模态转换与超分辨率的结合:高分辨率热红外无人机图像生成的协同框架
Modality Conversion Meets Superresolution: A Collaborative Framework for HighResolution Thermal UAV Image Generation
摘要
由于热成像传感器的局限性和成本问题,无人机(UAV)平台通常配备高分辨率(HR)可见光成像设备和低分辨率(LR)热成像相机,以实现全天候监测能力。现有研究通过两种方式生成高分辨率无人机热成像图像:一是利用高分辨率可见光图像和低分辨率热成像图像进行超分辨率(SR)处理,二是从高分辨率可见光图像进行模态转换(MC)。然而,可见光与热成像源之间的模态差异可能会降低生成图像的质量。我们观察到,模态转换任务有助于解决超分辨率任务中的跨模态差异问题,而超分辨率任务则能提供热信息条件以促进模态转换任务。此外,这两项任务具有相同的输出,因此无需任何额外标注即可同时进行。基于这一观察,我们提出了一种协同增强网络(CENet),通过联合执行无人机热成像图像超分辨率和可见光图像模态转换,实现高分辨率无人机热成像图像的生成。具体而言,我们设计了一个 mutual guidance module(MGM, mutual guidance module),以交替双向的方式交互超分辨率和模态转换任务的特征。考虑到低级视觉任务对位置敏感,为进一步增强两项任务之间的特征对齐,我们设计了双向对齐融合模块(BAFM),以保持模态转换分支和超分辨率分支的特征一致性。所提出的协同框架不仅实现了两项任务的联合统一训练,还生成了两种互补的高分辨率图像。在公开数据集上的大量实验表明,所提出的CENet在生成高分辨率无人机热成像图像方面优于当前最先进的超分辨率方法,这通过峰值信噪比(PSNR)和结构相似性指数(SSIM)得到了量化验证。
关键词------协同学习、模态转换(MC)、遥感、热成像图像超分辨率(SR)、无人机(UAV)。
一、引言
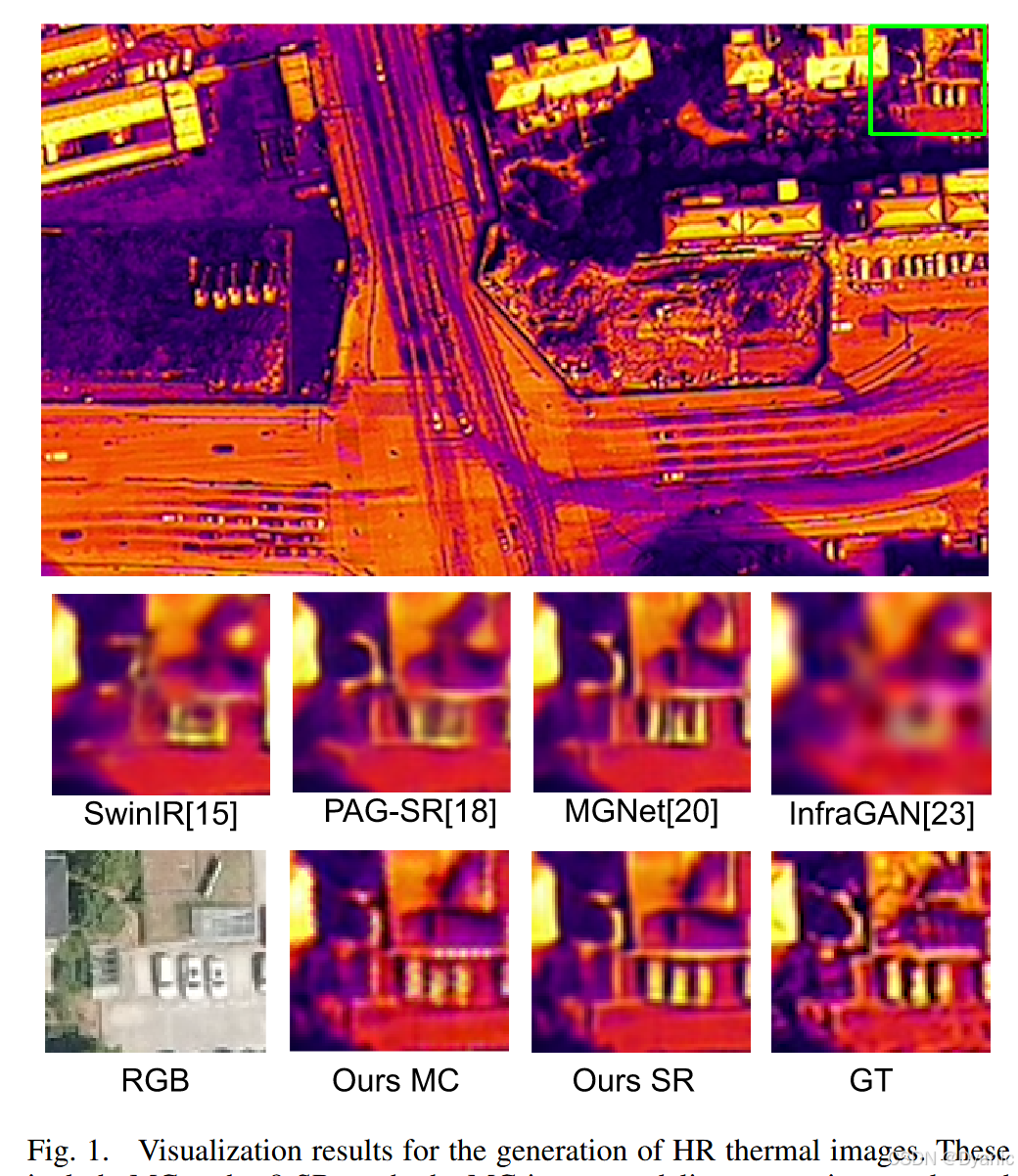
热成像技术不受光照条件影响,可全天候工作,适用于安全巡检1、农业测量2、野生动物保护3和水资源管理4等场景。从无人机(UAV)应用角度看,热成像技术具备大范围监控、高机动性、实时监测和快速部署等优势5,这使得无人机成为获取和应用热成像技术的有力工具。然而,无人机直接拍摄的热成像图像分辨率有限,严重阻碍了全面的图像分析6。因此,生成高分辨率(HR)热成像图像是提升图像解译能力的关键步骤。
为获取高分辨率图像,研究人员开发了多种图像超分辨率(SR)算法,旨在通过低分辨率(LR)图像解决这一问题。这些算法包括基于插值的方法7、8、基于重建的方法9、10,以及近年来随着深度神经网络(DNN)架构的持续研发11,基于DNN的图像超分辨率技术凭借其强大的特征提取能力展现出优异性能,例如单图像超分辨率(SISR)方法12、13、14、15、16。然而,当前的图像超分辨率方法在复杂场景中精确重建精细细节时面临挑战,尤其在信息丰富的无人机遥感图像中表现更为明显。这些挑战主要源于低分辨率图像中信息的稀缺性。如图1中的第一种方法所示,SISR方法在重建包含小目标的复杂结构时存在大量模糊现象。
为实现全天候监测,现有无人机平台通常配备双模态相机,可便捷地同时获取光学图像和热成像图像的配对样本。但由于传感器成本和技术限制,光学传感器的成像分辨率通常更高。因此,利用高分辨率可见光图像引导低分辨率热成像图像生成高分辨率热成像图像的方法受到广泛关注17、18、19、20。这些方法通过特征提取网络从可见光图像中提取有价值的特征,以增强热成像特征的表征能力。尽管这种方法在简单场景中有效,但在处理无人机拍摄的遥感图像时,由于视角多样、场景复杂、结构和纹理精细,精确提取可见光特征变得极为困难。甚至可见光特征提取网络的泛化能力不足可能会产生不准确的噪声,降低超分辨率结果的质量。如图1中的第二种和第三种方法所示,当前的引导式超分辨率方法难以有效调和热成像与可见光模态之间的巨大差异,这一局限性往往导致从可见光图像中提取的信息不完整或不准确,进而导致超分辨率结果出现明显失真。由于可见光图像与热成像图像之间存在显著的外观差异,如何从可见光图像中提取有价值的线索并指导高分辨率热成像图像的生成仍有待进一步研究。
模态转换(MC)任务是缓解不同模态间差异的有效解决方案。已有多项研究聚焦于可见光到热成像的模态转换,例如用于行人重识别的热成像生成对抗网络(ThermalGAN)21、用于面部热成像生成的热脸对比生成对抗网络(TFC-GAN)22,以及通用的可见光-热成像域转换网络红外生成对抗网络(InfraGAN)23。然而,现有模态转换任务仍面临数据不一致、语义鸿沟和数据稀疏等挑战,难以在进行模态转换的同时生成高分辨率的目标域图像。当模态转换任务应用于无人机图像时,这一问题更为突出。如图1中的第四种方法所示,现有模态转换技术生成的热成像图像存在明显模糊。
