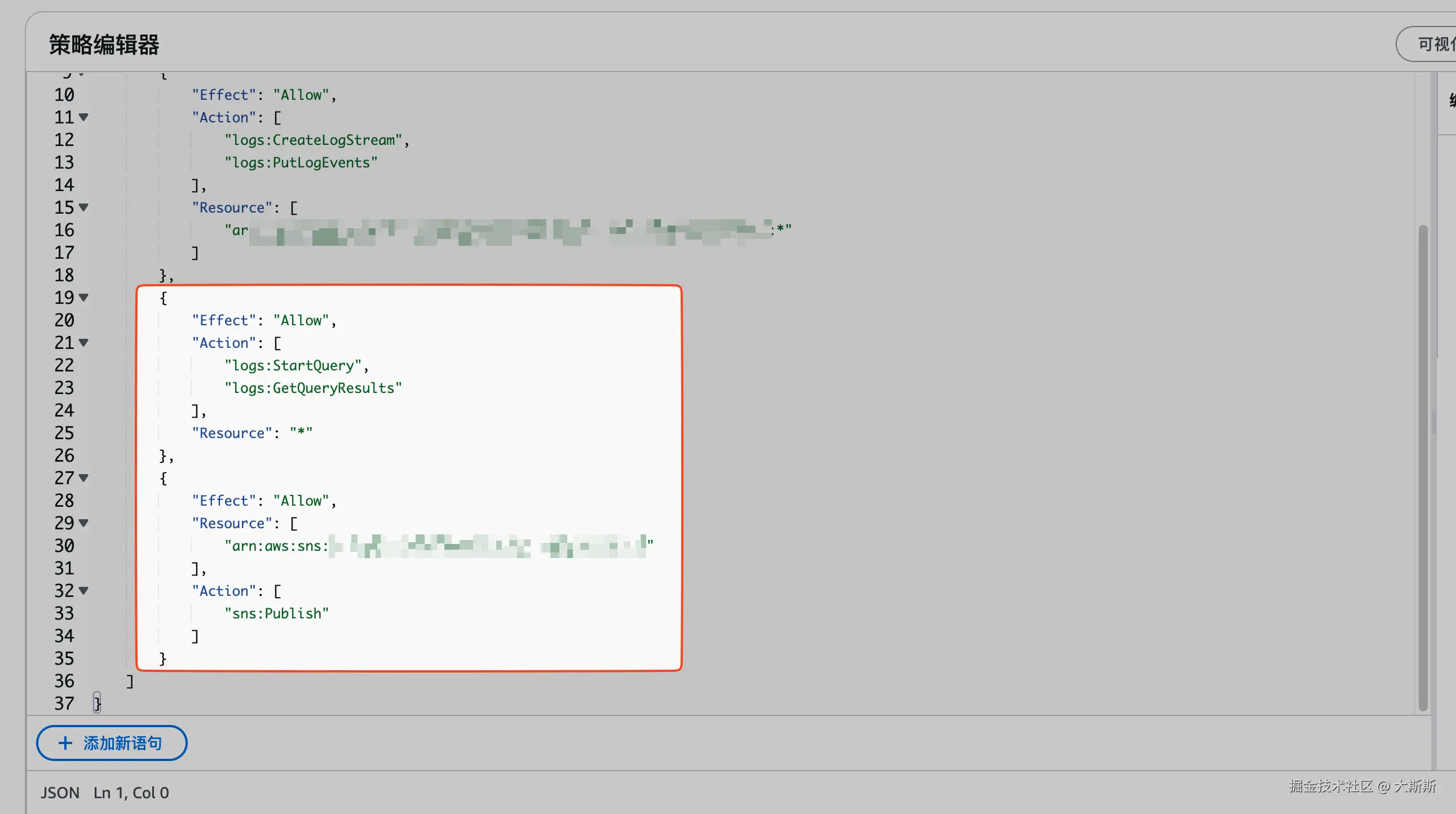
- 在策略编辑器中添加如下策略:
🗣️ 针对
sns:Publish,需指定 Resource,这里指定的是 SNS 主题的 ARN(在 SNS 控制台中可以找到)
json
{
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:StartQuery",
"logs:GetQueryResults"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Resource": [
"arn:aws:****"
],
"Action": [
"sns:Publish"
]
}
]
}
- 保存
Step 3:修改 Lambda 函数配置 - 环境变量
配置步骤如下:
- 登录 Lambda 函数控制台
- 导航栏选择 "函数",点击
LogAlarm函数【Step 1 中创建的】 - 点击标签页 "配置",选择 "环境变量",增加如下配置
| 环境变量 | 说明 | 案例 |
|---|---|---|
| ALERT_TITLE | 预警名,推送至 SNS 时用的 | Ads 运行日志异常告警 |
| LIMIT | 每次查询的异常日志个数 | 10 |
| LOG_GROUP | 日志组 | ads |
| MIN_COUNT | 异常日志数大于等于 MIN_COUNT 时才触发 | 1 |
| SNS_TOPIC_ARN | SNS 主题的 ARN | arn:aws:sns:xxxx:xxxxx:xxxxx |
| WINDOW_SECONDS | 捞取的日志时间周期 | 120 |
Step 4:验证是否生效
步骤如下:
- 创建测试【事件内容不重要,随便填】
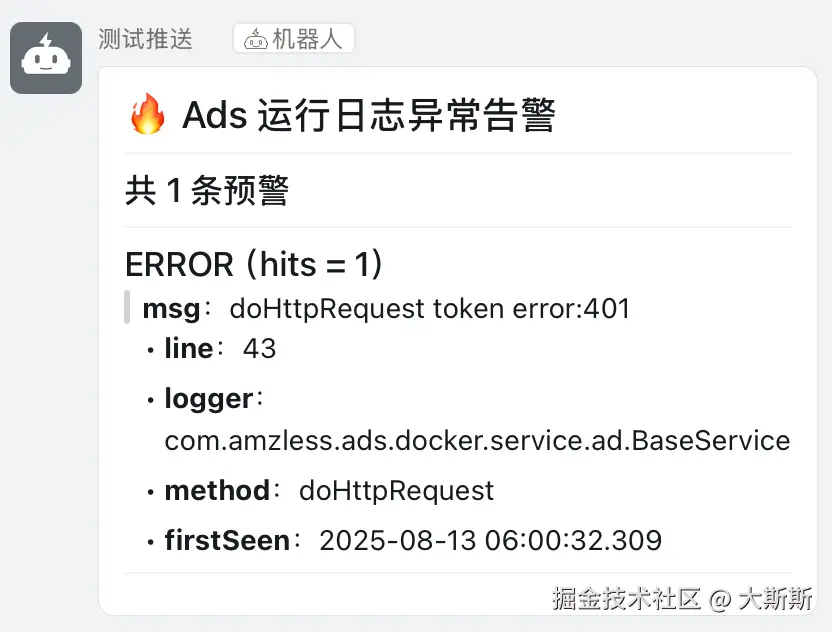
- 发起测试,验证是否收到推送
2.3 配置 EventBridge 周期性触发 Lambda 执行
步骤如下:
- 登录 EventBridge 控制台
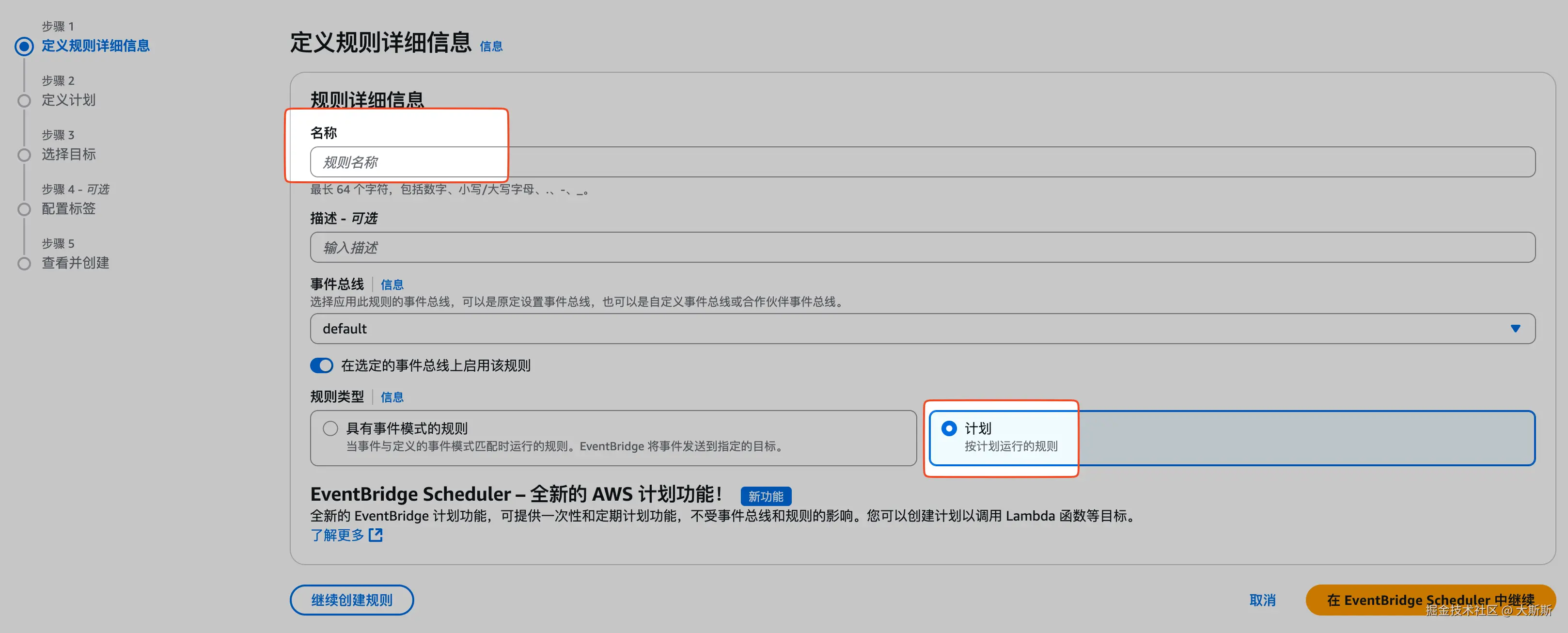
- 导航栏选择 "总线" -> "规则",点击 "创建规则"
