为什么要关注 Caffeine 缓存和淘汰策略?
在高并发业务场景下(如电商秒杀、热点新闻、实时推荐等),缓存命中率 和延迟 往往决定了系统的性能上限。 Java 世界中,Caffeine 已经是事实上的本地缓存首选,它不仅性能优秀,还在内存管理和淘汰策略方面设计得极为精巧。
- 性能层面:官方基准测试表明,Caffeine 的命中率在大多数真实业务场景中已经接近理论最优。
- 生态层面 :Spring Boot 2.x 之后,
spring-boot-starter-cache默认就集成了 Caffeine,你可以几乎零成本启用它。
一个现实例子:京东开源的 JD-HotKey 中间件在探测到 Redis 热 Key 时,可以将其直接推入客户端的 Caffeine 缓存,避免 Redis 热点访问引发的网络 IO 风暴。
但 Caffeine 真正厉害的地方,并不只是"快",而是它在淘汰策略上的精妙设计,尤其是 W-TinyLFU 这一算法,既兼顾高命中率,又高效利用有限的内存。
Spring Caffeine 作为一个高性能的开源 Java 缓存库,提供了高命中率和出色的并发能力。根据官方的描述,其缓存命中率已经接近了最优值。
在 Spring 生态系统中,Caffeine 已经成为默认的缓存提供者,与 Spring Cache 的集成非常简单。通过 Spring 的缓存抽象,你可以轻松地使用 Caffeine 的强大功能,而不需要直接与其 API 交互。
为什么淘汰策略如此重要?
而我们今天就来聊一下 Spring Caffeine 的淘汰策略,希望可以帮助你对 Caffeine 有更深的了解。
想象一下,如果我们的缓存可以无限大,那么我们根本不需要考虑淘汰任何数据,所有数据一旦进入缓存就可以永久保存。 我们根本无需淘汰缓存条目,所有数据都可以永久驻留,缓存命中率自然 100%。\ 可现实中,内存是宝贵且有限的,尤其在 JVM 内存已经被业务对象占用很大一部分时,缓存的膨胀很容易触发 OOM(OutOfMemoryError)。
