事件概述
**事件1:**8月1号晚上18点50分某服务宕机,容器OOM,随后非常快速的,该服务的4台容器全都宕机。
由于未添加HeapDumpOnOutOfMemoryError参数,无dump文件,排查近期上线功能内容,无果,且xxjob也有分流到其他容器,排除定时任务的影响,数据库也没死锁,只能添加-XX:HeapDumpPath参数待下次问题复现
**事件2:**8月6号早上10点40分发生宕机,容器再次OOM,从时间上看也并没有什么规律。
再次灰度发布新容器、扩容的同时,登陆旧容器应用查看dump文件,发现没有dump文件。排查发现是因为添加了-XX:+ExitOnOutOfMemoryError参数,于是在容器OOM时应用立即重启,未留下dump文件。
吸取本次教训,这次在测试环境配置参数后做混沌实验,注入OOM,测试能否正常dump文件,确保参数无误,下次出现问题能留下dump文件排查
**事件3:**8月15号晚上19点左右发生宕机,容器再次OOM,这次终于抓到dump文件了,灰发扩容的同时开始排查问题
问题排查和定位
使用MAT加载dump文件(Eclipse Memory Analyzer)
左上角 File >> Open Heap Dump >> 打开文件加载dump文件
PS:如果打开提示报错Out Of Memory ,需要在MAT的安装目录下找到MemoryAnalyzer.ini文件,并修改-Xmx改到比你的dump文件稍大些(我这里dump文件9G,直接给我的MAT干OOM了 😅)
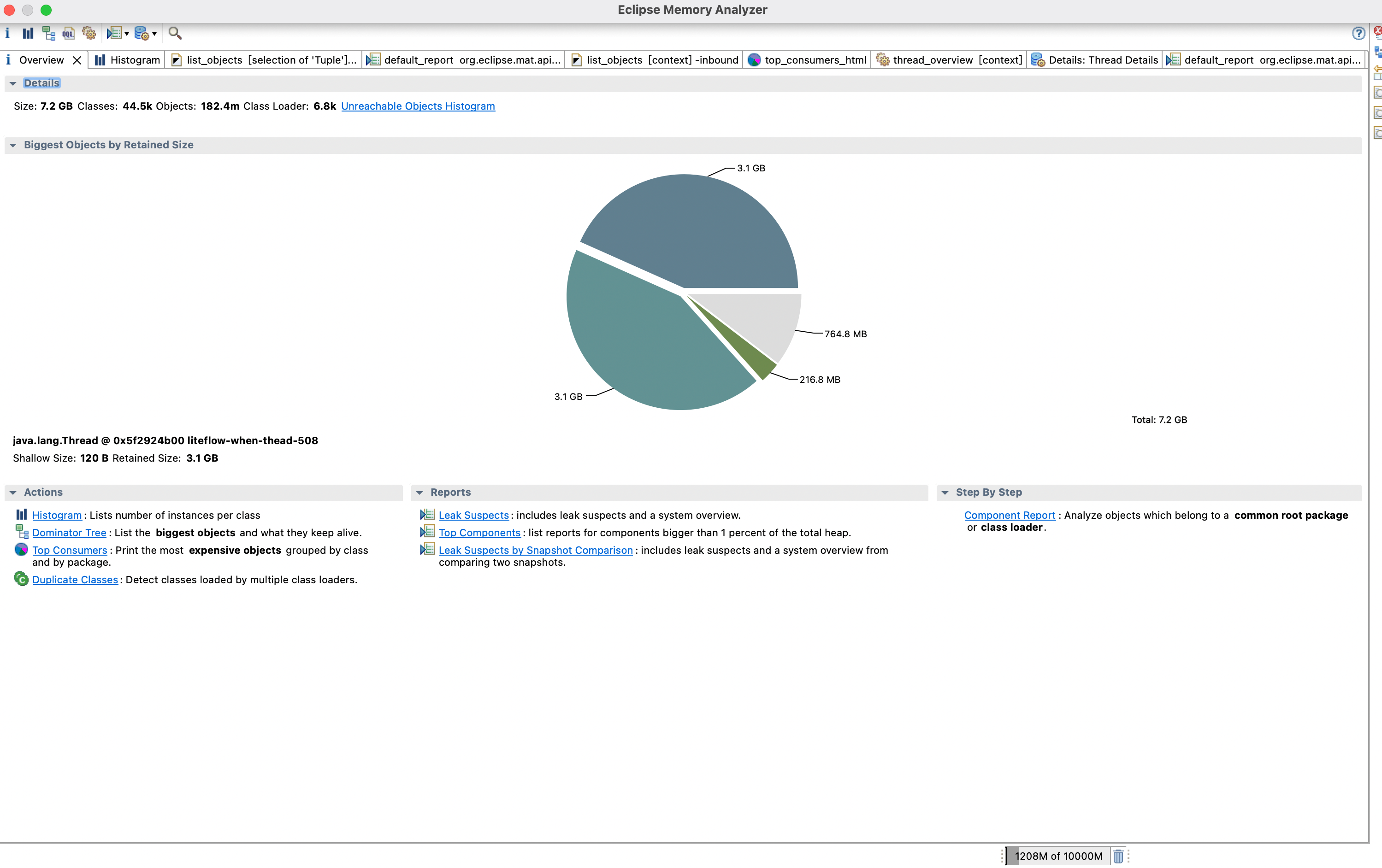
看Reports
点击Leak Suspects 查看有内存泄漏嫌疑的地方