由于模态转换和超分辨率任务具有相同的输出,因此可以对这两项任务进行联合训练。在各自学习深度特征表示的过程中,两种模态的特征可能会逐渐接近。同时,我们发现这两项任务之间存在相互增强的效应:模态转换任务的主要目标是将图像从可见光模态转换为热成像模态,确保中间特征与热成像域紧密对齐,这有效解决了跨模态引导超分辨率任务中的模态差异问题;同时,超分辨率任务旨在从低质量热成像图像生成高质量热成像图像,在此过程中提取的特征具有明显的热成像图像特性,有助于模态转换任务向热成像域转换,并加速训练过程。基于此,两项任务相互增强、相互促进。这种协同不仅提高了两项任务的效率,还提升了最终结果的质量。因此,模态转换与超分辨率任务的集成形成了一个动态反馈循环,其中一项任务的成功直接为另一项任务提供支持并增强其能力。此外,两项任务生成的热成像图像具有互补性,因此可以通过融合进一步提高生成的高分辨率热成像图像的质量。如图1所示,我们的模型能够将复杂的遥感可见光图像转换为热成像图像,并从中精确提取有用信息,从而有效指导超分辨率过程。我们将超分辨率输出作为最终的高分辨率热成像图像,该方法能够恢复车辆的结构信息,并清晰区分车辆数量。这种对小目标信息的优异恢复能力对于遥感图像的解译至关重要。
在本研究中,我们提出了一种用于高分辨率无人机热成像图像生成的协同增强网络(CENet)。与我们之前的工作不同,我们不再局限于从可见光图像中提取特定信息来指导热成像图像超分辨率。尽管此前的方法可以从可见光图像中提取全局场景信息,但边缘和语义线索中不可避免的不确定性导致对小目标和小区域纹理细节的恢复性能较差。我们通过联合学习模态转换任务和超分辨率任务,充分利用可见光图像中的信息,以生成高质量的高分辨率热成像图像。
首先,我们设计了一个 mutual guidance module(MGM, mutual guidance module),使两项任务能够相互增强。具体而言,我们使用两个分支分别学习模态转换和超分辨率任务的深度特征表示。鉴于Transformer24强大的特征表示能力,我们采用Transformer的注意力机制进行特征交互。为建模长期特征依赖关系并保留全局上下文,我们在特征交互前通过自注意力机制对其进行增强。为使两项任务能够协同学习,我们采用双向交叉注意力机制,将两项任务的增强特征嵌入到彼此的特征表示中。
由于模态转换任务的输出与超分辨率结果具有互补性,我们将两者融合作为最终的高分辨率结果。然而,在现有数据集中,由于模态间差异较大,手动对齐的可见光图像和热成像图像之间仍存在位置信息不匹配的问题。考虑到低级视觉任务对位置信息敏感,直接融合两个分支的输出效率较低。因此,我们设计了双向对齐融合模块(BAFM),以同时将两个分支的输出对齐到同一特征空间并进行有效特征融合。双向对齐提高了融合特征的质量,消除了因位置信息偏差导致的高分辨率热成像图像生成中的伪影。
综上所述,本文的主要贡献如下:
- 针对模态转换与超分辨率的统一,我们提出了一种新的无人机热成像图像生成任务,实现了两种图像生成任务在网络架构和学习范式上的统一。
- 所提出的CENet通过交替引导的方式联合优化图像超分辨率和模态转换,能够有效弥合不同模态间的差距,并生成更真实的细节。
- 为促进两项任务之间的相互学习,我们提出了MGM。该模块通过双向注意力机制使两个分支在特征层面相互增强,最终提升两项任务的结果。
- 为解决两项任务输出中的对齐问题,我们提出了BAFM。该模块使网络能够更有效地利用两项任务的互补性。
- 在两个可见光-热成像遥感数据集上的大量实验验证了所提出CENet的有效性。与现有最先进的SISR方法和引导式超分辨率方法相比,实验结果表明我们的方法在评价指标和视觉感知方面均表现更优。
二、相关工作
在本节中,我们回顾与本研究最相关的工作,包括单图像超分辨率(SISR)方法、引导式图像超分辨率方法和模态转换(MC)方法。
A. 单图像超分辨率方法
基于深度学习技术的单图像超分辨率近年来受到广泛关注。Dong等人12将传统的基于稀疏矩阵的超分辨率方法视为深度神经网络(DNN),首次将深度学习技术应用于图像超分辨率。随后,通过使用反卷积进行上采样25对其进行了改进,大幅提高了训练速度。Kim等人26增加了网络层数,并采用残差学习对网络进行建模,显著提升了结果性能。Lim等人27提出了更深更大的网络,并设计了多尺度超分辨率系统。Wang等人28提出了一种注意力辅助特征学习方法,以实现轻量化超分辨率网络。残差通道注意力网络(RCAN)13首次将注意力机制引入超分辨率领域,此后涌现出多种基于注意力机制的超分辨率方法,如二阶注意力29和混合注意力14。
