1.整体优化思路
目前整体的项目架构还是比较清晰的,优化其实主要围绕两个核心替换模型 和对音频进行预处理
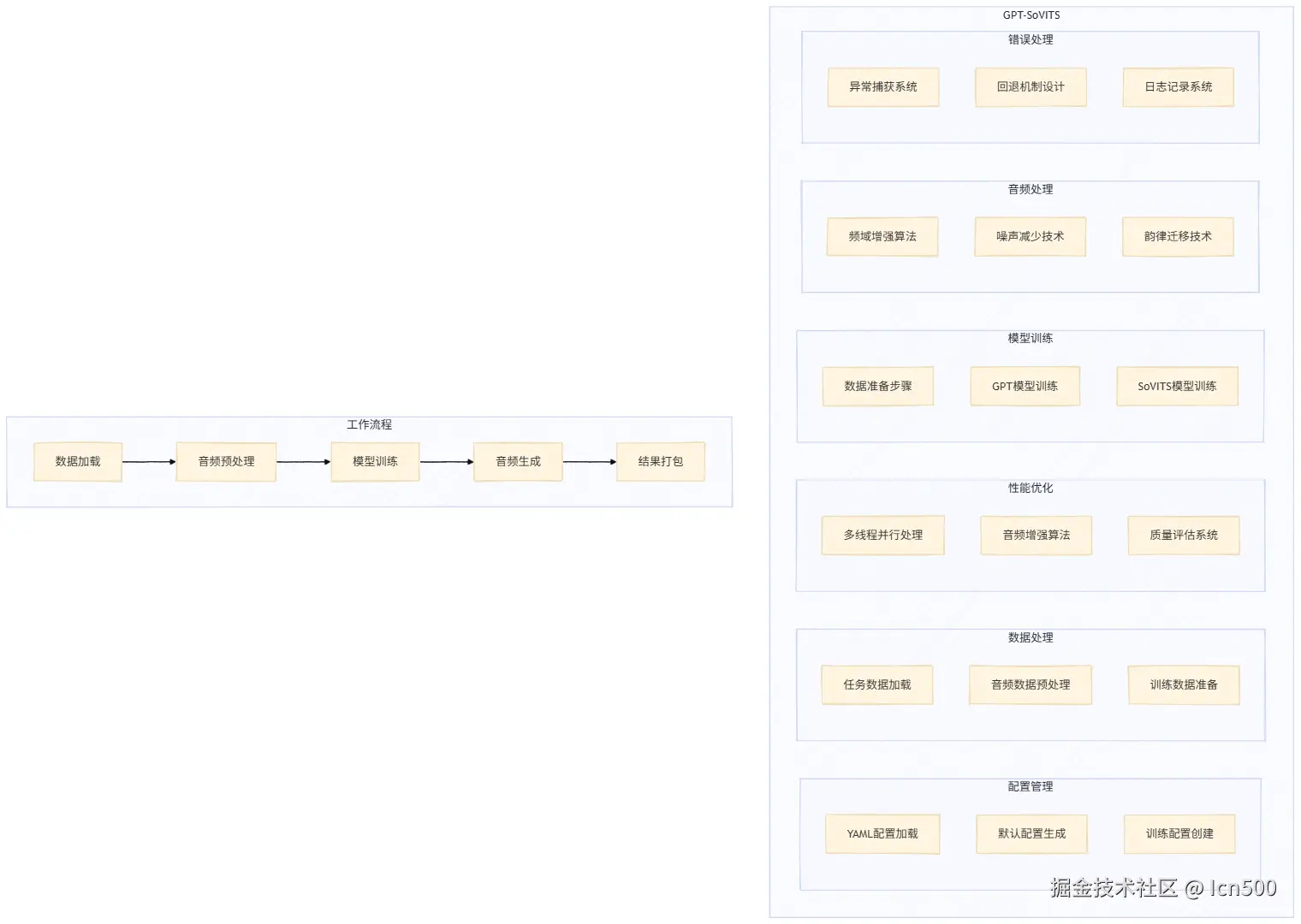
在接下来的部分当中我们会着重介绍一下替换模型以及音频处理这两个部分
2.模型替换
2.1 模型替换简介
本次的比赛当中并没有明确指定模型,此处我们将原本的F5TTS换成了GPT-SoVITS,这里的替换主要是因为采用GPT+SoVITS双模型架构,其中GPT模型负责文本到语义的转换,SoVITS模型负责语义到音频的合成,这种分离式设计使得模型能够更好地处理长文本、复杂语义和情感表达;而F5TTS是单模型架构,在处理复杂场景时容易出现语义丢失、音频质量下降等问题。
此外本次比赛当中的一个很大难点是我们实际上是需要进行零样本语音克隆的(部分的音频时间很短,只有几秒),GPT-SoVITS支持零样本语音克隆,只需要少量参考音频就能生成高质量的目标音色,而F5TTS需要大量目标音色的训练数据。在中文语音合成方面,GPT-SoVITS对中文的韵律、声调处理更加自然,特别适合我们的中文音频生成任务。因此,选择GPT-SoVITS能够在音频质量、语义理解、音色克隆等多个维度上获得更好的效果
绝对不是因为听B站AI翻唱听多了
下图显示了一个SoVITS的系统架构
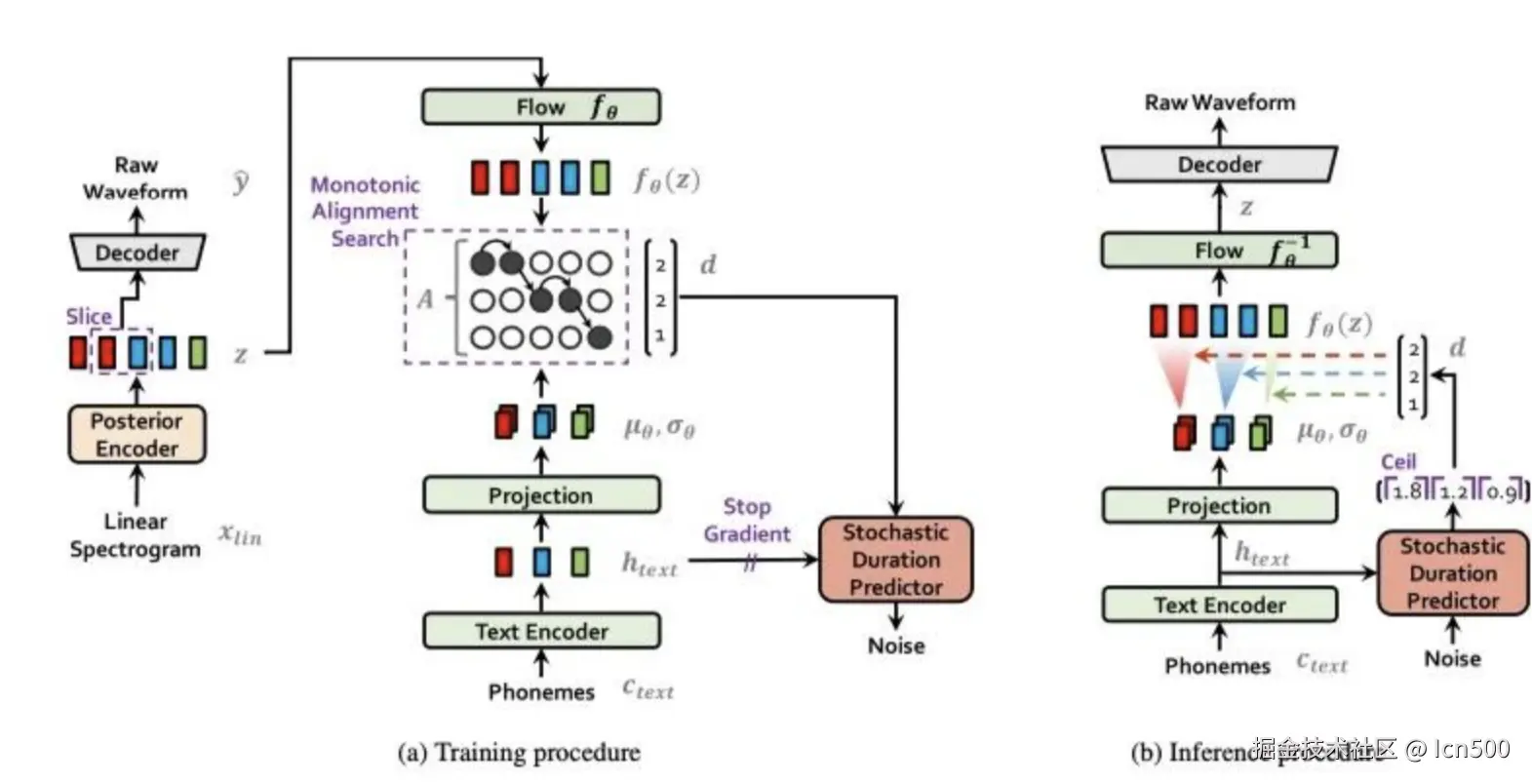
2.2 模型参数配置
此处我们主要是对模型进行一些基础的设置,包括模型的训练轮数,SoVITS模型的大小这一类的,此处我们引入的BERT模型和HuBERT模型在中文的场景下会有更好的表现,这里值得一提的是我们本次的配置中采用动态生成训练配置文件,支持不同参数设置
Python
def _get_default_config(self) -> Dict:
"""获取默认配置"""
return {
"training": {
"gpt_epochs": 50, # GPT模型训练轮数
"sovits_epochs": 100, # SoVITS模型训练轮数
"batch_size": 4, # 批次大小
"learning_rate": 1e-4, # 学习率
