
开源vs闭源AI工具大比较:成本、性能、生态的全方位对比
🌟 Hello,我是摘星! 🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。 🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。 🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。 🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
摘要
作为一名在AI领域深耕多年的技术从业者,我见证了开源与闭源AI工具的激烈竞争与共同发展。在这个AI技术日新月异的时代,选择合适的工具栈已经成为决定项目成败的关键因素。开源AI工具以其透明性、可定制性和社区驱动的创新模式,吸引了大量开发者和企业的关注;而闭源AI工具则凭借其稳定性、专业支持和开箱即用的特性,在商业应用中占据重要地位。
在我的实际项目经验中,我发现许多团队在选择AI工具时往往陷入两难境地:是选择成本相对较低但需要更多技术投入的开源方案,还是选择功能完善但成本较高的闭源产品?这个问题没有标准答案,因为它涉及到成本控制、性能要求、团队技术能力、业务场景等多个维度的考量。
通过对比分析Hugging Face、TensorFlow等开源平台与OpenAI API、Google Cloud AI等闭源服务,我发现两者各有优势:开源工具在模型透明度、定制化能力和长期成本控制方面表现突出,特别适合有技术实力的团队进行深度优化;闭源工具则在稳定性、易用性和企业级支持方面更胜一筹,能够快速满足商业化需求。
本文将从成本结构、性能表现、生态建设三个核心维度,深入剖析开源与闭源AI工具的差异,并结合实际案例分析不同场景下的最优选择策略,帮助技术决策者做出更明智的判断。
1. AI工具选择的战略意义
1.1 技术选型的重要性
在AI项目的技术选型中,开源与闭源工具的选择往往决定了项目的发展轨迹。这不仅仅是一个技术问题,更是一个涉及成本控制、风险管理、团队能力建设的战略决策。
python
# AI工具选型评估框架
class AIToolEvaluator:
def __init__(self):
self.criteria = {
'cost': 0.3, # 成本权重
'performance': 0.4, # 性能权重
'ecosystem': 0.3 # 生态权重
}
def evaluate_tool(self, tool_metrics):
"""
评估AI工具的综合得分
tool_metrics: 包含各项指标的字典
"""
total_score = 0
for criterion, weight in self.criteria.items():
if criterion in tool_metrics:
total_score += tool_metrics[criterion] * weight
return {
'total_score': total_score,
'recommendation': self._get_recommendation(total_score),
'risk_level': self._assess_risk(tool_metrics)
}
def _get_recommendation(self, score):
if score >= 8.0:
return "强烈推荐"
elif score >= 6.0:
return "推荐"
elif score >= 4.0:
return "谨慎考虑"
else:
return "不推荐"
def _assess_risk(self, metrics):
# 基于供应商依赖、技术复杂度等因素评估风险
vendor_dependency = metrics.get('vendor_dependency', 5)
technical_complexity = metrics.get('technical_complexity', 5)
risk_score = (vendor_dependency + technical_complexity) / 2
if risk_score <= 3:
return "低风险"
elif risk_score <= 7:
return "中等风险"
else:
return "高风险"
# 使用示例
evaluator = AIToolEvaluator()
# 开源工具评估
open_source_metrics = {
'cost': 8.5, # 成本优势明显
'performance': 7.0, # 性能良好但需优化
'ecosystem': 8.0, # 社区生态丰富
'vendor_dependency': 2, # 供应商依赖低
'technical_complexity': 8 # 技术复杂度高
}
# 闭源工具评估
closed_source_metrics = {
'cost': 5.0, # 成本较高
'performance': 9.0, # 性能优秀
'ecosystem': 7.5, # 生态相对封闭但完善
'vendor_dependency': 8, # 供应商依赖高
'technical_complexity': 3 # 技术复杂度低
}
open_result = evaluator.evaluate_tool(open_source_metrics)
closed_result = evaluator.evaluate_tool(closed_source_metrics)
print(f"开源工具评估结果: {open_result}")
print(f"闭源工具评估结果: {closed_result}")这个评估框架帮助我们量化分析不同工具的优劣势。开源工具在成本和生态方面表现突出,但技术复杂度较高;闭源工具在性能和易用性方面更胜一筹,但存在供应商依赖风险。
1.2 市场趋势分析
图1:AI工具市场份额趋势图 - 折线图 - 展示开源与闭源工具市场占有率的变化趋势
从市场趋势来看,开源AI工具的市场份额正在快速增长,这反映了技术社区对透明性和可控性的追求。
2. 成本维度深度对比
2.1 直接成本分析
成本是企业选择AI工具时最关心的因素之一。让我们通过具体的成本模型来分析两者的差异:
python
import numpy as np
import matplotlib.pyplot as plt
from dataclasses import dataclass
from typing import Dict, List
@dataclass
class CostModel:
"""AI工具成本模型"""
initial_cost: float # 初始成本
monthly_cost: float # 月度运营成本
scaling_factor: float # 扩展成本系数
maintenance_cost: float # 维护成本
training_cost: float # 培训成本
class CostCalculator:
def __init__(self):
# 开源工具成本模型
self.open_source = CostModel(
initial_cost=50000, # 初期开发投入
monthly_cost=5000, # 基础设施成本
scaling_factor=0.8, # 扩展成本较低
maintenance_cost=15000, # 维护成本较高
training_cost=30000 # 团队培训成本
)
# 闭源工具成本模型
self.closed_source = CostModel(
initial_cost=10000, # 初期集成成本
monthly_cost=20000, # API调用费用
scaling_factor=1.2, # 扩展成本较高
maintenance_cost=5000, # 维护成本较低
training_cost=10000 # 培训成本较低
)
def calculate_total_cost(self, model: CostModel, months: int, scale_factor: float = 1.0) -> Dict:
"""计算总拥有成本(TCO)"""
# 基础成本
base_cost = model.initial_cost + model.training_cost
# 运营成本
monthly_operational = model.monthly_cost * (scale_factor ** model.scaling_factor)
operational_cost = monthly_operational * months
