前言
本文聚焦 LangGraph 的基础控制方法,通过详细讲解与代码示例实现,帮助读者快速掌握其基础控制的写法,为后续开发 LangGraph Agent 工作流奠定基础。
状态管理
在 LangGraph 中,状态管理 是构建复杂工作流的核心机制。节点通过返回值更新图状态,状态更新规则由 State 对象的定义决定。
一、状态定义方式
-
TypedDict(适合简单场景):轻量型定义,适合结构简单、无需复杂验证的状态。
TypedDict 示例(简单场景)
from typing import TypedDict
class InputState(TypedDict):
user_input: str -
BaseModel(适合复杂场景):基于 Pydantic,支持类型验证、约束定义和嵌套结构,适合复杂状态。BaseModel 示例(复杂场景)
from pydantic import BaseModel
class State(BaseModel):
# 1. 工具调用相关消息列表(精确类型+长度约束)
messages: List[BaseMessage] = Field(
..., # 必须提供初始值,不允许为空
min_length=1, # 至少包含1条消息(原300可能为笔误,消息数量通常不需要这么大,调整为合理值)
description="工具调用的完整消息记录,包含用户指令、工具输入/输出、系统提示等,每条消息需为BaseMessage子类(如HumanMessage、ToolMessage)"
)# 2. 元数据(结构化键值对,明确包含的信息) metadata: Dict[str, Union[str, int, datetime, bool]] = Field( default_factory=lambda: { "session_id": "", # 会话唯一标识 "step": 0, # 当前流程步骤(从0开始) "last_tool": None, # 上一次调用的工具名称(如"search") "is_finished": False, # 流程是否已结束 "created_at": datetime.now() # 状态创建时间 }, description="状态元数据,包含会话标识、流程进度、工具调用记录、时间戳等关键信息,值类型支持字符串、数字、时间、布尔值" )
二、状态更新机制
节点通过返回值更新状态,LangGraph 使用 Reducer(规约器) 控制更新逻辑。
-
默认 Reducer(覆盖更新) **:**未指定 Reducer 时,节点返回的字段直接覆盖原状态对应字段。
from typing_extensions import TypedDict
class State(TypedDict):
foo: int
bar: list[str]节点函数:仅更新foo字段
def node_1(state: State) -> dict:
return {"foo": 2} # 无需返回bar,原bar值会保留初始状态:{"foo": 1, "bar": ["hi"]}
节点执行后状态:{"foo": 2, "bar": ["hi"]}(foo被覆盖,bar不变)
-
内置 Reducer :通过
Annotated指定内置 Reducer,实现复杂更新(如列表追加)。from typing import Annotated
from langgraph.graph import addclass State(TypedDict):
logs: Annotated[List[str], add] # 自动追加新元素def add_log(state: State) -> dict:
return {"logs": ["step 1 completed"]} # 追加到现有logs初始:{"logs": ["start"]} → 执行后:{"logs": ["start", "step 1 completed"]}
-
add_messages:消息列表专用(处理消息去重 / 更新)from typing import Annotated
from langgraph.graph.message import add_messages
from langchain_core.messages import AnyMessageclass State(TypedDict):
messages: Annotated[List[AnyMessage], add_messages] # 智能合并消息def add_ai_message(state: State) -> dict:
from langchain_core.messages import AIMessage
return {"messages": [AIMessage(content="Hello!")]} # 自动追加新消息 -
**自定义 Reducer:**根据业务需求定义更新逻辑(如重要消息置顶)。
from typing import Annotated
自定义Reducer:带"important"标签的消息置顶
def priority_adder(current: List[dict], new: List[dict]) -> List[dict]:
for item in new:
if "important" in item.get("tags", []):
current.insert(0, item) # 置顶
else:
current.append(item) # 普通追加
