基于 Flask 的电信用户流失信息分析系统:从零到一的实战分享
一套可落地的企业级客户流失分析与预测系统,覆盖数据建模、可视化大屏、权限体系、预测训练全流程。
目录
- 背景与目标
- 功能总览与系统截图说明
- 技术栈与架构设计
- 项目目录结构说明
- 核心功能与关键代码
- 鉴权与权限控制
- 客户数据管理(导入/导出/搜索筛选)
- 数据分析与可视化
- 机器学习训练与预测
- 仪表盘与业务指标
- 安装部署与初始化
- 可视化展示占位(可替换为实际效果)
- 常见问题与优化建议
- 结语与联系
- 毕业设计必备章节
- 需求分析
- 系统设计(架构/模块/流程)
- 数据库设计(表结构)
- API 设计与说明
- 实验与评估(指标与结果)
- 创新点与难点攻关
- 答辩要点与演示脚本
背景与目标
电信行业天然具备高频、长周期、强服务属性的特征,客户流失(Churn)预警与挽留是降本增效的重要抓手。本项目面向实际业务场景,提供:
- 客户全量信息管理与批量导入导出
- 多维度统计分析与趋势洞察
- 机器学习模型训练与在线预测
- 角色/权限/日志等通用后台能力
目标是开箱即用、易扩展、可自定义,既适合教学演示,也能作为中小业务的落地骨架。
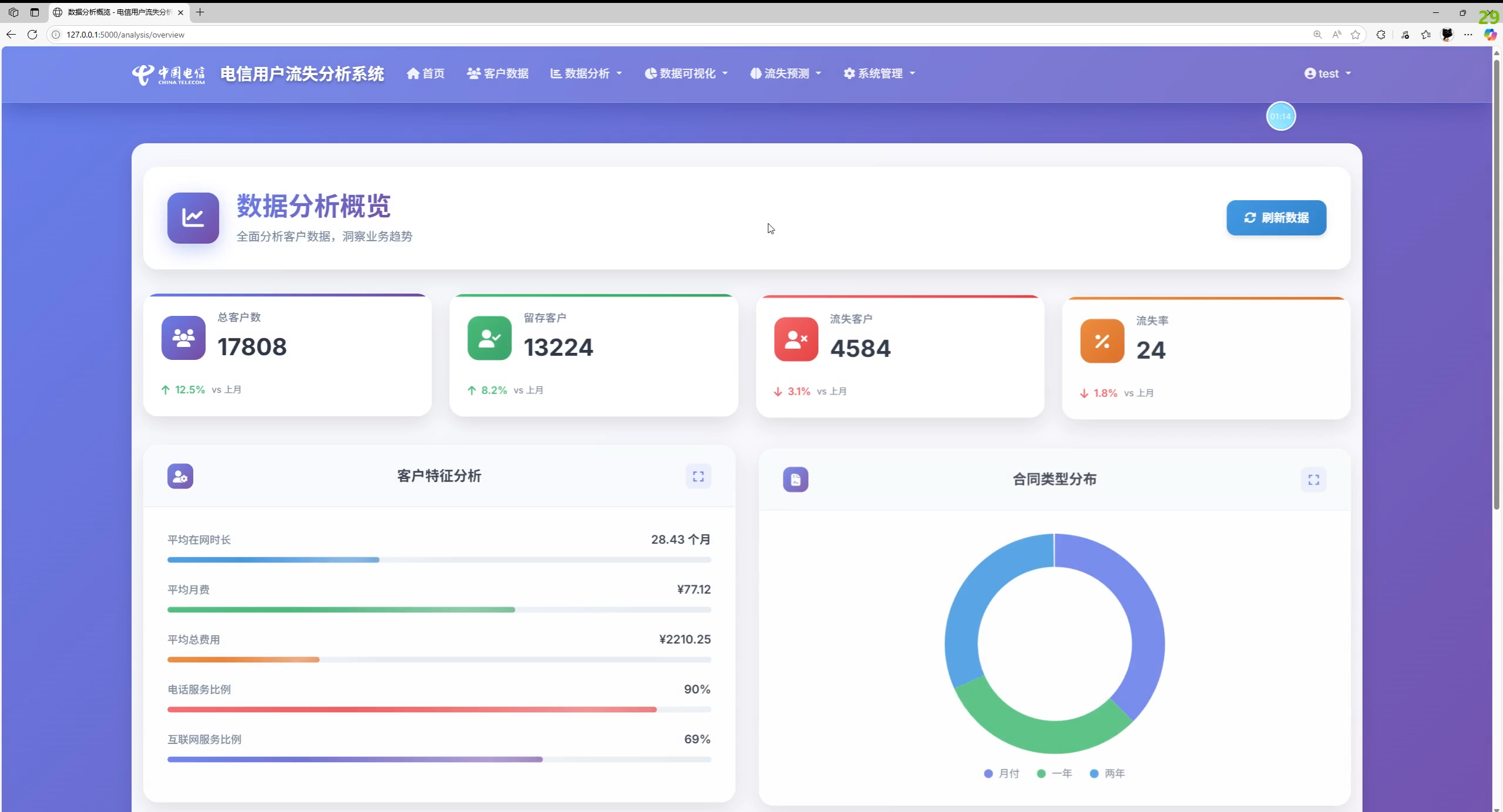
