针对 NVIDIA RTX 5070 Ti显卡(带16GB显存)的本地运行环境,目前适合PDF文本推理的模型和工具主要有以下几类:
-
NVIDIA NIM 微服务及基础模型
- NVIDIA 发布了适用于RTX 50 系列 GPU(包括5070 Ti)的 AI 基础模型,涵盖 PDF 提取、多模态理解、语言模型推理等任务。
- 这些模型支持本地 AI 推理,能够从 PDF 中提取文本、图表和图像,便于后续文本推理处理。
- 例如 Mistral-Nemo-12B-Instruct 模型在 NVIDIA NIM 微服务中用于语言理解,结合 NeMoRetriever 微服务用于PDF内容提取。
- 该方案支持 FP4 计算精度,显存和性能优化较好,适合 5070 Ti这样的消费级高性能 GPU。
-
开源智能文档提取工具如 NVIDIA-Ingest
- 英伟达开源的 NVIDIA-Ingest 工具专门用于 PDF 及多种文档格式的结构化提取。
- 该工具基于微服务架构,支持 GPU 加速(在大显存 GPU 上效率更好,但 5070 Ti 的 16GB 显存也是较为合适的),能够高效并行地提取文本、表格、图像等内容。
- 结合 OCR 技术实现复杂文档的文字和内容解析,为后续推理模型提供干净的文本输入。
-
适用模型注意事项
- 超大规模模型(如 Llama 2 70B 等)通常显存需求超过 5070 Ti 显存容量,需量化或分布式推理。
- 5070 Ti 适合运行如 NVIDIA NIM 集成的中等规模模型(12B 参数级别)和专门优化的推理模型。
- 本地运行时推荐结合轻量文本解析工具和专门针对 PDF 文档优化的语言模型推理服务。
1. 最佳模型选择
针对 NVIDIA RTX 5070 Ti 显卡,其 16GB 显存和较强的 AI 推理能力,使其非常适合运行中型规模的文字推理模型。根据最新的测试和评测数据,以下是最适合 5070 Ti 用于文字推理的模型和推荐:
-
Mistral系列模型
- Mistral 模型在 5070 Ti 上表现出色,具备较快的推理速度和较高的输出效率。
- 5070 Ti 运行 Mistral 模型的推理令牌输出速度和响应时间均优于4070 和 5070 非 Ti 版本。
-
Llama 3 和 Llama 2 模型(中型规模,如 7B 到 12B 参数)
- Llama 3 在 5070 Ti 上的测试显示整体推理性能较优,响应更快,特别适合需要快速文本生成和推理的应用。
- Llama 2 虽然参数相对较少,但结合显卡能力,也能达到高效推理体验。
-
Phi 3.5 模型
- Phi 3.5 模型适合轻量级和中级推理任务,5070 Ti 上运行该模型具有较短的令牌生成时间和良好的输出流畅度。
综合上述模型的性能表现,5070 Ti 可以高效运行 Mistral-7B 及其同级别的Llama 3 系列模型,尤其是中小型号版本,这些模型对显存和算力要求适中,非常适合本地文字推理任务。
总结:
- 最适合 RTX 5070 Ti 的文字推理模型为中型规模(7B-12B 参数)的大语言模型,如 Mistral-7B 、Llama 3(7B-13B)和 Phi 3.5 等。
- 这些模型在 5070 Ti 上运行时,能兼顾推理速度和显存容量,提供流畅的本地文本理解和生成体验。
2. Mistral-7B 大概会占用多少显存?
Mistral-7B 模型在不同精度下的显存占用大致如下:
- BF16/半精度(16-bit浮点):约 14GB 显存(刚好)
- FP32/单精度(32-bit浮点):约 28GB 显存(不行)
- INT8量化(8-bit整数):约 7GB 显存 (轻松)
这是根据模型的 70 亿参数规模来估算的,计算方法是参数数量乘以每个参数类型的字节数。推理时,BF16 精度下约需 14GB 显存,这对于具备 16GB 显存的显卡(如RTX 5070 Ti)来说比较适合,可以在本地运行。
需要注意的是,显存使用还会受到额外的缓存和运行环境开销影响,实际使用时可能略高于基础参数显存计算值。
总结:
Mistral-7B 运行推理时,在 BF16 精度下约需 14GB 显存,适合搭载 16GB显存的显卡本地使用。如果使用 INT8 量化,则显存需求更低,约7GB,但性能和准确性可能略有影响。