return currentclass State(TypedDict):
notifications: Annotated[List[dict], priority_adder] # 使用自定义Reducer -
MessagesState(对话场景专用) : 预定义状态类,内置
messages字段和add_messagesReducer,可直接扩展。from langgraph.graph import MessagesState
class ChatState(MessagesState):
user_id: str # 扩展字段:用户ID
topic: str = "" # 扩展字段:对话主题节点:添加消息并更新主题
def update_chat(state: ChatState) -> dict:
from langchain_core.messages import HumanMessage
return {
"messages": [HumanMessage(content="讨论AI应用")],
"topic": "AI应用"
}
创建步骤序列-add_sequence
Sequence 是 LangGraph 中最基础的工作流模式,指节点按固定顺序依次执行的线性流程。每个节点完成后,状态会传递给下一个节点,直到所有节点执行完毕。
适用于步骤固定的场景,如:数据预处理→模型推理→结果格式化、多轮工具调用的依次执行等。
LangGraph 有两种方式定义节点顺序:
-
方式 1:手动添加节点和边(基础方式)
from langgraph.graph import START, StateGraph
1. 初始化图(绑定状态类型)
builder = StateGraph(State)
2. 添加节点(节点名默认为函数名,如"step_1")
builder.add_node(step_1) # 等价于 builder.add_node("step_1", step_1)
builder.add_node(step_2)
builder.add_node(step_3)3. 定义执行顺序:START → step_1 → step_2 → step_3
builder.add_edge(START, "step_1") # 起始点连接第一个节点
builder.add_edge("step_1", "step_2") # 节点1执行完→节点2
builder.add_edge("step_2", "step_3") # 节点2执行完→节点34. 编译图(生成可执行对象)
graph = builder.compile()
-
方式2:使用
add_sequence简化(推荐)一行代码添加序列节点,自动按列表顺序连接
builder = StateGraph(State).add_sequence([step_1, step_2, step_3])
builder.add_edge(START, "step_1") # 只需指定起始点graph = builder.compile()
分支机制(Branches)
LangGraph 支持通过分支机制实现节点的并行执行、条件路由等复杂工作流,核心包括并行执行 、延迟执行 和条件分支三种模式。
一、并行执行节点(Parallel Execution)
通过 "扇出(fan-out)→ 扇入(fan-in)" 机制让多个节点同时执行,提升工作流效率,适用于可并行处理的任务(如多源数据获取、并行计算等)。
-
实现核心:
-
扇出:从一个节点同时连接到多个节点(如 A → B 和 A → C);
-
扇入:多个节点的输出汇聚到同一个后续节点(如 B → D 和 C → D);
-
聚合规则 :通过
reducer定义并行节点的状态合并方式(如列表拼接)。
-
-
关键代码示例:
示例:A → B/C (并行) → D
builder = StateGraph(State)
builder.add_edge("a", "b") # 并行分支1
builder.add_edge("a", "c") # 并行分支2
builder.add_edge("b", "d") # 汇聚点
builder.add_edge("c", "d") # 汇聚点
二、延迟执行节点(Defer Execution)
当分支长度不同时(如一条分支多一个节点),让后续节点等待所有前置分支完成后再执行,避免因分支进度不一致导致的状态不完整。
-
实现核心:对需要等待的节点设置
defer=True,使其延迟执行,直到所有指向它的前置节点(包括长分支)都完成。 -
关键代码示例:
在并行执行示例基础上,给B添加一个子节点B_2
def b_2(state: State): return {"aggregate": ["B_2"]}
builder = StateGraph(State)
builder.add_node(a)
builder.add_node(b)
builder.add_node(b_2) # B的后续节点
builder.add_node(c)
builder.add_node(d, defer=True) # D延迟执行,等待所有前置完成分支结构:A→B→B_2→D,A→C→D
builder.add_edge(START, "a")
builder.add_edge("a", "b")
builder.add_edge("a", "c")
builder.add_edge("b", "b_2")
builder.add_edge("b_2", "d")
