ElasticSearch
- 基本概念
- ElasticSearch安装
- 管理工具
- LogStash安装
- ik中文分词器
- 索引组成
- 配置文件
- [RESTFul API(常用)](#RESTFul API(常用))
- 创建基本索引PUT
- 创建完整索引PUT
- 索引别名POST
- 删除索引DELETE
- 新增字段PUT/POST
- 插入或更新文档PUT
- 插入文档POST
- 更新文档POST
- 删除文档DELETE
- 删除文档中的字段POST
- 查询文档GET (根据ID)
- 批量查询POST/GET
- 批量设置字段默认值POST
- 数据迁移POST
- 分词器测试GET
- [系统信息查询GET _cat](#系统信息查询GET _cat)
- 索引变更
- 安全相关
基本概念
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
ElasticSearch是一个高可扩、开源的全文检索和分析引擎,可以很方便的扩展到数百台分布式节点,能够实时的在线扩容,基于此来实现精准、实时地快速存储、搜索、分析海量的结构化或非结构化数据。
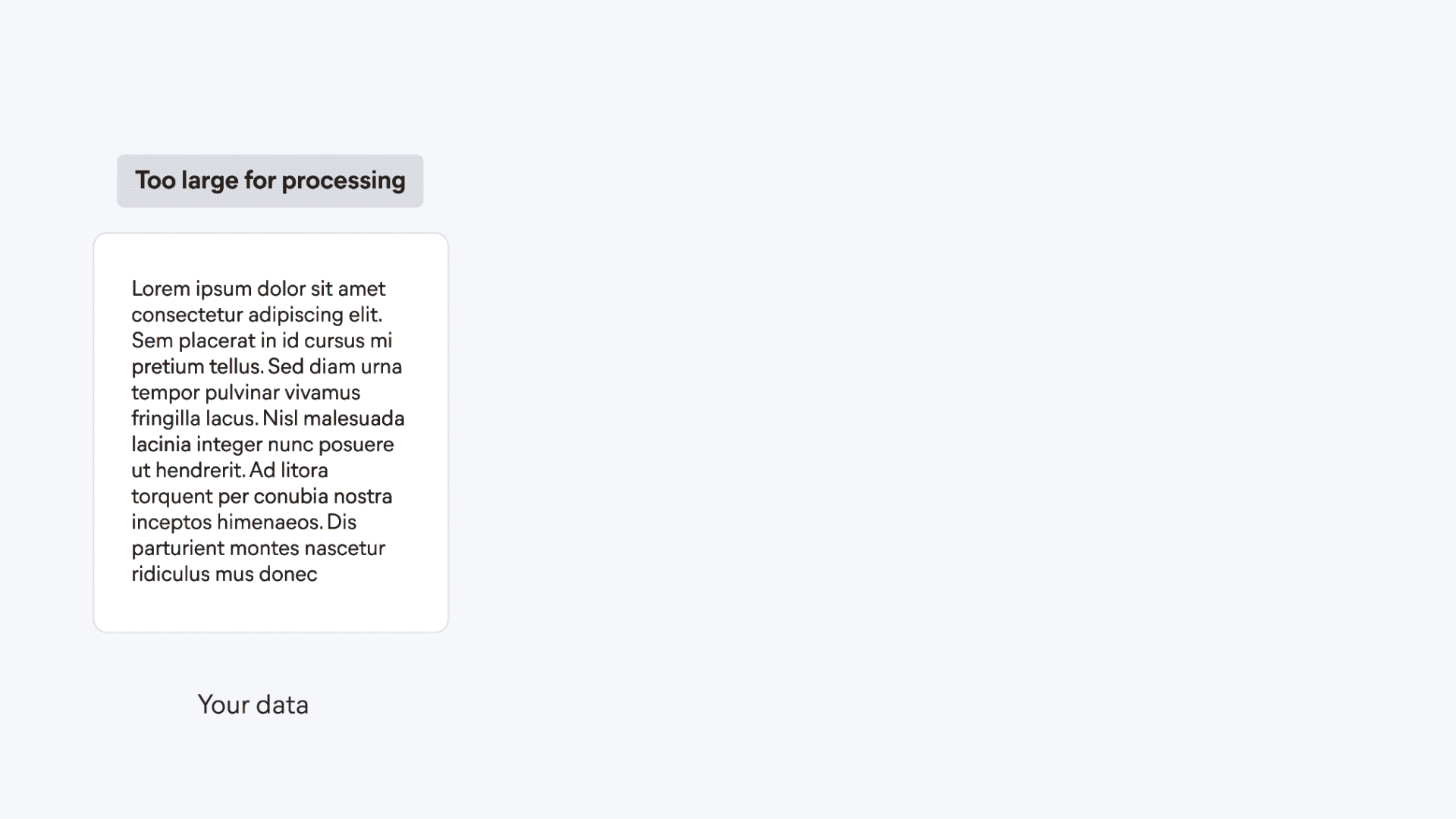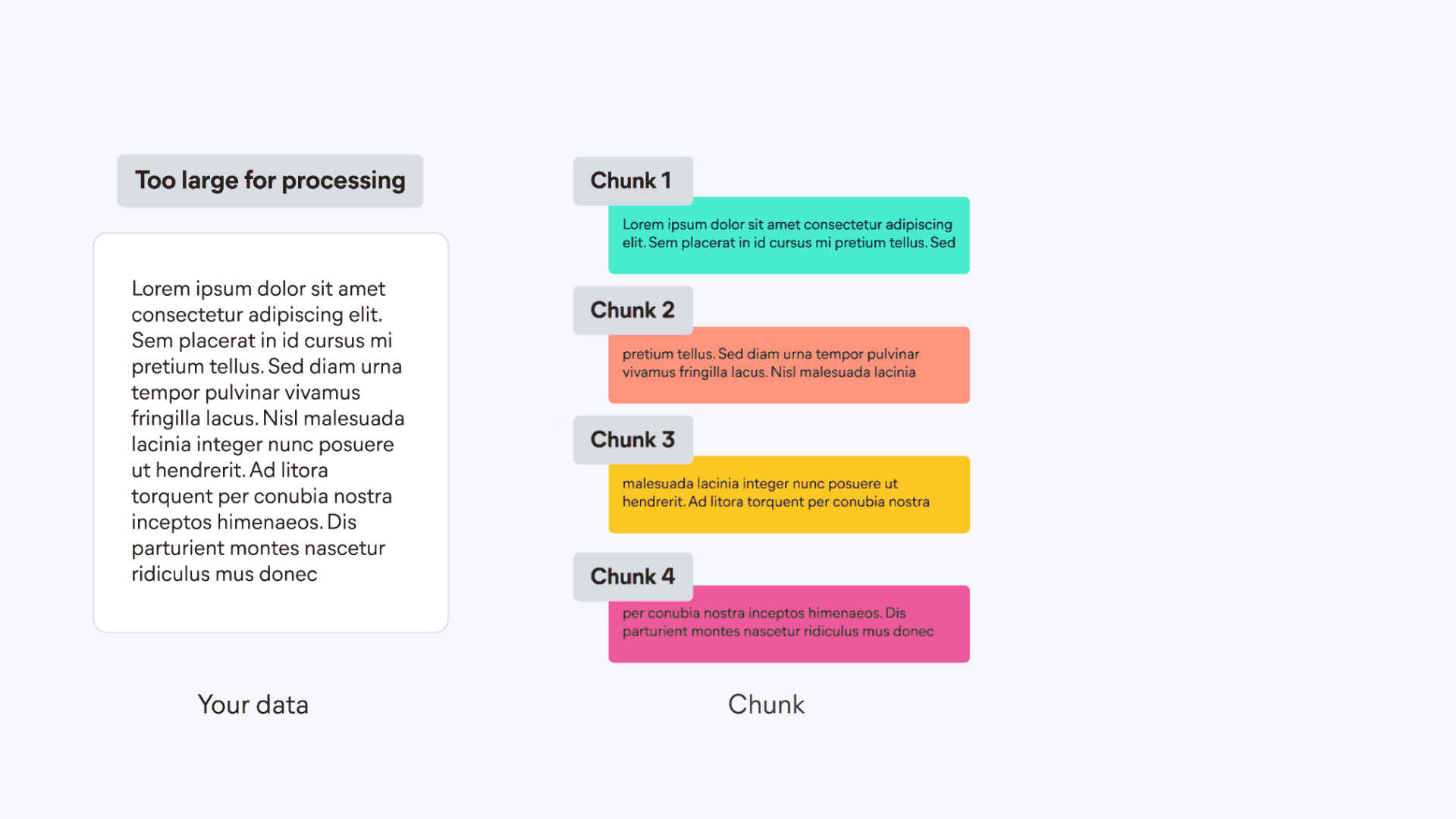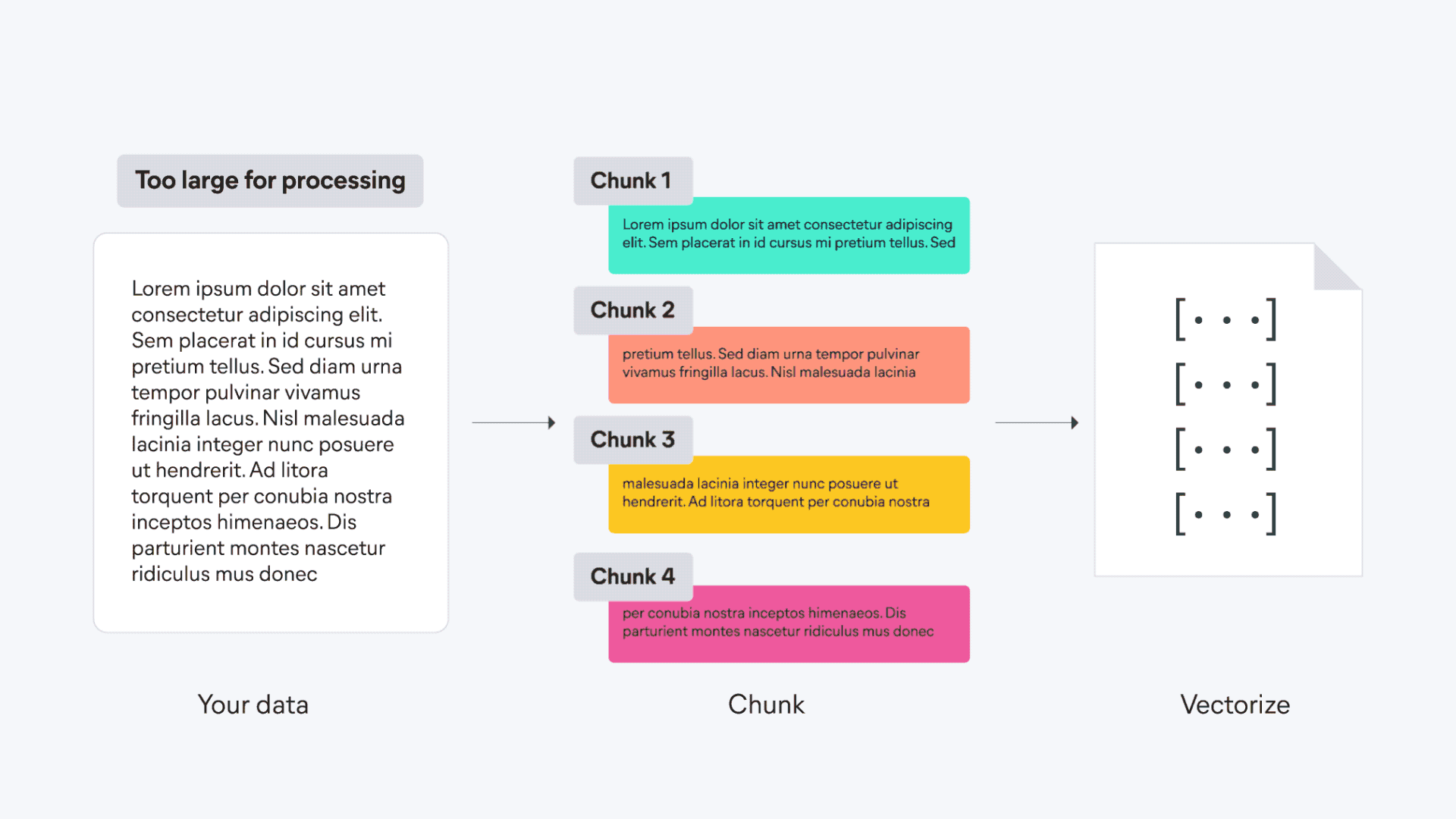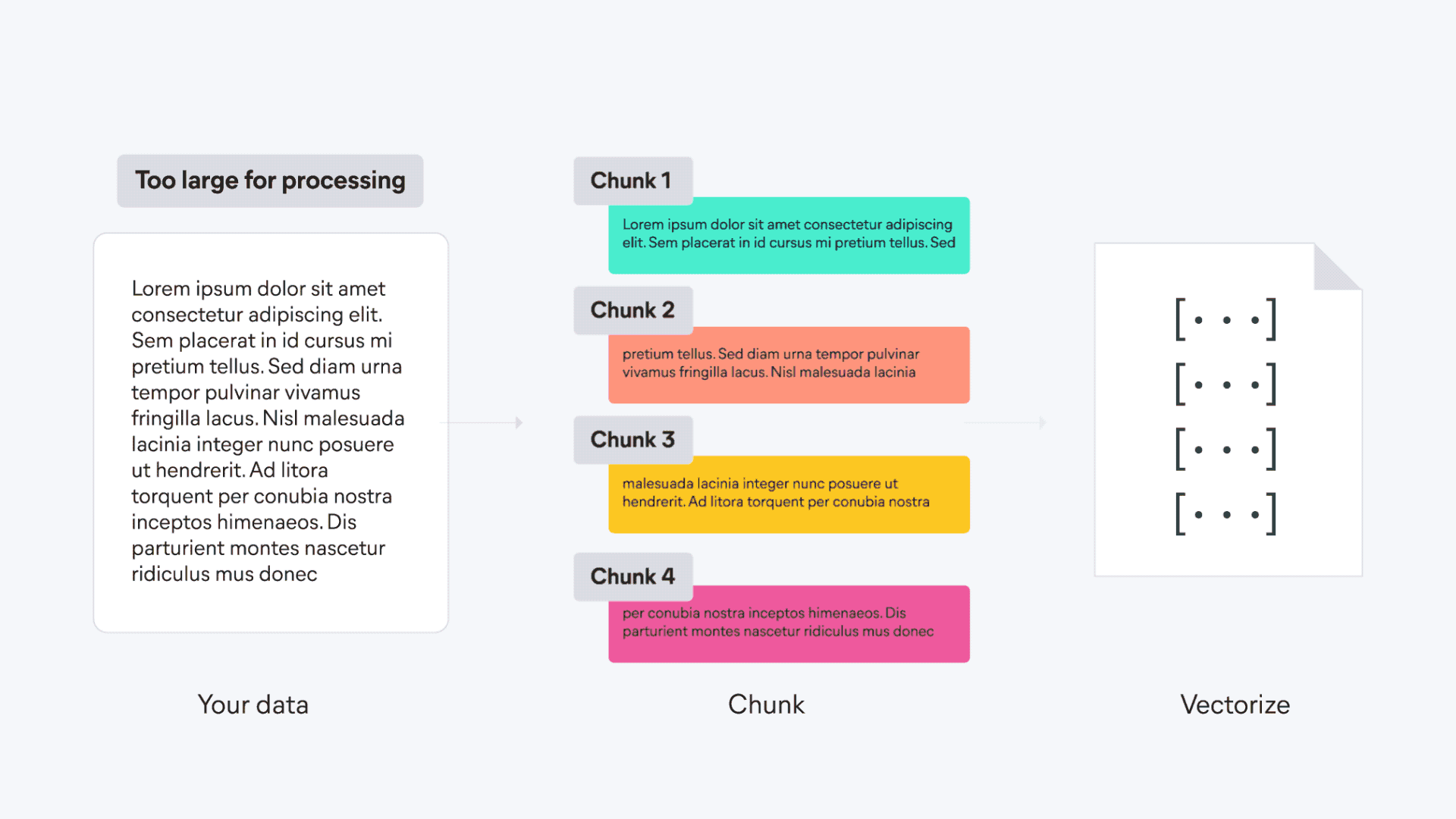
基本构成
| 构成单元 | 说明 |
|---|---|
| index索引 | 传统数据库的database的概念 |
| type | 传统数据库table的概念 6.x到7.x开始准备移除type, 为了兼容,include_type_name=false表示无需显示定义type include_type_name=true表示仍可以定义type,6.x到7.x 默认true 8.0将移除彻底type,默认include_type_name=false |
| docment | 对应传统数据库的row,数据行概念,最小数据单元 |
| filed | 字段 |
ElasticSearch是面向文档的数据库,它可以由多个index(库)构成,每个index包含不同的type(表)的document(数据行),每个document里有着自己的filed,但在7.0以后,取消了type的概念,index更像是一个表,而没有分库的概念了。
字段类型
通常在创建索引的时候,可以指定mapping映射,来定义字段名和类型等参数,常用字段类型如下,5.x开始,string已经取消,由text和keyword替代。
| 类型 | 说明 |
|---|---|
| text | 默认分词,文本,除此类型外,其他默认不分词做原值索引 |
| keyword | 默认不分词,原值做索引,文本 |
| date | 日期时间 |
| integer | 整数,32位 |
| long | 长整数,64位 |
| short | 短整数,16位 |
| double | 双精度,64位 |
| float | 单精度,32位 |
| scaled_float | 缩放因子的float,默认scaling_factor=100,比如33.12,内部存储为3312 |
| xxx_range | 范围值,插入时gte代表起始值,lte代表终止值 支持date_range、integer_range、short_range、double_range、long_range |
| date_nanos | 纳秒 |
