1. 硬件信息查看的起点:为什么你得先摸清家底?
想要在 Linux 系统里排查硬件问题,第一步不是直接修,而是搞清楚你手头的设备到底是个啥情况。硬件信息就像一张地图,告诉你 CPU、内存、磁盘、网络接口等每个部件的现状。没有这张地图,你就是在盲人摸象,修来修去可能越修越乱。
Linux 提供了不少工具帮你摸清硬件底细,比如 lscpu、lsblk、dmidecode 和 lspci,这些都是你的"探照灯"。
用 lscpu 看 CPU 的"身份证"
跑个 lscpu,你就能看到 CPU 的详细信息,比如架构、核心数、频率,甚至缓存大小。假设你在排查一台服务器性能瓶颈,lscpu 能告诉你是不是 CPU 型号太老,或者核心数不够用。比如:
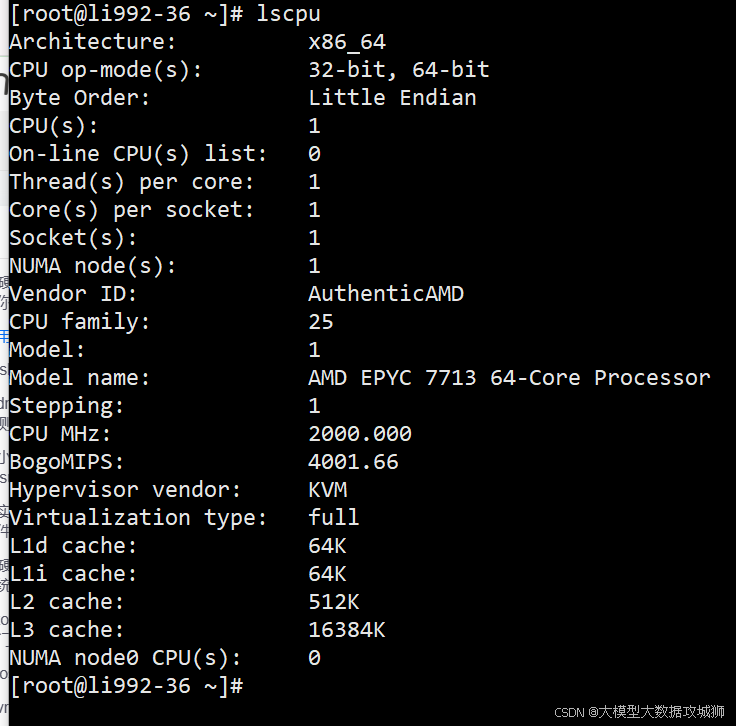 看重点:CPU(s) 表示逻辑核心数,Thread(s) per core 告诉你有没有超线程,CPU MHz 看当前频率。如果频率长期偏低(比如卡在 1200MHz 而最大是 3000MHz),可能触发了降频机制,后面咱们会讲怎么查原因。
看重点:CPU(s) 表示逻辑核心数,Thread(s) per core 告诉你有没有超线程,CPU MHz 看当前频率。如果频率长期偏低(比如卡在 1200MHz 而最大是 3000MHz),可能触发了降频机制,后面咱们会讲怎么查原因。
lsblk:磁盘和分区的"全家福"
磁盘问题是最常见的硬件故障之一,lsblk 是你的好帮手,用来查看块设备(硬盘、SSD、U盘等)和它们的分区情况。比如:
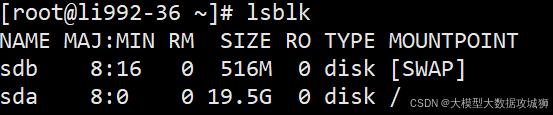
关键点:SIZE 告诉你设备容量,MOUNTPOINT 显示挂载点。如果某个磁盘没出现在列表里,可能硬件没识别,或者挂载有问题。记下来,后面会用到。
dmidecode:硬件的"DNA 检测"
如果你需要更详细的硬件信息,比如主板型号、BIOS 版本、内存条的厂商,dmidecode 是神器。它从系统的 DMI(Desktop Management Interface)表里提取信息。注意,运行这个命令通常需要 root 权限:
$ sudo dmidecode -t memory
# dmidecode 3.2
Getting SMBIOS data from sysfs.
SMBIOS 3.0.0 present.