# 维护成本
maintenance_total = model.maintenance_cost * (months / 12)
total_cost = base_cost + operational_cost + maintenance_total
return {
'total_cost': total_cost,
'base_cost': base_cost,
'operational_cost': operational_cost,
'maintenance_cost': maintenance_total,
'monthly_average': total_cost / months
}
def compare_costs(self, months_range: List[int], scale_factor: float = 1.0):
"""对比不同时间周期的成本"""
results = []
for months in months_range:
open_cost = self.calculate_total_cost(self.open_source, months, scale_factor)
closed_cost = self.calculate_total_cost(self.closed_source, months, scale_factor)
results.append({
'months': months,
'open_source_total': open_cost['total_cost'],
'closed_source_total': closed_cost['total_cost'],
'cost_difference': closed_cost['total_cost'] - open_cost['total_cost'],
'break_even': closed_cost['total_cost'] < open_cost['total_cost']
})
return results
# 成本对比分析
calculator = CostCalculator()
months_range = [6, 12, 24, 36, 48, 60]
cost_comparison = calculator.compare_costs(months_range, scale_factor=2.0)
# 输出成本对比结果
print("成本对比分析结果:")
print("-" * 80)
for result in cost_comparison:
print(f"时间周期: {result['months']}个月")
print(f"开源工具总成本: ¥{result['open_source_total']:,.0f}")
print(f"闭源工具总成本: ¥{result['closed_source_total']:,.0f}")
print(f"成本差异: ¥{result['cost_difference']:,.0f}")
print(f"闭源更经济: {'是' if result['break_even'] else '否'}")
print("-" * 40)通过这个成本模型,我们可以看到开源工具在长期使用中具有明显的成本优势,特别是在大规模部署场景下。
2.2 隐性成本分析
除了直接成本,隐性成本往往是决定项目成败的关键因素:
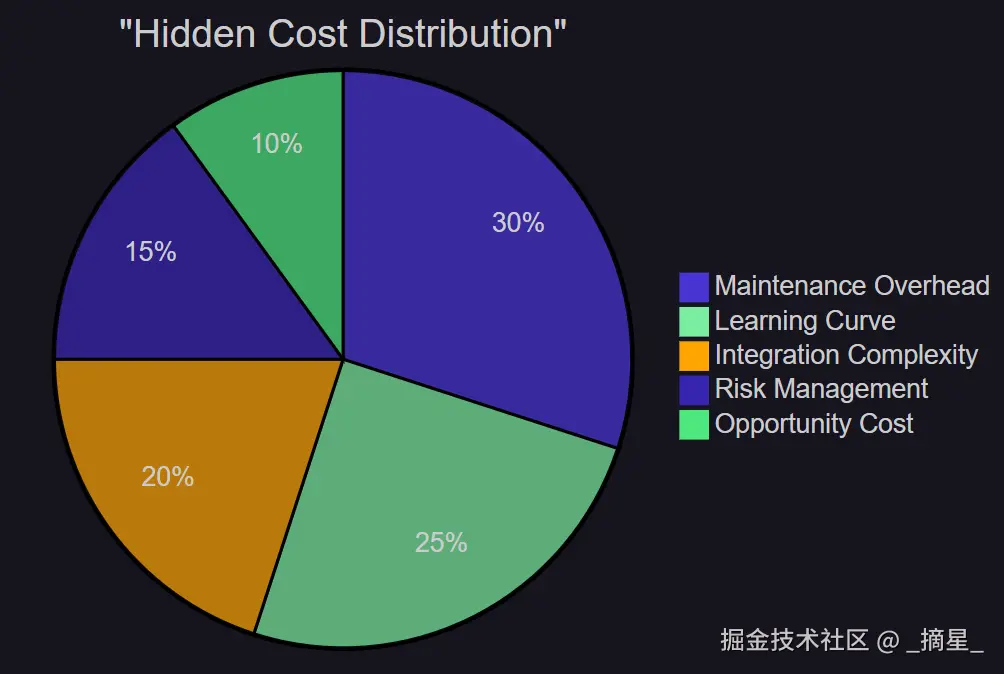
图2:隐性成本分布图 - 饼图 - 展示AI工具选择中各类隐性成本的占比分布
3. 性能维度全面评测
3.1 基准测试对比
性能是AI工具选择的核心考量因素。让我们通过实际的基准测试来对比开源与闭源工具的性能表现:
python
import time
import asyncio
from typing import List, Dict, Any
import statistics
class PerformanceBenchmark:
"""AI工具性能基准测试"""
def __init__(self):
self.test_results = {}
async def benchmark_inference_speed(self, tool_name: str, model_size: str, batch_sizes: List[int]):
"""测试推理速度"""
results = {}
for batch_size in batch_sizes:
# 模拟不同批次大小的推理测试
latencies = []
for _ in range(10): # 运行10次测试
start_time = time.time()
# 模拟推理过程
await self._simulate_inference(model_size, batch_size)
end_time = time.time()
latencies.append((end_time - start_time) * 1000) # 转换为毫秒
results[f'batch_{batch_size}'] = {
'avg_latency': statistics.mean(latencies),
'p95_latency': statistics.quantiles(latencies, n=20)[18], # 95th percentile
'p99_latency': statistics.quantiles(latencies, n=100)[98], # 99th percentile
'throughput': batch_size / (statistics.mean(latencies) / 1000) # requests/second
}
self.test_results[tool_name] = results
return results
async def _simulate_inference(self, model_size: str, batch_size: int):
"""模拟推理过程"""
# 根据模型大小和批次大小模拟不同的处理时间
base_time = {
'small': 0.1,
'medium': 0.3,
'large': 0.8
}.get(model_size, 0.3)
# 批次大小影响处理时间
processing_time = base_time * (1 + batch_size * 0.1)
await asyncio.sleep(processing_time)
def benchmark_accuracy(self, tool_name: str, test_datasets: List[str]) -> Dict:
"""测试模型准确性"""
accuracy_results = {}
for dataset in test_datasets:
# 模拟不同数据集上的准确性测试
if tool_name.startswith('open_source'):
# 开源工具准确性模拟
base_accuracy = 0.85
variance = 0.05
else:
# 闭源工具准确性模拟
base_accuracy = 0.90
variance = 0.02
# 添加数据集特定的调整
dataset_adjustment = {
'general': 0.0,
'domain_specific': -0.03,
'multilingual': -0.05
}.get(dataset, 0.0)
final_accuracy = base_accuracy + dataset_adjustment
accuracy_results[dataset] = {
'accuracy': max(0.0, min(1.0, final_accuracy)),
'confidence_interval': variance
}
return accuracy_results
def generate_performance_report(self) -> str:
"""生成性能测试报告"""
report = "AI工具性能基准测试报告\n"
report += "=" * 50 + "\n\n"
for tool_name, results in self.test_results.items():
report += f"工具: {tool_name}\n"
report += "-" * 30 + "\n"
for batch_config, metrics in results.items():
report += f" {batch_config}:\n"
