目录
一、XML概念和体系
1.XML概念
(1)XML指可扩展标记语言(EXtensible Markup Language)。
(2)XML没有预定义标签,需要自行定义标签。
- 格式:<标签></标签>
2.XML的特点
(1)XML数据以纯文本格式存储;
(2)实现不同应用程序之间的数据通信;
(3)实现不同平台间的数据通信;
(4)实现不同平台间的数据共享;
(5)使用XML将不同的程序、不同的平台之间联系起来;
3.XML的作用
(1)数据存储和数据传递,可以用来做配置文件。
(2)javaEE开发中用xml来作配置文件,SSM,DUBOO分布式框架等等。
4.XML和HTML之间的差异
(1)HTML里面的标签是已经设计好的的,我们需要学习使用。
(2)XML是自己来定义标签,以<标签></标签>格式定义即可。
5.总结
(1)我们学XML的目的是在JavaWeb中使用XML作为配置文件,后期这个XML会作为我们和框架之间的数据传输或者是数据的对接,也就是说通过XML和框架内的数据打交道。
二、标准的XML结构
XML
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="1001">
<name>java开发实战强化</name>
<author>张小三</author>
<price>98.5</price>
</book>
</books>1.上面的的XML标准结构中,根元素是我们自己定义的<books>,它和下面的<book>是父子关系,XML中所有的标签都是我们自己定义的。
2.注意:在XML中我们也可以和HTML中一样给元素加上属性,这个属性是我们自己定义的。
三、由XML文件扩展出来的体系(了解)
1.XHTML:可扩展超文本标记语言。
2.RSS(广泛用于网上新闻频道):Really Simple Syndication,简易信息聚合,使用RSS订阅能更块地获取信息,网站提供RSS输出,有利于让用户获取网站内容的最新更新。
四、XML基本语法
1.写出第一个XML文档
XML
<?xml version="1.0" encoding="UTF-8"?>
<student>
<name id="101">张三</name>
<age>20</age>
<school>长沙市一中</school>
</student>
<!-- <?xml version="1.0" encoding="UTF-8"?>
文档的申明,必须写在xml文档中第一行,对当前xml文件进行约定:
<?xml>文档申明的标签
version:指定解析当前xml文件的xml解析器的版本为1.0
encoding='UTF-8',当前文档的编码类型
-->2.XML的基本语法
(1)有且只有一个根元素;
(2)XML文档声明必须放在文档的第一行;
(3)所有标签必须成对出现;
(4)XML的标签严格区分大小写;
(5)XML元素可以嵌套其他元素;
(6)XML中的属性值必须加引号;
(7)XML中可以应用适当的注释:<!-- -->
3.XML命名规则
(1)名称可以包含字母、数字及其他字符;
(2)名称不能以数字或者标点符号开始;
(3)名称不能以字母xml开始(xml是关键字);
(4)名称不能包含空格,要做到见名知意;
五、XML约束
1.XML约束就是约束我们XML文档中标签的,对标签做一些限制。
2.XML中的约束有两种,一种的DTD,一种是Schema。
(1)DTD:语法自成一派,早期就出现的;可读性比较差。
XML
<?xml version='1.0' encoding='UTF-8'?>
<!DOCTYPE student [
<!ELEMENT student (name,school,age,loc)> <!--指定约束student标签下只能包含子标签:name,age,school,loc四个标签,每个标签只能有一个-->
<!ELEMENT name (#PCDATA)> <!--对name标签的描述,数据类型是:#PCDATA文本类型-->
<!ELEMENT age (#PCDATA)>
<!ELEMENT school (#PCDATA)>
<!ELEMENT loc (#PCDATA)>
]>
<student>
<name>李四</name>
<school>长沙市一中</school>
<age>22</age>
<loc>长沙市岳麓区</loc>
</student>-
引入外部约束:PADATA(Parsed Character DATA)的意思是被解析的字符数据
-
元素的个数
- +:代表一个或多个
- *:代表零个或多个
- ?:代表零个或一个
- 案例:
XML<?xml version='1.0' encoding='UTF-8'?> <!DOCTYPE student SYSTEM "stu.dtd"> <!--引入外部的约束dad文件--> <student> <name>李四</name> <school>长沙市一中</school> <age>22</age> <loc>长沙市岳麓区</loc> <city>北京</city> </student> stu.dtd文件中的内容: <!ELEMENT student (name+,school*,age?,loc,city)> <!--指定约束student标签下只能包含子标签:name,age,school,loc四个标签,而且出现的顺序也要保持一致;name的数量是一个或多个,school的数量是零个或多个,age的数量是零个或一个,loc只能有一个,city只能有一个--> <!ELEMENT name (#PCDATA)> <!--对name标签的描述,数据类型是:#PCDATA文本类型--> <!ELEMENT age (#PCDATA)> <!ELEMENT school (#PCDATA)> <!ELEMENT loc (#PCDATA)> <!ELEMENT city (#PCDATA)>