Handle 0x0020, DMI type 17, 84 bytes
Memory Device
Manufacturer: Samsung
Serial Number: 12345678
Part Number: M393A2K43BB1-CRC
Size: 16384 MB
Form Factor: DIMM
Speed: 2400 MHz
Type: DDR4用处:如果怀疑内存条有问题,dmidecode -t memory 可以告诉你每条内存的品牌、速度和插槽位置,方便定位坏掉的那根。
小技巧:别忘了 lspci 和 lsusb
想知道 PCIe 设备(比如显卡、网卡)的情况?用 lspci:
$ lspci
00:1f.2 SATA controller: Intel Corporation 6 Series/C200 Series Chipset Family SATA AHCI Controller
01:00.0 Ethernet controller: Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network ConnectionUSB 设备(比如外接硬盘、键盘)用 lsusb:
$ lsusb
Bus 002 Device 003: ID 0781:5583 SanDisk Corp. Ultra Fit
Bus 001 Device 002: ID 046d:c077 Logitech, Inc. M105 Optical Mouse这些命令帮你确认硬件是否被系统正确识别。如果设备没出现在列表里,可能是驱动问题或硬件故障,后面会细说怎么排查。
实践案例:服务器卡顿,硬件信息怎么帮你?
假设你接手一台卡顿的 Linux 服务器,怀疑是硬件问题。第一步,跑 lscpu 看 CPU 频率是否异常;再用 lsblk 确认所有磁盘是否正常挂载;最后用 dmidecode -t memory 检查内存条是否一致(混用不同频率的内存可能导致性能问题)。这些信息就像拼图,帮你快速锁定问题范围。
2. 硬件监控的"眼睛":实时掌握系统状态
光知道硬件规格还不够,排查故障得看硬件的实时状态。Linux 下有不少工具能让你"盯着"硬件的运行情况,比如 top、htop、iostat 和 vmstat,它们能告诉你 CPU、内存、磁盘 I/O 的使用情况。
top 和 htop:性能监控的入门级神器
top 是 Linux 自带的性能监控工具,实时显示系统资源占用:
$ top
top - 19:25:43 up 2 days, 3:12, 1 user, load average: 0.45, 0.67, 0.72
Tasks: 190 total, 1 running, 189 sleeping, 0 stopped, 0 zombie
%Cpu(s): 5.2 us, 3.1 sy, 0.0 ni, 91.5 id, 0.2 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 16372160 total, 234560 free, 12837600 used, 3300000 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 3123456 avail Mem解读:
-
load average:系统负载,三个数字分别表示过去 1、5、15 分钟的平均负载。如果数字高于 CPU 核心数,说明系统压力大。
-
%Cpu(s):us(用户进程)、sy(系统进程)、wa(等待 I/O)是关键。如果 wa 高,说明磁盘 I/O 可能有瓶颈。
-
Mem:内存使用情况,free 少不一定有问题,Linux 会尽量用 buff/cache 缓存数据。
htop 是 top 的升级版,界面更友好,支持鼠标操作,推荐安装(sudo apt install htop 或 sudo yum install htop)。它能直观显示每个进程的资源占用,方便定位"吃资源"的家伙。
iostat:磁盘性能的"心电图"
磁盘读写慢是常见问题,iostat(需要安装 sysstat 包)能告诉你磁盘的性能表现:
$ iostat -dx 1
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 10.00 20.00 800.00 1600.00 80.00 0.50 15.00 10.00 20.00 5.00 15.00重点看:
-
%util:磁盘利用率,接近 100% 说明磁盘忙得喘不过气。
-
await:平均 I/O 等待时间,单位毫秒,值越高说明磁盘越慢。
-
rkB/s 和 wkB/s:读写速度,单位 KB/s,帮你判断磁盘是否达到预期性能。
vmstat:系统资源的"全景图"
vmstat 提供 CPU、内存、I/O 的综合信息,适合快速概览:
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 234560 123456 3300000 0 0 800 1600 500 1000 5 3 91 1 0关注:
-
r 和 b:运行和阻塞的进程数,b 高说明 I/O 有瓶颈。
-
si 和 so:交换分区读写,值不为 0 说明内存不足,系统在用 swap。
-
bi 和 bo:块设备读写,单位是块/秒,结合 iostat 能更精准定位问题。
实践案例:排查高负载的"元凶"
假设一台服务器负载很高(load average 超过核心数),你可以用 htop 找到占用 CPU 或内存的进程,再用 iostat 检查磁盘是否繁忙。如果 iostat 显示 %util 接近 100%,说明磁盘可能是瓶颈,接下来可以用 fio 测试磁盘性能(后面会讲)。如果内存占用高,vmstat 的 si/so 不为 0,可能需要加内存条了。
3. 日志:硬件故障的"黑匣子"
硬件出问题,系统日志就是你的"黑匣子",记录了设备初始化、错误和警告。Linux 的日志文件和工具(比如 dmesg 和 journalctl)能帮你找到线索。
