一、项目配置
1.1 确认celery及django版本相对应,本文使用django3.2 、celery5.5
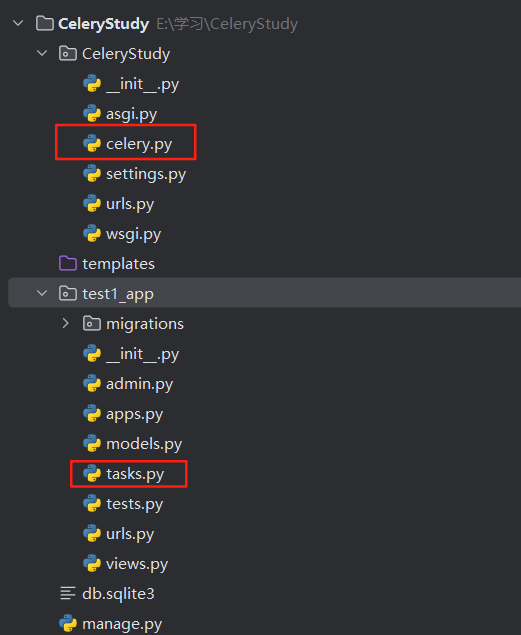
1.2 创建一个名为CeleryStudy 的django 项目,以及一个名为test1_app ,目录结构如下:
1.3 配置celery的setting参数(大部分不需要全局配置,可以针对tasks单独配置)
python
CELERY_BROKER_URL = 'redis://127.0.0.1:6379/0'
CELERY_RESULT_BACKEND = 'django-db' # django-db(使用 Django 数据库存储结果)
CELERY_ACCEPT_CONTENT = ['json'] # 指定 Celery 接受的任务序列化格式(避免反序列化安全问题)。
CELERY_TASK_SERIALIZER = 'json' # 指定任务的序列化方式
CELERY_RESULT_SERIALIZER = 'json' # 指定结果的序列化方式
CELERY_TIMEZONE = TIME_ZONE # 设置 Celery 的时区(影响定时任务的调度时间)
CELERY_BEAT_SCHEDULER = 'django_celery_beat.schedulers:DatabaseScheduler' # 指定定时任务调度器的后端
# 默认内存调度:celery.beat:PersistentScheduler(需配合 beat_schedule_filename)
# Redis 调度:celery.beat:RedisScheduler(需安装 celery-redis-scheduler)
CELERYD_CONCURRENCY = 4 # Worker 并发数(默认 CPU 核心数)
CELERY_BEAT_SCHEDULE = { # 一般在celery.py文件配置
'every-10-seconds': {
'task': 'myapp.tasks.debug',
'schedule': 10.0,
},
}
CELERY_BEAT_MAX_LOOP_INTERVAL = 300 # 秒, Beat 调度器的最大循环间隔(默认 5 分钟)
CELERY_TASK_TIME_LIMIT = 300 # 硬超时 5 分钟(任务被强制终止)
CELERY_TASK_SOFT_TIME_LIMIT = 240 # 软超时 4 分钟(触发 `SoftTimeLimitExceeded`)
CELERY_TASK_DEFAULT_RETRY_DELAY = 60 # 任务重试间隔 1 分钟
CELERY_WORKER_LOG_FORMAT = '%(asctime)s [%(levelname)s] %(message)s' # 自定义 Worker 日志格式
...... # 等等等等等等, 还有一大堆配置1.4 celery全局配置
python
# celery.py
import os
from celery import Celery
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'CeleryStudy.settings') # 其作用是为 Django 提供配置文件的定位信息,确保框架能正确加载项目的各项设置
app = Celery('CeleryStudy') # celery实例,一般命名为项目名称
app.config_from_object('django.conf:settings', namespace='CELERY') # celery实例从setting中CELERY开头的配置获取
app.autodiscover_tasks() # 自动发现并注册项目中定义的tasks,会发现 @shared_task 和 @app.task1.5 修改项目init文件,通过给外部导入
python
# __init__.py
from .celery import app as celery_app
__all__ = ("celery_app",)1.6 在app中新建tasks写入任务逻辑
python
# tasks.py
import time
from celery import shared_task
@shared_task
def test_add(x, y):
time.sleep(2)
return x + y
@shared_task
def pre_task_test(x):