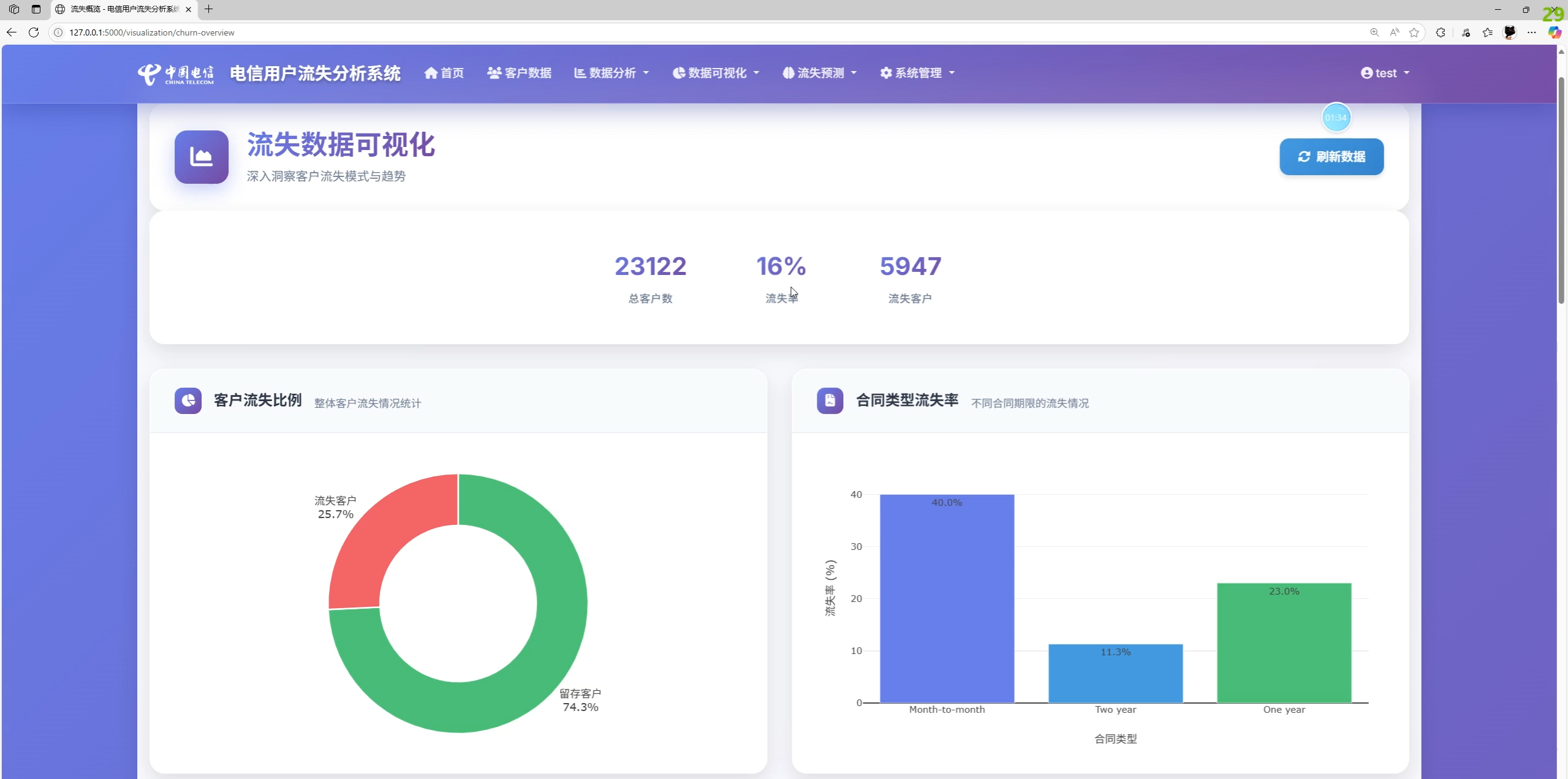
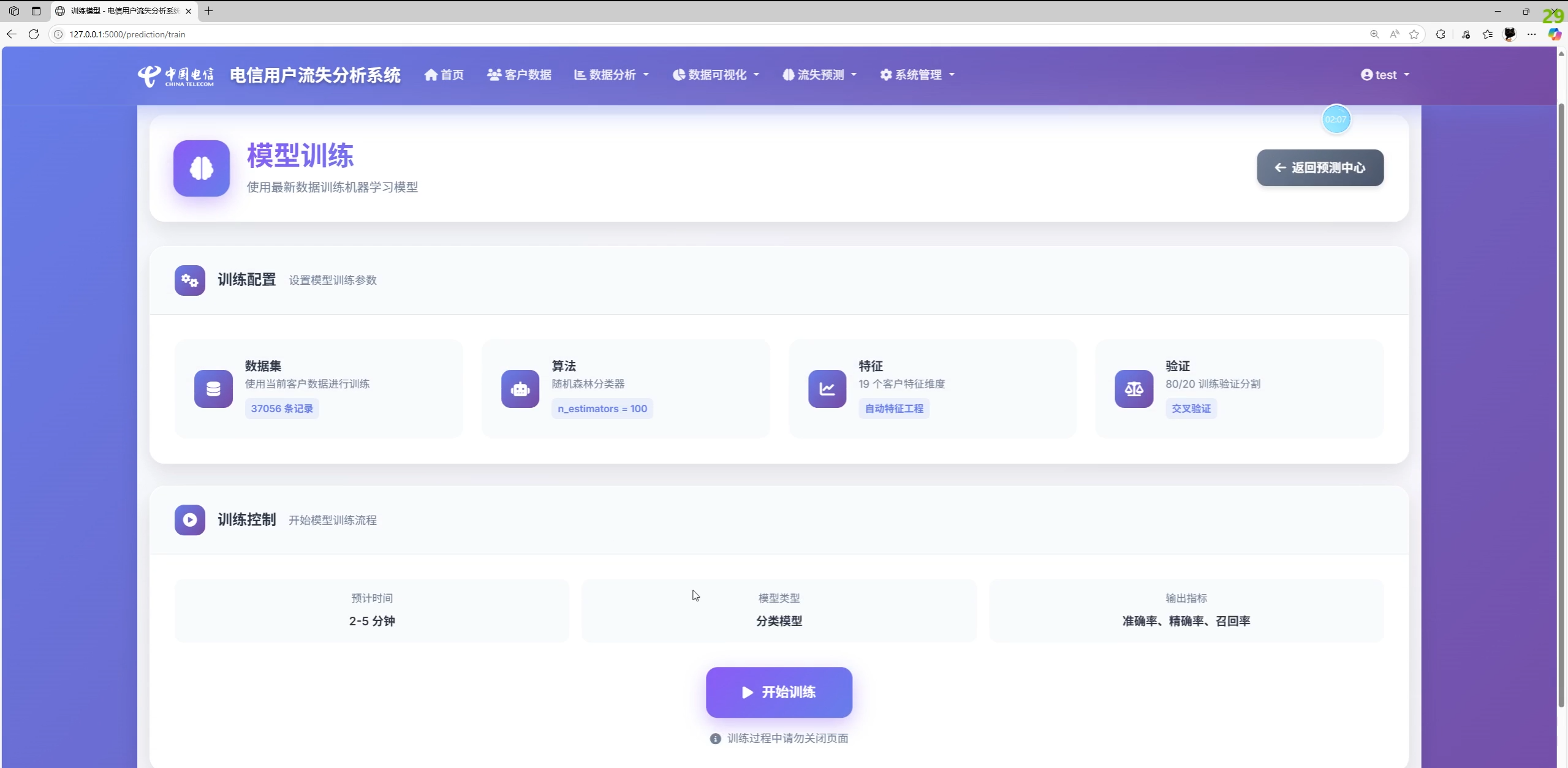
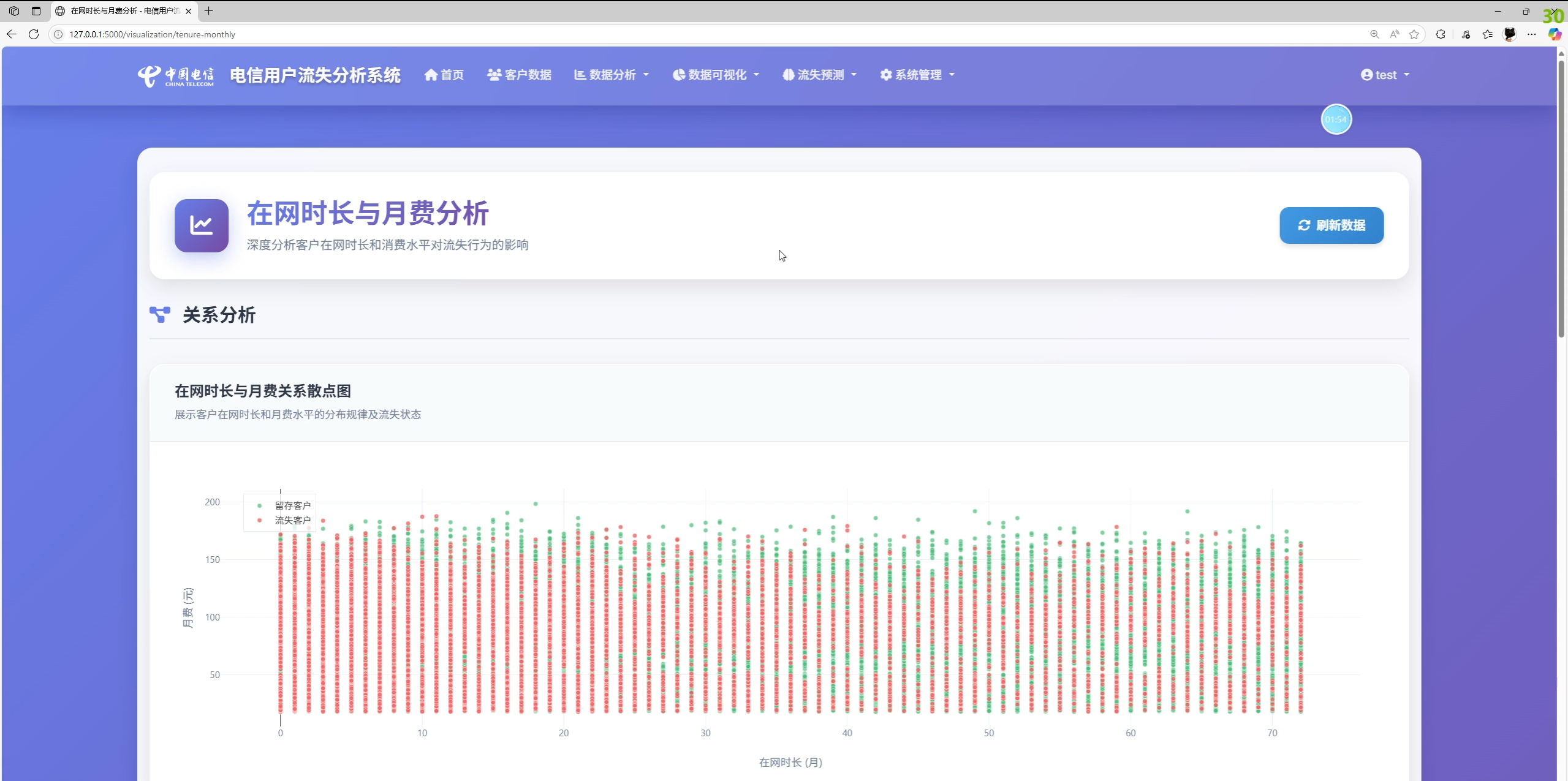
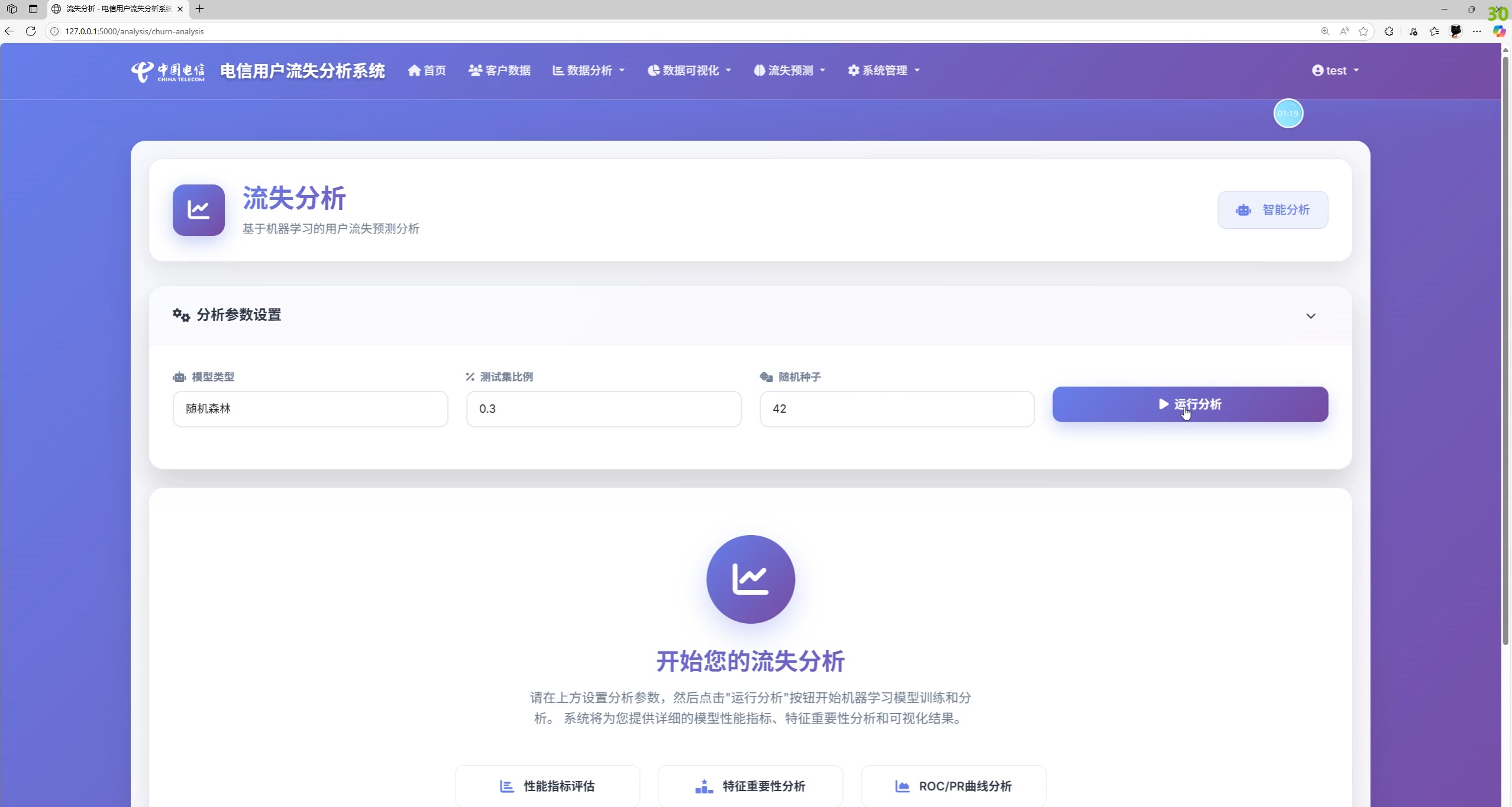
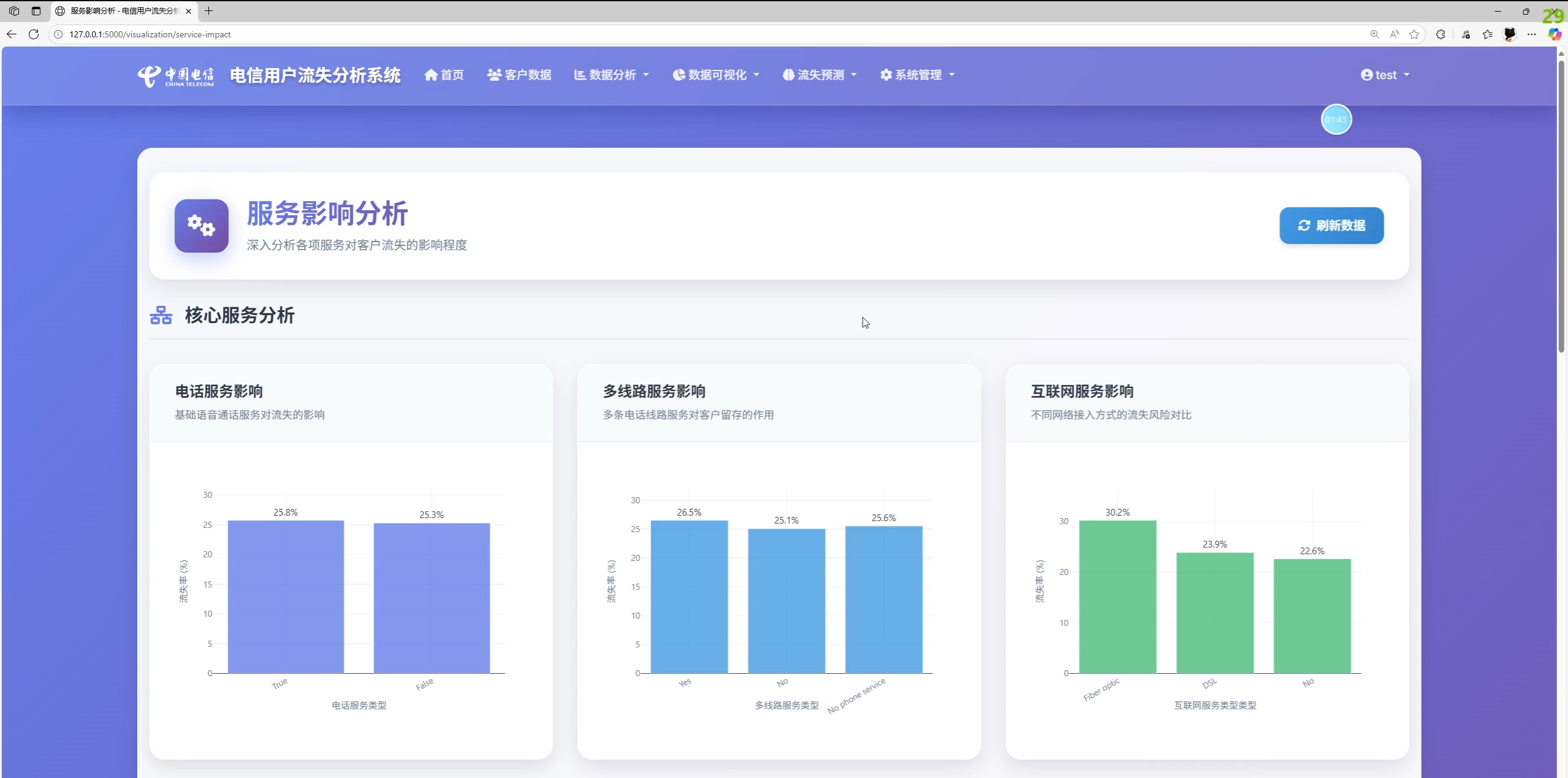
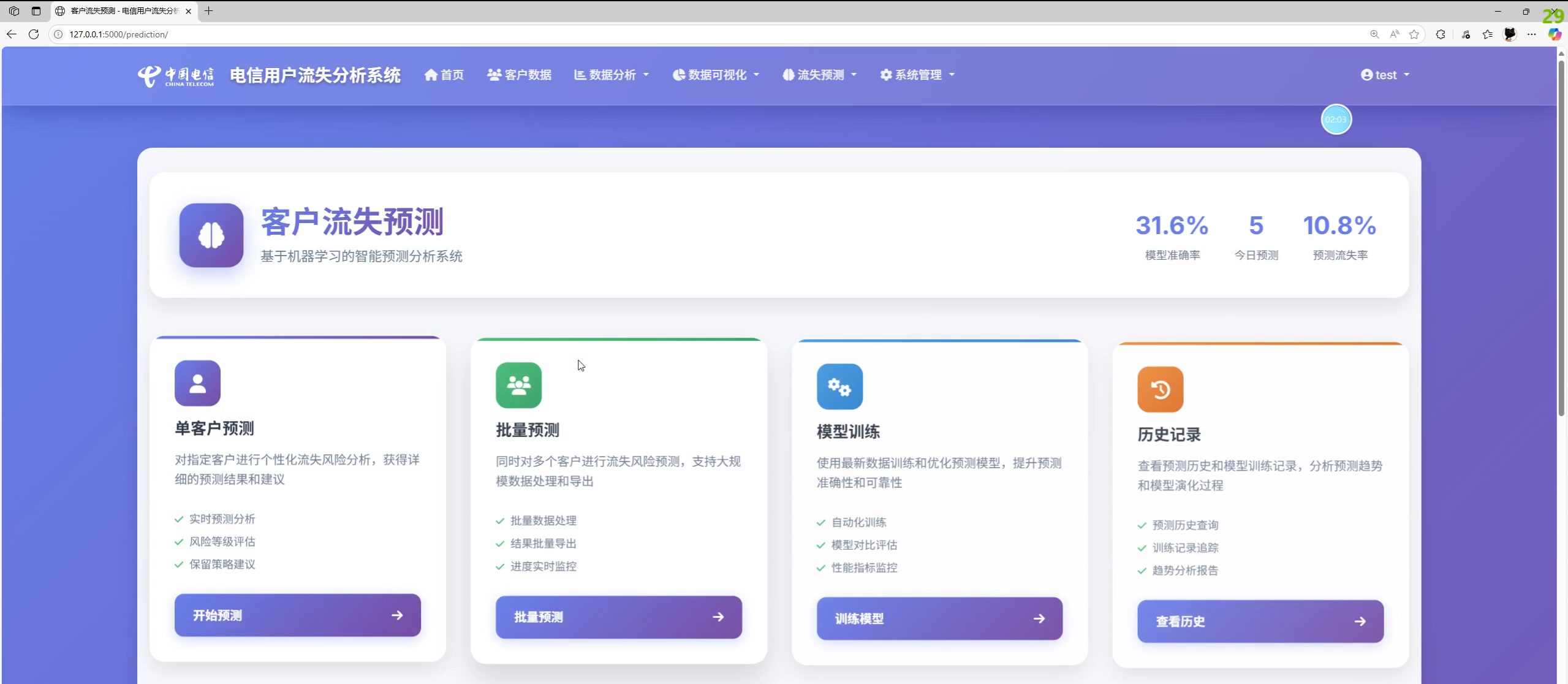
功能总览与系统截图说明
实际功能(依据前端模板与后端接口实现):