dmesg:硬件初始化的"第一手资料"
dmesg 显示内核日志,特别适合排查硬件相关问题,比如设备驱动加载失败、磁盘错误等:
$ dmesg | grep -i error
[ 2.345678] ata1: SATA link up 6.0 Gbps (SStatus 133 SControl 300)
[ 2.345690] ata1.00: failed to read native max address (err_mask=0x4)解读:这段日志提示 SATA 磁盘有错误(err_mask=0x4),可能是连接问题或磁盘坏了。可以用 smartctl(后面会讲)进一步检查。
小技巧:用 dmesg -w 实时监控日志,插拔设备时能立刻看到系统反应。
journalctl:系统日志的"全能选手"
journalctl 是 systemd 的日志工具,覆盖系统和硬件相关事件:
$ journalctl -p 3 -xb
-- Logs begin at Mon 2025-07-01 09:00:00 UTC, end at Sun 2025-08-10 19:30:00 UTC. --
Aug 10 19:25:43 server1 kernel: EXT4-fs error (device sda3): ext4_find_entry:1314: inode #123456: comm rsync: reading directory lblock 0重点:-p 3 过滤错误级别的日志,-xb 显示最近一次启动的日志。如果看到类似上面的 EXT4 文件系统错误,说明磁盘可能有坏块,赶紧用 fsck 检查(后面会细说)。
日志过滤技巧
日志信息多得像大海捞针,学会过滤很重要:
-
用 grep 筛选关键词:dmesg | grep -i 'disk\|sata\|usb'。
-
限制时间范围:journalctl --since "2025-08-10 18:00"。
-
关注硬件相关模块:journalctl | grep -i 'kernel\|udev\|sata'。
实践案例:硬盘掉线的"侦探游戏"
假设一台服务器的 /data 挂载点突然不可用,lsblk 确认磁盘还在,但 dmesg 显示:
[12345.678901] sd 0:0:0:0: [sdb] Medium access timeout
[12345.678920] sd 0:0:0:0: [sdb] Device not ready这提示磁盘可能掉线,可能是 SATA 线松了或磁盘硬件故障。下一步,检查物理连接,或者用 smartctl 查看磁盘健康状态。
4. 磁盘故障排查:从"慢"到"坏"的应对策略
磁盘问题可能是性能瓶颈的罪魁祸首,也可能是数据丢失的元凶。Linux 下有工具帮你从性能测试到健康检查,全面诊断磁盘。
用 fio 测试磁盘性能
fio 是个强大的磁盘性能测试工具,能模拟不同负载(顺序读写、随机读写)。先安装(sudo apt install fio),然后跑个简单测试:
$ fio --name=randread --rw=randread --bs=4k --size=1G --numjobs=1 --iodepth=32 --runtime=60 --time_based --group_reporting
randread: (g=0): rw=randread, bs=4K, size=1G, ioengine=libaio, iodepth=32
fio-3.16
Starting 1 process
Jobs: 1 (f=1): [r(1)] [100.0% done] [150.2MB/s] [38.5K IOPS]
randread: (groupid=0, jobs=1): err= 0: pid=12345
read: IOPS=38500, BW=150.2MiB/s解读:
-
IOPS:每秒 I/O 操作数,衡量随机读写性能。
-
BW:带宽,衡量顺序读写速度。
-
如果 IOPS 很低(比如低于 1000),可能磁盘老化或控制器有问题。
smartctl:检查磁盘健康
smartctl(来自 smartmontools 包)可以查看磁盘的 SMART 数据,告诉你磁盘是否快"挂"了:
$ sudo smartctl -a /dev/sda
smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.4.0-42-generic] (local build)
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Red
Device Model: WDC WD40EFRX-68N32N0
Serial Number: WD-WCC7K1YH1234
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED关键指标:
-
Reallocated_Sector_Ct:坏块数量,值不为 0 说明磁盘开始坏了。
-
Wear_Leveling_Count(SSD 专用):磨损程度,接近 100% 说明 SSD 寿命快到头。
-
Current_Pending_Sector:等待重新分配的扇区,值高说明磁盘有潜在问题。
操作建议:如果 smartctl -t short /dev/sda 跑短测试后显示错误,赶紧备份数据,考虑换盘。
fsck:修复文件系统
如果日志提示文件系统错误(比如 EXT4 错误),可以用 fsck 检查和修复:
$ sudo fsck /dev/sda3
fsck from util-linux 2.34
e2fsck 1.45.6 (20-Mar-2020)
/dev/sda3: recovering journal
/dev/sda3: Clean, 123456/52428800 files, 9876543/209715200 blocks注意:fsck 必须在磁盘未挂载时运行,否则可能损坏数据。可以用 umount /dev/sda3 卸载,或者在单用户模式下操作。
