目录
- 为什么需要"打包"
- 三个核心名词:module、chunk、bundle
- 一张图 + 一条时间线:Webpack 的工作流程
- 从源码到产物的 5 个阶段
- 代码演示:把 10 行源码变成 3 个 bundle
- 常见疑问 & 易混淆点
- 小结
当你第一次运行 npm run build,看到终端里滚动着几十条"chunk、bundle、module"的日志时,是否也和我一样满脸问号:
• 明明只写了一行 import React,为何生成了三个 .js 文件?
• 那个 200 KB 的 vendor~lodash.e3b4c5.js 到底算"模块"还是"文件"?
• 开发环境一切正常,生产环境却白屏,是不是 chunk 和 bundle 搞错了?
Webpack 的官方文档有 100 多万字,却很少有人用一句话说清:
"它只是一台把无数源代码模块(module)按规则拼成逻辑代码块(chunk),再落盘成浏览器可加载文件(bundle)的流水线。"
1. 为什么需要"打包"
浏览器只认识三种静态资源:HTML、CSS、JS。但我们写 React、Vue、TypeScript、Sass... 它们必须先被转译、合并、压缩,再交付给浏览器。Webpack 的角色就是:
• 把五花八门的源文件转译成浏览器能跑的静态文件
• 在体积、缓存、并行加载之间做权衡与优化
2. 三个核心名词
(1) module(模块)
• 最小工作单位,一个 .js/.ts/.css/.png 都算一个模块
• 在内存里以「路径+内容」形式存在,带一个唯一 id(NormalModule 对象)
(2) chunk(代码块)
• 逻辑概念 :Webpack 根据入口(entry)、动态 import、SplitChunksPlugin 的规则,把一批模块 逻辑上 划在一起
• 特点:chunk 不直接落盘,是生成 bundle 之前的"中间产物"
(3) bundle(文件)
• 物理概念 :一个 chunk 经过插件(Terser、CSS 提取等)加工后,最终写到磁盘上的 一个文件
• 关系:1 个 chunk → 1 个 bundle(默认);也可通过配置让 1 个 chunk → N 个 bundle(例如提取 CSS 为独立文件)
一句话记忆:
module 是"砖",chunk 是"墙",bundle 是"房子"。
3. 一张图 + 一条时间线
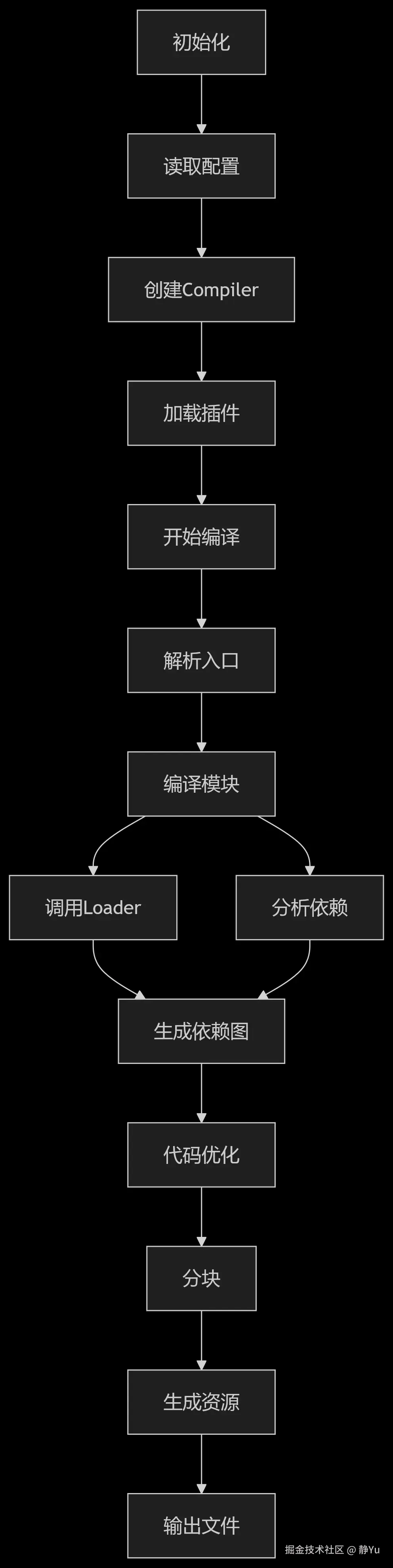 时间线(CLI 日志对应):
时间线(CLI 日志对应):
• 1️⃣ build modules(解析模块)
• 2️⃣ chunk assets(生成 chunk)
• 3️⃣ emit(写出 bundle)
4. 从源码到产物的 5 个阶段
Webpack的打包流程可以分为以下几个主要阶段:
(1)初始化阶段
- 读取配置文件 :解析
webpack.config.js或命令行传入的配置参数.
webpack启动时首先任务就是获取完整的配置信息,来源为配置文件和命令行参数; - 合并配置 :将命令行参数与配置文件合并.