(2)Schema技术。
- Schema是DTD的代替者,名称为XML Schema,用于描述XML文档结构,比DTD更加强大,最主要的特征之一就是XML Schema支持数据类型。
- Schema是用XML验证XML遵循XML的语法。
- Schema可以用能处理XML文档的工具处理。
- 在一个XML文档中要引入多个约束文件时得使用Schema。
- 案例:
XML
<?xml version='1.0' encoding='UTF-8'?>
<student
xmlns="http://www.w3school.com.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3school.com.cn abc.xsd"> <!--引入外部Schema约束-->
<name>李四</name>
<age>22</age>
<school>长沙市一中</school>
<school>长沙市一中</school>
<loc>长沙市岳麓区</loc>
</student>- abc.xsd文件内容
XML
<?xml version="1.0"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.w3school.com.cn"
xmlns="http://www.w3school.com.cn"
elementFormDefault="qualified">
<xs:element name="student">
<xs:complexType> <!--complexType:表示当前元素是复合元素(含有子元素的称为复合元素)-->
<xs:sequence> <!--表示子元素按序列来约束-->
<xs:element name="name" type="xs:string"/>
<xs:element name="age" type="xs:string"/>
<xs:element name="school" type="xs:string"/> <!--如果含有多个相同的子元素,就写多个-->
<xs:element name="school" type="xs:string"/>
<xs:element name="loc" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>-
一般情况下,我们使用Schema约束都会从外部引入一个Schema约束,因为Schema约束本身就是一个xml文档,看起来比较繁琐,所以我们都会把Schema单独写在一个文件中,然后用到的时候就从外部引入,引入Schema约束文件是放在跟标签的开始标签里面,当作属性。
-
引入外部Schema约束引入详解:
*XML<student xmlns="http://www.w3school.com.cn" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.w3school.com.cn abc.xsd"> <!--引入外部Schema约束-->- xmlns:相当于java中import,因为Schema是基于w3school的标准的,所以引入的是w3school的官网,w3school就是一个技术标准,我们把这个技术标准称为命名空间。
- xsi:代表别名,因为这里又导入了一个命名空间,这个命名空间是目标命令空间,我们给它起了一个别名,叫xsi。
- schemaLocation:通过目标命名空间指定一个本地空间。
-
Schema约束详解:
*XML<xs:element name="student"> <xs:complexType> <!--complexType:表示当前元素是复合元素(含有子元素的称为复合元素)--> <xs:sequence> <!--表示子元素按序列来约束--> <xs:element name="name" type="xs:string"/> <xs:element name="age" type="xs:string"/> <xs:element name="school" type="xs:string"/> <!--如果含有多个相同的子元素,就写多个--> <xs:element name="school" type="xs:string"/> <xs:element name="loc" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:element>- element:代表要约束的元素。
- 属性name:属性值是要约束的元素名称。
- 属性type:是元素的类型。