实践案例:磁盘读写慢的"急诊室"
一台服务器的 /home 目录访问很慢,iostat 显示 await 高达 50ms,%util 接近 90%。用 fio 测试发现随机读 IOPS 只有 500,远低于预期。跑 smartctl -a /dev/sda 发现 Reallocated_Sector_Ct 为 128,说明磁盘有坏块。解决方案:备份数据,换新盘,恢复数据。
5. 网络硬件排查:当"网速慢"不是运营商的锅
网络问题是 Linux 服务器运维中的常见"头疼病",可能是网卡硬件故障、驱动问题,也可能是配置错误。别急着怪运营商,先用 Linux 工具把自家网络硬件的底细摸清楚。
用 ethtool 摸清网卡状态
ethtool 是诊断网卡的利器,能告诉你网卡的连接状态、速度、双工模式等。运行以下命令查看:
$ sudo ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 1
Transceiver: internal
Auto-negotiation: on
Link detected: yes关键点:
-
Speed:当前网卡速度。如果显示 100Mb/s 但你预期是 1000Mb/s,可能是网线质量差或交换机配置问题。
-
Duplex:双工模式,Full 表示全双工,Half 会严重影响性能。
-
Link detected:如果显示 no,说明网卡没连上,检查网线或交换机端口。
小技巧:用 ethtool -S eth0 查看网卡统计信息,比如丢包率(rx_errors 或 tx_errors),如果数值不断增加,说明网卡或网络有问题。
ip 和 ifconfig:网络接口的"体检表"
ip 命令是现代 Linux 系统中查看网络接口的首选工具(ifconfig 虽老但仍常用):
$ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 00:15:5d:01:02:03 brd ff:ff:ff:ff:ff:ff解读:state UP 表示接口正常工作,LOWER_UP 表示物理层连接正常。如果 state DOWN,可能是网卡被禁用(用 sudo ip link set eth0 up 启用)或硬件故障。
用 ping 和 iperf 测试网络性能
ping 是最简单的网络连通性测试工具,但别只盯着是否通,还要看延迟和丢包率:
$ ping -c 4 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=117 time=25.3 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=117 time=25.5 ms
...
--- 8.8.8.8 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3004ms
rtt min/avg/max/mdev = 25.321/25.467/25.612/0.123 ms如果丢包率高或延迟波动大,可能是网卡硬件或驱动问题。进一步用 iperf 测试带宽(需安装 iperf3):
$ iperf3 -c 192.168.1.100
Connecting to host 192.168.1.100, port 5201
[ 5] local 192.168.1.101 port 12345 connected to 192.168.1.100 port 5201
[ ID] Interval Transfer Bitrate
[ 5] 0.00-10.00 sec 1.10 GBytes 940 Mbits/sec提示:如果带宽远低于预期(比如千兆网卡只跑出 100Mbit/s),检查网卡速度(ethtool)和网线质量。
日志中的网络线索
网络问题也可能在 dmesg 或 journalctl 中留下痕迹,比如驱动加载失败或中断异常:
$ dmesg | grep -i eth0
[ 2.123456] e1000e: eth0 NIC Link is Up 1000 Mbps Full Duplex
[ 1234.567890] e1000e 0000:01:00.0 eth0: Detected Hardware Unit Hang解读:Detected Hardware Unit Hang 提示网卡硬件或驱动有问题,可能需要更新驱动或更换网卡。
实践案例:网速慢的"破案之旅"
一台服务器下载文件慢得像乌龟爬,ethtool eth0 显示速度只有 100Mb/s,但网卡支持 1000Mb/s。检查网线发现是 Cat5 而非 Cat5e,更换后速度恢复正常。再跑 iperf3,确认带宽达到 940Mb/s,问题解决。如果速度仍不正常,可能需要更新网卡驱动(用 modprobe 重新加载模块)。
6. CPU 故障排查:当"核心"不给力
CPU 是服务器的"大脑",一旦出问题,系统可能直接卡死或性能暴跌。排查 CPU 问题需要关注温度、频率、负载和硬件错误。
检查 CPU 温度:别让"大脑"过热
过热是 CPU 故障的常见原因,用 sensors(需安装 lm-sensors)查看温度:
$ sensors
coretemp-isa-0000
Adapter: ISA adapter
Package id 0: +45.0°C (high = +80.0°C, crit = +90.0°C)
Core 0: +43.0°C (high = +80.0°C, crit = +90.0°C)
Core 1: +44.0°C (high = +80.0°C, crit = +90.0°C)注意:如果温度接近或超过 crit 值(比如 90°C),CPU 可能触发降频保护,导致性能下降。检查散热器是否积尘,或风扇是否正常工作。
小技巧:用 watch -n 1 sensors 每秒刷新温度,观察负载变化时的温度波动。
频率异常:CPU 为啥"偷懒"?
