背景意义
研究背景与意义
膝关节屈伸运动的检测在运动医学、康复治疗及运动训练中具有重要的应用价值。随着人们对健康和运动的重视,膝关节的功能评估与运动表现分析逐渐成为研究的热点。膝关节作为人体重要的负重关节,其运动状态直接影响到运动员的表现和运动安全。因此,开发一个高效、准确的膝关节屈伸运动检测系统,不仅能够帮助运动员优化训练方案,还能为临床医生提供科学依据,以制定个性化的康复计划。
近年来,深度学习技术在计算机视觉领域取得了显著进展,尤其是目标检测和实例分割任务中,YOLO(You Only Look Once)系列模型以其快速和高效的特点被广泛应用。YOLOv11作为该系列的最新版本,进一步提升了检测精度和速度,适合实时应用场景。通过对YOLOv11的改进,结合针对膝关节屈伸运动的特定需求,可以实现对运动状态的精准识别与分析。
本研究将基于改进的YOLOv11模型,构建一个膝关节屈伸运动检测系统。数据集包含1200张经过精细标注的图像,分为"膝关节屈伸运动"和"非屈伸运动"两类。这一数据集的构建为模型的训练和评估提供了坚实的基础。通过实例分割技术,系统不仅能够识别膝关节的运动状态,还能精确定位运动过程中的关键点,从而为运动员的技术动作分析提供详细的数据支持。
综上所述,基于改进YOLOv11的膝关节屈伸运动检测系统的研究,不仅具有重要的理论意义,还具备广泛的应用前景。该系统的成功开发将为运动医学领域提供新的工具,推动运动训练和康复治疗的科学化进程。
图片效果
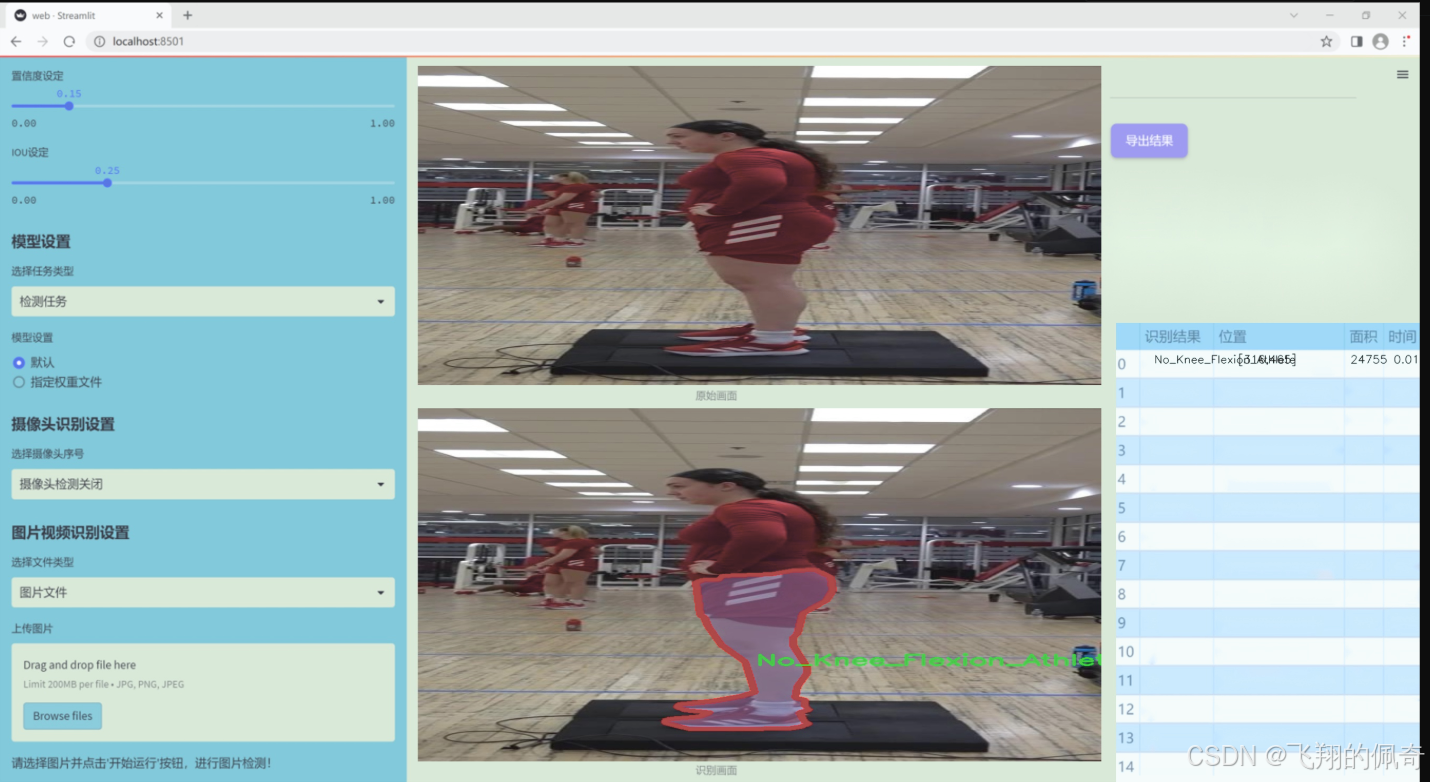
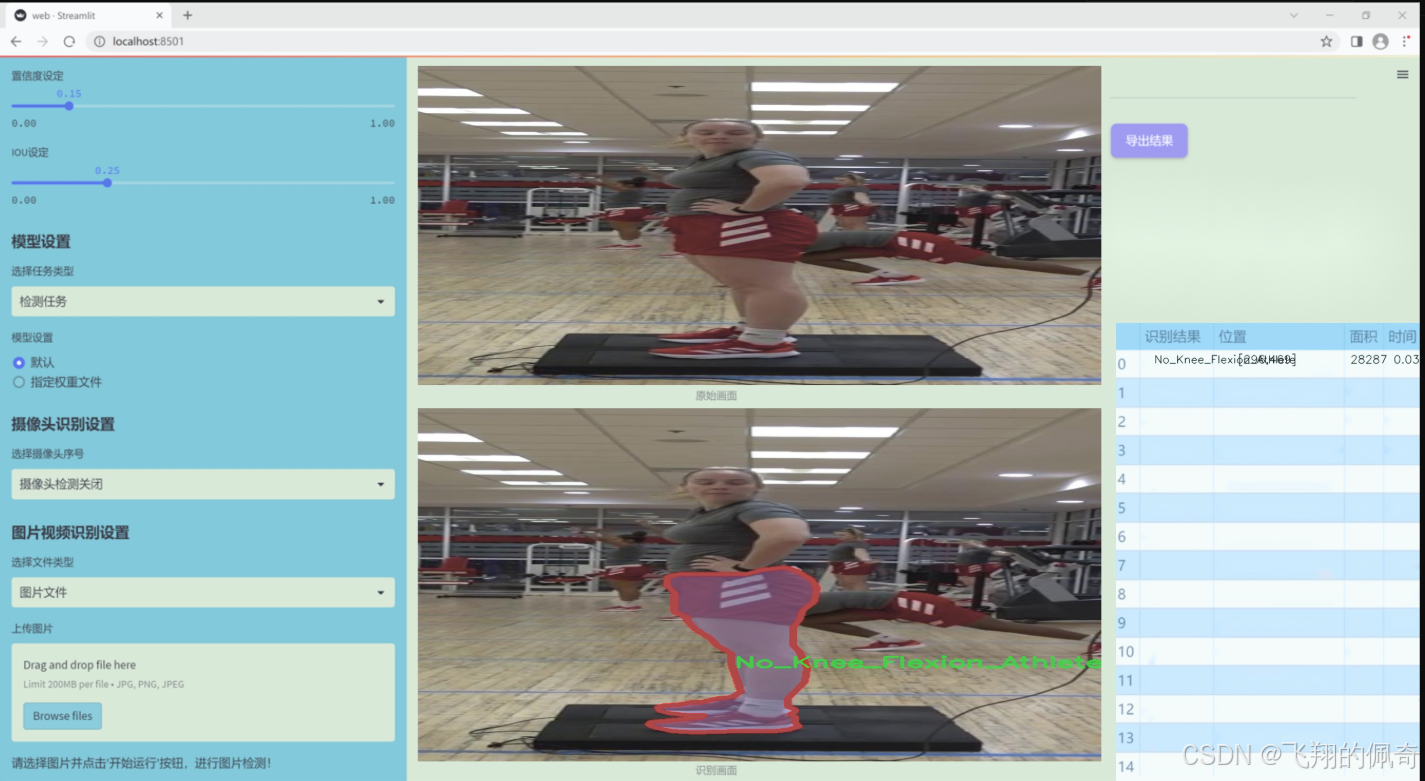
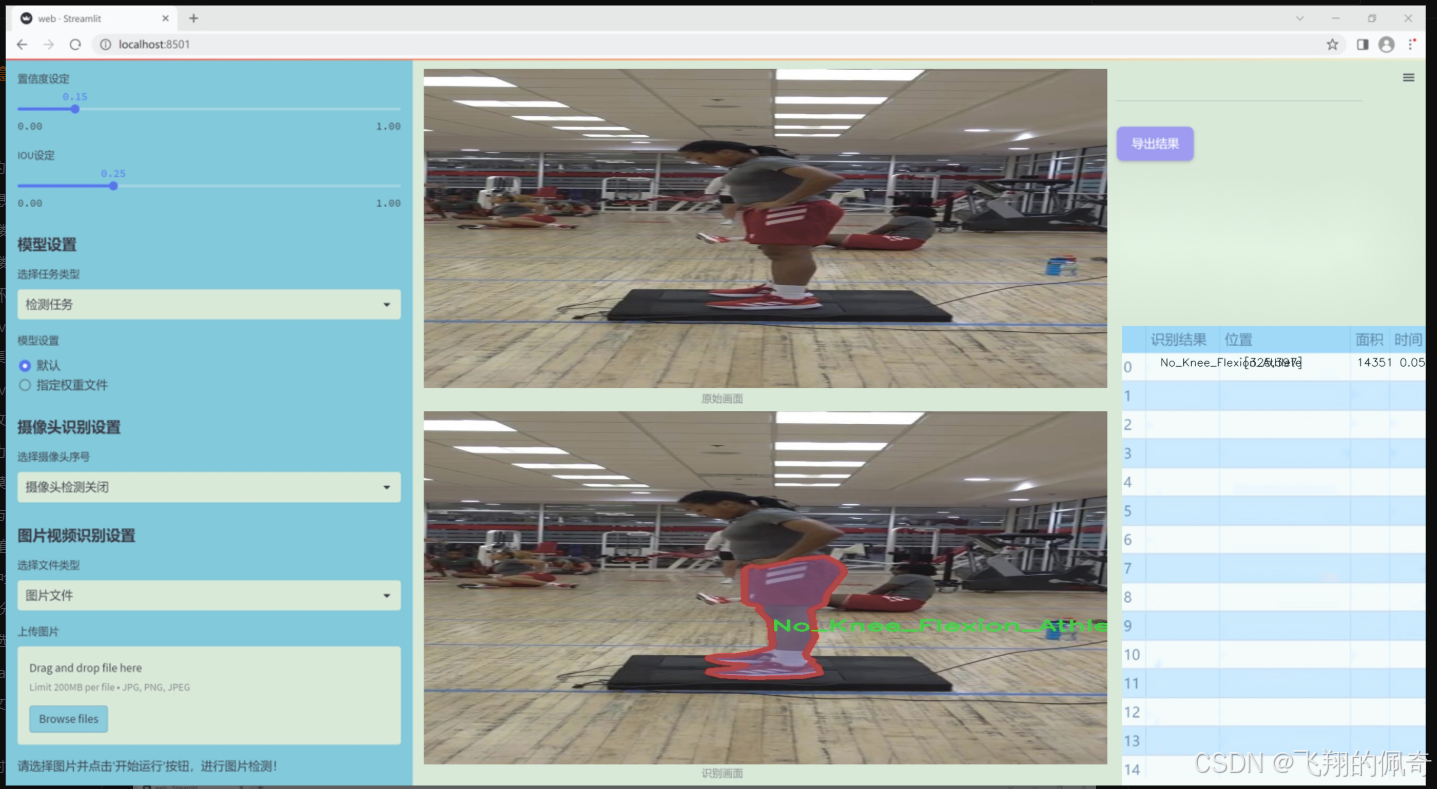
数据集信息
本项目数据集信息介绍
本项目旨在开发一种改进的YOLOv11膝关节屈伸运动检测系统,所使用的数据集名为"Knee_Flexion_Segmentation"。该数据集专注于膝关节屈伸运动的识别与分析,特别是在运动员群体中的应用。数据集包含两个主要类别,分别为"Knee_Flexion_Athlete"和"No_Knee_Flexion_Athlete",这两个类别的设计旨在帮助模型有效区分运动员在进行膝关节屈伸运动时的状态与未进行该运动时的状态。
