本来想找ai方面的实习,发现他们实习的内容主要是抓取数据和自动化测试。下面是实习面试的考查作业用的Playwright进行抓取小红书数据和京东自动化测试。防止反爬用了请求头伪装和行为模拟来应对。
Playwright 是由 Microsoft 开发的一个现代化的、跨浏览器的 自动化测试工具 ,用于 Web 应用程序的 端到端测试(E2E Testing) 。它支持使用 JavaScript/TypeScript、Python、C# 和 Java 编写自动化脚本,能够控制 Chrome、Firefox、WebKit(Safari)等主流浏览器。
安装步骤可以去B站里搜索,很简单。
bash
# 安装 Playwright
pip install playwright
# 安装浏览器驱动(Chromium, Firefox, WebKit)如果已经有了,可以忽略
playwright install
# 运行脚本
python your_script.py题目一:模拟购物浏览流程(可见 Chrome)
使用 Playwright(或等效技术),在 可见浏览器(非无头) 中完成以下任务:
- 打开任意一个购物网站(如京东、天猫、亚马逊等)。
- 搜索一个指定品类(例如"蓝牙耳机")。
- 找到并点击一个指定品牌的商品(例如"Sony")。
- 在商品详情页向下滚动浏览若干秒(模拟人类操作)。
- 点击"加入购物车"。
- 返回搜索结果页并继续浏览。
要求:
- 必须在可见的 Chrome 中运行。
- 操作过程需有适当延时、鼠标轨迹、滚动等人类化动作。
- 保留运行日志和关键截图(例如搜索页、商品页、购物车状态)。
导入的包
arduino
from playwright.sync_api import sync_playwright, expect
import time
import os
import random配置
#
LOGIN_STATE_FILE = "storage_state.json"
SCREENSHOT_DIR = "screenshots"
MAX_RETRIES = 3storage_state.json登录验证需要用到,第二个是配置截图放的路径。
os.makedirs(SCREENSHOT_DIR,
def log(msg):
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] {msg}")
def random_delay(min_sec=1, max_sec=3):
time.sleep(random.uniform(min_sec, max_sec))
def move_mouse_naturally(page, x, y):
start_x, start_y = 0, 0
steps = 10
for i in range(1, steps + 1):
ratio = i / steps
ease_ratio = 3 * ratio**2 - 2 * ratio**3
current_x = int(start_x + (x - start_x) * ease_ratio)
current_y = int(start_y + (y - start_y) * ease_ratio)
page.mouse.move(current_x, current_y)
time.sleep(random.uniform(0.05, 0.15))
page.mouse.move(x, y)
def get_visible_text(locator):
"""安全提取可见文本内容"""
try:
elements = locator.element_handles()
return "".join([e.text_content().strip() for e in elements]).lower()
except:
return ""
def simulate_shopping():
with sync_playwright() as p:
log("启动浏览器...")
browser = p.chromium.launch(
channel="chrome",
headless=False,
slow_mo=50,
args=[
"--start-maximized",
"--disable-blink-features=AutomationControlled",
"--disable-infobars",
"--no-sandbox",
"--disable-dev-shm-usage",
"--disable-web-security",
"--allow-running-insecure-content",
"--disable-features=IsolateOrigins,site-per-process",
"--disable-site-isolation-trials",
"--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36"
],
ignore_default_args=["--enable-automation"]
)
context = browser.new_context(
viewport={"width": 1920, "height": 1080},
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36",
java_script_enabled=True,
storage_state=LOGIN_STATE_FILE if os.path.exists(LOGIN_STATE_FILE) else None
)这里定义了一些日志,随机数,滑动界面。
下面就是自动化测试流程
page
# 隐藏自动化特征
page.add_init_script("""
() => {
Object.defineProperty(navigator, 'webdriver', { get: () => false });
window.chrome = { runtime: {}, loadTimes: () => {}, csi: () => {} };
Object.defineProperty(navigator, 'languages', { get: () => ['zh-CN', 'zh', 'en'] });
Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3, 4, 5] });
callPhantom = undefined; _phantom = undefined; __nightmare = undefined;
const originalQuery = window.navigator.permissions.query;
window.navigator.permissions.query = (parameters) => (
parameters.name === 'notifications' ?