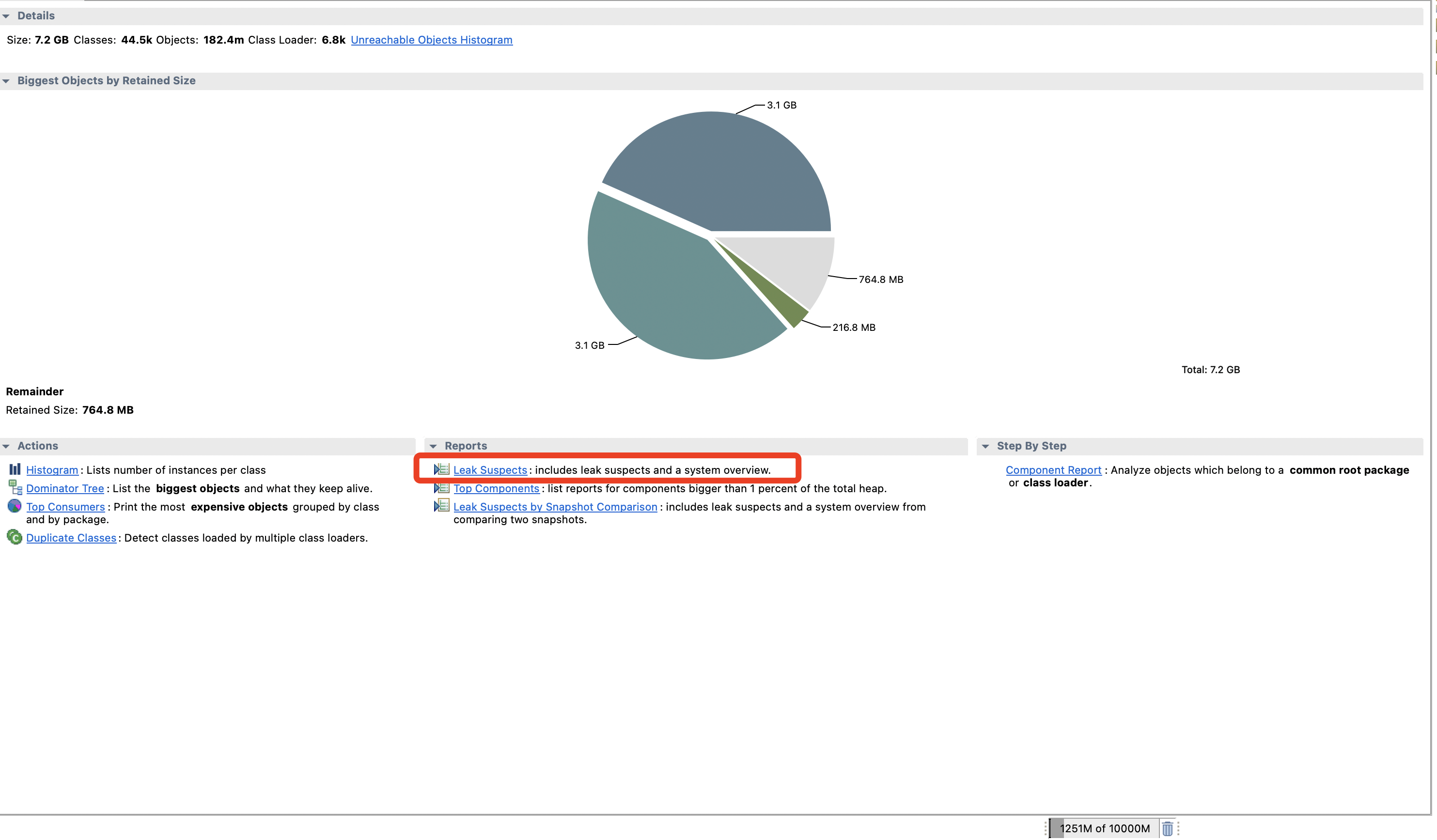
看Problem Suspect 1(问题嫌疑,有嫌疑的地方1)
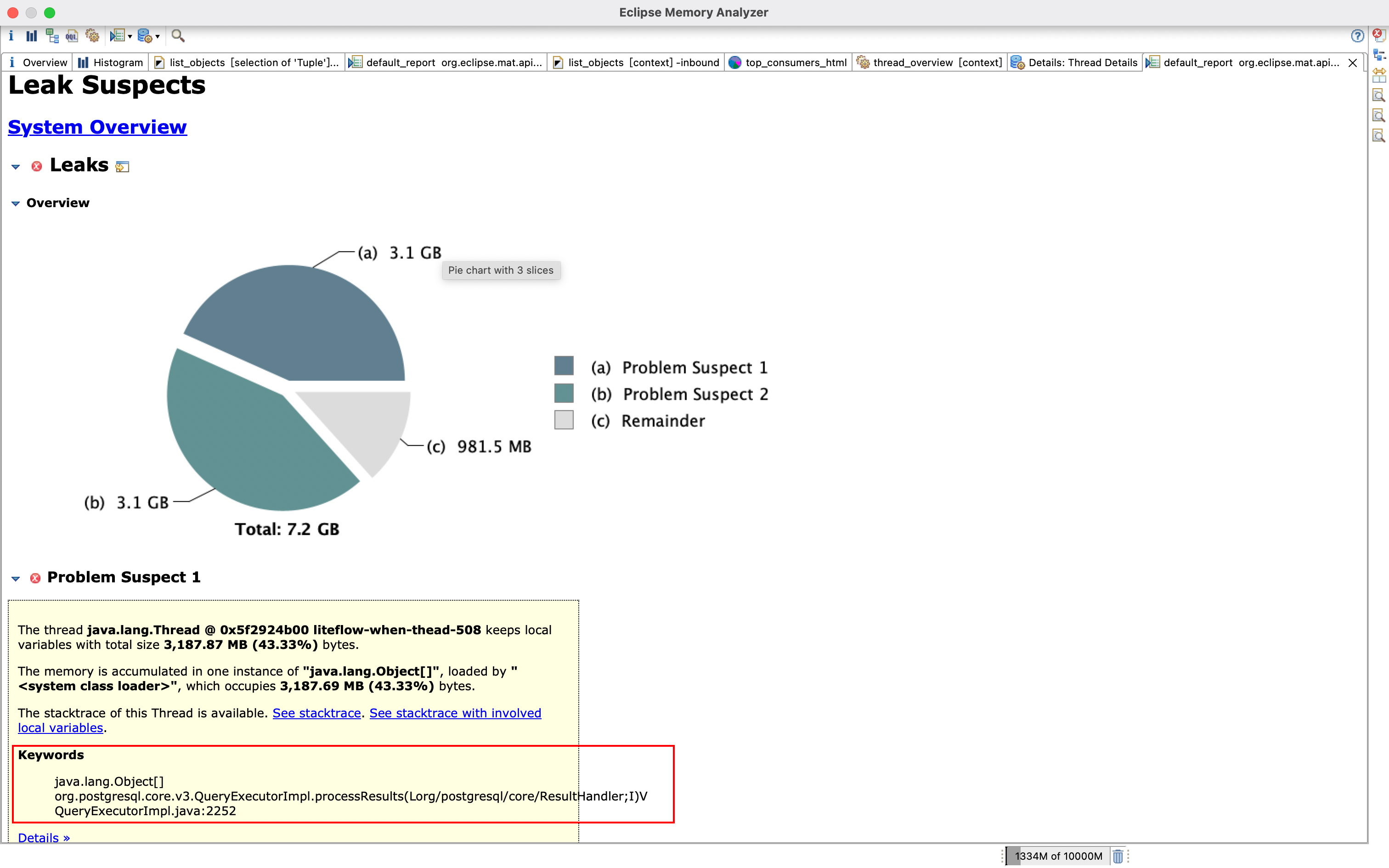
圈红圈的地方,org.postgresql.core.v3.QueryExecutorImpl.processResults ,从这里可以看出端疑,从方法名称可以看出来是对返回结果的处理,基本可以猜测是某个查询方法返回的对象过大或者过多导致的OOM**(** Problem Suspect 2也是指向这个方法**)**
Keywords
- java.lang.Object\[\]
- org.postgresql.core.v3.QueryExecutorImpl.processResults(Lorg/postgresql/core/ResultHandler;I)V