| boolean | 布尔 |
| ip | IP |
集群结构
ES是内置分布式存储,创建索引就必须指定主分片和副本分片数量,它将index里的数据划分到不同的分片进行存储,一个document只可能存储在一个分片中,增加/删除节点时,分片会自行调整到可用的节点存储。
ES默认有5个primary shard主分片(ES7.0后默认1个),每个主分片都默认有1个replica shard副本分片,负责对主分片容错和承担读请求负载,也就是默认至少5个主分片+5个副本分片,共10个分片分散在不同的数据节点上。
-
一个主分片对应的副本分片,不会存储在相同的数据节点上,避免节点宕机后主、副分片都不可用;
-
副本分片,可以实时的动态调整数量,便于应对突然增加的读请求;
-
在6.x之前,primary shard主分片数量初始化后不可以改变,因为在较早版本中,document在插入数据后生成分片规则标识,便固定一成不变;
-
6.1开始后,ES支持在线变更主分片大小,动态扩容,主分片扩容数量按5的倍数设置,操作期间需要锁住所有index的写入;
-
每个分片的大小,一般控制在30G左右,容量越大,效率越低,实践中要尽量可能的分散数据。
倒排索引
全文检索通常是从数据内容冲提取出大量的关键字词,搜索的时候,对搜索关键字进行分词,再去匹配各个数据内容提取出来的关键字词。最终查询到与关键词相关性较高的文档,倒排索引能够更加高效的查询。
假设有2篇文档,ID分别是1和2
文档ID-1,内容:我是大玩家,爱玩大作
文档ID-2,内容:我爱技术,能持续学习技术
先以正向索引的结构为例:
| 文档ID | 提取词1 | 提取词2 | 提取词3 | 提取词n... |
|---|---|---|---|---|
| 1 | 玩(2) | 玩家 | 爱 | ... |
| 2 | 技术(2) | 持续 | 爱 | ... |
正向索引,需要遍历所有文档提取词,进行匹配查询,如果数据量大,这样的查询技术无法满足基本的功能需求,尤其是目前数据量庞大的时代。
而倒排索引的结构如下:
| 提取词 | 文档 |
|---|---|
| 技术 | 文档ID-2(2) |
| 玩家 | 文档ID-2 |
| 爱 | 文档ID-1,文档ID-2 |
| 玩 | 文档ID-2(2) |
| ... | ... |
倒排索引也就是,搜索输入的关键字,去匹配索引的提取词,再查找相应文档,基本的原理是简单的,但实际中往往还要考虑更复杂的,如关键词命中次数,次数多,加权还是不加,加多少,等等问题。
ElasticSearch安装
ElasticSearch依赖JVM运行环境,需要预先配置Java相关环境变量,Logstash也需要JVM环境。
bash
#安装JVM和java开发工具
yum install -y java-1.8.0-openjdk-devel.x86_64
#编辑环境变量
vim /etc/profile
#底部追加内容
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.292.b10-0.el8_3.x86_64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
#使环境变量生效
source /etc/profile
gz包下载完成后,解压文件
bash
#当前目录为/usr/local
tar -zxvf elasticsearch-6.8.13-linux-x86_64.tar.gz
mv elasticsearch-6.8.13-linux-x86_64 elasticsearch
#添加非root用户并授权