随着Transformer24、30、31的出现,用于图像恢复的Swin Transformer(SwinIR)15以更精简的参数显著提升了超分辨率性能,Zamir等人16则将自注意力扩展到通道层面。近期研究还表明,扩散模型(DM)能够生成极具前景的结果。Saharia等人32通过集成额外的残差块增强了扩散模型的架构,这一修改将低分辨率图像引入随机迭代去噪过程,有助于实现超分辨率。Yan等人33提出了一种融合注意力机制和域特征对齐的特征生成器,利用生成器的输出特征作为扩散模型框架中的条件,以解决生成图像中的伪影问题。Chen等人34提出了一种分层集成扩散模型,通过在高度压缩的潜在空间中增强扩散过程,提高了模型的效率。
由于成像系统的限制,热成像图像的分辨率较低,因此热成像超分辨率开始受到关注。在单图像超分辨率领域,Choi等人35提出了首个基于卷积神经网络(CNN)的热成像超分辨率模型。Chudasama等人36采用非对称残差学习网络,并为高频和低频信息设置不同的特征提取模块,取得了较好的结果。Prajapati等人37提出了一种基于通道拆分的CNN,用于消除热成像超分辨率中的冗余特征。Wang等人38将红外相机的内部参数显示建模为特征表示,提升了模型在多种传感器数据集上的超分辨率性能。尽管这些单图像可见光和单图像热成像超分辨率方法取得了一些进展,但在大尺度超分辨率任务中,这些单图像超分辨率方法生成的高分辨率图像仍存在失真。
B. 引导式图像超分辨率方法
随着多模态技术的广泛应用,引导式超分辨率方法也取得了一定进展。Hui等人39提出使用高分辨率强度图像引导深度图进行超分辨率。Sun等人40从RGB相机中提取场景结构信息,并提出深度估计任务,通过联合训练深度图超分辨率任务和深度估计任务以获得更好的性能。Fu等人41提出了一种基于CNN的无监督高光谱图像超分辨率网络,将RGB相机的光谱响应(CSR)作为先验知识。在磁共振(MR)图像超分辨率中,Fang等人42首次提出了一种跨模态Transformer架构,利用高分辨率T1W1图像引导低分辨率T2W1图像进行超分辨率。Dong等人43提出了一种 mutual guidance network( mutual guidance network),通过在CNN架构上采用互调制策略来利用跨模态依赖关系。
在热成像超分辨率领域,Han等人17利用CNN的局部感知特性从可见光图像中提取高频信息,以补充热成像图像缺失的纹理特征。然而,该方法未考虑全局特征的提取,也忽略了低频信息在引导超分辨率过程中的作用。Gupta和Mitra18提出了一种基于金字塔结构的可见光图像边缘特征提取网络,利用多尺度可见光边缘信息辅助超分辨率。但这种方法未能充分利用可见光图像中包含的所有有用信息。为了更好地利用可见光图像中的有效信息,有研究提出了特征对比损失,以在特征提取过程中减小两种模态特征之间的差异19。然而,经过处理后,热成像和可见光特征只是简单地融合在一起,缺乏充分的特征交互。考虑到视觉Transformer(Vision Transformer)44强大的特征提取和长距离关系处理能力,Zhao等人20提出从可见光图像中提取不同线索(包括外观、边缘和语义信息),然后通过跨模态注意力机制将其嵌入到热成像特征中,以获得更好的结果。
这些方法均用于引导热成像图像的超分辨率过程。尽管当前引导式超分辨率中出现了许多可见光特征提取方法,但在复杂场景中,这些方法总会导致可见光信息的丢失和失真。如何有效且充分地利用可见光图像成为一个关键问题。因此,在本文中,我们创新性地将模态转换任务与超分辨率任务相结合,通过协同学习中的特征交互有效弥合两种模态之间的差距,充分利用可见光图像中的信息。
C. 模态转换方法
在图像处理中,多模态通常包括可见光、热成像、深度以及各种医学成像模态。将图像从一种模态转换为另一种模态的任务称为模态转换。随着各种生成对抗网络(GAN)的发展和兴起,如GAN45、循环一致性对抗网络(Cycle-GAN)46、判别性部分域对抗网络(DPGAN)47和对抗性潜在GAN(AdvLatGAN)48,图像从一种模态到另一种模态的转换任务得以实现,并取得了良好的结果。PixToPix49采用Unet网络架构作为生成器,在双模态数据集上使用条件GAN作为判别器,结合GAN损失和L1损失进行有监督训练,取得了较好的性能。Cycle-GAN46解决了训练时缺乏配对图像的问题。Star GAN(StarGAN)50实现了三种以上图像域之间的相互转换。Wang等人51提出了一种多域配对图像转换框架,利用不同域对之间的共享信息进行相互学习以实现图像转换。Albahar和Huang52开发了一种基于卷积的双向特征交互模块,以进一步挖掘引导图像中包含的条件信息。
近年来,热成像与可见光图像之间的模态转换也得到了研究。Berg等人53提出了一种基于CNN的两步转换方法,用于热成像图像到可见光图像的端到端转换。Liu等人54通过利用近红外光照下单芯片硅基RGB相机的成像机制,在热成像到可见光图像的转换中取得了良好的性能。Moradi和Ghaderi55提出了一种专门用于将可见光图像转换为热成像图像的对抗生成网络。Yi等人56提出了一种基于梯度归一化的循环生成对抗方法,以获得更好的结果。