- QueryExecutorImpl.java:2252

看Details
接下来我们点击Details看看具体的堆栈信息
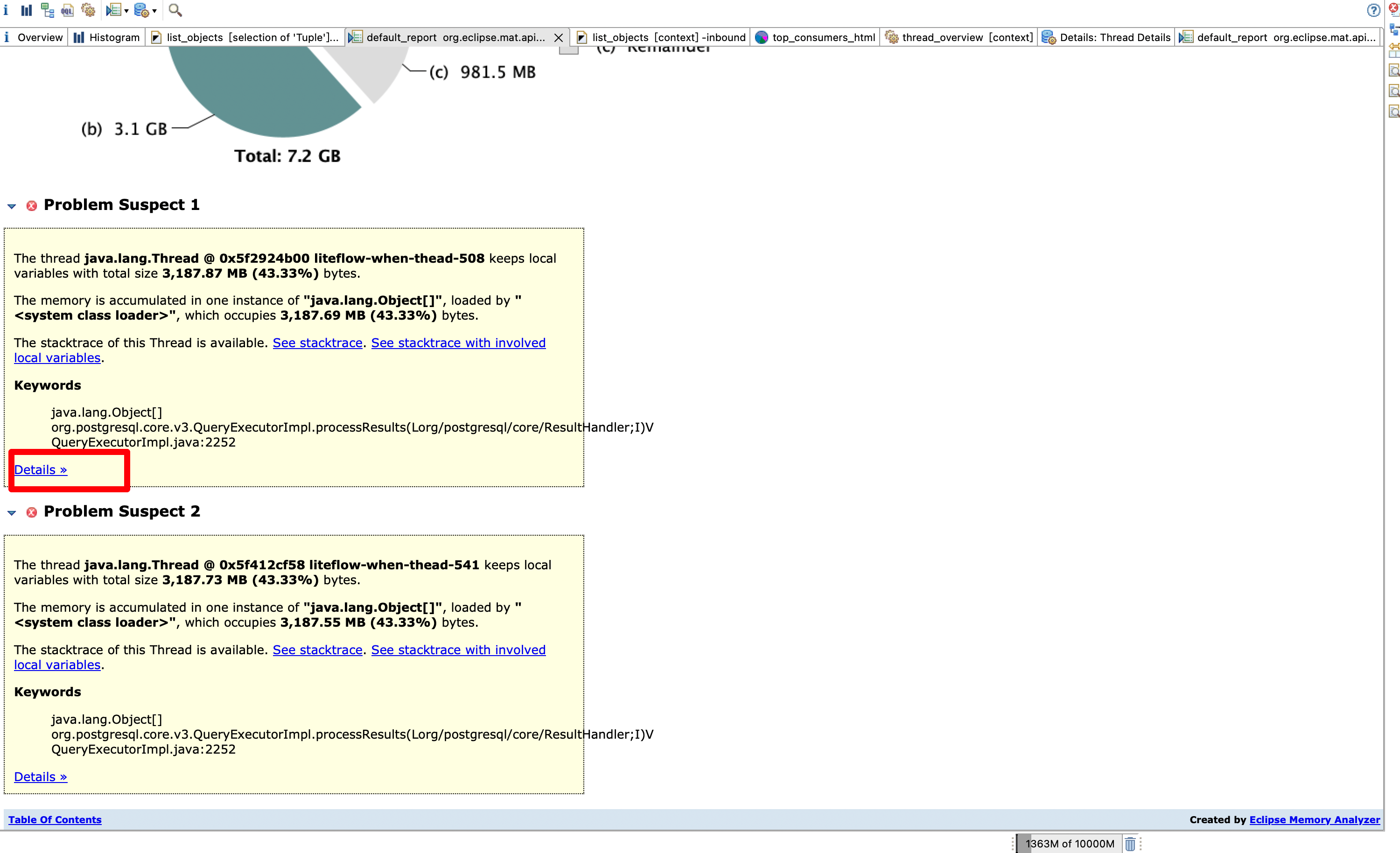
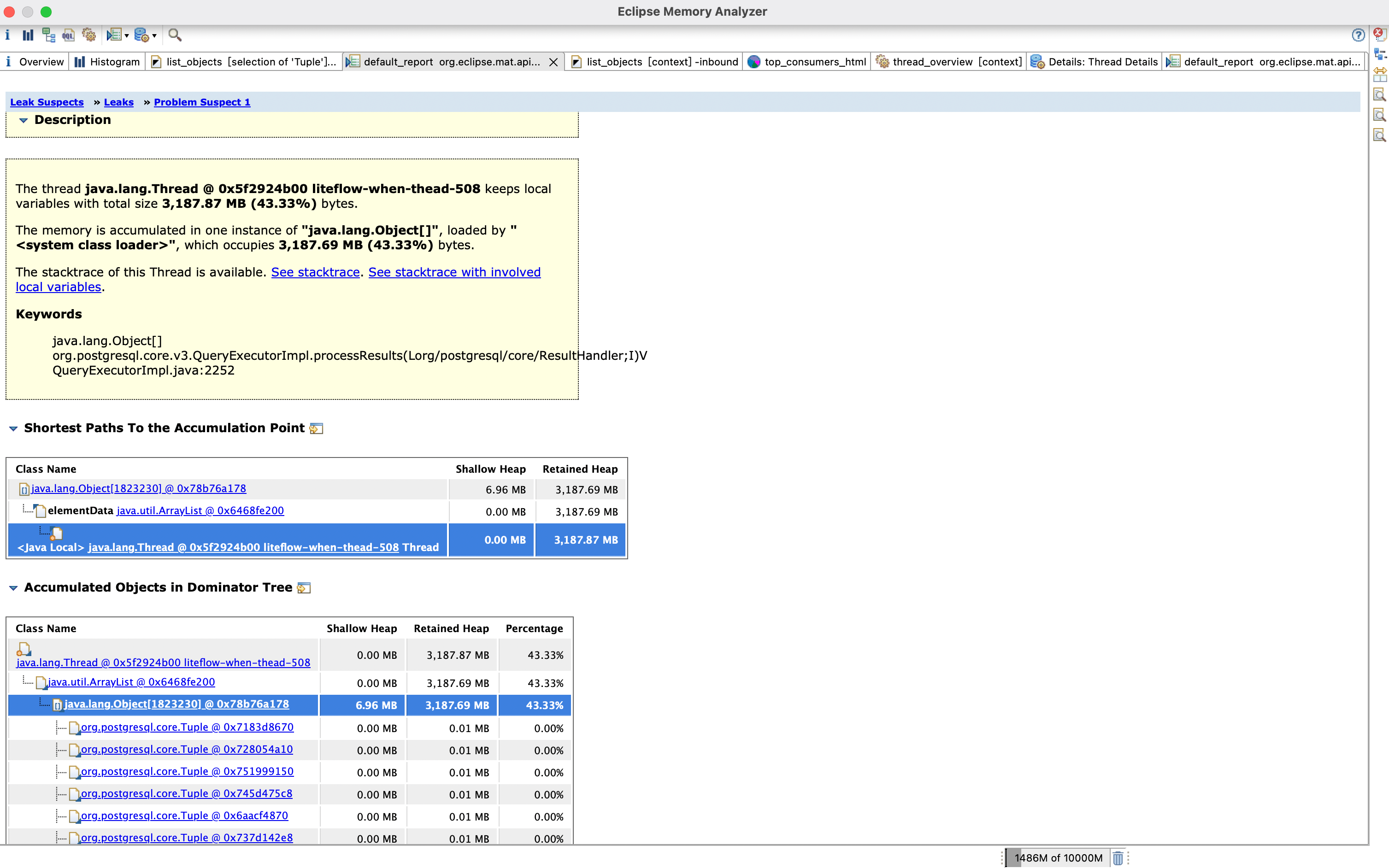
Accumulated Objects by Class in Dominator Tree(按类聚合数据)
往下拉,这里可以看到 Accumulated Objects by Class in Dominator Tree
可以看到Tuple这个类有128万个,总共占用了3335MB,接近3个G的内存
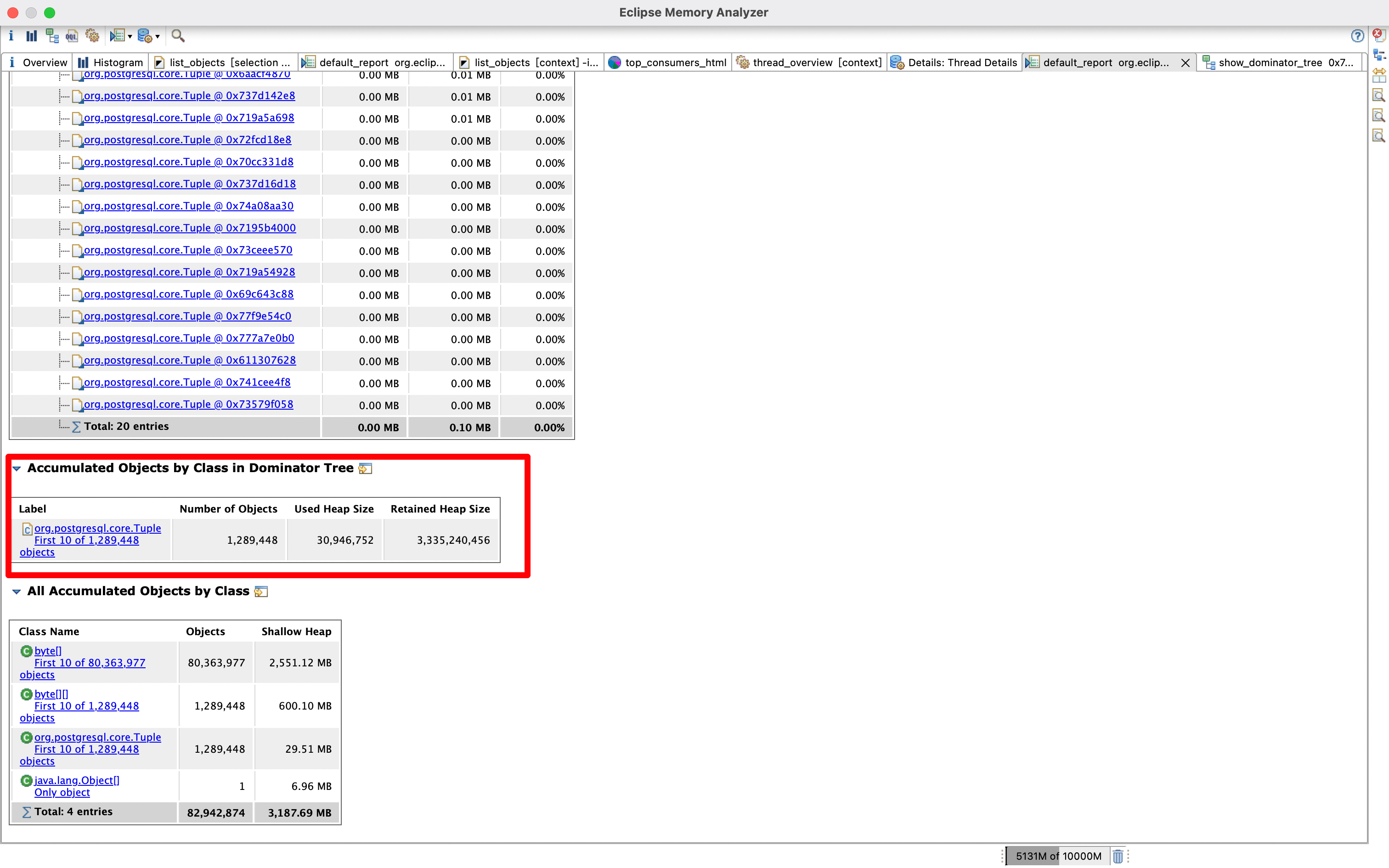