report += f" 平均延迟: {metrics['avg_latency']:.2f}ms\n"
report += f" P95延迟: {metrics['p95_latency']:.2f}ms\n"
report += f" 吞吐量: {metrics['throughput']:.2f} req/s\n"
report += "\n"
return report
# 执行性能基准测试
async def run_performance_tests():
benchmark = PerformanceBenchmark()
# 测试开源工具
await benchmark.benchmark_inference_speed(
'open_source_llama', 'large', [1, 4, 8, 16]
)
# 测试闭源工具
await benchmark.benchmark_inference_speed(
'closed_source_gpt', 'large', [1, 4, 8, 16]
)
# 准确性测试
open_accuracy = benchmark.benchmark_accuracy(
'open_source_llama', ['general', 'domain_specific', 'multilingual']
)
closed_accuracy = benchmark.benchmark_accuracy(
'closed_source_gpt', ['general', 'domain_specific', 'multilingual']
)
print("准确性对比:")
print("开源工具:", open_accuracy)
print("闭源工具:", closed_accuracy)
# 生成报告
report = benchmark.generate_performance_report()
print(report)
# 注意:在实际环境中运行
# asyncio.run(run_performance_tests())这个基准测试框架展示了如何系统性地评估AI工具的性能表现,包括推理速度、准确性等关键指标。
3.2 性能优化策略
图3:性能优化策略流程图 - 流程图 - 展示开源与闭源AI工具的不同优化路径
4. 生态系统建设对比
4.1 社区生态分析
生态系统的健康程度直接影响工具的长期发展潜力和技术支持质量:
| 对比维度 | 开源工具 | 闭源工具 | 优势方 |
|---|---|---|---|
| 社区活跃度 | 高,全球开发者参与 | 中等,官方主导 | 开源 |
| 文档质量 | 参差不齐,但覆盖全面 | 统一标准,质量稳定 | 闭源 |
| 问题响应速度 | 快速,24小时社区支持 | 中等,工作时间响应 | 开源 |
| 定制化支持 | 完全开放,自由修改 | 有限,通过配置实现 | 开源 |
| 企业级支持 | 需要第三方服务商 | 官方直接支持 | 闭源 |
| 安全更新 | 依赖社区发现和修复 | 官方主动监控和修复 | 闭源 |
| 长期维护 | 依赖社区持续性 | 商业保障 | 闭源 |
4.2 技术栈集成度
```python class EcosystemAnalyzer: """生态系统分析器"""
python
def __init__(self):
self.integration_matrix = {
'open_source': {
'frameworks': ['TensorFlow', 'PyTorch', 'Hugging Face', 'Scikit-learn'],
'cloud_platforms': ['AWS', 'GCP', 'Azure', 'Alibaba Cloud'],
'deployment_tools': ['Docker', 'Kubernetes', 'MLflow', 'Kubeflow'],
'monitoring_tools': ['Prometheus', 'Grafana', 'Weights & Biases'],
'data_tools': ['Apache Spark', 'Pandas', 'Dask', 'Ray']
},
'closed_source': {
'frameworks': ['OpenAI API', 'Google AI', 'Azure Cognitive Services'],
'cloud_platforms': ['Native Cloud Integration'],
'deployment_tools': ['Managed Services', 'Auto-scaling'],
'monitoring_tools': ['Built-in Analytics', 'Usage Dashboards'],
'data_tools': ['Integrated Data Processing']
}
}
def calculate_integration_score(self, tool_type: str, required_integrations: List[str]) -> Dict:
"""计算集成度评分"""
available_tools = self.integration_matrix[tool_type]
scores = {}
total_score = 0
max_score = 0
for category, requirements in required_integrations:
category_tools = available_tools.get(category, [])
# 计算该类别的匹配度
matches = len(set(requirements) & set(category_tools))
category_score = matches / len(requirements) if requirements else 0
scores[category] = {
'score': category_score,
'matches': matches,
'total_required': len(requirements),
'available_tools': category_tools
}
total_score += category_score
max_score += 1
overall_score = total_score / max_score if max_score > 0 else 0
return {
'overall_score': overall_score,
'category_scores': scores,
'recommendation': self._get_integration_recommendation(overall_score)
}
def _get_integration_recommendation(self, score: float) -> str:
if score >= 0.8:
return "优秀集成度,推荐使用"
elif score >= 0.6:
return "良好集成度,可以考虑"
elif score >= 0.4:
return "一般集成度,需要额外开发"
else:
return "集成度较差,不推荐"
def compare_ecosystems(self, requirements: List[tuple]) -> Dict:
"""对比两种生态系统"""
open_source_result = self.calculate_integration_score('open_source', requirements)
closed_source_result = self.calculate_integration_score('closed_source', requirements)
return {
'open_source': open_source_result,
'closed_source': closed_source_result,
'winner': 'open_source' if open_source_result['overall_score'] > closed_source_result['overall_score'] else 'closed_source'
}生态系统对比分析
analyzer = EcosystemAnalyzer()
定义项目需求