groupadd es
useradd es -g es -p password
chown -R es:es elasticsearch 根目录主要文件
| 文件 | 说明 |
|---|---|
| bin/elasticsearch | 实例启动 |
| bin/elasticsearch-setup-passwords | 账号密码工具 |
| bin/elasticsearch-plugin | 插件工具 |
| config/elasticsearch.yml | 实例节点配置文件 |
| config/jvm.options | jvm配置文件 |
| config/log4j2.properties | 日志配置 |
| plugins | 插件目录 |
启动一个实例节点,默认配置为9200端口
bash
cd /usr/local/elasticsearch/bin
#切换用户
su es
#-d 后台运行
./elasticsearch -d 启动完成后,wget http://localhost:9200 获得基本节点信息
bash
{
"name" : "sSyEHNl",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "iFSrT3UgRp-cdoKmPx3r9w",
"version" : {
"number" : "6.8.13",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "be13c69",
"build_date" : "2020-10-16T09:09:46.555371Z",
"build_snapshot" : false,
"lucene_version" : "7.7.3",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
} 在linux下定义服务并开机启动
chkconfig方式(可service elasticsearch start/stop/restart维护)
bash
#添加非root用户并授权,已建立则忽略
groupadd es
useradd es -g es -p password
chown -R es:es /usr/local/elasticsearch
#root用户操作以下
#编辑并保存
vim /etc/init.d/elasticseach
#!/bin/sh
#chkconfig: 2345 10 90
#description: elasticsearch
#运行应用的用户
EXEC_USER=elasticsearch
#程序运行文件
EXEC_FILE=/usr/local/elasticsearch/bin/elasticsearch
#运行参数
EXEC_OPTS="-d"
start() {
echo "$EXEC_FILE starting ...... "
#chkconfig方式,切换用户
su - $EXEC_USER -c "$EXEC_FILE $EXEC_OPTS"
exr=$?
if [ $exr -ne 0 ]; then
echo "start error"
else
echo "started"
fi
}
stop() {
echo "stopping $EXEC_FILE ..."
kill -15 `ps -ef|grep $EXEC_FILE|grep -v grep|grep -v stop|awk '{print $2}'`
exr1=$?
if [ $exr1 -ne 0 ]; then
echo "stop error......"
