前言
学习包管理器,光看理论是不够的。最好的方式就是动手做一个项目!
今天我们要构建一个豆瓣电影爬虫,这个项目会用到多个第三方包,让你真正体验包管理器在项目开发中的实际作用。
项目目标
我们要做一个豆瓣电影数据爬虫,功能包括:
- 爬取豆瓣电影排行榜数据
- 提取电影名称、海报、详情信息
- 将数据保存为 JSON 文件
技术选型
在开始之前,我们需要选择合适的包:
javascript
// 项目需要的包
{
"网络请求": "axios - 简单易用的请求库",
"HTML解析": "cheerio - 解析HTML神器",
"文件操作": "fs - Node.js内置模块"
}项目初始化
1. 创建项目目录
bash
# 创建项目文件夹
mkdir douban-movie-crawler
cd douban-movie-crawler
# 初始化 npm 项目
npm init -y执行 npm init -y 后,会生成一个基础的 package.json 文件:
json
{
"name": "douban-movie-crawler",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}2. 安装依赖包
现在我们需要安装项目所需的包(一般是在开发过程中发现需要用到哪些包再去安装):
bash
# 安装 axios 用于网络请求
npm install axios
# 安装 cheerio 用于解析HTML
npm install cheerio执行后,package.json 会自动更新:
json
{
"name": "douban-movie-crawler",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"axios": "^1.11.0",
"cheerio": "^1.1.2"
}
}同时会生成 package-lock.json 文件(用于锁定依赖版本)和node_modules文件(存放第三方库)
3. 项目结构

编写爬虫代码
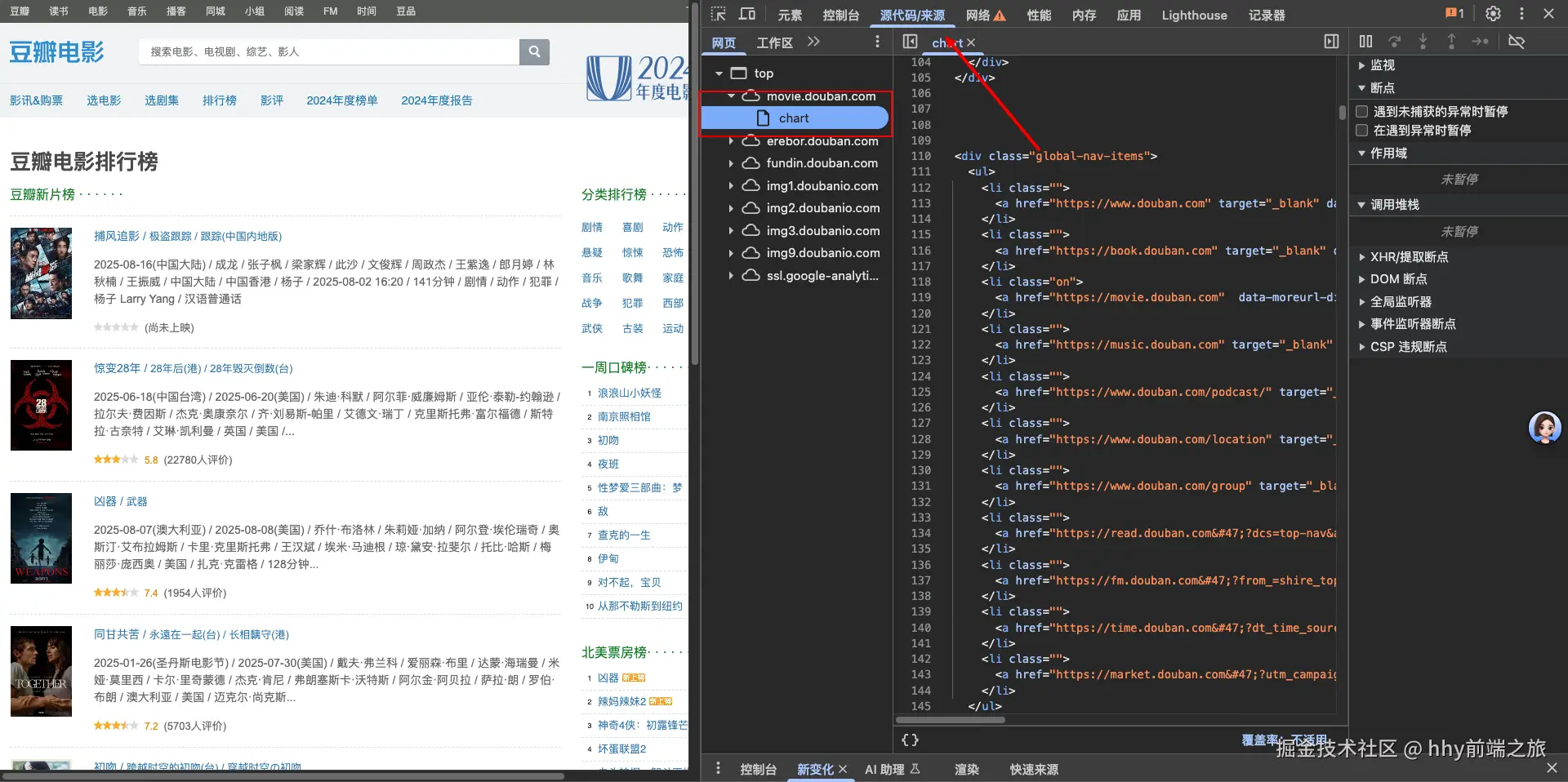