查官方的文档可以看到这个类是 Class representing a row in a ResultSet. 也就是表示查出来的一个结果行,查了100多万个结果出来,那基本可以确定是有异常的sql了,多半是没有传递查询条件之类的,我们接着看
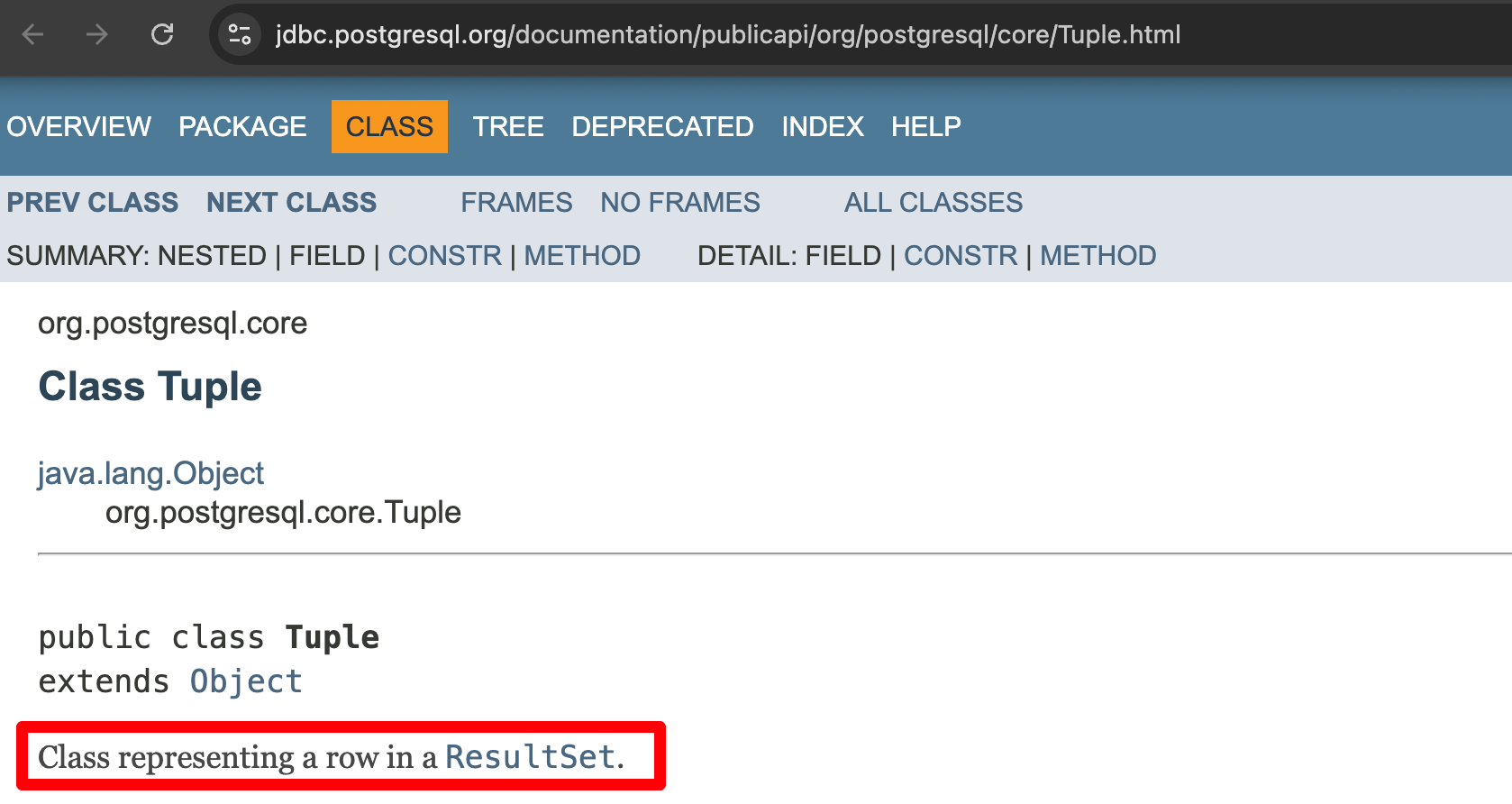
看Thread Stack
和我们平时看报错的堆栈信息一样去看,这里已经可以定位到具体的查询方法了,大概长这样(代码经过脱敏处理,隐去实际业务对象名称等):
@Override
public List<XXObject> getByXxIds(List<String> xxIds) {
QueryParam queryParam = new QueryParam();
queryParam.setXxIds(xxIds);