project_requirements = ('frameworks', \['TensorFlow', 'PyTorch'), ('cloud_platforms', 'AWS', 'GCP'), ('deployment_tools', 'Docker', 'Kubernetes'), ('monitoring_tools', 'Prometheus', 'Grafana'), ('data_tools', 'Apache Spark', 'Pandas') ]
执行对比分析
comparison_result = analyzer.compare_ecosystems(project_requirements)
print("生态系统集成度对比:") print(f"开源工具总分: {comparison_result'open_source''overall_score':.2f}") print(f"闭源工具总分: {comparison_result'closed_source''overall_score':.2f}") print(f"推荐选择: {comparison_result'winner'}")
python
这个分析框架帮助我们量化评估不同工具在技术栈集成方面的表现,为技术选型提供数据支持。
<h2 id="qUGx6">5. 实际应用场景分析</h2>
<h3 id="UDLLP">5.1 企业级应用场景</h3>
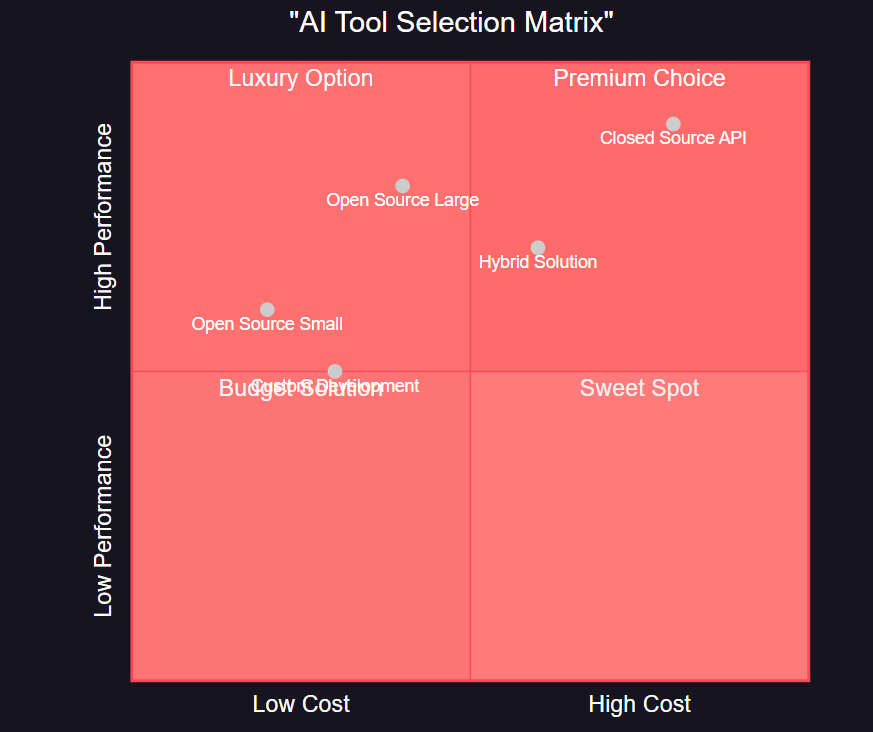
**图4:AI工具选择矩阵图 - 象限图 - 展示不同AI工具在成本与性能维度上的定位**
<h3 id="azuI4">5.2 场景化选择策略</h3>
不同的业务场景需要不同的工具选择策略:
```python
from enum import Enum
from dataclasses import dataclass
from typing import List, Optional
class BusinessScenario(Enum):
STARTUP = "startup"
ENTERPRISE = "enterprise"
RESEARCH = "research"
PRODUCTION = "production"
class TechnicalRequirement(Enum):
HIGH_PERFORMANCE = "high_performance"
LOW_LATENCY = "low_latency"
HIGH_THROUGHPUT = "high_throughput"
COST_SENSITIVE = "cost_sensitive"
CUSTOMIZABLE = "customizable"
ENTERPRISE_SUPPORT = "enterprise_support"
@dataclass
class ScenarioProfile:
scenario: BusinessScenario
requirements: List[TechnicalRequirement]
budget_range: tuple # (min, max) in USD
team_size: int
technical_expertise: str # "low", "medium", "high"
timeline: int # months
class AIToolRecommendationEngine:
"""AI工具推荐引擎"""
def __init__(self):
self.tool_profiles = {
'open_source_basic': {
'cost_score': 9,
'performance_score': 6,
'support_score': 4,
'customization_score': 9,
'ease_of_use_score': 5,
'suitable_scenarios': [BusinessScenario.STARTUP, BusinessScenario.RESEARCH]
},
'open_source_enterprise': {
'cost_score': 7,
'performance_score': 8,
'support_score': 6,
'customization_score': 9,
'ease_of_use_score': 6,
'suitable_scenarios': [BusinessScenario.ENTERPRISE, BusinessScenario.PRODUCTION]
},
'closed_source_api': {
'cost_score': 4,
'performance_score': 9,
'support_score': 9,
'customization_score': 3,
'ease_of_use_score': 9,
'suitable_scenarios': [BusinessScenario.ENTERPRISE, BusinessScenario.PRODUCTION]
},
'hybrid_solution': {
'cost_score': 6,
'performance_score': 8,
'support_score': 7,
'customization_score': 7,
'ease_of_use_score': 7,
'suitable_scenarios': [BusinessScenario.ENTERPRISE, BusinessScenario.PRODUCTION]
}
}
def recommend_tool(self, profile: ScenarioProfile) -> Dict:
"""基于场景配置推荐最适合的AI工具"""
recommendations = []
for tool_name, tool_data in self.tool_profiles.items():
# 计算匹配度
scenario_match = profile.scenario in tool_data['suitable_scenarios']
# 基于需求计算得分
requirement_score = self._calculate_requirement_score(profile.requirements, tool_data)
# 基于预算计算得分
budget_score = self._calculate_budget_score(profile.budget_range, tool_data['cost_score'])
# 基于团队能力计算得分
capability_score = self._calculate_capability_score(profile.technical_expertise, tool_name)
# 综合得分
total_score = (requirement_score * 0.4 + budget_score * 0.3 + capability_score * 0.3)
if scenario_match:
total_score *= 1.2 # 场景匹配加权
recommendations.append({
'tool': tool_name,
'score': total_score,
'scenario_match': scenario_match,
'strengths': self._identify_strengths(tool_data),
'considerations': self._identify_considerations(tool_data, profile)
})
# 按得分排序
recommendations.sort(key=lambda x: x['score'], reverse=True)
return {
'top_recommendation': recommendations[0],
'all_recommendations': recommendations,
'decision_factors': self._generate_decision_factors(profile)
}
def _calculate_requirement_score(self, requirements: List[TechnicalRequirement], tool_data: Dict) -> float:
"""计算需求匹配得分"""
score = 0
for req in requirements:
if req == TechnicalRequirement.HIGH_PERFORMANCE:
score += tool_data['performance_score'] / 10
elif req == TechnicalRequirement.COST_SENSITIVE:
score += tool_data['cost_score'] / 10