由于遥感图像与自然图像存在差异,尽管自然图像的模态转换任务取得了一些进展,但遥感图像模态转换任务的结果仍不尽如人意。我们提出的协同框架中的模态转换任务旨在填补这一空白。
三、CENet:用于高分辨率无人机热成像图像生成的协同增强网络
3.1节将讨论用于高分辨率无人机热成像图像生成的CENet的整体设计。我们提出的MGM和BAFM将分别在3.2节和3.3节中详细介绍。最后,3.4节将讨论CENet的损失函数。
A. 整体框架
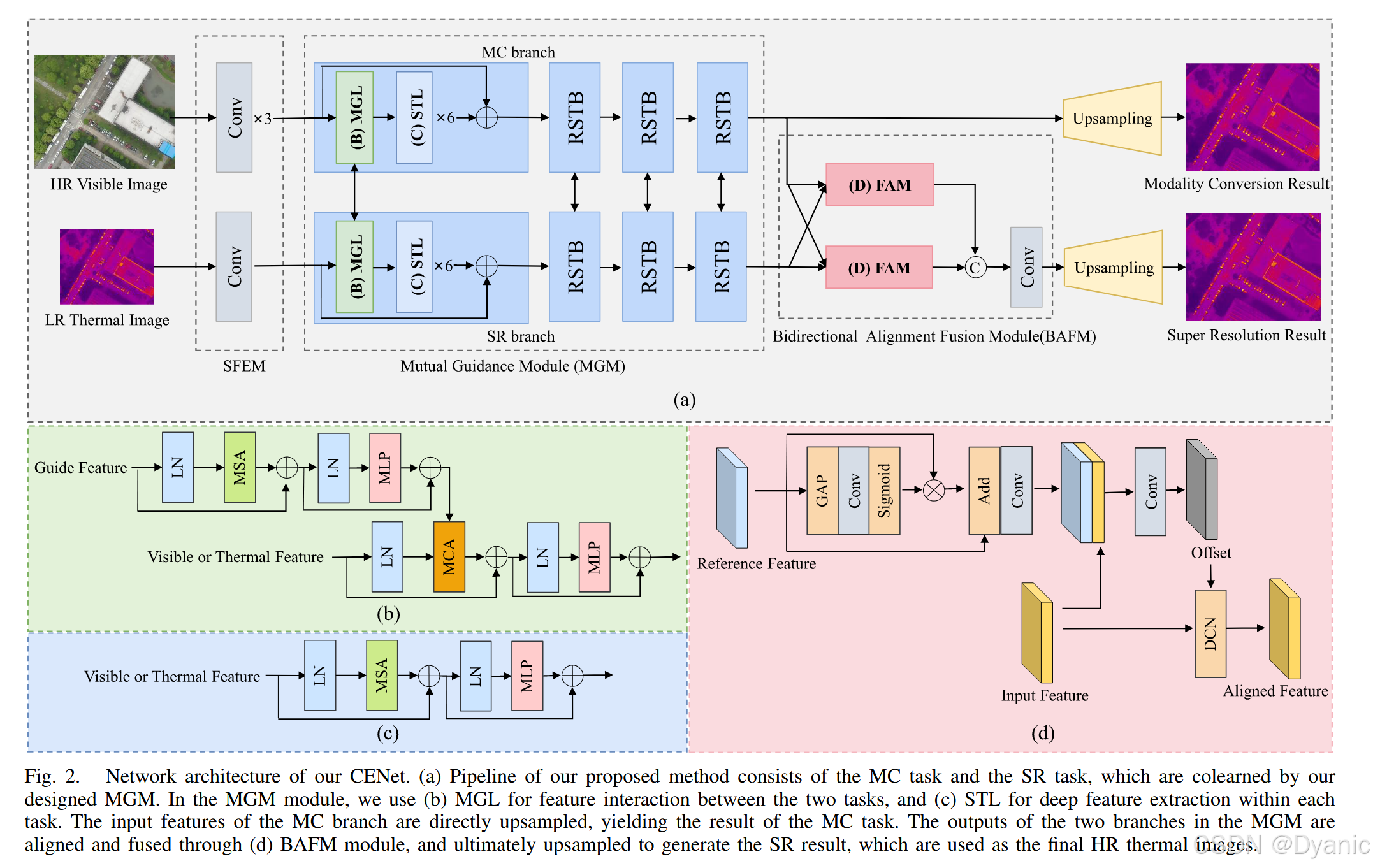
模态转换(MC)任务和超分辨率(SR)任务可以相互耦合、相互促进,因此将这两个任务结合起来至关重要。鉴于Swin Transformer57在超分辨率领域取得的重大进展,我们选择SwinIR15模型作为基线。在SwinIR的基础上,我们提出了一种新的协同训练框架CENet,其中超分辨率任务可以为模态转换任务提供丰富的热信息,而模态转换任务则为无人机热成像图像超分辨率解决跨模态差异问题。如图2(a)所示,我们的CENet包含三个部分:浅层特征提取模块(SFEM)、mutual guidance module(MGM, mutual guidance module)和双向对齐融合模块(BAFM)。
1)浅层特征提取模块:对于不同模态的图像,我们对其进行不同类型的浅层特征提取。对于热成像图像,我们采用单个3×3卷积层来扩展相应特征图的通道数。由于可见光图像比热成像图像分辨率更高,且包含丰富的高频信息,我们使用三个3×3卷积进行特征提取。这种方法能够有效提取两种模态的浅层特征,并保留各自的独特信息。
2)交互指导模块:为促进两个任务之间的协同学习和相互增强,我们提出了MGM。在MGM中,有两个分支分别用于两个子任务的深度特征提取,并采用双向注意力传递机制,使两个任务之间能够进行全面的特征交互,从而生成用于模态转换和超分辨率的高质量特征。
3)双向对齐融合模块:由于模态转换任务和超分辨率任务的输入不同,且受不同损失的限制,它们的输出具有互补性。为纠正可见光图像与热成像图像的位置偏差并进行有效融合,我们设计了BAFM,对两个分支输出的特征进行精细对齐和融合。融合后的特征经过上采样,得到高分辨率热成像图像。
B. 交互指导模块
为使两个任务能够学习彼此的特征表示,我们设计了MGM,它是CENet的核心组件。在MGM中,有两个分支分别用于两个子任务的深度特征提取,并采用双向注意力传递机制,使两个任务之间能够进行全面的特征交互,从而生成用于模态转换和超分辨率的高质量特征。MGM的结构如图2(a)所示,该模块包含两个分支,即模态转换分支和超分辨率分支。每个分支由四个残差Swin Transformer块(RSTB)组成,每个RSTB包含六个Swin Transformer层(STL)和一个我们设计的交互指导层(MGL, mutual guidance layer)。MGL和STL的结构分别如图2(b)和(c)所示。
为学习长期依赖关系并保留全局上下文信息,MGL首先通过多头自注意力(MSA)和移位窗口机制增强来自对侧分支的引导信息。然后,通过多头交叉注意力(MCA)和移位窗口机制生成来自对侧分支的注意力,并利用该注意力进行引导。对于局部窗口特征,MSA中的查询、键和值矩阵QQQ、KKK、VVV均来自同一输入特征。在MCA中,这些矩阵的计算如下:
Q=YWQ,K=YWK,V=XWV(1) Q = Y W^Q,K = Y W^K,V = X W^V \tag{1} Q=YWQ,K=YWK,V=XWV(1)
其中WQW^QWQ、WKW^KWK、WVW^VWV是线性投影矩阵,在不同窗口之间共享。XXX表示当前分支输入的特征,Y表示来自对侧分支的特征。
注意力矩阵通过局部窗口内的自注意力或交叉注意力机制计算,如下所示:
Attention(Q,K,V)=softmax(QKT/dk+B)V(2) Attention(Q, K, V) = softmax(QKT /\sqrt{d_k} + B)V \tag{2} Attention(Q,K,V)=softmax(QKT/dk +B)V(2)
其中BBB是可学习的相对位置编码矩阵,dkd_kdk是查询K的维度,Attention(⋅)Attention(·)Attention(⋅)表示自注意力或交叉注意力。在MSA中,QQQ、KKK、VVV来自自身分支;在MCA中,QQQ和KKK来自对侧分支传递的特征,VVV来自自身分支输入的特征。
STL中的整个过程公式如下:
Y=MSA(LN(Y))+YY=MLP(LN(Y))+Y(3) Y = MSA(LN(Y)) + Y \\ Y = MLP(LN(Y)) + Y \tag{3} Y=MSA(LN(Y))+YY=MLP(LN(Y))+Y(3)