Promise.resolve({ state: 'denied' }) :
originalQuery(parameters)
);
}
""")
page.set_default_timeout(30000)
try:
# =============== 1. 打开首页 ===============
log("正在打开京东首页...")
page.goto("https://www.jd.com", wait_until="networkidle")
page.bring_to_front()
log(f"当前页面: {page.url} | 标题: {page.title()}")
page.screenshot(path=os.path.join(SCREENSHOT_DIR, "1_homepage.png"))
if "risk" in page.url or "validate" in page.url:
log("⚠️ 检测到风控,请手动完成验证...")
input("✅ 完成验证后按回车继续...")
move_mouse_naturally(page, 200, 300)
random_delay(1, 2)
# =============== 2. 搜索商品 ===============
log("正在搜索 '蓝牙耳机Sony'...")
search_box = page.locator('input#key').first
expect(search_box).to_be_visible(timeout=10000)
search_box.fill("")
search_box.type("蓝牙耳机Sony", delay=100)
log("关键词输入完成")
search_btn = page.locator('button:has-text("搜索"), #searchBtn').first
search_btn.click()
log("搜索按钮已点击")
try:
with page.expect_navigation(timeout=15000):
pass
log(f"✅ 页面跳转完成: {page.url}")
except:
log("⚠️ 未检测到跳转,等待异步加载...")
page.wait_for_load_state("networkidle")
# =============== 3. 等待商品列表加载 ===============
log("等待商品列表加载...")
page.wait_for_selector('div.plugin_goodsCardWrapper[data-sku]', state='visible', timeout=30000)
log("✅ 搜索结果加载成功")
page.screenshot(path=os.path.join(SCREENSHOT_DIR, "2_search_results.png"))
# =============== 4. 查找并点击商品(适配新版京东) ===============
log("正在查找 Sony 商品...")
product_card = None
product_url = None
for attempt in range(MAX_RETRIES):
log(f"第 {attempt + 1} 次尝试查找商品...")
cards = page.locator('div.plugin_goodsCardWrapper[data-sku]')
if cards.count() == 0:
log("⚠️ 未找到任何商品卡片,刷新重试...")
page.reload()
random_delay(3, 5)
continue
found = False
for i in range(min(20, cards.count())):
card = cards.nth(i)
if not card.is_visible():
continue
# 提取标题文本(兼容高亮 font 标签)
title_elem = card.locator('.goods_title_container_1x4i2, ._text_1x4i2_30')
if title_elem.count() == 0:
continue
title = get_visible_text(title_elem)
if not title:
continue
# 判断是否为 Sony 耳机
if ("sony" in title or "索尼" in title) and ("耳机" in title or "耳塞" in title or "耳麦" in title):
log(f"✅ 匹配到目标商品: '{title}'")
product_card = card
sku = card.get_attribute("data-sku")
if sku:
product_url = f"https://item.jd.com/{sku}.html"
found = True
break
if found:
break
else:
log("未找到目标商品,刷新重试...")
page.reload()
random_delay(3, 5)
if not product_card:
raise Exception("❌ 未找到 Sony 蓝牙耳机商品卡片")
# =============== 5. 点击进入商品详情页(点击卡片) ===============
log("正在点击商品卡片...")
