VideoPipe是一个用于视频分析和结构化的框架,采用 C++ 编写、依赖少、易上手。它像管道一样,其中每个节点相互独立并可自行搭配,VideoPipe可用来构建不同类型的视频分析应用,适用于视频结构化、图片搜索、人脸识别、交通/安防领域的行为分析(如交通事件检测)等场景。
VideoPipe项目仓库中已经提供了50多个集成传统AI算法模型的Sample源码,涉及到车牌识别、人脸识别、违章检测、图搜、OCR、AI变脸、目标检测、图像分类、图像分割等各个领域。在大模型逐渐成为主流的今天(多模态大模型赋能传统AI视觉算法领域中表现优秀),VideoPipe也支持大模型集成啦,这次重点介绍VideoPipe如何集成多模态大模型来完成视频(图片)分析相关任务。
快速开始
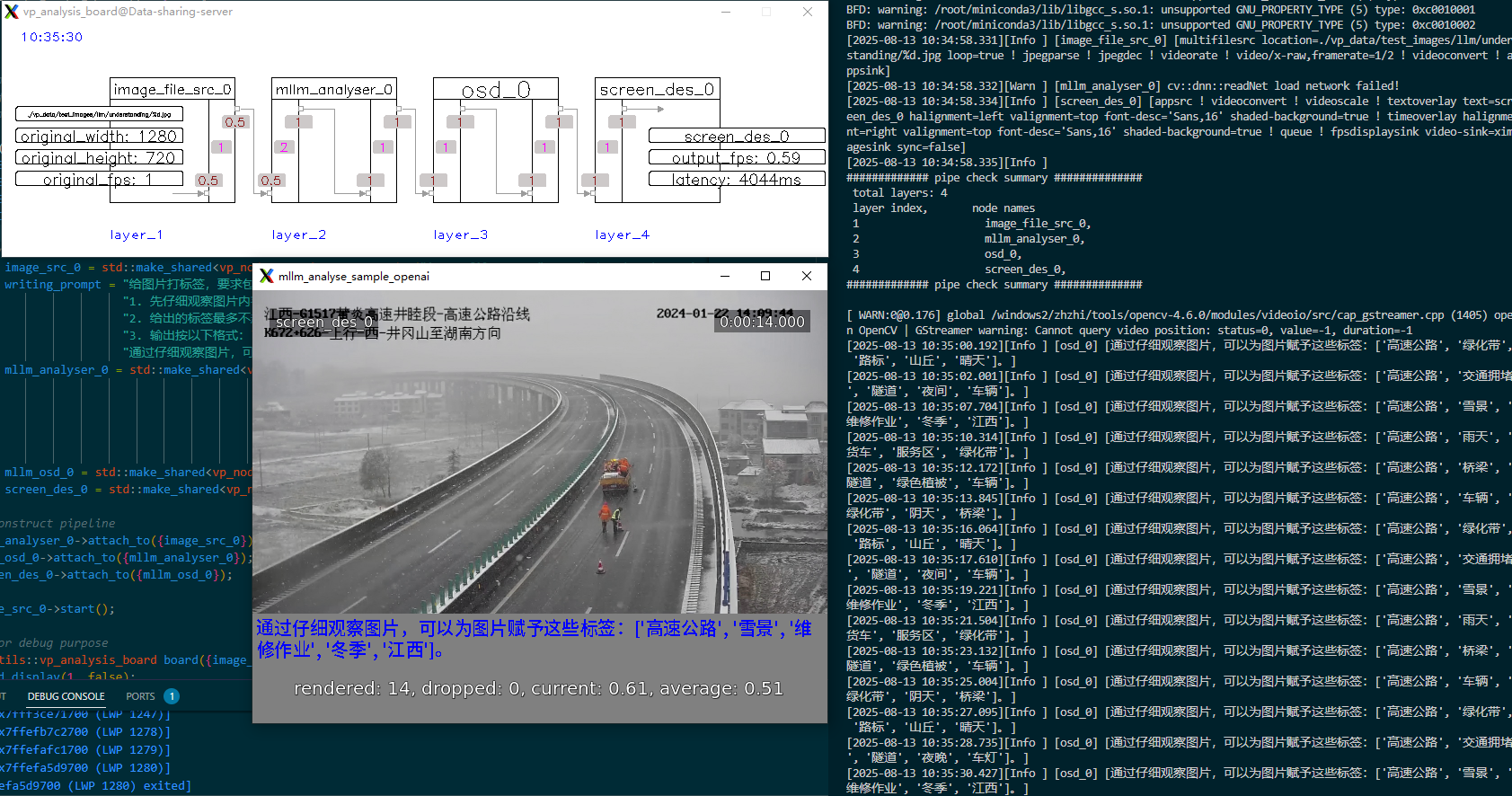
下面基于VideoPipe和阿里云qwen-vl多模态大模型实现一个简单的图片理解的功能:从本地磁盘读取图片序列(现实场景中可以从网络获取图片或视频数据),大模型根据事先定义的Prompt提示词,对图片进行识别理解,依次对图片进行标签化,然后将标签化结果叠加到图片下方,最后显示结果。
1、创建VideoPipe节点类型(事先准备好aliyun大模型服务api_key)
2、将节点串起来,组成Pipeline管道
3、启动管道(一共55行代码)
1 #include "../nodes/vp_image_src_node.h"
2 #include "../nodes/infers/vp_mllm_analyser_node.h"
3 #include "../nodes/osd/vp_mllm_osd_node.h"
4 #include "../nodes/vp_screen_des_node.h"
5 #include "../nodes/vp_rtmp_des_node.h"
6
7 #include "../utils/analysis_board/vp_analysis_board.h"
8
9 /*
10 * ## mllm_analyse_sample_openai ##
11 * image(frame) analyse based on Multimodal Large Language Model(from aliyun or other OpenAI-compatible api services).
12 * read images from disk and analyse the image using MLLM using the prepared prompt.
13 */
14 int main() {
15 VP_SET_LOG_INCLUDE_CODE_LOCATION(false);
16 VP_SET_LOG_INCLUDE_THREAD_ID(false);
17 VP_SET_LOG_LEVEL(vp_utils::vp_log_level::INFO);
18 VP_LOGGER_INIT();
19
20 // create nodes
21 auto image_src_0 = std::make_shared<vp_nodes::vp_image_src_node>("image_file_src_0",