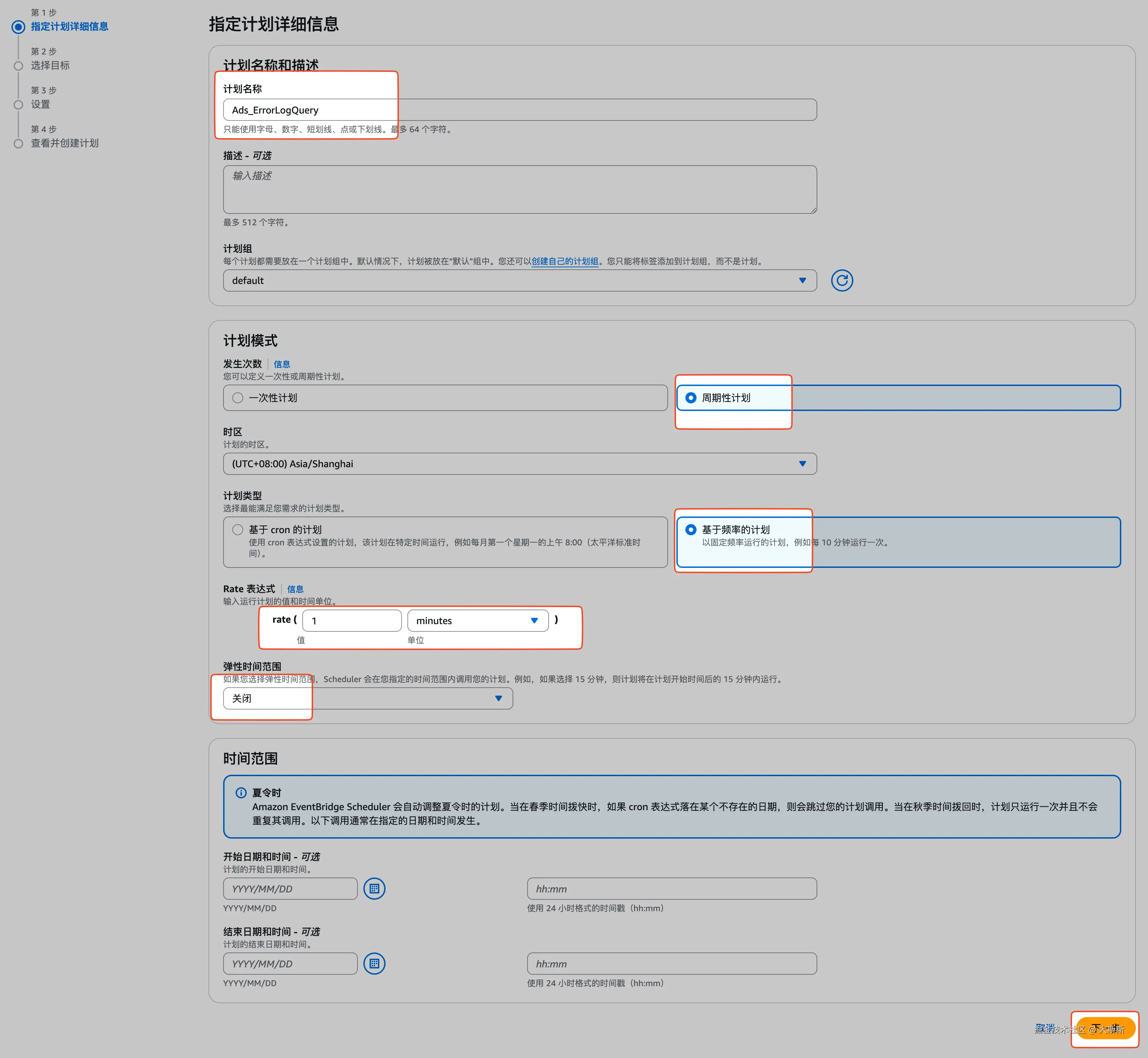
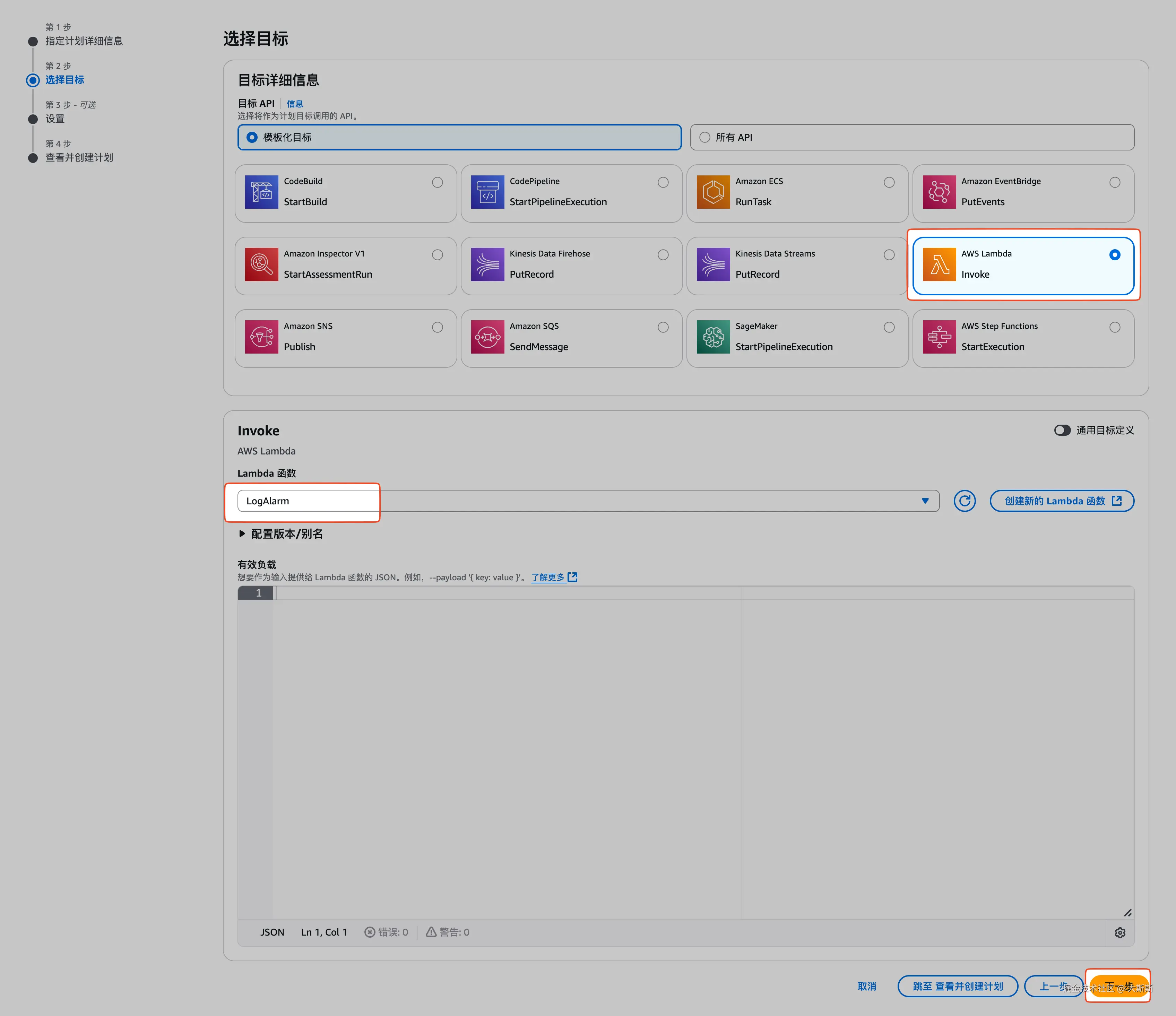
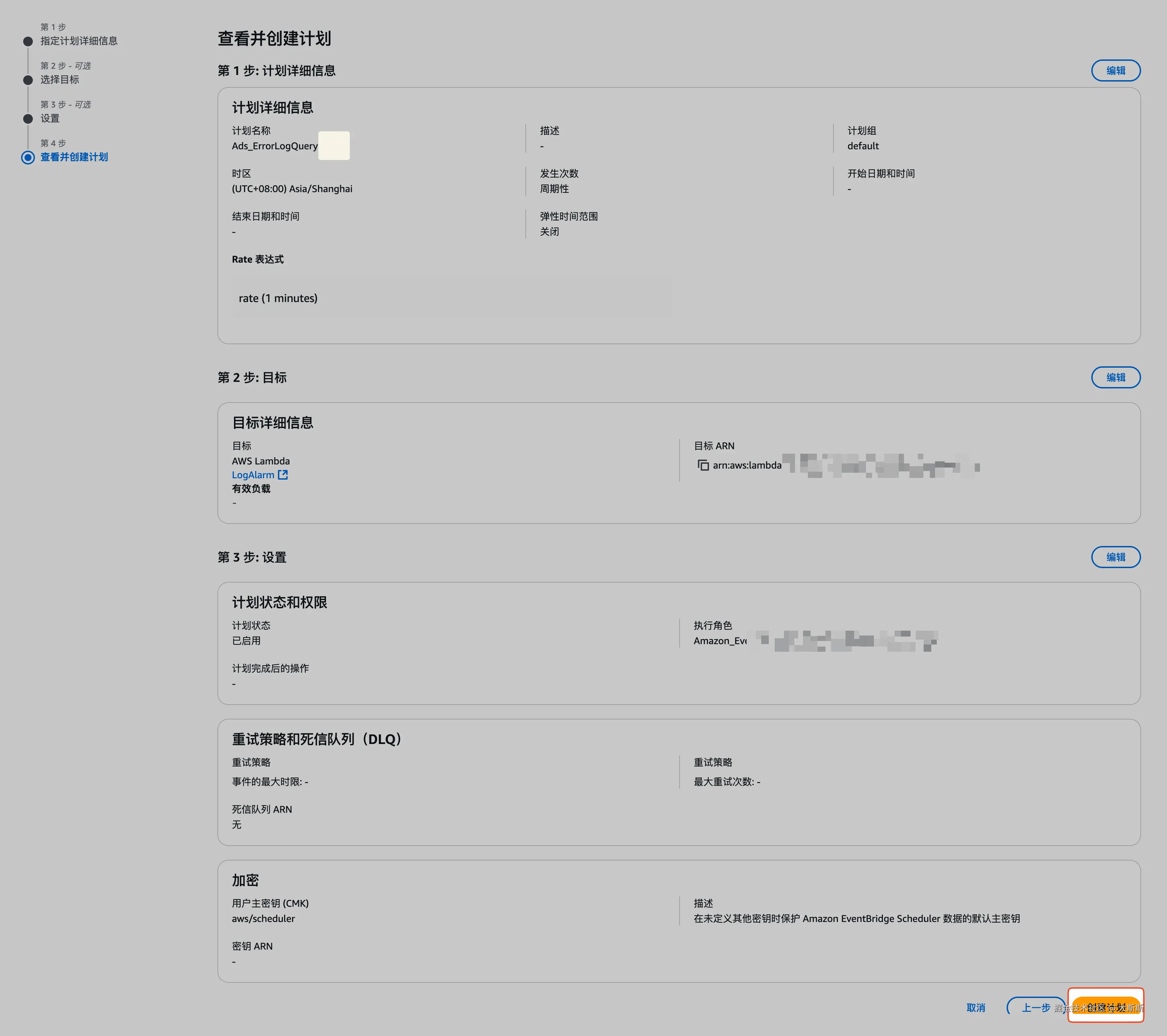
- 通过步骤条配置规则【这里配置为每分钟执行一次,目标为之前创建的 Lambda 函数
LogAlarm】
三、日志查询
可在 CloudWatch 的 Log Insights 中查询日志(类似阿里云的 SLS)。
步骤如下:
- 登录 CloudWatch 控制台
- 导航栏 "日志" -> "Log Insights"
- 选择日志组
ads
附录
Lambda 查询日志并推送 SNS 函数源码
python
# -*- coding: utf-8 -*-
import os
import json
import time
import math
import logging
from datetime import datetime, timezone
from typing import List, Dict, Any, Optional
import boto3
from botocore.config import Config
from urllib import request as urlrequest
from urllib.error import URLError, HTTPError
# ---------- 配置 ----------
logger = logging.getLogger()
logger.setLevel(logging.INFO)
AWS_CONFIG = Config(
retries={"max_attempts": 5, "mode": "standard"},
read_timeout=15,
connect_timeout=5,
)
logs = boto3.client("logs", config=AWS_CONFIG)
sns = boto3.client("sns", config=AWS_CONFIG)
# ---------- 环境变量 ----------
LOG_GROUP = os.environ.get("LOG_GROUP", "").strip() # 必填