fi
else
echo "stopped"
fi
}
case "$1" in
start)
start
;;
stop)
stop
sleep 6
;;
restart)
stop
sleep 6
start
;;
*)
echo "Userage: $0 {start|stop|restart}"
exit 1
esac
#编辑完成后,赋予权限
chmod +x /etc/init.d/elasticsearch
#增加开机自启(可service elasticsearch start/stop/restart维护)
chkconfig --add elasticsearch
chkconfig elasticsearch on systemd方式(可systemctl start/stop/restart elasticsearch维护)
bash
#在elasticsearch根目录建立新脚本,与syschkconfig方式的脚本一致
vim /usr/local/elasticsearch/manager.sh
#将su - $EXEC_USER -c "$EXEC_FILE $EXEC_OPTS" 这一行改为
$EXEC_FILE $EXEC_OPTS
#保存后赋权
chmod +x /usr/local/elasticsearch/manager.sh
#添加非root用户并授权,已建立则忽略
groupadd es
useradd es -g es -p password
chown -R es:es /usr/local/elasticsearch
#root用户操作以下
#编辑systemd服务配置
vim /lib/systemd/system/elasticsearch.service
#编辑保存以下内容
[Unit]
Description=elasticsearch
After=network.target
[Service]
Type=forking
User=es
Group=es
ExecStart=/usr/local/elasticsearch/manager.sh start
ExecReload=/usr/local/opt/elasticsearch/manager.sh restart
ExecStop=/usr/local/opt/elasticsearch/manager.sh stop
PrivateTmp=true
[Install]
WantedBy=multi-user.target
#保存编辑完成后,赋权
chmod +x /lib/systemd/system/elasticsearch.service
#设置开机启动(可systemctl start/stop/restart elasticsearch维护)
systemctl enable elasticsearch管理工具
elasticsearch-head通常用来建立索引、查看数据概览,以及数据原始数据等基本操作;
kibana通常用来开发测试、运维监控、复杂查询等工作,它们都是基于NodeJS的应用。
NodeJS安装
无论是ES-HEAD或是Kibana,都需要NodeJS运行环境,安装NodeJS:
NoedJS下载
二进制包下载完成,解压安装
bash
#当前目录为/usr/local
#解压包
tar -xvf node-v10.6.0-linux-x64.tar.xz
#重命名文件
mv node-v10.6.0-linux-x64 nodejs10.6.0
cd nodejs10.6.0
#建立全局路径
mkdir node_global
mkdir node_cache
#设置环境变量
vi /etc/profile
#添加
export NODE_HOME=/usr/local/nodejs10.6.0
export PATH=$PATH:$NODE_HOME/bin
export NODE_PATH=$NODE_HOME/lib/node_modules
export PATH=$PATH:$NODE_HOME/node_global
#保存
:wq
source /etc/profile
#配置全局路径和阿里npm镜像
npm config set prefix "/usr/local/nodejs10.6.0/node_global"
npm config set cache "/usr/local/nodejs10.6.0/node_cache"
npm config set registry https://registry.npm.taobao.org
#安装cnpm,与npm用法一致
npm install -g cnpm --registry=https://registry.npm.taobao.orgelasticsearch-head
传统数据库一般都有客户端工具,如MySQL的sqlyog,ElasticSearch我们通常使用elasticsearch-head进行基本的管理,而具体命令执行则可以在Kibana操作。
下载完成后,在elasticsearch-head根目录执行
bash
cd /usr/local/elasticsearch-head-master
#安装ES-HEAD 所需模块
cnpm install 等待所需模块安装完成后
bash
#启动ES-HEAD
npm run start 浏览器访问http://ip:9100 ,填写相应的服务节点地址,即可对ElasticSearch进行基本的管理维护。
elasticsearch-head一般用于数据概览、建立索引等基本操作,也可以停止服务节点等操作。
kibana
Kibana是一个提供开发工具、图表视图、在线查询等综合性的工具,开箱即用。通常开发中更多使用Kibana辅助开发,elasticsearch-head仅作为基本的建库和数据概览。
Kibana下载
gz包下载完成后,解压文件
bash
#当前目录为/usr/local
tar -zxvf kibana-6.8.13-linux-x86_64.tar.gz
mv kibana-6.8.13-linux-x86_64 kibana 配置文件为 kibana根目录/config/kibana.yml
启动kibana,默认kibana的端口是5601,elastic search地址是localhost:9200
bash
cd /user/local/kibana/bin
./kibana 启动完成后,访问http://ip:5602 可以看到查询辅助、可视化、开发帮助等工具
定义系统服务,设置开机启动
chkconfig方式(可service kibana start/restart/stop管理)
bash
#定义非root用户并赋予权限
groupadd kibana
useradd kibana -g kibana -p password
chown -R kibana:kibana /usr/local/kibana
#root用户进行以下操作
#新建服务脚本
vim /etc/init.d/kibana
#内容编辑如下
#!/bin/sh
# chkconfig: 2345 10 90
EXEC_FILE=/usr/local/kibana/bin/kibana
#kibana配置参数pid.file指定
EXEC_PID=/usr/local/kibana/pid
EXEC_USER=kibana
start() {
echo "$EXEC_FILE starting ...... "
#chkconfig方式,切换用户
su - $EXEC_USER -c "$EXEC_FILE &"
exr=$?
if [ $exr -ne 0 ]; then
echo "start error"
else
echo "started"
fi
}
stop() {
echo "stopping $EXEC_FILE ..."
kill -15 `ps -ef|grep $EXEC_FILE|grep -v grep|grep -v stop|awk '{print $2}'`
exr1=$?
if [ $exr1 -ne 0 ]; then
echo "stop error, retry......"
kill -15 `cat $EXEC_PID`
exr2=$?
if [ $exr2 -ne 0 ]; then
echo "stop error"
else
echo "stopped"
fi
else
echo "stopped"
fi
}
case "$1" in
start)
start
;;
stop)
stop
sleep 6
;;
restart)
stop
sleep 6
start
;;
*)
echo "Userage: $0 {start|stop|restart}"
exit 1
esac
#编辑完成后,赋予权限并启用
chmod +x /etc/init.d/kibana
chkconfig --add kibana
chkconfig kibana on systemd方式(可systemctl start/restart/stop kibana)
bash
#root 用户操作以下
#新建应用管理脚本
vim /usr/local/kibana/kibana.sh
#内容与chkconfig方式脚本一致,将 su - $EXEC_USER -c "$EXEC_FILE $EXEC_OPTS"改为以下:
$EXEC_FILE &
#赋予权限
chmod +x /usr/local/kibana/kibana.sh
#新建systemd服务脚本
vim /lib/systemd/system/kibana.service
#内容如下:
[Unit]
#服务描述
Description=kibana server
#在什么服务之后启动
After=network.target
[Service]
#后台运行的形式
Type=forking
#服务运行的用户
User=kibana
#服务运行的用户组
Group=kibana
#启动脚本
ExecStart=/usr/local/kibana/kibana.sh start
#重启脚本
ExecReload=/usr/local/kibana/kibana.sh restart
#停止脚本
ExecStop=/usr/local/kibana/kibana.sh stop
#分配独立的临时空间
PrivateTmp=true
[Install]
WantedBy=multi-user.target
#保存编辑后,赋予权限
chmod +x /lib/systemd/system/kibana.service
#定义非root用户并赋予目录权限
groupadd kibana
useradd kibana -g kibana -p password
chown -R kibana:kibana /usr/local/kibana
#启用服务并开机启动(可systemctl start/restart/stop kibana管理)
systemctl enable kibanaLogStash安装
LogStash一般用于接收外部日志导入ElasticSearch。
bash
#当前目录为/usr/local
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.8.13.tar.gz
tar -zxvf logstash-6.8.13.tar.gz
mv logstash-6.8.13 logstash 在/usr/local/logstash下新建规则配置文件logstash.conf
lua
input {
tcp {
host => "0.0.0.0"
port => 4560
mode => "server"
codec => json_lines
}
}
filter {
mutate {
lowercase => [ "springAppName" ]
remove_field => ["port","logOutputLogstashHost", "logOutputLogstashPort","logOutputLevel"]
}
}
output {
stdout { codec => rubydebug }
elasticsearch {
hosts => "172.24.122.2:9200"
index => "dd-%{springAppName}-%{+YYYY.MM}"
}
} 在/usr/local/logstash/conf/logstash.yml 下新增以下配置
properties
# 受理线程数
pipeline.workers: 1
# 实际输出数据时线程数, 小于受理线程数
pipeline.output.workers: 1
# 每批处理多少条数据
pipeline.batch.size: 1000
# 延时多少秒处理
pipeline.batch.delay: 10 手动启动logstash
bash
#切换logstash用户
su logstash
# 以自定义规则配置启动
/usr/local/logstah/bin/logstah -f /usr/local/logstash/cfg/logstash.conf 定制系统服务并自启动
bash
#添加非root用户
groupadd logstash
useradd logstash -g logstash -M -s /sbin/nologin
#建立日志目录
mkdir /var/log/logstash/
chown -R logstash:logstash /var/log/logstash/
chown -R logstash:logstash /usr/local/logstash/ 编辑 服务初始化配置 vim /usr/local/logstash/startup.options
sh
# Override Java location
#JAVACMD=/usr/bin/java
# logstash根目录
LS_HOME=/usr/local/logstash
# logstash主配置目录
LS_SETTINGS_DIR=/usr/local/logstash/config
# 启动参数 -f 自定义规则配置文件
LS_OPTS="--path.settings ${LS_SETTINGS_DIR} -f /usr/local/logstash/cfg/logback_to_logstash.conf"
# Arguments to pass to java
LS_JAVA_OPTS=""
# pidfiles aren't used the same way for upstart and systemd; this is for sysv users.
LS_PIDFILE=/var/run/logstash.pid
# 用户名和组
LS_USER=logstash
LS_GROUP=logstash
# Enable GC logging by uncommenting the appropriate lines in the GC logging
# section in jvm.options
LS_GC_LOG_FILE=/var/log/logstash/gc.log
# Open file limit
LS_OPEN_FILES=16384
# Nice level
LS_NICE=19
# 服务名和服务描述
SERVICE_NAME="logstash"
SERVICE_DESCRIPTION="logstash"