其中MSA、MLP和LN分别表示多头自注意力、多层感知机和层归一化的函数,Y表示输入特征。
引导特征在与当前分支的特征结合计算交叉注意力之前,先经过STL处理。整个过程公式如下:
Y=STL(Y)Xl=MCA(LN(Xl−1),Y)+Xl−1Xl+1=MLP(LN(Xl))+Xl−1(4) Y = STL(Y) \\ X^l = MCA(LN(X^{l−1}), Y) + X^{l−1} \\ X^{l+1} = MLP(LN(X^{l})) + X^{l-1} \tag{4} Y=STL(Y)Xl=MCA(LN(Xl−1),Y)+Xl−1Xl+1=MLP(LN(Xl))+Xl−1(4)
其中STL表示Swin Transformer层,MCA表示多头交叉注意力函数,MLP和LN分别表示多层感知机和层归一化。XXX和YYY分别表示当前分支的特征和来自对侧分支的特征。
在RSTB的特征处理中,我们仅设置一个MGL用于两个分支的特征交互,之后设置独立不干扰的STL组,使两种模态在信息交互后能够通过各自的STL处理接收的信息,从而更专注于各自的任务。
C. 双向对齐融合模块
经过MGM模块后,我们得到来自可见光的模态转换特征和来自热成像的超分辨率特征,此时两种特征的域信息已非常相似。为消除两种特征在位置信息上的差异,并挖掘特征之间的互补潜力,我们设计了BAFM对两种特征进行对齐和融合,其结构如图2(a)所示。
受特征对齐金字塔网络(FaPN)58的启发,我们首先将模态转换特征和超分辨率特征输入两个特征对齐模块(FAM)。FAM的结构如图2(d)所示。在进行特征对齐之前,我们先选择参考特征,并明确建模特征的重要性依赖关系,以避免冗余信息的干扰。过程如下:
Xselt=Conv(Xref+u∗Xref)u=σ(Conv(GAP(Xref)))(5) X_{selt} = Conv(X_{ref} + u ∗ X_{ref}) \\ u = σ(Conv(GAP(X_{ref}))) \tag{5} Xselt=Conv(Xref+u∗Xref)u=σ(Conv(GAP(Xref)))(5)
其中XrefX_{ref}Xref表示参考特征,XseltX_{selt}Xselt表示选择后的特征,GAP表示全局平均池化层,Conv表示1×1卷积,σσσ表示sigmoid激活函数。
根据待对齐特征和选择后的参考特征的组合预测映射参数偏移量,然后通过可变形卷积利用该偏移量对受对齐特征进行对齐。过程如下:
FAM(Xref,Xin)=DCN(Xin,Δ)Δ=Conv(Xselt,Xin)(6) FAM(X_{ref}, X_{in}) = DCN(X_{in}, Δ)\\ Δ = Conv(X_{selt}, X_{in}) \tag{6} FAM(Xref,Xin)=DCN(Xin,Δ)Δ=Conv(Xselt,Xin)(6)
其中XseltX_{selt}Xselt表示选择后的参考特征,XinX_{in}Xin表示待对齐特征,⋅,⋅·, ·⋅,⋅表示沿通道维度的拼接操作,Conv表示1×1卷积,Δ表示可变形卷积中的偏移量,XrefX_{ref}Xref表示参考特征,DCN表示可变形卷积。
经过两个FAM后,对齐后的特征进行通道拼接操作,然后通过3×3卷积减少通道数,作为最终输出特征。整个BAFM模块的公式如下:
Xout=Conv(FAM1(Xmc,Xsr),FAM2(Xsr,Xmc))(7) X_{out} = Conv(FAM_1(X_{mc}, X_{sr}), FAM_2(X_{sr}, X_{mc})) \tag{7} Xout=Conv(FAM1(Xmc,Xsr),FAM2(Xsr,Xmc))(7)
其中⋅,⋅·, ·⋅,⋅表示沿通道维度的拼接操作,XmcX_{mc}Xmc和XsrX_{sr}Xsr分别表示MGM模块中模态转换分支和超分辨率分支的输出,FAM1FAM_1FAM1和FAM2FAM_2FAM2表示两个结构相同的FAM模块,Conv表示3×3卷积层。
D. 损失函数
CENet的输入是高分辨率可见光图像和低分辨率热成像图像,其中低分辨率热成像图像通过对真值(GT)热成像图像下采样得到。可见光图像和热成像图像首先输入SFEM,然后可见光特征和热成像特征被送入MGM中的两个不同分支,用于建模深度特征表示。对于模态转换任务,其MGM分支的输出特征直接通过像素重排(pixelshuffle)上采样,得到作为模态转换任务输出的图像。对于超分辨率任务,利用BAFM对MGM的模态转换分支和超分辨率分支的特征进行精细对齐和融合,最后对融合后的特征进行像素重排上采样,得到超分辨率结果。我们将超分辨率结果作为整个框架生成的最终高分辨率热成像图像。
为获得准确的模态转换结果,我们采用pix2pix论文中的损失函数进行输出评估。该方法结合了L1损失和条件GAN损失,其中L1损失的计算如下:
Lpix=∣∣Imc−Ihr∣∣1(8) \mathcal{L}{pix} = ||I{mc} − I_{hr}||_1 \tag{8} Lpix=∣∣Imc−Ihr∣∣1(8)
其中ImcI_{mc}Imc表示模态转换结果,IhrI_{hr}Ihr表示真值热成像图像。
由于欧氏距离约束会导致图像模糊,我们在模态转换任务中引入条件GAN损失,其公式如下:
Ladv=Ex,ylogD(x,y)+Ex,zlog(1−D(G(x,z)))(9) \mathcal{L}{adv} = \mathbb{E}{x,y}log D(x, y) + \mathbb{E}_{x,z}log(1 − D(G(x, z))) \tag{9} Ladv=Ex,ylogD(x,y)+Ex,zlog(1−D(G(x,z)))(9)
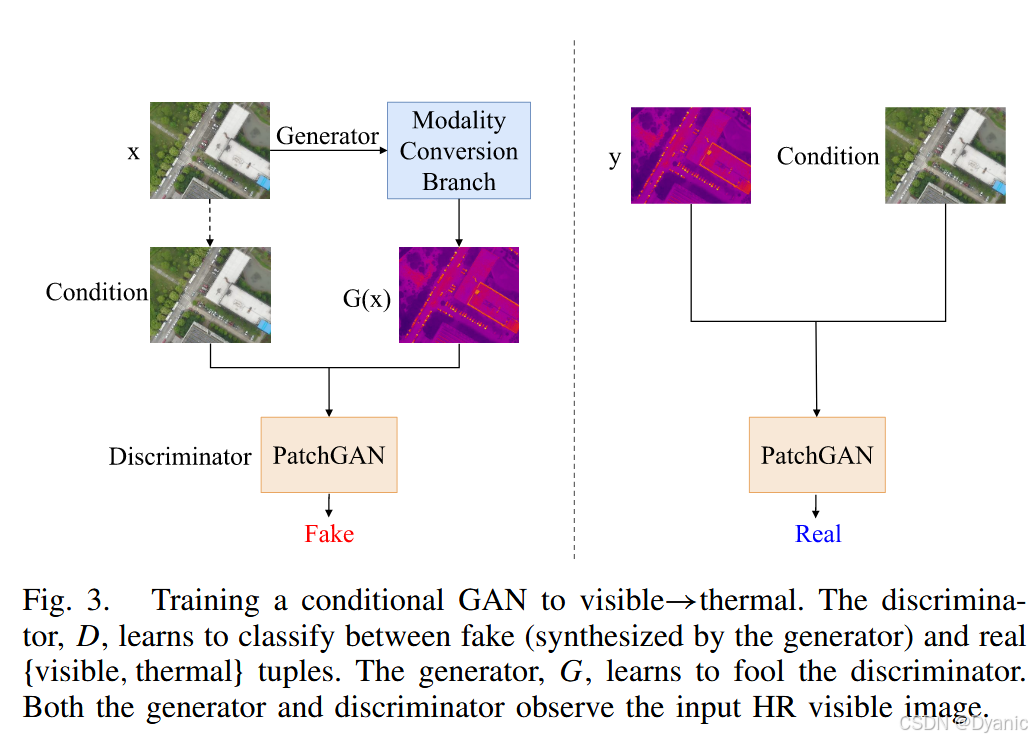
其中xxx表示输入的可见光图像,yyy表示真值热成像图像,zzz表示随机噪声,DDD表示判别器,GGG表示生成器。如图3所示,在输入判别器计算损失之前,真值热成像图像和预测的模态转换图像都与高分辨率可见光图像在通道上进行拼接。
模态转换任务的总损失函数如下:
Lmc=αLadv+βLpix(10) \mathcal{L}{mc} = αL{adv} + βL_{pix} \tag{10} Lmc=αLadv+βLpix(10)
其中ααα和βββ是超参数,我们遵循Pix2pix49的设置,令α=1α=1α=1,β=100β=100β=100。
对于超分辨率任务的输出,我们使用传统的L1损失进行约束,损失计算如下:
Lsr=∣∣Isr−Ihr∣∣1(11) \mathcal{L}{sr} = ||I{sr} − I_{hr}||_1 \tag{11} Lsr=∣∣Isr−Ihr∣∣1(11)
其中IsrI_{sr}Isr是我们超分辨率任务的预测结果,IhrI_{hr}Ihr是真值热成像图像。
为平衡两个任务的训练,我们采用不确定性损失61作为整个模型的最终损失函数,损失计算如下:
Ltotal=12σ12Lmc+12σ22Lsr+log(σ1σ2)(12) \mathcal{L}{total} = \frac{1}{2σ₁²}L{mc} + \frac{1}{2σ₂²}L_{sr} + log(σ₁σ₂) \tag{12} Ltotal=2σ121Lmc+2σ221Lsr+log(σ1σ2)(12)
其中LmcL_{mc}Lmc和LsrL_{sr}Lsr分别表示模态转换任务和超分辨率任务的损失函数,σ₁和σ₂是可学习参数,分别表示LmcL_{mc}Lmc和LsrL_{sr}Lsr的损失权重,损失函数的最后一项log(σ1σ2)log(σ₁σ₂)log(σ1σ2)作为权重的正则化项。
四、实验
在本节中,我们在VGTSR20数据集和DroneVehicle62数据集上对所提出的CENet和其他最先进的方法进行了全面评估。首先,我们将在4.1节介绍实验中使用的两个无人机视角可见光-热成像图像数据集和评估指标。4.2节将介绍CENet的实现细节。然后,4.3节将研究我们的CENet的有效性,最后4.4节将报告消融实验和可视化结果。
A. 数据集和评估指标
VGTSR数据集是在无人机平台下构建的,用于可见光引导的无人机热成像图像超分辨率。它包含1025对可见光和热成像图像,分辨率均为640×512,且经过人工对齐,其中800张图像用于训练,225张图像用于测试。该数据集包含校园和街道两个主要场景,并在不同天气条件和一天中的不同时间拍摄。
DroneVehicle数据集是一个基于无人机平台的大规模RGB-红外车辆检测数据集,包含总共28439对RGB-红外图像,涵盖城市、道路、居民区、停车场等昼夜场景。原始未标记图像的分辨率为840×712,且RGB图像和相应的热成像图像是对齐的。由于原始数据集规模较大,我们从中选取1000张图像作为训练集,300张图像作为测试集,并进行双三次(BI)和模糊下采样(BD)作为模型的输入。为确保训练集和测试集的独立分布,我们让训练集和测试集都包含不同时间段的图像。
为了定量评估生成的高分辨率热成像图像的质量,我们使用两个常用的评估指标:峰值信噪比(PSNR)和结构相似性指数(SSIM)。PSNR和SSIM的值越高越好。
B. 实现细节
我们的模型在配备24GB内存的RTX 3090 GPU平台上训练,实现基于公开平台PyTorch。在我们提出的CENet中,卷积核大小、嵌入维度、窗口大小、注意力头数和补丁大小分别设置为3×3、96、8、6和1。我们的模态转换分支和超分辨率分支各包含四个RSTB,每个RSTB有一个MGL模块和六个STL模块。对于模态转换分支,我们始终输入高分辨率可见光图像。对于超分辨率分支,我们输入经过BI或BD退化处理的低分辨率热成像图像。
