点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月11日更新到:
Java-94 深入浅出 MySQL EXPLAIN详解:索引分析与查询优化详解
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

MySQL 索引与排序机制详解
两种排序方式概述
MySQL 查询处理排序时主要支持两种方式:filesort 和 index 排序。这两种方式在性能上有显著差异,理解它们的区别对于数据库优化至关重要。
filesort 排序方式
filesort 是 MySQL 的通用排序算法,当无法使用索引排序时就会采用这种方式。其工作流程如下:
- 数据获取阶段:首先执行查询获取满足条件的记录
- 排序处理阶段 :将结果集放入排序缓冲区(sort buffer)
- 如果数据量小,完全在内存中完成排序
- 如果数据量大,会使用临时文件进行多轮归并排序
- 结果返回阶段:将排序后的结果返回给客户端
典型的使用 filesort 的场景包括:
- 对没有索引的列进行排序
- 使用了 ORDER BY 与 GROUP BY 不同的表达式
- 排序方向与索引定义方向不一致(如索引是 ASC 但查询要求 DESC)
index 排序方式
index 排序是利用索引本身的有序特性来避免额外的排序操作,其优势包括:
- 直接利用索引:按照索引顺序读取数据,天然有序
- 无额外开销:省去了排序缓冲区的分配和排序计算过程
- 性能优势:特别是对于大型结果集,性能提升显著
使用 index 排序的条件:
- ORDER BY 子句中的列必须与索引列顺序完全匹配
- 排序方向(ASC/DESC)必须与索引定义一致
- 不能跳过索引中的列(遵循最左前缀原则)
性能对比示例
假设有一个包含百万条记录的用户表:
sql
-- 情况1:filesort
SELECT * FROM users WHERE status = 'active' ORDER BY registration_date;
-- 情况2:index排序
SELECT * FROM users WHERE status = 'active' ORDER BY id; -- id是主键在这个例子中,第一种查询可能需要进行完整的 filesort 操作,而第二种查询可以直接利用主键索引的有序性,性能差异可能达到几个数量级。
优化建议
- 为常用排序条件创建合适的索引
- 尽量让排序条件与索引定义完全匹配
- 监控慢查询日志中的"Using filesort"警告
- 适当增大 sort_buffer_size 参数可以减少磁盘临时文件的使用
- 考虑使用覆盖索引避免回表操作
算法对比
MySQL 文件排序(filesort)算法详解
双路排序(Two-pass sorting)
双路排序是 MySQL 中的传统排序算法,其工作流程如下:
- 第一次磁盘扫描:只读取排序字段(ORDER BY 子句中指定的列)和行指针(row pointer)
- 排序阶段:在 sort buffer 中对这些排序键进行排序