# If you need to run a command or script before launching Logstash, put it
# between the lines beginning with `read` and `EOM`, and uncomment those lines.
###
## read -r -d '' PRESTART << EOM
## EOM 设置服务脚本权限并添加开机自启动
bash
#生成系统服务
/usr/local/logstash/bin/system-install /usr/local/logstash/config/startup.options
#设置开机启动服务
systemctl enable logstashik中文分词器
由于ElasticSearch默认的分词器,对中文分词不太理想,原因是没有完善的中文词库,很容易将中文的正文提取出所有单个汉字作为提取词,ik中文分词器则弥补了这一不足,并且支持词库扩展,实践中往往基于ik+行业词库来支撑ES分词。
ik分词模式
两种分词器使用的最佳实践是,生成索引时用ik_max_word,查询搜索时用ik_smart
ik_max_word
它将按最细颗粒度提取,比如会将"中华人民共和国人民大会堂"拆分为"中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等。
ik_smart
它会按最粗的颗粒度提取,比如会将"中华人民共和国人民大会堂"拆分为中华人民共和国、人民大会堂。
安装ik插件
ik中文分词器下载 版本必须与ElasticSearch版本对应。
安装方式一,对应版本的zip包下载完成后
bash
cd /usr/local/elasticsearch/plugins
#插件存放的目录
mkdir analysis-ik
cd analysis-ik
mv /user/local/elasticsearch-analysis-ik-6.8.13.zip /usr/local/elasticsearch/plugin/ik/
#解压插件
unzip elasticsearch-analysis-ik-6.8.13.zip
#将zip包内的词库文,存到es的config下,名称与插件目录下的ik插件目录名一致。
mkdir /usr/local/elasticsearch/config/analysis-ik
mv config/* /usr/local/elasticsearch/config/analysis-ik/
安装方式二,插件工具安装
bash
cd /usr/local/elasticsearch/bin
#使用elasticsearch-plugin插件工具安装
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.8.13/elasticsearch-analysis-ik-6.8.13.zip
#开始下载插件
-> Downloading https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.8.13/elasticsearch-analysis-ik-6.8.13.zip
[=================================================] 100%
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.net.SocketPermission * connect,resolve
See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
#输入y同意即可
Continue with installation? [y/N]y
-> Installed analysis-ik
两种方式,都需重新启动服务节点后,插件才能加载完成, 关闭当前ES服务节点可以通过 kill 进程,也可以通过elasticsearch-head关闭服务。
ik分词测试
浏览器访问kibana,选择dev tools,使用ik_max_word这个分词模式进行测试,输入以下命令
bash
# _analyze是ES的分词API
GET _analyze//kibana dev tools将转成 get请求http://esIP:port/_analyze
{
#analyzer指分词器,"ik_max_word"是插件ik提供的分词器
"analyzer": "ik_max_word",
"text": "长铗归来乎"
} 执行命令,因为是ik_max_word这个分词模式,分词颗粒度比较细,响应结果如下:
json
{
"tokens" : [
{
"token" : "长",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "铗",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "归来",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "乎",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
}
]
} 根据此结果可以得出,"长铗 "这个词并没有在词库中,而"归来 "是在ik内置中文词库,所以提取出了"归来 ",而未提取出"长铗"。
ik词库
扩展词典
安装ik插件后
/usr/local/elasticsearch/configf/analysis-ik
该目录下是ik插件的中文词库文件dic,将词库配置文件IKAnalyzer.cfg.xml的内容编辑修改,增加扩展词库名sine.dic,修改如下:
xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">sine.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties> 在词库配置文件的当前目录下新建分词词典sine.dic,编辑内容如下:
bash
我不是
你就是 重启服务节点后词库生效,当内容中有"xxxx我不是 xxx"的时候,将提取关键词"我不是",它被认为是一个完整的关键词。
扩展测试
浏览器访问kibana,选择dev tools,使用ik_smart这个分词模式进行测试,输入以下命令
bash
# _analyze是ES的分词API
GET _analyze //kibana dev tools将转成 get请求http://esIP:port/_analyze
{
#"analyzer" 指定分词器
"analyzer": "ik_smart",
"text": "我不是你"
} 因为是ik_smart 分词模式,颗粒度较粗,所以结果提取词少,并且因为扩展词库中有"我不是"这个词,所以分词器提取出了这个词。
json
{
"tokens" : [
{
"token" : "我不是",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "你",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 1
}
]
}索引组成
一个索引的主要组成如下所示:
json
{
"state":"open",//状态
"settings":{
"number_of_shards":5,//主分片数
"number_of_replicas":1,//副本分片数
"provided_name":"索引名",
"analysis":{//分词器定义
"analyzer" : {
"自定义分词器名":{
分词器定义规则
}
}
}
},
//映射,可理解为数据结构定义
"mappings":{
//type是将来要移除的,目前6.x~7.x是兼容模式
//include_type_name=false,创建索引时mapping可不定义type
//include_type_name=true,创建索引时mapping须显示定义type
"_doc":{
"字段名":{
"type":"字段类型",
"analyzer":"分词器名"
......
}
...
}
}
}配置文件
ES配置
在默认情况下,ElasticSearch根目录下的config,主要配置文件是elasticsearch.yml和jvm.options,JVM配置在jvm.options中,ES本身各属性的配置在elasticsearch.yml中。
JVM配置
jvm.options的主要配置:
bash
#最小堆
-Xms4g
#最大堆
-Xmx4g
#建议设置最小堆,最大堆一致
#目的是为了能够在GC回收进行标记清除后,不必重新分配堆大小,提高效率
#通常设为服务器的一半,留一半给系统和lucene消耗
#lucene的设计会消耗系统内存当作缓存
#即使服务器64g内存,也只需分配32G足够,剩下的内存也会被Lucene消耗当作缓存ES集群结构
bash
#集群名,如果有多个集群,用此区分,默认elasticsearch
cluster.name: elasticsearch
#主分片数,默认5,值为5的倍数
index.number_of_shards: 5
#每个主分片的从分片,默认1
index.number_of_replicas: 1
#恢复数据的线程数,默认4
cluster.routing.allocation.node_initial_primaries_recoveries: 4
#增加/删除节点的时候,恢复数据的线程数,默认2
cluster.routing.allocation.node_concurrent_recoveries: 2
#数据恢复时网络带宽限制,例如1000mb,0代表无限制
indices.recovery.max_size_per_sec: 0
#恢复数据的并发流限制,默认5
indices.recovery.concurrent_streams: 5
#集群的节点,可以知道其它多少个节点可以选master,默认1
#建议设为集群数/3
discovery.zen.minimum_master_nodes: 1
#组播发现其它集群节点的超时时间,默认3秒
discovery.zen.ping.timeout: 3s
#单播发现
#集群初始节点,port为tcp通讯端口,非http
#一般固定几个master节点,在此配置就可
discovery.zen.ping.unicast.hosts: ["host1:port", "host2:port", "host3:port"]
#组播发现,5.0以前
#组播地址
#discovery.zen.ping.multicast.group: 224.2.2.4
#组播端口 UDP
#discovery.zen.ping.multicast.port: 54328
#开启组播
#discovery.zen.ping.multicast.enabled: true
#绑定地址,null代表绑定所有可用的网络接口
#discovery.zen.ping.multicast.address: nullES节点属性
bash
#节点名称,如果不指定,默认随机指定一个name列表中名字
#该列表在es的jar包中config文件夹里name.txt文件中
node.name: node9200
#该节点是否有资格选举为master,默认true
node.master: true
#该节点是否存储数据,默认true
node.data: true