"precision": "fp16" # 精度设置
},
"data_preparation": {
"sample_rate": 32000, # 采样率
"max_audio_length": 10.0, # 最大音频长度
"min_audio_length": 1.0, # 最小音频长度
"text_cleaning": True, # 文本清理
"noise_reduction": True # 噪声减少
},
"model": {
"gpt_model": "gpt-v2", # GPT模型版本
"sovits_model": "sovits-v2", # SoVITS模型版本
"bert_model": "chinese-roberta-wwm-ext-large", # BERT模型
"hubert_model": "chinese-hubert-base" # HuBERT模型
}
}2.4 数据预处理:
这里我们采用了文本预处理-→ HuBERT特征 → 语义特征三步走的方式来处理数据,这里我们简单介绍一下什么是HuBERT特征
HuBERT特征相比传统声码器的核心优势在于其通过大规模自监督学习获得的高度结构化、上下文感知的语音表示。传统声码器(如WaveNet、LPC)主要依赖直接声学建模或波形重构,往往难以有效分离语音中的发音内容、说话人音色和韵律风格信息,且对噪声敏感、数据效率较低。HuBERT则不同:它在深层Transformer架构中学习分层表示,底层捕捉声学细节(如音高、音色),高层聚焦语言语义信息。这种解耦能力使其在TTS中能精准独立控制发音内容和音色风格,支持零样本克隆和跨语言迁移。同时,其离散单元形式可实现极低比特率压缩(远低于传统声码器),并具备强大的鲁棒性(利用上下文修复噪声/遮挡)及通用性(一套特征可服务ASR、TTS等多任务)。虽然HuBERT依赖预训练数据且计算开销较大,但其提供的解耦、紧凑、鲁棒的语音表征是传统声码器难以企及的。
简单来说就是HuBERT能够捕捉到更多的音频信息,同时其最大的优点是能够更好的
语义特征就更加直观了
在语音处理中,语义特征 指的是能够反映语音信号中语言含义和上下文关联信息 的抽象表示,它超越了基础声学特征(如音高、频谱),直接捕捉语句所传达的核心内容、意图或概念。