由于我们要爬的是豆瓣电影的内容,那么我们可以先在浏览器中打开豆瓣电影的网站,https://movie.douban.com/chart,右键检查(或F12)打开控制台,选中源代码/来源 tab栏,然后我们可以看到这个下面的chat是html文件,我们要拿到的就是这个html文件
1. 网络请求模块
创建 getMovies.js 文件:
javascript
const axios = require("axios");
/**
* 得到所有电影的html字符串
*/
async function getMoviesHtml() {
const resp = await axios.get("https://movie.douban.com/chart")
console.log(resp);
}
getMoviesHtml()这里我们使用了 axios 包来发送 HTTP 请求, 用于获取豆瓣网站的数据。相比 Node.js 内置的 http 模块,axios 提供了更简洁的 API。
我们可以在终端中运行一下这个文件,看看获取到的resp是什么
// 运行命令
node getMovies.js
可以发现得到的resp是一个对象,里面有很多的属性,而这里的data就是我们需要的html数据
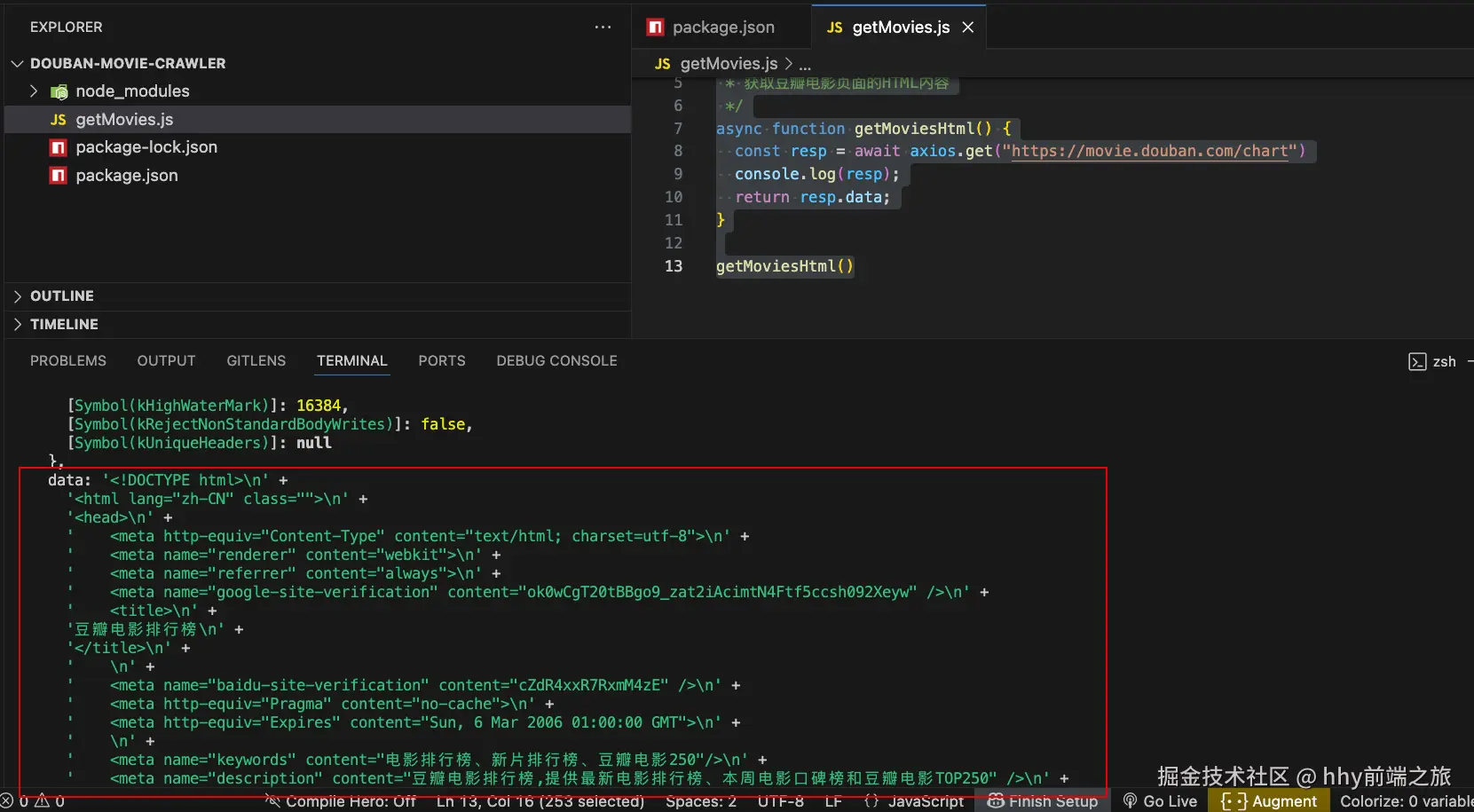
所以我们需要拿到resp.data,那么在getMoviesHtml函数中返回resp.data
2. 数据解析模块
现在获取到了html,那么我们就需要对这个html进行解析,这里就需要用到另外一个库:cheerio,前面已经安装过了,现在就直接拿来用即可
javascript
// getMovies.js
const axios = require("axios");
const cheerio = require("cheerio");
/**
* 得到所有电影的html字符串
*/
async function getMoviesHtml() {
const resp = await axios.get("https://movie.douban.com/chart")
return resp.data;
}
/**
* 获取所有电影数据
*/
async function getMoviesData() {