List<XXObject> xxObjectPOList = xxObjectRepository.listLines(queryParam);
return this.translate(xxObjectPOList);
}这里已经开始猜测xxIds为空,无传入参数导致全表查询出了几百万行数据
但是为了实锤,本着严谨的态度,我们接着看
Thread Overview and Stacks
回到能看到线程的Shortest Paths To the Accumulation Point,右键》》Java Basics 》》Thread Overview and Stacks
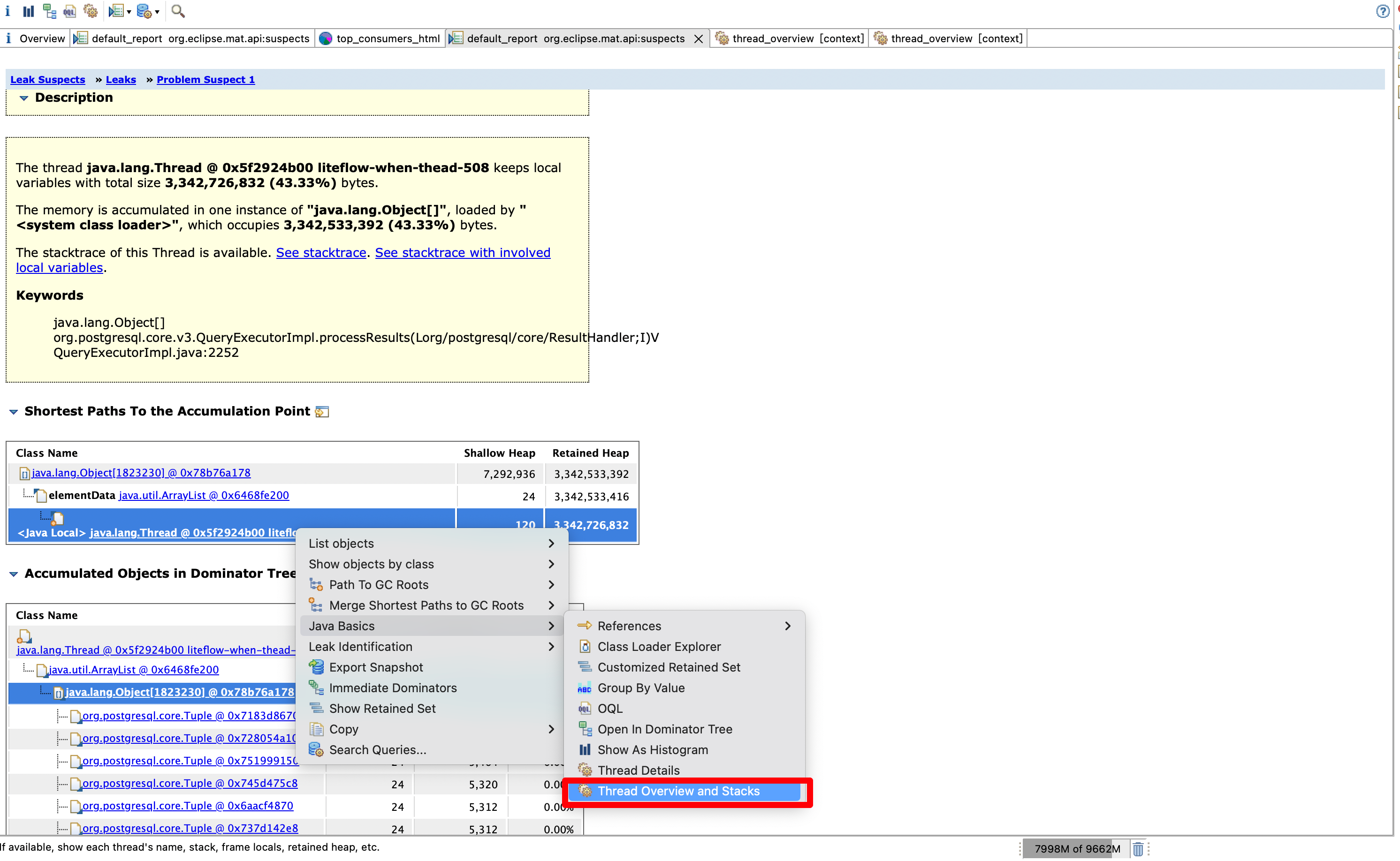
这里可以看到刚刚占用内存的processResults结果处理方法,不过这里我们要看的是sql和入参,所以应该关注PreparedStatement方法