builder.add_edge("c", "d")
builder.add_edge("d", END)graph = builder.compile()
graph.invoke({"aggregate": []})输出:['A', 'B', 'C', 'B_2', 'D'](D等待B_2完成后执行)
三、条件分支(Conditional Branching)
根据运行时的状态动态选择执行路径,适用于需要根据输入或中间结果决策的场景(如根据用户问题类型路由到不同处理节点)。
-
实现核心:使用
add_conditional_edges定义条件路由函数,根据状态返回下一步节点名称(可返回单个或多个节点)。 -
动态路由:
class State(TypedDict):
which: str # 决策字段def conditional_edge(state: State) -> Literal["b", "c"]:
return state["which"] # 动态路由builder.add_conditional_edges("a", conditional_edge)
-
单/多分支路由:
def route_nodes(state: State) -> Sequence[str]:
if state["type"] == "complex":
return ["c", "d"] # 多分支
return ["b"] # 单分支
MapReduce 模式
在 LangGraph 中,Map-Reduce 是一种通过并行处理子任务(Map 阶段) 再聚合结果(Reduce 阶段) 的工作流模式,适用于需要批量处理多个相似任务并汇总结果的场景(如多文档摘要、多源数据整合等)。其核心通过 Send API 实现动态扇出(Fan-out)并行任务,再通过汇聚节点完成结果合并。
-
代码示例
import operator
from typing import Annotated
from langchain_openai import ChatOpenAI
from typing_extensions import TypedDict
from langgraph.types import Send
from langgraph.graph import END, StateGraph, START
from pydantic import BaseModel, Field"""
生成与{topic}相关的1到3个示例的逗号分隔列表。
生成一个关于{subject}的笑话
下面是一些关于{topic}的笑话。选择最好的一个!返回最佳的ID。
{jokes}
"""subjects_prompt = """Generate a comma separated list of between 1 and 3 examples related to: {topic}."""
joke_prompt = """Generate a joke about {subject}"""
best_joke_prompt = """Below are a bunch of jokes about {topic}. Select the best one! Return the ID of the best one.
{jokes}"""class Subjects(BaseModel):
subjects: list[str]class Joke(BaseModel):
joke: strclass BestJoke(BaseModel):
id: int = Field(description="Index of the best joke, starting with 0")from dotenv import load_dotenv
load_dotenv()
model = ChatOpenAI(model="gpt-4o-mini")class OverallState(TypedDict):
topic: str
subjects: list
jokes: Annotated[list, operator.add]
best_selected_joke: strclass JokeState(TypedDict):
subject: strdef generate_topics(state: OverallState):
prompt = subjects_prompt.format(topic=state["topic"])
response = model.with_structured_output(Subjects).invoke(prompt)
return {"subjects": response.subjects}def generate_joke(state: JokeState):
prompt = joke_prompt.format(subject=state["subject"])
response = model.with_structured_output(Joke).invoke(prompt)
return {"jokes": [response.joke]}def continue_to_jokes(state: OverallState):
return [Send("generate_joke", {"subject": s}) for s in state["subjects"]]"""for循环与列表推导式 以时间换空间的方式 python没有真正意义上的多线程"""
def best_joke(state: OverallState):