因此,缓存系统必须回答一个核心问题:
在有限空间内,如何保留最有价值的数据,从而最大化命中率?
在深入分析 Caffeine 的淘汰策略之前,我们要先来看一看 Caffeine 的整体架构,从整体看 Caffeine 提供了四种主要的 Cache 类型:
Cache: 最基本的缓存接口,需要手动加载值LoadingCache: 扩展了 Cache,支持自动加载值AsynCache:支持异步加载,但需要手动加载值AsyncLoadingCache: 支持异步加载值,返回 CompletableFuture
而上述这些 Cache 只是 Caffeine 向外提供的交互接口而已,当用户通过 Caffeine 构建器创建一个配置了边界(如 maximumSize 、 expireAfterWrite 等)的缓存时,底层实际创建和使用的是 BoundedLocalCache 实例。 BoundedLocalCache 的关键组件如下
java
class BoundedLocalCache<K, V> extends LocalCache<K, V> {
// 省略其他代码...
final FrequencySketch<K> sketch;
final AccessOrderDeque<Node<K, V>> accessOrderWindowDeque;
final AccessOrderDeque<Node<K, V>> accessOrderProbationDeque;
final AccessOrderDeque<Node<K, V>> accessOrderProtectedDeque;
// 省略其他代码...
}这里的几个关键字段解释一下:
sketch:这是一个频率草图,用于记录和估计每个键的访问频率accessOrderWindowDeque:准入窗口队列accessOrderProbationDeque:SLRU 中的 probation 段队列accessOrderProtectedDeque:SLRU 中的 protected 段队列
而这四个大将也组成了 Caffeine 中最优秀的缓存淘汰机制 W-TinyLFU 的底层设计。
W-TinyLFU 的核心思想
用图片来表示的话,我们可以认为 W-TinyLFU 的结构分为以下:
W-TinyLFU = Window Cache + TinyLFU 过滤器 + SLRU 主缓存 的组合拳。
- Window Cache(准入窗口):短期缓存,存放刚进入的条目。
- TinyLFU 过滤器:基于访问频率,决定新条目是否能进入主缓存。
- SLRU 主缓存 :
- Protected 段:多次访问的热点数据。
- Probation 段:一次访问或新晋的数据,等待"考察"。
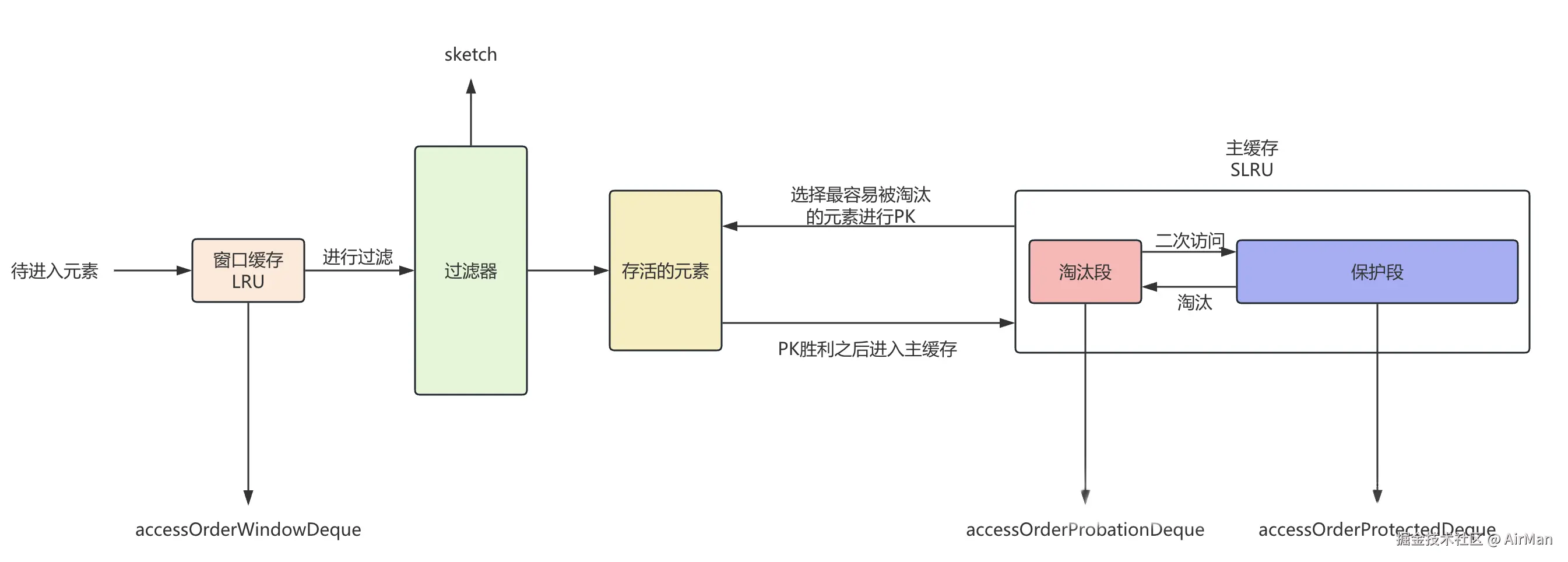
也就是说:W-TinyLFU算法的核心思想是:使用一个小的准入窗口(Window)来过滤掉可能只被访问一次的数据,然后使用TinyLFU策略来决定是否允许新数据进入主缓存区域。主缓存区域则使用SLRU(Segmented LRU)策略进行管理。
W-TinyLFU我们可以理解为其实本质上是一个多个缓存组件拼接出来的大缓存算法。
因此我们逐****个击破一下,先说过滤器吧。
当窗口缓存满了之后,触发LRU算法淘汰最久未访问元素,这个时候如果淘汰段还没满的话就直接该元素加入到淘汰段。
如果淘汰段满了的话就开始走过滤器开始比较主缓存中淘汰的元素和当前元素的访问频率。
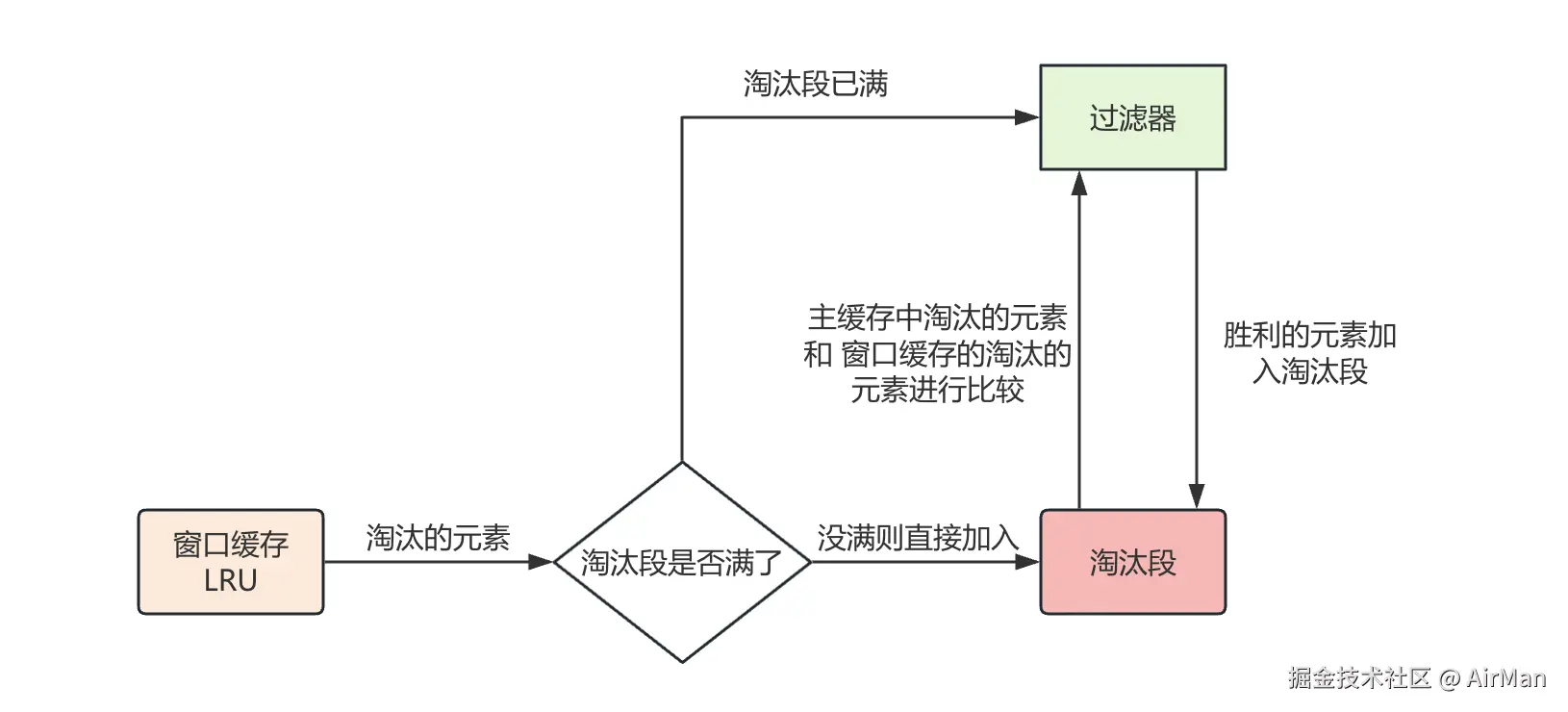