在数据集的构建过程中,研究团队收集了大量高质量的视频和图像数据,确保样本的多样性和代表性。每个类别均包含不同角度、不同环境下的运动员膝关节屈伸运动表现,涵盖了从静态到动态的多种姿态。这种丰富的数据来源不仅增强了模型的训练效果,还提高了其在实际应用中的泛化能力。此外,数据集中的样本经过精心标注,确保每一帧图像都能准确反映出运动员的膝关节状态,为后续的深度学习模型训练提供了坚实的基础。
通过对"Knee_Flexion_Athlete"和"No_Knee_Flexion_Athlete"这两个类别的深入分析,研究团队能够更好地理解膝关节屈伸运动的生物力学特征,进而优化YOLOv11模型的结构与参数设置,以实现更高的检测精度和实时性。这一数据集不仅为膝关节运动的研究提供了重要的实验基础,也为运动医学、康复训练等领域的相关研究奠定了良好的数据支持。通过不断迭代和优化,最终目标是构建一个高效、准确的膝关节屈伸运动检测系统,以助力运动员的训练与康复。





核心代码
以下是经过简化和注释的核心代码部分,保留了模型的主要结构和功能:
import torch
import torch.nn as nn
from timm.models.layers import SqueezeExcite
def _make_divisible(v, divisor, min_value=None):
"""
确保所有层的通道数是可被8整除的。
:param v: 输入的通道数
:param divisor: 除数
:param min_value: 最小值
:return: 调整后的通道数
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v: # 确保不超过90%
new_v += divisor
return new_v
class Conv2d_BN(nn.Sequential):
"""
包含卷积层和批归一化层的组合模块。
"""
def init (self, in_channels, out_channels, kernel_size=1, stride=1, padding=0, dilation=1, groups=1):
super().init ()
self.add_module('conv', nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias=False))
self.add_module('bn', nn.BatchNorm2d(out_channels))
@torch.no_grad()
def fuse_self(self):
"""