jokes = "\n\n".join(state["jokes"])
prompt = best_joke_prompt.format(topic=state["topic"], jokes=jokes)
response = model.with_structured_output(BestJoke).invoke(prompt)
return {"best_selected_joke": state["jokes"][response.id]}graph = StateGraph(OverallState)
graph.add_node("generate_topics", generate_topics)
graph.add_node("generate_joke", generate_joke)
graph.add_node("best_joke", best_joke)graph.add_edge(START, "generate_topics")
graph.add_conditional_edges("generate_topics", continue_to_jokes, ["generate_joke"])
graph.add_edge("generate_joke", "best_joke")
graph.add_edge("best_joke", END)
app = graph.compile()from IPython.display import Image
Image(app.get_graph().draw_mermaid_png(output_file_path='./img/示例4.png'))
Call the graph: here we call it to generate a list of jokes
for s in app.stream({"topic": "animals"}):
print(s)
两个关键阶段:
def generate_joke(state: JokeState):
prompt = joke_prompt.format(subject=state["subject"])
response = model.with_structured_output(Joke).invoke(prompt)
return {"jokes": [response.joke]}
def continue_to_jokes(state: OverallState):
return [Send("generate_joke", {"subject": s}) for s in state["subjects"]]-
Map 阶段:将一个总任务拆分为多个子任务,并行执行(如为每个子项生成结果);
-
generate_joke:将主任务分解为多个子任务
-
continue_to_jokes:使用 Send API 动态创建并行任务
class OverallState(TypedDict):
topic: str
subjects: list
jokes: Annotated[list, operator.add]
best_selected_joke: strdef best_joke(state: OverallState):
jokes = "\n\n".join(state["jokes"])
prompt = best_joke_prompt.format(topic=state["topic"], jokes=jokes)
response = model.with_structured_output(BestJoke).invoke(prompt)
return {"best_selected_joke": state["jokes"][response.id]}
-
-
Reduce 阶段:收集所有子任务的结果,进行汇总、筛选或加工(如从多个结果中选最优)。
-
jokes 字段:通过 operator.add 规约器实现并行结果的自动拼接,确保多个子任务的输出被合并。
-
best_joke:从聚合的jokes中筛选最优结果。
-
循环控制机制
循环结构的三要素
builder.add_edge(START, "a") # 入口节点
builder.add_conditional_edges("a", route) # 条件分支
builder.add_edge("b", "a") # 循环回边-
入口节点:工作流起点
-
条件分支:决定继续循环或退出
-
循环回边:实现节点间循环
终止条件实现
def route(state: State) -> Literal["b", END]:
if len(state["aggregate"]) < 7: # 终止条件判断
return "b" # 继续循环
else:
return END # 退出循环递归深度控制
若终止条件可能无法满足(如逻辑漏洞),需设置递归限制(recursion limit),规定最大执行步数(超级步骤),超过则抛出异常。
from langgraph.errors import GraphRecursionError
try:
# 设置递归限制为4(最多执行4个超级步骤)
graph.invoke({"aggregate": []}, {"recursion_limit": 4})
except GraphRecursionError:
print("Recursion Error: 超过最大执行步数")可视化图