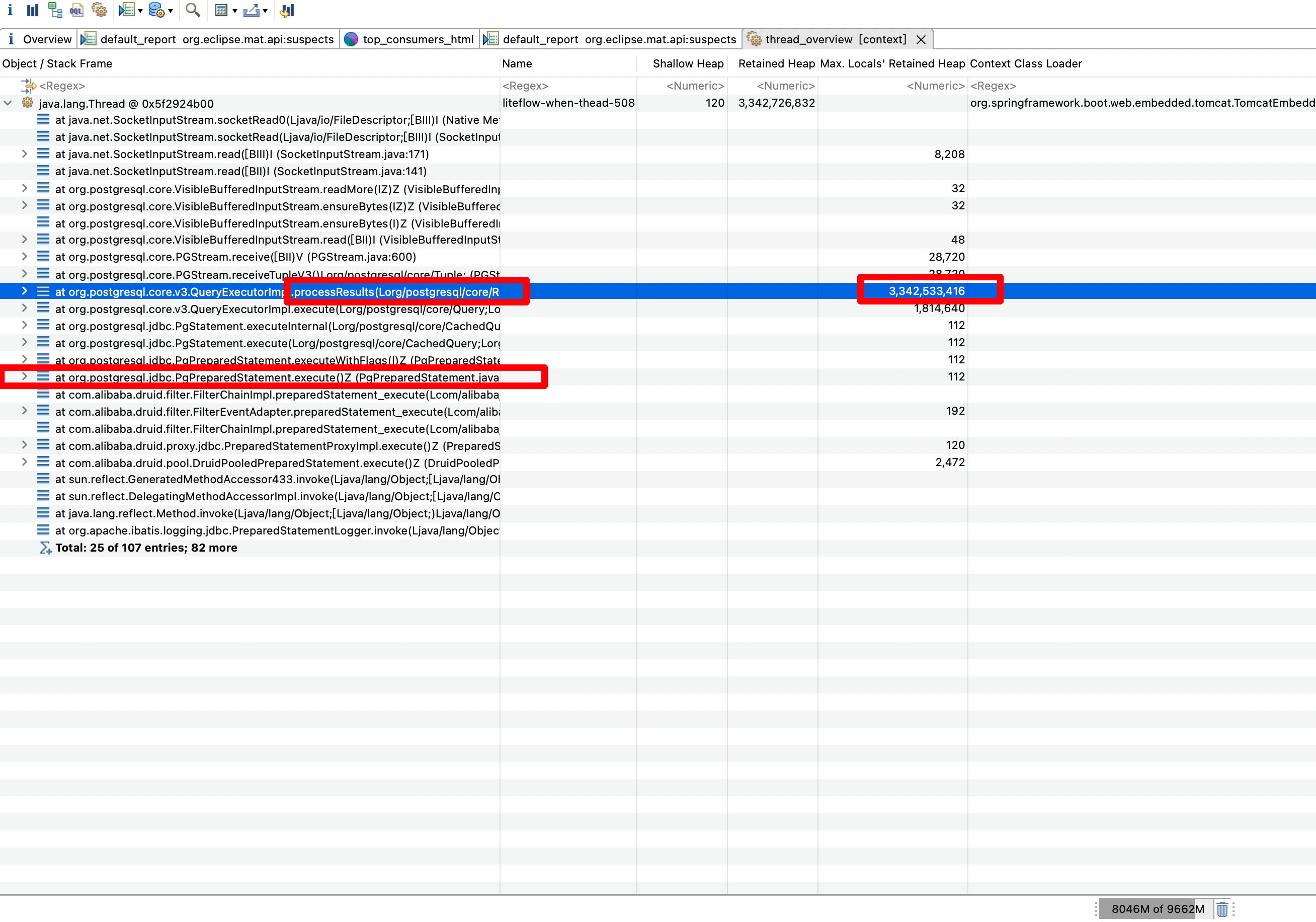
这里我们层层打开,可以看到preparedQuery,也就是加载的sql,其中的key就是就是执行的sql
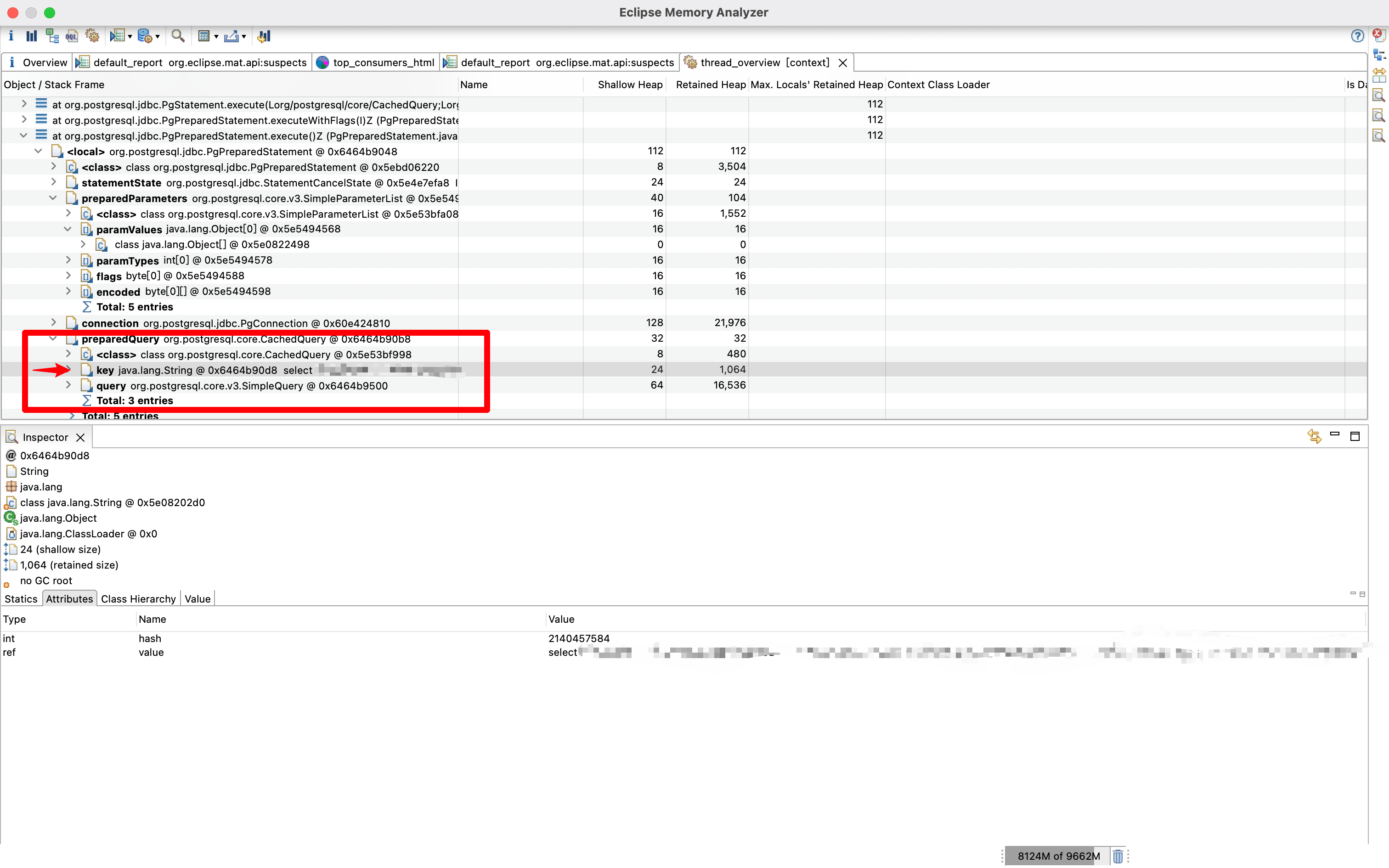
而paramValues也就是对应的入参了,可以看到是空的,那就基本实锤了
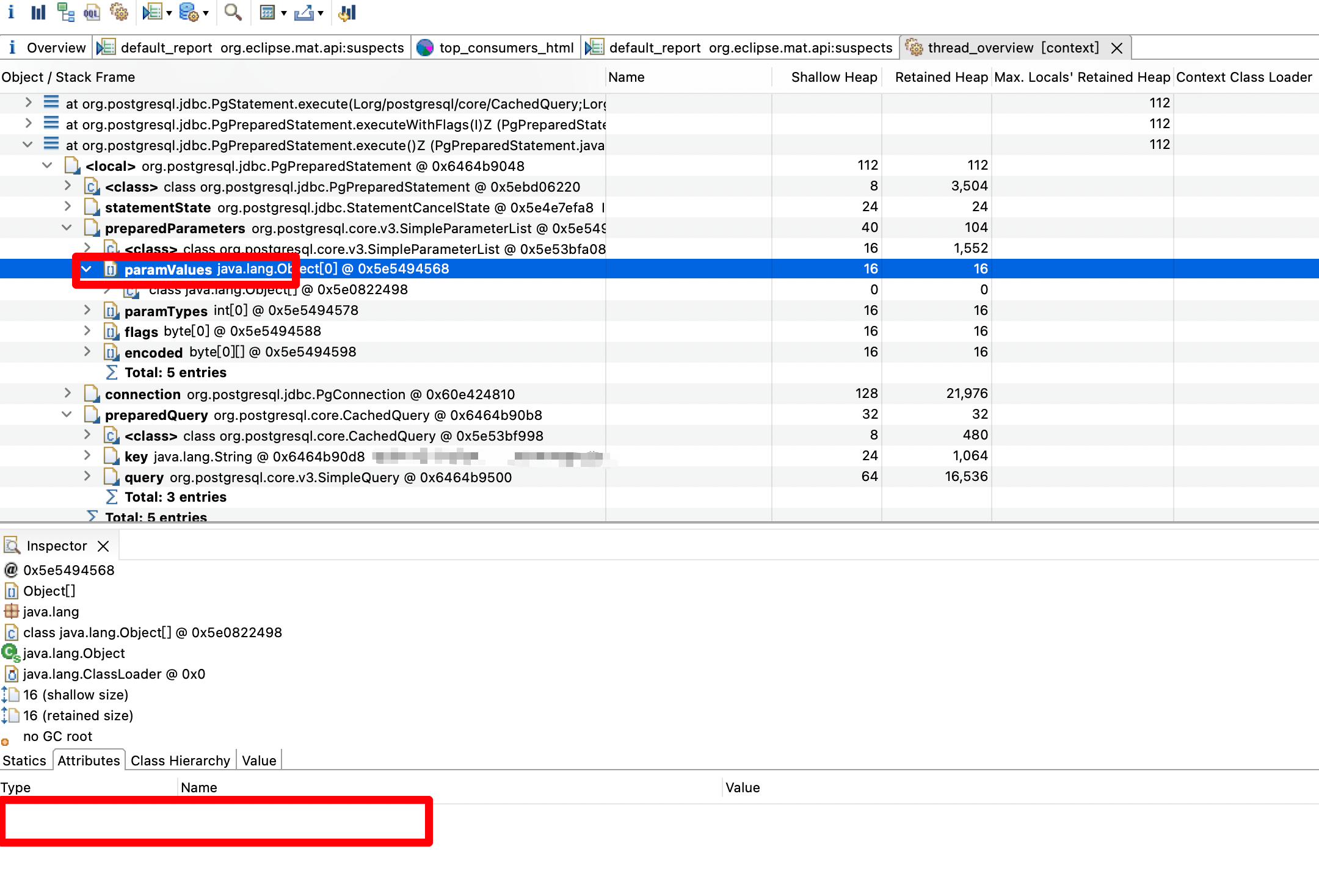
最后结合日志,查看该方法操作的时间和系统三次宕机的时间是否对得上,结果是都对上了
这个是历史功能,按理说以前也应该会有这样的问题,那么为什么不会呢
继续排查日志,发现诱因是前端调整导致用户可以对已经操作过的单据再次执行该操作,而这时候已经没有需要操作的数据了,因而导致了后续的问题
根因分析
根本原因还是底层通用逻辑没有做好参数校验,接口的健壮性没有做好
长期解决方案及改进措施
-
对整个系统中类似的查询接口审查参数校验是否完整
-
检查其他服务的dump配置是否添加
-
制定好规范、代码审查标准
-
熔断,虽然本次事件没产生雪崩效应,但是没做熔断也是事实
-
完善监控告警
-
也许有时间(不可能)应该AOP做默认分页,超出一定数量的数据查询,需要自己评估并传递参数
PS:遇到OOM问题第一时间灰发新容器,加内存
遇到问题第一时间想到的肯定是灰发新容器,加内存等等,但是我个人加的还是比较扣扣搜搜,没舍得一次加到位,4台机器加到6台,8G加到10G,但是实际用户一次操作,十几G的内存就出来了,连点几下,一下子全挂了,下次遇到问题还是需要直接加倍,先稳住生产环境(机器多又不花我钱 🐶),稳住了才有精力去排查问题