- 从结构上看,xml文档中最外层的是student标签,里面可以有name,age等子标签。
- complexType:代表复合元素,也就是当前元素下面可以包含子元素。
- sequence:代表子元素按序列来约束。
- 如果有多个相同的元素,就在Schema约束中写多个,简单来说,就是Schema约束中怎么写,我们在xml中就要怎么写。
- element:代表要约束的元素。
-
总结:
- XML Schema:用于验证当前Schema文档的命名空间(用于验证Schema本身)同时它还规定了来自命名空间XML Schema的元素和数据类型。
- Schema其实就是一个xml,使用xml的语法规则,xml解析器解析起来比较方便,是为了替代DTD;但是Schema约束文本内容比DTD的内容还要多,所以目前也没有真正意义上替代DTD。
- DTD的约束,类似于java的继承(单一继承)。
- Schema约束,类似于java的实现接口(多实现)。
- 命名空间的作用:
- 一个xml如果想指定它的约束规则,假设使用的是DTD,那么这个xml只能指定一个DTD,不能指定多个DTD。但是如果一个xml的约束是定义在schema里面,并且是多个schema,那么是可以的。简单来说:一个xml可以引用多个schema约束,但是只能引用一个DTD约束。
- 命名空间的作用就是在写元素的时候,可以指定该元素使用的是哪一套规则。
六、HTTP协议详解
1.客户端和服务器的连接过程:
(1)建立TCP连接
- TCP连接是长连接,比较消耗资源;
- TCP连接是基于IP加端口号连接;
(2)客户端向服务器发送请求
(3)服务器响应客户端的请求并下发数据
(4)发送完数据后断开连接
2.什么是TCP:
(1)TCP(Transmission Control Protocol)中文:传输控制协议,就是由网络层的IP协议和传输层的TCP协议组成的面向连接(三次握手),数据安全,速度略低;分为客户端和服务器。
(2)三次握手:客户端先向服务端发起请求,服务端响应请求,传输数据。
3.请求:客户端根据用户地址信息将数据发送给服务器的过程。
4.响应:服务器将请求处理结果发送给浏览器的过程。
七、HTTP的概念和介绍
1.概念:超文本传输协议(Hyper Text Transfer Protocol)。
2.作用:规范了浏览器和服务器的数据交互。
3.特点:
(1)简单快速:客户向服务器请求服务时,只需传送请求方法和路径。
- 请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通讯速度很快。
(2)灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
(3)无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
(4)无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
4.支持B/S及C/S模式
5.HTTP1.1版本后支持可持续连接
(1)在一次请求之后,在一定的时间内如果没有新的请求,那么此次http请求,立马进入断开的倒计时,这样做的优点是,可以提高一次http连接的请求效率。
八、HTTP的交互流程
1.HTTP的交互流程一般分为四个步骤(一次完整的请求):
(1)步骤一:客户端和服务器端建立连接;
(2)步骤二:客户端发送请求数据到服务器端(HTTP协议);
(3)步骤三:服务器端接收到请求后,进行处理,然后将处理结果响应客户端(HTTP协议);
(4)步骤四:关闭客户端和服务器端的连接(HTTP协议);
九、HTTP协议的请求格式
1.请求格式的结构
(1)请求头:请求方式、请求的地址和HTTP协议版本。
(2)请求行:消息报头,一般用来说明客户端要使用的一些附加信息。
(3)空行:位于请求行和请求数据之间,空行是必须的。
(4)请求数据:非必须
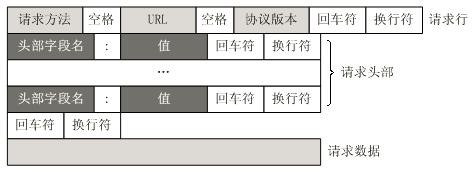
2.HTTP请求头详解
(1)Accept:这个标记的含义是告诉服务器我可以接受的数据的类型;
(2)Accept-Encoding:代表当前数据的压缩格式;
(3)Accept-Language:代表客户端支持的语言;
(4)Connection:请求的连接方式;
(5)Cookie:是服务器发送给客户端的一块牌牌,这个牌记录了客户端前面访问过服务器,并可以获取之前产生的一些数据信息;
(6)Host:请求的主机地址;
(7)User-Agent:使用的浏览器的类型;
3.HTTP响应头详解
(1)HTTP/2:连接状态,200表示连接成功,404表示找不到资源,505表示服务器的程序有问题,302表示请求的方式不支持;
(2)content-type:响应的数据类型;
(3)cache-control:缓存的控制方式;
(4)Expires:缓存的失效时间;
(5)Server:服务器的型号;
4.get请求方式和post请求方式
(1)get请求方式:没有请求体,提交的数据含在url后面。
(2)post请求方式:有请求体,提交的数据在请求体中。
十、HTTP协议的请求方式
1.根据HTTP标准,HTTP请求可以使用多种请求方法。
2.HTTP1.0定义了三种请求方法:GET、POST、HEAD方法