box = product_card.bounding_box()
if box:
move_mouse_naturally(page, box["x"] + 50, box["y"] + 50)
product_card.scroll_into_view_if_needed()
random_delay(0.5, 1)
product_card.hover()
random_delay(0.3, 0.8)
log(f"准备跳转商品页: {product_url}")
try:
with page.expect_popup(timeout=10000) as popup_info:
product_card.click()
detail_page = popup_info.value
except:
# 备用:直接跳转 URL
page.goto(product_url, wait_until="networkidle")
detail_page = page
detail_page.bring_to_front()
detail_page.wait_for_load_state("networkidle")
log(f"✅ 成功进入商品详情页: {detail_page.url}")
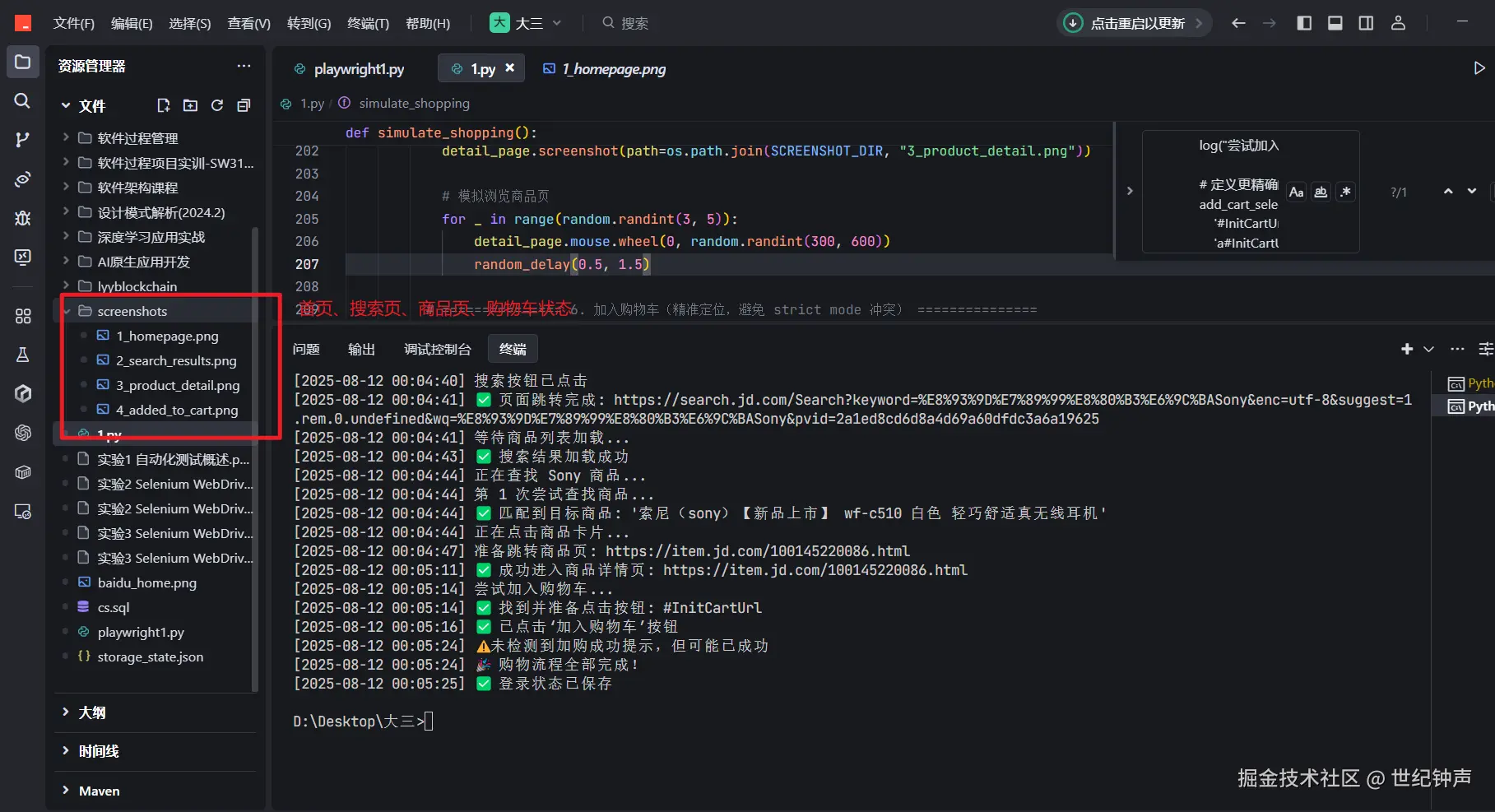
detail_page.screenshot(path=os.path.join(SCREENSHOT_DIR, "3_product_detail.png"))
# 模拟浏览商品页
for _ in range(random.randint(3, 5)):
detail_page.mouse.wheel(0, random.randint(300, 600))
random_delay(0.5, 1.5)
# =============== 6. 加入购物车(精准定位,避免 strict mode 冲突) ===============
log("尝试加入购物车...")