LangGraph 提供了多种方式可视化工作流图,帮助开发者调试、展示节点关系和执行流程。核心支持 Mermaid 语法生成 和 PNG 图像渲染,适用于不同场景(如文档嵌入、调试分析)。
Mermaid 语法生成
Mermaid 是一种文本驱动的图表描述语言,可生成流程图、时序图等。LangGraph 可直接将图转换为 Mermaid 语法,便于嵌入文档或通过 Mermaid 工具渲染。
-
代码示例:
生成 Mermaid 流程图语法
mermaid_code = graph.get_graph().draw_mermaid()
print(mermaid_code) -
生成示例:
%%{init: {'flowchart': {'curve': 'linear'}}}%%
graph TD;
start([start
]):::first
entry_node(entry_node)
node_entry_node_A(node_entry_node_A)
end([end
]):::last
start --> entry_node;
entry_node --> end;
entry_node --> node_entry_node_A;
node_entry_node_A -.-> entry_node; # 虚线表示条件边
classDef default fill:#f2f0ff,line-height:1.2
PNG 图像渲染
若需要图片格式(如用于报告、演示),LangGraph 支持通过多种工具生成 PNG 图像,以下是三种常用方式:
1. 基于 Mermaid.ink API
Mermaid.ink 是一个免费的在线 Mermaid 渲染服务,LangGraph 可直接调用该 API 生成 PNG,无需安装本地工具。
-
代码示例:
from IPython.display import Image, display
生成 PNG 并显示(默认使用 Mermaid.ink)
png_data = graph.get_graph().draw_mermaid_png()
display(Image(png_data)) -
生成示例:
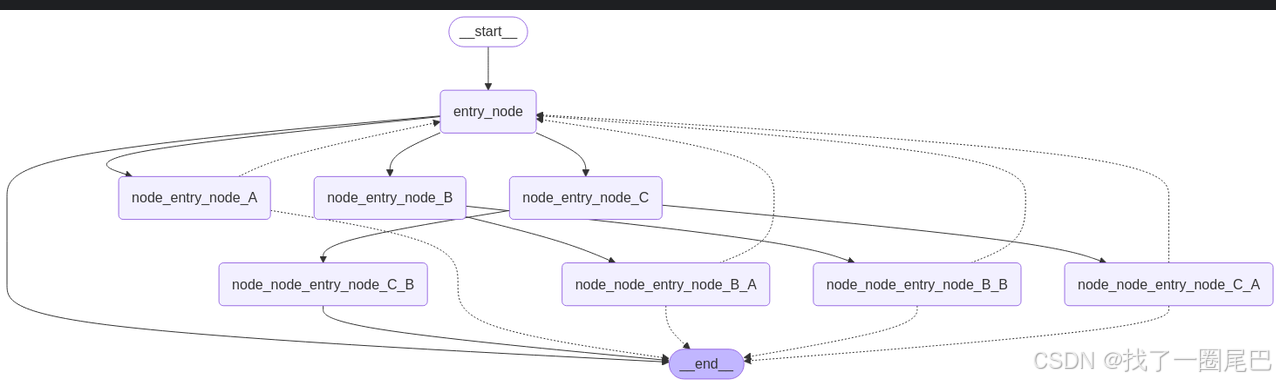
2. 基于 Mermaid + Pyppeteer
通过 Pyppeteer(Headless Chrome 工具)在本地渲染 Mermaid 语法为 PNG,支持更多自定义选项(如节点颜色、背景色)。
-
安装依赖
pip install pyppeteer nest-asyncio # nest-asyncio 用于 Jupyter 环境
-
代码示例:
import nest_asyncio
from langchain_core.runnables.graph import CurveStyle, NodeStyles, MermaidDrawMethod
from IPython.display import Image, displaynest_asyncio.apply() # Jupyter 环境需启用异步支持
自定义样式:线条类型、节点颜色、背景等
png_data = graph.get_graph().draw_mermaid_png(
curve_style=CurveStyle.LINEAR, # 线条样式:线性
node_colors=NodeStyles(
first="#ffdfba", # 起始节点颜色
last="#baffc9", # 终止节点颜色
default="#fad7de" # 默认节点颜色
),
background_color="white", # 背景色
padding=10, # 边距
draw_method=MermaidDrawMethod.PYPPETEER # 使用 Pyppeteer 本地渲染
)
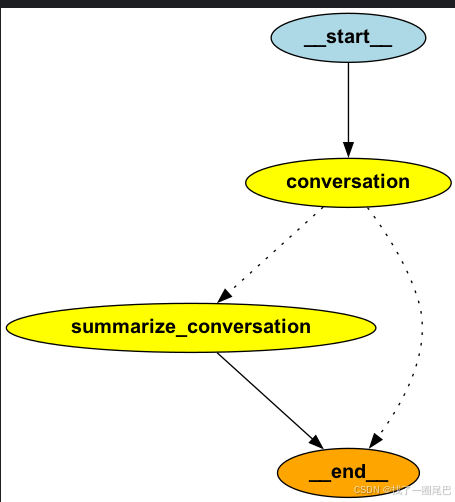
display(Image(png_data)) -
生成示例:
3.基于 Graphviz
Graphviz 是一款强大的开源绘图工具,LangGraph 可通过 pygraphviz 库调用其生成 PNG,适合复杂图的精细化展示。
-
安装依赖
-
安装 Graphviz 软件(官网);
-
安装 Python 依赖:
pip install pygraphviz
-
-
代码示例:
from IPython.display import Image, display
try:
png_data = graph.get_graph().draw_png() # 直接生成 PNG
display(Image(png_data))
except ImportError:
print("请安装 pygraphviz 和 Graphviz 工具")
适用场景总结
|---------------------|-------------|------------|----------------|
| 可视化方式 | 优点 | 缺点 | 适用场景 |
| Mermaid 语法 | 轻量、跨平台、易存储 | 需工具渲染才能可视化 | 文档嵌入、版本控制、快速分享 |
| Mermaid.ink API | 零依赖、快速生成 | 依赖网络、样式有限 | 临时调试、简单展示 |
| Mermaid + Pyppeteer | 本地渲染、样式丰富 | 需安装依赖 | 自定义需求高的本地展示 |
| Graphviz | 复杂图布局优、格式多样 | 安装复杂 | 专业报告、复杂工作流展示 |