3. DeepSeek R1-8B 和 mistral 7B 哪个在中文文字推理场景下效果更好?
在中文文字推理场景下,DeepSeek R1-8B和Mistral 7B各有优势,具体表现如下:
- DeepSeek R1-8B
- 参数更多,8B级别模型,推理能力较强,适合复杂任务。
- 使用Mixture of Experts(MoE)架构,推理时只激活部分专家,资源利用更高效。
- 在某些中文基准和推理测试中表现良好,但有报告指出中文环境下偶尔会有简体跳转和某些领域内容屏蔽问题。
- 许可方面使用MIT开源许可,社区应用较广。
- Mistral 7B
- 7B参数中型模型,模型较小但精炼,专注高效推理。
- 在开源社区中表现突出,部分Mistral模型在推理能力上甚至胜过同类更大型模型。
- 法国团队注重高质量数据训练,中文兼容性较好且推理速度较快。
- 其开源许可多为Apache 2.0,适合广泛使用。
- Mistral 7B 在中文理解与推理中被多方评价为具备强劲压缩表现,且对资源友好。
根据社区评测与实际表现,DeepSeek R1-8B适合追求更高推理能力和更复杂推理场景,而Mistral 7B则在资源有限、需要高效且精准中文推理的情况下表现优异。此外,Mistral因开源质量和社区支持,一些中文任务中的表现可能更为稳定。
总结:
- 需要更强推理和复杂中文任务,且硬件资源允许,推荐DeepSeek R1-8B。
- 需要快速响应、显存和计算资源有限且希望兼顾精准度,推荐Mistral 7B。
具体选择应结合你的硬件条件和使用场景。两者都有较好的中文推理能力,但Mistral 7B 在开源社区中文场景使用上更广泛和成熟一些.
4. mistral 7B 测试结果
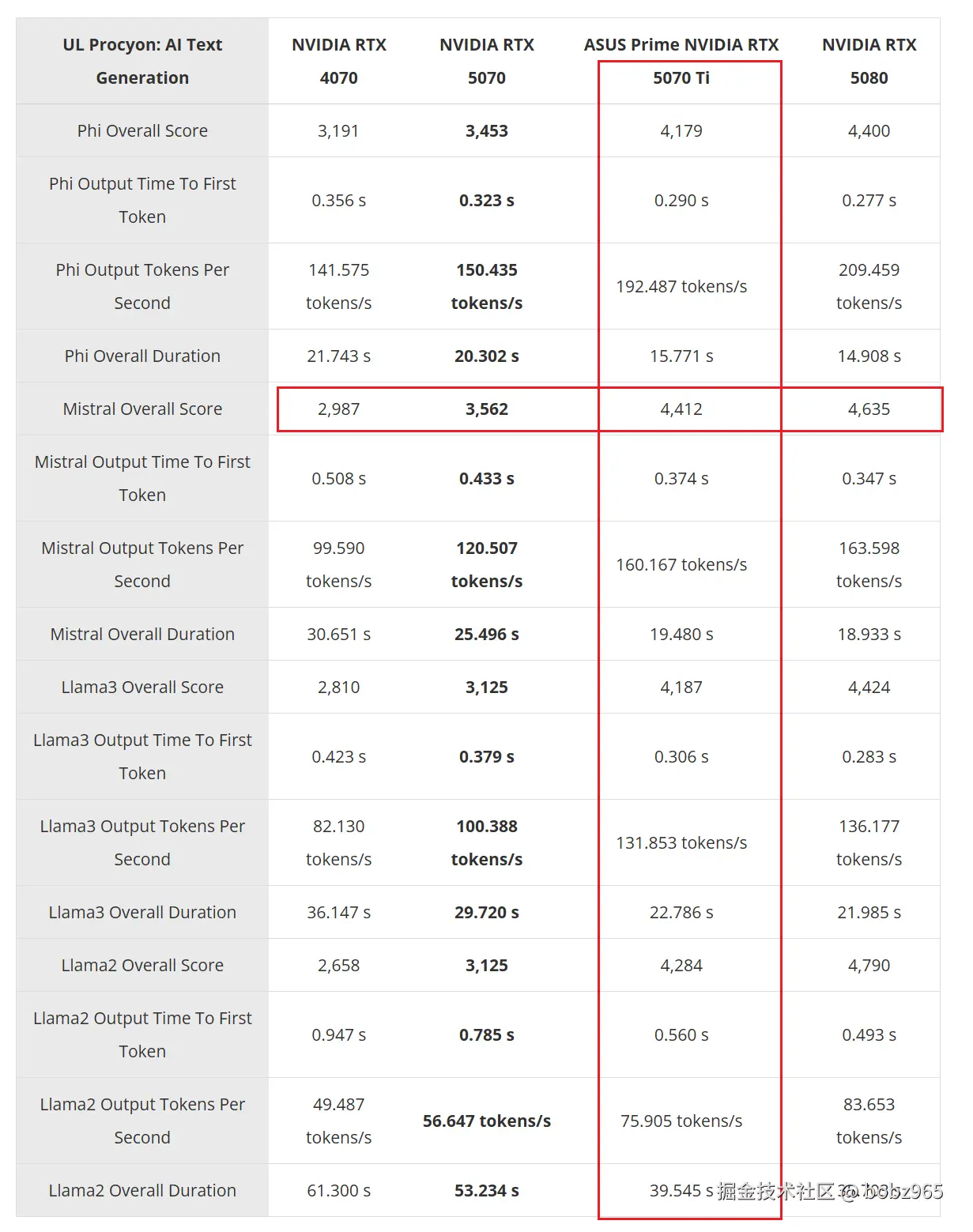
参考
- 模型对比:blog.csdn.net/FansUnion/a...
- 5070 模型测试:www.storagereview.com/zh-TW/revie...