让我们更加专业一些, 从 Window Cache 和 Protected Cache 中移出的缓存项称为 Candidate ,而从 Probation Cache 中移出的缓存项称为 Victim (受害者) 。那么在过滤器中,比较规则如下:
java
如果 Candidate 的访问频率 > Victim 的访问频率,则直接淘汰 Victim
如果 Candidate 的访问频率 <= Victim 的访问频率,此时分为两种情况:
如果 Candidate 的访问频率 < 5 ,则淘汰 Candidate ;
如果 Candidate 的访问频率 >= 5 ,则在 Candidate 和 Victim 中随机淘汰一个。这里还有一个比较好玩的事情:这些元素的访问频率是怎么被统计出来的?
之前我们说过所有的 BoundedLocalCache 底层都是 BoundedLocalCache,因此我们来看一看 BoundedLocalCache 对应的源码:
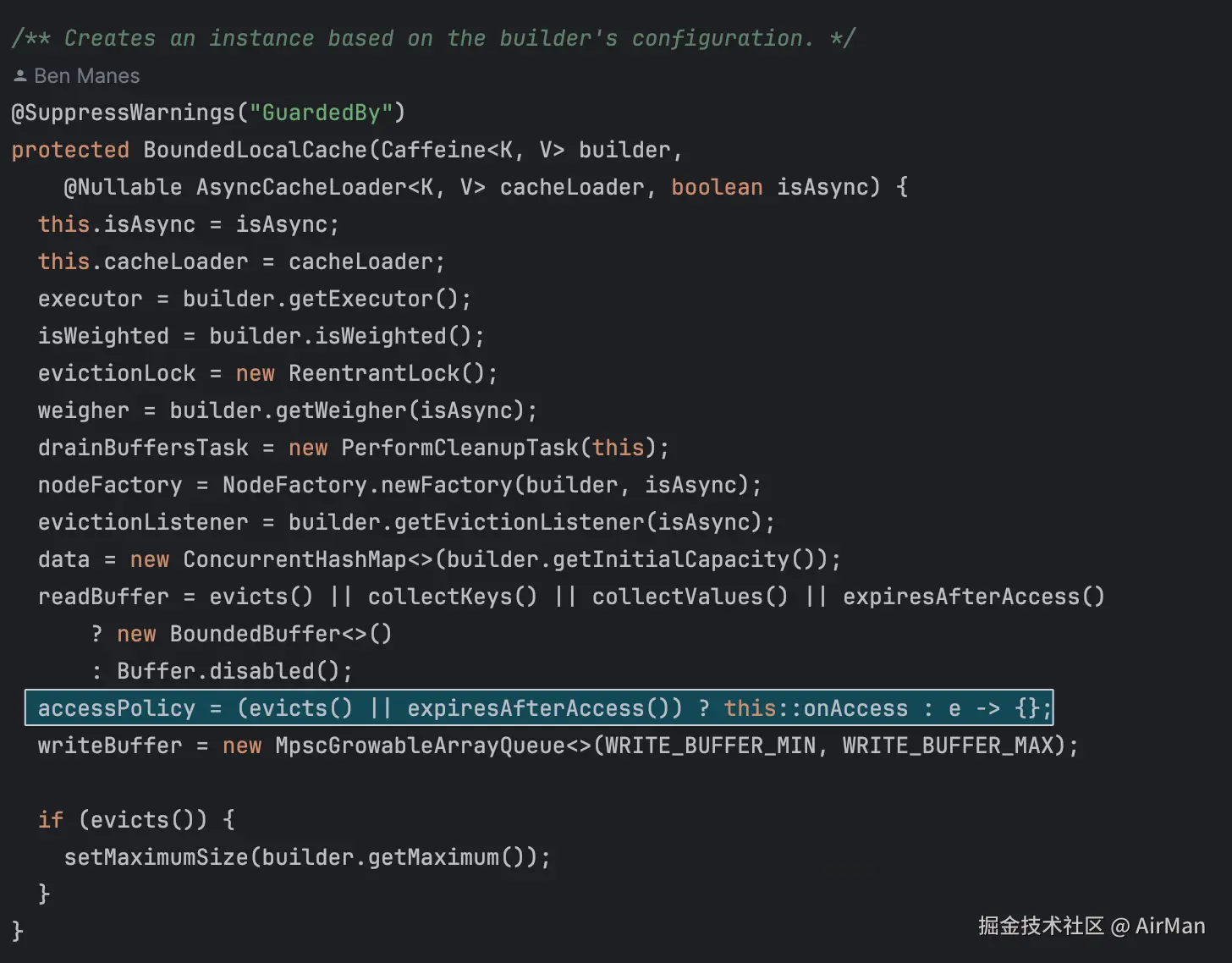
我们在这里根据缓存配置的策略(淘汰或访问过期)来决定是否在缓存条目被访问时执行回调方法(onAccess)。如果有需要,则注册回调;否则,使用一个空操作来避免开销
TinyLFU 中的频率统计:FrequencySketch
Caffeine 采用了 Count-Min Sketch(压缩计数器)来记录 Key 的访问频率:
- 空间效率高:只需很小内存即可存储大量 Key 的近似计数。
- 允许误差:适合缓存场景,对频率的近似统计已经足够。
而当你看onAccess源码的时候,你就会发现:
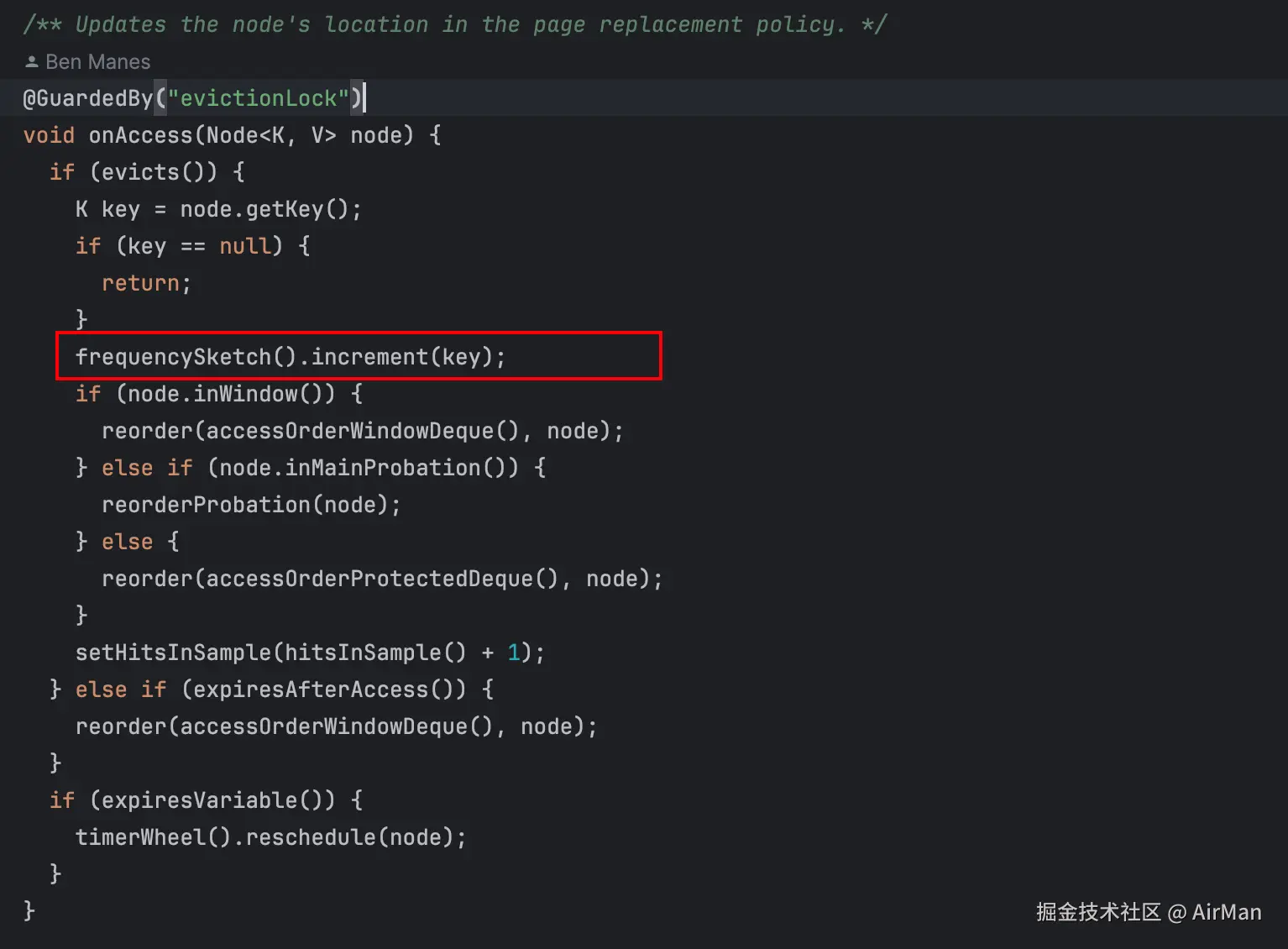
记录访问频率的代码原来是在这里,调用了 frequencySketch 的方法来更新元素的频率。
也就是说当一个元素配置了基于大小的驱逐策略或者基于时间的过期策略时,所有的key都会走到这个方法中进行频率的更新。