# 定时任务
return x二、异步任务
2.1 普通用法
2.1.1 通过delay
python
# views.py
from django.http import HttpResponse
from .tasks import test_add
# Create your views here.
def test_celery(request):
result = test_add.delay(1, 5)
return HttpResponse(result.task_id + ' : ' + result.status)2.1.2 通过apply_async
python
# countdown: 延迟执行(秒)。
# eta: 指定具体执行时间(datetime)。
# queue: 指定任务队列。
# expires: 任务过期时间。
# retry: 是否启用重试
from datetime import datetime, timedelta
# 延迟 10 秒执行
test_add.apply_async(args=(1, 5), countdown=10)
# 指定具体执行时间
test_add.apply_async(args=(1, 5), eta=datetime.now() + timedelta(minutes=1))
# 指定队列和过期时间
test_add.apply_async(args=(1, 5), queue='priority', expires=3600)2.2 高级用法
通过 signature 对象调用,预生成任务签名(task.s()),用于创建一个可序列化的任务调用对象。它允许你预定义任务及其参数,而无需立即执行,从而支持更灵活的任务组合(如链式调用、组调用等) ,签名对象是可序列化的,可以存储到数据库 或通过网络传递。
python
sig = test_add.s(1, 5) # 创建签名对象
sig.apply_async() # 异步执行
sig.delay() # 等价于 apply_async2.2.1 任务回调(Callback), 在任务成功后触发另一个任务(通过 link 参数)
python
test_add.apply_async(args=(1, 5), link=send_notification.s("Task completed!"))2.2.2 任务链(Chaining),通过 | 符号或 chain() 将多个任务串联,前一个任务的结果作为后一个任务的输入
python
from celery import chain
# 方法1:使用 | 符号
result = (task1.s(1, 2) | task2.s() | task3.s())()
# 方法2:使用 chain()
result = chain(task1.s(1, 2), task2.s(), task3.s())()2.2.3 任务组(Group), 并行执行多个任务,等待所有任务完成
python
from celery import group
result = group(task1.s(i) for i in range(10))() # 并发执行 10 个 task12.2.4 任务和弦(Chord),先并行执行一组任务(group),全部完成后执行一个汇总任务