融合卷积层和批归一化层为单一卷积层。
"""
conv, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps)**0.5
w = conv.weight * w[:, None, None, None]
b = bn.bias - bn.running_mean * bn.weight / (bn.running_var + bn.eps)**0.5
fused_conv = nn.Conv2d(w.size(1) * conv.groups, w.size(0), w.shape[2:], stride=conv.stride, padding=conv.padding, dilation=conv.dilation, groups=conv.groups)
fused_conv.weight.data.copy_(w)
fused_conv.bias.data.copy_(b)
return fused_convclass RepViTBlock(nn.Module):
"""
RepViT的基本构建块,包含通道混合和token混合。
"""
def init (self, inp, hidden_dim, oup, kernel_size, stride, use_se, use_hs):
super(RepViTBlock, self).init ()
self.identity = stride == 1 and inp == oup
if stride == 2:
self.token_mixer = nn.Sequential(
Conv2d_BN(inp, inp, kernel_size, stride, (kernel_size - 1) // 2, groups=inp),
SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),
Conv2d_BN(inp, oup, ks=1, stride=1, pad=0)
)
self.channel_mixer = nn.Sequential(
Conv2d_BN(oup, 2 * oup, 1, 1, 0),
nn.GELU() if use_hs else nn.Identity(),
Conv2d_BN(2 * oup, oup, 1, 1, 0)
)
else:
assert(self.identity)
self.token_mixer = nn.Sequential(
