
Amundsen 是一个数据发现和元数据引擎,旨在提高数据分析师、数据科学家和工程师与数据交互时的生产力。目前,它通过索引数据资源(表格、仪表板、数据流等)并基于使用模式(例如,查询频率高的表格会优先于查询频率低的表格)提供页面排名式的搜索功能来实现这一目标。您可以将其视为数据版的 Google 搜索。该项目以挪威探险家罗尔德·阿蒙森 (Roald Amundsen) 的名字命名,他是第一个发现南极的人。
React 配置
Flask
默认的 Flask 应用使用一个 LocalConfig,该配置会查找运行在 localhost 上的元数据与搜索服务。如需使用不同的端点,你需要创建一个适合自身用例的自定义配置类。一旦配置类创建完成,可通过 环境变量 引用:FRONTEND_SVC_CONFIG_MODULE_CLASS
有关如何针对特定功能利用 Flask 配置的更多示例,请参阅此 扩展文档。
有关 Flask 配置的更多信息,请参考官方 Flask 文档。
React 应用
应用配置
React 应用的某些功能会从 AppConfig 对象导入变量。可通过修改 config-custom.ts 来自定义该配置。
有关如何针对特定功能利用应用配置的示例,请参阅此 扩展文档。
自定义字体与样式
可通过修改 fonts-custom.scss 与 variables-custom.scss 来自定义字体与 CSS 变量。
Python 入口点
应用还利用 python entry points 实现自定义功能。
在本地 setup.py 中,将下列入口点指向给定功能需要实现的自定义类或方法。
在虚拟环境中运行 python3 setup.py install 并重启应用,使入口点更改生效。
python
entry_points="""
[action_log.post_exec.plugin]
analytic_clients_action_log = path.to.file:custom_action_log_method
[preview_client]
table_preview_client_class = amundsen_application.base.examples.example_superset_preview_client:SupersetPreviewClient
[announcement_client]
announcement_client_class = amundsen_application.base.examples.example_announcement_client:SQLAlchemyAnnouncementClient
"""Action 日志记录
创建一个自定义方法来处理 action 日志记录。在 [ action_log.post_exec.plugin] 组下,将本地 setup.py 中的 analytic_clients_action_log 入口点指向该方法。
Preview 客户端
创建一个 base_preview_client 的自定义实现。在 [preview_client] 组下,将本地 setup.py 中的 table_preview_client_class 入口点指向该类。
对于使用 Apache Superset 进行数据探索的用户,请查看 此文档,了解如何实现 Superset 的 preview 客户端。
Announcement 客户端
创建一个 base_announcement_client 的自定义实现。在 [announcement_client] 组下,将本地 setup.py 中的 announcement_client_class 入口点指向该类。
目前 Amundsen 不拥有公告的输入和存储。建议让客户端从外部 Web 订阅源获取公告信息。
认证
可在 Amundsen 内通过包装类或使用代理在 nginx/服务器级别保护微服务的方式接入认证。以下是设置端到端认证的方法。
Flask 配置
修改本文档所述 config.py 中的任何变量后,请务必重新构建应用以使变更生效。
注意:本文档仍在完善中,尚未覆盖 100% 的功能。欢迎提交 PR 以补全文档。
自定义路由
如需在 Amundsen 的前端应用中新增任何自定义 Flask 端点,请在 INIT_CUSTOM_ROUTES 变量上配置一个函数。该函数接收已创建的 Flask 应用,并可利用 Flask 的 add_url_rule 方法来增加自定义路由。
示例:将 INIT_CUSTOM_ROUTES 设为下方 init_custom_routes 方法,将在前端应用上暴露 /custom_route 端点。
bash
def init_custom_routes(app: Flask) -> None:
app.add_url_rule('/custom_route', 'custom_route', custom_route)
def custom_route():
pass仪表板预览
该服务提供下载仪表板资源预览图片的 API,当前仅支持 Mode。
仪表板预览图片会在用户浏览器中缓存最多一天。如需调整此缓存时间,可修改 DASHBOARD_PREVIEW_IMAGE_CACHE_MAX_AGE_SECONDS 的值。
如何配置 Mode 仪表板预览
添加以下环境变量:
bash
CREDENTIALS_MODE_ADMIN_TOKEN
CREDENTIALS_MODE_ADMIN_PASSWORD
MODE_ORGANIZATION如何在 Mode 仪表板上启用授权
默认情况下,Amundsen 在显示预览时不进行任何授权。通过在配置中注册 Mode 预览类的名称,可启用授权。
bash
ACL_ENABLED_DASHBOARD_PREVIEW = {'ModePreview'}Amundsen 仅从共享空间摄取 Mode 仪表板,所有已注册的 Mode 用户均可查看。因此,我们的授权首先会验证当前用户是否已在 Mode 中注册。该功能依赖于 Amundsen 通过 ModeDashboardUserExtractor 也摄取了 Mode 用户信息,且 metadata service 的版本必须不低于 v2.5.2。
如何支持其他产品的预览?