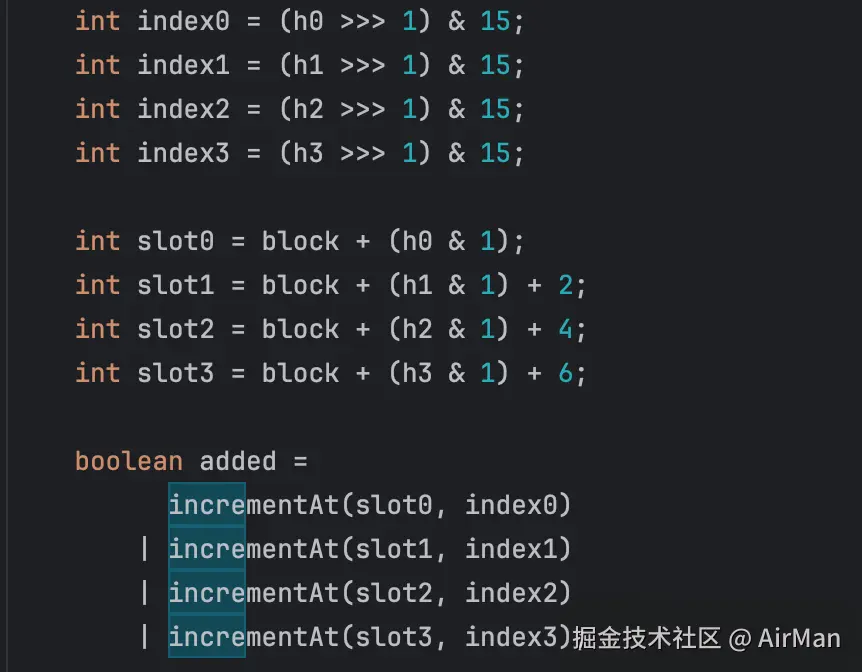
那让我们接着来看看这个 increment 方法是怎么实现的:
java
@SuppressWarnings({"ShortCircuitBoolean", "UnnecessaryLocalVariable"})
public void increment(E e) {
if (isNotInitialized()) {
return;
}
int blockHash = spread(e.hashCode());
int counterHash = rehash(blockHash);
int block = (blockHash & blockMask) << 3;
// Loop unrolling improves throughput by 10m ops/s
int h0 = counterHash;
int h1 = counterHash >>> 8;
int h2 = counterHash >>> 16;
int h3 = counterHash >>> 24;
int index0 = (h0 >>> 1) & 15;
int index1 = (h1 >>> 1) & 15;
int index2 = (h2 >>> 1) & 15;
int index3 = (h3 >>> 1) & 15;
int slot0 = block + (h0 & 1);
int slot1 = block + (h1 & 1) + 2;
int slot2 = block + (h2 & 1) + 4;
int slot3 = block + (h3 & 1) + 6;
boolean added =
incrementAt(slot0, index0)
| incrementAt(slot1, index1)
| incrementAt(slot2, index2)