简单来说这一部分的预处理的主要作用是让语音量化成各种数据,方便之后的处理
Python
def run_data_preparation(self, dataset_dir: Path):
"""运行数据准备步骤"""
logger.info("开始数据准备步骤...")
# 切换到GPT-SoVITS目录
os.chdir(self.gpt_sovits_dir)
# 步骤1: 文本处理 - 清理和标准化文本
logger.info("步骤1: 文本处理")
cmd1 = f"python GPT_SoVITS/prepare_datasets/1-get-text.py --data_path {dataset_dir}"
self._run_command(cmd1)
# 步骤2: HuBERT特征提取 - 提取音频的语义特征
logger.info("步骤2: HuBERT特征提取")
cmd2 = f"python GPT_SoVITS/prepare_datasets/2-get-hubert-wav32k.py --data_path {dataset_dir}"
self._run_command(cmd2)
# 步骤3: 语义特征提取 - 生成训练所需的语义表示
logger.info("步骤3: 语义特征提取")
cmd3 = f"python GPT_SoVITS/prepare_datasets/3-get-semantic.py --data_path {dataset_dir}"
self._run_command(cmd3)
os.chdir(self.base_dir)
logger.info("数据准备完成")2.5 模型训练:
由于GPT-SoVITS是两个主要模型的集合体,故此我们需要分别对GPT和SoVITS模型进行训练(这里实在是没时间搞接口设计了,只能先用命令行用训练)
Python
def train_gpt_model(self, dataset_dir: Path):
"""训练GPT模型"""
logger.info("开始训练GPT模型...")