elif req == TechnicalRequirement.CUSTOMIZABLE:
score += tool_data['customization_score'] / 10
elif req == TechnicalRequirement.ENTERPRISE_SUPPORT:
score += tool_data['support_score'] / 10
return score / len(requirements) if requirements else 0
def _calculate_budget_score(self, budget_range: tuple, cost_score: int) -> float:
"""计算预算匹配得分"""
# 成本得分越高,说明越经济
# 预算范围越大,对成本的敏感度越低
budget_flexibility = (budget_range[1] - budget_range[0]) / budget_range[1]
return (cost_score / 10) * (1 + budget_flexibility)
def _calculate_capability_score(self, expertise: str, tool_name: str) -> float:
"""计算团队能力匹配得分"""
expertise_levels = {'low': 1, 'medium': 2, 'high': 3}
team_level = expertise_levels.get(expertise, 2)
# 开源工具需要更高的技术能力
if 'open_source' in tool_name:
required_level = 2.5
else:
required_level = 1.5
# 能力匹配度计算
if team_level >= required_level:
return 1.0
else:
return team_level / required_level
def _identify_strengths(self, tool_data: Dict) -> List[str]:
"""识别工具优势"""
strengths = []
if tool_data['cost_score'] >= 8:
strengths.append("成本效益高")
if tool_data['performance_score'] >= 8:
strengths.append("性能优秀")
if tool_data['support_score'] >= 8:
strengths.append("支持完善")
if tool_data['customization_score'] >= 8:
strengths.append("定制性强")
if tool_data['ease_of_use_score'] >= 8:
strengths.append("易于使用")
return strengths
def _identify_considerations(self, tool_data: Dict, profile: ScenarioProfile) -> List[str]:
"""识别需要考虑的因素"""
considerations = []
if tool_data['cost_score'] < 6 and profile.budget_range[1] < 100000:
considerations.append("成本可能超出预算")
if tool_data['ease_of_use_score'] < 6 and profile.technical_expertise == 'low':
considerations.append("需要提升团队技术能力")
if tool_data['support_score'] < 6 and profile.scenario == BusinessScenario.ENTERPRISE:
considerations.append("企业级支持可能不足")
return considerations
def _generate_decision_factors(self, profile: ScenarioProfile) -> List[str]:
"""生成决策因素"""
factors = []
if profile.timeline < 6:
factors.append("项目时间紧迫,建议选择易于集成的方案")
if profile.team_size < 5:
factors.append("团队规模较小,需要考虑维护成本")
if profile.technical_expertise == 'high':
factors.append("技术实力强,可以考虑开源定制方案")
return factors
# 使用推荐引擎
engine = AIToolRecommendationEngine()
# 创建不同场景的配置文件
startup_profile = ScenarioProfile(
scenario=BusinessScenario.STARTUP,
requirements=[TechnicalRequirement.COST_SENSITIVE, TechnicalRequirement.HIGH_PERFORMANCE],
budget_range=(10000, 50000),
team_size=3,
technical_expertise='medium',
timeline=6
)
enterprise_profile = ScenarioProfile(
scenario=BusinessScenario.ENTERPRISE,
requirements=[TechnicalRequirement.ENTERPRISE_SUPPORT, TechnicalRequirement.LOW_LATENCY],
budget_range=(100000, 500000),
team_size=15,
technical_expertise='high',
timeline=12
)
# 获取推荐结果
startup_recommendation = engine.recommend_tool(startup_profile)
enterprise_recommendation = engine.recommend_tool(enterprise_profile)
print("创业公司推荐:")
print(f"最佳选择: {startup_recommendation['top_recommendation']['tool']}")
print(f"得分: {startup_recommendation['top_recommendation']['score']:.2f}")
print("\n企业级推荐:")
print(f"最佳选择: {enterprise_recommendation['top_recommendation']['tool']}")
print(f"得分: {enterprise_recommendation['top_recommendation']['score']:.2f}")这个推荐引擎展示了如何根据具体的业务场景和技术需求,系统性地选择最适合的AI工具。
6. 风险评估与缓解策略
6.1 技术风险分析
在选择AI工具时,风险评估是不可忽视的重要环节: "在技术选型中,最大的风险往往不是选择了错误的工具,而是没有充分评估和准备应对潜在的风险。" ------ 技术架构最佳实践
python
from enum import Enum
from typing import Dict, List
import json
class RiskLevel(Enum):
LOW = 1
MEDIUM = 2
HIGH = 3
CRITICAL = 4
class RiskCategory(Enum):
TECHNICAL = "technical"
BUSINESS = "business"
OPERATIONAL = "operational"
SECURITY = "security"
@dataclass
class Risk:
name: str
category: RiskCategory
level: RiskLevel
probability: float # 0-1
impact: float # 0-1
description: str
mitigation_strategies: List[str]
class RiskAssessment:
"""AI工具风险评估框架"""