const html = await getMoviesHtml();
// 将html字符串解析为可操作的dom对象
const $ = cheerio.load(html);
// 找到带有item属性的tr标签
var trs = $("tr.item")
console.log(trs);
}
getMoviesData()cheerio.load(html) 方法解析 HTML 字符串,返回的$是一个函数,可以提供类似 jQuery 的语法来操作 DOM
$("tr.item") 使用 CSS 选择器语法,查找所有 <tr> 标签且 class 包含 item 的元素
cheerio 让我们可以在服务端使用类似 jQuery 的语法来解析 HTML,非常方便!
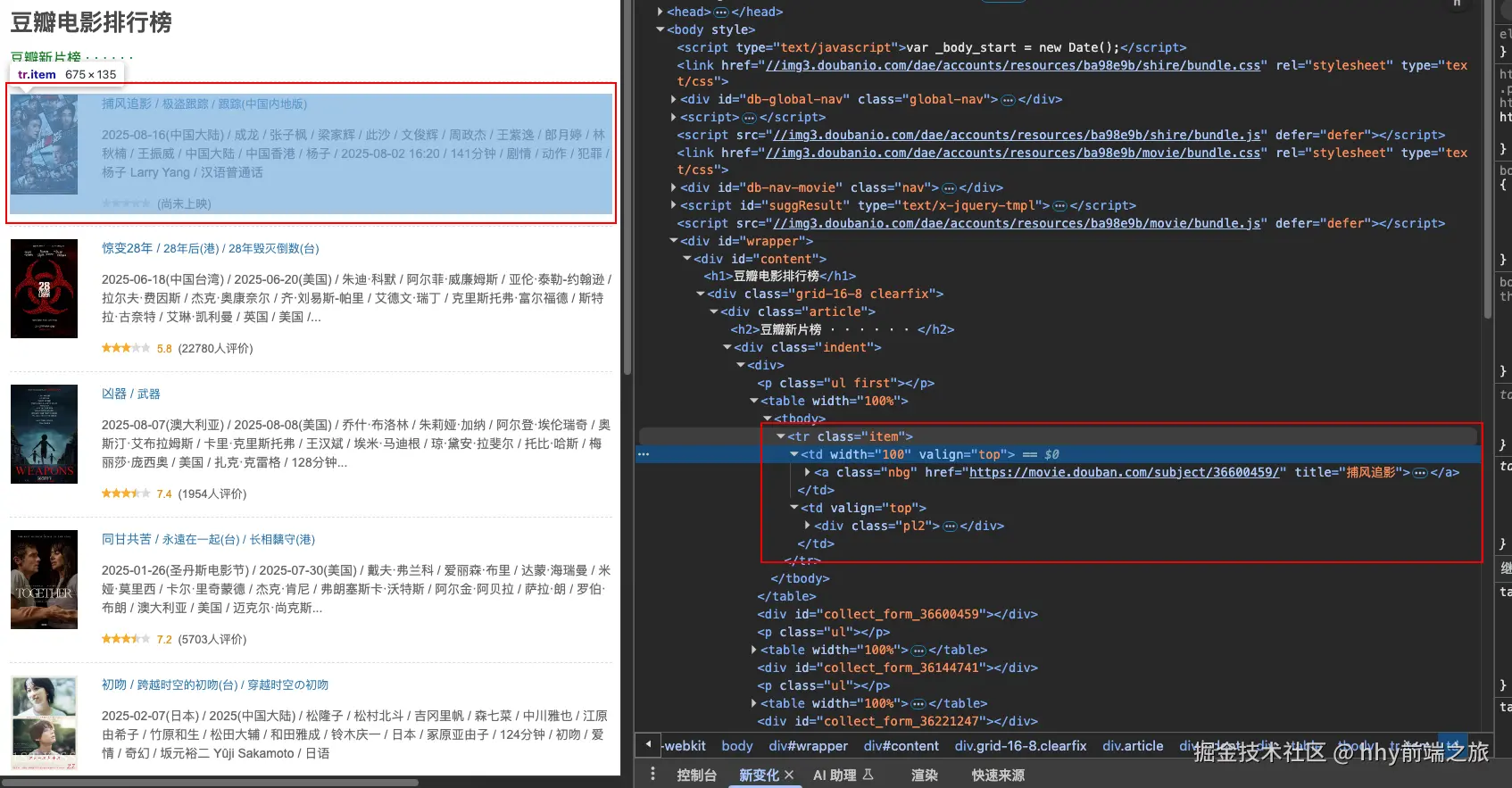
tr中的内容是这部分电影基础内容:
3. 单部电影数据提取
javascript
// getMovies.js
const axios = require("axios");
const cheerio = require("cheerio");
/**
* 得到所有电影的html字符串
*/
async function getMoviesHtml() {
const resp = await axios.get("https://movie.douban.com/chart")
return resp.data;
}
/**
* 获取所有电影数据
*/
async function getMoviesData() {
const html = await getMoviesHtml();
const $ = cheerio.load(html);
var trs = $("tr.item")
var movies = [];
for (let i = 0; i < trs.length; i++) {
var tr = trs[i];
//分析每个tr的数据,得到一部电影对象
var m = getMovie($(tr));
movies.push(m);
}
return movies;
}
/**
* 分析tr,得到一部电影对象
* @param {*} tr