# 定义更精确的选择器,优先使用 id 和可见性
add_cart_selectors = [
'#InitCartUrl', # ✅ 最佳选择:唯一 ID,且是实际生效按钮
'a#InitCartUrl:visible', # 显式要求可见
'a.btn-special1.btn-lg[href*="cart.jd.com"][onclick*="加入购物车"]', # 属性组合定位
'a:has-text("加入购物车"):visible >> nth=0', # 只取第一个可见的
'a:has-text("加入购物车"):not([style*="display: none"])', # 排除隐藏元素
]
added = False
for sel in add_cart_selectors:
try:
btn = detail_page.locator(sel)
count = btn.count()
if count == 0:
log(f"⚠️ 选择器未找到元素: {sel}")
continue
# 只取第一个可见的
target_btn = None
for i in range(count):
b = btn.nth(i)
if b.is_visible():
target_btn = b
break
if not target_btn:
log(f"⚠️ 选择器元素均不可见: {sel}")
continue
log(f"✅ 找到并准备点击按钮: {sel}")
target_btn.scroll_into_view_if_needed()
random_delay(0.5, 1.0)
target_btn.hover()
random_delay(0.3, 0.6)
# 使用 force=True 避免被遮挡或动画影响
target_btn.click(force=True)
log("✅ 已点击'加入购物车'按钮")
break # 成功点击后跳出
except Exception as e:
log(f"❌ 尝试选择器 '{sel}' 失败: {str(e)}")
continue
else:
raise Exception("❌ 所有加购按钮尝试均失败")
# =============== 7. 等待加购成功提示 ===============
try:
success = detail_page.wait_for_selector(
"text=添加成功 >> visible=true || "
"text=已加入购物车 >> visible=true || "
"text=成功添加 >> visible=true",
timeout=8000
)
if success:
log("✅ 商品已成功加入购物车")
added = True
except Exception as e:
log("⚠️ 未检测到加购成功提示,但可能已成功")
added = True # 保守认为成功
if not added:
raise Exception("❌ 加购未确认成功")
detail_page.screenshot(path=os.path.join(SCREENSHOT_DIR, "4_added_to_cart.png"))
log("🎉 购物流程全部完成!")
except Exception as e:
log(f"❌ 执行失败: {str(e)}")
page.screenshot(path=os.path.join(SCREENSHOT_DIR, f"error_{int(time.time())}.png"))
input("按回车关闭浏览器...")