| incrementAt(slot3, index3);
if (added && (++size == sampleSize)) {
reset();
}
}这个代码里面本质上是对一个计数器进行自增操作。但是它能够以一个非常小的空间统计大量元素的计数,同时保证高的性能及准确性。
与布隆过滤器类似,由于它是基于概率的,因此它所统计的计数是有一定概率存在误差的,也就是可能会比真实的计数大。比如一个元素实际的计数是10,但是计算器的计算结果可能比10大。因此适合能够容忍计数存在一定误差的场景,比如缓存中元素被访问频率。
用图表示的话,我们可以认为逻辑如下:
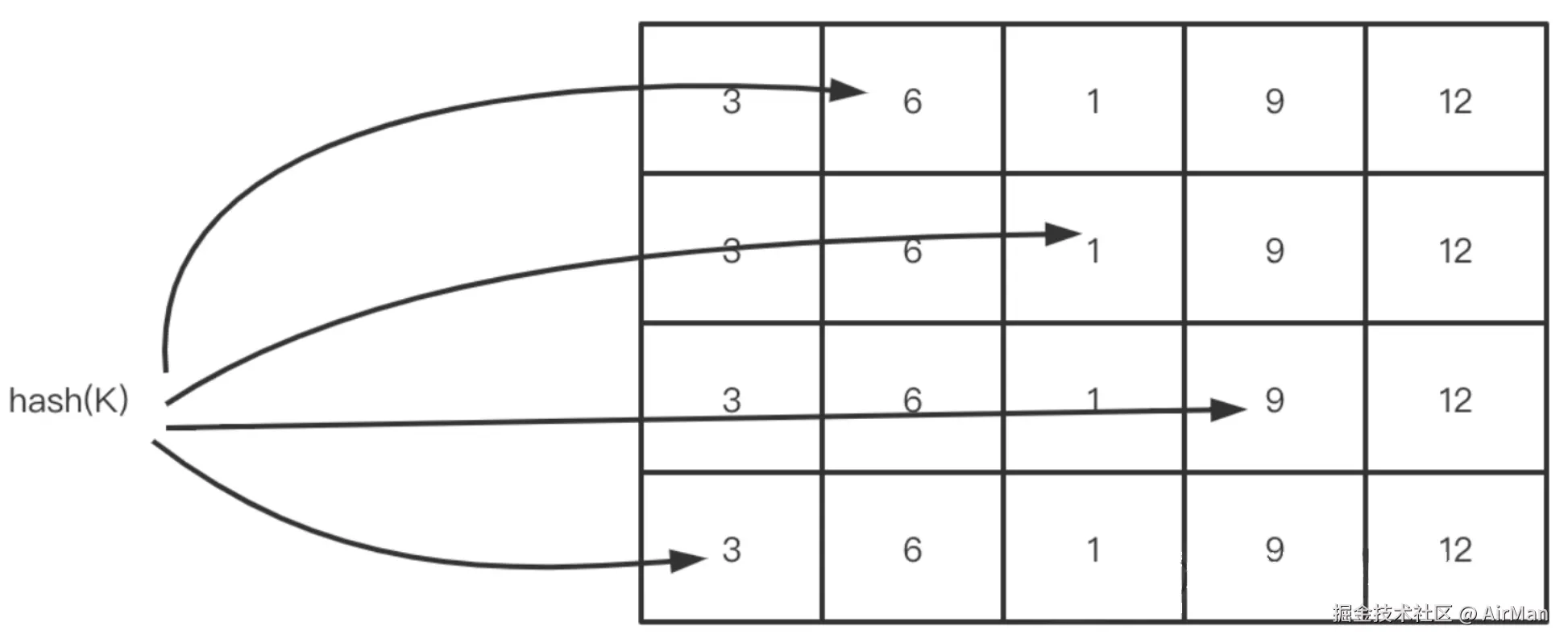
我们会对一个key进行hash得到下标之后,对 下标位置的值+1。为了减少不同key之间的Hash冲突,我们选择多次哈希之后对多个位置进行自增操作。并且在取值的时候取最小值。
而在Caffeine中我们使用了四个哈希函数。因此你可以在代码中看到increment方法在最后add的时候是操作了四个块:
因为不同元素可能会哈希冲突,导致两个不同的元素对同一个区块做了自增操作。因此我们最后选择的是一个key下值最小的快作为当前key的访问频率。
并且这里还有一个问题是:如果一个key的历史访问频率很高,但是后面这个key不咋访问了,那如果有一些新增的热key在PK的时候也是PK不过这个历史访问热key的。
为了解决这个问题,Caffeine设计了衰退期,每当区块的值达到15或者整个二维数组的值达到一定的限度之后,就会调用Reset方法,将所有区块的值除于二。相当于衰减所有的key。
这种设计下确保了 CountMinSketch 中的频率估计能够反映近期的访问模式,而不是无限期地累积旧的访问计数。这是 TinyLFU 缓存策略中保持频率信息新鲜度的关键机制。
在这里还有一个拓展的点,但是我在Caffeine的项目中实在是没有找到这个拓展点,有看过源码的同学可以评论区告诉我这段逻辑在哪里:
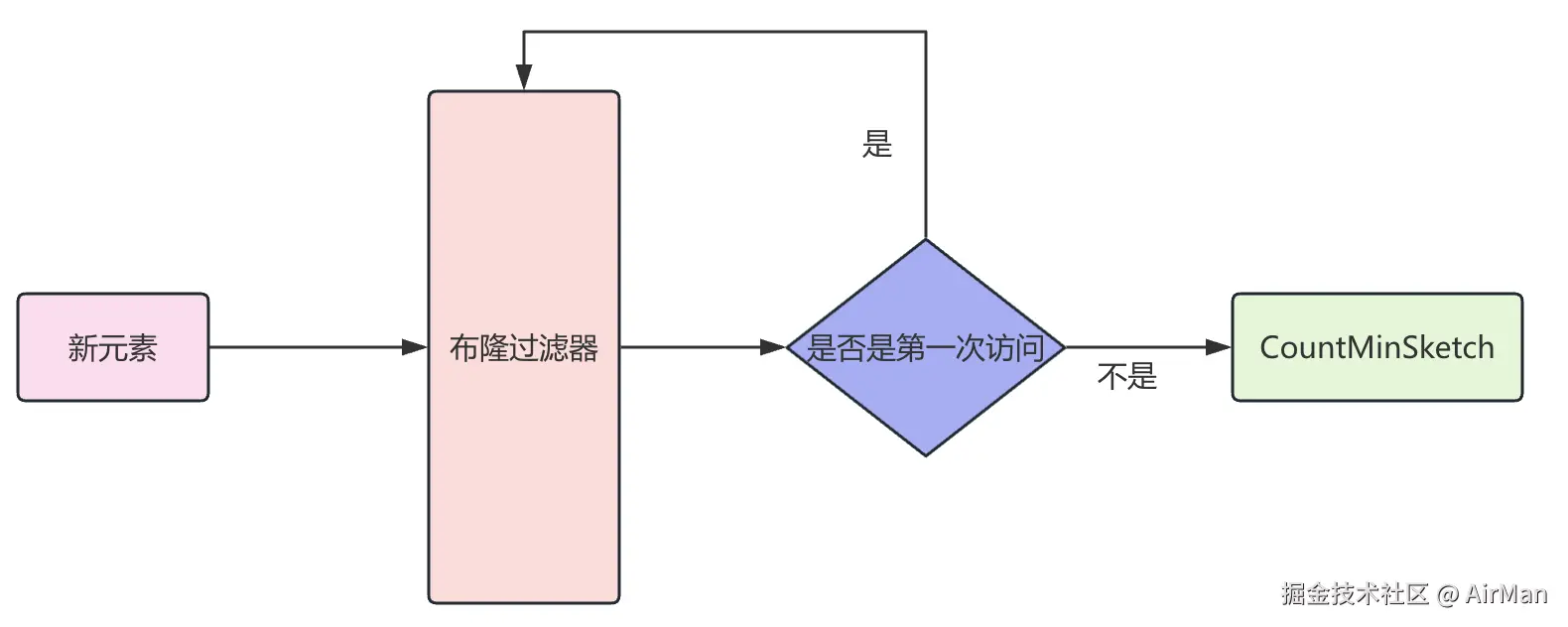
为了极致的节省内存,当一个元素加入CountMinSketch之前,通常会有布隆过滤器进行拦截。
原因是因为有的元素可能就访问一次,但是如果我们还是要为这个元素在CountMinSketch中使用四个区块来记录访问频率的话就太浪费内存了。
因此我们会使用布隆过滤器来进行一次过滤,当你第一次访问的时候,你就会被记录在布隆过滤器中,当你是第二次访问的时候,才会穿过布隆过滤器进入CountMinSketch。
那说完了过滤器之后,我们来看看主缓存
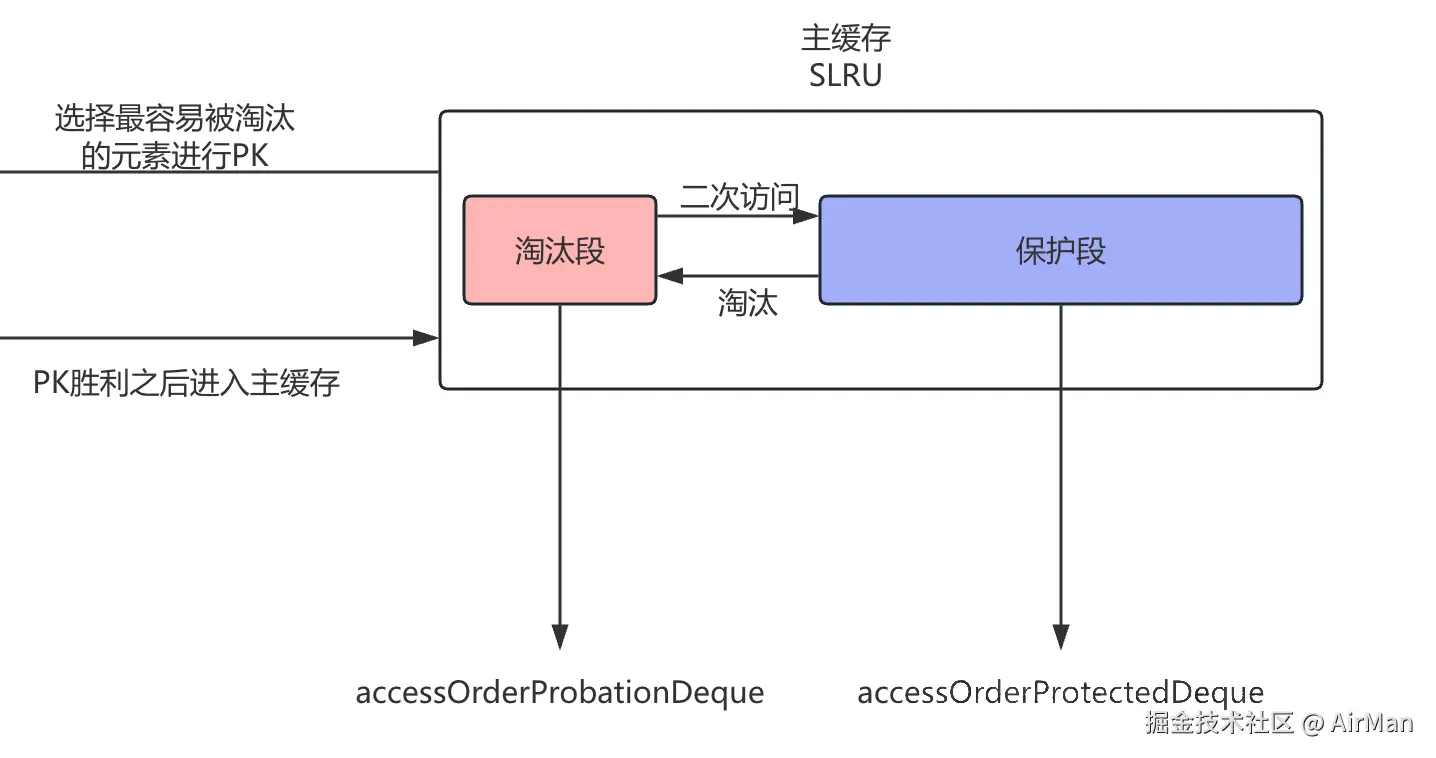
一整个主缓存被分为了两部分:淘汰段和保护段:
主缓存的 SLRU 管理
它本质上采用的就是SLRU算法,在介绍SLRU之前,我们要简单的介绍一下LRU:
LRU的意思是淘汰最近最少使用的元素。如果我们将所有元素看做是一个链表,每一个被最新访问了的元素都会被添加到链表的头部。而如果一个元素最近没有被访问的话,他就会被慢慢的推向链表尾部。当空间不足的时候,我们会选择淘汰链表尾部的元素,因为尾部的元素是最久没有被使用的。
但是LRU算法会有一个缺点:容易受到稀疏流量的影响。当遇到大量的稀疏流量的时候,会把大量的元素淘汰出去,而这些稀疏流量有可能后续就不会被再次访问,导致缓存的命中率大大降低。
为了解决这个问题,我们设计出了SLRU。SLRU将将 LRU 分成保护段(protected segment)和淘汰段(probationary segment)
新数据会被存储在淘汰段,后续如果被访问到,则被提升到保护段。当保护段满的时候,数据会被淘汰至淘汰段,这时候如果淘汰段也满了的话,则使用 LRU 驱逐。
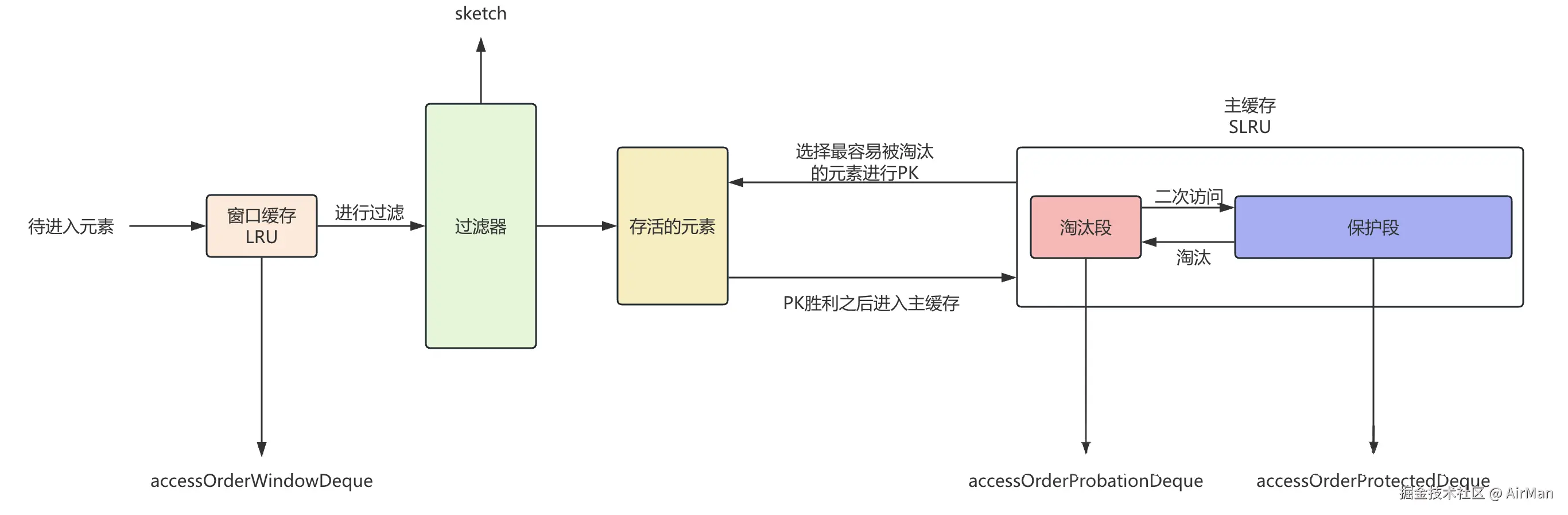