*/
function getMovie(tr) {
// 获取到电影名称
var name = tr.find("div.pl2 a").text();
name = name.replace(/\s/g, "");//去掉空白字符
name = name.split("/")[0];
// 电影封面图
var imgSrc = tr.find("a.nbg img").attr("src");
// 电影详情
var detail = tr.find("div.pl2 p").text();
console.log(name, 'name')
console.log(imgSrc, 'imgSrc')
console.log(detail, 'detail')
console.log('=========================')
return {
name,
imgSrc,
detail
}
}
getMoviesData()我们在拿到所有的tr标签以后,需要遍历每个tr标签,解析电影的名称,电影的封面图和电影的基础信息,这些信息都在对应的标签中可以获取,可以通过在网页中查看具体的元素找到不同内容的存放位置
然后运行一下打印看看:
node getMovies.js
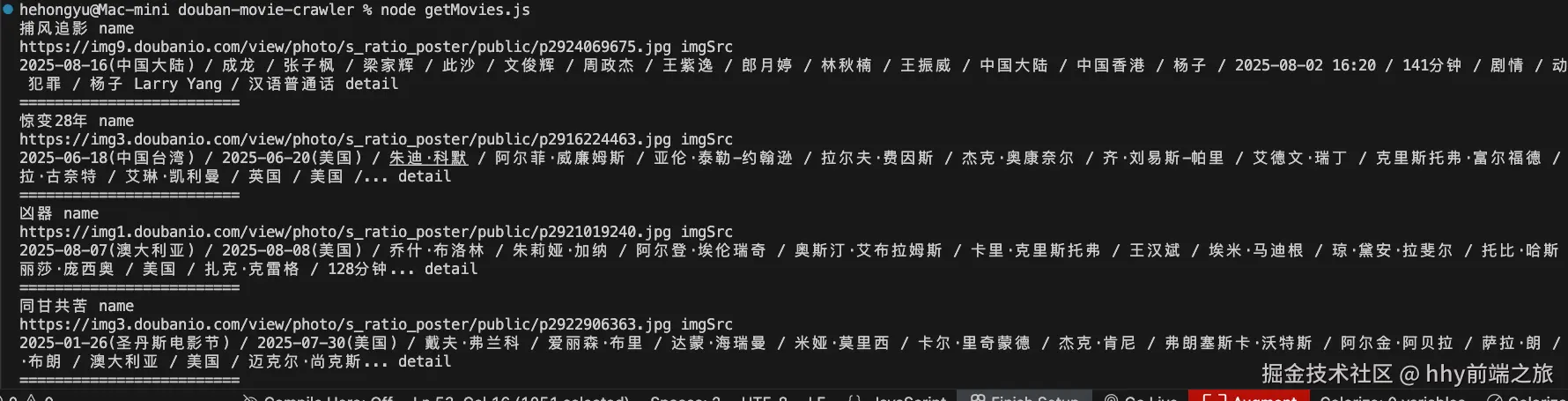
好的,已经成功拿到了电影信息,下面我们把getMoviesData函数导出,然后在主文件去使用 下面是getMovies.js文件的完整内容:
javascript
const axios = require("axios");
const cheerio = require("cheerio");
/**
* 得到所有电影的html字符串
*/
async function getMoviesHtml() {
const resp = await axios.get("https://movie.douban.com/chart")
return resp.data;
}
/**
* 获取所有电影数据
*/
async function getMoviesData() {
const html = await getMoviesHtml();