finally:
# 保存登录状态
try:
if page.locator('text="我的京东"').is_visible(timeout=5000):
context.storage_state(path=LOGIN_STATE_FILE)
log("✅ 登录状态已保存")
except:
log("⚠️ 无法保存登录状态")
time.sleep(2)
context.close()
browser.close()
if __name__ == "__main__":
simulate_shopping()注意事项
京东页面结构随时可能发生改变,相应该代码需要改变。上面是无头浏览器里面运行的。如果需要的是普通浏览器,则需要下列改变
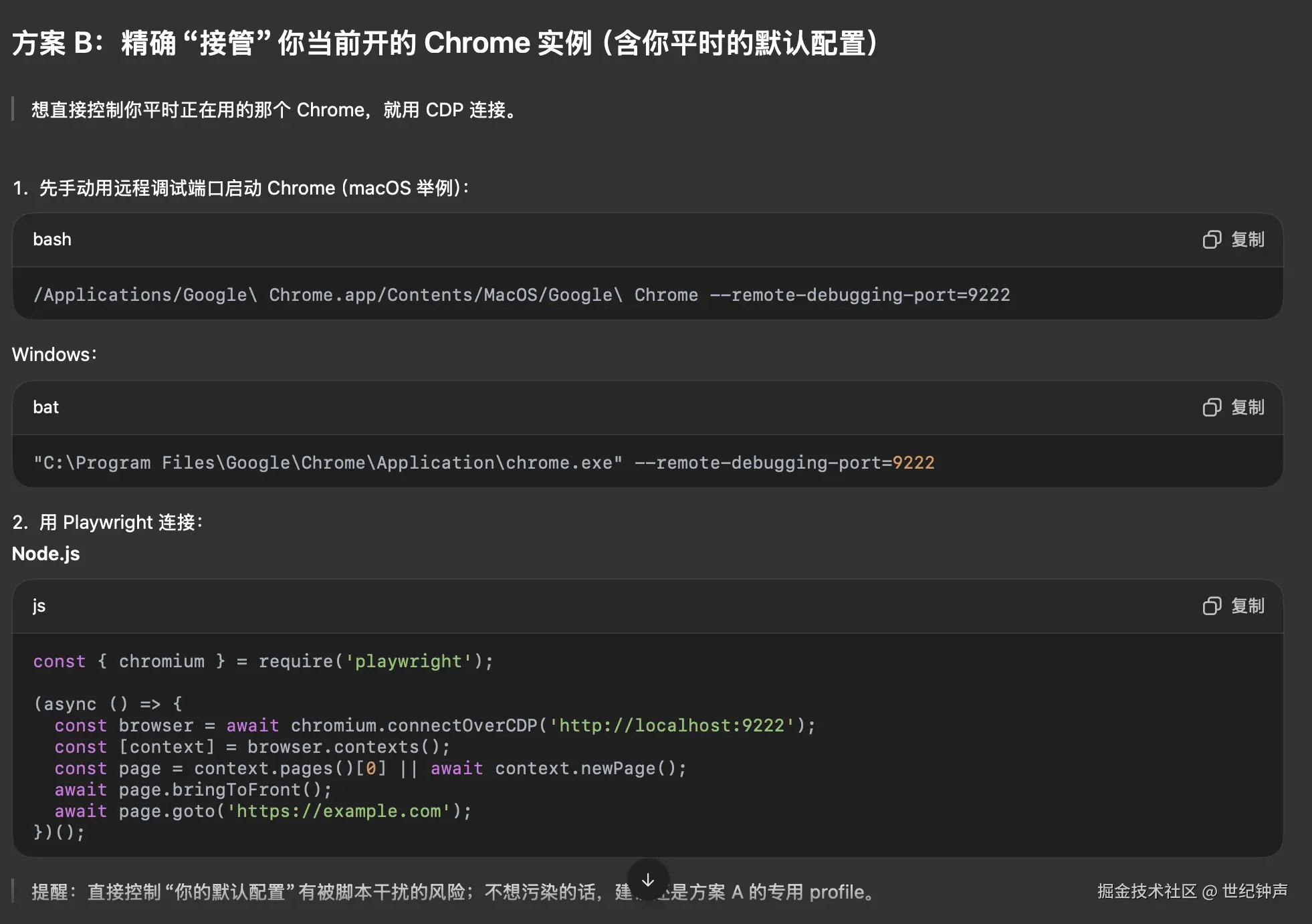
代码示例
from
from pathlib import Path
with sync_playwright() as p:
user_data_dir = str(Path(__file__).parent / "my-chrome-profile")
context = p.chromium.launch_persistent_context(
user_data_dir,
headless=False,
channel="chrome",
slow_mo=50
)
page = context.new_page()
page.goto("https://example.com")运行结果:
题目二:网站数据采集并入库
实现一个脚本,完成以下任务:
- 打开一个指定网站(例如小红书的某个公开页面,或任意可访问的公开数据网站)。
- 抓取页面中的数据(如标题、作者、点赞数等)。
- 通过 HTTP POST 请求 将数据发送到一个数据库接口(接口地址和字段格式可自行定义,也可用 Mock 服务如 webhook.site)。
要求:
- 需能正确提取至少 5 条数据。
- 数据格式为 JSON,字段清晰可读。
- 代码中需体现 HTTP 请求发送过程(可用 axios、fetch、requests 等)。
- 需要在 README 中说明运行步骤。
实现步骤
-
安装依赖
bashpip install playwright requests -
查看结果
- 抓取的数据会保存在
data/目录下的JSON文件中 - 截图会保存在
screenshots/目录 - 控制台会输出数据发送状态
- 抓取的数据会保存在
数据格式示例
json
[
{
"title": "夏日穿搭分享 | 一周穿搭不重样",
"author": "时尚达人",
"likes": 2458,
"cover_url": "https://ci.xiaohongshu.com/xxx.jpg",
"url": "https://www.xiaohongshu.com/explore/xxx",
"platform": "xiaohongshu",
"timestamp": "2023-07-20T15:30:45.123456"
},
...
]代码如下
python
from playwright.sync_api import sync_playwright
import requests
import json
import time
import random
from datetime import datetime
import os
# ==================== 配置 ====================
TARGET_URL = "https://www.xiaohongshu.com/explore"
WEBHOOK_URL = "https://webhook.site/YOUR-UNIQUE-URL"
SCREENSHOT_DIR = "screenshots"
DATA_DIR = "data"
MAX_POSTS = 10
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
DEBUG_PORT = 9222
os.makedirs(SCREENSHOT_DIR, exist_ok=True)