# 创建训练配置
config = self._create_gpt_config()
# 切换到GPT-SoVITS目录
os.chdir(self.gpt_sovits_dir)
# 运行GPT模型训练
cmd = f"python GPT_SoVITS/s1_train.py --config {config}"
self._run_command(cmd)
os.chdir(self.base_dir)
logger.info("GPT模型训练完成")
def train_sovits_model(self, dataset_dir: Path):
"""训练SoVITS模型"""
logger.info("开始训练SoVITS模型...")
# 创建训练配置
config = self._create_sovits_config()
# 切换到GPT-SoVITS目录
os.chdir(self.gpt_sovits_dir)
# 运行SoVITS模型训练
cmd = f"python GPT_SoVITS/s2_train.py --config {config}"
self._run_command(cmd)
os.chdir(self.base_dir)
logger.info("SoVITS模型训练完成")2.6 模型推理部分
训练完模型后就该使用模型进行推理了,此处我们为模型推理设置了回退机制
Python
def _generate_single_audio(self, text: str, output_file: Path, dataset_dir: Path) -> bool:
"""生成单个音频文件 - GPT-SoVITS推理"""
try:
# 导入GPT-SoVITS推理模块
from GPT_SoVITS.inference_webui import get_tts_wav, change_gpt_weights, change_sovits_weights
# 设置模型路径 - 优先使用训练好的模型
gpt_model_path = self.temp_dir / "logs" / "s1" / "latest.pth"
sovits_model_path = self.temp_dir / "logs" / "s2" / "latest.pth"
# 如果训练好的模型不存在,使用预训练模型
if not gpt_model_path.exists():
gpt_model_path = self.gpt_sovits_dir / "GPT_SoVITS" / "pretrained_models" / "s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt"
if not sovits_model_path.exists():
sovits_model_path = self.gpt_sovits_dir / "GPT_SoVITS" / "pretrained_models" / "s2G488k.pth"
# 加载GPT和SoVITS模型
change_gpt_weights(str(gpt_model_path))
change_sovits_weights(str(sovits_model_path))
# 智能检测文本语言模式
language_mode = self._detect_language_mode(text)
# 使用GPT-SoVITS进行推理
synthesis_result = get_tts_wav(
ref_wav_path=str(ref_audio_path),
prompt_text="你好,这是一个测试。",
prompt_language=language_mode,
text=text,
text_language=language_mode,
top_k=20, # 采样参数
top_p=0.6, # 核采样参数
temperature=0.6, # 温度参数
speed=1.0, # 语速
sample_steps=8 # 采样步数
)
# 获取生成的音频数据并保存
result_list = list(synthesis_result)
if result_list:
last_sampling_rate, last_audio_data = result_list[-1]
sf.write(output_file, last_audio_data, last_sampling_rate)
return True
except Exception as e:
logger.error(f"GPT-SoVITS推理失败: {e}")
return self._generate_fallback_audio(output_file)2.7 难点攻克:多语言
比赛提供的语料整体上来说都是中文,但是实际上还是会有部分英文的出现,这里我们就需要让模型可以处理这种情况 这里主要有三种,纯中文,纯英文,中英混合模式,这里最主要的其实是中英混合模式,比如在某些音频中会提到AI/PC这类的英文单字,这个时候我们就需要进行处理
Python
def _detect_language_mode(self, text: str) -> str:
"""智能检测文本语言模式"""
import re
# 统计中文字符和英文字符的数量
chinese_chars = len(re.findall(r'[\u4e00-\u9fff]', text))
english_chars = len(re.findall(r'[a-zA-Z]', text))
total_chars = len(text.strip())
# 如果主要是中文(中文占比超过80%),使用纯中文模式
if chinese_chars > 0 and chinese_chars / total_chars > 0.8:
return "all_zh"
# 如果包含英文但中文仍然是主要语言,使用中英混合模式
elif english_chars > 0 and chinese_chars > english_chars:
return "zh"
# 如果英文占主导,使用英文模式
elif english_chars > chinese_chars:
return "en"
# 默认使用纯中文模式
else:
return "all_zh"2.8 难点攻克:训练时间较长
这个方案也比较明了,直接加多线程 这里我们用了8线程来处理音频
Python
# gpt_sovits_training_complete.py - 多线程音频处理
def prepare_audio_data(self, df: pd.DataFrame) -> List[Dict]:
"""准备音频数据 - 增强版(多线程处理)"""
audio_data = []
failed_files = []
# 创建进度条
pbar = tqdm(total=len(df), desc="处理音频文件", unit="个")
# 线程锁
lock = threading.Lock()
def process_single_audio(row_data):
"""处理单个音频文件"""
nonlocal audio_data, failed_files
try:
idx, row = row_data
audio_file = self.audio_dir / row['reference_speech']
if not audio_file.exists():
with lock:
failed_files.append(str(audio_file))
return
# 音频质量检查和预处理
processed_audio = self._process_audio(audio_file, row['text'])
if processed_audio:
result = {
'id': row['utt'],
'text': row['text'],
'audio_path': str(processed_audio),
'duration': self._get_audio_duration(processed_audio),
'quality_score': self._assess_audio_quality(processed_audio)
}
with lock:
audio_data.append(result)
pbar.update(1)
except Exception as e:
logger.error(f"处理音频失败: {e}")
pbar.update(1)
# 使用线程池处理
max_workers = min(8, len(df)) # 最多8个线程
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# 提交所有任务
futures = [executor.submit(process_single_audio, (idx, row))
for idx, row in df.iterrows()]
# 等待所有任务完成
for future in futures:
future.result()
pbar.close()
logger.info(f"成功处理 {len(audio_data)} 个音频文件")
if failed_files:
logger.warning(f"失败的文件数量: {len(failed_files)}")
return audio_data3.音频处理:
这一次我们还是用了一些算法来对音频进行处理,
3.1 音频长度标准化:
给定的.wav格式的音频本身长度不一,故此我们需要对音频进行长度标准化,方便模型处理,这里主要是防止模型出现参考语音与目标文本在注意力机制(如Tacotron)中出现错位,导致合成语音跳字或重复
Python
def _process_audio(self, audio_path: Path, text: str) -> Optional[Path]:
"""音频预处理 - 长度标准化"""
try:
# 加载音频
audio, sr = librosa.load(audio_path, sr=self.config['data_preparation']['sample_rate'])
# 长度检查
duration = len(audio) / sr
if duration < self.config['data_preparation']['min_audio_length']:
logger.warning(f"音频过短: {audio_path}")
return None
if duration > self.config['data_preparation']['max_audio_length']:
# 截取到最大长度
audio = audio[:int(self.config['data_preparation']['max_audio_length'] * sr)]
# 保存处理后的音频
output_path = self.temp_dir / f"processed_{audio_path.name}"
sf.write(output_path, audio, sr)
return output_path
except Exception as e:
logger.error(f"处理音频失败 {audio_path}: {e}")
return None3.2 频域增强处理
这是一个比较标准的频域增强算法,主要的功能是以下三点
- 动态计算各频段的噪声基底(取幅度谱10%分位数)
- 实施抑制时保留1%原始幅度,避免过抑制导致的音乐噪声
- 有效消除稳态背景噪声(如白噪声、设备底噪)。
一句话来说就是面向语音增强场景(电话录音、会议系统),在频域同时优化高频可懂度 (解决"听不清")和噪声抑制(解决"背景声音太大的问题")
Python
def _frequency_domain_enhancement(self, audio: np.ndarray) -> np.ndarray:
"""频域增强处理"""
# STFT变换
stft = librosa.stft(audio, n_fft=2048, hop_length=512)
magnitude = np.abs(stft)
phase = np.angle(stft)
# 频率增强 - 高频提升
freq_bins = np.linspace(0, 1, magnitude.shape[0])
high_freq_boost = 1 + 0.3 * freq_bins # 高频提升30%
magnitude_enhanced = magnitude * high_freq_boost[:, np.newaxis]