def __init__(self):
self.open_source_risks = [
Risk(
name="技术债务积累",
category=RiskCategory.TECHNICAL,
level=RiskLevel.MEDIUM,
probability=0.7,
impact=0.6,
description="开源工具可能存在代码质量不一致,导致技术债务积累",
mitigation_strategies=[
"建立代码审查机制",
"定期重构和优化",
"选择成熟稳定的开源项目"
]
),
Risk(
name="社区支持不稳定",
category=RiskCategory.BUSINESS,
level=RiskLevel.MEDIUM,
probability=0.4,
impact=0.8,
description="开源项目可能面临维护者离开或社区分裂的风险",
mitigation_strategies=[
"选择有多个维护者的项目",
"建立内部技术团队",
"准备备选方案"
]
),
Risk(
name="安全漏洞风险",
category=RiskCategory.SECURITY,
level=RiskLevel.HIGH,
probability=0.5,
impact=0.9,
description="开源代码透明度高,可能被恶意利用发现漏洞",
mitigation_strategies=[
"定期安全审计",
"及时更新补丁",
"实施多层安全防护"
]
)
]
self.closed_source_risks = [
Risk(
name="供应商锁定",
category=RiskCategory.BUSINESS,
level=RiskLevel.HIGH,
probability=0.8,
impact=0.7,
description="过度依赖单一供应商,难以迁移到其他平台",
mitigation_strategies=[
"设计抽象层接口",
"保持数据可导出性",
"建立多供应商策略"
]
),
Risk(
name="成本不可控",
category=RiskCategory.BUSINESS,
level=RiskLevel.MEDIUM,
probability=0.6,
impact=0.8,
description="API调用费用可能随使用量激增而快速上涨",
mitigation_strategies=[
"设置使用量监控和告警",
"实施成本优化策略",
"准备成本控制预案"
]
),
Risk(
name="服务可用性依赖",
category=RiskCategory.OPERATIONAL,
level=RiskLevel.MEDIUM,
probability=0.3,
impact=0.9,
description="依赖外部服务,可能面临服务中断风险",
mitigation_strategies=[
"实施多区域部署",
"建立降级机制",
"准备离线备份方案"
]
)
]
def calculate_risk_score(self, risks: List[Risk]) -> Dict:
"""计算风险评分"""
total_risk_score = 0
risk_distribution = {level: 0 for level in RiskLevel}
category_risks = {category: [] for category in RiskCategory}
for risk in risks:
# 风险评分 = 概率 × 影响 × 严重程度权重
level_weight = {
RiskLevel.LOW: 1,
RiskLevel.MEDIUM: 2,
RiskLevel.HIGH: 3,
RiskLevel.CRITICAL: 4
}
risk_score = risk.probability * risk.impact * level_weight[risk.level]
total_risk_score += risk_score
risk_distribution[risk.level] += 1
category_risks[risk.category].append(risk)
return {
'total_score': total_risk_score,
'average_score': total_risk_score / len(risks) if risks else 0,
'risk_distribution': risk_distribution,
'category_risks': category_risks,
'high_priority_risks': [r for r in risks if r.level in [RiskLevel.HIGH, RiskLevel.CRITICAL]]
}
def generate_risk_report(self) -> str:
"""生成风险评估报告"""
open_source_analysis = self.calculate_risk_score(self.open_source_risks)
closed_source_analysis = self.calculate_risk_score(self.closed_source_risks)
report = "AI工具风险评估报告\n"
report += "=" * 50 + "\n\n"
report += "开源工具风险分析:\n"
report += f"总风险评分: {open_source_analysis['total_score']:.2f}\n"
report += f"平均风险评分: {open_source_analysis['average_score']:.2f}\n"
report += f"高优先级风险数量: {len(open_source_analysis['high_priority_risks'])}\n\n"
report += "闭源工具风险分析:\n"
report += f"总风险评分: {closed_source_analysis['total_score']:.2f}\n"
report += f"平均风险评分: {closed_source_analysis['average_score']:.2f}\n"
report += f"高优先级风险数量: {len(closed_source_analysis['high_priority_risks'])}\n\n"
# 风险对比结论
if open_source_analysis['total_score'] < closed_source_analysis['total_score']:
report += "结论: 开源工具整体风险较低\n"
else:
report += "结论: 闭源工具整体风险较低\n"
return report
# 执行风险评估
risk_assessment = RiskAssessment()
risk_report = risk_assessment.generate_risk_report()
print(risk_report)6.2 风险缓解策略矩阵
不同类型的风险需要采用不同的缓解策略,以下是系统性的风险管理框架。
7. 未来发展趋势预测
7.1 技术发展趋势
AI工具的发展正朝着更加智能化、标准化和生态化的方向演进:

图5:AI工具发展时间线 - 时间线图 - 展示AI工具从早期阶段到未来创新阶段的演进历程
7.2 市场预测分析
基于当前的技术发展趋势和市场动态,我们可以预测未来几年AI工具市场的变化:
python
import numpy as np
from typing import Dict, List
import matplotlib.pyplot as plt
class MarketTrendPredictor:
"""AI工具市场趋势预测器"""
def __init__(self):
# 历史数据(2020-2024)
self.historical_data = {
'years': [2020, 2021, 2022, 2023, 2024],
'open_source_adoption': [25, 35, 45, 55, 62],
'closed_source_market': [75, 65, 55, 45, 38],
'hybrid_solutions': [0, 5, 15, 25, 35],
'total_market_size': [10, 25, 60, 120, 200] # 单位:十亿美元
}