那放到我们这个算法设计中,从主缓存中基于SLRU驱逐出来的元素会和窗口缓存中驱逐出来的元素在过滤器中进行PK,选择出访问频率最高的元素重新加入到主内存的淘汰段中,继续走SLRU的那一套逻辑。
为什么 W-TinyLFU 这么强?
如果只用一句话概括:它用很小的空间,把"短期热点"和"长期热点"同时照顾到了,还能抵御一次性流量冲击,并且命中率接近理论最优。
它将短期适应性与长期记忆有机结合:新数据先进入短期的 Window Cache 快速响应突发热点,再通过 TinyLFU 的频率统计和 SLRU 的两段淘汰机制,保证访问频率高的稳定热点长期留存。这种设计能有效抵御一次性流量冲击,避免真实热点被误淘汰,同时在多变的访问模式下保持高命中率。
同时,W-TinyLFU 的 Count-Min Sketch 频率统计占用极小内存,更新开销 O(1),并通过衰减机制保持统计结果的新鲜度,实现了空间利用率和淘汰决策效率的双优。实测表明,无论是 Zipf 分布、混合负载还是突发流量场景,它的命中率都显著优于传统 LRU 和 LFU,并且稳定性极高,非常适合现代高并发业务环境。
- 短期适应性:Window Cache 提供新数据的短期缓冲。
- 长期记忆:Count-Min Sketch 保存访问频率。
- 抗一次性流量冲击:SLRU 分段保护真正热点。
- 空间利用率高:频率统计和衰减机制保持信息新鲜。
Caffeine 在各种实测负载(如 Zipf 分布、社交网络访问模式)下,命中率比传统 LRU 高出 10%~20%。
总结
Caffeine 的 W-TinyLFU 淘汰策略是多个经典思想的组合:
- Window 缓存(快速响应短期热点)
- TinyLFU(概率性频率统计)
- SLRU(分段保护长期热点)
- 衰减机制(保证新热点能上位)
这种设计既保留了 高命中率 ,又保证了 内存利用效率,也致使它会成为 Spring Boot 默认缓存实现