为了减少训练过程中的内存使用,通常的做法是随机裁剪图像,并使用得到的补丁作为模型的输入。仅在测试时才将整个图像输入模型。为了与基线SwinIR和其他超分辨率方法保持一致,我们每次裁剪得到一个像素大小为48×48的补丁作为输入。对于4倍超分辨率,我们从低分辨率热成像图像中裁剪一个48×48的补丁,并从高分辨率可见光图像上的相应位置裁剪一个192×192的补丁。对于8倍超分辨率,我们从低分辨率热成像图像中裁剪一个48×48的补丁,并从高分辨率可见光图像上的相应位置裁剪一个384×384的补丁。通过裁剪获得的可见光和热成像补丁用作模型的输入。
我们采用自适应矩估计(ADAM)优化器,其中β1=0.9,β2=0.99,ε=10⁻⁸。模型使用的小批量大小为8。为了促进模型收敛,我们首先冻结BAFM的参数,对整个网络的其他权重进行200个epoch的预训练,然后花费50个epoch仅训练BAFM,最后以端到端的方式训练整个模型。学习率最初设置为10⁻⁴,然后每200个epoch衰减一半。
C. 定量和定性评估
为了验证CENet的有效性,我们在VGTSR数据集和DroneVehicle数据集上进行了可见光引导的热成像图像的模态转换实验和不同尺度的超分辨率实验。在VGTSR数据集上,我们报告了当前最先进的模态转换方法InfraGAN23,以及八种最先进的单图像超分辨率方法,包括基于CNN的密集深度反投影网络(DDBPN)59、残差密集网络(RDN)60、二阶注意力网络(SAN)29和增强深度超分辨率网络(EDSR)27,基于通道注意力机制的RCAN13方法和添加了层注意力的整体注意力网络(HAN)方法,以及基于Transformer的方法SwinIR和Restormer。此外,还有四种引导式超分辨率方法:MultiNet17、基于金字塔边缘图和注意力的引导式超分辨率(PAG-SR)18、未对齐引导式热成像超分辨率(UGSR)19和多条件引导网络(MGNet)20,其中MGNet目前具有最佳性能。
表I显示了在VGTSR数据集上使用BI和BD退化模型的4倍和8倍超分辨率结果。与单图像超分辨率方法和引导式超分辨率方法相比,在4倍超分辨率情况下,我们的方法在使用BI退化模型时,PSNR提高了0.08dB,SSIM提高了0.0002;在使用BD退化模型时,PSNR提高了0.14dB,SSIM提高了0.003。在8倍超分辨率下,对于BI退化模型,我们的方法PSNR提高了0.17dB,SSIM提高了0.011;对于BD退化模型,我们的方法PSNR指标提高了0.17dB,SSIM提高了0.0009。
不同的单图像超分辨率方法在性能上非常接近,而在引导式超分辨率中,尽管MultiNet和UGSR参考了高分辨率可见光图像,但由于仅使用了简单的特征交互方法,导致可见光图像中对热成像无意义的噪声被引入,因此PSNR和SSIM较低。PAG-SR优于几乎所有单图像超分辨率方法,因为它使用金字塔网络从可见光图像中提取边缘信息,减少了噪声的影响。MGNet引入了边缘、语义和外观线索,使其比其他方法具有显著优势。通过引入模态转换、任务辅助超分辨率,并使用双向特征对齐融合,我们的CENet实现了最佳性能。
我们的模型在DroneVehicle数据集上也获得了最佳性能,如表II所示。与单图像超分辨率方法和引导式图像超分辨率方法相比,我们的CENet在4倍超分辨率设置下,BI退化情况下提高了0.96dB,BD退化情况下提高了1.36dB;在8倍超分辨率设置下,BI退化情况下显著提高了2.65dB,BD退化情况下提高了1.78dB。对于SSIM评估指标的测试,在4倍超分辨率的BI退化方法情况下,我们提高了0.012;在8倍超分辨率情况下,提高了0.087。在BD退化方法情况下,4倍超分辨率我们显著提高了0.018,8倍超分辨率提高了0.049。
我们的模型不仅在PSNR和SSIM评估指标上取得了良好的性能,在感知质量上也有显著提升。如图4-7所示,与主流的模态转换方法相比,我们的模态转换结果已经呈现出更丰富的信息。在此基础上,我们的CENet超分辨率结果恢复的纹理细节和结构信息最接近真值热成像图像。特别是在8倍超分辨率中,一些可见光结构信息由于两种模态之间的巨大差异,不可避免地将可见光图像中的噪声纳入热成像图像,导致纹理紊乱和结构失真现象。我们的CENet通过模态转换和超分辨率任务的协同学习,减少了两种模态之间的域差异,从而解决了这些问题。从可视化结果可以看出,我们的CENet恢复了更好的纹理细节和结构信息。
与其他单图像超分辨率和引导式超分辨率模型相比,我们的模型在参数数量方面也具有一定优势。图8显示了不同超分辨率方法的模型大小和性能比较。结果表明,我们提出的方法在性能上优于其他现有技术,同时使用更少的参数,消耗更少的内存。与当前性能最佳的模型相比,我们模型的参数数量减少了36%。在推理时间方面,对于分辨率为512×640的图像,当前的单图像超分辨率方法和最先进的引导式超分辨率方法在4倍超分辨率下的测试时间分别为0.16秒、0.48秒,而我们的CENet为0.45秒,我们在性能和推理速度之间取得了良好的平衡。