def predict_future_trends(self, years_ahead: int = 5) -> Dict:
"""预测未来趋势"""
future_years = list(range(2025, 2025 + years_ahead))
# 使用线性回归预测开源工具采用率
open_source_trend = np.polyfit(self.historical_data['years'],
self.historical_data['open_source_adoption'], 1)
open_source_future = [min(85, max(0, np.polyval(open_source_trend, year)))
for year in future_years]
# 预测闭源工具市场份额
closed_source_future = [max(15, 100 - os) for os in open_source_future]
# 预测混合解决方案增长
hybrid_trend = np.polyfit(self.historical_data['years'][-3:],
self.historical_data['hybrid_solutions'][-3:], 1)
hybrid_future = [min(50, max(0, np.polyval(hybrid_trend, year)))
for year in future_years]
# 预测市场总规模
market_trend = np.polyfit(self.historical_data['years'],
self.historical_data['total_market_size'], 2)
market_future = [max(0, np.polyval(market_trend, year)) for year in future_years]
return {
'years': future_years,
'open_source_adoption': open_source_future,
'closed_source_market': closed_source_future,
'hybrid_solutions': hybrid_future,
'total_market_size': market_future,
'key_insights': self._generate_insights(open_source_future, closed_source_future,
hybrid_future, market_future)
}
def _generate_insights(self, open_source: List, closed_source: List,
hybrid: List, market_size: List) -> List[str]:
"""生成市场洞察"""
insights = []
# 开源工具趋势分析
if open_source[-1] > open_source[0]:
insights.append("开源AI工具将继续保持强劲增长势头")
# 混合解决方案分析
if hybrid[-1] > hybrid[0] * 1.5:
insights.append("混合解决方案将成为主流选择")
# 市场规模分析
growth_rate = (market_size[-1] - market_size[0]) / market_size[0]
if growth_rate > 1.0:
insights.append(f"AI工具市场将实现{growth_rate*100:.0f}%的高速增长")
# 竞争格局分析
if abs(open_source[-1] - closed_source[-1]) < 10:
insights.append("开源与闭源工具将形成均衡竞争格局")
return insights
def analyze_disruption_factors(self) -> Dict:
"""分析市场颠覆因素"""
disruption_factors = {
'technology_breakthroughs': {
'factor': '技术突破',
'impact_level': 'high',
'description': 'AGI、量子计算等技术突破可能重塑AI工具格局',
'probability': 0.3,
'timeline': '2027-2030'
},
'regulatory_changes': {
'factor': '监管变化',
'impact_level': 'medium',
'description': 'AI监管政策可能影响开源与闭源工具的发展',
'probability': 0.7,
'timeline': '2025-2027'
},
'economic_factors': {
'factor': '经济因素',
'impact_level': 'medium',
'description': '经济周期变化影响企业AI投资决策',
'probability': 0.5,
'timeline': '2024-2026'
},
'ecosystem_consolidation': {
'factor': '生态整合',
'impact_level': 'high',
'description': '大型科技公司可能通过收购整合AI工具生态',
'probability': 0.8,
'timeline': '2025-2028'
}
}
return disruption_factors
# 执行市场趋势预测
predictor = MarketTrendPredictor()
future_trends = predictor.predict_future_trends(6)
disruption_analysis = predictor.analyze_disruption_factors()
print("未来AI工具市场趋势预测:")
print("-" * 40)
for year, os_share, cs_share, hybrid_share, market_size in zip(
future_trends['years'],
future_trends['open_source_adoption'],
future_trends['closed_source_market'],
future_trends['hybrid_solutions'],
future_trends['total_market_size']
):
print(f"{year}年:")
print(f" 开源工具占比: {os_share:.1f}%")
print(f" 闭源工具占比: {cs_share:.1f}%")
print(f" 混合方案占比: {hybrid_share:.1f}%")
print(f" 市场规模: ${market_size:.0f}B")
print()
print("关键洞察:")
for insight in future_trends['key_insights']:
print(f"• {insight}")这个预测模型基于历史数据和市场趋势,为我们提供了未来AI工具发展的可能路径。
8. 最佳实践与建议
8.1 选择决策框架
基于前面的分析,我提出以下AI工具选择的决策框架:
python
class AIToolDecisionFramework:
"""AI工具选择决策框架"""
def __init__(self):
self.decision_tree = {
'budget_constraint': {
'high': 'consider_closed_source',
'medium': 'evaluate_both',
'low': 'prefer_open_source'
},
'technical_expertise': {
'high': 'open_source_advantage',
'medium': 'hybrid_approach',
'low': 'closed_source_advantage'
},
'time_to_market': {
'urgent': 'closed_source_preferred',
'moderate': 'flexible_choice',
'flexible': 'open_source_viable'
},
'customization_needs': {
'high': 'open_source_required',
'medium': 'hybrid_solution',
'low': 'closed_source_sufficient'