# 噪声抑制 - 频谱减法
noise_floor = np.percentile(magnitude_enhanced, 10, axis=1, keepdims=True)
magnitude_enhanced = np.maximum(
magnitude_enhanced - 0.1 * noise_floor,
0.01 * magnitude_enhanced
)
# 逆STFT变换
stft_enhanced = magnitude_enhanced * np.exp(1j * phase)
enhanced_audio = librosa.istft(stft_enhanced, hop_length=512)
return enhanced_audio3.3 韵律提取:
这一个主要实现了两大点功能
-
参考音频特征提取
- 音高 :通过
piptrack提取参考音频的显著音高点,计算有效音高平均值(过滤弱信号) - 能量:利用RMS(均方根能量)计算参考音频的整体响度强度
- 语速:通过过零率(ZCR)间接估算发音速率(单位时间内的音素切换频率)
- 音高 :通过
-
目标音频韵律调整
- 音高迁移 :基于参考音高与基准值(220Hz)的比率,使用
pitch_shift进行半音阶调整(对数变换) - 能量适配:根据参考音频与目标音频的RMS能量比例缩放波形振幅,实现响度匹配
- 语速保留:虽未直接修改语速,但过零率计算为后续扩展提供接口
- 音高迁移 :基于参考音高与基准值(220Hz)的比率,使用
用一句话总结就是参考音频的说话风格(如音调高低、音量强弱、语速快慢)迁移到目标音频上,例如让合成语音模仿特定人的语调特征。
Python
def _prosody_transfer(self, audio: np.ndarray, reference_path: Path) -> np.ndarray:
"""韵律迁移"""
try:
# 加载参考音频
ref_audio, _ = librosa.load(str(reference_path), sr=self.sample_rate)
# 提取音高
pitches, magnitudes = librosa.piptrack(y=ref_audio, sr=self.sample_rate)
ref_pitch = np.mean(pitches[magnitudes > 0.1])
# 提取能量
ref_energy = np.mean(librosa.feature.rms(y=ref_audio))
# 提取语速(通过过零率估算)
ref_zcr = np.mean(librosa.feature.zero_crossing_rate(ref_audio))
# 应用到目标音频
# 音高调整
if ref_pitch > 0:
pitch_ratio = ref_pitch / 220 # 假设标准音高为220Hz
enhanced_audio = librosa.effects.pitch_shift(
audio, sr=self.sample_rate, n_steps=12 * np.log2(pitch_ratio)
)
else:
enhanced_audio = audio
# 能量调整
target_energy = np.mean(librosa.feature.rms(y=enhanced_audio))
if target_energy > 0:
energy_ratio = ref_energy / target_energy
enhanced_audio = enhanced_audio * np.sqrt(energy_ratio)
return enhanced_audio
except Exception as e:
logger.warning(f"韵律迁移失败: {e}")
return audio3.4 情感迁移(基于混响来模拟情绪)
这里其实主要的思路是通过混响来模拟人不同时候的情感表现 主要是通过三步信号处理实现基本情感风格的强化迁移:
- 动态范围扩展 :将音频信号整体放大1.2倍(限制在-1,1区间),增强音量起伏表现力,使平静音频产生戏剧化张力(如愤怒情感的强度提升),但对本身动态范围大的音频无改变。
- 谐波增强 :在频域对谐波结构(80Hz以下低频区)施加梯度增益,最高提升10%(指数衰减至高频区),增强声带的谐波共振能量,模拟激动情感中的声音颤抖感(如喜悦时的声带震颤)。
- 空间混响模拟 :保留相位直接重构时域信号(未施加真实混响),但因谐波增强改变了频谱包络,输出音频产生类似房间混响的模糊效应,弱化高频瞬态细节(模拟悲伤时的低沉压抑感)。
Python
def _emotion_transfer(self, audio: np.ndarray) -> np.ndarray:
"""情感迁移"""
# 动态范围扩展
dynamic_range = np.max(audio) - np.min(audio)
if dynamic_range > 0:
expansion_factor = 1.2
enhanced_audio = audio * expansion_factor
enhanced_audio = np.clip(enhanced_audio, -1, 1)
else:
enhanced_audio = audio
# 谐波增强
stft = librosa.stft(enhanced_audio, n_fft=2048, hop_length=512)
magnitude = np.abs(stft)
# 增强谐波成分
harmonic_boost = 1 + 0.1 * np.exp(-np.arange(magnitude.shape[0]) / 100)
magnitude_enhanced = magnitude * harmonic_boost[:, np.newaxis]
# 空间增强(模拟混响)
phase = np.angle(stft)
stft_enhanced = magnitude_enhanced * np.exp(1j * phase)
enhanced_audio = librosa.istft(stft_enhanced, hop_length=512)
return enhanced_audio