用 lscpu 或 cat /proc/cpuinfo 检查 CPU 频率:
$ cat /proc/cpuinfo | grep "cpu MHz"
cpu MHz : 1200.000
cpu MHz : 1200.000如果频率远低于标称最大值(比如标称 3.0GHz,但实际只有 1.2GHz),可能是以下原因:
-
省电模式:检查 /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor,如果显示 powersave,用 echo performance | sudo tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor 切换到性能模式。
-
过热降频:结合 sensors 确认温度。
-
BIOS 设置:某些服务器 BIOS 限制了 CPU 性能,需进入 BIOS 检查。
用 stress 测试 CPU 稳定性
想知道 CPU 是否稳定?用 stress(需安装)模拟高负载:
$ stress --cpu 8 --timeout 60
stress: info: [12345] dispatching hogs: 8 cpu, 0 io, 0 vm, 0 hdd跑 60 秒后,观察 dmesg 是否有错误(比如 Machine Check Exception),或用 htop 看 CPU 使用率是否正常。如果系统卡死或报错,CPU 可能有硬件问题。
实践案例:CPU 性能"失踪"之谜
一台服务器运行慢,lscpu 显示频率卡在 1.2GHz,sensors 温度高达 85°C。清理散热器后温度降到 50°C,频率恢复到 2.8GHz,性能正常。如果清理无效,可能需要检查主板或更换 CPU。
7. 内存故障排查:当"记忆"开始出错
内存问题可能导致系统崩溃、进程被杀死或性能下降。Linux 提供了工具帮你检测内存故障和使用情况。
用 memtester 测试内存
memtester 可以在用户空间测试内存稳定性(需安装):
$ sudo memtester 1024 5
memtester version 4.5.1 (64-bit)
pagesize is 4096
want 1024MB (1073741824 bytes)
got 1024MB (1073741824 bytes), trying mlock ...locked.