- 第二次磁盘扫描:根据排序后的行指针回表读取完整的数据行
- 结果返回:将排序后的完整数据返回给客户端
适用场景:
- 当查询的列很多,或者列数据很大时
- 当 max_length_for_sort_data 参数值设置较小时
- 特别是当使用 SELECT * 查询大量列时
优点:减少了内存使用,因为只需要缓存排序键而非整行数据
单路排序(Single-pass sorting)
单路排序是 MySQL 优化的排序算法,其工作流程如下:
- 单次磁盘扫描:一次性读取查询需要的所有列(包括排序字段和其他字段)
- 内存排序:在 sort buffer 中对这些数据进行排序
- 结果返回:直接返回已排序的结果集
潜在问题:
- 如果查询数据超出 sort buffer 大小(由 sort_buffer_size 参数控制)
- 会导致多次磁盘读取操作
- 可能需要创建临时表
- 最终产生多次 I/O 操作,反而降低性能
优化建议:
- 避免使用
SELECT *,只查询必要的列 - 适当增加 sort_buffer_size 参数值
- 调整 max_length_for_sort_data 参数值(控制单行数据最大长度)
示例场景:
sql
-- 不推荐的写法(可能导致单路排序性能问题)
SELECT * FROM large_table ORDER BY create_time DESC;
-- 推荐的写法(减少数据传输量)
SELECT id, name, create_time FROM large_table ORDER BY create_time DESC;参数调整示例:
sql
-- 增加排序缓冲区大小(默认通常为256KB)
SET sort_buffer_size = 4 * 1024 * 1024; -- 设置为4MB
-- 调整单行排序数据最大长度(默认1024字节)
SET max_length_for_sort_data = 8192; -- 设置为8KBEXPLAIN
如果我们使用 EXPLAIN 命令分析 SQL 查询的执行计划时:
在结果集的 Extra 列中,如果出现"Using filesort"的提示,这表示 MySQL 在执行查询时使用了文件排序(filesort)操作。filesort 是一种成本较高的排序方式,当不能使用索引排序时,MySQL 会将结果集放入临时表并进行排序。这种情况下,我们应该考虑优化查询或添加适当的索引来提高性能。
优化 filesort 的常见方法包括:
- 为 ORDER BY 子句中的列创建合适的索引
- 确保 WHERE 条件中的列和 ORDER BY 列使用相同的索引
- 减少查询返回的数据量
相反,如果 Extra 列显示"Using Index",这表示查询使用了覆盖索引(Covering Index),即查询所需的所有数据都可以从索引中获取,而不需要回表查询数据行。这种情况是最理想的:
- 查询性能最优,因为完全避免了访问数据表
- 可以使用 index 排序方式,效率远高于 filesort
- 减少了 I/O 操作,降低了内存使用
在实际开发中,我们应尽量设计查询使其能够使用覆盖索引,具体方法包括:
- 创建包含所有查询字段的复合索引
- 避免 SELECT * 查询,只选择必要的列
- 确保 WHERE、ORDER BY 和 GROUP BY 子句中的列被索引覆盖
例如,对于查询:
sql
SELECT id, name FROM users WHERE status = 1 ORDER BY create_time;创建索引 (status, create_time, id, name) 就能实现覆盖索引,避免 filesort 操作。
index方式
当我们使用 order by 子句索引组合满足索引最左前列的时候:
sql
explain select id from wzk_user order by id;执行结果如下所示:
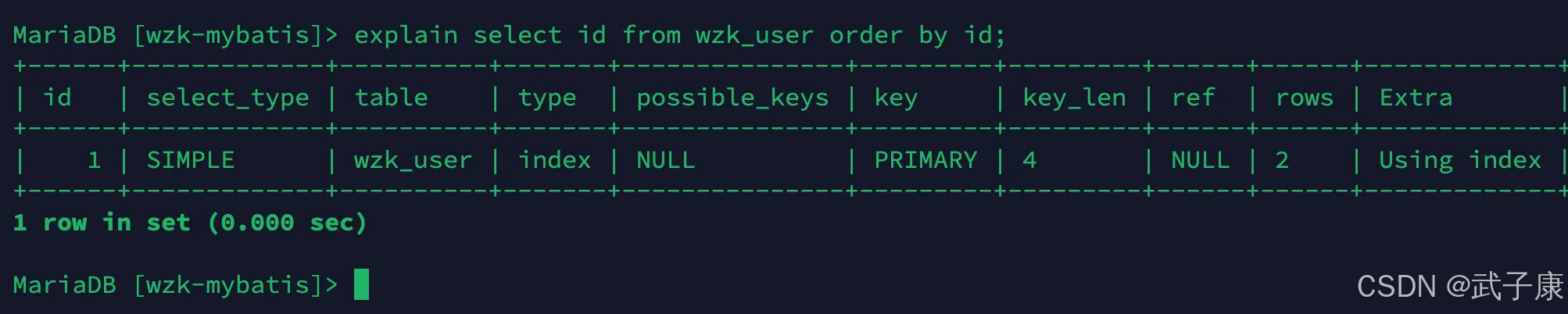
当我们使用 where 子句 + order by子句 索引组合列满足索引最左前列的时候:
sql
explain select id from user_info where age > 18 order by username;对应的结果如下所示:
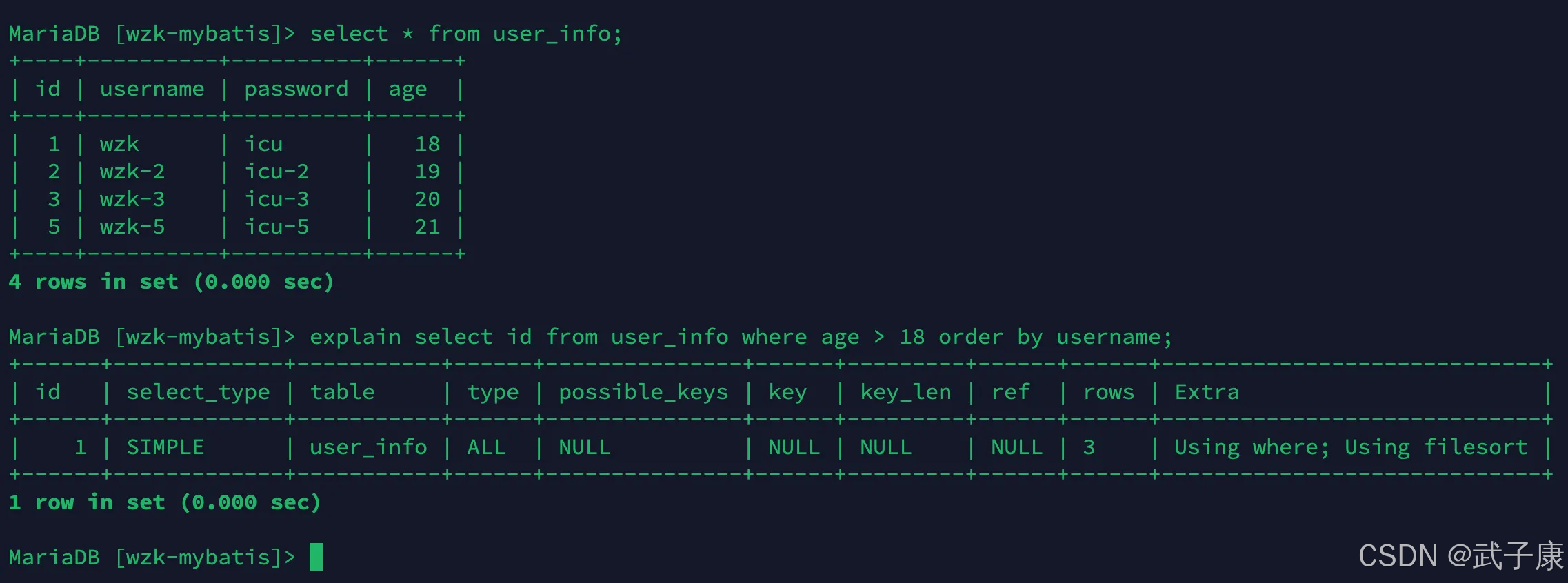
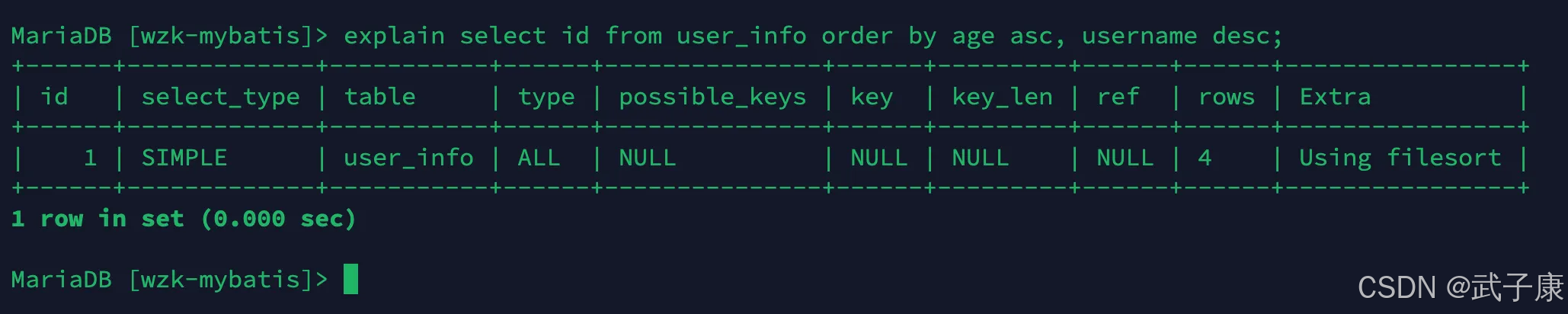
filesort方式
对索引列同时使用了 ASC 和 DESC:
sql
explain select id from user_info order by age asc, username desc;对应的结果如下所示:
where 子句和order by子句满足最左前缀,但where 子句使用了范围查询:
sql
explain select id from user_info where age > 10 order by username;对应的结果如下所示:

order by 或者 where + order by 索引没有满足索引最左前列:
sql
explain select id from user_info order by username;执行结果如下所示:

使用了不同的索引,MySQL每次只采用一个索引,order by涉及了两个索引:
sql
explain select id from user_info order by username, age;对应的结果如下所示:
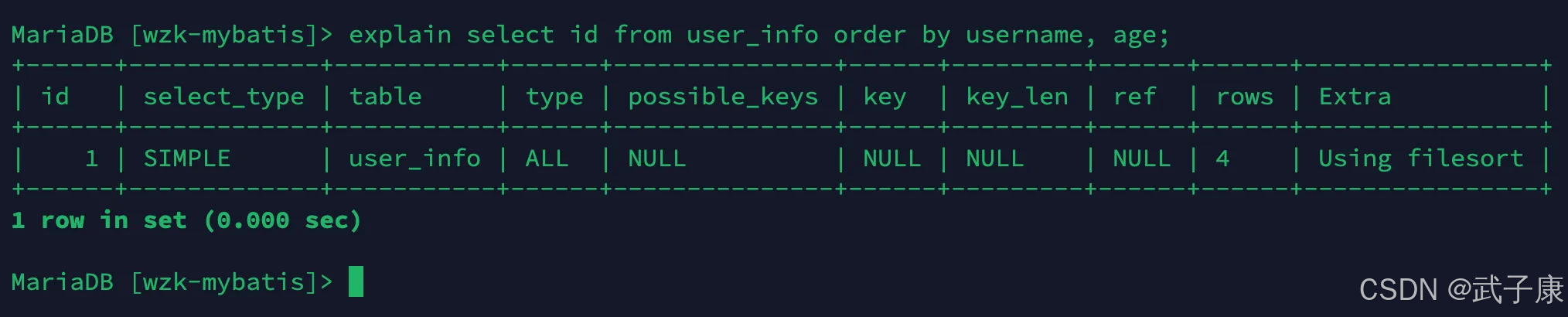
where 子句与order by子句,使用了不同的索引:
sql
explain select id from user_info order by abs(age);对应的结果如下所示:

ASC DESC
- ASC:升序(Ascending),从小到大。
- DESC:降序(Descending),从大到小。
- SQL 中默认是 ASC,显式写 DESC 会反转结果顺序。
sql
SELECT * FROM users ORDER BY age ASC; -- 年龄小的在前