可通过将其预览类添加到 DefaultPreviewMethodFactory 来为不同产品增加预览支持。
若要开发新的预览类,需实现继承 BasePreview 的类,ModePreview 可作为很好的示例。
邮件客户端功能
Amundsen 有两个功能会用到自定义邮件客户端 ------ 反馈工具和通知。为使用这些功能,必须将 base_mail_client 的自定义实现映射到 MAIL_CLIENT 配置变量。若要在 UI 中完全启用这些功能,还必须将应用配置变量中对应功能的开关设为 true。请参见应用配置文档中的此条目获取更多信息。
问题跟踪集成功能
Amundsen 支持在表详情视图中显示关联工单的功能。该功能既展示未结工单,也允许用户为表报告新工单。这些工单必须在其文本中包含 table_uri 才能被显示;通过该功能创建的工单会自动附加 table_uri。工单按从新到旧排序,当前仅展示未结工单。当前仅支持 JIRA。UI 也必须启用才能使用此功能,请参见此处的配置说明。
要使用此功能,需在 config.py 中设置若干配置项。
以下列出了这些设置及其应设值:
python
ISSUE_LABELS = [] # type: List[str] (创建工单时可选的 label)
ISSUE_TRACKER_URL = None # type: str (你的 JIRA 环境,如 'https://jira.net')
ISSUE_TRACKER_USER = None # type: str (建议使用服务账号)
ISSUE_TRACKER_PASSWORD = None # type: str
ISSUE_TRACKER_PROJECT_ID = None # type: int (希望在其下创建 JIRA 工单的项目 ID)
ISSUE_TRACKER_CLIENT = None # type: str (完全限定类名及路径)
ISSUE_TRACKER_CLIENT_ENABLED = False # type: bool (启用功能,必须设为 True)
ISSUE_TRACKER_MAX_RESULTS = None # type: int (一次最多展示的工单数)
ISSUE_TRACKER_ISSUE_TYPE_ID = None # type: int (仅 Jira:云部署/托管部署需要时覆盖默认工单类型 ID)程序化描述
Amundsen 支持在表页面配置其他 Markdown 支持且不可编辑的描述框。如果有多位编写者希望向 Amundsen 写入不同信息,而这些信息要么过于公司特定因而永远不会直接集成到 Amundsen 中,要么需要长文本才能准确传达信息,则此功能很有用。
有哪些更具体的示例?
- 你有一个现有流程,可为数据集生成质量报告,并希望将其嵌入表页面。
- 你有一个流程可检测 PII 信息(同时添加相应标签/徽章),还会生成简单报告以提供上下文。
- 你拥有适用于数据存储的扩展表信息,希望抓取并展示在表页面中
程序化描述通过"描述来源"引用,描述来源是唯一的标识符。在 UI 中,它们会出现在表页面的结构化元数据下。
在 config.py 中,你可配置描述以自定义顺序,以及它们应位于左列还是右列。
python
PROGRAMMATIC_DISPLAY = {
'RIGHT': {
"test3" : {},
"test2" : { "display_order": 0 }
},
'LEFT': {
"test1" : { "display_order": 1 },
"test0" : { "display_order": 0 },
},
'test4': {"display_order": 0},
}配置中未提及的描述来源将按字母顺序排在列表底部。若 PROGRAMMATIC_DISPLAY 保持为 None,则所有新增字段将按后端返回的顺序显示。以下屏幕截图展示了其在左下角的效果:
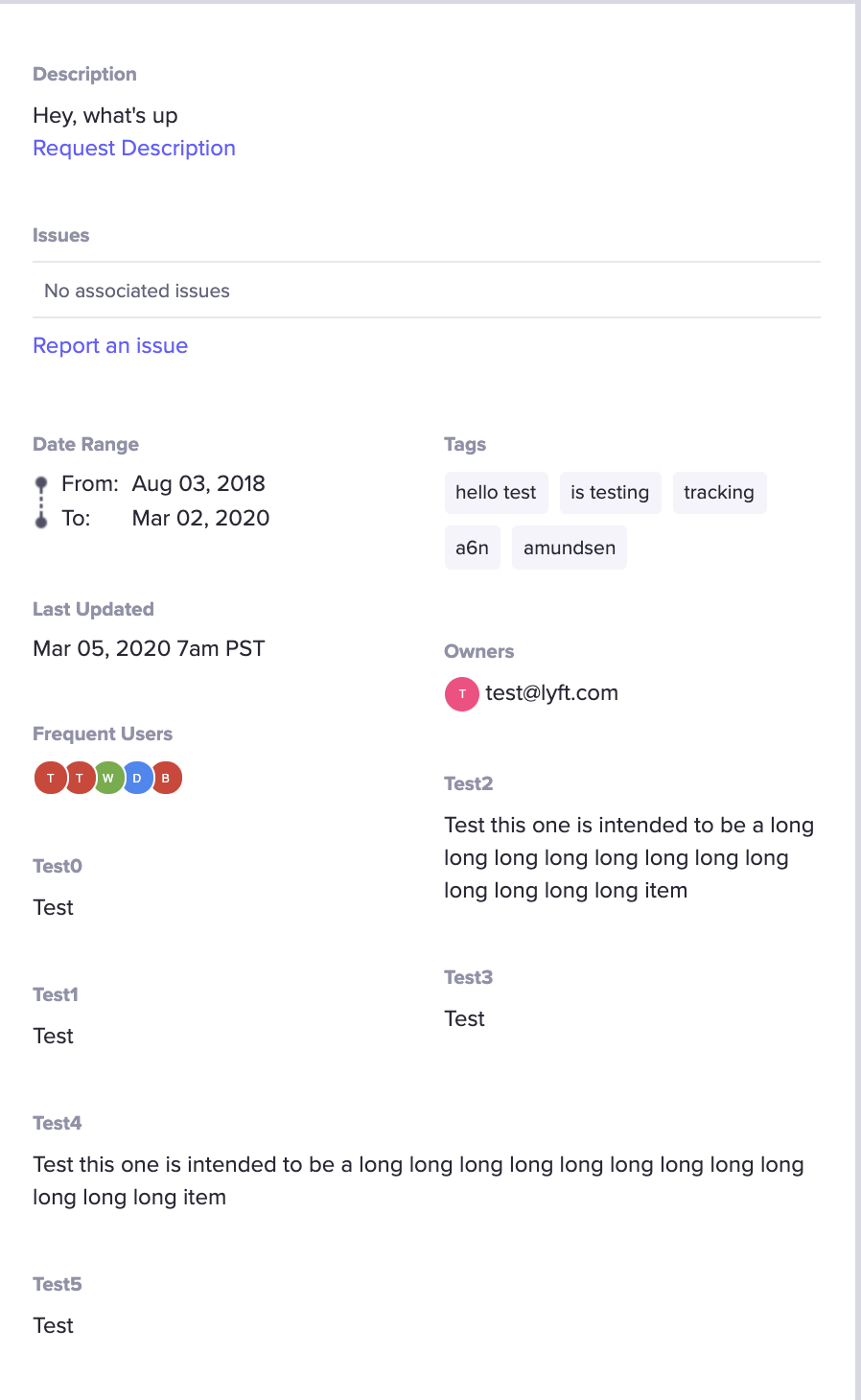
不可编辑的表描述