Loop 1/5:
Stuck Address : ok
Random Value : ok
Compare XOR : ok
Compare SUB : ok
...解读:如果测试报告错误(比如 Stuck Address: FAIL),说明内存条可能有坏块,建议更换。
注意:memtester 只测试分配的内存,建议搭配 memtest86+(需重启进入专用测试环境)做全面检测。
检查内存使用情况
用 free -m 查看内存占用:
$ free -m
total used free shared buff/cache available
Mem: 15984 12560 230 100 3194 3045
Swap: 2047 0 2047关注:
-
available:实际可用内存,低于 100MB 可能导致性能问题。
-
Swap:如果 used 不为 0,说明内存不足,进程开始用交换分区。
如果内存占用高,用 top 或 htop 找出"吃内存"的进程,必要时杀掉(kill -9 <pid>)。
日志中的内存线索
内存故障可能在 dmesg 中留下记录:
$ dmesg | grep -i memory
[ 1234.567890] Out of memory: Killed process 12345 (python) total-vm:1234567kB解读:Out of memory 说明内存不足,系统触发 OOM Killer 杀进程。解决办法是增加内存或优化进程。
实践案例:随机崩溃的"幕后黑手"
服务器时不时崩溃,dmesg 显示 OOM Killer 频繁触发,free -m 可用内存只有 50MB。跑 memtester 发现内存测试通过,说明不是硬件问题。检查发现是个 Python 脚本内存泄漏,优化代码后问题解决。如果 memtester 报错,就得换内存条了。
8. 电源与散热:硬件健康的"幕后英雄"
电源和散热问题往往被忽略,但它们可能是硬件故障的"隐形杀手"。电源不稳可能导致系统重启,散热不良会让 CPU 或 GPU 降频甚至宕机。Linux 下虽然直接监控电源的工具不多,但通过一些间接方法和硬件日志,你能揪出这些"幕后黑手"。
检查电源状态
Linux 下可以用 upower 或 acpi 查看电源相关信息(需安装相应包)。比如用 upower 检查 UPS 或电池状态:
$ upower -i /org/freedesktop/UPower/devices/battery_BAT0
native-path: BAT0
vendor: SMP
model: DELL XYZ123
serial: 1234
power supply: yes
updated: Sun 10 Aug 2025 07:30:00 PM PDT
has history: yes
has statistics: yes
battery
present: yes
state: discharging
energy: 45.6 Wh
energy-full: 50.4 Wh
energy-rate: 12.3 W
voltage: 11.4 V
time to empty: 3.7 hours
percentage: 90%关键点:如果 state 显示 discharging 且 energy-rate 异常高,说明电源消耗过快,可能是硬件负载过高或电源模块故障。对于服务器,检查 dmesg 是否有电源相关错误:
$ dmesg | grep -i power
[ 2.123456] ACPI: Power Resource [PRWF] (on)
[ 1234.567890] power_supply BAT0: failed to update status解读:如果看到类似 failed to update status,可能是电源管理模块有问题,检查物理连接或更新固件。
散热问题排查
散热问题通常通过 CPU 或主板温度反映出来,用 sensors(需安装 lm-sensors)监控:
$ sensors
coretemp-isa-0000
Adapter: ISA adapter
Package id 0: +55.0°C (high = +80.0°C, crit = +90.0°C)
Core 0: +53.0°C (high = +80.0°C, crit = +90.0°C)
Core 1: +54.0°C (high = +80.0°C, crit = +90.0°C)
fan1: 1200 RPM (min = 1000 RPM)
fan2: 1100 RPM (min = 1000 RPM)关注:
-
温度:如果接近 crit(如 90°C),说明散热不足,检查风扇或散热片。
-
风扇转速:fan1 和 fan2 显示转速,低于 min 值可能风扇故障。
小技巧:用 watch -n 1 sensors 实时监控温度和风扇转速,结合 stress --cpu 8 测试高负载下的散热表现。
日志中的电源与散热线索
电源或散热问题可能在 dmesg 或 journalctl 中留下记录:
$ journalctl -p 3 -xb | grep -i thermal
Aug 10 19:25:43 server1 kernel: CPU0: Core temperature above threshold, cpu clock throttled (total events = 123)解读:cpu clock throttled 表示 CPU 因过热降频,赶紧检查散热器是否积尘或风扇是否停转。
实践案例:服务器莫名重启的"电源疑云"
一台服务器经常无故重启,journalctl -p 3 -xb 显示 ACPI: Power Button: Power Button pressed,但没人碰过电源键。检查 dmesg,发现电源模块多次报告 under-voltage。最终确认是电源供电不足,更换更高功率的电源后问题解决。如果日志没线索,可能是主板或 PSU 硬件故障,需进一步测试。
9. BIOS 与固件:硬件的"底层逻辑"
BIOS 或 UEFI 固件是硬件与系统之间的桥梁,版本过旧或配置错误可能导致硬件不被识别或性能异常。Linux 下可以通过查看固件信息和更新来排查问题。
用 dmidecode 查看 BIOS 信息
dmidecode -t bios 能告诉你当前 BIOS 版本和厂商信息:
$ sudo dmidecode -t bios
# dmidecode 3.2
Getting SMBIOS data from sysfs.
SMBIOS 3.0.0 present.
Handle 0x0000, DMI type 0, 24 bytes
BIOS Information
Vendor: American Megatrends Inc.
