1 DNN原理
DNN(Deep Neural Network,深度神经网络)
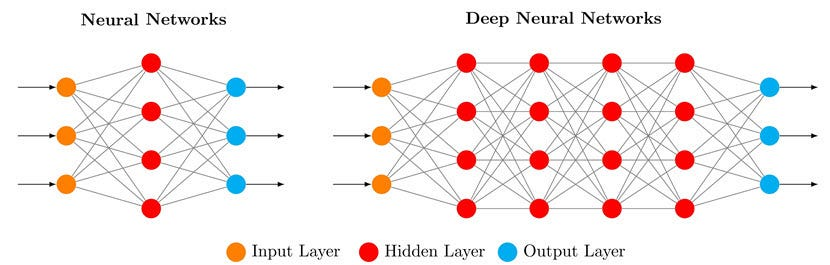
DNN 就是有多层神经元组成的人工神经网络,其中"深度"指的是隐藏层数 ≥ 2(输入层和输出层不算在隐藏层里)。白话就是多层的神经网络就是DNN。。。
深层网络像"多步推理",多层特征变换能提取复杂模式,比如识别猫脸、翻译语言、理解语音。
运算过程:
-
前向传播(Forward Propagation)
数据从输入层开始,一层层计算:
z=Wx+b a=f(z)
这里 W 是权重,b 是偏置,f 是激活函数(如 ReLU、Sigmoid)。
-
损失计算(Loss)
把预测结果和真实标签对比,算出误差(如 MSE、交叉熵)。
-
反向传播(Backpropagation)
用链式法则计算每个权重的梯度,然后调整权重(梯度下降)。
-
重复训练
反复迭代(epochs),直到误差足够小。
2 程序1
MNIST识字:https://colab.research.google.com/github/tinyMLx/colabs/blob/master/2-2-7-ExploringCategorical.ipynb
2.1 代码段1
python
# Load libraries
import sys
import tensorflow as tf
data = tf.keras.datasets.mnist
(training_images, training_labels), (val_images, val_labels) = data.load_data()
training_images = training_images / 255.0
val_images = val_images / 255.0
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(20, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=20, validation_data=(val_images, val_labels))
model.evaluate(val_images, val_labels)
classifications = model.predict(val_images)
print(classifications[0])
print(val_labels[0])这段代码就是标准的训练MNIST的。使用了2层网络,输入是28*28的矩阵,应该是点阵图的大小。两层分别是20个神经元和10个神经元,激活函数分别是relu,softmax。第二层10个是因为输出是0到9,正好10个数字。
bash
Epoch 18/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 6s 3ms/step - accuracy: 0.9706 - loss: 0.0966 - val_accuracy: 0.9577 - val_loss: 0.1577
Epoch 19/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 5s 2ms/step - accuracy: 0.9718 - loss: 0.0933 - val_accuracy: 0.9585 - val_loss: 0.1591
Epoch 20/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 5s 3ms/step - accuracy: 0.9711 - loss: 0.0904 - val_accuracy: 0.9583 - val_loss: 0.1581
<keras.src.callbacks.history.History at 0x7907b6b24bd0>训练了20次,最后的准确率大概是97%。
bash
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.9503 - loss: 0.1891
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step
[2.5914019e-07 1.0987135e-11 1.6813523e-08 3.8598047e-04 3.0853717e-10
1.4766560e-07 1.5491802e-11 9.9957925e-01 3.5518447e-06 3.0758667e-05]
7最后使用验证数据集测试,val_images,准确率大概能达到95%。最后一个数字7也预测出来了。
2.2 代码段2
python
data = tf.keras.datasets.mnist
(training_images, training_labels), (val_images, val_labels) = data.load_data()
training_images = training_images / 255.0
val_images = val_images / 255.0
layer_1 = tf.keras.layers.Dense(20, activation=tf.nn.relu)
layer_2 = tf.keras.layers.Dense(10, activation=tf.nn.softmax)
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28,28)),
layer_1,
layer_2])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=20)
model.evaluate(val_images, val_labels)
classifications = model.predict(val_images)
print(classifications[0])
print(val_labels[0])
print(layer_1.get_weights()[0].size)
print(layer_1.get_weights()[1].size)
print(layer_2.get_weights()[0].size)
print(layer_2.get_weights()[1].size)这个代码和之前的几乎一致,主要是为了查看层的参数。
print(layer_1.get_weights()0.size)第一层的权重(weights)。784x28x28=15680。
print(layer_1.get_weights()1.size) 第一层的偏置,也就是神经元。20,表示有20个神经元。
print(layer_2.get_weights()0.size) 第二层的权重(weights)200。这一层的10个乘以上一层的20个。
print(layer_2.get_weights()1.size) 10。第二层的神经元,10个。
3 程序2
练习:https://colab.research.google.com/github/tinyMLx/colabs/blob/master/2-2-12-AssignmentQuestion.ipynb
3.1 代码段1
bash
# Load libraries
import sys
import tensorflow as tf
# Load in fashion MNIST
mnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
# Define the base model
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
training_images = training_images / 255.0#YOUR CODE HERE#
test_images = test_images / 255.0#YOUR CODE HERE#