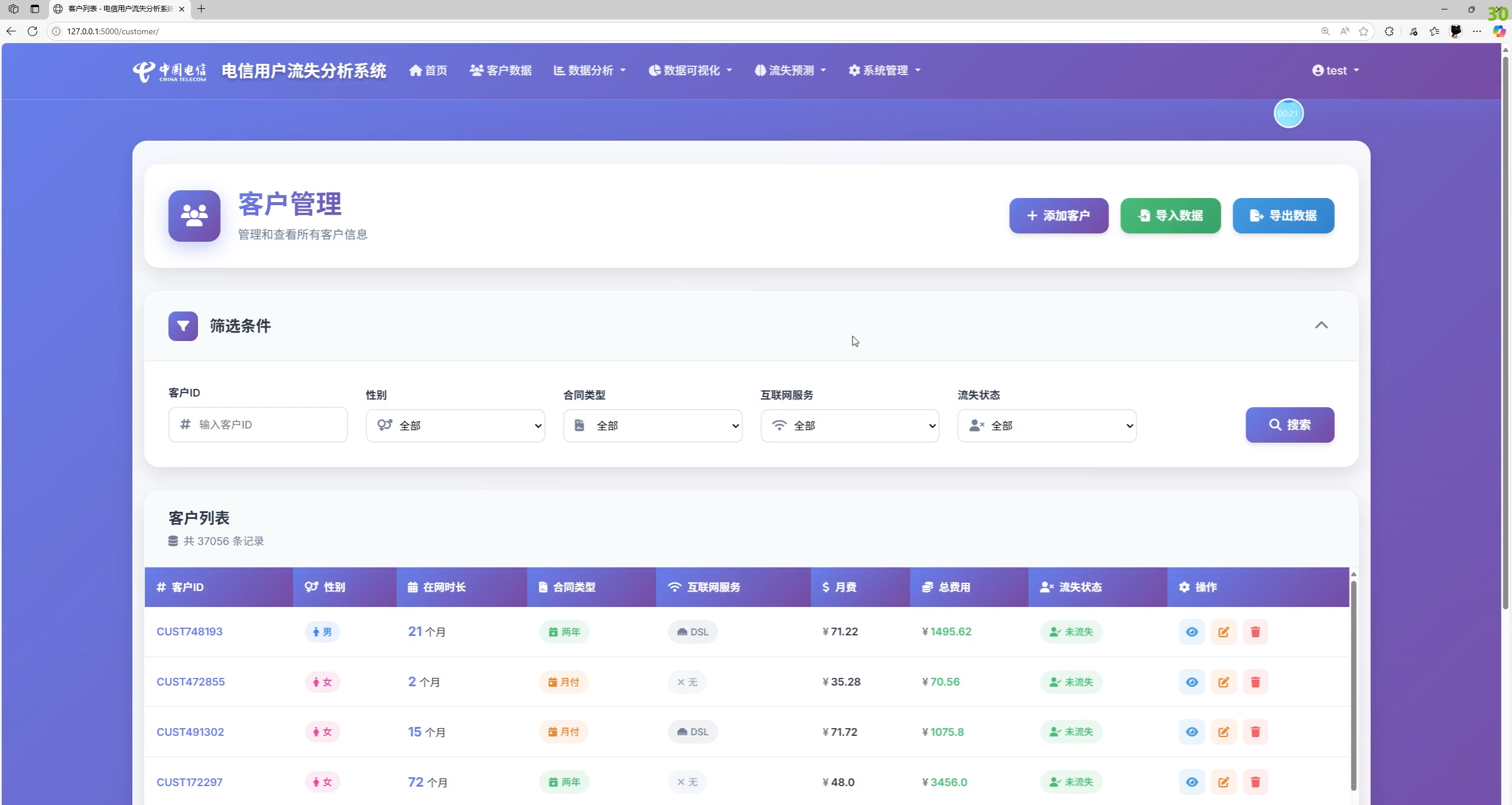
- 客户管理:新增、编辑、删除、分页搜索、条件筛选、批量导入(Excel/CSV)、批量导出
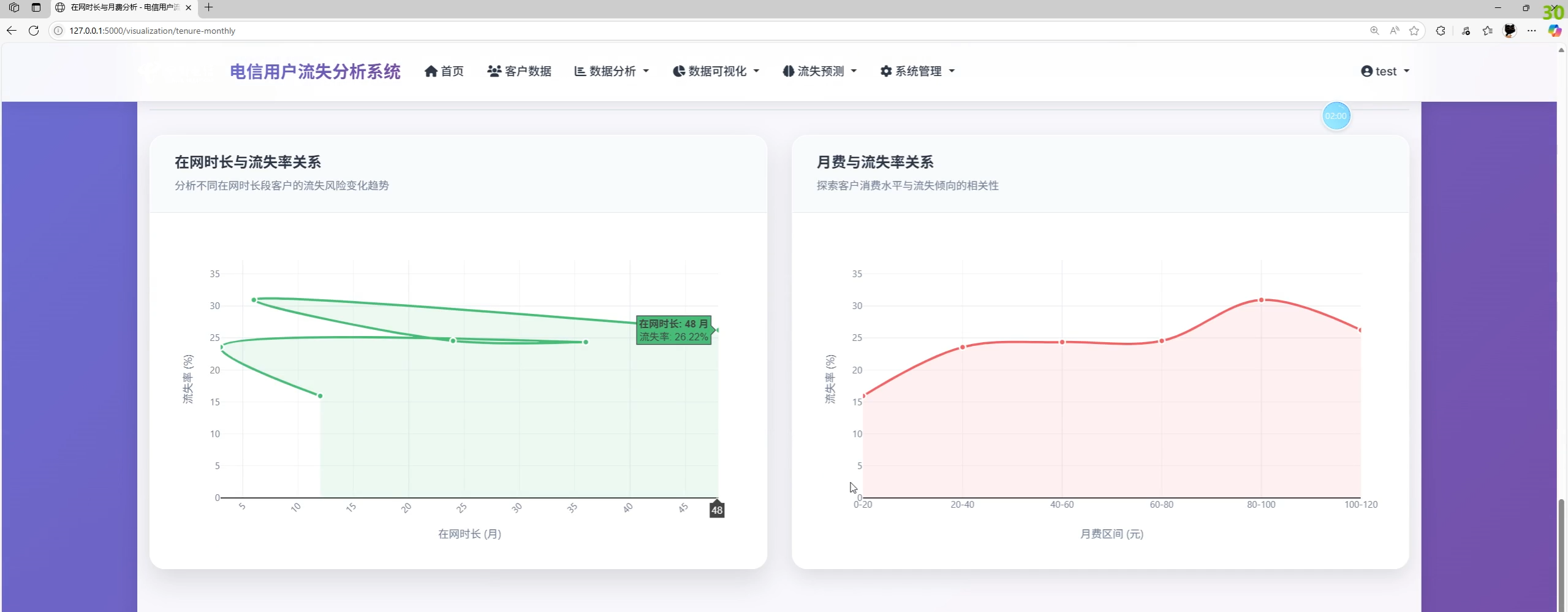
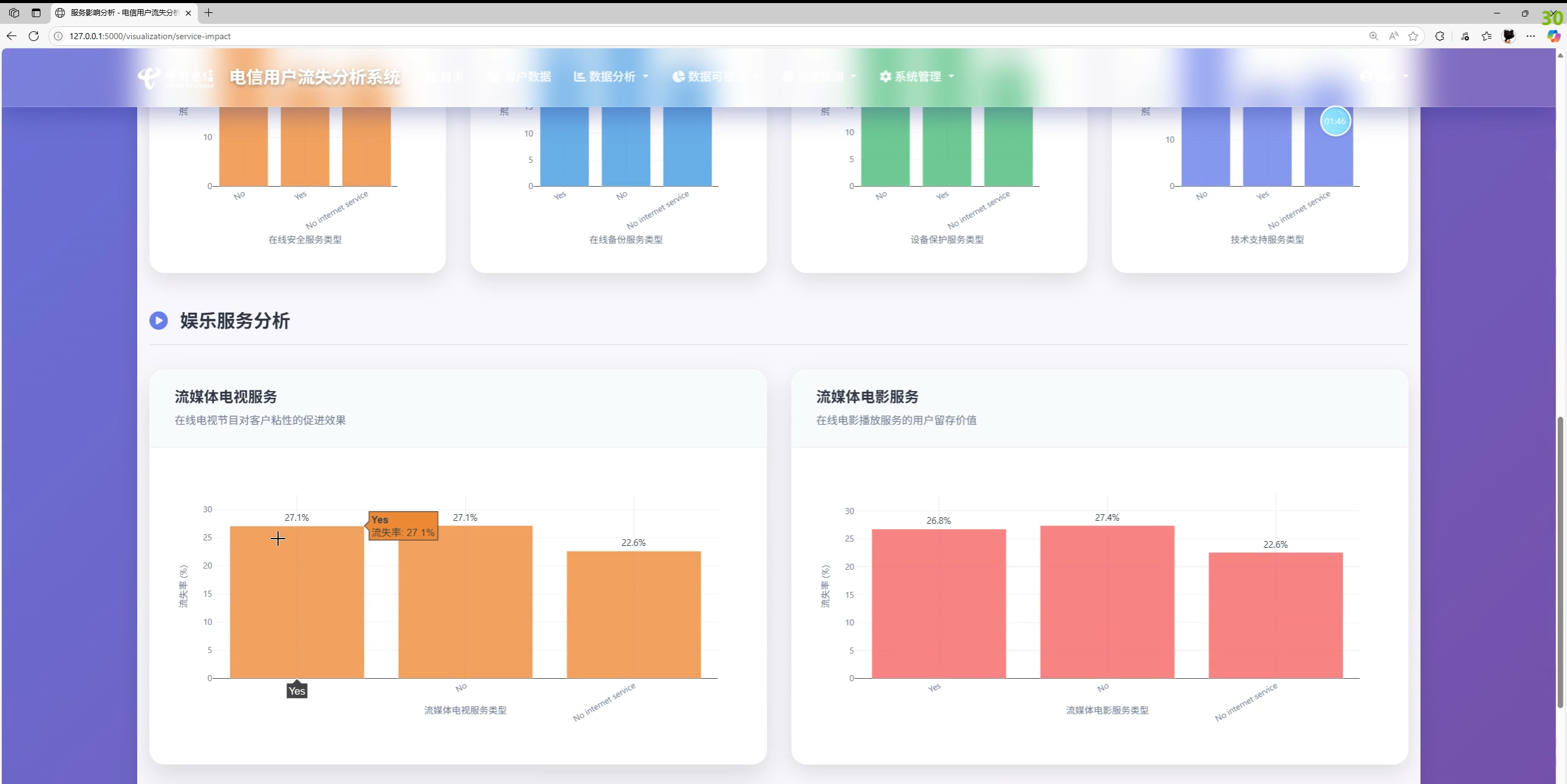
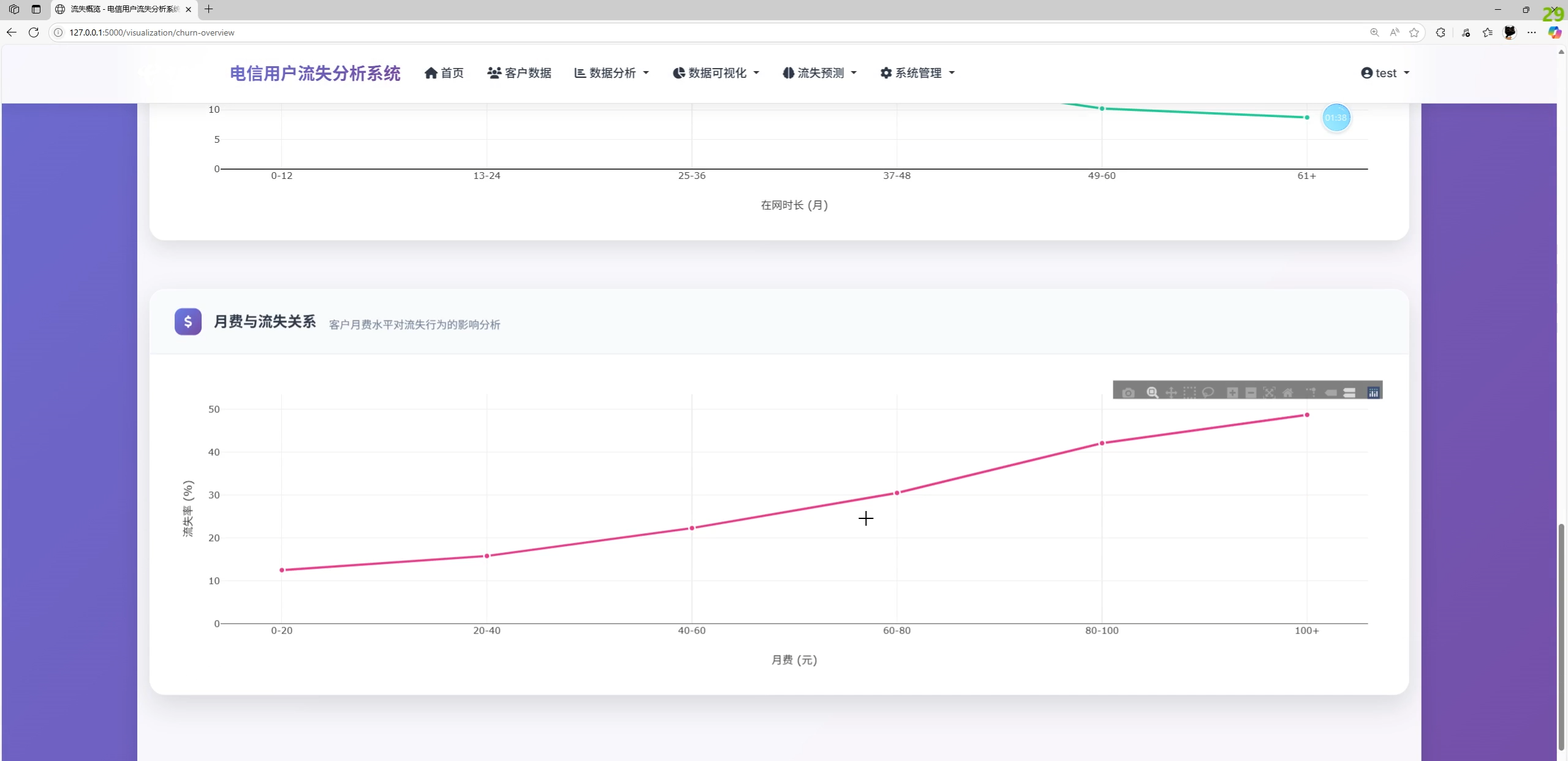
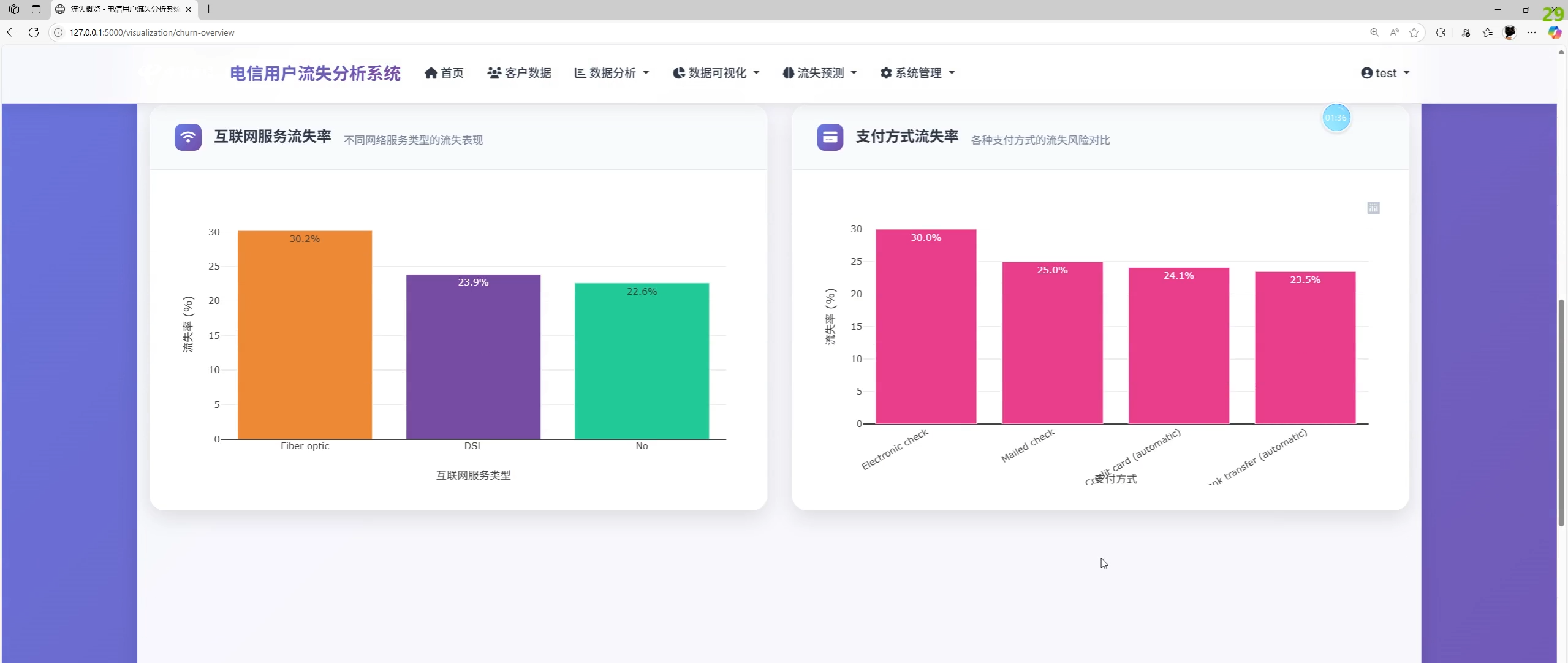