#节点的绑定ip和 其它节点访问的ip,也可以分开配置
#network.bind_host 节点绑定IP
#network.publish_host 其它节点与当前节点交互的IP
network.host: 127.0.0.1
#节点之间tcp通讯的端口
transport.tcp.port: 9300
#节点之间tcp传输时,是否压缩数据,默认false
transport.tcp.compress: true
#ES节点对外的HTTP服务端口
http.port: 9200
#http响应内容最大容量
http.max_content_length: 100mb
#是否开启http服务,默认true
http.enabled: true
#开启跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
#es配置文件路径,默认是es根目录下的config文件夹
path.conf: /xxx/conf
#当前节点的数据存储路径,默认是es根目录下的data
path.data: /xxx/data
#临时文件路径,默认es根目录下的work
path.work: /xxx/work
#日志文件路径,默认es根目录下的logs
path.logs: /xxx/logs
#插件路径,默认es根目录下的plugins
path.plugins: /xxx/plugins
#锁住内存,建议true
#当物理内存不够用时,JVM会进行SWAP(磁盘部分空间当内存)
#即使操作系统关闭SWAP,但JVM启动时有一个过程到达指定的内存大小,还是true
bootstrap.memory_lock: trueES数据与恢复策略
所有可以被选举为master的节点,必须配置以下参数
bash
#文件系统默认local,本地模式,可选HDFS
#HDSF配置
#gateway.type: hdfs
#gateway.hdfs.url: hdfs://ip:9000
gateway.type: local
#集群中的运行的节点(master+data)数达到这个参数,可以立即恢复数据
#建议一半以上
gateway.expected_nodes: 0
#集群中的主节点已经运行了多少个,可以立即恢复数据
#建议master节点数一半以上
gateway.expected_master_nodes: 0
#集群中的data数据节点已经运行了多少个,可以立即恢复数据
#建议data数据节点数一半以上
gateway.expected_data_nodes: 0
#数据恢复的超时时间,指的是上述expected节点数量,在这个时间范围内没达到要求的数量
#则按以下recover_after定义的节点数,如果满足数量则进行数据恢复
#默认5分钟
gateway.recover_after_time: 5m
#上述数据恢复超时后,若运行的节点(master+node)数达到此参数,则进行数据恢复
#建议最小3,master+node最小数量(低于3无法选举)
gateway.recover_after_nodes: 3
#上述数据恢复超时后,若运行的master数量达到此参数,则进行数据恢复
#建议最小1,按最小集群的情况
gateway.recover_after_master_nodes: 1
#上述数据恢复超时后,若运行的data数据节点数量达到此参数,则进行数据恢复
#建议最小2,按最小集群的情况
gateway.recover_after_data_nodes: 2ES安全配置
bash
#开启SSL
xpack.security.enabled: true
xpack.security.http.ssl.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
#方式一, PEM格式指定服务节点证书,服务节点密钥, CA中心证书
#https
xpack.security.http.ssl.key: /xxx/node.key
xpack.security.http.ssl.certificate: /xxx/node.crt
xpack.security.http.ssl.certificate_authorities: /etc/elasticsearch/new_certs/ca.crt
#节点之间通信
xpack.security.transport.ssl.key: /xxx/node.key
xpack.security.transport.ssl.certificate: /xxx/node.crt
xpack.security.transport.ssl.certificate_authorities: certs/ca.crt
#方式二,p12格式(包含所有证书 密钥信息),推荐
#https
xpack.security.http.ssl.keystore.path: /xxx/elastic-certificates.p12
xpack.security.http.ssl.truststore.path: /xxx/elastic-certificates.p12
#节点间通信
xpack.security.transport.ssl.keystore.path: /xxx/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /xxx/elastic-certificates.p12Kibana配置
kibana服务配置
bash
#http服务端口
server.port: 5601
#主机地址
server.host: 0.0.0.0
#hostName
server.name: "kibana"
#服务pid号写的文件
pid.file: /usr/local/kibana/kibana5601.pid
#国际化,默认"en"
i18n.locale: "zh-CN"
#开启kibana对外ssl服务
server.ssl.enabled: true
#可用es/bin/elasticsearch-certgen 输入详细信息 生成
#或者es/bin/elasticsearch-certutil直接生成证书
#PEM证书
server.ssl.certificate: /xxx/server.crt
#证书密钥
server.ssl.key: /xxx/server.key
#认证中心 CA
server.ssl.certificateAuthorities: /xxx/ca.crtkibana-es相关配置
bash
# 指定es节点
elasticsearch.hosts: ["http://ip1:port", "http://ip2:port"]
#kibana自身保存的搜索和可视化相关数据
#对应es中的索引,若不存在则新建,默认.kibana
kibana.index: ".kibana"
#kibana初始加载的默认模块
kibana.defaultAppId: "home"
#kibana访问es的账号密码,若es设置了账号密码
elasticsearch.username: "kibana_system"
elasticsearch.password: "password"
#kibana ssl连接es, es节点host改为https
elasticsearch.ssl.verificationMode: certificate
#CA认证中心证书 .crt/.pem
elasticsearch.ssl.certificateAuthorities: /xxx/ca.pemRESTFul API(常用)
以下都是使用kibana dev tools测试
以下都是使用kibana dev tools测试
以下都是使用kibana dev tools测试
使用postman或者curl,需要完整的 method http://ip:port/api
创建基本索引PUT
PUT /新建索引名
创建索引时若定义mapping映射规则,插入第一条文档的时候ES会自行产生mapping结构。
bash
PUT /索引名
{
"settings":{
#主分片数,默认5(7以后默认1)
"number_of_shards":5,
#副本分片,默认1(每个主分片对应1个副本分片)
"number_of_replicas":1,
}
}创建完整索引PUT
PUT /新建索引名
创建自定义分词器+mapping映射的索引,定义mapping的时候,若url带参数include_type_name=false,表示无需显示定义type(默认"_doc")。
6.x到7.x,默认include_type_name=true,mapping时仍需定义type。
8.0开始默认include_type_name=false,mapping时无需定义type。
bash
PUT /索引名
{
"settings":{
#主分片数,默认5(7以后默认1)
"number_of_shards":5,
#副本分片,默认1(每个主分片对应1个副本分片)
"number_of_replicas":1,
#分词器
"analysis":{
"analyzer":{
#提取文档的分词器
"zh_cn_analyzer":{
"type":"custom",
#ik颗粒度最细的分词模式
"tokenizer":"ik_max_word",
#最大分词15个
"max_token_length":15,
#忽略大小写
"filter":["lowercase","stemmer","asciifolding"],
#过滤html
"char_filter":["html_strip"]
},
#查询关键字的分词器
"zh_cn_analyzer_query":{
"type":"custom",
#ik颗粒度最细的分词模式
"tokenizer":"ik_smart",
#最大分词5个
"max_token_length":5,
#忽略大小写
"filter":["lowercase","stemmer","asciifolding"],
#过滤html
"char_filter":["html_strip"]
}
}
}
},
"mappings":{
#type类型,因请求未指定include_type_name=false表示无需定义type
#这里显示定义高版本兼容的默认值"_doc"
"_doc":{
"properties":{
"nickName":{
#text默认分词,keyword默认不分词
"type":"text",
#指定生成索引的分词
"analyzer":"zh_cn_analyzer",
#指定查询的分词
"search_analyzer":"zh_cn_analyzer_query",
#越大权值越高
"boost":100,
"fields":{
#内嵌字段keyword,存原值做索引
#超过50个字符就不做索引
"keyword":{
"type":"keyword",
"ignore_above":50
}
}
},
"speech":{
"type":"text",
#指定生成索引的分词
"analyzer":"zh_cn_analyzer",
#指定查询的分词
"search_analyzer":"zh_cn_analyzer_query",
"boost":200
},
"country":{
"type": "keyword",
#超过8个字符,就不做索引,只存储
"ignore_above":8
},
"job_exp":{
"type":"date_range",
"format":"yyyy-MM-dd",