QUERY = os.environ.get("QUERY", "").strip() # 可选(留空则使用默认查询,适配你的日志格式)
WINDOW_SECONDS = int(os.environ.get("WINDOW_SECONDS", "60")) # 每次查询的时间窗口(秒)
LIMIT = int(os.environ.get("LIMIT", "50")) # 返回分组上限
MIN_COUNT = int(os.environ.get("MIN_COUNT", "1")) # 仅当分组次数 >= 该阈值才推送
SNS_TOPIC_ARN = os.environ.get("SNS_TOPIC_ARN", "").strip() # 可选
# 可选:自定义告警标题前缀
ALERT_TITLE = os.environ.get("ALERT_TITLE", "CloudWatch Logs Insights 告警").strip()
# ---------- 默认查询(与你的日志格式匹配) ----------
# 日志样式:
# [2025-08-12 11:10:58.302][reqId][traceId][thread][LEVEL][logger][method][line] - msg-{"json":"..."}
DEFAULT_QUERY = f"""
fields @timestamp, @message
| parse @message "[*][*][*][*][*][*][*][*] - *" as ts, reqId, traceId, thread, level, logger, method, line, msg
| filter level = "ERROR"
| stats
count() as hits,
min(@timestamp) as firstSeen,
max(@timestamp) as lastSeen
by logger, method, line, msg, level
| sort firstSeen desc
| limit {LIMIT}
""".strip()
def _ensure_query() -> str:
if LOG_GROUP == "":
raise ValueError("环境变量 LOG_GROUP 不能为空")