Amundsen 支持对选定的表配置表和列描述为不可编辑。由于各种原因,你可能希望使表描述不可编辑,例如表已从权威来源获得描述。可在 config.py 中定义匹配规则以选择表。该配置很有用,因为表选择标准可能公司特定,不会直接与 Amundsen 集成。你可组合使用 schema 和表名进行表选择。
以下是可使用此功能的一些示例:
- 你希望将应用中的所有表设为不可编辑
- 你希望将给定 schema 或 schema 模式下的所有表设为不可编辑。
- 你希望将给定 schema 模式下特定表名模式的所有表设为不可编辑。
- 你希望将给定表名模式的所有表设为不可编辑。
Amundsen 在 config.py 文件中有两个变量可用于定义匹配规则:
ALL_UNEDITABLE_SCHEMAS:布尔开关,控制是否可编辑表。也可通过环境变量 'ALL_UNEDITABLE_SCHEMAS' 设置UNEDITABLE_SCHEMAS:schema 集合,其中所有表都应为不可编辑。它接受确切的 schema 名称。UNEDITABLE_TABLE_DESCRIPTION_MATCH_RULES:MatchRuleObject 列表,每个 MatchRuleObject 包含 schema 名的正则或表名的正则或两者。
ALL_UNEDITABLE_SCHEMAS 的目的是提供禁用 schema 编辑的总开关。如果你计划通过 databuilder 而非允许用户通过 UI 来更新所有 schema,请使用此开关。
UNEDITABLE_SCHEMAS 的目的可由 UNEDITABLE_TABLE_DESCRIPTION_MATCH_RULES 实现,但出于向后兼容性我们保留这两个变量。
若希望限制给定 schema 下的表,可按如下方式使用 UNEDITABLE_SCHEMAS:
python
UNEDITABLE_SCHEMAS = set(['schema1', 'schema2'])完成上述配置后,'schema1' 和 'schema2' 中的所有表将拥有不可编辑的表和列描述。
若有更复杂的匹配规则,可使用 UNEDITABLE_TABLE_DESCRIPTION_MATCH_RULES。它提供更大的灵活性和控制,因为可创建多个匹配规则并使用正则匹配 schema 和表名。
可按如下方式在 config.py 中配置匹配规则:
python
UNEDITABLE_TABLE_DESCRIPTION_MATCH_RULES = [
# 匹配 schema1 中所有表的规则
MatchRuleObject(schema_regex=r"^(schema1)"),
# 匹配 schema2 和 schema3 中所有表的规则
MatchRuleObject(schema_regex=r"^(schema2|schema3)"),
# 匹配 schema4 中以 'noedit_*' 为表名模式的表的规则
MatchRuleObject(schema_regex=r"^(schema4)", table_name_regex=r"^noedit_([a-zA-Z_0-9]+)"),
# 匹配 schema5、schema6 和 schema7 中以 'noedit_*' 为表名模式的表的规则
MatchRuleObject(schema_regex=r"^(schema5|schema6|schema7)", table_name_regex=r"^noedit_([a-zA-Z_0-9]+)"),
# 匹配所有以 'others_*' 为表名模式的表的规则
MatchRuleObject(table_name_regex=r"^others_([a-zA-Z_0-9]+)")
]完成此配置后,用户将无法从 UI 编辑匹配上述规则的任何表的表和列描述。
Superset 预览集成
Amundsen 的数据预览功能要求开发者实现一个自定义的 base_preview_client,用于请求数据。该功能通过为最终用户提供查看实际资源数据样本的选项来辅助数据发现,使用户能够验证他们是否希望继续探索该数据,或继续搜索。