#index analyzed text默认
#index not_analyzed 整个原始值放入索引中
#index no 不做索引,不被搜索
#6.x+ 值改为true或者false
"index":false
},
"money":{
"type":"double",
#作为关键词,等同于类型keyword
"index":true
},
"birthday":{
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss"
}
}
}
}
}索引别名POST
索引一定要建立别名,在实践中涉及到变更,通常通过数据迁移方式完成,只有事先定义别名,才能实现无缝迁移变更。通过索引别名的操作,与通过真实索引一致。
POST /_aliases
bash
POST /_aliases
{
"actions":
[
{
#给指定的索引设置别名
"add": {
"index": "真实索引名2",
"alias": "索引别名A"
},
#删除索引的别名
"add": {
"index": "真实索引名1",
"alias": "索引别名A"
}
},
{
#解除索引与别名关联
"remove": {
"index": "真实索引名3",
"alias": "索引别名A"
},
#解除索引与别名关联
"remove": {
"index": "真实索引名4",
"alias": "索引别名A"
}
}
]
}删除索引DELETE
DELETE /索引/类型/文档ID
bash
DELETE /idx1新增字段PUT/POST
PUT /POST /索引/_mapping?include_type_name=false
或者
PUT /POST /索引/_mapping/类型
bash
PUT /idx1/_mapping?include_type_name=false
{
"properties":{
"newField":{
"type":"text",
"index":false
}
}
}插入或更新文档PUT
PUT /索引/类型/文档ID
必须要指定ID,文档ID不存在则插入新文档,文档ID已存在则更新
bash
PUT /idx1/_doc/1
{
"nickName":"张三",
"speech":"我的演讲主题是,我有一个梦想",
"country":"中国",
"job_exp":{
"gte":"1949-10-01",
"lte":"2049-10-01"
},
"birthday":"2020-02-02 02:02:02",
"money":1622.22
}插入文档POST
POST /索引/类型/文档ID(可选)
指定文档ID时,文档ID存在则更新,不存在则新建文档;
文档ID未指定时,随机一个文档ID插入。
bash
#不指定ID,随机ID
POST /idx1/_doc
{
"nickName":"张三",
"speech":"我的演讲主题是,我有一个梦想",
"country":"中国",
"job_exp":{
"gte":"1949-10-01",
"lte":"2049-10-01"
},
"birthday":"2020-02-02 02:02:02",
"money":1622.22
}更新文档POST
POST /索引/类型/文档ID/_update
指定文档ID更新,提交到json,修改的属性必须在**"doc"**属性内
bash
POST /idx1/_doc/2/_update
{
"doc":{
"nickName":"小崽子",
"speech":"我的演讲主题是,我有一个梦想",
"country":"中国",
"job_exp":{
"gte":"1949-10-01",
"lte":"2049-10-01"
},
"birthday":"2020-02-02 02:02:02",
"money":1622.22
}
}删除文档DELETE
DELETE /索引/类型/文档ID
bash
DELETE /idx1/_doc/1删除文档中的字段POST
POST /索引/_update_by_query
只能删除文档数据中的字段,并不能删除索引本身mapping结构中定义的字段,需要删除mapping中的字段参考下文中的 索引变更
bash
POST /idx2/_update_by_query
{
"script" : "ctx._source.remove(\"字段名\")",
"query": {
"bool": {
"must": [
{
"exists": {
"field": "字段名"
}
}
]
}
}
}查询文档GET (根据ID)
GET /索引/类型/文档ID
bash
GET /idx1/_doc/1批量查询POST/GET
POST /GET /索引/类型/_search
类型可省略
bash
# 简单查询
POST /.idx/_search
{
# 查询条件
"query": {
# match用于分词搜索,term用于keyword字段精确搜索
"match": {
"字段名":"搜索关键字"
}
},
# 排序字段列表
"sort": [
{
"_id":{
"order": "desc"
},
"age":{
"order": "asc"
}
}
],
#分页参数
"from": 0,
"size": 20
}
# 复杂查询
POST /.idx/_search
{
# 查询条件
"query": {
#bool 多个条件查询
"bool":{
#must必须全部满足,should满足一个即可,must_no全部不满足
"must":[
{
"match": {
"字段名1":"搜索关键字1"
}
},
{
"match": {
"多值字段":"搜索关键字1 搜索关键字2 搜过关键字3..."
}
},
{
"term": {
"keyword字段":"精准匹配关键字"
}
}
],
#过滤数据范围
"filter":{
"range":{
"age":{
#age字段>3
"gt":3,
#age字段<50
"lt":50
}
}
}
}
},
#返回结果包含命中的高亮词
"highlight":{
#高亮词前缀标签
"pre_tags":"<h1>",
#高量词结束标签
"post_tags":"</h1>",
#高亮词的字段,包括搜索词和字段内容分词
"fields":{
"name":{}
}
},
# 排序字段列表
"sort": [
{
"_id":{
"order": "desc"
},
"age":{
"order": "asc"
}
}
],
#分页参数
"from": 0,
"size": 20
}批量设置字段默认值POST
POST /索引/_update_by_query
bash
POST /idx1/_update_by_query
{
"script":{
"lang":"painless",
"inline":"if(ctx._source.字段名 == null){ctx._source.字段名='0'}"
}
}数据迁移POST
POST _reindex
相同的字段名,源索引不会覆盖新索引mapping中对字段属性的定义
源索引中多出的字段,因document数据中含有字段,会自动在新索引mapping中定义字段
bash
POST _reindex
{
#源索引
"source": {
"index": "sourceIdx"
},
#目标索引
"dest": {
"index": "targetIdx"
}
}分词器测试GET
全局
bash
GET _analyze
{
#分词器
"analyzer": "ik_max_word",
#测试文本
"text": "长铗归来乎"
}索引内
bash
GET /索引名/_analyze
{
#索引内自定义的分词器
"analyzer": "zh_cn_analyzer",
#测试文本
"text": "长铗归来乎"
}系统信息查询GET _cat
bash
#查询所有master节点信息
GET /_cat/master?v
#查询各个索引的概要信息,单位kb,按文档数降序
GET _cat/indices?v&bytes=kb&s=docs.count:desc
#查询集群健康状态
GET _cat/health?v
#查询集群节点的服务器状态
GET _cat/nodes?v&h=ip,node.role,name,disk.avail,heap.percent,ram.percent,cpu
#查看每个数据节点上的分片数(shards),以及每个数据节点磁盘剩余
GET _cat/allocation?v
#查询整个集群文档数
GET _cat/count?v
#查询某个或某些索引文档数
GET _cat/count/索引名*?v
#查询某个或某些索引的分片
GET _cat/shards/索引名*?v索引变更
经验总结
由于倒排索引的特殊性制,对已有索引字段直接修改是无法直接完成的事情。对索引的mapping来讲,只能新增字段,无法修改/删除,对document文档数据来说,可以删除字段或者设定新字段的默认值,但无法改变索引的mapping。
无论是哪种变更的情况,一定会涉及到数据迁移,所以在实践中,务必使用索引的别名进行业务操作。
只有事先定义别名,才能实现无缝迁移变更。
通过索引别名的操作,与通过真实索引操作一致。
索引别名设置 数据迁移reindex 设置字段默认值 删除文档中的字段
新增/修改字段的变更可以利用数据迁移reindex + 设置字段默认值解决
删除的变更可以通过删除文档数据中的字段,再reindex 解决
建议处理过程
1.按修改/增加/删除后的mapping字段定义,建立 中间索引B,和新索引C
2.原索引A 数据迁移 reindex 到 中间索引B
3.reindex过程中,中间索引B中相同字段名的mapping属性不受影响,完成修改目的
4.中间索引B中新增的字段,也不受reindex影响,完成新增目的
5.将中间索引B中 文档数据对应需要删除的字段进行删除,再reindex数据迁移到 新索引C
6.因中间索引B中的文档数据已删除指定字段,reindex到新索引C不会新增字段定义,完成删除目的
7.再将源索引A的别名指向新索引C,同时将索引A与别名摘除,在线无缝变更完成。
测试演示
新建源索引 idx_a
bash
#参数include_type_name=false, mapping无需定义type,默认"_doc"
PUT /idx_a?include_type_name=false
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name":{
"type": "text"
},
"content":{
"type":"text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"birthday":{
"type": "date",
"format": "yyyy-MM-dd"
}
}
}
} 设置索引idx_a别名为.idx
bash
POST /_aliases
{
"actions": [
{
"add": {
"index": "idx_a",
"alias": ".idx"
}
}
]
} 根据别名插入3条文档数据
bash
POST /.idx/_doc/1
{
"name":"张三1",
"content":"我来了,我想说一句话",
"birthday":"2020-02-02"
} 查询别名索引.idx的数据
bash
POST /.idx/_search
{
"from": 0,
"size": 3
}
#响应结果:
...