q = QUERY if QUERY else DEFAULT_QUERY
# 强制把 limit 调整为环境变量中的 LIMIT(若用户自带 QUERY 可不强制覆盖)
# 这里不硬改用户自带 QUERY,尊重自定义:若需要强制,可在此处做替换。
return q
# ---------- 工具函数 ----------
def _epoch_ms_to_iso8601(ms: int) -> str:
# AWS 返回的 @timestamp 通常是 epoch ms
return datetime.fromtimestamp(ms / 1000.0, tz=timezone.utc).isoformat()
def _poll_query(query_id: str, timeout_seconds: int = 20, poll_interval: float = 1.0) -> Dict[str, Any]:
"""轮询 Logs Insights 直到完成/失败/取消,返回响应结果"""
start = time.time()
while True:
resp = logs.get_query_results(queryId=query_id)
status = resp.get("status")
if status in ("Complete", "Failed", "Cancelled"):
return resp
if time.time() - start > timeout_seconds:
raise TimeoutError(f"Logs Insights 查询超时(>{timeout_seconds}s),queryId={query_id}")
time.sleep(poll_interval)
def _start_insights(log_group: str, query: str, start_time: int, end_time: int, limit: int) -> str:
resp = logs.start_query(
logGroupName=log_group,
startTime=start_time, # epoch seconds
endTime=end_time, # epoch seconds