# compile the model
model.compile(optimizer = tf.keras.optimizers.Adam(),
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
# fit the model to the training data
model.fit(training_images, training_labels, epochs=5)
# test the model on the test data
model.evaluate(test_images, test_labels)
classifications = model.predict(test_images)
print(classifications[0])这里主要是说的归一。也就是上面的training_images / 255.0,为什么是255?因为图像的每个像素(如 RGB 图像的红、绿、蓝通道)通常用8 位二进制数表示,其取值范围是 0~255。将像素值除以 255 后,所有像素值会被缩放至 0~1 的范围,这就是归一化。
归一化对机器学习的好处暂时不讲吧,有时间讲。。。
bash
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step - accuracy: 0.8793 - loss: 0.3363
[0.33580830693244934, 0.8801000118255615]上面最后算出来准确率大概是88%。
3.2 代码段2
python
NUMBER_OF_NEURONS = 512*2#YOUR_CODE_HERE#
# define the new model
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(NUMBER_OF_NEURONS, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
# compile fit and evaluate the model again
model.compile(optimizer = tf.keras.optimizers.Adam(),
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=5)
model.evaluate(test_images, test_labels)将第二层的网元增加一倍。
bash
Epoch 5/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 19s 10ms/step - accuracy: 0.8944 - loss: 0.2810
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - accuracy: 0.8813 - loss: 0.3263准确率提高了0.1%。。。不是很多。
3.3 代码段3
python
YOUR_NEW_LAYER = tf.keras.layers.Dense(128, activation=tf.nn.relu)#YOUR_CODE_HERE#
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
YOUR_NEW_LAYER,
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
# compile fit and evaluate the model again
model.compile(optimizer = tf.keras.optimizers.Adam(),
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=5)
model.evaluate(test_images, test_labels)再增加了一层。
bash
Epoch 5/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 21s 7ms/step - accuracy: 0.8953 - loss: 0.2775
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - accuracy: 0.8801 - loss: 0.3314提高了不到0.1%,好像也没啥用了。
3.4 代码段4
bash
# get new non-normalized mnist data
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
training_images_non = training_images #YOUR_CODE_HERE#
test_images_non = test_images #YOUR_CODE_HERE#
# re-compile, re-fit and re-evaluate
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
YOUR_NEW_LAYER,
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
model.compile(optimizer = tf.keras.optimizers.Adam(),
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images_non, training_labels, epochs=5)
model.evaluate(test_images_non, test_labels)
classifications = model.predict(test_images_non)使用不归一的数据集。
bash
Epoch 5/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 12s 6ms/step - accuracy: 0.6382 - loss: 0.8791
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - accuracy: 0.6663 - loss: 0.7887
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step准确率暴降到66%,看来还是归一好,得归一啊。
3.5 代码段5
python
# define and instantiate your custom Callback
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if( logs.get('accuracy') > 0.8 ):
self.model.stop_training = True
callbacks = myCallback()
# re-compile, re-fit and re-evaluate
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
model.compile(optimizer = tf.keras.optimizers.Adam(),
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=5, callbacks=[callbacks])就是一个callback,可以设置退出训练的条件,免得无休止训练。这里用了logs.get('accuracy') > 0.8,也就是准确率80%以上就退出,基本上第一轮就结束了。
好了,只用使用看起来也不难,就是多层的神经网络,用Tensorflow还是挺好用的。不过用多少层,每一层用多少神经元,激活函数用什么,这些都还是有讲究。后面再看吧。。。
最后是官方答案:Course | edX