Webpack 会将配置文件和命令行参数进行深度合并,生成一个最终的「合并配置对象」,合并逻辑主要是通过webpack-merge工具. - 创建Compiler对象 :初始化编译器实例,加载所有配置的插件
Compiler 是 Webpack 的核心编译器对象,负责统筹整个构建流程(从启动到输出结果),初始化过程包括:
绑定配置:将合并后的配置对象传入 Compiler,作为其内部状态的一部分。
加载插件:遍历配置中的 plugins 数组,调用每个插件的 apply 方法,让插件注册到 Compiler 的生命周期钩子中(如 beforeRun、emit 等)。 例如:HtmlWebpackPlugin 会在 emit 阶段生成 HTML 文件。
初始化内置工具:如模块解析器(Resolver)、依赖图管理器等,为后续的模块处理做准备。
javascript
const path = require('path');
module.exports = {
entry: './path/to/my/entry/file.js',
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'my-first-webpack.bundle.js',
}
};(2)编译准备阶段
在 Webpack 构建流程中,当完成初始配置解析和 Compiler 对象初始化后,会进入实际的编译准备阶段,这一阶段主要包括初始化工作目录、创建 Compilation 对象和执行编译前钩子,具体细节如下:
- 初始化工作目录 :设置入口上下文路径 Webpack 需要明确一个「基准目录」作为所有相对路径的参考,这个目录被称为上下文(context) 。 如果配置中未指定
context,则默认使用启动 Webpack 命令时的当前工作目录(process.cwd())。 也可在webpack.config.js中通过context字段指定,例如context: path.resolve(__dirname, 'src'),此时所有相对路径(如entry: './index.js')都会基于该目录解析。统一路径解析规则,避免因执行命令的目录不同而导致的路径错误,确保入口文件、加载器(loader)、插件等资源的路径解析一致。 - 创建Compilation对象 :每次编译都会创建新的Compilation实例
Compilation是 Webpack 中负责具体编译工作 的核心对象,它代表一次完整的编译过程(从模块解析到资源输出)。每次触发编译时(如首次构建、文件变化触发的重新构建)都会创建一个新的Compilation实例,确保每次编译的状态相互独立。Compilation对象在 Webpack 构建流程中的核心作用是作为单次编译过程的中央控制器,它通过管理所有模块及其依赖关系构建完整的依赖图(dependency graph),协调模块转换流程(如通过 loader 处理 ES6、TypeScript、CSS 等源码),执行 Tree-shaking 和代码压缩等优化操作,并最终将处理后的模块封装成 chunks 生成可部署的静态资源(如 bundle.js 和 chunk 文件),完整实现了从源代码到产出物的转换流水线。
与 Compiler 的关系 :
Compiler是全局管理者,负责统筹整个构建流程和生命周期;Compilation是单次编译的执行者,依赖Compiler提供的配置和钩子机制。
- 执行编译前钩子 :触发beforeRun、run等compiler钩子 Webpack 基于「钩子(hooks)」机制实现插件扩展,在编译开始前,会触发一系列
Compiler钩子,允许插件在编译启动前执行自定义逻辑。
- 关键钩子 :
beforeRun:在编译真正开始前触发(此时还未创建Compilation),可用于执行一些前置准备工作(如清理输出目录、检查环境依赖)。
run:在beforeRun之后、Compilation创建前触发,标志着编译流程正式启动。
compile:在Compilation实例创建前触发,插件可通过该钩子修改即将创建的Compilation的参数。
(3) 模块解析与构建阶段
-
从入口开始递归解析:根据entry配置找到入口文件
-
模块解析:使用resolver确定模块的完整路径
-
Webpack 使用内置的模块解析器(Resolver) 确定每个模块的完整物理路径,规则类似 Node.js 的 require.resolve(),但更灵活:
路径处理:
对于相对路径(如 ./utils):直接基于当前模块所在目录解析。
对于绝对路径(如 /src/config):基于 context 上下文路径解析。
对于模块名(如 lodash 或 react):先查找项目的 node_modules 目录,再查找全局模块目录。
自动补全:解析器会自动尝试补全文件扩展名(如 .js、.jsx、.ts,可通过 resolve.extensions 配置)、目录下的 index 文件(如 ./utils 会尝试 ./utils/index.js)。 extensions: '.js', '.vue', '.json', 配置扩展:可通过 webpack.config.js 的 resolve 字段自定义解析规则。 alias: { '@': resolve('src') } -