- 数据分析与可视化:流失率、合同/服务维度对比,在网时长/月费与流失关系趋势图,洞察卡片
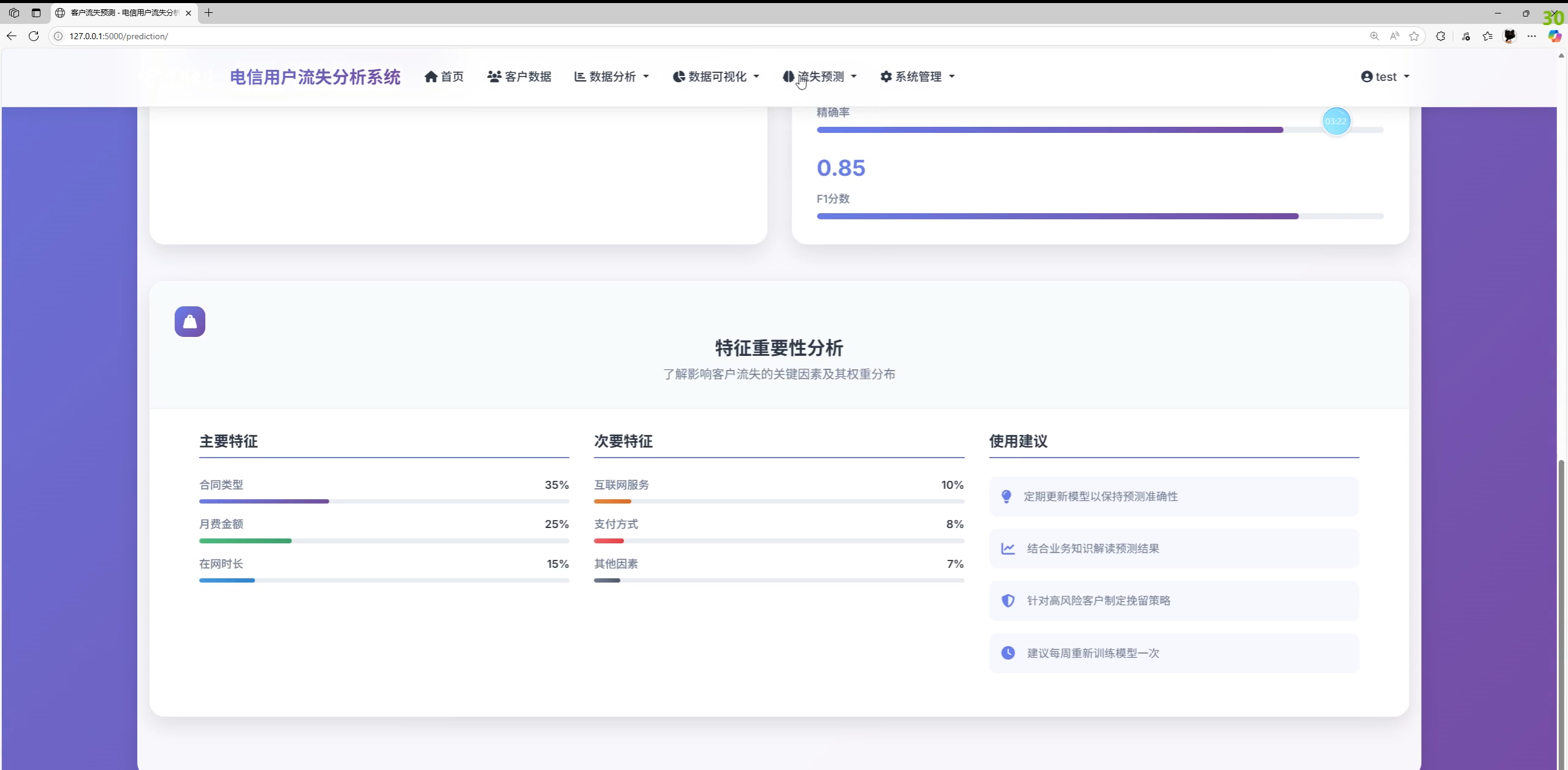
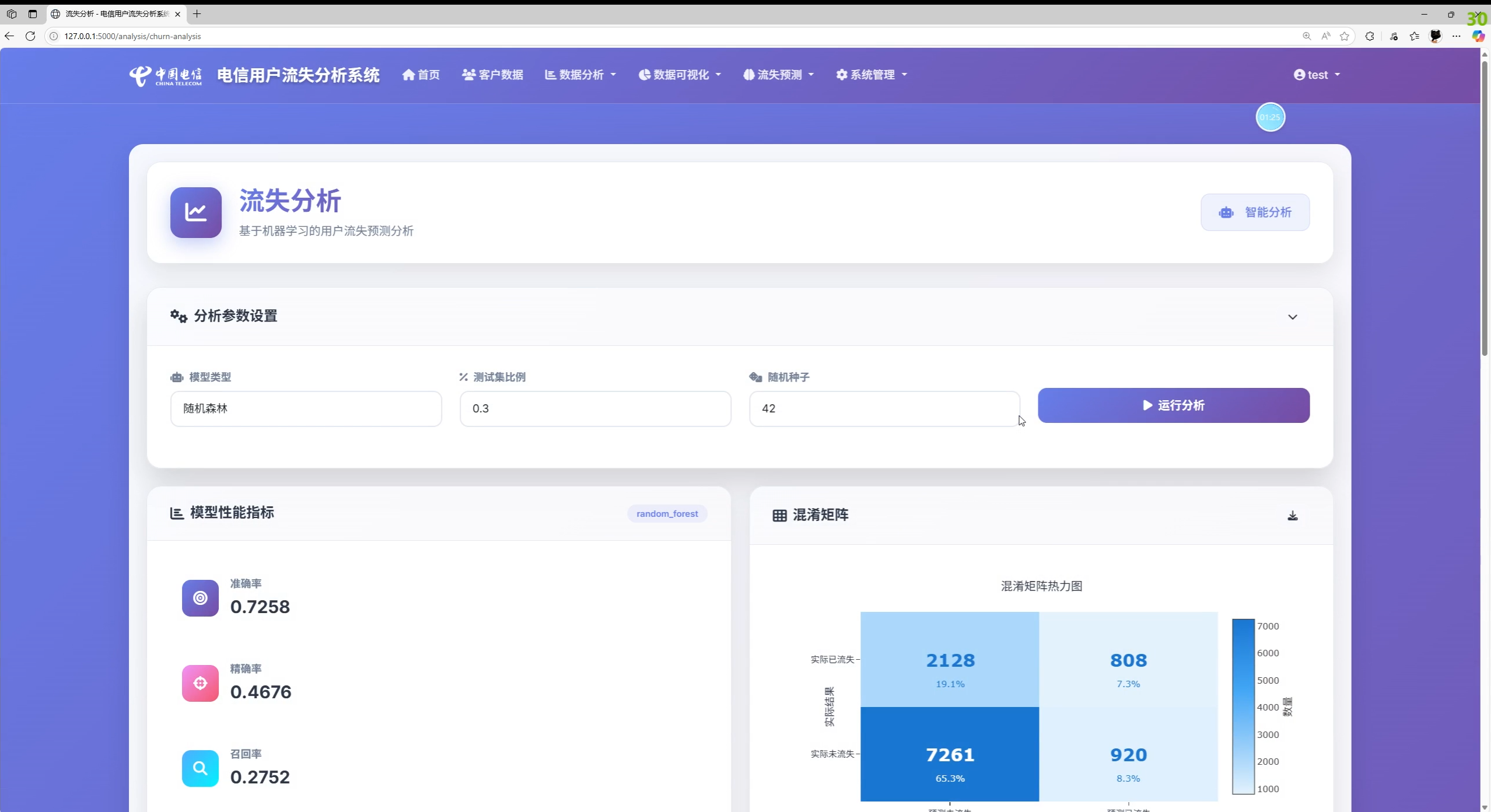
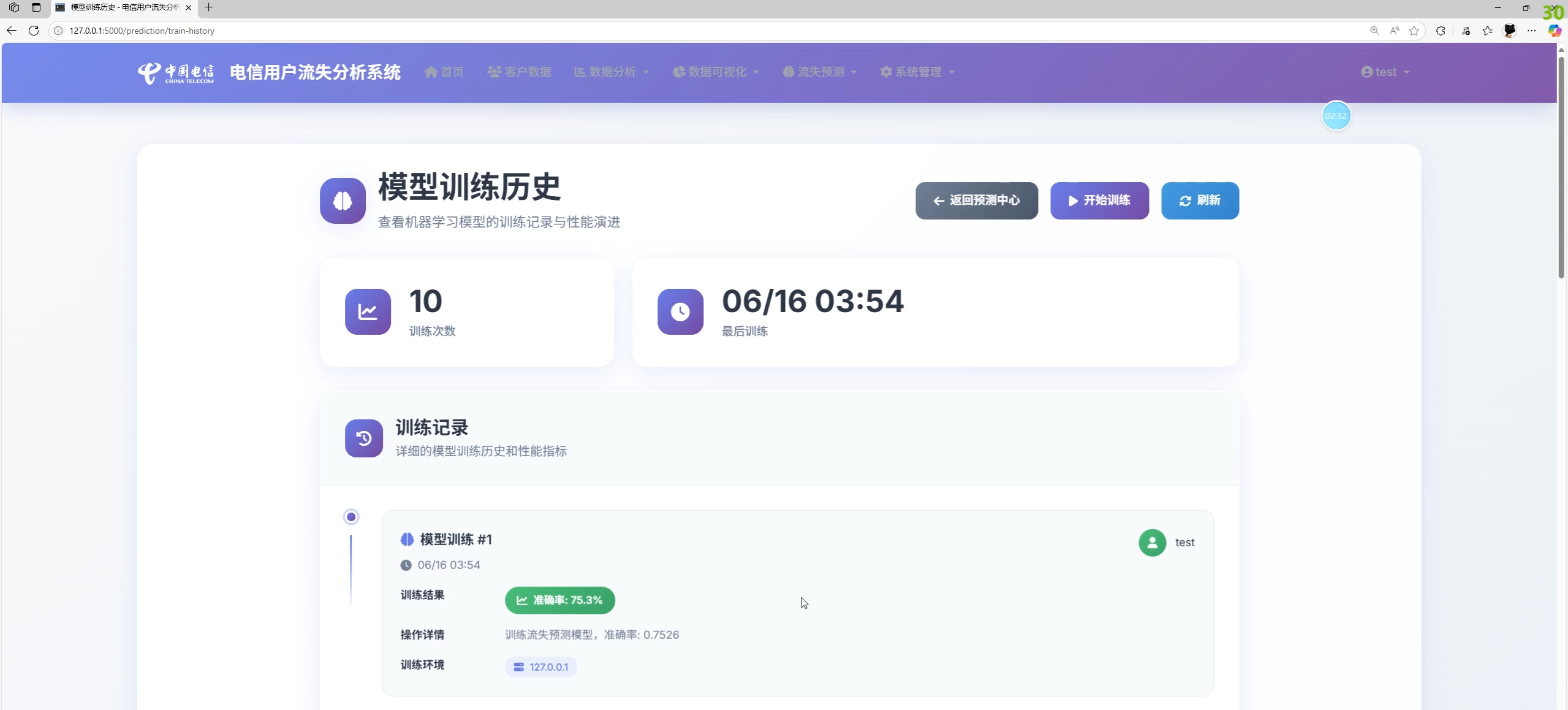
- 预测中心:单客户预测、批量预测、模型训练、训练历史、预测历史、模型性能指标展示
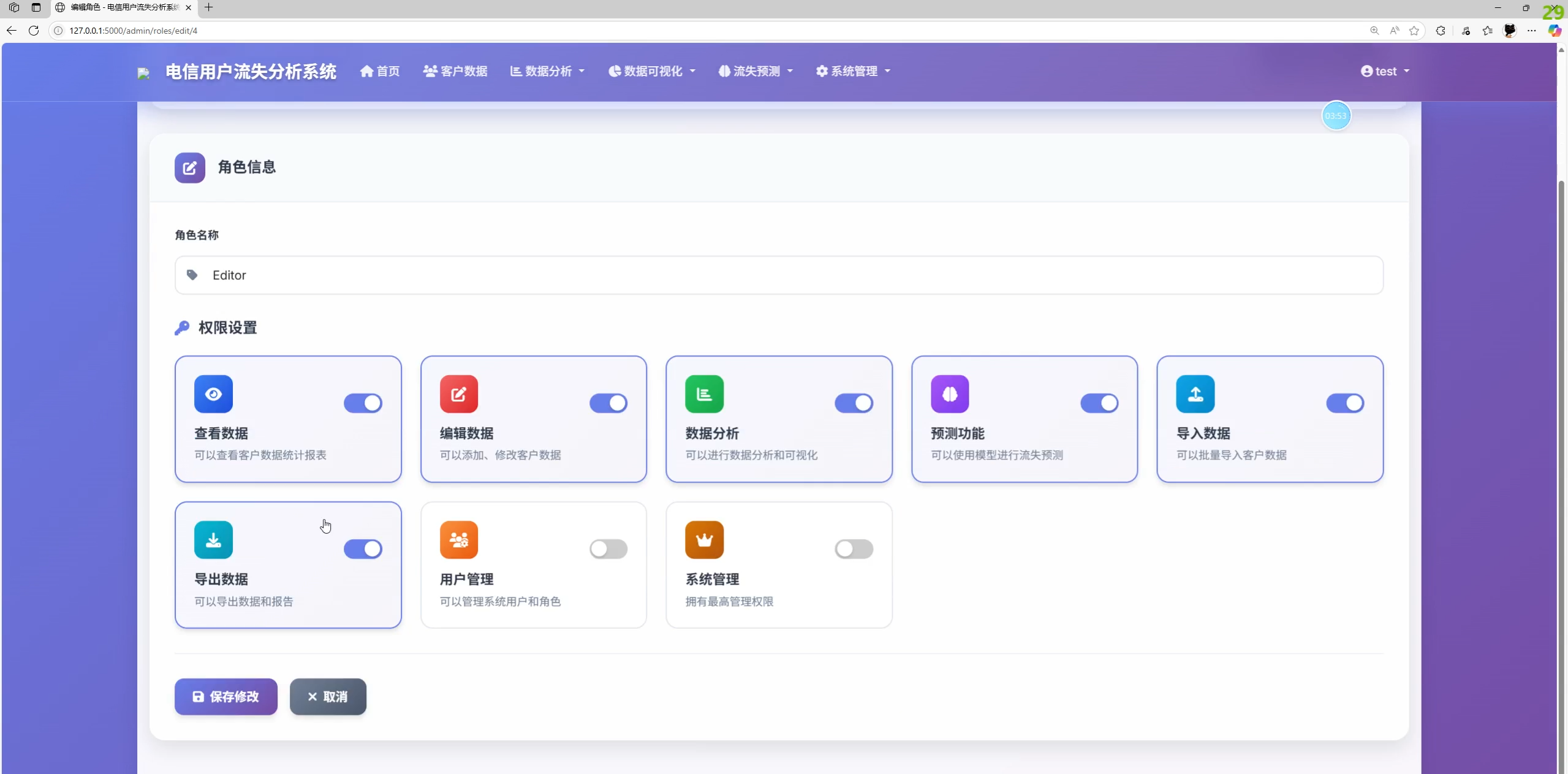
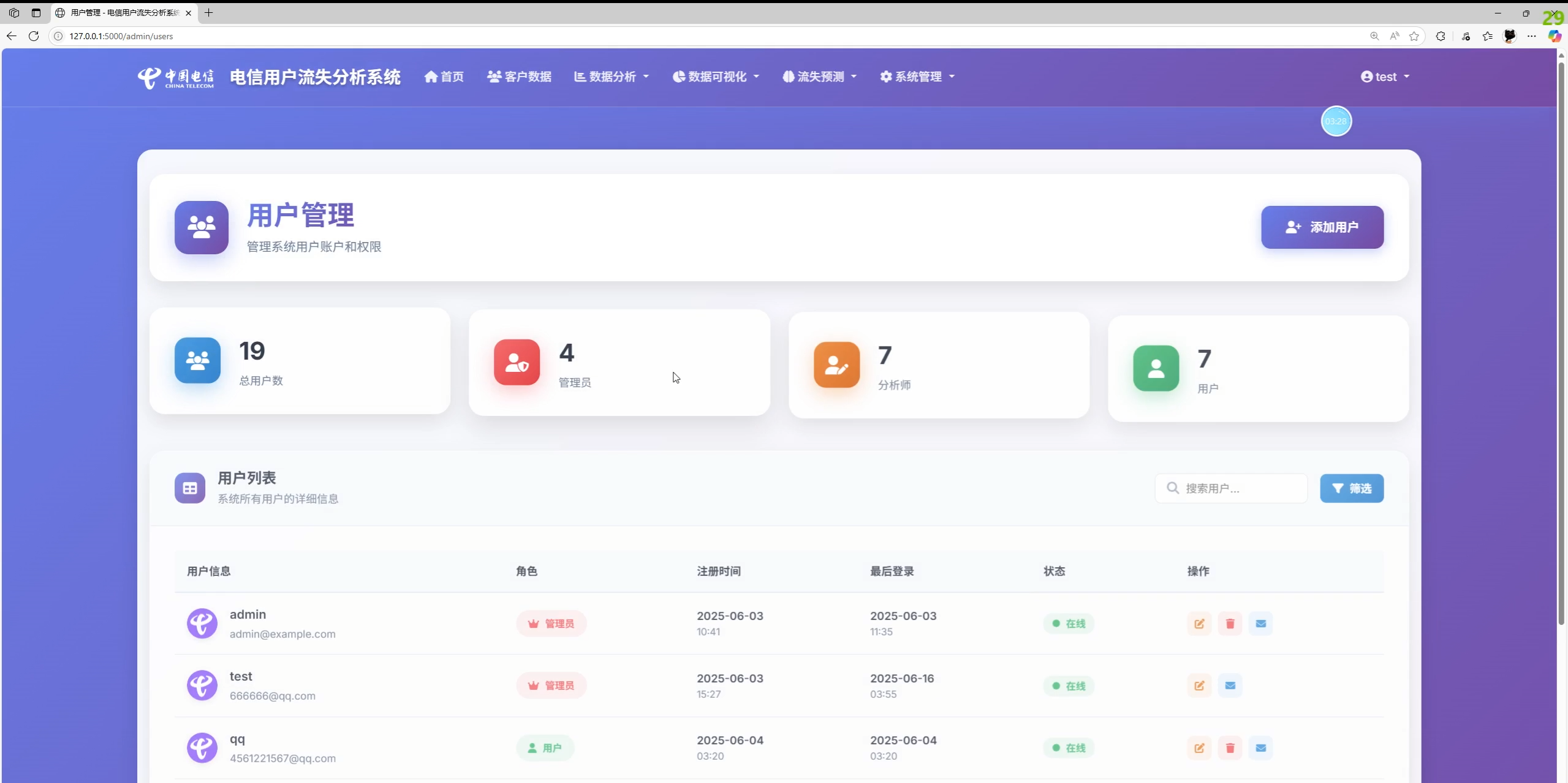