Conv2d_BN(inp, inp, 3, 1, 1, groups=inp),
SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),
)
self.channel_mixer = nn.Sequential(
Conv2d_BN(inp, hidden_dim, 1, 1, 0),
nn.GELU() if use_hs else nn.Identity(),
Conv2d_BN(hidden_dim, oup, 1, 1, 0)
)
def forward(self, x):
return self.channel_mixer(self.token_mixer(x))class RepViT(nn.Module):
"""
RepViT模型,包含多个RepViTBlock。
"""
def init (self, cfgs):
super(RepViT, self).init ()
self.cfgs = cfgs
input_channel = self.cfgs02
layers = Conv2d_BN(3, input_channel // 2, 3, 2, 1), nn.GELU(), Conv2d_BN(input_channel // 2, input_channel, 3, 2, 1)
for k, t, c, use_se, use_hs, s in self.cfgs:
output_channel = _make_divisible(c, 8)
exp_size = _make_divisible(input_channel * t, 8)
layers.append(RepViTBlock(input_channel, exp_size, output_channel, k, s, use_se, use_hs))
input_channel = output_channel
self.features = nn.ModuleList(layers)
def forward(self, x):
for f in self.features:
x = f(x)
return xdef repvit_m2_3(weights=''):
"""
构建RepViT模型的一个特定配置。
"""
cfgs = [
3, 2, 80, 1, 0, 1,
3, 2, 80, 0, 0, 1,
省略其他配置...