SELECT * FROM users ORDER BY age DESC; -- 年龄大的在前聚簇索引(Clustered Index)与辅助索引(Secondary Index)
- 索引结构
- InnoDB 存储引擎采用 B+ 树作为索引结构
- 聚簇索引:
- 叶子节点存储完整的数据记录(数据即索引)
- 每个表只能有一个聚簇索引,通常建立在主键上
- 物理存储顺序与索引顺序一致
- 辅助索引(二级索引):
- 叶子节点只存储主键值,不包含完整数据
- 通过回表操作获取完整数据
- 一个表可以有多个辅助索引
- 遍历方式
- 升序遍历:
- 从 B+ 树最左叶子节点开始向右顺序扫描
- 示例:SELECT * FROM table ORDER BY id ASC
- 降序遍历:
- 从 B+ 树最右叶子节点开始向左顺序扫描
- 示例:SELECT * FROM table ORDER BY id DESC
- 性能特点
- 聚簇索引优势:
- 范围查询效率高(数据物理连续)
- 主键查找只需一次IO
- 辅助索引特点:
- 需要两次查找(先查辅助索引,再查聚簇索引)
- 覆盖索引可避免回表(查询字段都在索引中)
- 应用场景
- 聚簇索引:
- 主键查询
- 范围查询(如 BETWEEN, >, <)
- 排序操作
- 辅助索引:
- 非主键字段查询
- 多条件查询(可建立复合索引)
- 频繁查询但更新少的字段聚簇索引(Clustered Index)与辅助索引(Secondary Index)
- 索引结构
- InnoDB 存储引擎采用 B+ 树作为索引结构
- 聚簇索引:
- 叶子节点存储完整的数据记录(数据即索引)
- 每个表只能有一个聚簇索引,通常建立在主键上
- 物理存储顺序与索引顺序一致
- 辅助索引(二级索引):
- 叶子节点只存储主键值,不包含完整数据
- 通过回表操作获取完整数据
- 一个表可以有多个辅助索引
- 遍历方式
- 升序遍历:
- 从 B+ 树最左叶子节点开始向右顺序扫描
- 示例:SELECT * FROM table ORDER BY id ASC
- 降序遍历:
- 从 B+ 树最右叶子节点开始向左顺序扫描
- 示例:SELECT * FROM table ORDER BY id DESC
- 性能特点
- 聚簇索引优势:
- 范围查询效率高(数据物理连续)
- 主键查找只需一次IO
- 辅助索引特点:
- 需要两次查找(先查辅助索引,再查聚簇索引)
- 覆盖索引可避免回表(查询字段都在索引中)
- 应用场景
- 聚簇索引:
- 主键查询
- 范围查询(如 BETWEEN, >, <)
- 排序操作
- 辅助索引:
- 非主键字段查询
- 多条件查询(可建立复合索引)
- 频繁查询但更新少的字段
索引与排序的关系
索引排序的基本原理
当 ORDER BY 子句的字段顺序与索引顺序完全一致且排序方向相同时(都是 ASC 或都是 DESC),MySQL 优化器可以利用索引的有序特性直接返回已排序的结果集,这种优化称为"索引排序"(Index Order By)。这种情况下,执行计划中不会出现"Using filesort"的额外操作。
示例:
sql
-- 假设有索引 idx_name_age (name, age)