const $ = cheerio.load(html);
var trs = $("tr.item")
var movies = [];
for (let i = 0; i < trs.length; i++) {
var tr = trs[i];
//分析每个tr的数据,得到一部电影对象
var m = getMovie($(tr));
movies.push(m);
}
return movies;
}
/**
* 分析tr,得到一部电影对象
* @param {*} tr
*/
function getMovie(tr) {
// 获取到电影名称
var name = tr.find("div.pl2 a").text();
name = name.replace(/\s/g, "");//去掉空白字符
name = name.split("/")[0];
// 电影封面图
var imgSrc = tr.find("a.nbg img").attr("src");
// 电影详情
var detail = tr.find("div.pl2 p").text();
return {
name,
imgSrc,
detail
}
}
module.exports = getMoviesData;4. 主程序入口
创建 index.js 文件, 引入刚刚导出的getMoviesData函数,执行这个函数得到存放有电影信息的对象,然后转为json字符串存储到json文件中
javascript
var getMovies = require("./getMovies")
var fs = require("fs");
async function init() {
// 获取电影数据
const movies = await getMovies();
// fs.writeFile 要求写入的内容必须是字符串或二进制数据,所以需要转换为json字符串
const moviesJson = JSON.stringify(movies)
// 将得到的电影数据存到json文件中
fs.writeFile("movie.json", moviesJson, function () {
console.log("成功!")