模块构建 :调用对应loader处理不同类型的模块(如JS、CSS、图片等) Loader 匹配:根据 module.rules 配置,对不同类型的文件匹配对应的 Loader 链。例如:
javascriptmodule: { rules: [ { test: /.css$/, use: ['style-loader', 'css-loader'] }, // CSS 文件先经 css-loader 处理,再经 style-loader 处理 { test: /.ts$/, use: 'ts-loader' } // TypeScript 文件用 ts-loader 转换为 JS ] }执行顺序:Loader 按 use 数组的从后往前顺序执行(如上述 CSS 规则中,css-loader 先执行,再将结果传给 style-loader)。
转换结果:Loader 将非 JS 模块转换为 JS 代码(例如:CSS 经 css-loader 处理后会变成导出样式字符串的 JS 模块),确保所有模块最终都能被 Webpack 当作 JS 处理。 -
依赖收集 :解析模块中的import/require语句,收集依赖关系 依赖识别:通过分析代码中的 import、require、import() 等语句,识别出当前模块依赖的其他模块。
递归收集:每识别出一个依赖,就会触发该依赖模块的解析流程(重复步骤 2-4),直到所有嵌套依赖都被处理。
动态依赖:对于动态导入(如 import('./pages/' + pageName)),Webpack 会将其识别为代码分割点,生成单独的 chunk 文件,实现按需加载。 -
AST解析 :对JavaScript代码进行抽象语法树分析
为了精确识别依赖和执行代码转换,Webpack 会将 JavaScript 代码解析为抽象语法树(AST)
AST 生成:使用 acorn 等解析器将代码字符串转换为结构化的 AST(一种描述代码语法结构的树状数据)。例如,import a from './a' 会被解析为包含 type: 'ImportDeclaration'、source: './a' 等字段的节点。
依赖提取:遍历 AST,找到所有 ImportDeclaration、CallExpression(对应 require)等节点,提取出依赖路径。
代码转换:部分 Loader 或插件会基于 AST 进行代码转换(如 Babel 转换 ES6+ 语法、Tree-shaking 移除未使用代码)。例如,Tree-shaking 会分析 AST 中的导出和引用关系,标记未使用的导出并在后续步骤中删除。
(4) 依赖图生成阶段
- 构建依赖图 :将所有模块及其依赖关系构建成依赖图
Webpack 会将所有解析过的模块及其相互依赖关系整合,形成一张完整的依赖图(Dependency Graph),该图以入口模块为根节点,通过递归遍历所有直接和间接依赖的模块(例如 A 模块依赖 B 模块,B 模块又依赖 C 模块),清晰映射出完整的模块引用网络。这张依赖图不仅是后续代码优化和打包的基础,更是 Webpack 确定最终输出内容的核心依据------它精确标识出需要包含的模块集合及其加载顺序,同时通过特殊处理机制(如模块缓存和引用隔离)有效解决循环依赖问题(例如 A → B → A 的闭环引用),确保复杂依赖关系下代码仍可正确执行。 - 模块优化 :执行各种优化操作,如tree shaking、作用域提升等
在构建完整的依赖图(Dependency Graph)后,Webpack 基于此图谱执行系统性优化:通过 Tree-shaking 静态分析 ES6 模块的import/export引用链,精准清除未使用的"死代码";利用 作用域提升(Scope Hoisting) 将关联模块合并至同一作用域,消除闭包开销并减少函数跳转损耗,显著提升运行时性能;借助 代码压缩工具 (如 TerserPlugin)实施三重精简策略------删除冗余字符、缩短标识符名称、合并等效语句;同时辅以模块去重、路径压缩、内容哈希缓存等协同优化,形成以依赖关系为决策核心的深度重构体系,最终产出高执行效率、小体积的现代化应用包。 - 模块封装 :将模块转换为可在浏览器中运行的代码 这一阶段是 Webpack 对模块进行深度处理和转换的核心环节,目标是将分散的模块整合为高效、可运行的代码,具体流程如下:
在模块优化完成后,Webpack 通过模块封装 将其转换为浏览器可执行的代码:首先注入自定义的__webpack_require__方法模拟 Node.js 的模块加载机制,解决浏览器原生不支持require的问题,实现模块隔离与依赖解析;同时为每个模块分配唯一 ID (或基于内容的哈希值),作为浏览器环境中的精准定位标识;再将核心的模块加载逻辑与依赖管理代码(即 运行时 runtime )直接嵌入输出文件,确保浏览器能自主解析模块依赖链;最终根据配置将代码封装为特定格式(如 IIFE 立即执行函数或 UMD 通用模块定义),使代码能在不同环境(浏览器、Node.js 等)中无缝运行。这一过程完整实现了从模块化源码到浏览器可执行产物的安全转换。
(5) 资源生成阶段
-
创建chunks :根据splitChunks配置将模块分组为不同的代码块
chunk 是 Webpack 对模块进行分组的单位,创建 chunk 的目的是实现代码分割和按需加载;
默认规则:Webpack 会为每个入口文件创建一个初始 chunk,并将其直接依赖的模块打包进去。