-- 可以直接使用索引排序的情况
SELECT * FROM users ORDER BY name ASC, age ASC;无法使用索引排序的情况
-
排序方向不一致:
- 当索引字段的排序方向与 ORDER BY 指定的方向不一致时
- 示例:
ORDER BY name ASC, age DESC(索引是 ASC,ASC)
-
字段顺序不匹配:
- ORDER BY 字段的顺序与索引定义的顺序不同
- 示例:
ORDER BY age, name(索引是 name, age)
-
混合使用 ASC 和 DESC:
- 即使字段顺序匹配,但排序方向混合时
- 示例:
ORDER BY name DESC, age ASC
-
包含非索引字段:
- ORDER BY 包含不在索引中的字段
- 示例:
ORDER BY name, email(email 不在索引中)
Filesort 操作
当无法使用索引排序时,MySQL 必须执行额外的排序操作(Filesort):
- 数据会被收集到排序缓冲区
- 使用快速排序算法在内存中排序
- 如果数据量太大,会使用临时文件进行外部排序
- 在 EXPLAIN 结果中会显示"Using filesort"
最佳实践建议
-
设计匹配查询的索引:
sql-- 为常见排序查询创建专用索引 CREATE INDEX idx_users_sort ON users(last_name ASC, first_name ASC, hire_date DESC); -
使用覆盖索引:
- 当查询只需要索引列时,可以完全避免访问表数据
- 示例:
SELECT user_id FROM users ORDER BY name(user_id 是主键)
-
**避免 SELECT ***:
- 只查询需要的列,增加使用覆盖索引的可能性
-
注意多列索引的顺序:
- 确保索引列顺序与常用 ORDER BY 子句一致
-
考虑使用 DESC 索引(MySQL 8.0+):
sqlCREATE INDEX idx_desc ON table_name (column_name DESC);
特殊情况说明
-
LIMIT 优化:
- 即使需要 Filesort,带有 LIMIT 的查询可能只需要排序部分数据
-
索引跳跃扫描(MySQL 8.0+):
- 在某些情况下,即使 ORDER BY 不是索引的最左前缀,也可能使用索引
-
分区表排序:
- 在分区表上排序可能会有不同的性能特征# 索引与排序的关系
索引排序的基本原理
当 ORDER BY 子句的字段顺序与索引顺序完全一致且排序方向相同时(都是 ASC 或都是 DESC),MySQL 优化器可以利用索引的有序特性直接返回已排序的结果集,这种优化称为"索引排序"(Index Order By)。这种情况下,执行计划中不会出现"Using filesort"的额外操作。
示例:
sql
-- 假设有索引 idx_name_age (name, age)
-- 可以直接使用索引排序的情况
SELECT * FROM users ORDER BY name ASC, age ASC;