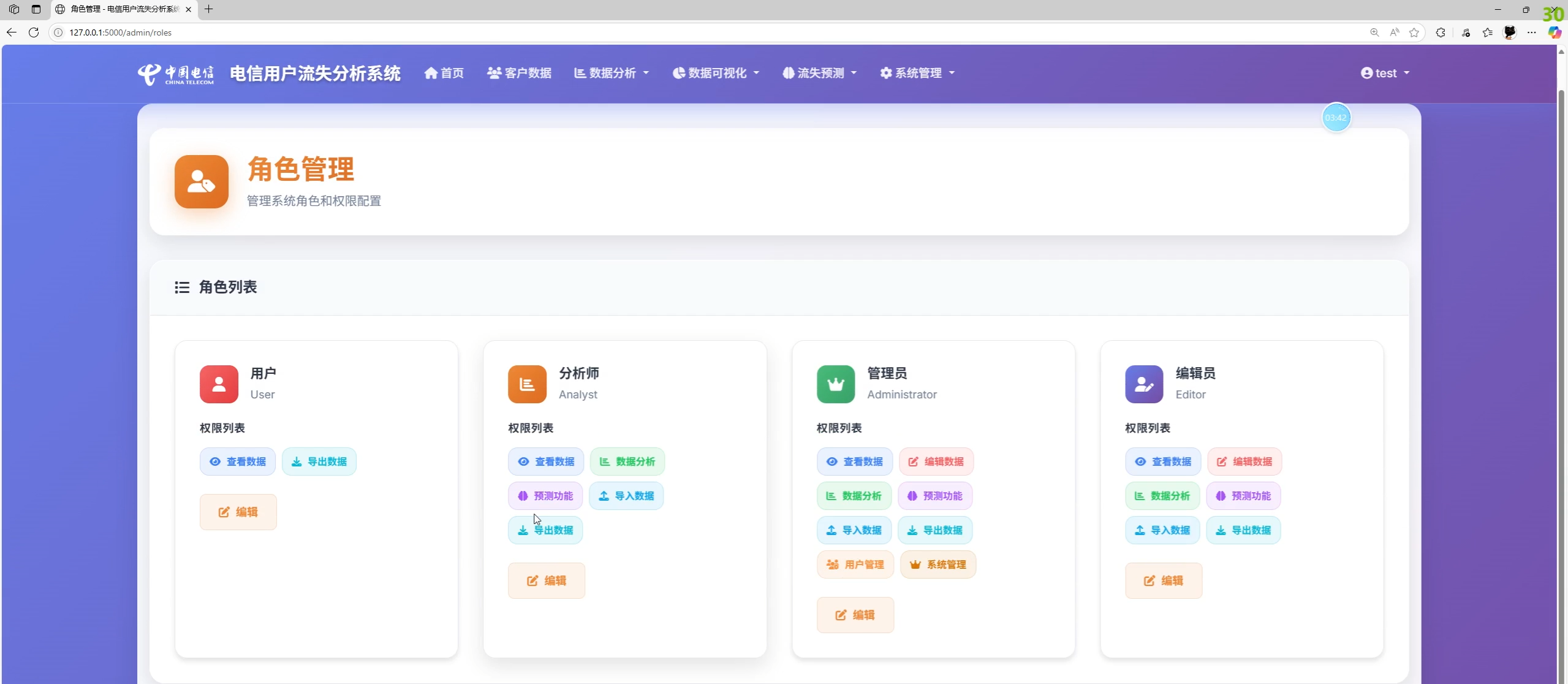
- 系统管理:用户/角色/权限、操作日志、账户安全(修改资料/密码、找回密码)
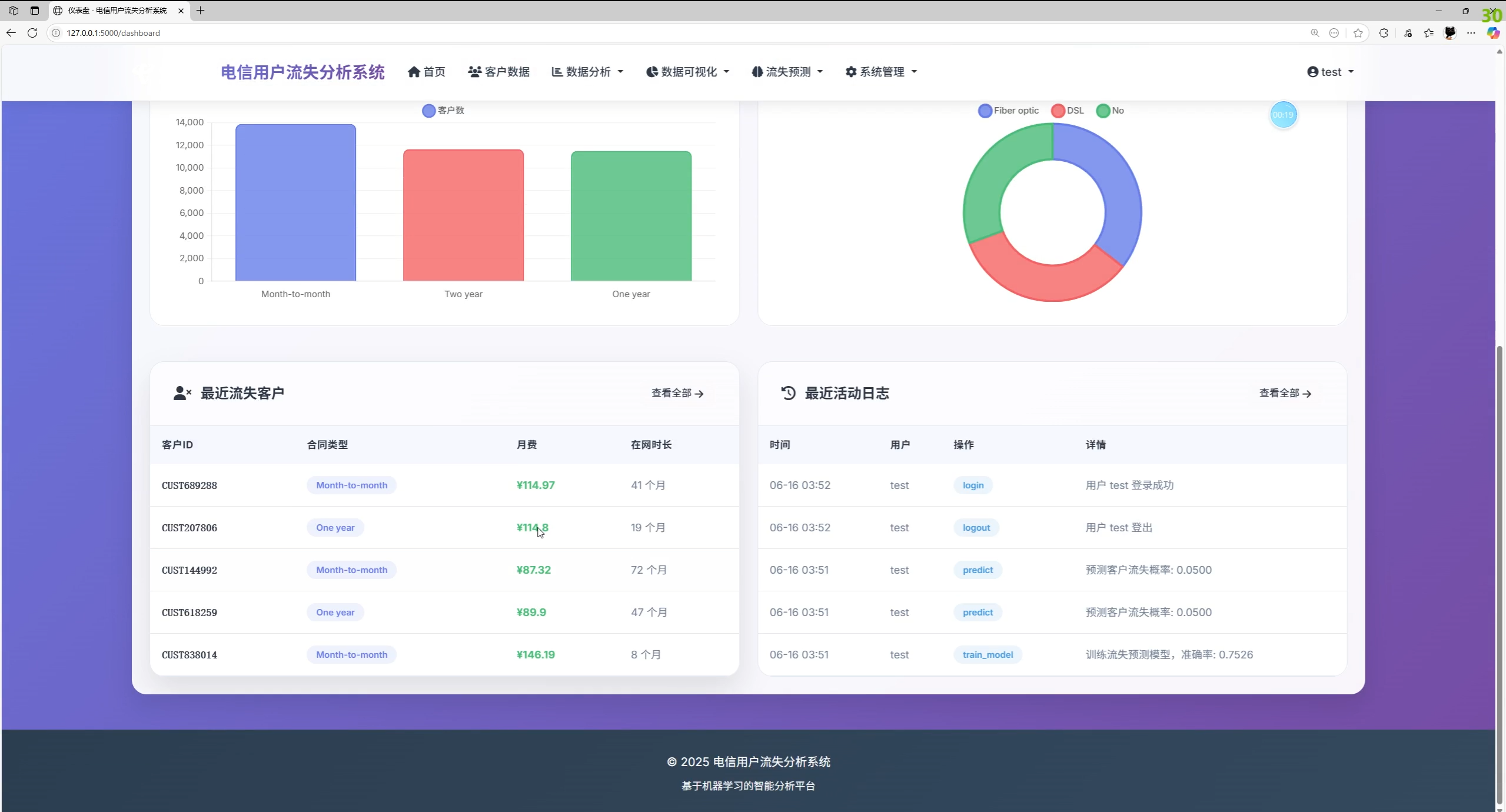
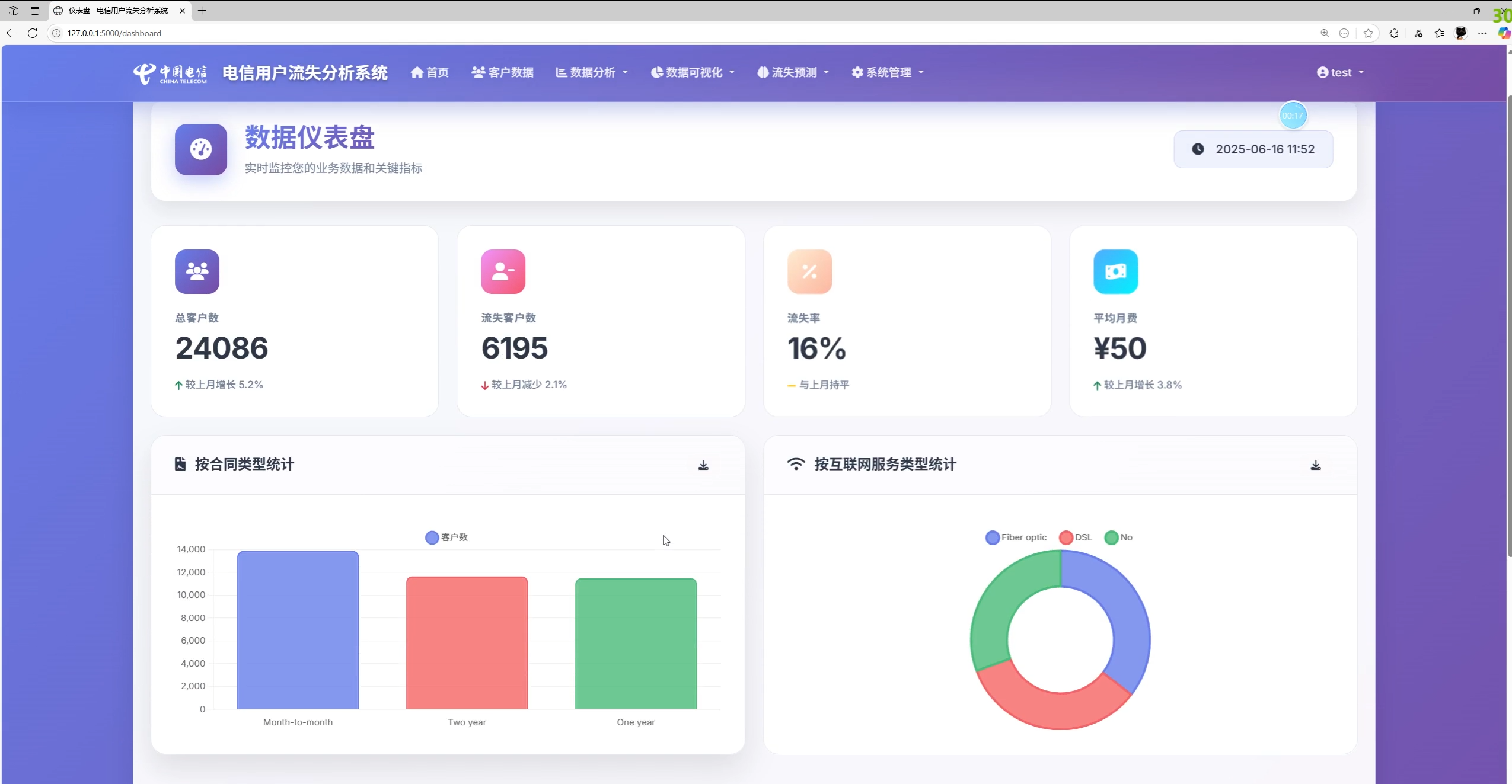
- 仪表盘:核心 KPI(客户数、流失数、流失率、平均月费)、最新流失客户、最近活动日志、常用维度图表
注:运行后可在浏览器访问首页与各业务页面进行体验。本文档末尾提供部署步骤。
💕项目源码获取,码界筑梦坊各平台同名,博客底部含联系方式卡片,欢迎咨询!

