HashMap 的put流程中,为什么第一步是计算 Key 的哈希值?本文从 "是什么"、"解决什么问题" 和 "如何计算" 三个维度来理解。
具体来说,put方法的大致流程是:
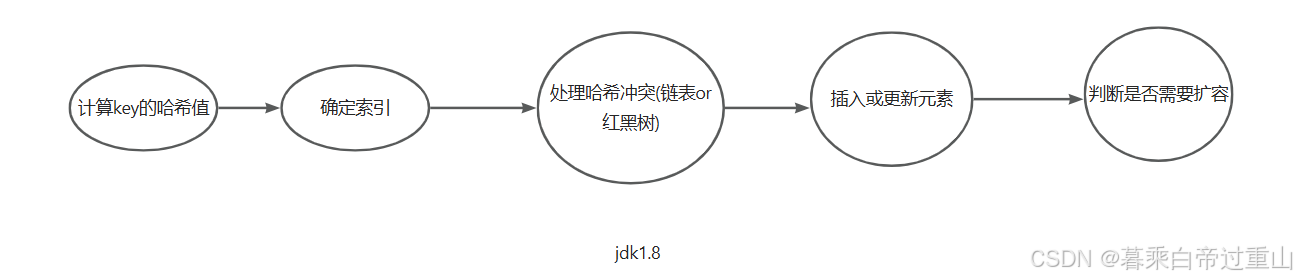
因此,计算哈希值是整个流程的起点,没有哈希值就无法确定元素应该存在哪里。
二、计算哈希值能解决什么问题?
核心解决 "如何将任意类型的 Key 高效映射到固定范围的数组索引" 的问题,具体体现在:
-
实现快速定位 :
数组的优势是 "随机访问"(通过索引直接定位元素,时间 O (1)),但数组索引是整数且范围固定(0~n-1)。哈希值通过计算能将任意类型的 Key(如 String、自定义对象等)转换为整数,再进一步映射到数组索引,从而利用数组的高效访问特性。
-
减少哈希冲突概率 :链接:什么是哈希冲突
好的哈希计算能让不同的 Key 尽量生成不同的哈希值,从而均匀分布到数组的不同位置,避免大量元素集中在同一个索引(减少链表 / 红黑树的长度),保证操作效率。
-
适配数组容量 :
哈希值经过处理后能被限制在数组容量范围内(如通过
hash & (n-1)计算索引),确保元素不会存储到数组之外。
三、哈希值的计算过程(JDK 1.8)
HashMap 对 Key 的哈希值计算分为三步,层层优化以保证分布均匀性:
1. 调用 Key 的hashCode()方法
每个对象(包括自定义对象)都继承了Object类的hashCode()方法,返回一个 32 位整数。
- 例如:
"abc".hashCode()的结果是96354;Integer.valueOf(100).hashCode()的结果是100。 - 作用:将任意类型的 Key 转换为一个整数(哈希值的基础)。
2. 扰动函数(二次哈希)
直接使用hashCode()的结果可能导致 "高位特征被忽略"(因为数组容量通常较小,如初始 16,计算索引时只会用到哈希值的低几位)。因此 JDK 1.8 通过扰动函数混合高位和低位:
java
static final int hash(Object key) {
int h;
// key为null时哈希值为0;否则将hashCode与自身右移16位的结果异或
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}- 原理:将哈希值的高 16 位与低 16 位进行异或(
^),让高位的特征 "混入" 低位,增加哈希值的随机性。 - 例:若
hashCode()结果为0x12345678,右移 16 位后为0x00001234,异或后得到0x1234444c,高低位特征均被保留。
3. 计算数组索引
通过位运算将扰动后的哈希值映射到数组容量范围内:
java
// n为数组容量(必须是2的幂,如16、32等)
int index = hash & (n - 1);- 等价于
hash % n(取模运算),但位运算&效率更高。 - 例:当容量
n=16时,n-1=15(二进制1111),任意哈希值与15做&运算,结果一定在0~15之间(符合数组索引范围)。
最后归纳
- 第一步是计算哈希值:这是 HashMap 将 Key 映射到数组索引的基础,是实现高效存取的前提。
- 解决的核心问题:将任意类型 Key 转换为可用于数组索引的整数,同时通过优化分布减少冲突,保证效率。
- 计算逻辑 :
hashCode()→ 扰动函数(混合高低位) → 位运算(hash & (n-1))→ 得到索引。
这种设计既利用了数组的快速访问特性,又通过哈希优化平衡了时间和空间效率,是 HashMap 高性能的关键。