3, 2, 640, 0, 1, 1
]
model = RepViT(cfgs)
if weights:
model.load_state_dict(torch.load(weights)'model')
return model
if name == 'main ':
model = repvit_m2_3('repvit_m2_3_distill_450e.pth')
inputs = torch.randn((1, 3, 640, 640))
res = model(inputs)
for i in res:
print(i.size())
代码说明:
_make_divisible: 确保通道数是8的倍数,以便在后续操作中避免不必要的计算。
Conv2d_BN: 自定义的卷积层与批归一化层的组合,支持融合操作以减少计算量。
RepViTBlock: 该类定义了RepViT的基本构建块,包含token混合和通道混合的操作。
RepViT: 整个模型的定义,使用配置列表构建多个RepViTBlock。
repvit_m2_3: 构建特定配置的RepViT模型,并加载预训练权重(如果提供)。
该代码实现了一个基于RepViT架构的深度学习模型,适用于图像处理任务。
这个程序文件 repvit.py 实现了一个基于 RepVGG 结构的视觉模型,主要用于图像分类任务。文件中包含多个类和函数,下面是对其主要内容的逐步说明。
首先,程序导入了必要的库,包括 PyTorch 的神经网络模块 torch.nn、NumPy 以及 timm 库中的 SqueezeExcite 层。接着,定义了一个 all 列表,列出了可供外部调用的模型名称。
replace_batchnorm 函数用于遍历神经网络中的所有子模块,将 BatchNorm2d 层替换为 Identity 层,从而实现模型的融合。这种融合在推理时可以提高效率。
_make_divisible 函数确保网络中所有层的通道数都是可被 8 整除的,这样做是为了适应某些硬件加速器的要求。
Conv2d_BN 类是一个自定义的卷积层,包含卷积操作和 BatchNorm 层,并在初始化时对 BatchNorm 的权重进行初始化。它还实现了 fuse_self 方法,用于将卷积和 BatchNorm 融合为一个卷积层,以提高推理速度。
Residual 类实现了残差连接,允许在训练期间随机丢弃部分输入,以增加模型的鲁棒性。它同样提供了 fuse_self 方法来融合内部的卷积层。
RepVGGDW 类实现了一个深度可分离卷积块,包含两个卷积层和一个 BatchNorm 层,最后通过残差连接将输入与输出相加。
RepViTBlock 类则是 RepViT 模型的基本构建块,包含 token mixer 和 channel mixer。token mixer 负责对输入进行卷积操作,而 channel mixer 则用于处理通道之间的关系。
RepViT 类是整个模型的核心,负责构建模型的结构。它根据配置参数(如卷积核大小、扩展因子、输出通道数等)逐层构建网络。该类还实现了 forward 方法,用于前向传播,并在 switch_to_deploy 方法中调用 replace_batchnorm 进行模型融合。
update_weight 函数用于更新模型的权重,将预训练的权重加载到模型中。
接下来,定义了多个函数(如 repvit_m0_9、repvit_m1_0 等),这些函数根据不同的配置构建不同版本的 RepViT 模型,并支持加载预训练权重。
最后,在 main 部分,程序实例化了一个 repvit_m2_3 模型,并通过随机生成的输入张量进行前向传播,打印输出的特征图的尺寸。
整体来看,这个程序实现了一个灵活的深度学习模型结构,适用于图像分类任务,并通过模块化设计和权重融合技术提升了模型的性能和推理效率。
10.4 mamba_yolo.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
from einops import rearrange
class LayerNorm2d(nn.Module):
def init (self, normalized_shape, eps=1e-6, elementwise_affine=True):
super().init ()
初始化2D层归一化
self.norm = nn.LayerNorm(normalized_shape, eps, elementwise_affine)
def forward(self, x):
# 将输入张量的维度从 (B, C, H, W) 转换为 (B, H, W, C)
x = rearrange(x, 'b c h w -> b h w c').contiguous()
# 应用层归一化
x = self.norm(x)
# 将维度转换回 (B, C, H, W)
x = rearrange(x, 'b h w c -> b c h w').contiguous()
return xclass CrossScan(torch.autograd.Function):
@staticmethod
def forward(ctx, x: torch.Tensor):
获取输入张量的形状
B, C, H, W = x.shape
ctx.shape = (B, C, H, W)
创建一个新的张量,用于存储交叉扫描的结果