技术栈与架构设计
-
后端与框架
- Flask、Blueprint 模块化
- Flask-SQLAlchemy(ORM)、Flask-Migrate(迁移)
- Flask-Login、Flask-JWT-Extended(鉴权/令牌)
- Flask-WTF(表单校验)、Flask-RESTful(API)
- CORS、Mail、Bcrypt 等常用扩展
-
数据库
- 默认 SQLite,可切换 MySQL/PostgreSQL
- 驱动:PyMySQL
-
数据分析与机器学习
- NumPy、Pandas、Scikit-learn
- Matplotlib、Seaborn(后端图表生成)
-
前端与可视化
- Jinja2 模板渲染
- Bootstrap(样式与布局)
- Chart.js(前端图表)
- AOS 动画、FontAwesome 图标
-
部署
- Gunicorn + Nginx(生产),.env 配置
Jinja2渲染/HTTP 用户/浏览器 Flask 应用 Blueprint: main/auth/customer/analysis/prediction/admin API v1: auth/customers Service/Logic SQLAlchemy ORM 数据库: SQLite/MySQL/PostgreSQL Sklearn Pipeline: 训练/预测 静态模型文件 .pkl Chart.js 可视化 Extensions: Login/JWT/Migrate/Mail/CORS
项目目录结构说明
text
code/
├─ app/
│ ├─ templates/
│ │ ├─ main/ # 仪表盘与首页
│ │ ├─ auth/ # 登录/注册/重置密码
│ │ ├─ customer/ # 客户管理(列表/新增/编辑/导入/查看)
│ │ ├─ analysis/ # 数据分析(概览/流失分析)
│ │ ├─ visualization/ # 可视化大屏(流失概览、服务影响、时长分布)
│ │ ├─ prediction/ # 预测中心(训练/预测/历史/批量结果)
│ │ └─ admin/ # 系统管理(用户/角色/日志/系统设置)
│ ├─ static/ # 静态资源(样式、脚本、图片)
│ ├─ models.py # 数据模型(User/Role/Customer/Log 等)
│ ├─ views/ # 各模块蓝图(auth/customer/prediction/...)
│ ├─ forms.py # 表单定义(Flask-WTF)
│ └─ __init__.py # 应用工厂
├─ migrations/ # 数据库迁移记录
├─ data/ # 数据样例/导入导出目录
├─ docs/ # 文档与示例
├─ app.py # 开发启动入口
├─ wsgi.py # 生产入口(gunicorn 使用)
├─ requirements.txt # 依赖列表
├─ create_tables.py # 初始化表结构脚本
├─ update_roles.py # 初始化/更新角色权限脚本
├─ generate_mock_data.py # 生成大规模模拟数据
└─ quick_generate_data.py # 快速生成少量模拟数据实际文件路径以本仓库为准,以上为核心目录与职责的说明性视图。
核心功能与关键代码
鉴权与权限控制(位运算权限)
角色与权限采用位掩码(Bitmask)实现,页面渲染与后端接口双重校验。在前端模板中可以看到权限判断:
jinja2
{# app/templates/customer/index.html #}
{% if current_user.can(Permission.EDIT) %}
<a href="{{ url_for('customer.create') }}" class="btn-action btn-primary">
<i class="fas fa-plus"></i>
<span>添加客户</span>
</a>
<a href="{{ url_for('customer.import_data') }}" class="btn-action btn-success">
<i class="fas fa-file-import"></i>
<span>导入数据</span>
</a>
{% endif %}
<a href="{{ url_for('customer.export_data') }}" class="btn-action btn-info">
<i class="fas fa-file-export"></i>
<span>导出数据</span>
</a>配合后端模型的 User.can() 方法,可以精准控制页面按钮与接口权限。
后端基于装饰器进行二次防护:
python
# app/decorators.py
from functools import wraps
from flask import abort
from flask_login import current_user
from app.models.role import Permission
def permission_required(permission):
def decorator(f):
@wraps(f)
def decorated_function(*args, **kwargs):
if not current_user.can(permission):
abort(403)
return f(*args, **kwargs)
return decorated_function
return decorator客户数据管理(导入/导出/搜索筛选)
客户列表支持多条件筛选(ID、性别、合同类型、网络服务、流失状态等)与分页展示:
jinja2
{# app/templates/customer/index.html 片段 #}
<form method="get" action="{{ url_for('customer.index') }}" class="search-form">
<input type="text" name="customer_id" placeholder="输入客户ID">
<select name="gender">
<option value="">全部</option>
<option value="Male">男</option>
<option value="Female">女</option>
</select>
<select name="contract"> ... </select>
<select name="internet_service"> ... </select>
<select name="churn"> ... </select>
<button type="submit" class="btn-search">搜索</button>
</form>新增客户表单涵盖基础信息、服务信息、合同与账单三大板块,字段与业务保持一致:
jinja2
{# app/templates/customer/create.html 片段 #}
{{ form.customer_id(class="form-control", placeholder="请输入客户ID") }}
{{ form.gender(class="form-control") }}
{{ form.tenure(class="form-control", type="number", min="0") }}
{{ form.internet_service(class="form-control") }}
{{ form.contract(class="form-control") }}
{{ form.monthly_charges(class="form-control", type="number", step="0.01") }}后端可使用 Pandas 进行批量导入与数据清洗,示例(可根据模型字段调整):
python
import pandas as pd
from app.extensions import db
from app.models.customer import Customer
def import_customers(file_path: str) -> int:
df = pd.read_excel(file_path) if file_path.endswith('.xlsx') else pd.read_csv(file_path)
df = df.fillna({"TotalCharges": 0})
created = 0
for _, row in df.iterrows():
customer = Customer(
customer_id=row["customerID"],
gender=row["gender"],
tenure=int(row["tenure"]),
internet_service=row["InternetService"],
contract=row["Contract"],
monthly_charges=float(row["MonthlyCharges"]),
total_charges=float(row["TotalCharges"]),
churn=True if str(row["Churn"]).lower() in ("yes", "true", "1") else False,
)
db.session.add(customer)
created += 1
db.session.commit()
return created数据分析与可视化
页面端通过 Chart.js 渲染图表,示例(仪表盘合同类型分布):
html
<canvas id="contractChart"></canvas>
<script>
const ctx = document.getElementById('contractChart');
new Chart(ctx, {
type: 'bar',
data: { labels: ['月付', '一年', '两年'], datasets: [{ label: '数量', data: [120, 80, 60] }] },
});
</script>后端也可利用 Matplotlib/Seaborn 生产静态图(用于报表导出等场景):
python
import matplotlib.pyplot as plt
import seaborn as sns
def plot_churn_by_contract(df):
plt.figure(figsize=(6,4))
sns.barplot(data=df, x="Contract", y="ChurnRate", palette="Blues")
plt.tight_layout()
plt.savefig("data/fig_contract_churn.png")机器学习训练与预测
基于 Scikit-learn 的典型训练流程,可结合业务字段做特征工程与持久化:
python
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import joblib
def train_model(dataset_path: str, model_path: str = "data/model_rf.joblib"):
df = pd.read_csv(dataset_path)
y = (df["Churn"].astype(str).str.lower().isin(["yes", "true", "1"]))
X = df.drop(columns=["Churn", "customerID"]) # 依据表头实际调整
categorical_cols = X.select_dtypes(include=["object"]).columns.tolist()
numeric_cols = X.select_dtypes(exclude=["object"]).columns.tolist()
preprocessor = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(handle_unknown="ignore"), categorical_cols),
("num", "passthrough", numeric_cols),
]
)
pipeline = Pipeline(steps=[
("prep", preprocessor),
("clf", RandomForestClassifier(n_estimators=300, random_state=42)),
])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
print(classification_report(y_test, y_pred))
joblib.dump(pipeline, model_path)
def predict_once(features: dict, model_path: str = "data/model_rf.joblib") -> float:
model = joblib.load(model_path)
df = pd.DataFrame([features])
proba = model.predict_proba(df)[0][1]
return float(proba)接口对接示例(curl):
bash
# 1) 登录获取 JWT
curl -s -X POST http://localhost:5000/api/v1/auth/login \
-H 'Content-Type: application/json' \
-d '{"username":"admin","password":"123456"}'
# 假设返回 token 写入变量
TOKEN=... # 请替换为上一步返回的 data.token
# 2) 分页获取客户(支持筛选)
curl -s 'http://localhost:5000/api/v1/customers?page=1&per_page=10&gender=Male' \
-H "Authorization: Bearer $TOKEN"
# 3) 新增客户
curl -s -X POST http://localhost:5000/api/v1/customers \
-H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" \
-d '{"customer_id":"CUST-10001","gender":"Male","tenure":12,"contract":"Month-to-month","internet_service":"DSL","monthly_charges":56.5,"total_charges":560.0}'
# 4) 更新客户
curl -s -X PUT http://localhost:5000/api/v1/customers/1 \
-H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" \
-d '{"monthly_charges":66.0}'
# 5) 删除客户
curl -s -X DELETE http://localhost:5000/api/v1/customers/1 \
-H "Authorization: Bearer $TOKEN"前端