Version: 5.14
Release Date: 03/15/2023
BIOS Revision: 5.14
Firmware Revision: 2.0关键点:如果 BIOS 版本较老(比如几年前的),可能不支持新硬件或有已知 bug,建议去主板厂商官网下载最新固件。
检查固件相关日志
BIOS 问题可能导致硬件初始化失败,dmesg 会记录相关信息:
$ dmesg | grep -i bios
[ 0.000000] BIOS-e820: [mem 0x00000000-0x0009ffff] usable
[ 1.234567] ACPI BIOS Error (bug): Could not resolve symbol [\_SB.PCI0.SAT0.SPT0._GTF.DSSP], AE_NOT_FOUND解读:ACPI BIOS Error 提示 BIOS 可能有 bug,更新到最新版本通常能解决。
更新 BIOS
BIOS 更新需要谨慎,操作不当可能导致系统无法启动。步骤如下:
-
用 dmidecode 确认主板型号(dmidecode -t baseboard)。
-
去厂商官网下载最新 BIOS 固件。
-
在 Linux 下用工具如 fwupd(需安装)更新:
sudo fwupdmgr refresh sudo fwupdmgr update
注意:更新前备份重要数据,确保电源稳定,断电可能"砖"了主板。
实践案例:新硬盘不识别的"BIOS瓶颈"
一台服务器新加的 NVMe SSD 在 lsblk 中看不到,dmesg 显示 nvme0: Device not ready。用 dmidecode -t bios 发现 BIOS 版本是 2019 年的,更新到最新版本后,SSD 正常识别。如果更新无效,可能是主板不支持该型号 SSD,需更换硬件。
10. 综合案例:从"玄学故障"到系统恢复
硬件问题往往不是单一的,可能是多个部件交互导致的"连锁反应"。下面通过一个综合案例,带你从头到尾排查一个复杂问题。
案例背景
一台 Linux 服务器(Ubuntu 20.04)运行数据库应用,最近频繁出现性能下降、随机重启和数据访问缓慢的问题。用户反馈"系统卡得像PPT",管理员需要快速定位并解决问题。
排查步骤
-
初步信息收集:
-
跑 lscpu,发现 CPU 是 Intel Xeon E5-2620 v4,8 核,频率卡在 1.2GHz(标称 3.0GHz)。
-
用 lsblk,确认所有磁盘都挂载正常,但 /data 分区访问慢。
-
用 free -m,发现可用内存只有 200MB,swap 使用了 1GB。
-
-
性能监控:
-
用 htop,发现数据库进程 mysqld 占用 60% 内存和 30% CPU。
-
跑 iostat -dx 1,/dev/sdb(挂载 /data)的 %util 接近 95%,await 高达 60ms。
-
用 sensors,CPU 温度 88°C,接近临界值 90°C。
-
-
日志分析:
-
dmesg | grep -i error 显示:
[12345.678901] EXT4-fs error (device sdb1): ext4_find_entry: reading directory lblock 0 [12346.123456] CPU0: Core temperature above threshold, cpu clock throttled -
journalctl -p 3 -xb 显示 OOM Killer 杀死了一些后台进程。
-
-
硬件测试:
-
用 smartctl -a /dev/sdb,发现 Reallocated_Sector_Ct 为 256,磁盘有坏块。
-
跑 memtester 1024 5,内存测试通过,排除内存硬件问题。
-
用 ethtool eth0,网卡速度正常,无丢包。
-
-
问题定位:
-
磁盘问题:/dev/sdb 有坏块,导致 I/O 瓶颈,影响数据库性能。
-
CPU 过热:温度高导致降频,性能下降。
-
内存不足:可用内存低,触发 OOM Killer,造成进程不稳定。
-
-
解决方案:
-
磁盘:备份 /data 数据,用 fsck /dev/sdb1 修复文件系统,计划更换新磁盘。
-
散热:清理 CPU 散热器,温度降到 50°C,频率恢复到 2.8GHz。
-
内存:优化 mysqld 配置,降低内存占用,计划加装内存条。
-
-
验证:
-
重启后,跑 iostat 确认磁盘 %util 降到 20%,await 降到 5ms。
-
用 sensors 确认温度正常,lscpu 显示频率正常。
-
数据库性能恢复,用户反馈系统流畅。
-
经验总结
这个案例告诉我们,硬件问题往往是多点并发,排查时要"由点到面":
-
先用 lscpu、lsblk、free 摸清硬件状态。
-
用 htop、iostat、sensors 监控实时表现。
-
结合 dmesg 和 journalctl 找线索。
-
针对性测试(smartctl、memtester)锁定问题。
-
综合施策,逐步验证。