D. 消融实验
- 协同学习框架的有效性:为了验证协同学习策略的有效性,我们将协同学习模型分解为两个子任务:超分辨率和模态转换。实验结果如表III所示。当我们仅训练模态转换任务或仅训练超分辨率任务时,PSNR分别显著下降2.68dB和0.75dB,SSIM也分别下降0.1167和0.0349。然而,当两个任务一起训练时,PSNR和SSIM显著高于单独训练任一子任务时的结果。
图9展示了单独学习和协同学习的可视化结果。可以看出,单一的模态转换或超分辨率会导致大量的模糊,我们的协同学习策略能够更有效地从可见光中提取信息并恢复真实的细节信息。同时,为了确定性能提升是否来自使用更大的模型,我们通过增加RSTB的数量,对具有相似参数数量的单一超分辨率、单一模态转换、引导式超分辨率、引导式模态转换和我们的CENet进行了对比实验。表IV显示了结果,表明在参数数量相似的情况下,单任务模型和引导信息模型与我们的方法相比都存在显著的性能差距。这突出了我们的协同学习框架的优越效率。
-
浅层特征提取模块的有效性:为了验证在浅层特征提取模块中为可见光和热成像图像设计不同数量卷积的适当性,我们根据卷积数量的不同设置了几组对比实验。当可见光图像和热成像图像都设置单个卷积时,由于对可见光图像的特征提取不足,PSNR和SSIM分别下降到25.87和0.7526。当可见光和热成像都设置三个卷积时,由于热成像图像分辨率较低,过多的卷积操作导致特征冗余,PSNR和SSIM分别下降到25.98和0.7587。因此,如果可见光图像设置三个卷积,热成像设置一个卷积,两者的浅层特征都能得到很好的提取,在精度和效率之间达到最佳平衡。
-
mutual guidance module和双向对齐融合模块的有效性:为了验证MGM模块的有效性,我们设计了不同的深度特征提取模块,例如没有任何特征交互,只有两个独立的RSTB主干,热成像单向引导可见光,可见光单向引导热成像以及我们的MGM。同时,我们在不同情况下添加或移除BAFM模块,以验证其有效性。实验结果如表V所示。与基线相比,在协同学习框架中使用我们提出的特征交互方法获得了改进。当使用单向特征交互时,无论是模态转换任务的特征传递到超分辨率任务,还是超分辨率任务的特征传递到模态转换任务,都有一定的改进效果。然而,单向引导无法弥合两种模态之间的巨大差距,因此结果仍不令人满意。通过使用 mutual guidance(即我们的MGM模块),实验效果进一步增强。同时,在BAFM模块中,将两个分支输出的特征对齐到同一特征空间,消除位置信息差异,实现高效融合。当使用MGM模块时,我们的方法将PSNR提高了0.52(从25.28到25.80),SSIM提高了0.0257(从0.7240到0.7497)。在此基础上,添加BAFM模块进一步将PSNR提高了0.23(从25.80到26.03),SSIM提高了0.0105(从0.7497到0.7602)。
为了进一步验证BAFM模块的有效性,使用了不同的融合方法,例如元素相加或拼接来融合两个任务的输出特征,结果如表VI所示,从中可以看出BAFM模块中的双向对齐融合方法充分利用了两个分支之间的互补信息,并获得了更好的性能。
- 超参数的选择:超参数对我们方法性能的影响如图10所示,从中我们可以观察到以下情况:1)当RSTB的数量t设置为4时,我们的方法达到最佳性能。2)增加RSTB模块中STL的数量t可以提高深度特征的建模能力,但当r>6时性能饱和。3)对于MCA和MSA模块,更大的窗口大小w更有利于挖掘上下文先验,但当w>8时性能饱和。4)增加注意力头数可以增强特征提取能力,但当注意力头数h>6时,性能趋于饱和。
消融实验的结果验证了模态转换和超分辨率协同学习的有效性,以及我们提出的MGM充分实现了两个任务之间高效的特征交互。我们的BAFM双向对齐两个任务的输出,消除了位置信息差异,并在高效融合后取得了更好的结果。
五、结论
在本文中,我们提出了CENet,一种用于高分辨率无人机热成像图像生成的协同增强网络。MGM利用双向跨模态注意力机制促进模态转换任务和超分辨率任务之间的全面特征交互,以弥合模态之间的差距。这种方式有效地保留了相关信息,在各项任务中都取得了最佳性能。BAFM通过双向特征对齐减轻了两个任务输出特征之间的位置信息差异。这个过程实现了高效的特征融合,并利用了两个任务输出的互补潜力。
在两个可见光-热成像遥感数据集上进行的实验表明,我们的方法生成了信息丰富的模态转换结果。与其他最先进的超分辨率方法相比,我们的方法在各种指标上都取得了最佳值,并且在视觉感知方面实现了出色的高分辨率热成像图像生成。
在未来的工作中,我们将研究将扩散模型纳入我们的协同框架,并进一步探索不同模态的未对齐图像对的高分辨率热成像图像生成。