{"name":"张三3", "content":"我来了,我想说一句话", "birthday":"2020-02-02"}
{"name":"张三2", "content":"我来了,我想说一句话", "birthday":"2020-02-02"}
{"name":"张三1", "content":"我来了,我想说一句话", "birthday":"2020-02-02"}
... 新建2个索引idx_b,idx_c。增加一个字段age,将原name字段类型改为keyword,删除birthday字段
bash
#PUT /idx_b... PUT /idx_c
PUT /idx_b?include_type_name=false
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name":{
"type": "keyword"
},
"content":{
"type":"text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"age":{
"type": "integer"
}
}
}
} 将源索引idx_a,数据迁移reinedx 到 中间索引idx_b
bash
POST /_reindex
{
"source": {
"index": "idx_a"
},
"dest": {
"index": "idx_b"
}
} 删除中间索引idx_b中文档数据的birthday字段
POST /idx2/_update_by_query
{
"script" : "ctx._source.remove(\"字段名\")",
"query": {
"bool": {
"must": [
{
"exists": {
"field": "字段名"
}
}
]
}
}
} 设置新增字段age的默认值为18
bash
POST /idx_b/_update_by_query
{
"script":{
"lang":"painless",
"inline":"if(ctx._source.age == null){ctx._source.age='18'}"
}
} 将idx_b reindex到 新索引 idx_c
bash
POST /_reindex
{
"source": {
"index": "idx_b"
},
"dest": {
"index": "idx_c"
}
} 删除中间索引idx_b,并操作索引别名.idx,关联idx_c,取消与源索引idx_a的关联
bash
#删除中间索引 idx_b
DELETE /idx_b
#.idx 索引别名, 添加idx_c, 删除idx_a
POST _aliases
{
"actions": [
{
"remove": {
"index": "idx_a",
"alias": ".idx"
}
},
{
"add": {
"index": "idx_c",
"alias": ".idx"
}
}
]
} 根据索引.idx 查询mapping结构,新增/删除/修改均已完成
bash
GET /.idx/_mapping
# 响应结果:真实索引为idx_c, 新增age、删除birthday、修改name都已完成。
{
"idx_c" : {
"mappings" : {
"_doc" : {
"properties" : {
"age" : {
"type" : "integer"
},
"content" : {
"type" : "text",
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"name" : {
"type" : "keyword"
}
}
}
}
}
} 查询别名.idx数据
bash
POST /.idx/_search
#响应结果
{"name":"张三3", "content":"我来了,我想说一句话", "age":"18"}
{"name":"张三2", "content":"我来了,我想说一句话", "age":"18"}
{"name":"张三1", "content":"我来了,我想说一句话", "age":"18"} 实践中这样做的好处是,既保留原有的数据,又完成了变更,也能够无缝迁移平滑过渡。
安全相关
EesaticSearch支持节点之间SSL通讯,也支持提供https服务,已经内置了工具便于生成证书。主要由xpack实现EsaticSearch安全相关功能,6.8开始免费开放基本安全功能。
证书相关配置,必须在elasticsearch的config目录下的一个位置
SSL
PEM格式
bash
cd /usr/local/elasticsearch
#生成CA认证中心证书,保存文件名ca.zip,有效期36500天
./bin/elasticsearch-certutil ca --pem --out ca.zip --days 36500 -s
#解压, 包含ca.crt和ca.key
unzip ca.zip
#根据CA证书,生成服务节点使用的证书,有效期36500天
./bin/elasticsearch-certutil cert --ca-cert ca/ca.crt --ca-key ca/ca.key --pem --name node --out node.zip --days 36500 -s
#得到node.zip,包含node.crt和node.crt
unzip node.zip生成证书完成后,得到CA证书和服务节点的证书,目录如下
bash
--ca
------ca.crt
------ca.key
--node
------node.crt
------node.key将这些文件拷贝到所有elasticsearch服务节点可以访问到的持久化目录,例如:
bash
cp ca/* /usr/local/elasticsearch/config/certs/
cp node/* /usr/local/elasticsearch/config/certs/修改所有ElasticSearch服务节点配置,http ssl是可选。
bash
#设置以下配置开启SSL
xpack.security.enabled: true
xpack.security.http.ssl.enabled: true
xpack.security.transport.ssl.enabled: true
#http服务
xpack.security.http.ssl.key: /usr/local/elasticsearch/config/certs/node.key
xpack.security.http.ssl.certificate: /usr/local/elasticsearch/config/certs/node.crt
xpack.security.http.ssl.certificate_authorities: /usr/local/elasticsearch/config/certs/ca.crt
#节点之间通信
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.key: /usr/local/elasticsearch/config/certs/node.key
xpack.security.transport.ssl.certificate: /usr/local/elasticsearch/config/certs/node.crt
xpack.security.transport.ssl.certificate_authorities: /usr/local/elasticsearch/config/certs/ca.crt完成上述步骤后,启动所有ES服务节点即可
Kibana配置文件修改
bash
#es服务节点改为 https
elasticsearch.hosts: ["https://ip:port"]
elasticsearch.ssl.verificationMode: certificate
#指定生成的CA认证中心证书
elasticsearch.ssl.certificateAuthorities "/usr/local/elasticsearch/config/certs/ca.crt"P12格式(推荐)
bash
cd /user/local/elasticsearch
#生成CA认证中心的证书
./bin/elasticsearch-certutil ca --days 36500
......
#定义证书文件名ca.p12
Please enter the desired output file [elastic-stack-ca.p12]: ca.p12
#设置CA的证书密码
Enter password for ca.p12 : 123456
#当前目录生成ca.p12文件
#生成服务节点用的证书,根据ca.p12文件
./bin/elasticsearch-certutil cert --ca ca.p12 --days 36500
#输入CA的证书密码
Enter password for CA (ca.p12) : 123456
#服务节点证书的文件名 node.p12
Please enter the desired output file [elastic-certificates.p12]: node.p12
#设置服务节点证书的密码
Enter password for node.p12 : 123456
#生成pem格式的CA证书,提供kibana或其它不支持pkcs12的应用使用
openssl pkcs12 -in ca.p12 -out ca.crt.pem -clcerts -nokeys
#输入CA证书的密码
Enter Import Password: 123456
#生成ca.crt.pem文件执行完成后获得文件
bash
--ca.p12
--node.p12
--ca.crt.pem将ca.p12和node.p12拷贝到所有es服务节点都能够访问到的持久化目录,将ca.crt.pem拷贝到kibana能访问的持久化目录
bash
cp ca.p12 /usr/local/elasticsearch/config/certs/
cp node.p2 /usr/local/elasticsearch/config/certs/
cp ca.crt /user/local/kibana/ssl/修改所有ElasticSearch服务节点配置,https 是可选
bash
#开启SSL
xpack.security.enabled: true
xpack.security.http.ssl.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
#https
xpack.security.http.ssl.keystore.path: /usr/local/elasticsearch/config/certs/node.p12
xpack.security.http.ssl.truststore.path: /usr/local/elasticsearch/config/certs/node.p12
#节点之间通信
xpack.security.transport.ssl.keystore.path: /usr/local/elasticsearch/config/certs/node.p12
xpack.security.transport.ssl.truststore.path: /usr/local/elasticsearch/config/certs/node.p12所有ES节点修改完成配置后,都需要设置证书文件的密码
bash
#所有ES节点均要设置证书的密码
cd /usr/local/elasticsearch
./bin/elasticsearch-keystore add xpack.security.transport.ssl.keystore
#输入节点证书的密码
Enter value for xpack.security.transport.ssl.keystore设置完证书密码,启动节点生效。
kibana配置文件修改
bash
#es服务节点改为 https
elasticsearch.hosts: ["https://ip:port"]
elasticsearch.ssl.verificationMode: certificate
#指定生成的CA认证中心证书
elasticsearch.ssl.certificateAuthorities "/usr/local/elasticsearch/config/certs/ca.crt.pem"设置密码
开启SSL后,节点都正常启动,通过以下方式设置密码,依次设置elastic、kibana、logstash_system、beats_system这些用户密码,其中elastic用户权限最大。
bash
cd /usr/local/elasticsearch
./bin/elasticsearch-setup-passwords interactive
Initiating the setup of passwords for reserved users elastic,kibana,logstash_system,beats_system.
You will be prompted to enter passwords as the process progresses.
#输入 y开始 设置密码...
Please confirm that you would like to continue [y/N]y
Enter password for [elastic]:
passwords must be at least [6] characters long
Try again.
Enter password for [elastic]:
Reenter password for [elastic]:
Passwords do not match.
Try again.
Enter password for [elastic]:
Reenter password for [elastic]:
Enter password for [kibana]:
Reenter password for [kibana]:
Enter password for [logstash_system]:
Reenter password for [logstash_system]:
Enter password for [beats_system]:
Reenter password for [beats_system]:
Changed password for user [kibana]
Changed password for user [logstash_system]
Changed password for user [beats_system]
Changed password for user [elastic]修改密码
bash
POST /_xpack/security/user/elastic/_password
{
"password" : "123456"
}