xs = x.new_empty((B, 4, C, H * W))
将输入张量展平并存储在 xs 中
xs:, 0 = x.flatten(2, 3) # 原始
xs:, 1 = x.transpose(dim0=2, dim1=3).flatten(2, 3) # 转置
xs:, 2:4 = torch.flip(xs:, 0:2, dims=-1) # 翻转
return xs
@staticmethod
def backward(ctx, ys: torch.Tensor):
# 反向传播
B, C, H, W = ctx.shape
L = H * W
# 计算梯度
ys = ys[:, 0:2] + ys[:, 2:4].flip(dims=[-1]).view(B, 2, -1, L)
y = ys[:, 0] + ys[:, 1].view(B, -1, W, H).transpose(dim0=2, dim1=3).contiguous().view(B, -1, L)
return y.view(B, -1, H, W)class SelectiveScanCore(torch.autograd.Function):
@staticmethod
@torch.cuda.amp.custom_fwd
def forward(ctx, u, delta, A, B, C, D=None, delta_bias=None, delta_softplus=False, nrows=1, backnrows=1):
确保输入张量是连续的
if u.stride(-1) != 1:
u = u.contiguous()
if delta.stride(-1) != 1:
delta = delta.contiguous()
if D is not None and D.stride(-1) != 1:
D = D.contiguous()
if B.stride(-1) != 1:
B = B.contiguous()
if C.stride(-1) != 1:
C = C.contiguous()
# 处理维度
if B.dim() == 3:
B = B.unsqueeze(dim=1)
ctx.squeeze_B = True
if C.dim() == 3:
C = C.unsqueeze(dim=1)
ctx.squeeze_C = True
ctx.delta_softplus = delta_softplus
ctx.backnrows = backnrows
# 调用 CUDA 核心进行前向计算
out, x, *rest = selective_scan_cuda_core.fwd(u, delta, A, B, C, D, delta_bias, delta_softplus, 1)
ctx.save_for_backward(u, delta, A, B, C, D, delta_bias, x)
return out
@staticmethod
@torch.cuda.amp.custom_bwd
def backward(ctx, dout, *args):
# 反向传播
u, delta, A, B, C, D, delta_bias, x = ctx.saved_tensors
if dout.stride(-1) != 1:
dout = dout.contiguous()
du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda_core.bwd(
u, delta, A, B, C, D, delta_bias, dout, x, ctx.delta_softplus, 1
)
return (du, ddelta, dA, dB, dC, dD, ddelta_bias, None, None, None, None)def cross_selective_scan(x: torch.Tensor, x_proj_weight: torch.Tensor, dt_projs_weight: torch.Tensor, A_logs: torch.Tensor, Ds: torch.Tensor, out_norm: torch.nn.Module = None):
获取输入张量的形状
B, D, H, W = x.shape
L = H * W
# 执行交叉扫描
xs = CrossScan.apply(x)
# 计算中间结果
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs, x_proj_weight)
dts, Bs, Cs = torch.split(x_dbl, [R, N, N], dim=2)
dts = torch.einsum("b k r l, k d r -> b k d l", dts, dt_projs_weight)
# HiPPO 矩阵
As = -torch.exp(A_logs.to(torch.float)) # (k * c, d_state)
Ds = Ds.to(torch.float) # (K * c)
# 调用选择性扫描
ys: torch.Tensor = SelectiveScan.apply(xs, dts, As, Bs, Cs, Ds)
return ysclass SS2D(nn.Module):