splitChunks 配置:通过 optimization.splitChunks 可自定义 chunk 分割规则,常见场景包括: 提取公共依赖(如将多个入口共用的 lodash 等库打包到 vendors chunk); 拆分大型模块(当模块体积超过阈值时自动拆分为独立 chunk); 分离异步依赖(动态导入 import() 引入的模块会自动生成单独 chunk)。
作用:减少重复代码、实现按需加载,提升页面加载速度(只加载当前页面所需的 chunk)。
jssplitChunks: { chunks: 'all', maxInitialRequests: Infinity, minSize: 20000, cacheGroups: { elementUI: { name: 'chunk-elementUI', // 单独将 elementUI 拆包 priority: 20, // 权重要大于 libs 和 app 不然会被打包进 libs 或者 app test: /[\/]node_modules[\/]element-ui[\/]/ }, commons: { name: 'chunk-commons', test: resolve('src/components'), // 可自定义拓展你的规则 minChunks: 3, // 最小公用次数 priority: 5, reuseExistingChunk: true } } }, -
模板渲染 :使用模板生成最终的bundle文件内容
Webpack 通过内置的「模板」将处理后的模块和 chunk 转换为可执行的 bundle 代码:
模板类型:根据 target 配置(如 web、node)使用不同模板,确保输出代码适配目标环境。
包裹逻辑:模板会为每个 chunk 添加包裹代码,实现模块的隔离和引用机制。 为每个模块分配唯一 ID,通过 webpack_require 方法实现模块间的引用。
-
资源清单生成 :创建assets对象,包含所有将要生成的文件
在输出文件前,Webpack 会生成一个完整的「资源清单」(assets 对象),统一管理所有待输出的资源:
assets 内容:该对象以「文件名」为键,以「文件内容 / 路径信息」为值,包含所有处理后的资源,如: JS bundle(如 main.js、vendors.js);
提取的 CSS 文件(如 style.css,需配合 mini-css-extract-plugin);
静态资源(如图片、字体,文件名可能包含 hash 用于缓存控制)。
hash 处理:根据文件内容生成 hash 并添加到文件名中(如 main.8f2b.js),实现长效缓存(内容不变则 hash 不变,浏览器可复用缓存)。
为输出做准备:assets 对象是后续「文件输出」阶段的直接数据源,Webpack 会根据该清单将所有资源写入到 output.path 配置的目录中。
(6) 文件输出阶段
- 文件写入:将生成的资源写入到输出目录
- 插件执行:触发emit、afterEmit等钩子,允许插件在文件写入前后执行操作
- 清理工作:执行最后的清理和收尾工作
5. 代码演示:把 6 行源码变成 2 个 bundle
入口文件内容
javascript
import loadsh from 'lodash'
const name = 'webpack'
function add(x, y) {
return x + y
}
add(3,5)webpack.config.js(关键片段)
css
module.exports = {
entry: {main: './src/index.js'},
output: {
filename: '[name].[contenthash:8].js',
},
optimization: {
splitChunks: {
chunks: 'all',
cacheGroups: {
vendor: {
test: /[\/]node_modules[\/]/,
name: 'vendor',
priority: 10,
},
},
},
}
}打包结果

6. 常见疑问 & 易混淆点
Q1:module 和 chunk 一定是 1:N 吗?
A:通常 1 个 chunk 包含多个 module;但 SplitChunksPlugin 可能把同一个 module 的副本 放进多个 chunk(为了并行加载),不过最终产物里的代码会借助 runtime manifest 保证只执行一次。
Q2:为什么 dev 模式下没有 contenthash?
A:dev 用内存文件系统,文件名固定方便 HMR;只有生产 emit 到磁盘时才需要长期缓存,故加 contenthash。
Q3:我写了 5 个 entry,却只看到 3 个 bundle?
A:若某些 entry 的依赖高度重叠,SplitChunksPlugin 会把它们合并进同一个 vendor chunk,减少 HTTP 请求。
7. 小结
• module = 源码文件
• chunk = 逻辑分组(Webpack 内部对象)
• bundle = 物理文件(磁盘产物)
记住"砖-墙-房子"比喻,就能在阅读任何 Webpack 日志或性能分析时快速定位:
- 想看依赖关系 → 找 module graph
- 想看代码分割 → 找 chunk graph
- 想看最终产物 → 看 dist 目录 bundle