queryString=query,
limit=limit
)
return resp["queryId"]
def _normalize_results(results: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""把 Logs Insights 的结果统一转为普通 dict 列表。
每一行 results[i]["results"] 是 [{field: 'hits', value: '5'}, ...] 的形式。
"""
rows = []
for row in results:
d = {}
for col in row.get("field", []) if isinstance(row, dict) and "field" in row else []:
# 兼容错误结构(理论上不会命中)
pass
# 正常结构:
for col in row.get("results", row): # 有些 SDK/环境会把层级 flatten
# 标准结构:row 是 dict,含 key "results": [ {field:'x', value:'y'}, ... ]
if isinstance(col, dict) and "field" in col and "value" in col:
d[col["field"]] = col["value"]
if not d and isinstance(row, list):
# 兼容 row 本身就是 list 的情况(每个元素是 {field, value})
for col in row:
if "field" in col and "value" in col:
d[col["field"]] = col["value"]
if d:
rows.append(d)
return rows
def _normalize_results_strict(results: List[Any]) -> List[Dict[str, Any]]:
"""严格解析官方响应(推荐)"""
rows = []
for row in results:
d = {}
for col in row:
d[col["field"]] = col.get("value")
rows.append(d)
return rows
def _format_markdown(groups: List[Dict[str, Any]]) -> str:
"""把聚合结果格式化为 Markdown 文本"""
lines = [f"# 🔥 {ALERT_TITLE}", "", "---", "", f"### 共 {len(groups)} 条预警", "", "---", ""]
for i, g in enumerate(groups, 1):
hits = g.get("hits", "0")
# 处理 firstSeen 时间字段
firstSeen_val = g.get("firstSeen")
if firstSeen_val:
try:
# 尝试作为 epoch 毫秒数处理
firstSeen = _epoch_ms_to_iso8601(int(float(firstSeen_val)))
except ValueError:
# 如果转换失败,可能已经是 ISO 格式字符串,直接使用
firstSeen = str(firstSeen_val)
else:
firstSeen = "-"
# 处理 lastSeen 时间字段
lastSeen_val = g.get("lastSeen")
if lastSeen_val:
try:
# 尝试作为 epoch 毫秒数处理
lastSeen = _epoch_ms_to_iso8601(int(float(lastSeen_val)))
except ValueError:
# 如果转换失败,可能已经是 ISO 格式字符串,直接使用
lastSeen = str(lastSeen_val)
else:
lastSeen = "-"
logger_s = g.get("logger") or "-"
method_s = g.get("method") or "-"
line_s = g.get("line") or "-"
msg_s = g.get("msg") or "-"
level_s = g.get("level") or "-"
# 添加每个错误的详细信息
lines.append(f"### {level_s}(hits = {hits})")