});
}
init()这里fs.writeFile是nodejs的语法,用于把数据写入到movie.json文件中,如果没有该文件则会创建这个movie.json文件,并写入内容
运行项目
// 运行命令
node index.js
2. 查看结果
运行成功后,会生成 movie.json 文件,内容如下:
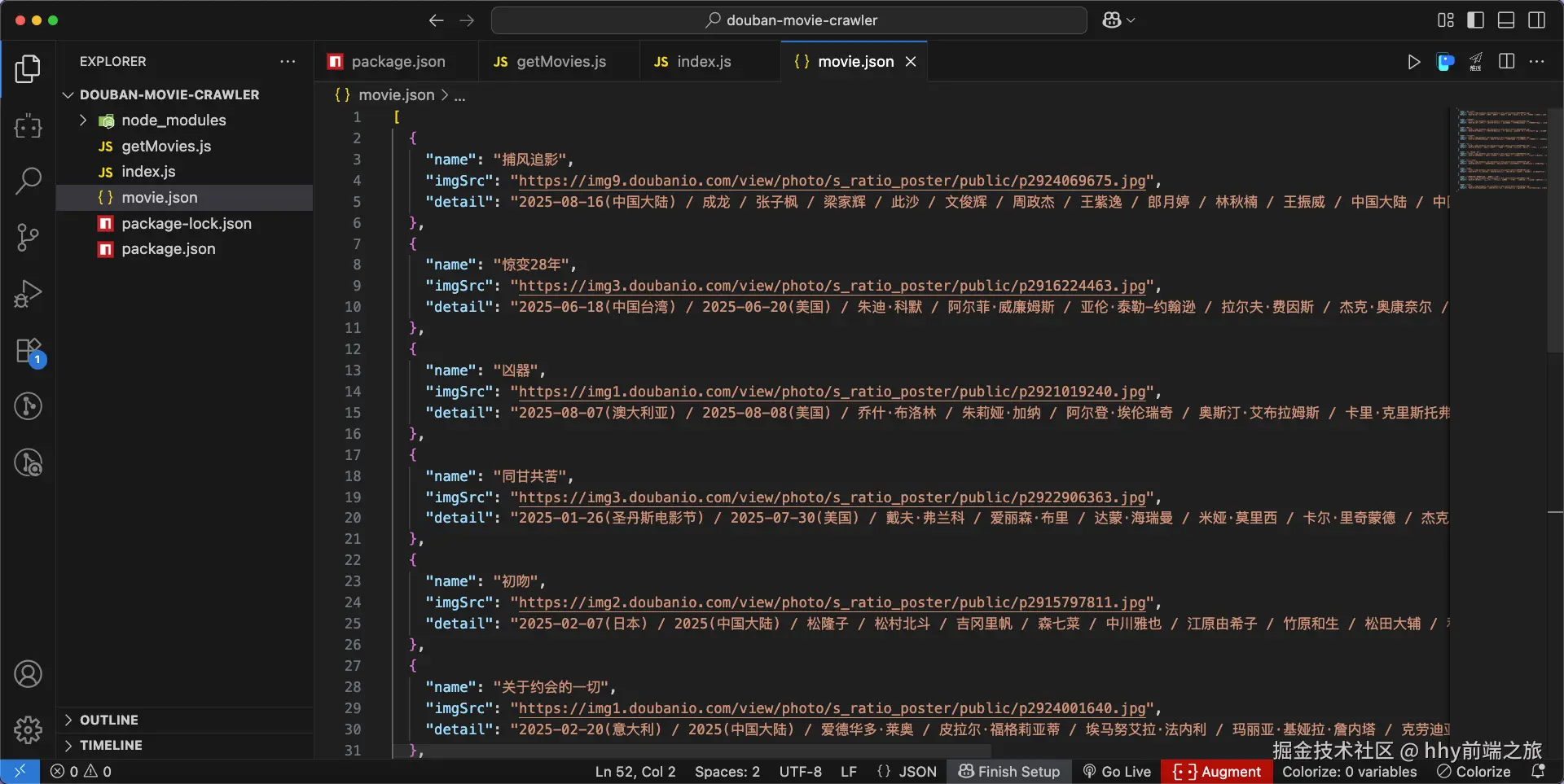
到此,就成功完成了从豆瓣爬取数据到解析数据,存储数据的全流程。
总结
通过这个实战项目,我们学到了:
🎯 包管理器的核心价值
- 依赖管理:自动安装和管理第三方包
- 版本控制:确保团队使用相同的依赖版本
- 项目配置:统一管理项目信息和脚本
- 团队协作:简化项目分享和部署
🔧 实际应用场景
- 选择合适的包解决特定问题
- 管理项目依赖关系
- 配置开发和生产环境
- 团队协作和项目部署
💡 最佳实践
- 合理选择依赖包
- 区分生产依赖和开发依赖
- 使用 package-lock.json 锁定版本
- 配置合适的脚本命令
这个项目虽然简单,但展示了包管理器在实际开发中的重要作用。通过动手实践,你会发现包管理器不仅仅是安装包的工具,更是现代前端开发的核心基础设施。
下一章预告
在下一章《语义版本控制:掌握版本管理的艺术》中,我们将深入学习:
- 语义化版本规范:理解主版本号、次版本号、补丁版本号的含义
- 版本范围指定 :掌握
^、~、>=等版本前缀的使用 - 依赖版本冲突:学会识别和解决版本冲突问题
- 版本锁定策略:了解 package-lock.json 的作用机制
- 安全更新:掌握如何安全地更新依赖包版本