(1)GET:请求指定的页面信息,并返回实体主体。
(2)POST:向指定资源提交数据,进行处理请求(例如:提交表单或者上传文件),数据被包含在请求体中;POST请求可能会导致新的资源的建立和/或已有资源的修改。
(3)HEAD:类似于GET请求,只不过返回的响应中没有具体的内容,用于获取报头。
3.HTTP1.1新增了五种请求方法:OPTIONS、PUT、DELETE、TRACE和CONNECT方法
(1)OPTIONS:允许客户端查看服务器的性能。
(2)PUT:从客户端向服务器传送的数据取代指定的文档的内容。
(3)DELETE:请求服务器删除指定的页面。
(4)TRACE:回显服务器收到的请求,主要用于测试或诊断。
(5)CONNCET:HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
(6)PATCH:是对PUT方法的补充,用来对已知资源进行局部更新。
4.GET和POST请求的区别
(1)GET请求方式:请求数据会以?的形式隔开拼接在请求头中,不安全,没有请求实体部分。最主要的是HTTP协议虽然没有规定请求数据的大小,但是浏览器对URL的长度是有限制的,所以get请求不能携带大量的数据。RUL会出现在浏览器的地址栏中,没有请求体。
- 各大浏览器对URL的长度限制:
- Microsoft Internet Explorer(Browser):IE浏览器对RUL的最大限制字符为2083个字符,如果超过这个数字,提交按钮没有任何反应。
- Firefox(Browser):火狐浏览器对URL的长度限制为65536个字符。
- Safari(Browser):URL最大长度限制为80000个字符。
- Opera(Browser):URL最大长度限制为190000个字符。
- Google(chrome):谷歌的URL最大长度限制为8182个字符。
- 服务器对URL的长度限制:
- Apache(Server):RUL最大长度为8192个字符。
- Microsoft Internet Information Server(IIS):能接受最大URL长度为16384个字符。
(2)POST请求方式:请求数据在请求体中进行发送,在URL中看不到具体的请求数据,安全,适合数据量大的数据发送,用户提交的数据会出现在请求体中。
十一、HTTP协议的响应
1.响应格式的结构:
(1)响应行(状态行):HTTP版本、状态码、状态消息。
(2)响应头:消息报头,客户端使用的附加信息。
(3)空行:响应头和响应实体之间的,必须的。
(4)响应实体:正文,服务器返回给浏览器的信息。
2.HTTP常见响应状态码含义:
(1)HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。
(2)HTTP状态码共分为5类:
- 1**:信息,服务器收到请求,需要请求者继续执行操作。
- 2**:成功,操作被成功接收并处理。
- 3**:重定向,需要进一步的操作来完成请求。
- 4**:客户端错误,请求包含语法错误或无法完成请求。
- 5**:服务器错误,服务器在处理请求的过程中发生了错误。
(3)常见状态码:
- 200:OK //代表客户端请求成功。
- 400:Bad Request //客户端请求有语法错误,不能被服务器所理解。
- 401:Unauthorized //请求未经授权,这个状态码必须和WWW-Authenticate报头域一起使用。
- 403:Forbidden //服务器收到请求,但是拒绝提供服务。
- 404:Not Found //请求的资源不存在,eg:输入了错误的URL。
- 500:Internal Server Error //服务器发生不可预期的错误(java代码编码有错误)。
- 503:Server Unavailable //服务器当前不能处理客户端的请求,一段时间可能恢复正常。
十二、Tomcat服务器介绍和使用
1.服务器的概念和作用
(1)服务器:
- 狭义的理解:服务器就是一个程序。
- 广义的理解:把一个服务器程序安装到一台电脑中,让这台电脑可以对外提供客户发送请求之后,进行响应处理,那么这台电脑我们称为服务器。
2.tomcat的下载地址:Apache Download Mirrors
3.tomcat是apache旗下的一个web服务器,apache是一个软件基金会。
4.tomcat的目录结构介绍:
(1)\bin:存放启动和关闭Tomcat的可执行文件;
- startup.bat:是tomcat在windows系统中启动的命令;
- startup.sh:是tomcat在linux系统中启动的命令;
- shutdown.bat:是tomcat在windows系统中关闭的命令;
- shutdown.sh:是tomcat在linux系统中关闭的命令;
(2)\conf:存放tomcat的配置文件;
(3)\lib:存放库文件;
(4)\logs:存放日志文件;
(5)\temp:存放临时文件;
(6)\WebApps:存放Web应用;
(7)\work:存放JSP转换后的java文件(Servlet文件)会存放到此目录下;
5.如果tomcat服务器起不来:
(1)可以考虑是否是没有配置环境变量。
(2)还可以考虑端口是否冲突了。