Apache Superset 是一个用于数据探索的开源商业智能工具。Amundsen 的数据预览功能在设计时已考虑与 Superset 的集成,这也是我们 Lyft 内部用于支持该功能的工具。本文档提供了如何配置 Amundsen 前端应用程序以利用 Superset 进行数据预览的见解。
实现
实现 base_superset_preview_client 以向 Superset 实例发出请求。
共享逻辑
base_superset_preview_client 实现了 base_preview_client 中的 get_preview_data(),包含此用例所需的最小逻辑。
如果 get_preview_data() 中传入了 optionalHeaders,它会更新请求的 headers。
python
# 克隆 headers,以免改变实例状态
headers = dict(self.headers)
# 将 optionalHeaders 合并到 headers
if optionalHeaders is not None:
headers.update(optionalHeaders)它在将数据返回给应用程序之前验证数据的结构。如果数据不符合 PreviewDataSchema,请求将失败。
python
# 验证并返回结果
response_dict = response.json()
columns = [ColumnItem(c['name'], c['type']) for c in response_dict['columns']]
preview_data = PreviewData(columns, response_dict['data'])
data, errors = PreviewDataSchema().dump(preview_data)
if not errors:
payload = jsonify({'preview_data': data})
return make_response(payload, response.status_code)
else:
return make_response(jsonify({'preview_data': {}}), HTTPStatus.INTERNAL_SERVER_ERROR)自定义逻辑
base_superset_preview_client 包含一个抽象方法 post_to_sql_json()。此方法将包含任何自定义逻辑,以便根据你在 Superset 实例上为该端点配置的保护措施,向 sql_json 端点成功发出请求。例如,这可能是在 headers 中附加其他值,或根据你的用例生成 SQL 查询的地方。
请参考以下 example_superset_preview_client 以获取 base_superset_preview_client 和 post_to_sql_json() 的示例实现。此示例假设在端口 8088 上运行了一个本地 Superset 实例,并且该端点上未配置任何安全、身份验证或授权。
使用方法
在 [preview_client] 组下,将本地 setup.py 中的 table_preview_client_class 入口点指向你的自定义类。
python
entry_points="""
...
[preview_client]
table_preview_client_class = amundsen_application.base.examples.example_superset_preview_client:SupersetPreviewClient
"""在你的虚拟环境中运行 python3 setup.py install 并重启应用程序,以使入口点更改生效。
风险提示与免责声明
本文内容基于公开信息研究整理,不构成任何形式的投资建议。历史表现不应作为未来收益保证,市场存在不可预见的波动风险。投资者需结合自身财务状况及风险承受能力独立决策,并自行承担交易结果。作者及发布方不对任何依据本文操作导致的损失承担法律责任。市场有风险,投资须谨慎。