python
from celery import chord
result = chord((task1.s(i) for i in range(10)), task2.s())() # 10 个 task1 完成后执行 task2三、定时任务
在celery文件中添加定时任务路由表
python
# celery.py
app.conf.beat_schedule = {
'task-name': { # 任务名称(自定义)
'task': 'myapp.tasks.my_task', # 任务函数路径(需可导入)
'schedule': 30, # 执行时间规则(固定间隔)
# 或 'schedule': crontab(minute='*/5'), # Cron 表达式
'args': (16, 16), # 传递给任务的参数(可选)
'options': {'queue': 'priority'}, # 其他选项(如指定队列)
},
# 可定义多个任务
}通过安装pip install django-celery-beat可以实现在admin后台动态修改定时任务配置
python
INSTALLED_APPS = [
...,
'django_celery_beat',
]
# 替换 Celery 的调度器
CELERY_BEAT_SCHEDULER = 'django_celery_beat.schedulers:DatabaseScheduler'配置完记得迁移数据库 python manage.py migrate
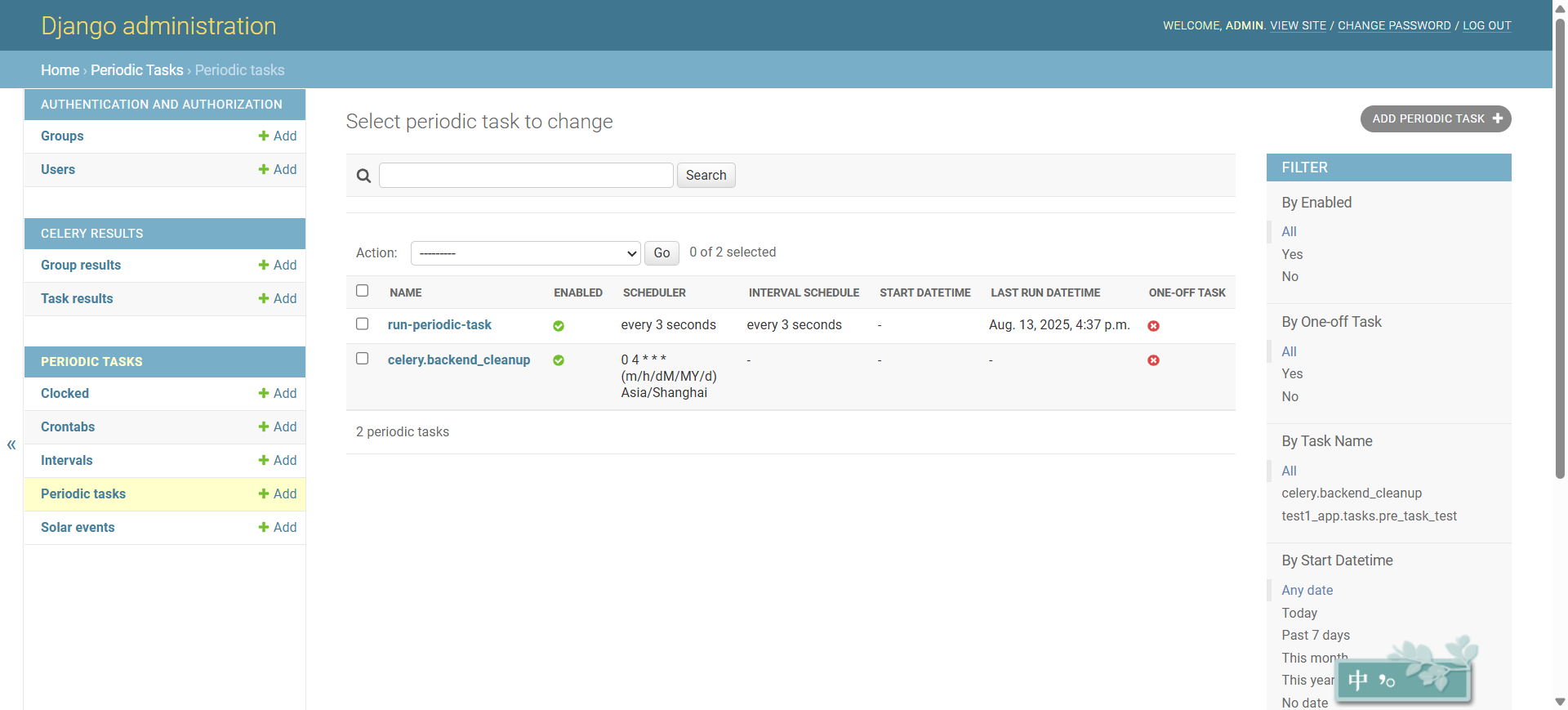
启动celery beat
worker = 干活的(执行任务)。
beat = 发任务的(定时生成任务)。
协作关系:beat 是"计划部门",worker是"执行部门",两者通过 Broker(消息队列)解耦。
生产建议:分开启动,Worker 可横向扩展,Beat 保持单例
python
# 启动 Worker(处理任务)
celery -A CeleryStudy worker -l info
celery -A CeleryStudy worker -l info -P eventlet # windows环境下命令
"""
prefork 是 Celery 在 Linux 上的默认并发模型,它使用多进程(Multiprocessing)处理任务,
适合 CPU 密集型场景。但 Windows 系统不支持 fork() 系统调用,因此无法使用 prefork 池。
在 Windows 上尝试使用 prefork 会直接报错,导致 Worker 无法启动。
eventlet 是一个基于协程(Coroutine)的并发库,通过绿色线程(Green Thread)实现高并发,
适合 I/O 密集型任务(如 Celery 的异步任务场景)。
在 Windows 上,eventlet 是少数可用的高性能并发池之一。
它通过非阻塞 I/O 和协程调度,避免了线程切换的开销,同时绕过了 GIL 的限制,
能显著提升任务处理效率
"""
# 启动 Beat(调度任务)
celery -A CeleryStudy beat -l info
# 合并启动
celery -A CeleryStudy worker --beat -l info