lines.append(f"> **msg**:{msg_s}")
lines.append(f"- **line**:{line_s}")
lines.append(f"- **logger**:{logger_s}")
lines.append(f"- **method**:{method_s}")
lines.append(f"- **firstSeen**:{firstSeen}")
if lastSeen != firstSeen:
lines.append(f"- **lastSeen**:{lastSeen}")
lines.append("")
lines.append("---")
lines.append("")
return "\n".join(lines)
def _send_sns(topic_arn: str, subject: str, message: str) -> None:
if not topic_arn:
return
sns.publish(TopicArn=topic_arn, Subject=subject[:100], Message=message)
def lambda_handler(event, context):
try:
query = _ensure_query()
now = int(time.time())
start_time = now - max(1, WINDOW_SECONDS)
end_time = now
logger.info(f"Running Logs Insights. group={LOG_GROUP}, window={WINDOW_SECONDS}s, limit={LIMIT}")
qid = _start_insights(LOG_GROUP, query, start_time, end_time, LIMIT)
resp = _poll_query(qid, timeout_seconds=min(60, max(15, int(WINDOW_SECONDS * 1.5))), poll_interval=1.0)
status = resp.get("status")
if status != "Complete":
logger.warning(f"Query not complete. status={status}")
return {"status": status, "groups": 0}
logger.info(f"Query complete. status={status}, resp={resp}")
raw_rows = resp.get("results", [])
# 官方结构解析
rows = _normalize_results_strict(resp.get("results", []))
# 过滤计数阈值(hits >= MIN_COUNT)
groups = []
for r in rows:
try:
hits = int(float(r.get("hits", "0")))
except Exception:
hits = 0
if hits >= MIN_COUNT:
groups.append(r)
if not groups:
logger.info("No groups exceed MIN_COUNT. Skip notify.")
return {"status": "ok", "groups": 0}
# 格式化输出(Markdown 文本)
md = _format_markdown(groups)
logger.info(f"Markdown: {md}")
# 推送
if SNS_TOPIC_ARN:
_send_sns(SNS_TOPIC_ARN, ALERT_TITLE, md)
# if WEBHOOK_URL:
# _send_webhook(WEBHOOK_URL, md)
logger.info(f"Notified groups={len(groups)}")
return {"status": "ok", "groups": len(groups)}
except Exception as e:
logger.exception("Lambda failed.")
# 出错也发一条(可选)
err_msg = f"{ALERT_TITLE} 执行失败:{str(e)}"
if SNS_TOPIC_ARN:
_send_sns(SNS_TOPIC_ARN, ALERT_TITLE + "(执行失败)", err_msg)
# 抛出以便可观测
raise