os.makedirs(DATA_DIR, exist_ok=True)
def log(msg):
print(f"[{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}] {msg}")
def random_delay(min_sec=1, max_sec=3):
time.sleep(random.uniform(min_sec, max_sec))
def save_data(data):
"""保存数据到本地JSON文件"""
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = os.path.join(DATA_DIR, f"xiaohongshu_data_{timestamp}.json")
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
log(f"数据已保存到 {filename}")
def send_to_api(data):
"""通过HTTP POST发送数据到API接口"""
headers = {
"Content-Type": "application/json",
"User-Agent": USER_AGENT
}
try:
response = requests.post(
WEBHOOK_URL,
data=json.dumps(data, ensure_ascii=False),
headers=headers,
timeout=10
)
log(f"API响应状态码: {response.status_code}")
return response.status_code == 200
except Exception as e:
log(f"发送数据到API失败: {str(e)}")
return False
def scrape_xiaohongshu():
with sync_playwright() as p:
try:
# =============== 1. 浏览器连接 ===============
log(f"正在连接到Chrome调试端口 {DEBUG_PORT}...")
browser = p.chromium.connect_over_cdp(f"http://localhost:{DEBUG_PORT}")
# 获取或创建上下文
context = browser.contexts[0] if browser.contexts else browser.new_context(
viewport={"width": 1920, "height": 1080},
user_agent=USER_AGENT,
locale="zh-CN"
)
# 创建新页面
page = context.new_page()
page.set_default_timeout(60000)
page.bring_to_front()
# 增强反检测
context.add_init_script("""
Object.defineProperty(navigator, 'webdriver', { get: () => false });
window.navigator.chrome = { runtime: {}, app: {} };
Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3] });
Object.defineProperty(navigator, 'languages', { get: () => ['zh-CN', 'zh'] });
""")
# =============== 2. 页面加载策略 ===============
log(f"正在打开小红书页面: {TARGET_URL}")
# 策略1: 先快速加载DOM
page.goto(TARGET_URL, wait_until="domcontentloaded", timeout=30000)
# 策略2: 检查是否有验证码
if page.locator('text=验证码').is_visible(timeout=5000):
log("⚠️ 检测到验证码,请手动完成验证...")