prediction/index.html、prediction/train.html、prediction/batch_predict.html等页面已提供交互与占位,可与以上接口对接。
仪表盘与业务指标
首页仪表盘汇总关键指标,并展示近期流失客户与活动日志。模板片段:
jinja2
{# app/templates/main/dashboard.html 片段 #}
<h2 class="metric-value">{{ stats.total_customers }}</h2>
<h2 class="metric-value">{{ stats.churn_customers }}</h2>
<h2 class="metric-value">{{ stats.churn_rate }}%</h2>
<h2 class="metric-value">¥{{ stats.avg_monthly }}</h2>后端可将近 30 天内的新增/流失趋势与热力信息注入模板,以支持运营日常观察。
安装部署与初始化
- 克隆与进入目录
bash
git clone <your-repo-url>
cd code- 创建虚拟环境并安装依赖
bash
python -m venv venv
venv/Scripts/activate # Windows
# source venv/bin/activate # macOS/Linux
pip install -r requirements.txt- 初始化数据库与角色
bash
python create_tables.py
python update_roles.py
# 可选:初始化角色(如果在自定义脚本中)
# from app.models.role import Role; Role.insert_roles()- 启动服务
bash
python app.py
# or production
gunicorn -w 4 -b 0.0.0.0:5000 wsgi:app访问 http://localhost:5000
可视化展示占位(请在替换为实际截图后保留说明)
以下为示意占位,请将运行后的页面截图替换进来:
- 仪表盘(Dashboard)KPI 总览与图表
- 客户列表页面(筛选与分页)
- 可视化大屏(流失概览/服务影响/趋势分析)
- 预测中心(单客户预测、批量预测、模型训练与历史)
- 系统管理(用户、角色与日志)
建议统一将图片放置于 docs/images/ 目录,并在本文档中使用相对路径引用:
markdown


常见问题与优化建议
-
数据集字段不一致
- 解决:在导入前统一字段名映射;或在导入脚本中做
rename与缺失值填充。
- 解决:在导入前统一字段名映射;或在导入脚本中做
-
训练效果不稳定
- 解决:做训练/验证/测试分层抽样;网格搜索/随机搜索超参;引入更强模型(XGBoost/LightGBM)。
-
前端加载较慢
- 解决:开启 gzip、CDN 静态资源;分页与懒加载;按需引入图表组件。
-
权限粒度需要更细
- 解决:基于位掩码扩充位段;在视图层与模板层同时加校验;为敏感操作引入二次确认与审计。
-
多环境配置
- 解决:使用
.env与多配置文件,区分 dev/staging/prod;敏感信息走环境变量。
- 解决:使用
附:应用工厂与扩展初始化(关键代码)
python
# app/__init__.py
from flask import Flask
from app.extensions import db, migrate, login_manager, mail, jwt, bcrypt, cors
def create_app(config_name='default'):
app = Flask(__name__)
from app.config import config
app.config.from_object(config[config_name])
config[config_name].init_app(app)
db.init_app(app)
migrate.init_app(app, db)
login_manager.init_app(app)
mail.init_app(app)
jwt.init_app(app)
bcrypt.init_app(app)
cors.init_app(app)
from app.views.main import main_bp
app.register_blueprint(main_bp)
# ... 省略其它蓝图注册(auth/customer/analysis/prediction/admin)
from app.api.v1 import api_v1
app.register_blueprint(api_v1, url_prefix='/api/v1')
return app
python
# app/config.py 关键配置
class Config:
SECRET_KEY = os.environ.get('SECRET_KEY') or 'hard-to-guess-string'
SQLALCHEMY_TRACK_MODIFICATIONS = False
POSTS_PER_PAGE = 5
UPLOAD_PATH = os.path.join(basedir, '..', 'data', 'raw')
python
# app/forms/customer.py 片段
class CustomerForm(FlaskForm):
customer_id = StringField('客户ID', validators=[DataRequired(), Length(1, 64)])
gender = SelectField('性别', choices=[('Male','男'),('Female','女')])
tenure = IntegerField('在网时长(月)', validators=[DataRequired(), NumberRange(min=0)])
contract = SelectField('合同类型', choices=[('Month-to-month','月付'),('One year','一年'),('Two year','两年')])
monthly_charges = FloatField('月费用', validators=[DataRequired(), NumberRange(min=0)])附:单元测试示例占位
python
# tests/test_customers_api.py
import json
def test_get_customers_requires_auth(client):
resp = client.get('/api/v1/customers')
assert resp.status_code in (401, 422) # 缺少JWT
def test_create_customer_flow(auth_client):
payload = {"customer_id":"UT-0001","gender":"Male","tenure":3,
"contract":"Month-to-month","internet_service":"DSL",
"monthly_charges":30.0,"total_charges":90.0}
resp = auth_client.post('/api/v1/customers', data=json.dumps(payload),
headers={'Content-Type':'application/json'})
assert resp.status_code == 201结语与联系
本文分享了一个面向业务的"电信用户流失信息分析系统",涵盖从数据到模型再到可视化与权限的完整闭环。你可以在此基础上快速定制面向自身场景的留存与增长方案。
如需交流与合作,请联系:码界筑梦坊各大平台同名。
毕业设计必备章节
需求分析
- 角色与权限
- 管理员:用户与角色管理、权限配置、查看日志、系统设置
- 数据分析师:数据分析、模型训练与评估、预测历史
- 数据编辑:客户数据增删改、导入导出
- 普通用户:查看与导出
- 功能性需求
- 客户数据管理(CRUD、批量导入/导出、条件检索、模板下载)
- 可视化与分析(指标卡、趋势图、多维对比)
- 机器学习(训练、预测、历史记录、模板下载与结果导出)
- 系统管理(用户/角色、操作日志、基础设置)
- 非功能性需求
- 易用性:清晰导航与筛选;表单校验;错误提示
- 可维护性:模块化蓝图、ORM、迁移、表单/模型/视图分层
- 安全性:登录/权限、CSRF 防护、密码哈希
系统设计(架构/模块/流程)
- 架构分层
- 表现层:Jinja2 模板渲染,Chart.js 可视化
- 业务层:Blueprint 划分(
main/auth/customer/analysis/prediction/admin/visualization) - 数据层:SQLAlchemy 模型与迁移
- 算法层:Sklearn Pipeline 训练与预测
- 核心流程(以"批量预测"为例)
- 前端上传 CSV/XLSX → 2) 校验字段/清洗 → 3) 加载/检查模型 → 4) 逐行推理 → 5) 记录日志 → 6) 结果渲染与导出
- 权限控制流程
- 模板显示控制 + 视图
@permission_required双重校验(位掩码)
- 模板显示控制 + 视图
数据库设计(表结构)
- 用户(
users)- 关键字段:
id, email, username, password_hash, role_id, member_since, last_seen, avatar_type
- 关键字段:
- 角色(
roles)- 关键字段:
id, name, default, permissions - 权限常量:
VIEW, EDIT, ANALYZE, PREDICT, IMPORT, EXPORT, MANAGE, ADMIN
- 关键字段:
- 客户(
customers)- 关键字段:
id, customer_id, gender, senior_citizen, partner, dependents, tenure, internet_service, contract, paperless_billing, payment_method, monthly_charges, total_charges, churn, created_at, updated_at
- 关键字段:
- 日志(
logs)- 关键字段:
id, user_id, operation, target, details, ip_address, user_agent, timestamp
- 关键字段:
以上字段来自实际模型定义文件:
app/models/user.py、role.py、customer.py、log.py。
API 设计与说明(视图路由)
-
客户模块(
app/views/customer.py)GET /customer/:客户列表(分页、条件筛选)GET|POST /customer/create:创建客户GET /customer/view/<id>:查看客户详情GET|POST /customer/edit/<id>:编辑客户GET /customer/delete/<id>:删除客户GET|POST /customer/import:导入客户数据(CSV/XLSX)GET /customer/export:导出当前筛选结果(CSV)GET /customer/download-import-template:下载导入模板
-
预测模块(
app/views/prediction.py)GET /prediction/:预测首页(模型状态/统计)GET /prediction/api/stats:预测统计(准确率、今日预测量、流失率等)GET|POST /prediction/train:训练模型并持久化static/models/churn_model.pklGET /prediction/train-history:训练历史GET /prediction/history:预测/批量预测历史GET|POST /prediction/predict/<id>:单客户预测GET|POST /prediction/batch-predict:批量预测(上传 CSV/XLSX)GET /prediction/download-template:下载批量预测模板GET /prediction/export-batch-results:导出批量预测结果
-
分析模块(
app/views/analysis.py)GET /analysis/overview:分析概览(KPI、维度统计、指标进度)GET|POST /analysis/churn-analysis:流失分析(多模型对比与指标输出)GET /analysis/api/churn-by-contract|tenure|monthly-charges|internet-service|payment-method:各维度流失率 API
-
管理模块(
app/views/admin.py)GET /admin/users|roles|logs|system:用户/角色/日志/系统页面GET|POST /admin/user/add:新增用户GET|POST /admin/user/<id>/edit:编辑用户POST /admin/user/<id>/delete:删除用户
实际部署时可在
app/api/v1暴露 REST API(当前仓库已有雏形:auth.py、customers.py)。
实验与评估(指标与结果)
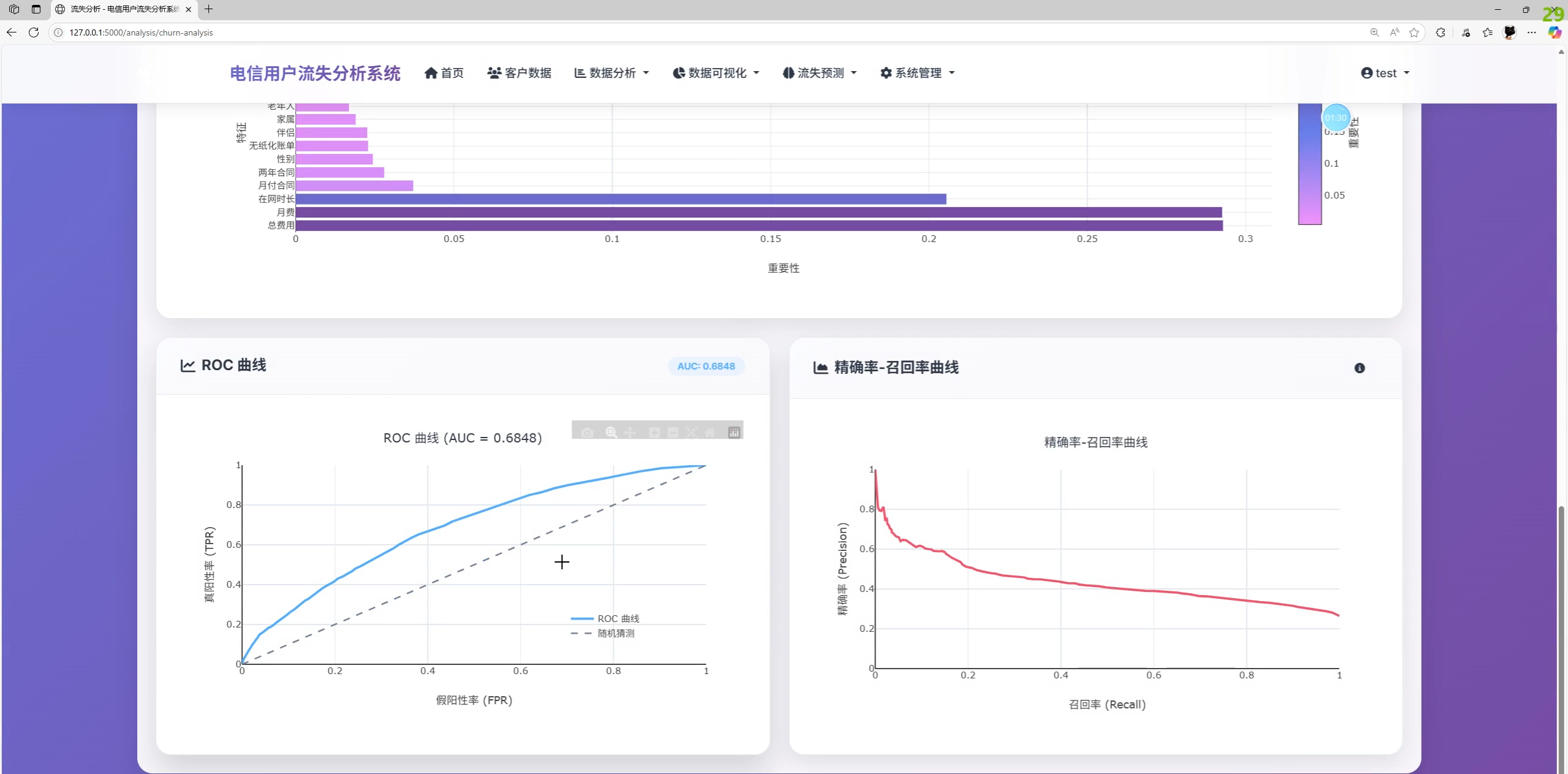
- 离线评估指标
- 准确率 Accuracy、精确率 Precision、召回率 Recall、F1、AUC-ROC
- 实验流程
- 数据清洗 → 划分训练/测试 → 预处理(数值标准化、类别独热)→ 训练(RF/GBDT/LogReg/SVM)→ 评估 → 记录 Log
- 示例代码(来源于
prediction.train_model与analysis.churn_analysis简化整理)
python
# 见上文训练管道与评估示例;可将报告写入 Log 便于前端读取展示- 结果呈现
- 训练历史页展示训练时间与指标;预测历史页展示近期待测分布
- 分析页展示混淆矩阵、ROC/PR 曲线与特征重要性(按需)
创新点与难点攻关
- 权限体系位掩码 + 视图/模板双重校验,保证"可见即有权"
- 预测闭环:模板下载 → 批量上传 → 预测 → 结果导出(含风险等级与建议)
- 训练与预测口径一致:以 Pipeline 固化处理环节,减少线上/离线偏差
- 可视化驱动洞察:前端 Chart.js + 后端统计接口,支持多维对比
- 可扩展性:
Blueprint模块化、forms/models/views分层、migrations可演进
答辩要点与演示脚本
- 要点
- 业务痛点:月付客户/高月费/短在网时长为典型高风险群体
- 技术闭环:数据 → 分析 → 模型 → 预测 → 导出 → 策略
- 安全合规:权限、日志、CSRF、密码哈希
- 演示脚本
- 登录管理员 → 创建一个分析师账号并分配权限
- 切换分析师 → 导入样例数据 → 查看仪表盘与分析页
- 训练模型 → 在客户列表中对单个客户发起预测
- 批量预测 → 导出预测结果 CSV(含风险等级/建议)
- 查看管理员日志页面,展示全链路审计