def init (self, d_model=96, d_state=16, ssm_ratio=2.0, dt_rank="auto"):
super().init ()
self.d_model = d_model
self.d_state = d_state
self.ssm_ratio = ssm_ratio
self.dt_rank = dt_rank
# 输入投影
self.in_proj = nn.Conv2d(d_model, int(ssm_ratio * d_model), kernel_size=1, bias=False)
# 输出投影
self.out_proj = nn.Conv2d(int(ssm_ratio * d_model), d_model, kernel_size=1, bias=False)
def forward(self, x: torch.Tensor):
# 前向传播
x = self.in_proj(x)
x = cross_selective_scan(x, self.x_proj_weight, self.dt_projs_weight, self.A_logs, self.Ds)
x = self.out_proj(x)
return xclass VSSBlock_YOLO(nn.Module):
def init (self, in_channels: int, hidden_dim: int):
super().init ()
self.proj_conv = nn.Conv2d(in_channels, hidden_dim, kernel_size=1, bias=True)
self.ss2d = SS2D(d_model=hidden_dim)
def forward(self, input: torch.Tensor):
input = self.proj_conv(input)
x = self.ss2d(input)
return x代码核心部分说明:
LayerNorm2d: 实现了对2D输入的层归一化,适用于图像数据。
CrossScan: 实现了交叉扫描的前向和反向传播,用于处理输入张量的不同变换。
SelectiveScanCore: 选择性扫描的核心实现,支持前向和反向传播,使用CUDA加速。
cross_selective_scan: 整合了交叉扫描和选择性扫描的逻辑,计算中间结果。
SS2D: 实现了一个基于选择性扫描的2D模块,包含输入和输出投影。
VSSBlock_YOLO: 一个包含选择性扫描模块的块,适用于YOLO等视觉任务。
这些部分构成了模型的核心功能,主要用于图像处理和特征提取。
这个程序文件 mamba_yolo.py 实现了一个基于深度学习的视觉模型,主要用于目标检测任务。文件中包含了多个类和函数,主要涉及到神经网络的构建和前向传播的实现。以下是对文件内容的详细说明。
首先,文件导入了一些必要的库,包括 torch 和 torch.nn,以及一些用于张量操作的库如 einops 和 timm.layers。这些库为模型的构建和训练提供了基础支持。
文件中定义了一个 LayerNorm2d 类,该类实现了二维层归一化。它通过重排输入张量的维度来适应 LayerNorm 的要求,并在前向传播中执行归一化操作。
接下来,定义了一个 autopad 函数,用于自动计算卷积操作的填充,以确保输出形状与输入形状相同。
然后,文件中实现了多个自定义的 PyTorch 操作,如 CrossScan 和 CrossMerge,这些操作用于处理张量的特定变换,尤其是在处理图像数据时。这些操作通过定义 forward 和 backward 方法来实现前向和反向传播。
在 SelectiveScanCore 类中,定义了一个选择性扫描的自定义操作,它的前向和反向传播都依赖于 CUDA 核心函数。这部分实现了高效的张量操作,适用于大规模数据处理。
cross_selective_scan 函数是一个重要的功能,它将输入张量进行选择性扫描,并结合多个参数进行处理,最终输出经过归一化的结果。
SS2D 类实现了一个特定的神经网络模块,包含多个卷积层和线性层,结合了选择性扫描的机制。它的构造函数中定义了多个超参数,如模型维度、状态维度、卷积核大小等。
接下来的 RGBlock 和 LSBlock 类实现了不同的网络块,分别用于特征提取和特征融合。这些块通过卷积操作和激活函数来处理输入数据,并使用跳跃连接来增强模型的表达能力。
XSSBlock 和 VSSBlock_YOLO 类则是更复杂的模块,结合了之前定义的组件,形成了完整的网络结构。这些模块在构造时会根据输入的维度和其他参数进行初始化,并在前向传播中执行一系列的张量操作。
SimpleStem 类实现了一个简单的卷积网络,用于提取输入图像的特征。它通过多个卷积层和激活函数构建了一个初步的特征提取模块。
最后,VisionClueMerge 类用于将多个特征图合并,形成最终的输出。这一过程通过对输入特征图的切片和拼接来实现,确保模型能够充分利用不同层次的特征信息。
整体来看,mamba_yolo.py 文件实现了一个复杂的深度学习模型,结合了多种先进的技术,如选择性扫描、层归一化和卷积操作,旨在提高目标检测任务的性能。模型的设计考虑了高效性和灵活性,适用于不同的输入数据和任务需求。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论 啦 、查看👇🏻获取联系方式👇🏻