input("✅ 完成验证后按回车继续...")
page.wait_for_load_state("networkidle")
# 策略3: 确保主要内容加载
page.wait_for_selector('.feeds-container', state="attached", timeout=30000)
page.screenshot(path=os.path.join(SCREENSHOT_DIR, "1_homepage.png"))
log(f"页面加载成功: {page.title()}")
# =============== 3. 数据提取优化 ===============
log("模拟人类滚动行为...")
for _ in range(random.randint(2, 4)):
page.mouse.wheel(0, random.randint(500, 1000))
random_delay(1.5, 3)
# =============== 3. 数据提取优化 ===============
log("开始提取笔记数据...")
# 使用更稳定的父级选择器
notes = page.locator('section.note-item[data-v-a264b01a]').all()
log(f"找到 {len(notes)} 条笔记")
collected_data = []
for i, note in enumerate(notes[:MAX_POSTS]):
try:
# 1. 先滚动到元素位置并等待
note.scroll_into_view_if_needed()
random_delay(1.5, 2.5) # 适当增加延迟
# 2. 提取标题 - 使用属性选择器增强稳定性
title = note.locator('[data-v-51ec0135][data-v-a264b01a]:visible').first.inner_text(
timeout=8000).strip() or "无标题"
# 3. 提取作者 - 使用class和属性组合
author = note.locator('.author .name[data-v-a264b01a]:visible').first.inner_text(
timeout=5000).strip() or "匿名用户"
# 4. 提取点赞数 - 使用最新的class结构
try:
likes = note.locator('.like-wrapper .count[selected-disabled-search]:visible').first.inner_text(
timeout=5000) or "0"
likes = ''.join(filter(str.isdigit, likes)) or "0"
except:
likes = "0"
log(f"笔记 {i+1} 点赞数提取失败,使用默认值0")
# 5. 提取封面图 - 使用精确的class组合
cover = note.locator('.cover.mask.ld img:visible').first.get_attribute(
"src", timeout=5000) or ""
# 6. 提取笔记链接 - 使用精确的class组合
try:
link = note.locator('a.cover.mask.ld:visible').first.get_attribute(
"href", timeout=5000) or ""
if link and not link.startswith('http'):
link = f"https://www.xiaohongshu.com{link}"
except:
link = ""
log(f"笔记 {i+1} 链接提取失败")
note_data = {
"title": title,
"author": author,
"likes": int(likes),
"cover_url": cover,
"url": link,
"platform": "xiaohongshu",
"collected_at": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
log(f"成功提取笔记 {i+1}: {title[:20]}... (点赞: {likes})")
collected_data.append(note_data)
# 每条笔记后随机延迟
random_delay(2, 4) # 增加延迟防止频率过高
except Exception as e:
log(f"提取第 {i+1} 条笔记时严重出错: {str(e)}")
continue
# =============== 4. 数据保存与发送 ===============
if collected_data:
save_data(collected_data)
if send_to_api(collected_data):
log(f"✅ 成功发送 {len(collected_data)} 条数据")
else:
log("❌ 数据发送失败")
else:
log("⚠️ 未提取到有效数据")
page.screenshot(path=os.path.join(SCREENSHOT_DIR, "2_final_page.png"))
log("🎉 抓取任务完成!")
except Exception as e:
log(f"❌ 发生严重错误: {str(e)}")
if 'page' in locals():
page.screenshot(path=os.path.join(SCREENSHOT_DIR, f"error_{int(time.time())}.png"))
finally:
if 'browser' in locals():
browser.close()
log("浏览器已关闭")
if __name__ == "__main__":
log("=== 小红书数据抓取程序开始 ===")
scrape_xiaohongshu()
log("=== 程序执行结束 ===")注意事项
- 我的默认登录了 ,设的时间短。所以第一次扫码可能会超时,需要重新运行,或者自己改一下超时时间
- 截图放的位置自己需要改一下