22 0,
23 "./vp_data/test_images/llm/understanding/%d.jpg",
24 2,
25 0.5);
26 auto writing_prompt = "给图片打标签,要求包含:\n"
27 "1. 先仔细观察图片内容,为图片赋予适合的标签\n"
28 "2. 给出的标签最多不超过10个\n"
29 "3. 输出按以下格式:\n"
30 "通过仔细观察图片,可以为图片赋予这些标签:['标签1', '标签2', '标签3']。";
31 auto mllm_analyser_0 = std::make_shared<vp_nodes::vp_mllm_analyser_node>("mllm_analyser_0", // node name
32 "qwen-vl-max", // mllm model name (support image as input)
33 writing_prompt, // prompt
34 "https://dashscope.aliyuncs.com/compatible-mode/v1", // api base url
35 "sk-XXX", // api key (from aliyun)
36 llmlib::LLMBackendType::OpenAI); // backend type
37 auto mllm_osd_0 = std::make_shared<vp_nodes::vp_mllm_osd_node>("osd_0",
38 "./vp_data/font/NotoSansCJKsc-Medium.otf");
39 auto screen_des_0 = std::make_shared<vp_nodes::vp_screen_des_node>("screen_des_0", 0);
40
41 // construct pipeline
42 mllm_analyser_0->attach_to({image_src_0});
43 mllm_osd_0->attach_to({mllm_analyser_0});
44 screen_des_0->attach_to({mllm_osd_0});
45
46 image_src_0->start();
47
48 // for debug purpose
49 vp_utils::vp_analysis_board board({image_src_0});
50 board.display(1, false);
51
52 std::string wait;
53 std::getline(std::cin, wait);
54 image_src_0->detach_recursively();
55 }运行效果
管道运行起来之后,大模型分析节点根据事先定义好的参数(模型名称、提示词、api_key)访问大模型服务,并解析大模型输出,随后显示节点将大模型输出绘制到图片中,并在控制台实时打印。VideoPipe目前支持的大模型后端有:OpenAI协议兼容服务、Ollama/vLLM本地部署服务。(视频效果参见官网)