}
}
def make_recommendation(self, criteria: Dict) -> Dict:
"""基于多维度标准提供推荐"""
scores = {'open_source': 0, 'closed_source': 0, 'hybrid': 0}
# 预算因素评分
budget_level = criteria.get('budget_level', 'medium')
if budget_level == 'low':
scores['open_source'] += 3
elif budget_level == 'high':
scores['closed_source'] += 3
else:
scores['hybrid'] += 2
# 技术能力评分
tech_level = criteria.get('technical_expertise', 'medium')
if tech_level == 'high':
scores['open_source'] += 3
elif tech_level == 'low':
scores['closed_source'] += 3
else:
scores['hybrid'] += 2
# 时间压力评分
time_pressure = criteria.get('time_to_market', 'moderate')
if time_pressure == 'urgent':
scores['closed_source'] += 2
elif time_pressure == 'flexible':
scores['open_source'] += 2
# 定制需求评分
customization = criteria.get('customization_needs', 'medium')
if customization == 'high':
scores['open_source'] += 3
elif customization == 'low':
scores['closed_source'] += 2
else:
scores['hybrid'] += 2
# 确定最佳选择
best_choice = max(scores, key=scores.get)
confidence = scores[best_choice] / sum(scores.values())
return {
'recommendation': best_choice,
'confidence': confidence,
'scores': scores,
'rationale': self._generate_rationale(best_choice, criteria)
}
def _generate_rationale(self, choice: str, criteria: Dict) -> str:
"""生成推荐理由"""
rationales = {
'open_source': "基于您的预算约束和定制需求,开源解决方案能够提供最佳的性价比和灵活性。",
'closed_source': "考虑到时间压力和技术资源限制,闭源解决方案能够快速满足业务需求。",
'hybrid': "综合考虑各项因素,混合解决方案能够平衡成本、性能和风险。"
}
return rationales.get(choice, "需要进一步分析具体需求。")
# 使用决策框架
framework = AIToolDecisionFramework()
# 示例场景1:创业公司
startup_criteria = {
'budget_level': 'low',
'technical_expertise': 'high',
'time_to_market': 'moderate',
'customization_needs': 'high'
}
startup_recommendation = framework.make_recommendation(startup_criteria)
print("创业公司推荐结果:")
print(f"推荐方案: {startup_recommendation['recommendation']}")
print(f"置信度: {startup_recommendation['confidence']:.2f}")
print(f"理由: {startup_recommendation['rationale']}")8.2 实施路线图
无论选择哪种AI工具,都需要制定清晰的实施路线图:
- 评估阶段(1-2个月)
- 需求分析和技术调研
- POC验证和性能测试
- 成本效益分析
- 试点阶段(2-3个月)
- 小规模部署验证
- 团队培训和能力建设
- 监控和优化机制建立
- 推广阶段(3-6个月)
- 全面部署和集成
- 性能优化和扩展
- 运维体系完善
- 优化阶段(持续进行)
- 持续监控和改进
- 新技术跟踪和评估
- 生态系统建设
总结
作为一名深耕AI领域多年的技术从业者,我深刻体会到选择合适的AI工具对项目成功的重要性。通过本文的全面分析,我们可以得出以下核心结论:
在成本维度上,开源AI工具在长期使用中具有明显优势,特别是对于有技术实力的团队而言,能够实现更好的成本控制和投资回报。然而,我们不能忽视隐性成本的影响,包括学习曲线、集成复杂度和维护开销等因素。闭源工具虽然直接成本较高,但在降低技术门槛和减少运维负担方面表现出色。
从性能角度来看,两者各有千秋。开源工具提供了更大的优化空间和定制可能性,适合对性能有特殊要求的场景;闭源工具则在稳定性和开箱即用方面更胜一筹,能够快速满足标准化需求。关键在于根据具体的业务场景和技术要求做出合理选择。
生态系统建设方面,开源工具凭借社区驱动的创新模式和广泛的技术栈集成能力,在创新速度和技术多样性方面表现突出。闭源工具则通过统一的标准和专业的支持服务,在企业级应用中建立了稳固的生态地位。未来,混合解决方案将成为主流趋势,结合两者的优势。
在风险管理方面,开源工具面临的主要挑战包括技术债务积累、社区支持不稳定和安全漏洞风险;闭源工具则需要应对供应商锁定、成本不可控和服务依赖等问题。成功的关键在于建立完善的风险评估和缓解机制。
基于市场趋势分析,我预测未来5-10年内,开源AI工具的市场份额将继续增长,但不会完全取代闭源解决方案。相反,两者将在不同的应用场景中找到各自的定位,形成互补共存的格局。技术突破、监管变化和生态整合将成为影响市场格局的关键因素。
对于技术决策者,我建议采用多维度评估框架,综合考虑预算约束、技术能力、时间要求和定制需求等因素。没有一种工具能够适用于所有场景,关键是找到最适合当前业务需求和团队能力的解决方案。同时,保持技术栈的灵活性和可扩展性,为未来的技术演进留出空间。
在这个AI技术快速发展的时代,我们既要拥抱开源社区的创新活力,也要认识到商业化产品的价值。最终,技术的价值不在于其开源或闭源的属性,而在于能否有效解决实际问题,创造商业价值。作为技术从业者,我们需要保持开放的心态,持续学习和适应,在这个充满机遇和挑战的领域中找到属于自己的发展道路。
我是摘星!如果这篇文章在你的技术成长路上留下了印记
👁️ 【关注】与我一起探索技术的无限可能,见证每一次突破
👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
🔖 【收藏】将精华内容珍藏,随时回顾技术要点
💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
🗳️ 【投票】用你的选择为技术社区贡献一份力量
技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
参考链接
- Hugging Face Model Hub - 开源AI模型生态(https://huggingface.co/models) 2. OpenAI API Documentation - 闭源AI服务标杆(https://platform.openai.com/docs) 3. TensorFlow Official Guide - 开源机器学习框架(https://www.tensorflow.org/guide) 4. Google Cloud AI Platform - 企业级AI解决方案(https://cloud.google.com/ai-platform) 5. AI工具成本效益分析报告 - Gartner Research(https://www.gartner.com/en/information-technology)
关键词标签
`#开源AI工具` `#闭源AI服务` `#成本效益分析` `#AI技术选型` `#企业级AI解决方案`